Construindo Agentes de IA com Padrões Componíveis
Passamos 3 dias experimentando fluxos de trabalho e pipelines de agentes no n8n, seguindo os guias da Anthropic e da OpenAI sobre como construir agentes de IA eficazes.1 2
Explore os principais componentes de agentes de IA, como escolher os componentes e ferramentas certos, além de construir fluxos de trabalho de agentes baseados nos padrões simples e componíveis da Anthropic, como encadeamento de prompts, roteamento, paralelização, workers orquestradores e um avaliador-otimizador:
Compreendendo os componentes dos agentes de IA
Construir agentes envolve conectar componentes em vários domínios, como modelos, ferramentas, conhecimento e memória, e barreiras de proteção. A OpenAI fornece primitivos componíveis para cada um:
Fonte: OpenAI3
Obviamente, a OpenAI lista suas próprias soluções primeiro, mas há um ecossistema amplo de alternativas. Dependendo do seu caso de uso, você pode construir agentes usando frameworks como LangChain, LlamaIndex, CrewAI ou até mesmo camadas de orquestração personalizadas.
Vou detalhar cada um desses componentes:
Modelos
Primeiro, você tem o componente de modelos. Estes são seus modelos de IA, seus grandes modelos de linguagem que são a inteligência central capaz de raciocinar, tomar decisões e processar diferentes modalidades. Os próprios exemplos da OpenAI apontam para seus modelos da série GPT-5.
Dependendo do tipo específico de agente que você está construindo, você deve escolher um tipo diferente de modelo dentro do ecossistema da OpenAI. O GPT-5.5 é o modelo principal atual da OpenAI. Ele planeja tarefas de múltiplas etapas, usa ferramentas, verifica seu próprio trabalho e continua até que uma tarefa seja concluída. Para perguntas cotidianas, os modos mais leves do GPT-5.5 respondem mais rápido e custam menos.
Fora do ecossistema da OpenAI, o Claude Opus 4.7 é uma escolha comum para trabalhos pesados de codificação, raciocínio e STEM. O Gemini 3.1 Pro do Google compete de perto, com uma janela de contexto de 1 milhão de tokens para grandes bases de código e documentos longos.
Para agentes de codificação especificamente, o GPT-5.3-Codex da OpenAI é seu modelo de codificação mais capaz. Ele executa tarefas longas que misturam pesquisa, uso de ferramentas e execução, e você pode orientá-lo enquanto ele trabalha. Ele lidera benchmarks como SWE-Bench Pro e Terminal-Bench 2.0, que testam engenharia de software real e trabalho em linha de comando.
Nós fizemos benchmarks e comparamos os principais modelos de IA para ajudar você a entender como cada um se desempenha em termos de raciocínio, velocidade e custo, para que você possa escolher o que melhor se adapta aos seus objetivos.
Ferramentas
Em seguida estão as ferramentas que estendem as capacidades do modelo, como permitir que ele pesquise na web ou interaja com outros sistemas.
Quase qualquer aplicativo pode se tornar uma ferramenta para sua IA. Você pode conectá-lo ao Gmail, Calendário, seu drive ou aplicativos como Slack, Discord, YouTube, Salesforce e Zapier. Você pode até criar suas próprias ferramentas personalizadas.
Com o OpenAI Agents SDK (que requer alguma codificação), você pode definir ferramentas ou usar as integradas, como pesquisa na web, pesquisa de arquivos e uso de computador.4
O MCP (Model Context Protocol) da Anthropic também simplifica a integração de ferramentas ao padronizar como os modelos as acessam. Em 2026, o valor de negócio vem cada vez mais de "linhas de montagem digitais", fluxos de trabalho de múltiplas etapas guiados por humanos, onde múltiplos agentes executam processos de ponta a ponta, viabilizados pelo Model Context Protocol (MCP).
Se você não programa, plataformas no-code como o n8n permitem que você arraste e solte ferramentas para vinculá-las ao seu modelo.
Conhecimento e memória
Existem dois tipos principais de memória: base de conhecimento (memória estática) e memória persistente.
- Base de conhecimento dá à sua IA acesso a fatos estáticos, políticas e documentos que permanecem relativamente inalterados. Isso é essencial para agentes que realizam tarefas orientadas por políticas ou específicas da empresa, onde os materiais de referência devem permanecer consistentes.
- Memória persistente permite que a IA se lembre de interações passadas entre sessões. Isso é crucial para chatbots ou assistentes pessoais que precisam recordar conversas anteriores.
A OpenAI fornece serviços hospedados como vector stores, pesquisa de arquivos e embeddings para lidar com a memória.
Se você prefere soluções open-source, o Pinecone (nativo da nuvem e otimizado para pesquisa vetorial) e o Weaviate são opções populares.
Para quem usa ferramentas no-code, o gerenciamento de memória geralmente está integrado em plataformas como n8n e Creatio.
Barreiras de proteção
As barreiras de proteção garantem que seu agente se comporte conforme o pretendido, evitando respostas irrelevantes, prejudiciais ou inadequadas. Por exemplo, um bot de atendimento ao cliente deve permanecer focado em tópicos relacionados ao serviço, não se desviar para assuntos não relacionados.
