Best 50+ Open Source AI Agents Listed
Everyone has been building AI agents so after hands-on testing with popular AI coding agents, AI agent builders and tools use benchmarks to evaluate their real-world capabilities, we put together a curated list of the best 50+ open source AI agents. Click the category headers to jump straight to our top picks:
Agent development & infrastructure
Domain-specific agent applications
- Web automation and navigation agents
- Coding and development tools
- Cybersecurity tools
- AI video content creators
- Finance assistants
- Healthcare assistants
- Research agents
- Data analysis assistants
- Personal assistants
How to think about AI agents?
An AI agent is a composable system that combines planning, memory, tool use, and iterative execution. It forms a structured loop around an LLM that can make decisions, perform actions, and adapt to new information.
Here is how to think about them:
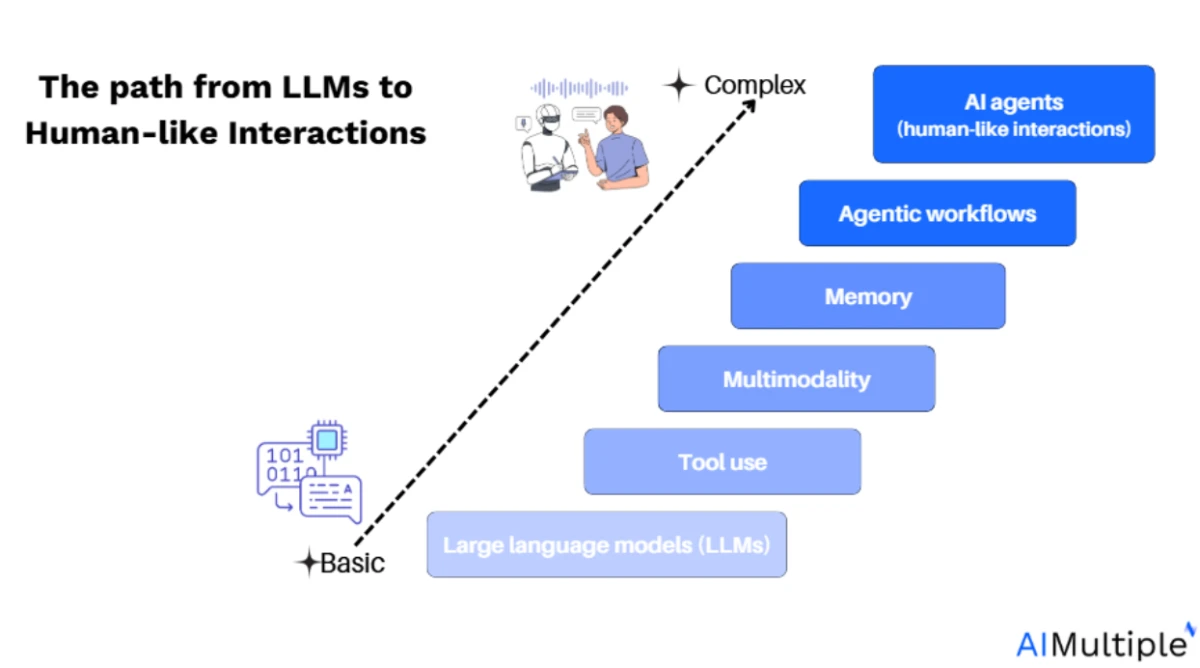
- Autonomy and workflows: AI agents range from basic task automation based on predefined workflows to fully autonomous systems capable of goal decomposition, memory usage, and tool interaction. The core technical challenge lies in maintaining context across steps and coordinating multi-stage operations.
- Context and control: The real challenge in AI agents is ensuring the LLM has the appropriate context at each step. This includes managing the content fed into the LLM and ensuring that the agent executes relevant tasks based on up-to-date context.
- Integration of tools: Building effective agents requires seamless integration with external tools, APIs, and data sources. Frameworks like LangChain can help integrate these external resources, but control over the workflow is essential for adapting the agent’s behavior to new inputs.
- Agent framework benefits: All agentic systems, whether simple workflows or complex autonomous agents, can benefit from core features provided by agentic frameworks. These features can be built from scratch or leveraged from an existing open-source platform, depending on your needs.
