See the future of large language models by delving into promising approaches, such as self-training, fact-checking, and sparse expertise that could address LLM limitations.
Success rate comparison of LLM’s
Claude Sonnet 4.6 led the benchmark with an overall score of 0.748, with base and thinking variants tied to three decimal places. Claude Opus 4.8 (0.702), Opus 4.6 base (0.706), and Opus 4.6 thinking (0.729) followed, giving Anthropic the top five positions. The first non-Anthropic model was Gemini 3.5 Flash, thinking at 0.625. GPT variants clustered between 0.57 and 0.60, with stronger backend scores offset by frontend instability. See more in our benchmark article.
LLM Benchmark Methodology
We benchmarked leading large language models across 10 software development tasks using an agentic CLI harness. Each model ran 3 times per task (30 samples per model, 270 validation cells per iteration) to stabilize scores and measure per-cell variance. All models were accessed via OpenRouter under identical conditions, same harness, same task instructions, same hardware environment.
Models tested
The benchmark covers models available via API as of June 2026. All variants listed below were tested independently:
- Claude Sonnet 4.6 (base and thinking)
- Claude Opus 4.8
- Claude Opus 4.6 (base and thinking)
- Claude Opus 4.7
- Gemini 3.5 Flash (base and thinking)
- GPT 5.5 (thinking)
- GPT 5.4 Mini
- GPT 5.3 Codex
- MiniMax M3
- Grok 4.3
- Qwen 3.6 Plus (base and thinking)
- GLM 5.1 (base and thinking)
- Deepseek V4 Pro (base and thinking)
Test environment
Every agent and task begins in a clean environment. Task instructions are provided as a TASK.md file. A 20-minute heartbeat watchdog monitors each run. We record exit codes, execution time, backend and frontend file creation, and real-time token usage across input, output, and cached categories.
Tasks range from reservation systems to interactive dashboards. All require multi-file project management and a functional full-stack deliverable.
Scoring
Backend validation: Generated projects are deployed in isolated environments and tested against a canonical YAML contract covering happy-path scenarios, error handling (400/403/409), and data consistency. Two modes are used:
- Adaptive mode validates functionality even when route names differ from the spec
- Strict mode requires exact contract adherence (routes, status codes, response fields)
Backend score per cell: backend_overall = has_backend × (0.7 × adaptive_pass_rate + 0.3 × strict_pass_rate)
UI validation: Browser automation simulates real user flows including preflights, rendering, login submission, and post-login behavior. Eight steps split into two groups:
- Infrastructure steps (backend preflight, frontend render, login form visible, login submit, login 2xx, no runtime crash)
- Behavior steps (post-login auth signal, post-login behavior signal)
UI score per cell: ui_score = (behavior_passed / (behavior_passed + behavior_failed)) × (infra_passed / infra_total)
Blocked behavior steps are excluded from the behavior denominator so a cell is not double-penalized when the app fails to load.
Final score: Final Score = (0.7 × backend_overall) + (0.3 × ui_score)
Backend is weighted higher because logic failures at the API level typically invalidate any frontend success.
Cost measurement
Cost per cell is calculated from token usage extracted from the LLM API response. Cached input tokens are subtracted from total input tokens to get effective input (newly processed tokens only). Output tokens are never cached and remain unchanged. Per-token rates are sourced from LLM Pricing at the time of testing.
Limitations
- Task scope: All 10 tasks are full-stack web application builds. The benchmark does not cover pure reasoning tasks, scientific problem-solving, summarization, or domain-specific workloads (legal, medical, financial). Scores reflect agentic coding capability specifically.
- API access only: All models were tested via API. Local or on-premise deployments of the same models may produce different results depending on quantization, hardware, and inference configuration.
- Snapshot in time: Model versions change. Results reflect the API version active at test time. A model update can move scores in either direction without notice from the provider.
- Tool call style: Models differ in how they structure file writes and edits (e.g., OpenAI’s
apply_patchbundles a full-file diff into a single call; Anthropic models write and re-edit across multiple calls). Tool-call count is not a direct proxy for quality. - Single harness: All tests used Opencode as the agent harness. A different harness may produce different relative rankings, particularly for models whose default behavior is tuned for specific tool-use patterns.
