2026 Web Crawler Benchmark to Feed Websites to AI
We benchmarked four crawl APIs across three domains of varying difficulty at three max depth levels (5, 10, 20) with a 1,000-page limit, measuring crawl coverage, execution time, link discovery, markdown link quality, and title extraction accuracy.
If you aim to:
- Turn web pages into structured data, see our guide on web scraping.
- Crawl entire websites, read on.
Web crawlers benchmark
You can read our benchmark methodology.
Average crawled pages vs cost per 1,000 pages
Crawled pages across domains by max depth
Firecrawl consistently crawled around 100 pages on theregister.com regardless of max depth, approximately 90 pages on entrepreneur.com across all depth levels, and only around 30 pages on amazon.com, likely due to Amazon’s aggressive bot protection. Notably, increasing max depth had virtually no impact on the number of pages Firecrawl was able to crawl across any domain.
Apify demonstrated the most consistent performance, reaching the maximum crawl limit of 1,000 pages on every domain at every depth level without any apparent difficulty, even on heavily protected sites like Amazon.
Cloudflare showed inconsistent behavior across tests:
- On theregister.com at max depth 5, it crawled only 100 pages, but at max depth 20 it reached nearly 1,000 pages.
- As we observed in earlier tests, Cloudflare occasionally crawls just 1 page and then terminates the job entirely. We confirmed this is not a caching issue (cache was disabled) and tested with wait times between runs of up to 1 minute, but the behavior persisted. At max depth 10 on theregister.com, this exact issue occurred, Cloudflare crawled only 1 page before stopping.
- On entrepreneur.com, Cloudflare crawled 780 pages at depth 5, increased to 885 at depth 10, but then dropped sharply to just 172 pages at depth 20. This drop may be related to Cloudflare’s crawl scheduler deprioritizing or timing out deeper link chains, or it could reflect an internal concurrency limit that causes the job to terminate prematurely when the crawl frontier grows too large at higher depths.
- On amazon.com, Cloudflare crawled 905 pages at depth 5, but the number steadily declined as max depth increased, dropping to 809 at depth 10 and 795 at depth 20, suggesting that deeper crawl configurations may cause Cloudflare to spend more time on link discovery overhead rather than actual page retrieval.
Nimble reached or approached the 1,000-page limit on theregister.com across all depth levels (1,000 / 1,000 / 999). On entrepreneur.com, it crawled 1,000 pages at depth 5 but showed slight drops at higher depths (896 at depth 10, 983 at depth 20), possibly due to its 7-hour timeout being reached before completing the full crawl at deeper levels, all Nimble runs ended with a timeout status. Amazon proved more challenging:
- At depth 5 it managed only 319 pages, but at depth 10 it jumped to 988 pages, then dropped to 906 at depth 20
- This inconsistency likely reflects the combination of Amazon’s bot protection mechanisms and Nimble’s timeout constraints, where deeper crawls take longer to process each page and may encounter more anti-bot challenges along the way
Execution time across domains by max depth
Firecrawl was the fastest provider across all domains, completing crawls in under 5 minutes, typically between 75-265 seconds. This speed comes at the cost of coverage, as Firecrawl also crawled the fewest pages. Essentially, it finishes quickly because it stops early.
Apify took around 2,200-2,400 seconds (~40 minutes) on theregister.com regardless of depth. On entrepreneur.com and amazon.com, execution times were significantly longer at 8,300-15,900 seconds (2-4 hours), reflecting the larger and more complex site structures. Despite the longer times, Apify consistently reached the 1,000-page limit, making it the most reliable in terms of coverage-to-time ratio.
Cloudflare showed timing that mirrors its inconsistent crawl counts:
- On theregister.com at depth 10, it completed in just 1 second, because it only crawled 1 page before stopping.
- On entrepreneur.com at depth 20, it finished in 10 seconds after crawling only 172 pages.
- When Cloudflare does complete a full crawl, times range from 3,500 to 25,200 seconds.
- As max depth increases, Cloudflare appears to prioritize reaching deeper pages over breadth, crawling fewer pages but completing faster. On amazon.com, execution time dropped from 25,200 seconds (timeout) at depth 5 to just 5,660 seconds at depth 20, while crawled pages also decreased from 905 to 795. This suggests Cloudflare’s crawler shifts its strategy at higher depths, spending less time on broad discovery and more on deep traversal.
