Top 5 Open-Source Agentic AI Frameworks in 2026
We benchmarked 4 popular open-source agentic frameworks across 2,000 runs (5 tasks, 100 runs each per framework), measuring end-to-end latency, token consumption, and architectural differences.
Agentic AI frameworks benchmark
We examined how the frameworks themselves influence agent behavior and the resulting impact on latency and token consumption.
LangGraph is the fastest framework with the lowest latency values across all tasks, while LangChain has the highest latency and token usage.
Across 5 tasks and 2,000 runs, LangChain emerges as the most token-efficient framework, while AutoGen leads in latency; LangGraph and LangChain follow closely behind. CrewAI draws the heaviest overall profile.
You can see agentic AI frameworks benchmark methodology for more details on the tasks.
Task 1: Basic aggregation
First, we measured the overhead of each framework when calling a single tool and returning the result, without performing any complex reasoning.
LangChain & LangGraph: For simple tasks, they perform nearly as fast as non-agentic code, both finishing under 5 seconds with fewer than 900 prompt tokens. LangGraph’s state-machine architecture introduces no noticeable latency compared to LangChain at this level of simplicity; the overhead of state management materializes as task complexity grows.
AutoGen: Sits slightly above LangChain and LangGraph in both latency and token usage, reflecting the baseline cost of its multi-agent conversation loop, two agents exchanging messages even for a single-step task.
CrewAI: Even when asked to make a single tool call, it exhibits what might be called “managerial overhead,” consuming nearly 3× the tokens of LangChain and taking almost 3× longer. The multi-step verification process between its Planner and Analyst personas offers a thorough but resource-intensive approach that prioritizes completeness over speed. This cost is structural: it appears regardless of task complexity.
Task 2: Comparative revenue analysis (state management)
In Task 2, we wanted to see the frameworks’ ability to hold two different filter groups in memory (State Persistence) and combine them.
CrewAI
In our log analysis, we found that CrewAI provides the highest level of infrastructure transparency among the frameworks, but at the cost of the highest resource consumption.
Instead of immediately returning retrieved data, CrewAI repeatedly validates its own processes through a self-review mechanism. This exploratory behavior caused it to hit the configured max_iter=10 limit, leaving some runs stuck in a continuous thinking loop without producing a JSON output.
The root cause of this behavior is that CrewAI injects multi-layered instructions into the system prompt, assigning each agent a role, goal, and backstory, while enforcing a ReAct-style Thought → Action → Observation loop at every step. Even for simple tasks, the LLM cannot skip this ceremony and dutifully produces verbose internal monologues, which compounds further in multi-agent scenarios.
CrewAI consumed nearly twice the tokens of the other frameworks and took over three times as long as LangChain, making it better suited for complex state transitions and multi-factor decision-making rather than straightforward data retrieval tasks.
LangChain
The fastest and most cost-effective framework. In our logs, we observed that LangChain completes the task in 5-6 steps without any detours: Load → Filter → Calculate → Filter → Calculate → Output. Since its state management is very simple, the overhead is nearly zero and latency is the lowest among all frameworks.
AutoGen
Delivered a very balanced performance.In Task 2, it matched LangGraph nearly exactly in both token use and latency, showing that the conversation loop’s overhead does not compound significantly when the task chain remains linear.
However, it occasionally adds an extra verification step to confirm parameters during the tool-calling process, making it slightly slower than LangChain. When it encounters an error in a tool call or the data doesn’t come back as expected, it immediately updates its reasoning in the next step and arrives at the correct JSON. Because it manages tool outputs as a conversational flow, it is one of the most resilient frameworks against logical errors.
LangGraph
In this task, LangGraph is the most stable framework thanks to its graph-based architecture. In its logs, we observed that state is carried very cleanly throughout the run. The risk of data contamination or segments interfering with each other is at the lowest level in this framework. Across all 100 runs, it produced results in nearly the same number of steps and within the same latency range.
Task 3: Threshold parsing (numerical discipline)
In this task, we wanted to see how accurately the frameworks translate natural language numerical conditions, such as “less than 1 year of tenure” and “more than $70 in monthly charges,” into precise tool parameters like tenure_max=12 and charges_min=70.0.
The LLM knows how to make this conversion; what we really wanted to test was whether the framework can protect these parameters throughout its own retry mechanisms, re-prompt context, and state management cycles.
LangChain & LangGraph
Both frameworks passed the parameters (tenure_max=12, charges_min=70) directly to the tool exactly as the LLM produced them, without any modification or re-prompt loop. This efficiency shows in the numbers: both frameworks completed Task 3 in under 9 seconds with under 1,800 prompt tokens, the lowest in this task.
When we wanted to measure whether numerical thresholds are preserved without the framework interfering, these two met our expectations: whatever parameter was generated, that is what ran.
AutoGen
Autogen is fully successful in numerical correctness. In some runs, it was observed that the framework added a verification step before passing the LLM-generated parameter to the tool, meaning the framework spent an extra step while preserving the parameter. At 2,480 tokens and 8 seconds, it matched LangChain’s latency despite the extra step, confirming that the verification overhead is real but small. It met our expectations in terms of parameter integrity, with the confirmation step introducing a marginal token cost rather than a meaningful latency penalty.
CrewAI
The most notable behavior was observed in CrewAI, which completed Task 3 in 30 seconds with 4,360 tokens, the highest in this task. Two distinct failure patterns emerged from log analysis.
In some runs, a value that should have been 68.81% was returned as 0.6878 (decimal ratio). This indicates that the framework’s output serialization can strip the LLM’s output from its original context.
The logs show that the LLM initially produced the correct parameters, tenure_max=12 and charges_min=70. However, once CrewAI entered a “Failed to parse” loop, the framework pushed the LLM to reconsider. In the re-prompt context, the LLM shifted the threshold to tenure_max=14 and completely disabled the charges_min filter, producing a churn rate of 46.84%, which is actually the churn rate of all customers with tenure less than 14. This was exactly the scenario we wanted to observe: the framework’s retry mechanism can corrupt a parameter that the LLM had gotten right.