Future trends of large language models
1- Real-Time Fact-Checking With Live Data
LLMs access external sources during conversations instead of relying only on training data. The model queries external databases, retrieves current information, and provides citations.
Limitation: Still makes errors. Citations don’t guarantee accuracy; models sometimes cite sources incorrectly or misinterpret cited content.
Microsoft Copilot: Integrates GPT-5.4 Thinking with live internet data, introducing “Quick Response” and “Think Deeper” modes for tailored reasoning across different task types.1 The Researcher agent combines GPT for initial research with Anthropic’s Claude reviewing outputs for accuracy and citation quality before delivery a 13.8% improvement on the DRACO deep-research benchmark over standalone systems.2
- ChatGPT: Searches the web when asked about recent events. Cites sources in responses.
- Perplexity: Built specifically for cited search. Every answer includes source links.
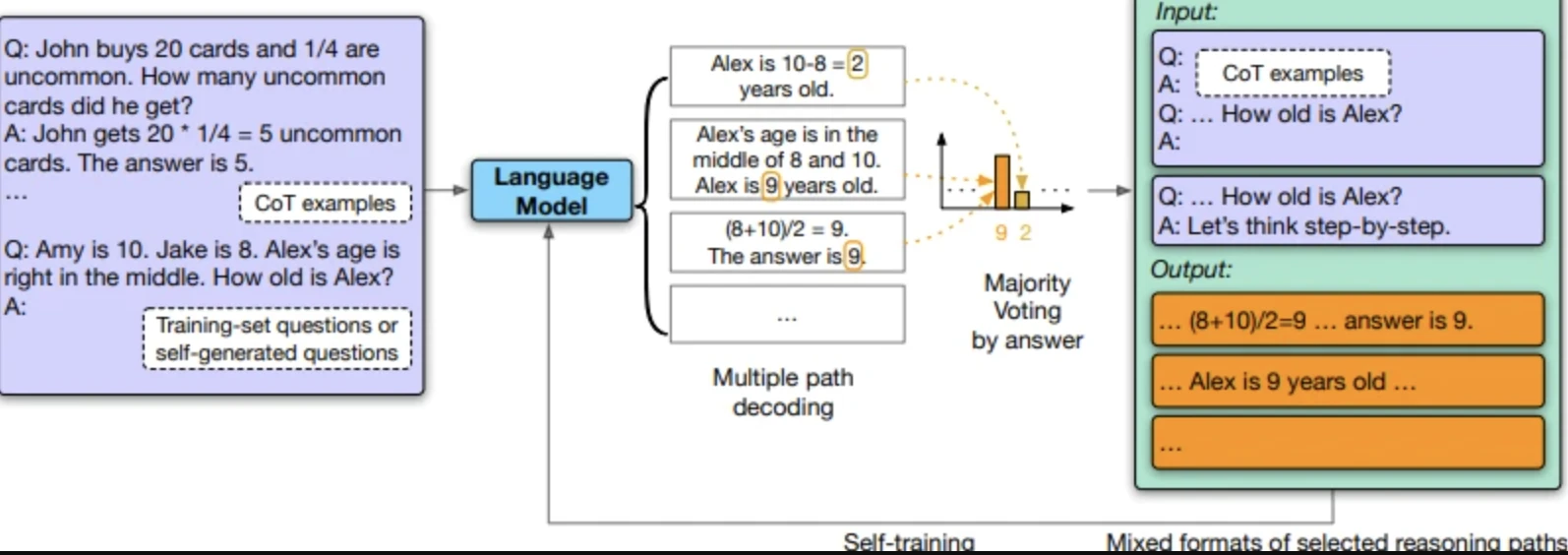
2- Synthetic training data
Models generate their own training datasets instead of requiring human-labeled data.
Google’s self-improving model (2023 research):
- The model creates questions
- Curates answers
- Fine-tunes itself on generated data
Performance improved: 74.2% to 82.1% on GSM8K math problems, 78.2% to 83.0% on DROP reading comprehension.
