Agentic RAG enhances traditional RAG by boosting LLM performance and enabling greater specialization. We conducted a benchmark to assess its performance on routing between multiple databases and generating queries.
Explore agentic RAG frameworks and libraries, key differences from standard RAG, benefits, and challenges to unlock their full potential.
Agentic RAG benchmark: Multi-database routing and query generation
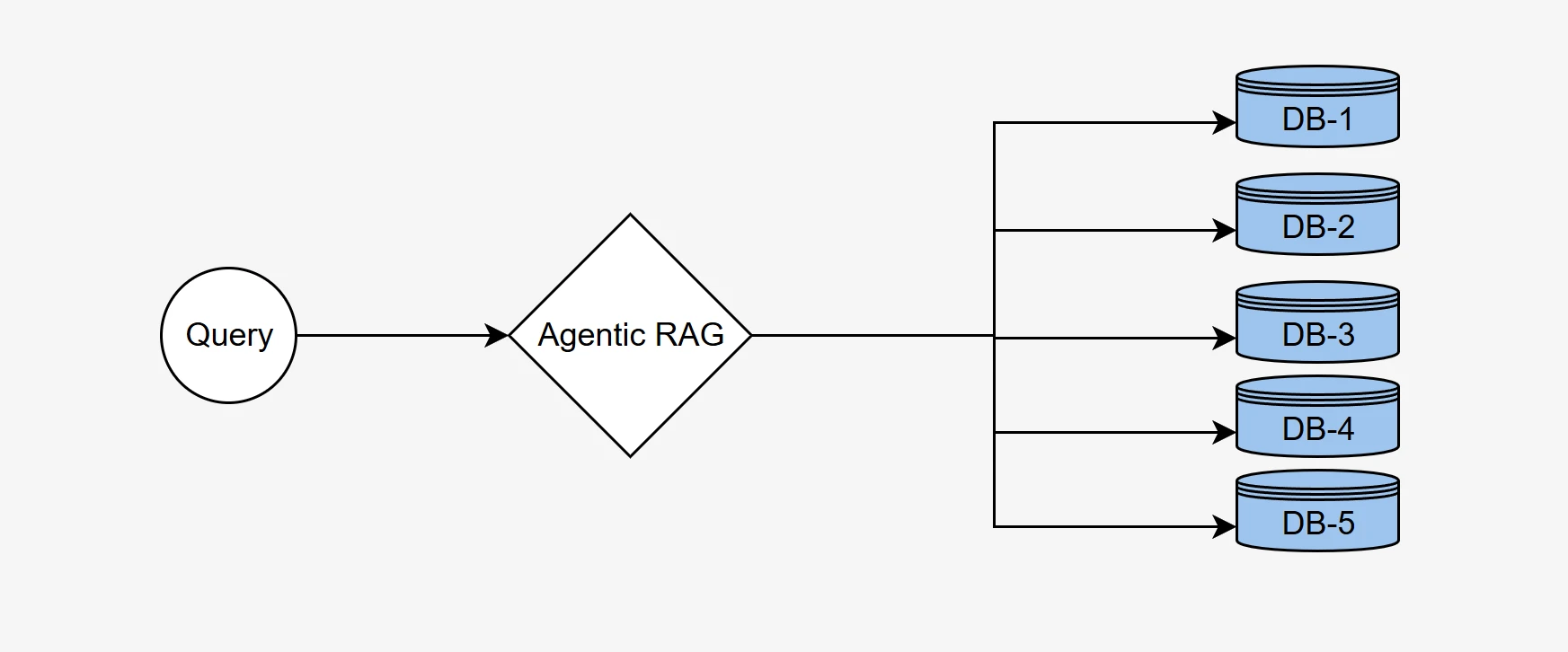
We used our agentic RAG benchmark methodology to demonstrate the system’s ability to select the correct database from a set of five distinct databases, each with unique contextual information, and generate semantically accurate SQL queries to retrieve the correct data.
In the agentic RAG benchmark, we used:
- Agent Framework: Langchain
- Vector database: ChromaDB
In many real-world enterprise scenarios, data is often distributed across multiple databases, each containing specialized information relevant to specific domains or tasks. For example, one database might store financial records, while another holds customer data or inventory details.
An effective Agentic RAG system must intelligently route a user’s query to the most relevant database to retrieve accurate information. This process involves analyzing the query, understanding the context, and selecting the appropriate data source from a set of available databases.