Task 4: Error resilience and pivot capacity
In this task, we wanted to see how each framework handles disruptive scenarios and observe the impact on latency and token consumption. The tool throws 3 different types of errors in succession (Network, Timeout, Rate Limit), pushing the agent into a corner. The first two errors instruct the agent to retry, and after retrying both, the incoming Rate Limit error tells the agent to wait 10 seconds. Once the agent waits and retries, the tool begins to function normally.
LangGraph & Autogen
These two frameworks found alternative solutions autonomously when faced with tool failures in this task.
When the tool returned a rate limit warning, instead of pausing and waiting, these agents decided to abandon the failing tool entirely and find an alternative path. Their approach was: “Since this tool isn’t working, I’ll filter each payment method one by one, calculate the churn rate for each separately, and then combine the results myself.”
Method: Instead of accomplishing the task with a single tool call, they broke it down by using two separate tools, one for filtering and one for calculation, processing each PaymentMethod (Electronic check, Mailed check, etc.) individually.
These agents operate with goal-oriented reasoning rather than path dependency. If the shortest path is unavailable, they can construct an alternative execution plan within seconds.
LangGraph reached 15,010 prompt tokens in Task 4, the highest single-task token count across the entire benchmark, because its state machine accumulated the growing history of each manual tool call back into context at every step. AutoGen followed at 10,750 tokens, slightly more contained due to its conversational handling of intermediate results. Despite this, both finished around 24-27 seconds, confirming that the additional token cost did not translate into meaningful latency because the pivot itself was fast.
CrewAI
Despite showing the highest token consumption in previous tasks, CrewAI exhibited the lowest token usage) but the highest latency values in this task.
Why the lowest token?
CrewAI did not go through a 10-15 step manual workaround like its competitors. When it encountered errors, instead of repeatedly pumping the entire history and complex intermediate data back into the LLM at every step, it built a more focused, modular reasoning loop. By avoiding unnecessary verbosity, it became the most cost-effective framework in this task.
Why high latency?
CrewAI’s managerial structure pauses and re-evaluates the plan when it encounters an error. When it received the 10-second wait warning, it spent more time in the “strategy planning” phase. Additionally, rather than pivoting to another tool for filtering, it persistently chose to wait for the main tool to recover or attempt with the stable tool, which extended the overall duration.
LangChain
LangChain went through its most significant transformation in this task, proving why resilience depends on proper configuration.
In our initial run, LangChain crashed on every single attempt with a ConnectionError.
LangChain’s default AgentExecutor treats raw Python exceptions thrown from within a tool as fatal errors and terminates the process. Unlike its competitors, it does not apply a “errors are observations” philosophy by default. Since the agent never sees the error, it has no chance to reason about it.
We wrapped the tool call inside langchain_agent.py with a try-except block. This converted the error into a readable message that the agent could process.
Post-fix behavior: After applying the fix, we observed in LangChain’s logs that it exhibited the exact same reasoning as LangGraph. It received 3 errors from the tool, immediately switched strategy and pivoted to using two separate tools, one for filtering and one for calculation, processed each payment method individually, and combined the results.
LangChain is actually just as capable and adaptive as LangGraph, but because the framework’s error handling was turned off by default, it had no opportunity to demonstrate this capability. Once properly configured, it reached the correct result using the same alternative path approach.
Why did these differences occur? (framework architecture analysis)
If agent behavior depended solely on the LLM (GPT-5.2), all frameworks should have behaved similarly. However, the clear differences in these ratios are rooted in the frameworks’ own inner loop mechanisms:
1. LangGraph & AutoGen (90% Pivot):
LangGraph operates on a State Machine architecture, while AutoGen works on a Conversation-based model. In both systems, errors are processed as a feedback loop. In LangGraph, the state that receives the error passes to the next node; in AutoGen, the Proxy agent forwards the error to the assistant as a chat message. This constant nudging mechanism forces the agent to keep searching for a solution. Because the agent is repeatedly confronted with the question “I got an error, what should I do?”, the probability of it deciding to take an alternative manual path rises to 90%.
2. LangChain (65% Pivot / 35% Wait):
LangChain runs on a sequential AgentExecutor architecture. Even with error handling in place, its execution loop has a more linear structure and is primarily focused on producing a Final Answer. If the tool throws errors for 3-4 steps, LangChain sometimes prefers to wait for the tool to succeed on the next attempt or produce a result from the existing context, rather than pivoting to an alternative strategy. Because LangChain’s state locking is more flexible than LangGraph’s, its wait/direct-solution ratio sits at around 35%.
3. CrewAI (0% Pivot):
CrewAI operates on a Managerial Process architecture. Its agents are wrapped in Role and Task definitions. When errors occur, its internal architecture typically triggers Self-Correction or Retry logic. However, a radical strategy change like “let’s scrap the entire plan and do manual filtering in 5 steps” conflicts with CrewAI’s managerial plan structure. It operates with the discipline of “I should fix the tool I was given or use the closest alternative” rather than abandoning its plan altogether. This is fundamentally a plan-centric approach as opposed to a goal-centric one.
Task 5: Unstructured data orchestration (unstructured data routing)
In task 5, we observed how the frameworks behave when they encounter JSON and long text (LongText) columns within a CSV. The agents needed to first discover the data type of these columns, then select the correct processing tools either sequentially or in parallel.
In the real world, unstructured data management requires an agent to go beyond standard tabular data and work with JSON blobs, free-text paragraphs, or nested objects.
For a framework to handle this type of data correctly, it needs to do two things well:
1- a discovery intelligence that understands which tool fits which data type
2- an orchestration mechanism that coordinates multiple independent tool calls.
We designed Task 5 specifically to measure these two capabilities separately.