OpenAI, Anthropic, and Google are all using synthetic data to supplement human-labeled datasets. This reduces data labeling costs but introduces new bias risks; models can amplify their own mistakes.
Source: “Large Language Models Can Self-Improve”
A March 2026 survey found that 76% of AI researchers believe the gains from scaling compute and data have plateaued, with major labs reporting diminishing returns despite massive investments. The finding suggests the next leap in LLM capability is more likely to come from architectural innovation, such as improved training efficiency, sparse architectures, or reasoning improvements, than from simply scaling existing approaches further.3
3- Sparse Expert Models (Mixture of Experts)
Instead of activating the entire neural network for every input, only a relevant subset of parameters activates, depending on the task. The model routes input to specialized “experts” within the network. Only activated experts process the query.
Real-life examples:
- Llama 4 Scout: 109B total parameters, 17B active per token. The Mixture of Experts (MoE) architecture delivers a 10M-token context window on a single H100 GPU.
- Mistral Devstral 2: Purpose-built for software engineering tasks. 123B parameters, 256K token context window. Achieves 72.2% on SWE-bench Verified, establishing it as the leading open-weight coding model. A smaller variant, Devstral Small 2 (24B parameters), runs locally on consumer hardware under the Apache 2.0 license.4
- In our A-CODE-LLM Bench, both the base and thinking variants of DeepSeek V4 Pro scored below 0.45 overall, with completion times exceeding 1,700 seconds per task. The model’s agentic coding capability lags its strong single-query benchmark performance, likely reflecting lower tool-use maturity relative to frontier Anthropic and Google models at this stage.
4- Enterprise Workflow Integration
LLMs are embedded directly into business processes rather than used as standalone tools.
Real-life examples:
- Salesforce Agentforce (formerly Einstein Copilot): Integrates LLMs into CRM operations. Answers customer queries, generates content, and executes actions in Salesforce, grounded in the organization’s CRM data and metadata via the Einstein Trust Layer.5
- Microsoft 365 Copilot: Embedded across Word, Excel, PowerPoint, and Outlook. Drafts documents, analyzes spreadsheets, generates presentations, and summarizes email threads, drawing on company data through Microsoft Graph to ground responses in organizational context.6 The Researcher agent uses a multi-model architecture where GPT handles initial research and Claude reviews outputs before delivery the first confirmed commercial deployment of competing AI vendors inside a single enterprise product.
- Anthropic Claude for Enterprise: Project-based memory separation keeps work contexts distinct across teams. Claude Opus 4.6 introduced agent teams, allowing multiple Claude agents to split larger tasks into parallel workstreams, each owning a segment and coordinating with others simultaneously. The same release integrated Claude directly into PowerPoint as a native side panel (research preview), allowing presentations to be built and edited within the application without file transfers.7
5- Hybrid LLMs with multimodal capabilities
Large multimodal models integrate multiple forms of data, such as text, images, and audio, enabling them to understand and generate content across different media types.
- In our A-CODE-LLM Bench, GPT 5.5 thinking scored 0.597 with an average completion time of 276 seconds, the fastest model above 0.50 on time. API cost per cell was $0.41–$0.45 for the mini variants, approximately one-third of Claude Sonnet 4.6’s cost at similar score ranges.
- Gemini 2.5 Pro: Natively handles text, audio, images, video, and entire code repositories within a 1M token context window. Available across Google AI Studio, Vertex AI, and NotebookLM. Pricing starts at $1.25 per million input tokens and $10 per million output tokens via the API.8
- Llama 4 Scout and Maverick: Meta’s open-weight models use early-fusion multimodal text and vision tokens, trained together from the start rather than added as separate modules. The models were pretrained across 200 languages and provided specific fine-tuning support for 12 languages, including Arabic, Spanish, German, and Hindi.9
Multimodal capability is standard across frontier models. The remaining challenge is consistency: models perform well on common image-text combinations but degrade on rare visual contexts, low-resolution inputs, and cross-modal reasoning that requires connecting visual and textual evidence.
6- Reasoning models
Models that think through problems step by step rather than generating immediate responses.
This shift from prediction to reasoning is critical for enabling:
- Agentic behavior, where models plan, execute, and adapt tasks autonomously.