New standards
- Model Context Protocol (MCP): The industry standard for how agents talk to external data sources. LangGraph integrates MCP to allow agents to “plug and play” with databases and local tools without custom wrappers.
- Stripe Agentic Commerce Protocol (ACP): This is the first live industry standard that allows AI agents to handle payments, inventory, and shipping securely. It enables “Agentic Checkout,” where the agent can complete a purchase for the user within a chat interface.
What exactly is an AI agent?
There is no agreed-upon definition of what constitutes an “AI agent”.
- Traditional AI defines agents as systems that interact with their surroundings.
- Simon Willison’s survey of practitioners presents a variety of working definitions from industry participants.2
- Anthropic’s definition outlines design principles for building effective and aligned AI agents.3
- Major consulting firms emphasizes the role of agents in automating business workflows and decision-making.4 .
Many of those explicitly include workflows and place autonomy at the end of a spectrum.
We agree with these viewpoints, hence, we do not provide a strict definition. Instead, we list the factors that cause an AI system to be considered more agentic:
- Environment and objectives:
- AI systems in complex environments, such as those with multiple tasks and unexpected changes, are agentic.
- AI systems that follow goals without being instructed are agentic.
- User interface and supervision: AI systems that can learn natural languages and systems that need less user supervision are agentic.
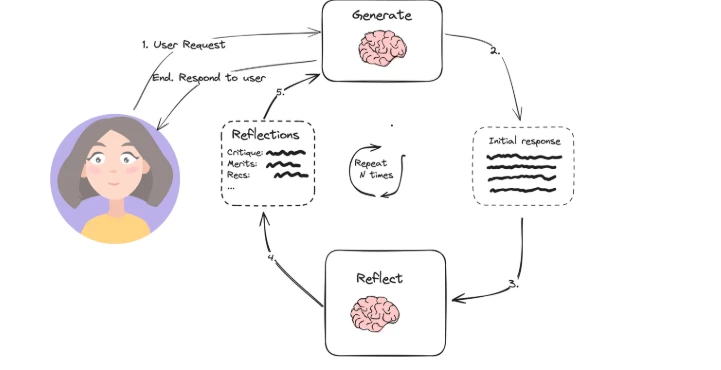
- System design: Systems that use design patterns such as tool usage (e.g., web search, programming) or planning (e.g., reflection, subgoal breakdown) are agentic.
For a more detailed explanation, we previously listed these factors and discussed how they define agentic AI systems.
Are these agents fully autonomous?
Not yet. Most open-source AI agents enhance LLM autonomy by enabling tool use, decision-making, and problem-solving, but they still require structured inputs and a human in the loop.
Examples like Devon and PR-Agent follow predefined logic or RL workflows rather than demonstrating full agentic behavior. Other AI agents still lack (Autonomous Learning + Generalization) capabilities.
When (and when not) to use AI agents
Not every LLM application requires agentic complexity. Many use cases are better served by lightweight retrieval-augmented generation (RAG).
Agentic systems introduce architectural overhead: memory management, tool orchestration, error handling, and control loops which increase latency and cost. For example, in our benchmarks, we observed that the success rates of AI agents decreased after 35 minutes of human interaction.
To mitigate these risks, it’s essential to test agentic systems in controlled environments and implement robust guardrails before deployment.
Agents are most valuable when the steps cannot be easily predicted or hardcoded. They are particularly suited for situations where:
- Tasks are dynamic and multi-step, with branching logic or unclear subgoals.
- Tool usage is conditional or adaptive, requiring the system to choose which tool to invoke based on input or prior state.
- Long-term memory or context is required, across sessions or stages of execution.
- Execution must respond to environmental feedback, such as API results, search outputs, or failed actions.
- Human-in-the-loop collaboration is needed, where autonomy and oversight must be blended (e.g., AI copilots).
On the other hand, workflows or stateless LLM calls are preferable when:
- Task logic is static or predictable, such as form filling or content transformation.
- Low latency is critical, such as in user-facing interactions.
- Minimizing cost is essential, especially by avoiding recursive LLM calls and complex orchestration.
Read more
Here are our latest benchmarks on infrastructure commonly used by agentic systems:
- Remote browsers: How browser infrastructure enables agents to interact with the web securely.
- Browser MCP benchmark: Top MCP servers for tool use and web access.