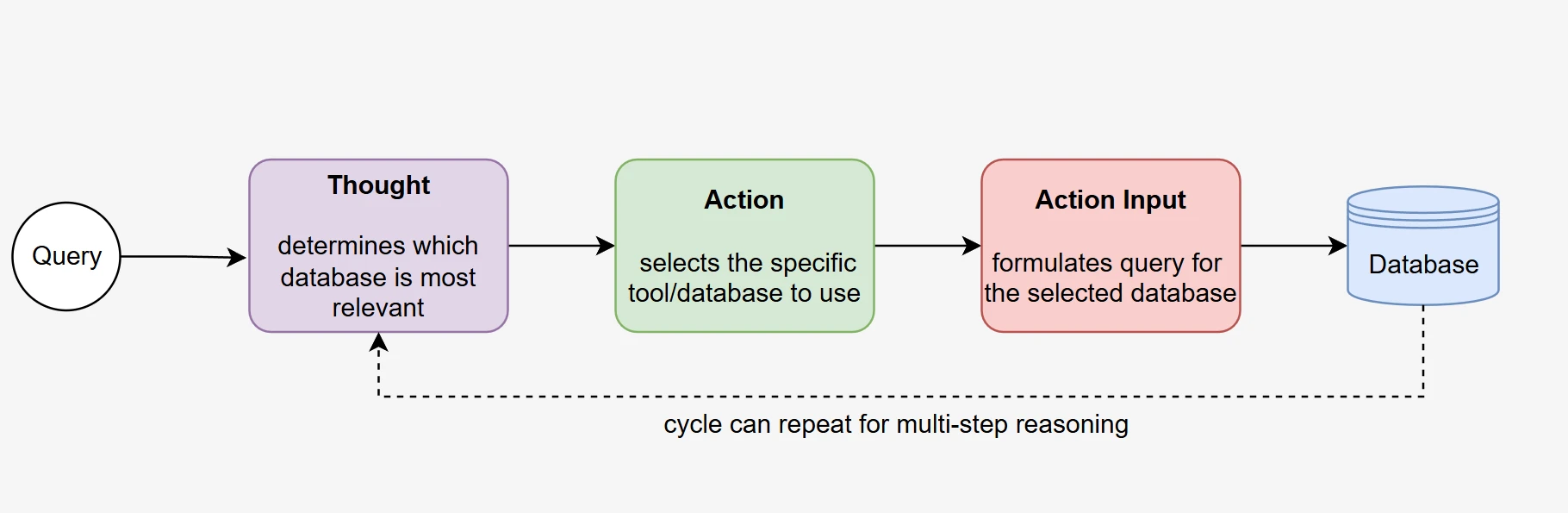
Agent’s thought process
At the heart of an Agentic RAG system lies the LLM’s ability to autonomously reason and act to achieve a goal. Our function-calling-based approach enables models to demonstrate true agentic behavior through self-directed database selection and iterative information gathering.
Autonomous decision making: The agent analyzes the incoming user query and autonomously determines which database function to call based on query context and available function descriptions. This decision-making process occurs without predetermined routing rules, demonstrating genuine reasoning capabilities.
Multi-step execution: The agent typically performs multiple function calls in sequence, first to identify and access the relevant database, then to gather detailed schema information, and finally to refine its understanding before generating the SQL query. This iterative process mirrors human problem-solving approaches.
Self-correction capability: When initial function calls don’t provide sufficient information, the agent can autonomously decide to make additional calls with refined parameters, demonstrating adaptive behavior that goes beyond simple retrieval systems.
Goal-directed behavior: Throughout the process, the agent maintains focus on generating an accurate SQL query, using each function call result to inform subsequent decisions and actions.