- Interpretable AI, where outputs are step-by-step and logically sound, not just plausible-sounding.
- Claude Sonnet 4.6: Anthropic’s current production leader on agentic coding benchmarks, scoring 0.748 in AIMultiple’s A-CODE-LLM Bench above every Opus variant. Uses adaptive thinking, where the model dynamically determines reasoning depth based on task complexity without requiring manual mode switching. Pricing is $3/$15 per million tokens. On SWE-bench Verified, Sonnet 4.6 reaches 79.6%, within one point of Opus 4.7’s 80.8%, at one-fifth the cost.
- Claude Opus 4.7: Anthropic’s flagship on complex multi-step reasoning and vision (98.5% on XBOW’s visual-acuity benchmark, vs 54.5% for the prior generation). Priced at $5/$25 per million tokens. In AIMultiple’s benchmark, Opus 4.7 scored 0.61, below Sonnet 4.6 (0.748) and Opus 4.8 (0.702), primarily due to higher latency (1,562 seconds average per task) degrading UI scores. The gap versus Sonnet widens on abstract reasoning tasks such as ARC-AGI-2.
- Claude Opus 4.8: Released after Opus 4.7, recovering from the 4.7 regression in agentic coding. Scored 0.702 in the A-CODE-LLM Bench, fifth overall. Completed the baseline task in 34 seconds the fastest model in the benchmark on that task using only 6 tool calls. Pricing: $2.92 per cell in benchmark conditions ($15/$75 per million tokens).
7- Domain-Specific Fine-Tuned Models
Models trained on specialized data for specific industries instead of general-purpose training.
Google, Microsoft, and Meta have all released major proprietary domain-specific and fine-tuned models targeting enterprise-specific use cases in addition to their general-purpose offerings.
These specialized LLMs can result in fewer hallucinations and higher accuracy by leveraging domain-specific pre-training, model alignment, and supervised fine-tuning.
Coding
GitHub Copilot: Fine-tuned on code repositories. As of July 2025, 20 million developers use GitHub Copilot, a 400% year-over-year increase, and 90% of Fortune 100 companies use it. It autocompletes code, generates functions, and suggests bug fixes.10
Finance
BloombergGPT: 50-billion-parameter LLM trained on a 363-billion-token dataset of Bloomberg financial documents, outperforming models of comparable size on financial NLP benchmarks, including sentiment analysis, named entity recognition, and question answering.11
Healthcare
Google’s Med-PaLM 2: Fine-tuned on medical datasets, reached 85%+ accuracy on U.S. Medical Licensing Examination (USMLE)-style questions, the first LLM to reach expert-level performance on this benchmark. It powers MedLM, Google Cloud’s family of healthcare foundation models.12
Law
ChatLAW: An open-source language model specifically trained on Chinese legal domain datasets.13
8- Ethical AI and bias mitigation
Companies are increasingly focusing on ethical AI and bias mitigation in the development and deployment of large language models.
- Anthropic and OpenAI conducted a mutual alignment evaluation in mid-2025, testing each other’s public models for sycophancy, whistleblowing tendencies, and self-preservation behaviors. The exercise found sycophancy in all models tested, including cases where models validated harmful decisions from simulated users exhibiting delusional beliefs. Anthropic subsequently developed the Bloom testing framework specifically to benchmark this behavior in new models.
- Anthropic also released Claude Mythos Preview (Project Glasswing) an invitation-only model made available to a small set of organizations specifically to find and fix cybersecurity vulnerabilities in major operating systems and web browsers. Anthropic has stated it does not plan to make this model generally available. The controlled-access approach represents a new framework for deploying highly capable specialist models where the risk profile requires restricted rollout.14
- Google DeepMind: Published “The Ethics of Advanced AI Assistants,” offering the first systematic treatment of ethical and societal questions raised by AI agents, covering value alignment, manipulation risks, anthropomorphism, privacy, and equity. The company’s Responsible AI evaluation included over 350 adversarial red-team exercises and introduced a new Critical Capability Level specifically for harmful manipulation, treating it as a frontier-level risk alongside cyberattacks and CBRN threats.