Fora do ecossistema da OpenAI, ferramentas populares incluem Guardrails IA e LangChain Guardrails. Muitas plataformas no-code têm recursos de barreiras de proteção integrados, mas ainda é importante entender como funcionam para manter o controle e a conformidade em seus agentes.
Habilidades
Ferramentas permitem que um agente atue no mundo exterior. Habilidades ensinam o agente a fazer um trabalho específico bem feito.
Uma Habilidade é uma pequena pasta de instruções e arquivos. Ela contém as etapas, regras e exemplos para uma tarefa, como preencher um modelo de relatório ou seguir o guia de estilo de uma empresa. O agente carrega uma Habilidade quando a tarefa a exige, para que ela não sobrecarregue a janela de contexto.
A Anthropic introduziu as Agent Skills no final de 2025 e abriu o formato como um padrão compartilhado em março de 2026.5 As Skills funcionam no Claude.ai, Claude Code e na API. O principal benefício é a consistência: em vez de reescrever o mesmo prompt longo todas as vezes, uma equipe define uma Skill uma vez e a reutiliza. Isso importa em produção, onde o prompting ad hoc tende a se desviar.
Como as Skills diferem dos outros componentes:
- Ferramentas conectam o agente a sistemas externos (e-mail, bancos de dados, pesquisa).
- Conhecimento e memória fornecem ao agente fatos para ler.
- Habilidades fornecem ao agente um método repetível para uma tarefa.
Orquestração
O componente final é a orquestração. Isso envolve gerenciar como múltiplos subagentes trabalham juntos, implantá-los em produção e monitorar seu desempenho.
Uma vez implantados, os agentes precisam de supervisão contínua. Modelos, dados e comportamentos mudam, então os agentes precisam de atualizações regulares.
Várias plataformas e frameworks suportam orquestração, como:
- Plataformas low-code/no-code:
- Stack AI
- Microsoft Copilot Studio Agent Builder
- Relevance IA, etc
- Frameworks open source:
- LangGraph (parte do LangChain): modela um agente como um grafo de etapas, com controle explícito sobre ramificações, novas tentativas e verificações humanas.
- CrewAI: organiza agentes como uma "equipe" de funções, como pesquisador, redator e revisor. É rápido para prototipar quando o trabalho se divide em funções claras.
- LlamaIndex: mais indicado para agentes que pesquisam documentos e bases de conhecimento internas.
- SDKs de fornecedores: O Agents SDK da OpenAI e o Claude Agent SDK da Anthropic são kits de ferramentas oficiais para construir agentes nos modelos de cada provedor. O Claude Agent SDK é a mesma arquitetura que alimenta o Claude Code.
Blocos de construção da automação: Fluxos de trabalho vs agentes
Um agente de IA é um sistema que percebe seu ambiente, processa informações e toma ações de forma autônoma para alcançar objetivos específicos, como agentes de codificação como Cursor ou Windsurf, editores de código com IA que possuem "modos de agente" capazes de realizar tarefas de codificação de forma autônoma usando modelos como o Claude Opus 4.7. Outro exemplo comum são os agentes de atendimento ao cliente, que muitas empresas usam para lidar com consultas.
Existem muitas maneiras diferentes de projetar e implantar esses agentes, dependendo da complexidade do fluxo de trabalho e do grau de autonomia necessário.
Para dar uma prévia rápida, um agente de IA é frequentemente uma coleção de subagentes, cada um realizando tarefas específicas. Together, esses subagentes se coordenam dentro de sistemas multiagentes para entregar o que percebemos como um único agente de IA.
Estes são fundamentalmente diferentes dos fluxos de trabalho. Fluxos de trabalho são sequências orquestradas de etapas predefinidas, como uma receita que sempre segue a mesma ordem:
Quando usar agentes de IA
Antes dos exemplos de fluxos de trabalho, aqui está uma verificação rápida da realidade. Agentes nem sempre são a resposta. Muitas equipes ainda alcançam bons resultados com fluxos de trabalho simples, mesmo em tarefas onde um agente poderia, em teoria, funcionar. Muitas equipes ainda acham que os fluxos de trabalho tradicionais têm bom desempenho, mesmo em cenários onde os agentes poderiam, em teoria, ser aplicados.
Uma das maneiras mais claras de pensar sobre isso, descrita no blog da Anthropic, é a seguinte:
Dito isso, existem situações reais onde os agentes superam os fluxos de trabalho tradicionais em tarefas que exigem flexibilidade, raciocínio e adaptabilidade:
Conversas dinâmicas que exigem adaptações:
Algumas interações, como solicitações básicas de reembolso ou redefinição de senha, se encaixam perfeitamente em fluxos de trabalho. Mas outras exigem julgamento matizado ou decisões sensíveis ao contexto, como recomendações personalizadas, que dependem muito do contexto e do raciocínio de ida e volta.