AutoGen
AutoGen delivered a strong performance in this task, finishing at 8,170 prompt tokens and a median latency of 47 seconds, the fastest and most token-efficient result in Task 5.
The conversation loop at the core of its architecture, the messaging between AssistantAgent and UserProxyAgent, is typically seen as a structure that leads to verbosity. However, in Task 5, this structure turned into an advantage.
By looking at the conversation history, LLM recognized that the Metadata and SupportNotes columns were independent of each other. It then sent a single TOOL CALLS response listing 4 tools simultaneously: inspect_column(Metadata), inspect_column(SupportNotes), parse_json_column(…), and summarize_text_column(…) all ran in parallel. This allowed it to complete the task in 3 LLM turns, with the fewest tokens and the fewest steps.
The technical reason behind this behavior is clear: AutoGen’s tool execution engine runs the tool_calls list returned by the LLM atomically and collects the results in a single conversation step. The framework’s “manage the conversation” philosophy naturally allows multiple parallel channels to be opened at the same time, and the token and latency numbers confirm this directly.
LangGraph
LangGraph finished at 9,150 prompt tokens and 70 seconds median, close to AutoGen on tokens but slower on time.Its State Machine architecture displayed both its greatest strength and its most notable weakness simultaneously in Task 5.
In every run, the llm node → tools node → llm node loop accumulates all previous tool outputs in state and passes them to the LLM. This structure guarantees that the agent never forgets anything, which is normally a significant advantage.
However, in Task 5 this strength worked against it. LangGraph was finding the correct tools and building the correct segment. But even after the analysis was complete, it detected ambiguities in the accumulating state, interpreting completed steps as still pending, and repeatedly triggered additional tool calls. Even though it had retrieved the necessary data and was about to produce the correct answer, the state machine’s “missing step” signal kicked in and the agent entered unnecessary loops. As a result, the number of tool calls per run ranged between 6 and 16. The state’s power of “never forgetting anything” sometimes made completed steps appear as incomplete, pulling the agent back into redundant cycles and pushing latency 23 seconds above AutoGen despite a comparable token count.
CrewAI
CrewAI’s Task 5 performance produced the highest variance across the entire benchmark. In some runs, it followed a flawless sequence with 5 tool calls, no detours, executing like a script. In these runs, CrewAI’s role and task defined managerial structure worked exactly as intended: when the agent clearly understood its role, it behaved predictably and with discipline.
However, in other runs (e.g., run 16: 35 tool calls), complete chaos ensued. The root cause was the internal monologue (Thought) that CrewAI generates at every step. After correctly building the segment with the right filter, the agent’s inner monologue began questioning whether additional filters should also be applied. After seeing the result, it doubted whether the current segment was valid or the previous one should take precedence. This doubt pushed it to reload the data from scratch. Then it filtered again, entered another verification loop, doubted again, and repeated this spiral 8 times.
In CrewAI, each Thought produces an independent evaluation, and these evaluations occasionally invalidate previously verified steps. The Managerial Process’s “continuous verification” reflex, in some runs, pushed the agent into re-questioning its own correct decisions.
LangChain
LangChain’s AgentExecutor structure is inherently sequential, and Task 5 is where that constraint was most visible. At 10,070 prompt tokens and 86 seconds median, it was the slowest framework in this task despite not having the highest token count.
It makes a single tool call at each step, receives the result, then moves on, which means 4 independent tools required 4 separate LLM turns with 4 separate waiting periods. AutoGen’s 47-second median versus LangChain’s 86 seconds is a direct measurement of the cost of sequential versus parallel execution.
In Task 5, LangChain’s tool count settled at either 9 or 15. These two clusters point to two typical strategies: in some runs, it skipped the inspection step and went directly to parsing and summarizing (9 tools), while in others it inspected each column first before processing (15 tools). LangChain’s linear executor identity became clear here: it exhibited neither AutoGen’s parallel efficiency nor CrewAI’s monologue chaos.
Unstructured data management and framework architecture
The results of this task reveal that how efficiently a framework can manage unstructured data (JSON, LongText) is directly tied to its inner loop mechanism:
Frameworks capable of parallel tool calls (AutoGen) can process independent data columns in a single step. In real-world scenarios involving large JSON objects and numerous text columns, this difference translates into a massive cost and speed advantage.
Frameworks with state-driven loops (LangGraph) excel at data consistency but carry the risk of re-evaluating completed steps accumulated in history.
Monologue-based frameworks (CrewAI) are deeply capable of understanding the type and meaning of data, but this depth sometimes turns into excessive questioning and looping.
Linear execution frameworks (LangChain) process different branches of unstructured data separately, producing a middle-ground result from both worlds.
GitHub star growth of agentic frameworks
Compare agentic AI frameworks
Agentic AI frameworks vary across several key dimensions, and understanding these differences is essential for making meaningful comparisons.
Multi-agent orchestration
Multi-agent orchestration coordinates multiple specialized AI agents to tackle complex workflows that exceed single-agent capabilities. Rather than building one monolithic agent, orchestration divides work among agents with distinct roles, tools, and expertise. Each framework offers different approaches to agent coordination.
LangGraph
LangGraph is a relatively well-known framework and stands out as a key option for developers building agent systems.
Explicit multi-agent coordination: You can model multiple agents as individual nodes or groups, each with its own logic, memory, and role in the system.