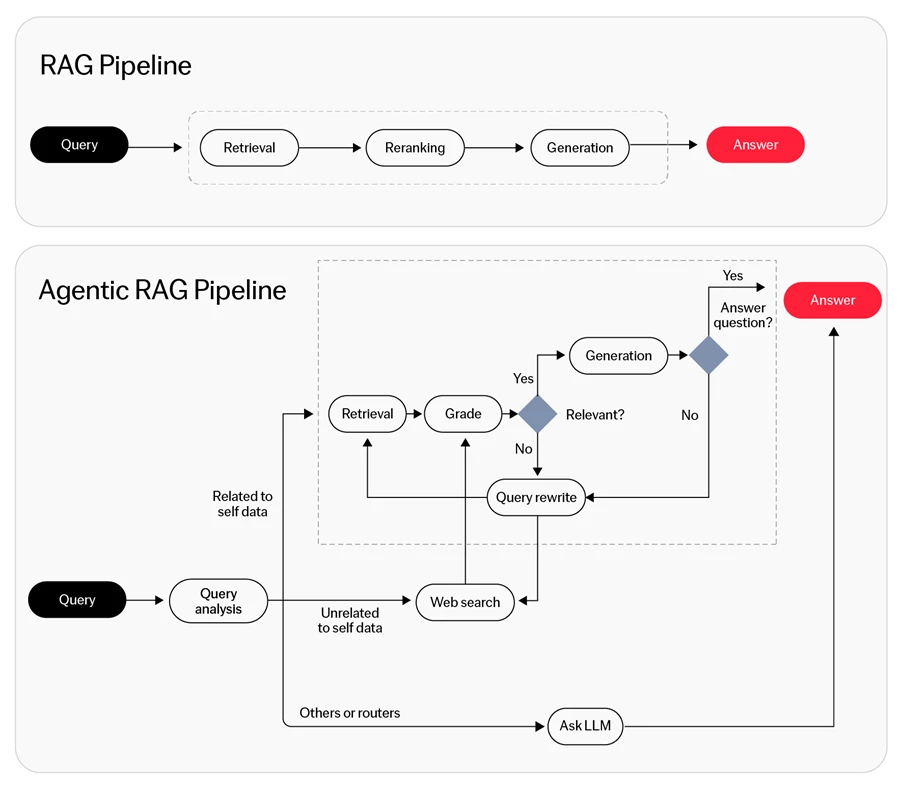
This autonomous, multi-turn interaction pattern fundamentally differentiates agentic RAG from traditional RAG systems that follow predetermined pathways and single-shot retrieval mechanisms.
Agentic RAG benchmark methodology
This benchmark evaluates the capability of Large Language Models (LLMs) to function as autonomous agents within a Retrieval-Augmented Generation (RAG) pipeline. Specifically, it measures two core competencies:
- Database routing: The agent’s ability to correctly identify and select the most relevant database from multiple candidates given a natural language question.
- SQL generation: The agent’s ability to generate an accurate SQL query using the schema of the selected database.
Dataset
The benchmark utilizes the BIRD-SQL dataset1 , a widely adopted academic benchmark for text-to-SQL tasks. BIRD-SQL provides natural language questions paired with ground truth database identifiers and gold-standard SQL queries, making it ideal for evaluating both routing accuracy and query generation quality.
From the full BIRD-SQL dataset, we curated a subset of 500 questions distributed across five distinct databases covering diverse domains:
Each question has exactly one correct target database. The answer to every question resides in one specific database, requiring the agent to make a definitive routing decision.
Semantic ambiguity challenge
To evaluate the agent’s reasoning capabilities beyond surface-level keyword matching, we introduced cross-database semantic similarity as a deliberate confounding factor during question selection.
Question selection process:
- All candidate questions from the five databases were embedded using sentence transformers (
all-MiniLM-L6-v2). - Cross-database question pairs were computed and ranked by cosine similarity.
- Questions with cross-database cosine similarity scores above 0.70 were intentionally prioritized for inclusion, creating scenarios where semantically similar questions belong to entirely different databases.
Example of semantic confounding:
Question A (financial DB): “For the client whose loan was approved first on 1993/7/5, what is the increase rate of his/her account balance from 1993/3/22 to 1998/12/27?”
Question B (debit_card DB): “For the customer who paid 634.8 in 2012/8/25, what was the consumption decrease rate from Year 2012 to 2013?”
Both questions follow nearly identical semantic patterns: they identify a specific customer through a transaction event, then calculate a rate change over a time period. Yet the correct databases differ entirely; one requires loan and account data, while the other needs transaction and consumption data. This forces the agent to perform deeper contextual reasoning about the data domain rather than relying on surface-level financial keywords that would match both databases.
Database environment
The schema and a brief natural language description of each database were stored in ChromaDB, a vector database used for efficient semantic retrieval. Each database’s collection contains:
- A high-level description of the database’s domain and purpose
- Per-table schema documents, including column names, data types, and value descriptions
This setup allows the agent to retrieve relevant schema information through semantic search after selecting a target database.