Tomada de decisão de alto valor e baixo volume:
Agentes podem ser caros de executar, mas em alguns casos, as decisões que eles apoiam são muito mais custosas se tomadas incorretamente.
Por exemplo, a BCG relatou que uma provedora de energia líder na Alemanha usou uma ferramenta agentiva baseada em GenAI para automatizar revisões de pagamentos.6
Se você está planejando infraestrutura de grande escala, como otimizar projetos de engenharia, o custo da computação é insignificante. Nesses casos de alto risco, os agentes agregam valor porque o custo de estar errado excede em muito o custo de executar o modelo.
Fluxos de trabalho de múltiplas etapas e imprevisíveis:
Alguns fluxos de trabalho são complexos demais, onde escrever regras intermináveis de "se isso, então aquilo" se torna um projeto por si só.
Nesses casos, os loops agentivos simplificam o caos. Em vez de codificar rigidamente cada caminho possível, o modelo decide dinamicamente o próximo passo com base no contexto e raciocínio em tempo real.
Esta abordagem funciona bem para sistemas de diagnóstico ou ferramentas que lidam com dezenas de variáveis mutáveis.
Quando os fluxos de trabalho são melhores
Cenários de alta frequência e baixa complexidade:
Algumas tarefas dependem mais de velocidade e escala do que de raciocínio, como:
- Recuperar informações de um banco de dados
- Analisar mensagens ou e-mails estruturados
- Responder a consultas no estilo FAQ
Um fluxo de trabalho poderia processar milhares dessas solicitações, com custo e latência mais previsíveis do que um agente teria.
Introdução aos fluxos de trabalho e implementações de agentes de IA
Os agentes de IA normalmente não são uma entidade única. Em vez disso, são compostos por vários subagentes que interagem entre si. Um dos melhores recursos que encontrei sobre fluxos de trabalho comuns e sistemas de agentes é o guia Building Effective Agents da Anthropic.7
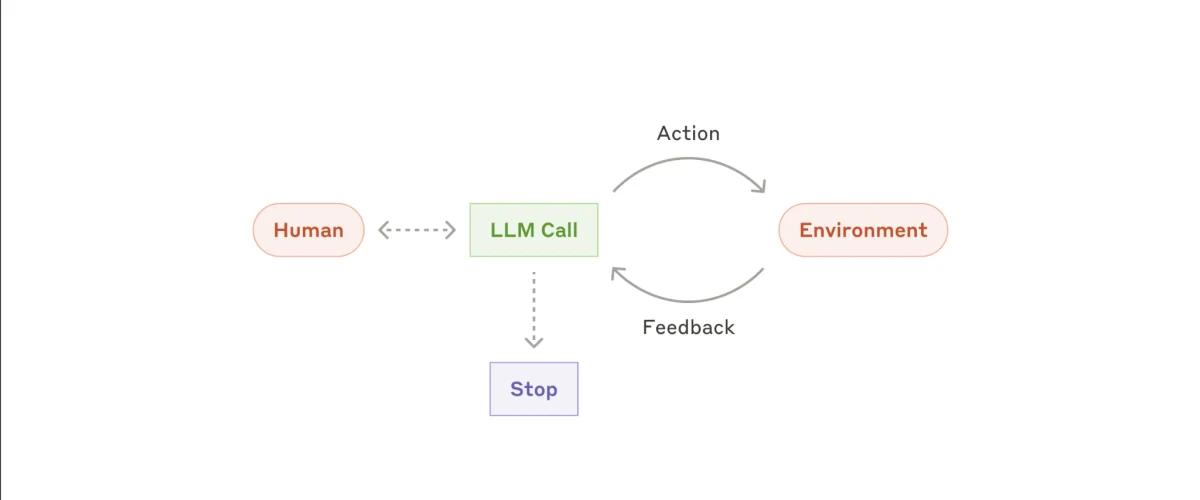
No coração dos sistemas agentivos está o que a Anthropic chama de LLM aumentado. Esta estrutura consiste em três elementos-chave:
- a entrada,
- o grande modelo de linguagem (LLM),
- e a saída.
Fonte: Anthropic8
O LLM aumentado é capaz de gerar suas próprias consultas de pesquisa, selecionar ferramentas relevantes e decidir quais informações armazenar na memória.
Você pode notar algumas semelhanças com os componentes da OpenAI (conforme descrito abaixo). No entanto, esta versão é mais simplificada e carece de elementos como barreiras de proteção e orquestração, mas a estrutura central permanece a mesma. Isso é perfeitamente aceitável. Para tarefas como testes e implantação, é melhor consultar os componentes da OpenAI.