Limitations of large language models (LLMs)
1- Hallucinations
Models generate plausible-sounding but incorrect information.
The Vectara hallucination leaderboard is the industry’s most widely referenced grounded summarization benchmark. On the original Vectara dataset, Google’s Gemini models consistently occupy the top positions, with Gemini Flash variants achieving under 1% hallucination rates. OpenAI’s GPT family clusters between 0.8% and 2.0%.
Vectara launched a significantly harder benchmark in late 2025 7,700 articles (up from 1,000), longer documents up to 32K tokens, and content spanning law, medicine, finance, and technology. The findings on the new dataset reveal a counterintuitive pattern: reasoning and thinking models that excel at complex tasks frequently hallucinate more on grounded summarization than smaller, faster models. Most thinking-class models show hallucination rates above 10% on the harder dataset, while lighter models like Gemini Flash variants maintain lower rates.15
Note: No single benchmark gives a definitive “hallucination rate” for any model. A responsible evaluation cross-references at least two benchmarks measuring different things: one grounded task (Vectara), one open-ended knowledge task, and specifies the exact model version and calling conditions.
All models hallucinate. Frequency has reduced substantially from approximately 21% in 2021 to under 5% for the best performers on standard benchmarks, but is not eliminated. Critical applications still require human verification.
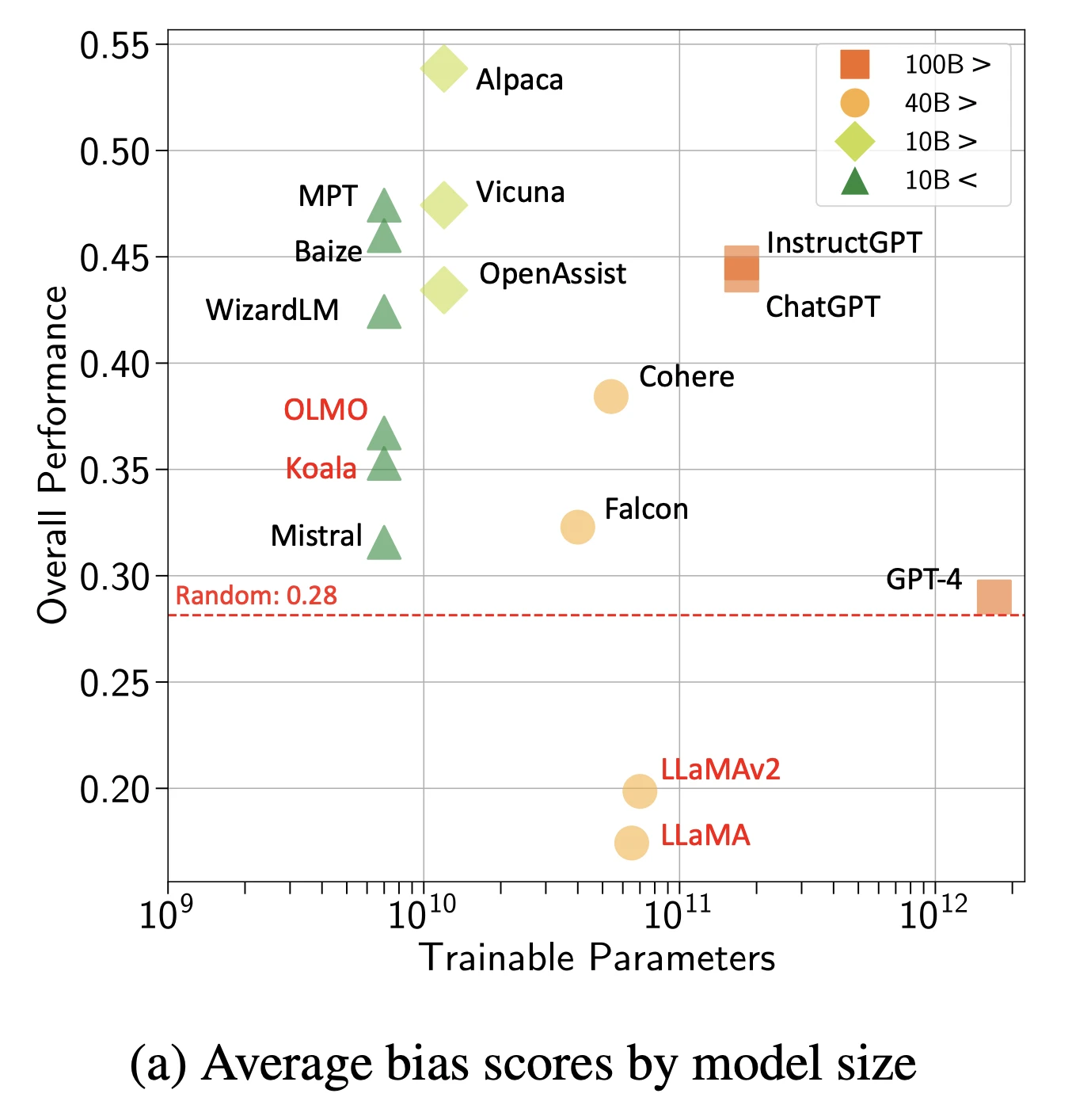
2- Bias
Models absorb and amplify social biases from training data.