Open source AI agent examples
Some tools described as “AI agents” aren’t actually all that agentic; these systems (e.g., Devon PR-agent) are largely RL-based AI workflows, with LLMs organized through predefined code paths.
1. Agent frameworks (Build-Your-Own)
Modular libraries and SDKs for developers to build agents with control over logic, memory, tools, and orchestration.
✳️ Some agents like SmolAgents and Agno fit into both agent frameworks and workflow automation categories.
General agent frameworks
Frameworks that focus on building agents, offering flexible, customizable tools for orchestrating workflows, multi-agent setups, and general-purpose use cases.
- LangGraph – Graph-based LLM workflow orchestration – LangGraph is proprietary software, but it provides an open-source library for agent development. Best for RAG pipelines, agent memory/ state handling, and multi-agent setups.
- AutoGen – Multi-agent async collaboration – Designed for coordinating tool-using agents through chat-like APIs. Best for automating complex workflows, particularly in autonomous code generation.
- CrewAI – No-code/low-code multi-agent framework – One of the easiest tools to start with, offering ready-made agent templates (e.g., meeting preparation agent).
Specialized agent frameworks
Frameworks with a specialized focus on specific types of agent behaviors or agent integrations.
- Camel – Role-based agent simulation – Optimized for collaborative, role-playing agents using structured reasoning. Best for workflow automation and synthetic data generation.
- Mastra – Frontend-integrated agent development – JavaScript-based, best for embedding agents in user-facing applications.
- PydanticAI – Type-safe minimal agent control – Provides tight validation and transparent logic paths with Pydantic.
- Cybersecurity AI (CAI) – AI-driven cybersecurity agent framework – Provides penetration testing, vulnerability discovery, and red teaming with human-in-the-loop capabilities, leveraging large language models and integrations with tools like Nmap.
- Atomic Agents – Schema-first granular custom agent builder – Built for granular agent structure and composable logic.
- SmolAgents – Lightweight agent SDK for developers – Minimal abstraction, routes logic via Python instead of JSON.
Agent runtimes (Pre-built autonomous agents)
Pre-built, self-contained agents you can run immediately (like an app). Typically support autonomous execution of tasks from natural language goals.
Fully autonomous:
- Auto-GPT – Goal decomposition and autonomous execution – Breaks down goals into subtasks and completes them using tools, memory, and reasoning. Offers pre-built agents and a low-code interface.
- AIlice – Local general-purpose task execution – Executes complex tasks on-device, supports local tools and file manipulation. Aims to create an AI assistant, similar to JARVIS, based on the open-source LLM.
- Manus AI – General-purpose sandboxed operations. Runs tools and workflows in a safe sandbox, capable of handling multi-domain, multi-step operations autonomously. It is acquired by Meta, integrating to Meta’s “Personal Ambient Intelligence” ecosystem.5
Partially autonomous:
- BabyAGI – Iterative task loop executor – Creates, prioritizes, and runs task lists in a feedback loop. Best for task generation experiments.
Browser/Interface-based:
- AgentGPT – Browser-deployed autonomous agent – Enables users create and execute task agents through a web UI. Lightweight, best for experimentation.
- OpenManus – Persistent browser agent – Designed for session-spanning workflows in browser environments. Uses tools like Playwright to automate web interactions. Good for using across existing automation pipelines. Setup is quick with Conda.
2. Workflow automation and orchestration
Tools that automate workflows and integrate multiple platforms or services, often with the capability to integrate AI agents.
General workflow automation and integration agents
Platforms that connect APIs, trigger events, and automate tasks, making it easy to build and integrate workflows across different systems.
- n8n – Visual workflow automation and API integration – Connects apps, triggers, and data flows using a node editor. It combines visual no-code building with custom JavaScript/Python and supports 400+ integrations. You can self-host, run AI agent workflows with LangChain. Best for technical people.
- PlanExe – LLM-to-Gantt/WBS planning tool – AI planner similar to OpenAI’s deep research. Converts natural language goals into structured timelines using LlamaIndex.
- Agno ✳️ – Developer-friendly workflow and agent builder – It fits both as a workflow automation tool (helping automate tasks and workflows) and an agent builder.
- SmolAgents ✳️ – Lightweight agent SDK for developers – SmolAgents is flexible enough to fit both as a lightweight agent SDK (for agent frameworks) and a workflow tool (as it integrates with Hugging Face models).