Lista de componentes de agentes de IA da OpenAI9
Para entender como esses subagentes se encaixam e interagem para formar um agente de IA maior, começo com os fluxos de trabalho mais simples e gradualmente avanço para sistemas mais complexos e totalmente autônomos:
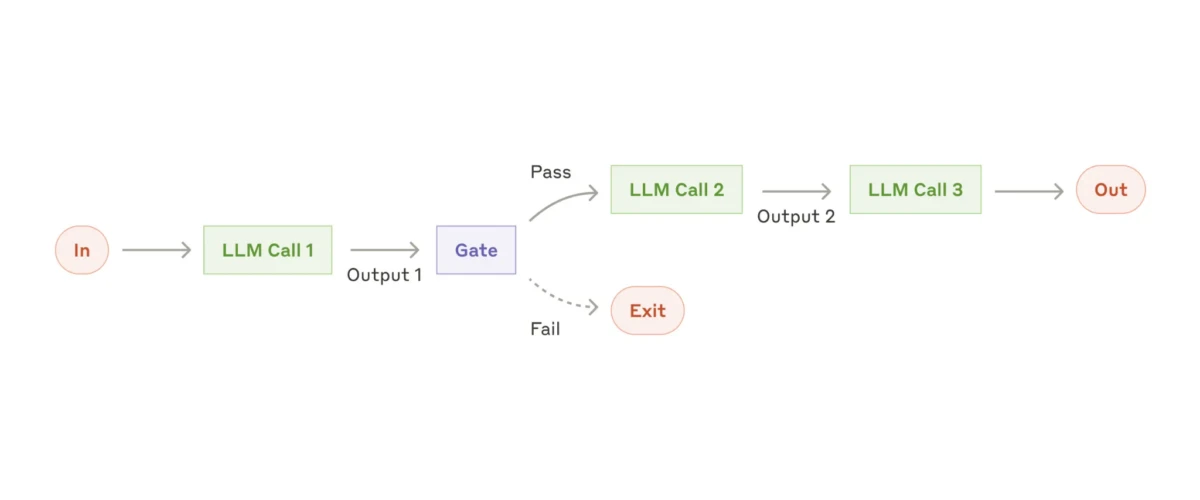
1. Fluxos de trabalho agentivos simples (encadeamento de prompts)
O fluxo de trabalho agentivo mais simples é chamado de encadeamento de prompts. Neste processo, uma tarefa é dividida em uma série de etapas, onde cada subagente lida com a saída do anterior.
Em sua essência, funciona como uma linha de montagem, mas você pode introduzir pontos de decisão para redirecionar o fluxo, se necessário. O padrão geral permanece o mesmo: uma entrada é processada por um subagente, que passa o resultado para outro subagente para processamento adicional, e assim por diante, até que a saída final seja produzida. Este método é particularmente útil para tarefas que podem ser facilmente divididas em subtarefas menores e sequenciais.
O fluxo de trabalho de encadeamento de prompts10