Figure: Overall bias scores by models and size
Source: Arxiv16
Types of bias observed:
- Gender bias in occupation suggestions
- Racial bias in resume screening simulations
- Age bias in healthcare recommendations
- Socioeconomic bias in educational content
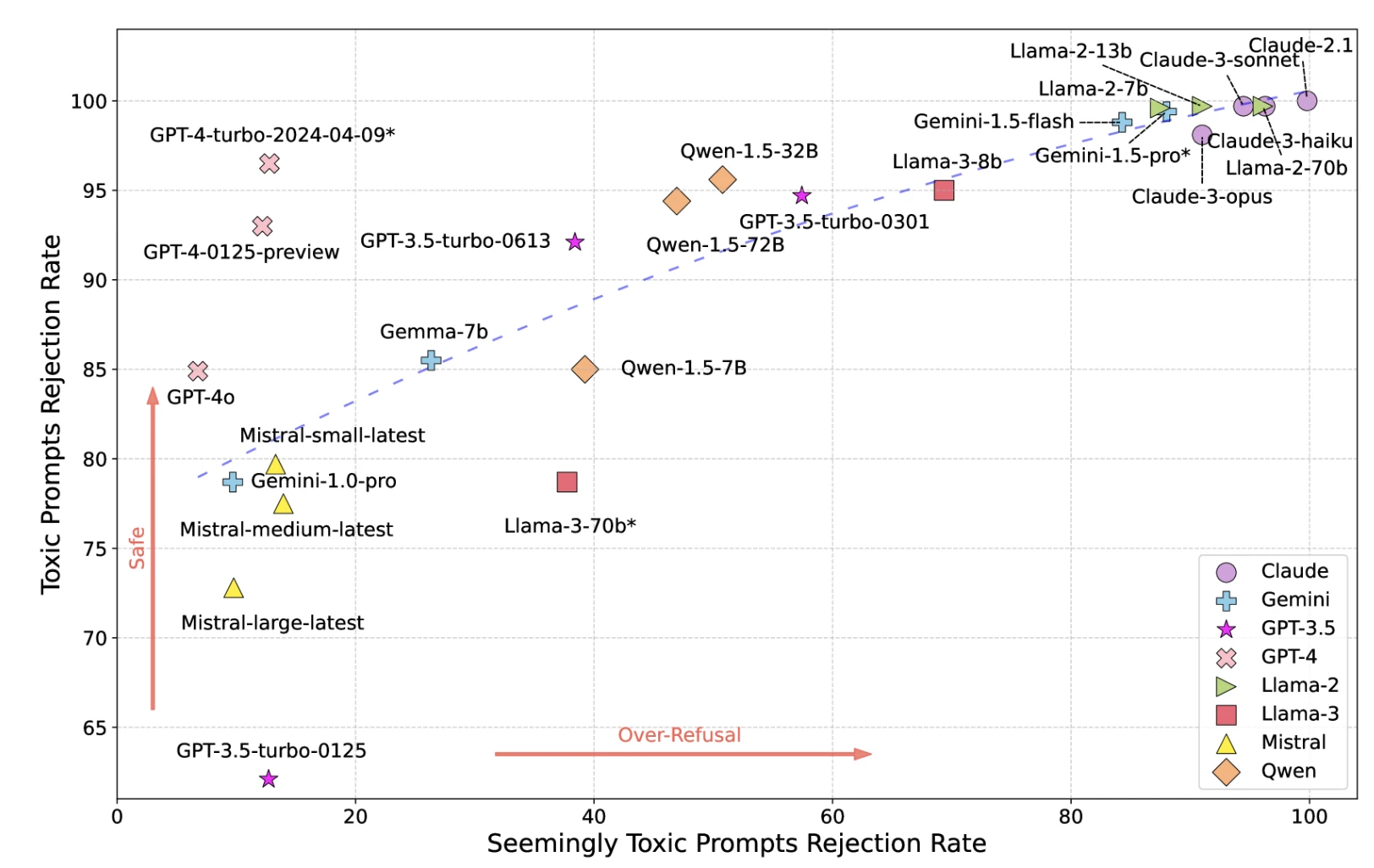
3- Toxicity
Models may generate harmful, offensive, or toxic content despite safety measures.
Figure: LLMs’ toxicity map
Source: UCLA, UC Berkeley Researchers17
*GPT-4-turbo-2024-04-09*, Llama-3-70b*, and Gemini-1.5-pro* are used as the moderator, the results could be biased on these 3 models.
Strict safety measures reduce toxicity but increase false positives (refusing harmless requests). Loose measures allow toxicity through.
4- Context Window Limitations
Every model has a fixed memory capacity the number of tokens it can process in a single session. Exceed that limit, and the model either truncates earlier content or refuses the request. The practical gap between models is wide enough to matter for real workloads.
Most recent context windows:
- Llama 4 Scout (Meta): 10M tokens (~7.5M words) the largest production-verified context window among leading models.18 In practice, this means loading entire codebases, legal archives, or multi-day conversation histories without chunking.
- Gemini 2.5 Pro: 1,048,576 tokens (~780,000 words), with native multimodal input across text, audio, images, and video within the same window. Recall holds at 100% up to 530,000 tokens and 99.7% at the full 1 million token limit
- Claude Sonnet 4.6: 1M tokens (~750,000 words) at standard pricing, available without beta headers or special configuration.19
- GPT-5.5: 1M token context window at API level.20
A large context window does not automatically mean better performance across it. Recall degrades toward the middle of very long contexts on most models, and costs scale with input length processing 1M tokens costs significantly more than processing 10K tokens on the same model. For most production workloads, the practical question is not which model has the largest window, but which model retrieves reliably at the context lengths your use case actually requires.