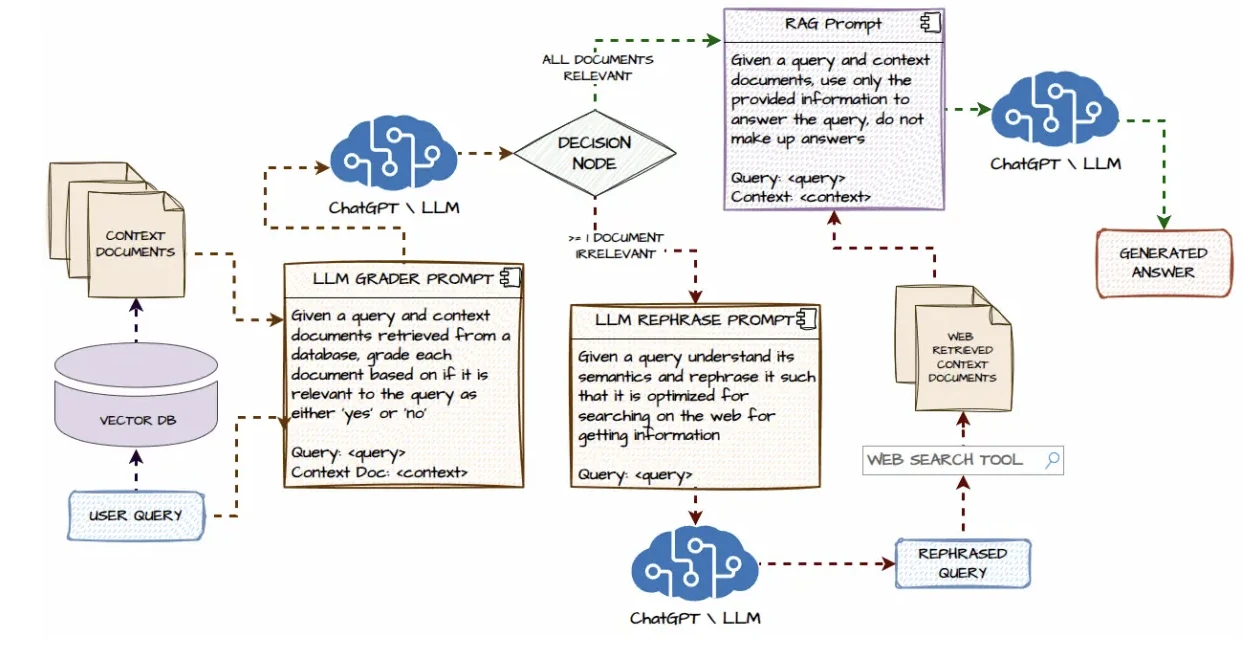
It creates AI workflows across APIs and tools. Thus, it is a good fit for RAG and custom pipelines.
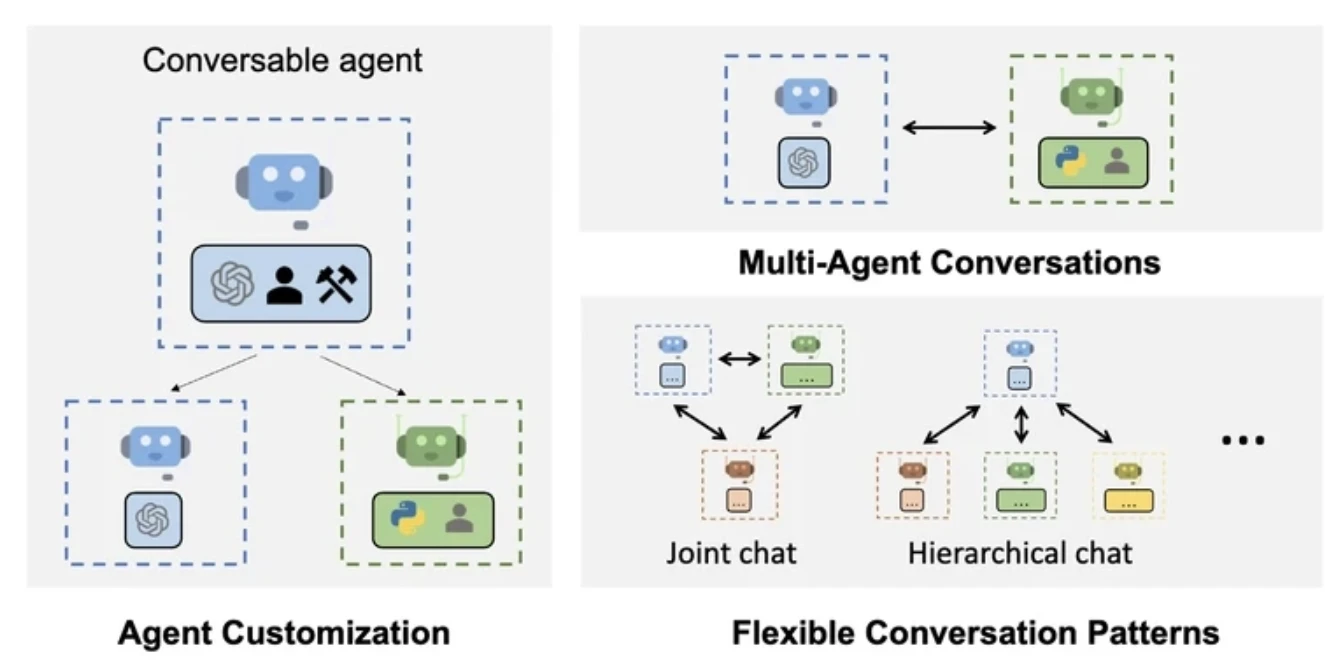
AutoGen
AutoGen allows multiple agents to communicate by passing messages in a loop. Each agent can respond, reflect, or call tools based on its internal logic.
It has an asynchronous agent collaboration, making it particularly useful for research and prototyping scenarios where agent behavior requires experimentation or iterative refinement.