Nimble hit the 7-hour timeout (25,200 seconds) on every single run across all domains and depth levels. This is notable because in our earlier quick tests with max depth 1, Nimble completed without timing out. In the full benchmark with depths of 5-20 and a 1,000-page limit, it consistently ran until the timeout was reached. Despite this, Nimble still managed to crawl a high number of pages in most cases (~900-1,000 on theregister.com and entrepreneur.com), meaning it is actively crawling throughout the 7 hours but simply never signals completion.
Link text fill rate across providers by max depth
To assess markdown output quality, we measured what percentage of links in each provider’s markdown contain anchor text, the clickable text portion of a link. A missing anchor text (e.g., [](/about) instead of [About Us](/about)) means the crawler failed to extract the link’s label.
- Nimble: 100% across all depths
- Cloudflare: 91-94%
- Firecrawl: 90%
- Apify: 77-78% , roughly 1 in 5 links missing anchor text
Crawl depth had minimal impact on fill rates for any provider, suggesting this is a characteristic of each provider’s parsing engine rather than a crawl setting.
Link text fill rate across providers by domain
Looking at fill rates across different domains reveals how site complexity affects each provider’s link extraction quality.
- Nimble maintained 100% across all domains.
- Apify showed the most variation, 89% on amazon.com but dropping to 66% on entrepreneur.com, meaning one-third of its links on that site were missing anchor text. This suggests Apify struggles more with content-heavy sites that have complex navigation structures.
- Firecrawl performed best on theregister.com (98%) but dropped to 81% on entrepreneur.com, following a similar pattern to Apify.
- Cloudflare was the most consistent after Nimble, staying between 89-94% regardless of domain.
Entrepreneur.com proved the most challenging domain for link text extraction, both Apify (66%) and Firecrawl (81%) had their lowest scores there, likely due to the site’s heavy use of nested navigation menus and dynamic content elements that are harder to convert cleanly into markdown.
Total links in markdown output across domains by max depth
Link count variance across providers was consistently high (74-97%), indicating that providers extract very different numbers of links from the same pages. To get a more detailed view of this disparity, we measured the total markdown link count per provider.
- Apify returned the most links overall, particularly on amazon.com with over 420K links at depth 5 (~423 per page). On entrepreneur.com it stabilized around 63K regardless of depth. Its output includes ad trackers and tracking pixels alongside page content links.
- Cloudflare peaked at 303K on entrepreneur.com at depth 10 but dropped to 53K at depth 20. On the same entrepreneur.com homepage, Cloudflare extracted 434 links compared to Apify’s 143, capturing full navigation menus and submenus.
- Firecrawl consistently returned 5-9K links across all configurations, limited by its low page count.
- Nimble returned 3-40K links total, averaging 5-28 links per page compared to 60-420 for other providers. On entrepreneur.com’s homepage, Nimble returned 13 links versus Cloudflare’s 434, limited to main article headlines. Its 100% fill rate reflects that the links it did include all had anchor text, rather than indicating comprehensive link coverage. Nimble does not output standard markdown links. Its count includes escaped HTML links found within the markdown output.
Title present rate across providers
Title similarity across providers showed less than 1% deviation across all tests and domains, confirming that when providers do extract a title, they consistently return the same result. Title present rate also remained between 98-100% across all max depth levels, showing that crawl depth has no meaningful impact on title extraction.
When broken down by domain, some differences emerged:
On entrepreneur.com and theregister.com, most providers achieved 99-100% title present rates. Amazon.com was the only domain where meaningful differences appeared, Firecrawl dropped to 93% and Nimble to 95.9%, while Apify maintained 99.6%. This aligns with Amazon’s heavier bot protection, which can block or distort page responses, causing some providers to return pages without extractable titles.
What is a web crawler?
A web crawler, sometimes called a “spider” or “agent,” is a bot that browses the internet to index content.
Crawlers have moved beyond search engines and now serve as the Agentic Data Layer. They act as the eyes for autonomous AI agents like Claude Code and OpenAI Operator, assisting with real-time tasks such as competitive research and multi-step transactions.
What does a web crawler do?