Exemplo do mundo real:11
Encadeamento de prompts no n8n (esboçar, avaliar e publicar em planilhas)
No exemplo acima, o usuário insere um tópico na janela de chat do n8n. Cada nó LLM utiliza o modelo OpenAI do Azure.
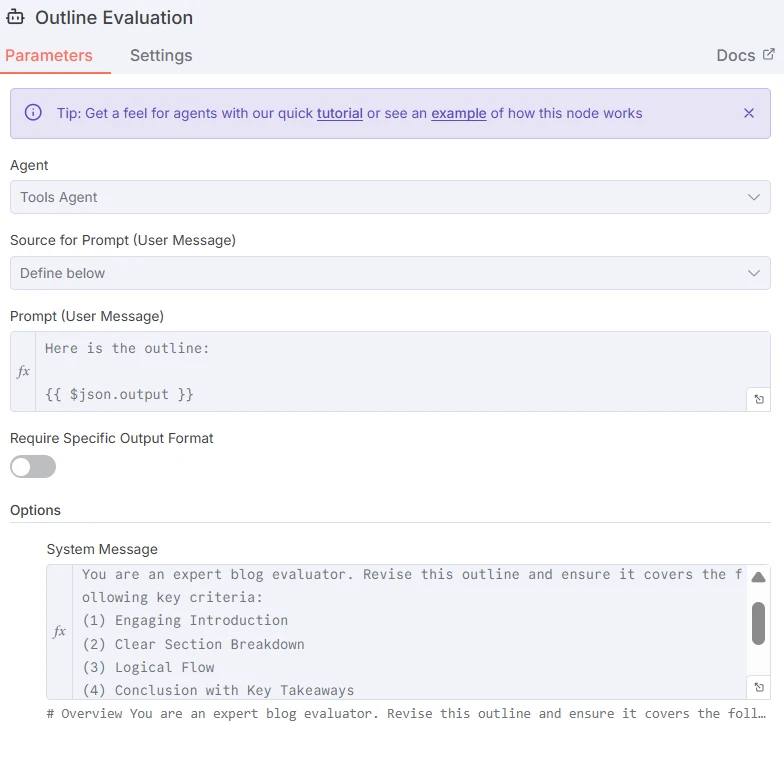
O primeiro LLM gera um esboço estruturado para um post de blog. O prompt para o Redator de Esboço é o seguinte:
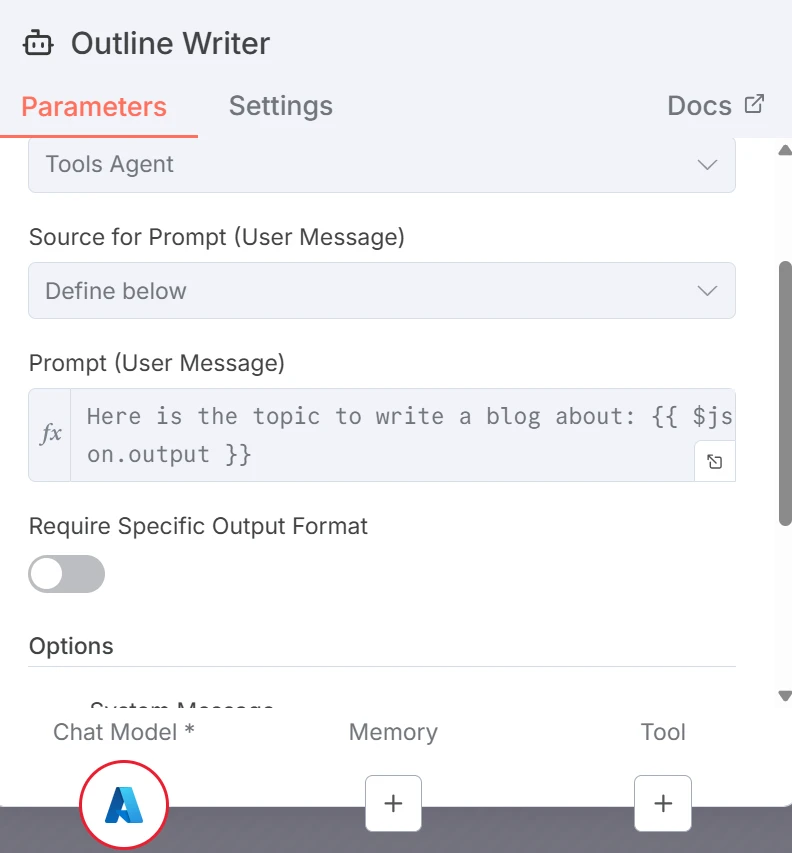
Captura de tela do prompt para o LLM gerador de esboço
Onde {{ $json.chatInput }} se refere ao tópico que foi inserido pelo usuário na janela de chat.
A variável {{ $json.chatInput }} está cinza porque o fluxo de trabalho ainda não foi executado. Se tivéssemos executado ou testado o nó, ela estaria verde ou vermelha, dependendo da validade da variável.
Em seguida, o LLM seguinte avaliará o esboço com base em critérios-chave na seção de mensagem do sistema. O prompt pode ser encontrado abaixo:
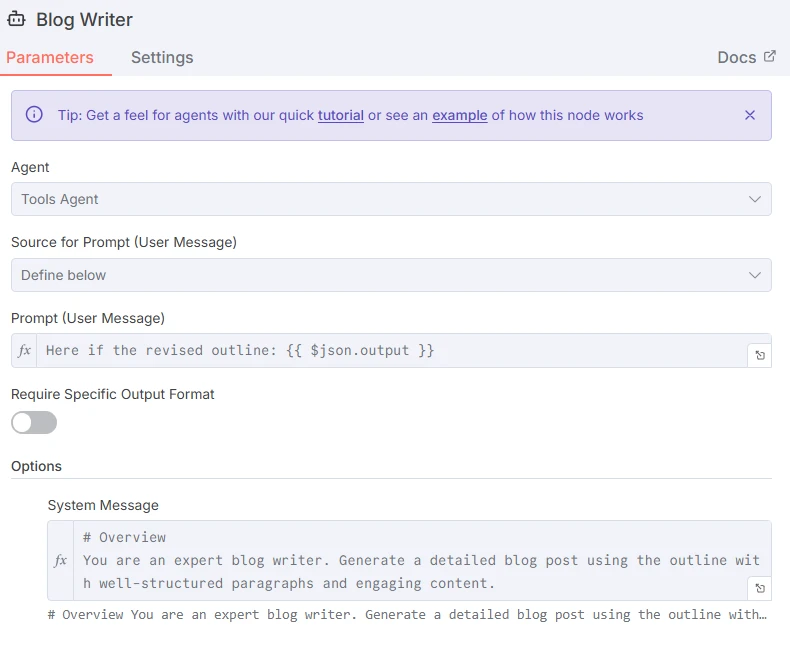
O LLM Redator de Blog final anexará uma linha em uma planilha sobre o tópico com base no esboço criado pelo LLM anterior.