- Windmill – Open-source developer platform and workflow engine – Converts scripts into UIs, APIs, and cron jobs; supports Python, TypeScript, Go, and other languages.
- Activepieces – Open-source automation platform – Self-hosted visual workflow builder for automating tasks and integrating apps with minimal coding. It supports 280+ MCP servers to run distributed AI tasks and agent chains at scale.
- Huginn – Web automation and agent management – Builds agents for automating web-based tasks and monitoring.
- Node-RED – Flow-based development for IoT and real-time data – Integrates services and automates tasks with a browser-based flow editor.
Multi-agent workflow orchestration
Frameworks designed to coordinate interacting agents across structured workflows and integrate multi-agent systems.
- HyperAgent – Full software lifecycle agent orchestration – Agents work together to plan, code, and verify engineering tasks.
- Supercog – agentic – Modular orchestration with reusable logic blocks – Designed for scalable, structured, team-based automation.
3. Web automation and navigation
Agents autonomously navigate websites and perform multi-step tasks, such as form filling, data extraction, and web browsing automation.
Autonomous web agents and copilots
General-purpose autonomous agents (web-capable):
- AgenticSeek – Fully autonomous web browsing agent – Fully Local Manus AI. Specializes in data extraction and form filling, automating web-based tasks.
- Agent-E – DOM-aware browser automation agent – Focuses on interacting with web pages by parsing the (Document Object Model) DOM, best for clicking buttons and filling forms.
- AutoWebGLM – LLM-based web agent – Uses reinforcement learning and HTML simplification for better navigation across complex websites.
Vision-based web navigation agents (multimodal):
- Autogen extension WebSurfer – Multimodal web agent – Combines text and visual input (screenshots) to enhance web interaction.
- Skyvern – AI agent with computer vision – Automates workflows using LLMs and computer vision, handling both text and visual elements.
- WebVoyager – Vision-enabled web agent – Uses text and screenshots to improve navigation on image-heavy websites.
For more on open-source web automation and navigation, here is a structured look at some of the top tools and agents:
Web automation & scraping toolkits
LLM-powered web RPA and browser extensions
4. Coding and development agents
AI agents designed to assist with coding tasks, providing real-time support for developers through code suggestions, debugging, and task automation.
CLI-based coding agents
- Codex CLI – Multi-mode interaction tool (suggest, edit, run) – Enhances developer workflows via the command line by offering code suggestions and edits.
- OpenDevin – Open-source AI coding assistant – Assists with programming tasks, offering code suggestions for various languages. Note OpenDevin is recently rebranded to OpenHands to reflect its broader mission of “All Hands AI.”6
- Aider – AI pair programming assistant – Integrated into your terminal for coding assistance, supporting autocompletion, debugging, and task automation.
AI code editors
- Neovim – AI-integrated code editor – AI-powered plugins providing code completions, refactoring.
- Visual Studio Code (VS Code) – AI-powered code completion and debugging tool – Offers code suggestions and autocompletion via GitHub Copilot, integrated with IDE environments for developers.
- Cursor – AI-integrated code editor – Built with real-time AI-powered code completion.
Prompt-to-app builders (Vibe coding)
Open source v0 / lovable / Bolt alternatives:
- Dyad – Open-source AI app builder – Local-first, no-code tool for building AI-driven applications with natural language commands.
- vx.dev – Open-source AI app builder – A local-first, low-code tool focused on transforming natural language prompts into apps.
5. Cybersecurity agents
AI agents designed to enhance cybersecurity operations, including tasks like penetration testing, vulnerability discovery, red teaming, and autonomous threat detection.
- YAWNING TITAN – Abstract, graph-based cybersecurity simulation – Supports training of agents for autonomous cyber operations with a focus on graph-based environments.
- bumpgen – Package management agent – Upgrades npm packages (Node.js package manager) automatically.
- Cyber-Security LLM Agents – LLM-driven cybersecurity tasks – Built on top of AutoGen. Used in various research applications to demonstrate ChatGPT EDR automation and automated CI/CD for detection engineering.
6. AI video content creation agents
AI agents that assist in generating, editing, and enhancing visual and multimedia content, including art, images, and videos.
- Mochi – Text-to-video generation – Converts text prompts into video, with a focus on creating short-form videos. Well-suited for quickly generating videos from textual descriptions.