Web crawling was split into three modes, each designed for a different crawler goal.
- Discovery mode (traditional): Search engine bots like Googlebot crawl URLs for indexing, helping people find results through search engines.
- Retrieval Mode (RAG): AI bots like ChatGPT-User or PerplexityBot fetch specific pages in real time to answer user prompts. They use markdown instead of HTML to fit the AI model’s token limits.
- Agentic Mode (Action-Oriented): This new type of crawler in 2026 does more than just read content. Using Model Context Protocol (MCP), these bots can interact with websites to book flights or run software commands.
In the past, crawlers used selectors such as XPath or CSS to extract data. AI-Native Extraction has become the norm.
Tools such as Firecrawl and Crawl4AI use natural language instructions to find data. Instead of writing rules for each element, developers can tell the crawler to “extract the product price,” and the AI will find the right value even if the website’s code changes.
Build vs. buy web crawlers in the AI era
1. Building Your Own Crawler
Ideal for protecting core intellectual property and enabling deep customization. Building now requires developing a proprietary agent layer, not just writing basic Scrapy scripts.
- When to build: Select this approach if your crawler provides a unique competitive advantage. For instance, build your own if you are developing a specialized search engine or require complete control over sensitive or regulated data.
- The toolset: You no longer need to start from scratch. Developers now leverage the Model Context Protocol (MCP) to enable internal AI agents to interact with the web.
2. Using Web Crawling Tools & APIs
Managed tools have advanced from basic scrapers to autonomous agents.
- Zero-maintenance extraction: Modern tools such as Kadoa and Firecrawl use self-healing AI. You specify the required data, such as “Product Price,” rather than its location in the code. If the website layout changes, the tool adapts automatically.
- Compliance as a service: Many providers offer built-in compliance with the EU AI Act. They manage required audit logs and copyright opt-out checks, which are challenging to implement independently.
- Speed to value: Purchasing a platform can move your project from concept to production within weeks.
Figure 5: An explanation of how a URL frontier works.
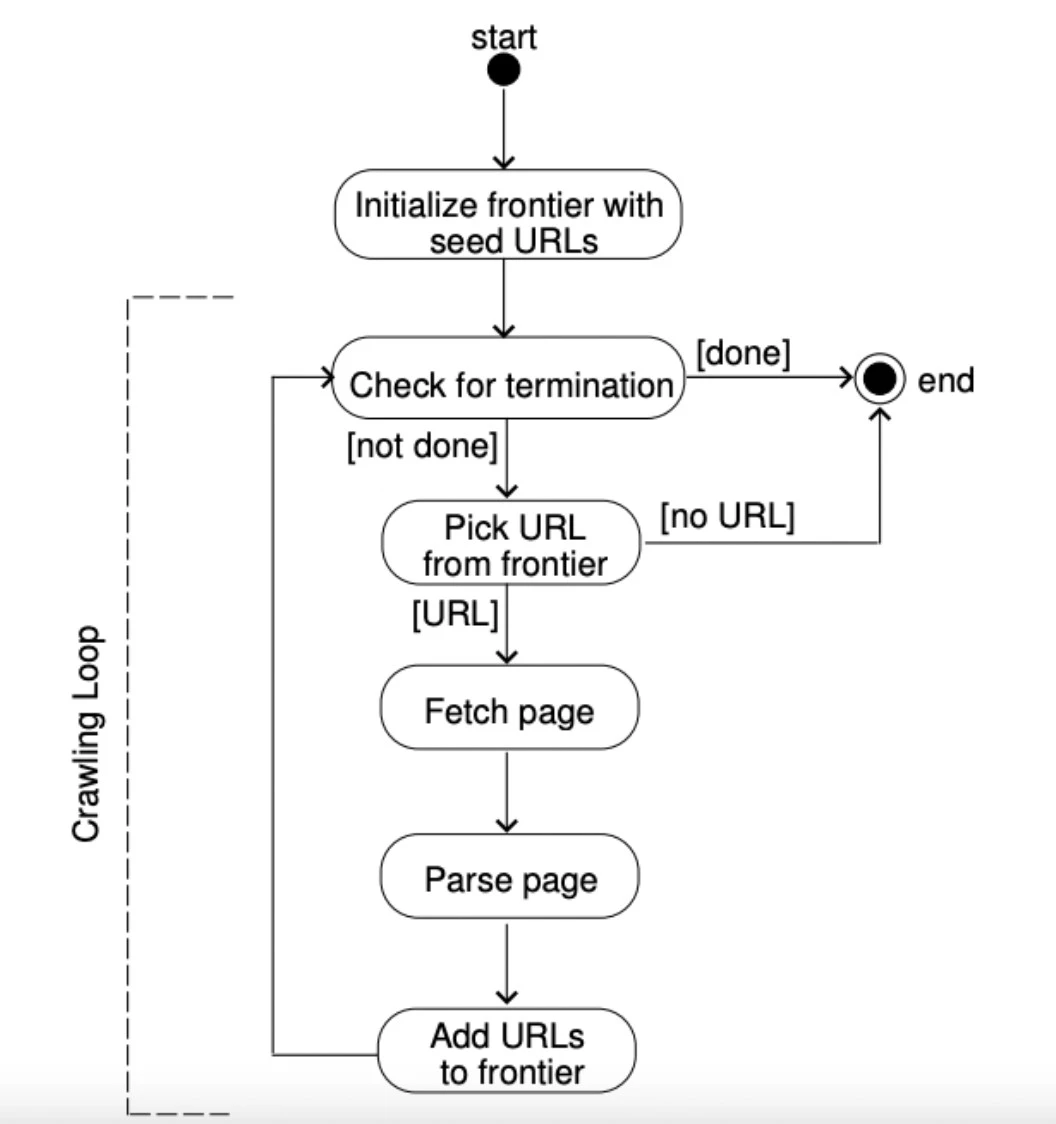
Are web crawlers legal?
In general, web crawling is legal, but depending on how and what you crawl, you could quickly find yourself in a legal bind. Four major pillars determine whether crawling (and the scraping that typically follows) is legal:
1. Public vs. private: Only crawl data that is openly available to the public without an account.
2. Personal information: Steer clear of PII (names, emails, and addresses) unless you have a lawful basis.