Agent architecture
A function-calling-based agentic architecture was employed across all models to ensure fair and standardized comparison. Each of the five databases was represented as a distinct callable function (tool) with standardized parameters. This design leverages each model’s native function calling capabilities, enabling models to autonomously:
- Analyze the incoming question
- Select and invoke the appropriate database function
- Receive schema information as a function response
- Optionally invoke additional functions for refinement
- Generate the final SQL query
This approach maintains a consistent evaluation methodology across different model families, including traditional models and reasoning-optimized models.
Agentic process flow
The system implements a genuine multi-turn agentic loop rather than a fixed pipeline:
- Question analysis: The agent receives the natural language question along with descriptions of all five available database functions.
- Database selection (Tool call): The agent autonomously selects and calls the database function it deems most relevant. This is a real function call; the agent receives the schema as a structured tool response within the same conversation context.
- Schema reasoning: The agent observes the returned schema and reasons about which tables and columns are relevant to the question.
- Optional recovery: If the agent determines that the selected database does not contain the required information, it may call a different database function enabling self-correction without external intervention.
- SQL generation: Based on the accumulated context (question + schema observation), the agent produces the final SQL query.
This multi-turn conversational flow differentiates the benchmark from traditional single-shot RAG approaches. The agent maintains full context across turns, can observe the results of its actions, and can iteratively refine its approach hallmarks of true agentic behavior.
Key architectural properties:
- The conversation is continuous, the agent sees its own prior reasoning and tool responses
- No artificial turn limits are imposed; the agent decides when it has sufficient information
- Both database selection and SQL generation occur within the same agentic session
- The number of tool calls per question is recorded as an additional metric for analyzing agent efficiency
Evaluation process
For each question in the benchmark:
Step 1: Database routing evaluation
The agent’s first database function call is recorded as its routing decision. This is compared against the ground truth database specified in the BIRD-SQL dataset.
Metric: Database routing accuracy (% correct selections out of total questions)
Step 2: SQL quality evaluation
The SQL query generated by the agent is evaluated using an LLM-as-Judge approach. A separate judge model (Claude 4 Sonnet) receives both the agent’s generated SQL and the BIRD-SQL ground truth SQL, and assigns a semantic similarity score on a 0–5 scale:
Important design decision: SQL quality is evaluated when the agent selects the correct database. If the agent routed to the wrong database, it receives an automatic score of 0, since a SQL query against the wrong schema is inherently meaningless. This ensures the SQL quality metric purely reflects query generation ability, uncontaminated by routing errors.
Metrics:
- Average SQL quality score (out of 5.0), computed over correctly-routed questions
- Perfect match rate: percentage of correctly-routed questions scoring 5/5
Controlled variables
To ensure fair comparison across models:
- All models receive identical system prompts and tool definitions
- Temperature is set to 0 for deterministic outputs
- No model-specific prompt engineering or few-shot examples are provided (zero-shot evaluation)
- The BIRD-SQL evidence field (domain-specific hints) is withheld from all models to measure unassisted reasoning
- All models access the same ChromaDB instance with identical schema embeddings
Agentic RAG frameworks & libraries
Agentic RAG frameworks enable AI systems to find information, reason, make decisions, and take action. Top tools and libraries that power Agentic RAG:
This list includes tools that meet the following criteria:
- 50+ stars on GitHub.
- Common usage in Agentic RAG projects.
Note that in the table:
- Tool use refers to the native ability of a system to route and call tools within its environment.
- Tool type refers to the main usage area of the tools, such as:
- Agentic RAG frameworks are designed specifically for building, deploying, or configuring Agentic RAG systems.
- Agent libraries enable the creation of intelligent agents that can reason, make decisions, and execute multi-step tasks.
- LLMOps frameworks manage the lifecycle of LLMs and optimize the deployment and use of LLMs within agent-based systems.
- LLMs that have built-in capabilities for tool calling and routing, allowing for dynamic decision-making. Other LLMs may require external APIs or integrations to enable agent functionality.
- Verification of tool use and agent types is achieved through public sources.
What is the agentic RAG?
Agentic Retrieval-Augmented Generation (RAG) is an AI framework that combines retrieval techniques with generative models to enable dynamic decision-making and knowledge synthesis. This approach integrates the accuracy of traditional RAG with the generative capabilities of advanced AI, aiming to enhance the efficiency and effectiveness of AI-driven tasks.