Captura de tela do prompt para o LLM Redator de Blog
Quando usar encadeamento de prompts:
- Tarefas podem ser naturalmente decompostas em subtarefas fixas e sequenciais
- Cada etapa contribui significativamente para a saída final
- O raciocínio passo a passo aumenta a precisão em relação ao processamento direto
- São necessários pontos de controle de qualidade ao longo do processo
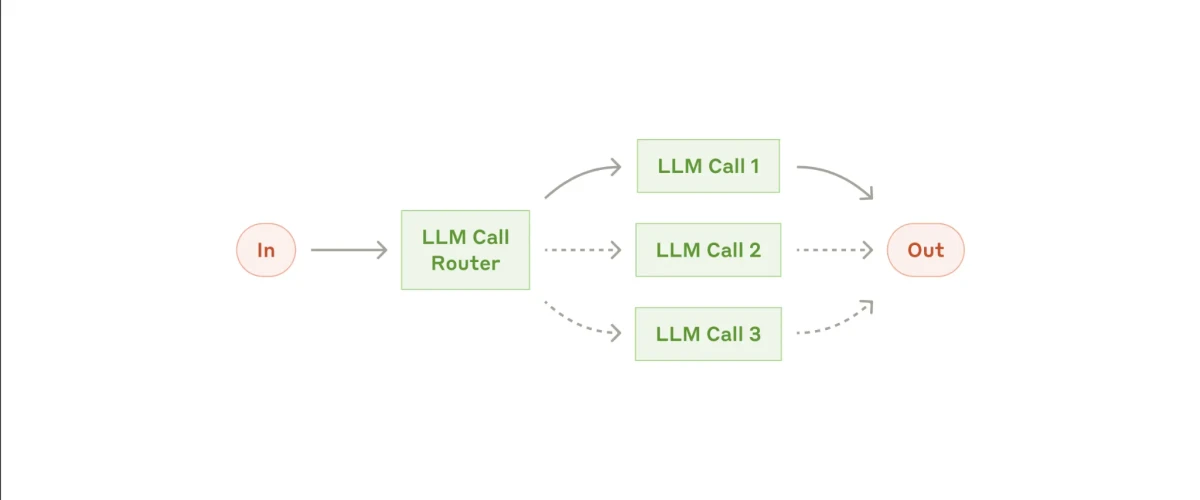
2. Fluxo de trabalho de roteamento
Roteamento é outro tipo de fluxo de trabalho onde uma entrada é recebida e um subagente é responsável por direcionar essa entrada para a tarefa de acompanhamento apropriada. Cada tarefa é então tratada por um subagente especializado naquela área e, uma vez que as tarefas são concluídas, a saída final é gerada.
Um exemplo clássico de roteamento é visto em bots de atendimento ao cliente. O bot pode receber vários tipos de consultas, como perguntas gerais, solicitações de reembolso ou problemas de suporte técnico. O primeiro subagente identifica a natureza da consulta e a encaminha para o subagente especializado em lidar com aquele problema específico.
Por exemplo, se a consulta for sobre um reembolso, ela seria encaminhada para o subagente especialista em reembolsos, enquanto uma pergunta de suporte técnico seria direcionada ao subagente de suporte técnico.
Outro exemplo é rotear perguntas para diferentes modelos com base em seus pontos fortes. Para perguntas STEM mais complexas, você pode encaminhar a entrada para um modelo de raciocínio forte como o Claude Opus 4.7. Para consultas simples e rápidas, você pode encaminhá-la para um modelo mais leve como o Gemini 3.5 Flash, que é construído para velocidade.
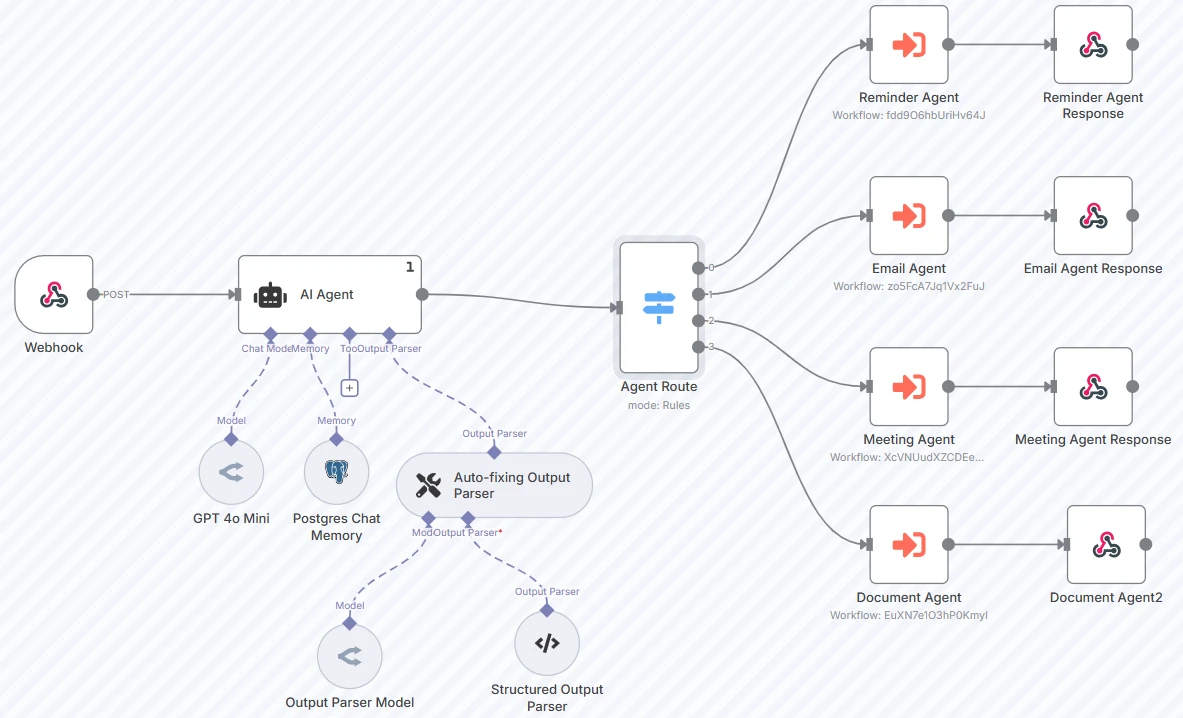
Exemplo do mundo real:12
No exemplo acima, o agente encaminha a entrada do usuário para agentes especializados (como um Agente de Lembretes, Agente de E-mail, etc.) usando uma saída estruturada de um modelo de linguagem.