3. Server health: Use rate limits to avoid slowing down the server; avoid “DDOSing” a website.
4. Copyright: Articles and images are protected by copyright, but facts (prices, dates) are not.
What is the difference between web crawling and web scraping?
Web scraping is using web crawlers to scan and store all the content from a targeted webpage. In other words, web scraping is a specific use case of web crawling to create a targeted dataset, such as pulling all the finance news for investment analysis and searching for specific company names.
Traditionally, once a web crawler has crawled and indexed all of the elements of the web page, a web scraper extracted data from the indexed web page. However, these days scraping and crawling terms are used interchangeably with the difference that crawler tends to refer more to search engine crawlers. As companies other than search engines started using web data, the term web scraper started taking over the term web crawler.
What are the challenges of web crawling?
1. Database freshness
Websites’ content is updated regularly. Dynamic web pages, for example, change their content based on the activities and behaviors of visitors. This means that the website’s source code does not remain the same after you crawl the website. To provide the most up-to-date information to the user, the web crawler must re-crawl those web pages more frequently.
2. Crawler traps
Websites employ different techniques, such as crawler traps, to prevent web crawlers from accessing and crawling certain web pages. A crawler trap, or spider trap, causes a web crawler to make an infinite number of requests and become trapped in a vicious crawling circle. Websites may also unintentionally create crawler traps. In any case, when a crawler encounters a crawler trap, it enters something like an infinite loop that wastes the crawler’s resources.
3. Network Bandwidth
Downloading a large number of irrelevant web pages, utilizing a distributed web crawler, or recrawling many web pages all result in a high rate of network capacity consumption.
4. Duplicate pages
Web crawler bots mostly crawl all duplicate content on the web; however, only one version of a page is indexed. Duplicate content makes it difficult for search engine bots to determine which version of duplicate content to index and rank. When Googlebot discovers a group of identical web pages in search result, it indexes and selects only one of these pages to display in response to a user’s search query.
Top 3 web crawling best practices
1. Politeness/Crawl rate
Websites set a crawl rate to limit the number of requests made by web crawler bots. The crawl rate indicates how many requests a web crawler can make to your website in a given time interval (e.g., 100 requests per hour). It enables website owners to protect the bandwidth of their web servers and reduce server overload. A web crawler must adhere to the crawl limit of the target website.