Limitations of traditional RAG systems
Agentic RAG aims to overcome the limitations faced with the standard RAG system, such as:
- Difficulty in information prioritization: RAG systems often struggle to efficiently manage and prioritize data within large datasets, which can reduce overall performance.
- Limited integration of expert knowledge: These systems may undervalue specialized, high-quality content, favoring general information instead.
- Weak contextual understanding: While capable of retrieving data, they frequently fail to fully comprehend its relevance or how it aligns with the specific query.
How to build an agentic RAG
1. Tool use
- Employ routers: The first step involves employing routers to determine whether to retrieve documents, perform calculations, or rewrite the query. This approach adds decision-making capabilities to route requests to multiple tools, enabling large language models (LLMs) to select appropriate pipelines.
- Tool-calling integration: This refers to creating an interface for agents to connect with selected tools. Users can leverage LLMs with tool-calling capabilities or build their own to:
- Pick a function to execute.
- Infer the necessary arguments for that function.
- Enhance query understanding beyond traditional RAG pipelines, enabling tasks like database queries or complex reasoning.
2. Agent implementation
- Single-call agents: A query triggers a single call to the appropriate tool, returning the response. This is effective for straightforward tasks, but may struggle with vague or complex queries.
- Multi-call agents: This approach involves dividing tasks among specialized agents, with each agent focusing on a specific subtask. For example:
- Retriever agent: Optimizes real-time query retrieval.
- Manager agent: Handles task delegation and orchestration.
3. Multi-step reasoning
For complex workflows, agents use reasoning loops to perform iterative, multi-step reasoning while retaining memory of intermediate steps. These loops involve:
- Calling multiple tools.
- Retrieving data and validating its relevance.
- Rewriting queries as needed.
Frameworks often define multiple agents to handle specific subtasks, ensuring efficient execution of the overall process.
4. Hybrid approaches: combining retrieval and execution
A hybrid approach combines retrieval pipelines with dynamic execution strategies:
- Embedding and vector-based retrieval strategies for document access.
- Tool-calling capabilities for dynamic query resolution.
- Multi-agent collaboration for specialized subtasks.
What is the difference between RAG and agentic RAG?
Here are the strengths and weaknesses of RAG vs. Agentic RAG based on different aspects:
- Prompt engineering
- Traditional RAG: Relies heavily on manual optimization of prompts.
- Agentic RAG: Dynamically adjusts prompts based on context and goals, reducing the need for manual intervention.
- Context awareness
- Traditional RAG: Has limited contextual awareness and relies on static retrieval processes.
- Agentic RAG: Considers conversation history and adapts retrieval strategies dynamically based on context.
- Autonomy
- Traditional RAG: Lacks autonomous actions and cannot adapt to evolving situations.
- Agentic RAG: Performs real-time actions and adjusts based on feedback and real-time observations.
- Reasoning
- Traditional RAG: Requires additional classifiers and models for multi-step reasoning and tool usage.
- Agentic RAG: Handles multi-step reasoning internally, eliminating the need for external models.
- Data quality
- Traditional RAG: Has no built-in mechanism to evaluate data quality or ensure accuracy.
- Agentic RAG: Evaluates data quality and performs post-generation checks to ensure accurate outputs.
- Flexibility
- Traditional RAG: Operates on static rules, limiting adaptability.
- Agentic RAG: Employs dynamic retrieval strategies and adjusts its approach as needed.
- Retrieval efficiency
- Traditional RAG: Retrieval is static and often costly due to inefficiencies.
- Agentic RAG: Optimizes retrievals to minimize unnecessary operations, reducing costs and improving efficiency.
- Simplicity
- Traditional RAG: Features a straightforward setup with fewer configuration complexities.
- Agentic RAG: Involves more complex configurations to support dynamic and context-aware operations.
- Predictability
- Traditional RAG: Consistent and rule-based, but rigid in behavior.
- Agentic RAG: Behavior can vary dynamically based on real-time context and observations.
- Cost in deployments
- Traditional RAG: Cheaper for basic setups, but may incur higher long-term operational costs.
- Agentic RAG: Requires a higher initial investment due to advanced features and dynamic capabilities.
Long-context models vs agentic RAG: When retrieval becomes unnecessary
The context window revolution of 2025-2026 challenges a core assumption in RAG architecture. Models now support 1-2 million tokens, forcing a fundamental question: when does direct context processing outperform complex retrieval agents?