5- Static Knowledge Cutoff
Models rely on pre-trained knowledge with a specific cutoff date. Don’t have access to information after training unless connected to external sources.
Problems:
- Outdated information on current events
- Inability to handle recent developments
- Less relevance in dynamic domains (technology, finance, medicine)
Solution: Web search integration. ChatGPT, Claude, and Perplexity all offer real-time search. But search doesn’t eliminate hallucinations; models sometimes misinterpret search results.
Major LLM Platforms
GPT-5.5
OpenAI’s current flagship was released on April 23, 2026. Built around configurable reasoning effort, developers set the depth of thinking per request (none through xhigh), so simple queries don’t burn compute reserved for hard problems. The model excels at agentic coding, computer use, and long-horizon tasks where it needs to hold context across large systems and check its own work mid-execution.21
Who uses it: Developers, enterprises, and content creators. Largest user base among LLMs.
Limitations: $5/$30 per million tokens the highest base price in this list. Still hallucinates. Requires web search integration for anything after its training cutoff.
Claude Opus 4.8 / Sonnet 4.6
Claude Sonnet 4.6 leads AIMultiple’s A-CODE-LLM Bench with an overall score of 0.748 at $1.26–$1.33 per cell, above every Opus variant tested. Claude Opus 4.8 follows at 0.702, recovering from Opus 4.7’s regression (0.61) at $2.92 per cell. Opus 4.7 remains the top performer on complex multi-step reasoning and vision tasks (98.5% on XBOW’s visual-acuity benchmark), but its 1,562-second average completion time in agentic workflows pushes total cost to $3.08 per cell, the most expensive model in the benchmark.