- CogVideo – Text-to-video generation – Converts text prompts into video with high fidelity, enabling image-to-video creation. A more advanced tool for high-quality video generation from text or images.
- Allegro – Text-to-video generation – Converts text prompts into video with a focus on creative content creation. This tool emphasizes creative video synthesis from text to produce unique visual narratives.
- DALL·E (Open-source versions) – Text-to-video generation – Generates images from text descriptions, turning written prompts into detailed and creative visual content.
7. Finance agents
AI agents that deliver automated reinforcement learning enhancement or real-time financial data analysis.
- FinRL – Automated reinforcement learning for trading – Autonomously learns and executes trading strategies based on market data, adapting to dynamic financial environments.
- OpenBB Terminal – Financial data analysis – Provides autonomous financial insights for real-time trading, enabling investment professionals to make informed trading decisions.
8. Healthcare agents
AI agents that assist in medical diagnostics, disease monitoring, and health insights by analyzing patient data and medical reports.
- HIA (Health Insights Agent) – Medical report analysis – Analyzes medical reports and provides health insights.
- AI-HealthCare-Assistant – Disease diagnosis and monitoring – Diagnoses and monitors diseases using patient data.
9. Research agents
AI agents that assist in data gathering, literature reviews, and hypothesis testing, streamlining the research process.
- ChemCrow – Autonomous chemistry research agent – Integrates LLMs with chemistry tools to plan and execute complex experimental and computational tasks in chemical analysis.
- GPT Researcher – Autonomous general research assistant – Performs structured online searches, analyzes content, and compiles detailed research reports with minimal user input.
10. Data analysis agents
AI agents that process, analyze, and interpret data to provide actionable insights and support decision-making.
Finance
- FinRobot – Financial data analysis agent – Automates financial data interpretation and reporting using large language models.
Business intelligence and querying agents
- Wren AI – Text-to-SQL business insights agent – Converts natural language questions into SQL queries for business reporting.
- Entaoai – GenAI-assisted data engineering tool – Provides a chat interface for data querying and transformation tasks.
- Vanna AI – Natural language to SQL agent – Generates SQL queries based on user prompts to explore structured datasets.
Social media agents
- Twitter Personality Agent – Social media analysis agent – Analyzes tweet history to infer behavioral and personality traits.
11. Personal assistance agents
AI agents that help with task management, scheduling, and personal organization, enhancing productivity and time management.