The shifting context landscape
Context windows expanded dramatically from 128k tokens in early 2024 to over 1M in 2026. Recent research using full-length novels as test data reveals that this expansion creates new architectural trade-offs engineers must consider.4
Computational cost of processing massive contexts must be weighed against the engineering complexity and potential failure points of retrieval systems. Processing 1M tokens eliminates the lossy compression of chunking and indexing, but at a high per-query cost.
The retrieval bottleneck problem
Research on long-form documents identifies a severe limitation in traditional RAG approaches. Standard top-k retrieval creates what researchers call a “retrieval bottleneck”: when the initial fetch misses the relevant chunk, the system lacks a recovery mechanism.
Agentic RAG addresses this through iterative query refinement. Studies show agentic systems successfully solve a significant portion of problems that fail completely under single-shot retrieval. The autonomous loop allows agents to reformulate queries when initial attempts return insufficient information.5
However, when data fits within expanded context windows, direct long-context processing outperforms even sophisticated agentic retrieval systems. The performance gap exists because the model can reason across the entire document simultaneously, avoiding the fragmentation inherent in chunk-based retrieval.
Different types of Agentic RAG models
Some of the agents that leverage Large Language Models (LLMs) within Retrieval-Augmented Generation (RAG) frameworks include:
- Routing agent: Uses a Large Language Model (LLM) for agentic reasoning to select the most appropriate Retrieval-Augmented Generation (RAG) pipeline (e.g., summarization or question-answering) for a given query. The agent determines the best fit by analyzing the input query.
- One-shot query planning agent: Decomposes complex queries into smaller subqueries, executes them across various RAG pipelines with different data sources, and combines the results into a comprehensive response.
- Tool use agent: Enhances standard RAG frameworks by incorporating external data sources (e.g., APIs, databases) to provide additional context. This allows for more enriched processing of queries using LLMs.
- ReAct agent: Integrates reasoning and action for handling sequential, multi-part queries. It maintains an in-memory state and iteratively invokes tools, processes their outputs, and determines the next steps until the query is fully resolved.
- Dynamic planning & execution agent: Aimed at managing more complex queries, this agent separates high-level planning from execution. It uses an LLM as a planner to design a computational graph of steps needed to answer the query and employs an executor to carry out these steps efficiently. The focus is on reliability, observability, parallelization, and optimization for production environments.
Agentic RAG benefits
Agentic RAG improves LLMs through:
- Autonomous & goal-oriented approach: Unlike traditional RAG, Agentic RAG acts like an autonomous agent, making decisions to achieve defined goals and pursue deeper, more meaningful interactions.
- Improved context awareness & sensitivity: Agentic RAG dynamically considers conversation history, user preferences, prior interactions, and the current context to provide relevant, informed responses and decision-making.
- Dynamic retrieval & advanced reasoning: It uses intelligent retrieval methods tailored to queries, while evaluating and verifying the accuracy and reliability of retrieved data.
- Multi-agent orchestration: It coordinates multiple specialized agents, breaking down queries into manageable tasks and ensuring seamless coordination to deliver accurate results.
- Increased accuracy with post-generation verification: Agentic RAG models perform quality checks on generated content, ensuring the best possible response and combining LLMs with agent-based systems for superior performance.
- Adaptability & learning: These systems continuously learn and improve over time, enhancing problem-solving abilities, accuracy, and efficiency, and adapting to various domains for specific tasks.
- Flexible tool utilization: Agents can leverage external tools like search engines, databases, or APIs to enhance data collection, processing, and customization for diverse applications.
Agentic RAG challenges
- Data quality: Reliable outputs require high-quality, curated data. Challenges arise when integrating and processing diverse datasets, including textual and visual data, to meet user query requirements. Further data retrieval processes must also ensure accuracy and consistency.
- Tip: Implement automated data cleansing tools and AI-driven data validation techniques to ensure consistent and high-quality data integration across textual and visual datasets.
- Scalability: Efficient management of system resources and retrieval processes is critical as the system grows. As user queries and data volumes increase, handling both real-time and batch processing for further data retrieval becomes a significant challenge.
- Tip: Utilize scalable cloud-based infrastructure and distributed computing frameworks to handle increasing data loads efficiently. Incorporate dynamic load balancing for real-time query handling.
- Explainability: Ensuring transparency in decision-making builds trust. Providing clear insights into how responses to user queries are generated, particularly when leveraging textual and visual data, remains a persistent challenge.