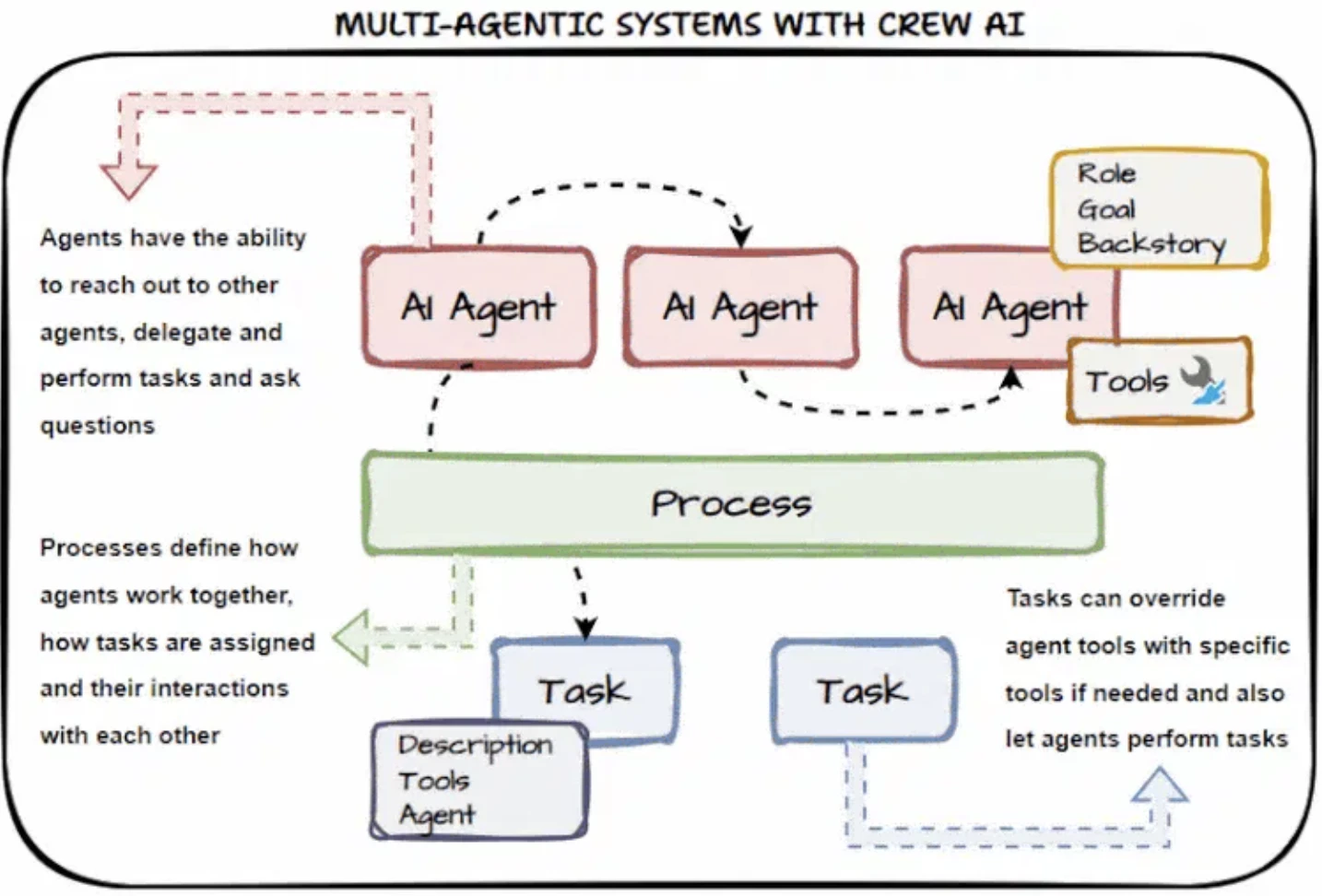
CrewAI
CrewAI handles most of the low-level logic for you and provides multi-agent orchestration:
- Integrates with monitoring tools for tracing and debugging
- Built-in execution control through Flows with conditional logic, loops, and state management
- Supports hierarchical (manager-worker) and structured multi-agent coordination
OpenAI Swarm
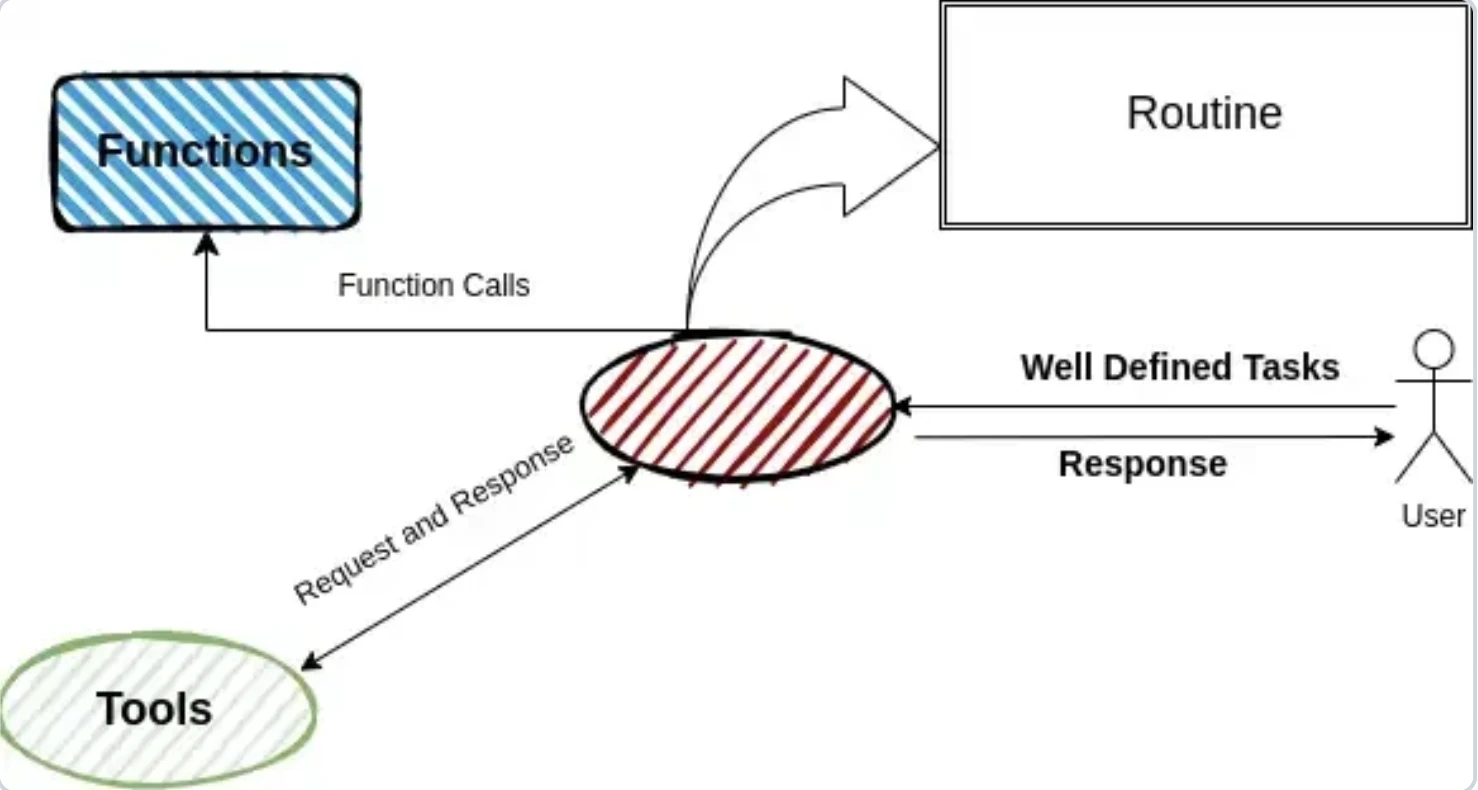
Swarm is a lightweight, experimental multi-agent framework for prototyping. Agents work sequentially through handoffs, transferring tasks while maintaining shared context. It uses natural language routines and Python tools for flexible workflows.
LangChain
LangChain is a framework for building single-agent LLM applications with RAG tooling. It provides modular components including chains, tools, memory, and retrieval for document processing workflows.
LangChain operates primarily through single-agent execution patterns where one agent manages the workflow.
Agent and function definition
LangGraph
LangGraph takes a graph-based approach to agent design, where each agent is represented as a node that maintains its own state. These nodes are connected through a directed graph, enabling conditional logic, multi-team coordination, and hierarchical control. This enables you build and visualize multi-agent graphs with supervisor nodes for scalable orchestration.
LangGraph uses annotated, structured functions that attach tools to agents. You can build out nodes, connect them to various supervisors, and visualize how different teams interact. Think of it like giving each team member a detailed job description. This makes it easier to build and test agents that work together.
AutoGen
AutoGen defines agents as adaptive units capable of flexible routing and asynchronous communication. Agents interact with each other (and optionally with humans) by exchanging messages, allowing for collaborative problem-solving. Like LangGraph uses annotated, structured functions.
CrewAI
CrewAI takes a role-based design approach. Each agent is assigned a role (e.g., Researcher, Developer) and a set of skills, functions or tools it can access. Function definition is through structured annotations.
OpenAI Swarm
OpenAI Swarm uses a routine-based model where agents are defined through prompts and function docstrings. It doesn’t have formal orchestration or state models, relying instead on manually structured workflows. Functions behavior is inferred by the LLM through docstrings (Swarm identifies what a function does by reading its description) making this setup flexible but less precise.
LangChain
LangChain uses a chain-based architecture where a single orchestrator agent manages calls to language models and various tools. It defines functions through explicit interfaces like toolkits and prompt templates.