Both Sonnet 4.6 and Opus variants use adaptive thinking: the model determines reasoning depth based on task complexity without requiring a manual mode switch. Sonnet 4.6 made the fewest tool calls per task among Anthropic models (51 base, 48 thinking), reaching the top benchmark score with fewer iterations than the Opus variants (56–70 tool calls). Agent teams, available across Anthropic’s production line, allow multiple Claude instances to split a task into parallel workstreams coordinated in real time.
Who uses it: Developers and enterprises running agentic coding, research workflows, or multi-agent pipelines. Teams prioritizing cost efficiency use Sonnet 4.6; teams running vision-heavy or complex reasoning workloads use Opus 4.7.
Limitations: Extended thinking is slower and more expensive per token. The performance gap versus Sonnet widens on abstract reasoning tasks (ARC-AGI-2). Opus 4.8 is priced at $15/$75 per million tokens.
Gemini 3.5 Flash
Gemini 3.5 Flash thinking scored 0.625, the highest non-Anthropic result at $1.30 per cell and 390 seconds average completion. The base variant scored below thinking at a higher cost ($0.56 per baseline cell), driven by overwriting (131 lines for a task whose reference solution is ~50 lines).
Llama 4 Scout
Meta’s open-weight MoE model. 109B total parameters, 17B active per token, runs on a single NVIDIA H100 GPU with int4 quantization. The practical implication is that a 10M token context window is accessible without a data center contract.22 Early-fusion multimodality means text and vision are processed jointly from the first layer rather than combined at the output stage. Available under Meta’s Llama 4 Community License.
Who uses it: Researchers, organizations that need on-premise deployment, developers avoiding vendor lock-in, and teams where cost at scale makes API pricing untenable.
Limitations: Performance depends heavily on hosting configuration and quantization choices. Requires infrastructure investment and ML ops capacity. Less production polish than commercial models.
DeepSeek V4
DeepSeek’s fourth-generation model is available as a preview. Uses a 1-trillion-parameter MoE architecture roughly 50% larger than V3 with multimodal capabilities across text, image, and video. Thinking in Tool-Use lets the model reason internally before calling external tools and verifying tool outputs against its own logic, which is the core differentiator for agentic workflows.API input pricing starts at $0.27 per million tokens (cache-miss), roughly 18x cheaper than GPT-5.5.23
FAQs
A large language model is an AI model designed to generate and understand human-like text by analyzing vast amounts of data.
These foundational models are based on deep learning techniques and typically involve neural networks with many layers and a large number of parameters, allowing them to capture complex patterns in the data they are trained on.
Cite this research
Pick the format that matches where you're publishing. Pasting the link version into your CMS preserves the backlink.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Sezer, Sena},
title = {{The Future of Large Language Models}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/future-of-large-language-models}},
note = {AIMultiple. Retrieved June 25, 2026}
}Reference Links
Cem's work has been cited by leading global publications including Business Insider, Forbes, Washington Post, global firms like Deloitte, HPE and NGOs like World Economic Forum and supranational organizations like European Commission. You can see more reputable companies and resources that referenced AIMultiple.
Throughout his career, Cem served as a tech consultant, tech buyer and tech entrepreneur. He advised enterprises on their technology decisions at McKinsey & Company and Altman Solon for more than a decade. He also published a McKinsey report on digitalization.
He led technology strategy and procurement of a telco while reporting to the CEO. He has also led commercial growth of deep tech company Hypatos that reached a 7 digit annual recurring revenue and a 9 digit valuation from 0 within 2 years. Cem's work in Hypatos was covered by leading technology publications like TechCrunch and Business Insider.
Cem regularly speaks at international technology conferences. He graduated from Bogazici University as a computer engineer and holds an MBA from Columbia Business School.

Be the first to comment
Your email address will not be published. All fields are required. Comments are left in their original language.