- Tip: Leverage AI explainability tools like SHAP or LIME to make model predictions interpretable and integrate visualization dashboards to clarify the reasoning behind responses.
- Privacy and security: Strong data protection and secure communication protocols are essential. Managing sensitive or confidential data requires robust encryption and compliance mechanisms during storage, further data retrieval, and processing.
- Tip: Employ end-to-end encryption and access management solutions, and ensure compliance with data protection regulations such as GDPR or CCPA. Use secure API gateways for further data retrieval.
- Ethical concerns: Addressing bias, fairness, and misuse is crucial for responsible AI deployment. Ensuring unbiased responses to diverse user queries remains a key consideration in ethical AI design.
- Tip: Deploy responsible AI platforms and AI governance tools to cope with AI bias and comply with four guiding principles of AI.
Future prospects
The latest research on agentic RAG includes improvement areas like:
- Knowledge graph integration: Enhances reasoning by leveraging complex data relationships.
- Emerging technologies: Incorporating tools like ontologies and the semantic web to advance system capabilities.
- Specialized agent collaboration: Agents with expertise in different domains (e.g., sales, marketing, finance) work together in a coordinated workflow to address complex tasks.
- Quality optimization: Addressing inconsistent output to improve the reliability and precision of multi-agent systems.
Further reading
Explore other RAG benchmarks, such as:
- Top 10 Multilingual Embedding Models for RAG
- Embedding Models: OpenAI vs Gemini vs Cohere
- Top 16 Open Source Embedding Models for RAG
- Top Vector Database for RAG: Qdrant vs Weaviate vs Pinecone
- Reranker Benchmark: Top 8 Models Compared
- Multimodal Embedding Models: Apple vs Meta vs OpenAI
FAQs
Retrieval-Augmented Generation (RAG) is a technique that combines retrieval-based methods with generative models to enhance information retrieval and response generation.
Explore more on retrieval-augmented generation technique and common models.
An agent is a computer program designed to observe its environment, make decisions, and execute actions autonomously to achieve specific objectives without direct human intervention.
Usage in AI Systems
Agents are used to automate tasks, optimize processes, and make intelligent decisions in dynamic environments. Depending on their complexity, agents can range from simple rule-based systems to advanced models using learning techniques.
Types of Agents
Reactive Agents: Operate based on the current state of the environment and follow predefined rules, without using past experiences.
Cognitive Agents: Store past experiences and use them to analyze patterns and make decisions, enabling learning from previous interactions.
Collaborative Agents: Interact with other agents or systems to achieve shared goals, often within multi-agent systems where coordination and information sharing are key.
Agentic RAG can be better for tasks requiring more dynamic, context-aware decision-making and iterative interactions, but its effectiveness depends on the specific use case and implementation needs.
Vanilla RAG passively retrieves and generates answers based on a static query-response model, while agentic RAG incorporates iterative processes, decision-making, and dynamic interactions to refine responses or handle complex tasks.
Cite this benchmark
Pick the format that matches where you're publishing. Pasting the link version into your CMS preserves the backlink.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Sarı, Ekrem},
title = {{Top 20+ Agentic RAG Frameworks}},
year = {2026},
month = jul,
howpublished = {\url{https://aimultiple.com/agentic-rag}},
note = {AIMultiple. Retrieved July 17, 2026}
}Reference Links
Cem's work has been cited by leading global publications including Business Insider, Forbes, Washington Post, global firms like Deloitte, HPE and NGOs like World Economic Forum and supranational organizations like European Commission. You can see more reputable companies and resources that referenced AIMultiple.
Throughout his career, Cem served as a tech consultant, tech buyer and tech entrepreneur. He advised enterprises on their technology decisions at McKinsey & Company and Altman Solon for more than a decade. He also published a McKinsey report on digitalization.
He led technology strategy and procurement of a telco while reporting to the CEO. He has also led commercial growth of deep tech company Hypatos that reached a 7 digit annual recurring revenue and a 9 digit valuation from 0 within 2 years. Cem's work in Hypatos was covered by leading technology publications like TechCrunch and Business Insider.
Cem regularly speaks at international technology conferences. He graduated from Bogazici University as a computer engineer and holds an MBA from Columbia Business School.





Be the first to comment
Your email address will not be published. All fields are required. Comments are left in their original language.