While primarily focused on centralized workflows, LangChain supports extensions for multi-agent setups but lacks built-in agent-to-agent communication.
Memory
Memory capabilities:
- Stateful: Whether the framework supports persistent memory across executions.
- Contextual: Whether it supports short-term memory via message history or context passing.
Memory features is a key part of building agentic systems to remember context and adapt over time:
- Short-term memory: Keeps track of recent interactions, enabling agents to handle multi-turn conversations or step-by-step workflows.
- Long-term memory: Stores persistent information across sessions, such as user preferences or task history.
- Entity memory: Tracks and updates knowledge about specific objects, people, or concepts mentioned during interactions (e.g., remembering a company name or project ID mentioned earlier).
LangGraph
LangGraph uses two types of memory: in-thread memory, which stores information during a single task or conversation, and cross-thread memory, which saves data across sessions. Developers can use MemorySaver to save the flow of a task and link it to a specific thread_id. For long-term storage, LangGraph supports tools like InMemoryStore or other databases. This provides flexible control over how memory is scoped and retained across executions.
AutoGen
AutoGen uses a contextual memory model. Each agent maintains short-term context through a context_variables object, which stores interaction history. It doesn’t have built-in persistent memory.
CrewAI
CrewAI provides layered memory out of the box. It stores short-term memory in a ChromaDB vector store, recent task results in SQLite, and long-term memory in a separate SQLite table (based on task descriptions). Additionally, it supports entity memory using vector embeddings. This memory setup is automatically configured when memory=True is enabled,
OpenAI Swarm
Swarm is stateless and does not manage memory natively. Developers can pass short-term memory through context_variables manually, and optionally integrate external tools or third-party memory layers (e.g., mem0) to store longer-term context.
LangChain
LangChain supports both short-term and long-term memory through flexible components. Short-term memory is typically managed via in-memory buffers that track conversation history within a session. For long-term memory, LangChain integrates with external vector stores or databases to persist embeddings and retrieval data.
Developers can customize memory scopes and strategies using built-in memory classes, enabling efficient management of contextual and entity-specific memory across interactions.
Human-in-the-loop
LangGraph
LangGraph supports custom breakpoints (interrupt_before) to pause the graph and wait for user input mid-execution.
AutoGen
AutoGen natively supports human agents via UserProxyAgent, allowing humans to review, approve, or modify steps during agent collaboration.