- VacAIgent (pre-build CrewAI agent) – Travel planning assistant –Autonomously generates full trip itineraries using Streamlit and LLMs.
- Inbox Zero – Email assistant – prioritizes, classifies, and summarizes messages using natural language processing and Gmail integration.
- Cal – Calendar scheduling agent – Automates meeting creation, rescheduling, and summarization via LLM-based interaction.
Building AI agent systems
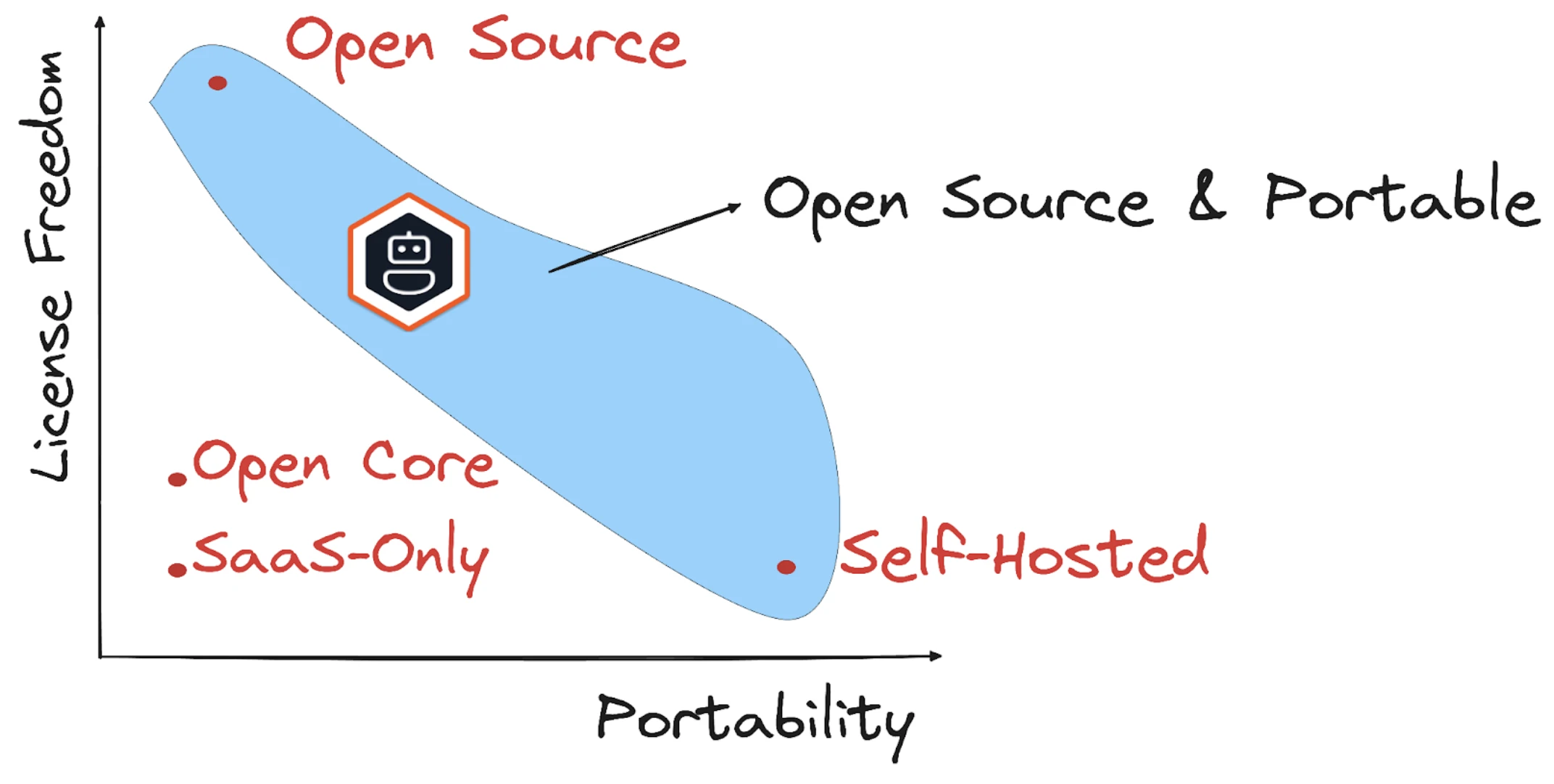
Many AI frameworks are controlled by a single vendor or public repos, but tightly governed.
These projects often shift toward open core models: the base code remains free, but multi-agent orchestration, observability, or fine-grained control can be gated behind commercial licenses. Some “open” ecosystems, production use often requires buying into a locked backend.
Source7
Real-world AI agent projects
From our experience, here are some AI agents and their applications:
- AI Code editors for API development building App
- Screenshot to code execution for AI website generation
- Computer use agents to order deliveries, make a restaurant reservation or design a room.
Other standalone AI agent projects:
Other framework-wise AI agent projects:
Further reading
Cite this research
Pick the format that matches where you're publishing. Pasting the link version into your CMS preserves the backlink.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{Best 50+ Open Source AI Agents Listed}},
year = {2026},
month = may,
howpublished = {\url{https://aimultiple.com/open-source-ai-agents}},
note = {AIMultiple. Retrieved May 14, 2026}
}Reference Links
Cem's work has been cited by leading global publications including Business Insider, Forbes, Washington Post, global firms like Deloitte, HPE and NGOs like World Economic Forum and supranational organizations like European Commission. You can see more reputable companies and resources that referenced AIMultiple.
Throughout his career, Cem served as a tech consultant, tech buyer and tech entrepreneur. He advised enterprises on their technology decisions at McKinsey & Company and Altman Solon for more than a decade. He also published a McKinsey report on digitalization.
He led technology strategy and procurement of a telco while reporting to the CEO. He has also led commercial growth of deep tech company Hypatos that reached a 7 digit annual recurring revenue and a 9 digit valuation from 0 within 2 years. Cem's work in Hypatos was covered by leading technology publications like TechCrunch and Business Insider.
Cem regularly speaks at international technology conferences. He graduated from Bogazici University as a computer engineer and holds an MBA from Columbia Business School.

Be the first to comment
Your email address will not be published. All fields are required. Comments are left in their original language.