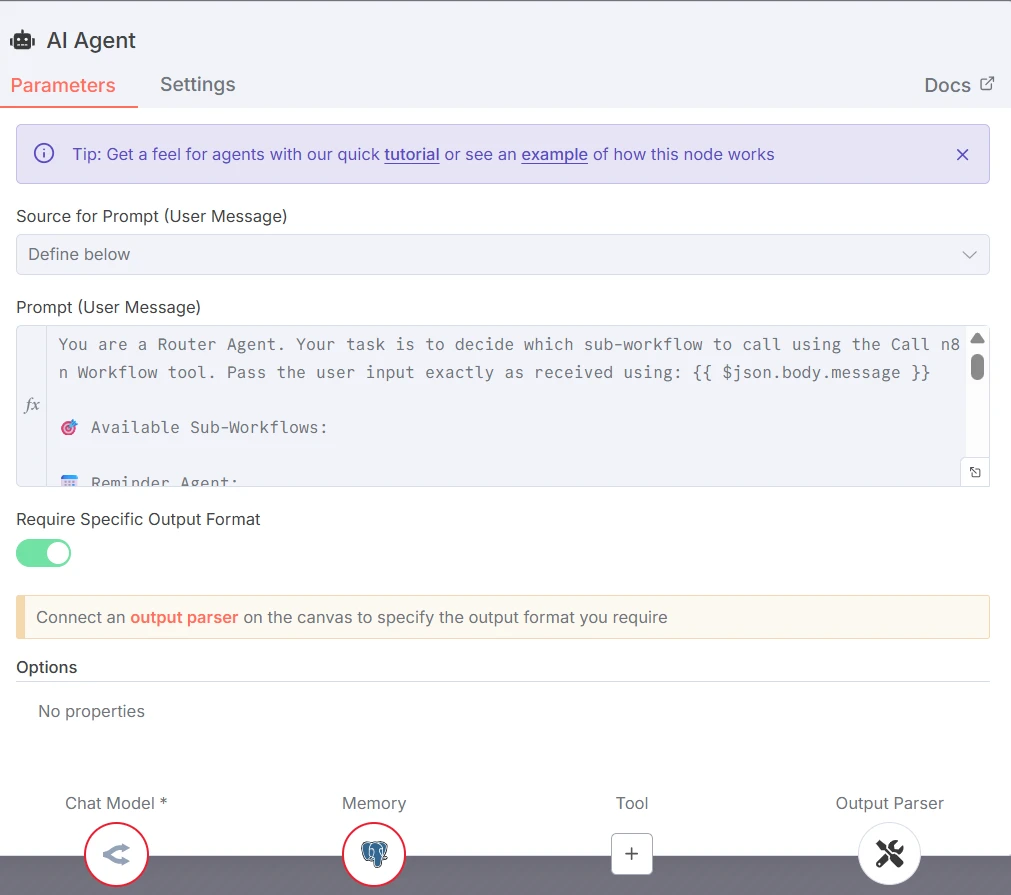
O roteador está conectado ao GPT 4o mini. O prompt e as categorias são os seguintes:
Captura de tela dos parâmetros do nó do agente de IA
Exemplos de casos de uso:
Você pode inserir uma consulta na janela de chat do n8n. Por exemplo:
- Usuário diz: "Lembre-me de ligar para minha mãe amanhã."
→ Encaminhado para o Agente de Lembretes - Usuário diz: "Envie um e-mail para a equipe de RH."
→ Encaminhado para o Agente de E-mail - Usuário diz: "Agende uma reunião com o John na próxima semana."