CrewAI:
CrewAI enables feedback after each task by setting human_input=True; the agent pauses to collect natural language input from the user.
OpenAI Swarm
OpenAI Swarm offers no built-in HITL.
LangChain
LangChain allows inserting custom breakpoints within chains or agents to pause execution and request human input. This supports review, feedback, or manual intervention at defined points in the workflow.
Model Context Protocol (MCP) integration in agentic AI frameworks
AI agents need to interact with external tools like databases, APIs, file systems, and business applications. Without a standard, each framework had to build custom integrations for every tool, creating a fragmented ecosystem. MCP solves this by providing a universal protocol that lets any agent connect to any tool through a single interface.
How each framework integrates with MCP
LangGraph
LangGraph connects to MCP servers through an adapter that automatically discovers available tools and converts them into LangChain-compatible format. Agents can then use these tools seamlessly alongside their native capabilities.
AutoGen
AutoGen provides built-in MCP integration through its extension module. Developers can connect to MCP servers and make all their tools available to AutoGen agents with just a few lines of code.
CrewAI
CrewAI agents can directly reference MCP servers in their configuration using simple URLs or structured settings. The framework handles connection lifecycle and error management automatically.
OpenAI Swarm
Swarm benefits from OpenAI’s native MCP support across its ecosystem. Since OpenAI integrated MCP into ChatGPT and its Agents SDK, Swarm can leverage this infrastructure directly.
LangChain
LangChain offers MCP tool-calling capabilities where Python functions act as bridges to MCP servers. This enables pulling tools from various sources and integrating them into chains, agents, and other LangChain components without custom wrappers.
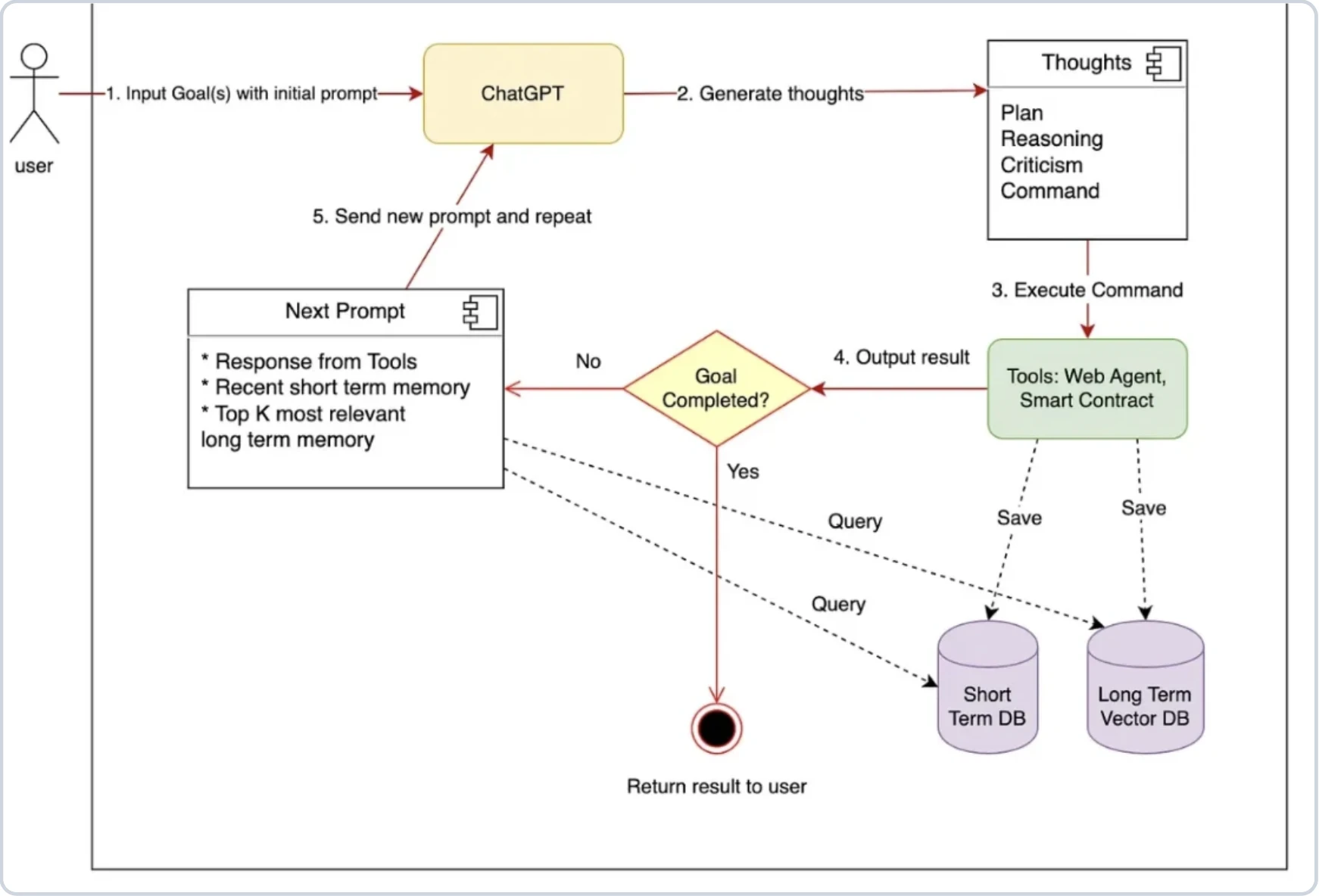
What agentic AI frameworks actually do?
Agentic AI frameworks assist with prompt engineering and managing how data flows to and from LLMs. At a basic level, they help structure prompts so the LLM responds in a predictable format and route responses to the right tool, API, or document.
If building from scratch, you would manually define the prompt, extract the tool the LLM wants to use, and trigger the corresponding API call. Frameworks streamline this by:
- Prompt orchestration: Building, managing, and routing complex prompts to LLMs
- Tool integration: Letting agents call external APIs, databases, code functions, etc.