2. Robots.txt compliance
A robots.txt file is a text file placed at the root of a website that tells crawlers which pages they are allowed or disallowed to access. It is a voluntary standard, meaning compliant bots respect it but it does not technically prevent access. Following a website’s robots.txt is considered a best practice, and in many jurisdictions, ignoring it may expose you to legal or reputational risk.
3. IP rotation
Websites employ different anti-scraping techniques such as CAPTCHAs to manage crawler traffic and reduce web scraping activities. For instance,browser fingerprinting is a tracking technique used by websites to gather information about visitors, such as session duration or page views.
This method allows website owners to detect “non-human traffic” and block the bot’s IP address. To avoid detection, you can integrate rotating proxies, such as residential proxies, into your web crawler.
Web crawlers benchmark methodology
We tested four crawl APIs (Apify, Nimble, Cloudflare, Firecrawl) on three domains of varying difficulty: amazon.com (heavy bot protection), entrepreneur.com (complex content site), and theregister.com (news site).
Shared configuration
All providers received identical core settings to ensure a fair comparison:
- Sitemap: Disabled, providers must discover pages through HTML links only
- External links: Disabled, crawlers stay within the target domain
- Subdomains: Enabled, subdomain pages are followed (e.g., india.entrepreneur.com)
- JavaScript rendering: Enabled, all providers use a headless browser
- Cache: Disabled
- Page limit: 1,000 pages per run
- Timeout: 7 hours (25,200 seconds)
- Rate limit handling: 20-second wait with up to 3 retries on HTTP 429
Each provider was tested at three max depth levels (5, 10, 20) across all three domains, totaling 36 crawl runs. Providers were tested sequentially (not in parallel), each combination was run once, and crawl status was polled every 1 second.
Apify was configured with the website-content-crawler actor using Playwright/Firefox as its headless browser. Subdomain access was controlled via glob patterns, and Apify’s built-in proxy was used for all requests.
Nimble, Cloudflare, and Firecrawl were configured using their respective REST APIs with the shared settings described above. No additional provider-specific configurations were applied beyond the standardized parameters.
For Cloudflare, we used the Workers Paid plan. The reported cost reflects what we spent to crawl 1,000 pages under this plan. Cloudflare charges based on browser rendering time rather than page count.
For Firecrawl, we used the Hobby plan. The reported cost is the prorated amount for 1,000 credits out of the credits provided in this plan. Effective per-page cost varies depending on the plan tier and whether extra credit packs are purchased.
Cite this research
Pick the format that matches where you're publishing. Pasting the link version into your CMS preserves the backlink.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Şipi, Nazlı},
title = {{2026 Web Crawler Benchmark to Feed Websites to AI}},
year = {2026},
month = jul,
howpublished = {\url{https://aimultiple.com/web-crawler}},
note = {AIMultiple. Retrieved July 2, 2026}
}Cem's work has been cited by leading global publications including Business Insider, Forbes, Washington Post, global firms like Deloitte, HPE and NGOs like World Economic Forum and supranational organizations like European Commission. You can see more reputable companies and resources that referenced AIMultiple.
Throughout his career, Cem served as a tech consultant, tech buyer and tech entrepreneur. He advised enterprises on their technology decisions at McKinsey & Company and Altman Solon for more than a decade. He also published a McKinsey report on digitalization.
He led technology strategy and procurement of a telco while reporting to the CEO. He has also led commercial growth of deep tech company Hypatos that reached a 7 digit annual recurring revenue and a 9 digit valuation from 0 within 2 years. Cem's work in Hypatos was covered by leading technology publications like TechCrunch and Business Insider.
Cem regularly speaks at international technology conferences. He graduated from Bogazici University as a computer engineer and holds an MBA from Columbia Business School.

Comments 1
Share Your Thoughts
Your email address will not be published. All fields are required. Comments are left in their original language.
Hi Cem, I think there is a misunderstanding regarding the robots.txt role in the crawling context. The web bots can crawl any website when indexing is allowed without having the robots.txt somewhere on their top domain, subdomains and ports and so on. The role of a robots.txt is to keep control of the traffic from web bots so the website is not overloaded by requests.