- Memory: Maintaining state across turns or sessions (short- and long-term)
- RAG integration: Enabling knowledge retrieval from external sources
- Multi-agent coordination: Structuring how agents collaborate or delegate tasks
Agentic AI frameworks: Real life use cases
LangGraph – Multi-agent travel planner
A production project built with LangGraph demonstrates a stateful, multi-agent travel assistant that pulls flight and hotel data (using Google Flights & Hotels APIs) and generates travel recommendations.4
CrewAI – Agentic content creator
CrewAI’s official examples repository includes flows like trip planning, marketing strategy, stock analysis, and recruitment assistants, where role-specific agents (e.g., “Researcher”, “Writer”) collaborate on tasks.5
CrewAI turns a high-level content brief into a complete article using Groq.
Core features of agentic AI frameworks
Model support:
- Most are model-agnostic, supporting multiple LLM providers (e.g., OpenAI, Anthropic, open-source models).
- However, system prompt structures vary by framework and may perform better with some models than others.
- Access to and customization of system prompts is often essential for optimal results.
Tooling:
- All frameworks support tool use, a core part of enabling agent actions.
- Offer simple abstractions to define custom tools.
- Most support Model-Context-Protocol (MCP), either natively or through community extensions.
Memory / State:
- Use state tracking to maintain short-term memory across steps or LLM calls.
- Some helps agents retain prior interactions or context within a session.
RAG (Retrieval-Augmented Generation):
- Most include easy setup options for RAG, integrating vector databases or document stores.
- This allows agents to reference external knowledge during execution.
Other common features
- Support for asynchronous execution, enabling concurrent agent or tool calls.
- Built-in handling for structured outputs (e.g., JSON).
- Support for streaming outputs where the model generates results incrementally.
- Basic observability features for monitoring and debugging agent runs.
Benchmark methodology
1. Task Structure
Task 1: Measures whether a single tool call can be made with the correct parameter. The framework’s base infrastructure overhead is most clearly revealed in this simple scenario.
Task 2: Requires holding the results of two separate filter groups in memory and combining them into a single output. State management and multi-segment coordination are tested.
Task 3: Measures whether numerical conditions in natural language are translated into tool parameters without distortion. The real test is whether the framework’s retry and re-prompt mechanisms can preserve these parameters.
Task 4: A tool throws Network, Timeout, and RateLimit errors in succession. Whether the framework changes strategy in the face of these errors is measured.
Task 5: The agent must first discover JSON and LongText columns, then call the correct tools with the correct scope parameters. Whether the framework executes independent tools in parallel or sequentially is observed.
What a task actually looks like
To make the setup concrete, here is Task 5, the most complex task in agentic AI frameworks benchmark. Every framework received the identical prompt and the identical set of tools; only the framework wrapping the LLM changed.
Prompt given to the agent:
Analyze churned customers (Churn=’Yes’) who pay more than 100 in MonthlyCharges.
- Filter the dataset to Churn=’Yes’.
- Inspect the ‘Metadata’ and ‘SupportNotes’ columns to discover their data types.
- Extract the ‘device_type’ distribution from the JSON ‘Metadata’ column.
- Count complaint keywords from the free-text ‘SupportNotes’ column.
Return the result as JSON only.
Required JSON output:
Why this task discriminates between frameworks: the agent has to plan a chain of four tool calls, keep the filtered segment in state across every call, and recognize that one column is JSON while the other is free text. A framework that runs the independent columns in parallel (AutoGen) finishes far faster than one that runs them sequentially (LangChain), and a framework that re-evaluates completed steps (LangGraph, CrewAI) loops unnecessarily. The strict JSON schema lets us score correctness automatically.
2. Configuration
All frameworks used the same LLM model (openai/gpt-5.2) and the same temperature value (0.1). For all tasks, each agent was given the same tools and the same prompts. Each framework was set up in its native structure: LangChain with AgentExecutor, LangGraph with StateGraph, AutoGen with AssistantAgent + UserProxyAgent, and CrewAI with Agent + Task + Crew.
The IBM Telco Customer Churn dataset (7,032 customers) was used. Tool state was reset before each run. 100 independent runs were executed for each framework and task combination.
Max iteration limits were set according to task complexity: 10 for Tasks 1, 2, and 3; 20 for Task 4 due to the flaky tool loop; and 20 for Task 5 due to the 4-step discovery chain.
Cite this benchmark
Pick the format that matches where you're publishing. Pasting the link version into your CMS preserves the backlink.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Şipi, Nazlı},
title = {{Top 5 Open-Source Agentic AI Frameworks in 2026}},
year = {2026},
month = jul,
howpublished = {\url{https://aimultiple.com/agentic-frameworks}},
note = {AIMultiple. Retrieved July 6, 2026}
}Reference Links
Cem's work has been cited by leading global publications including Business Insider, Forbes, Washington Post, global firms like Deloitte, HPE and NGOs like World Economic Forum and supranational organizations like European Commission. You can see more reputable companies and resources that referenced AIMultiple.
Throughout his career, Cem served as a tech consultant, tech buyer and tech entrepreneur. He advised enterprises on their technology decisions at McKinsey & Company and Altman Solon for more than a decade. He also published a McKinsey report on digitalization.
He led technology strategy and procurement of a telco while reporting to the CEO. He has also led commercial growth of deep tech company Hypatos that reached a 7 digit annual recurring revenue and a 9 digit valuation from 0 within 2 years. Cem's work in Hypatos was covered by leading technology publications like TechCrunch and Business Insider.
Cem regularly speaks at international technology conferences. He graduated from Bogazici University as a computer engineer and holds an MBA from Columbia Business School.

Comments 1
Share Your Thoughts
Your email address will not be published. All fields are required. Comments are left in their original language.
Thank you for this informative and detailed article! It helped me get a reading on these frameworks.