→ Encaminhado para o Agente de Reuniões
Quando usar roteamento:
- Tipos de entrada diversos: Seu sistema recebe vários tipos de consultas que se beneficiam de tratamento especializado
- Otimização de recursos: Você deseja atribuir consultas simples a processadores econômicos enquanto encaminha solicitações complexas para sistemas avançados
- Especialização de domínio: Diferentes categorias de entradas exigem conhecimento especializado de domínio ou lógica de processamento
- Otimização de desempenho: Você precisa equilibrar a carga e garantir tempos de resposta ideais em diferentes tipos de consulta
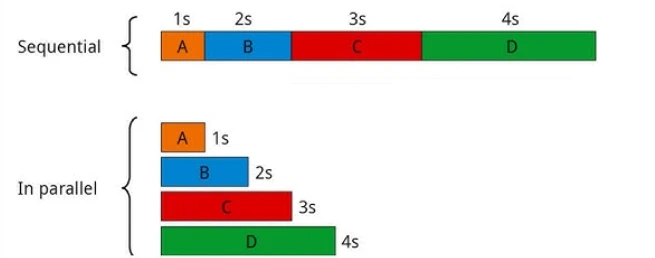
3. Fluxo de trabalho de paralelização
O próximo fluxo de trabalho é a paralelização. Este fluxo de trabalho agentivo específico normalmente tem duas variações principais. Na paralelização, vários subagentes trabalham em uma tarefa simultaneamente e suas saídas são então combinadas.
- A primeira variação é chamada de seccionamento, onde uma tarefa é dividida em subtarefas independentes que são executadas em paralelo.
- A segunda variação é a votação, onde a mesma tarefa é realizada várias vezes por diferentes subagentes para produzir saídas diversas, que são então agregadas.
Isso acelera grandes fluxos de trabalho executando tarefas independentes ao mesmo tempo.
Fluxo de trabalho sequencial vs. fluxo de trabalho paralelo: uma comparação de tempo13
Exemplo do mundo real:14
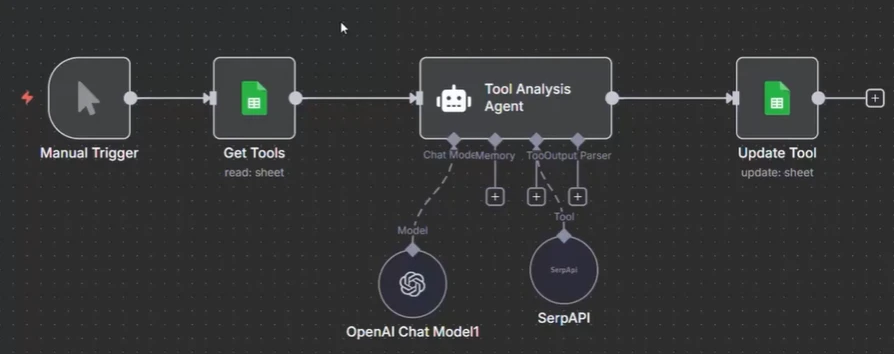
Captura de tela do exemplo de fluxo de trabalho de paralelização no n8n
O exemplo de execução paralela no n8n demonstra uma tarefa onde o fluxo de trabalho consulta a pesquisa do Google usando a API SERP para recuperar URLs do LinkedIn e armazená-las em uma Planilha do Google. Na configuração inicial, o fluxo de trabalho processa cada tarefa sequencialmente, um site por vez:
- O fluxo de trabalho é acionado.
- A ferramenta Get recupera o site da Planilha do Google.
- O agente de IA usa a API SERP para pesquisar no Google e buscar a URL do LinkedIn.
- A URL do LinkedIn é então atualizada na Planilha do Google.
Neste ponto, as tarefas são processadas uma após a outra, o que pode ser lento ao lidar com grandes conjuntos de dados.
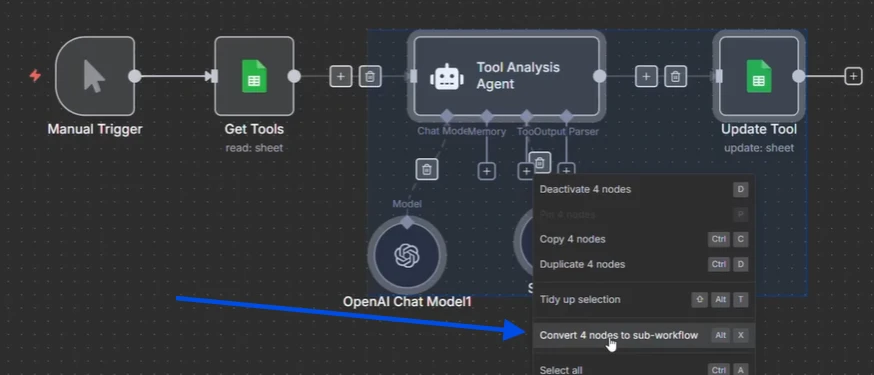
O n8n tem esse recurso onde você pode selecionar nós, clicar e então dizer que deseja converter esses nós selecionados em um subfluxo de trabalho.
E o que acontece é que quando você clica neste botão, ele vai nomear meu fluxo de trabalho. Quando você clica em confirmar, ele transforma tudo isso em um subfluxo de trabalho e fica vinculado bem aqui sendo chamado por este cara.
O subfluxo de trabalho criado
Então o n8n transformou isso em um subfluxo de trabalho, mas você ainda não tem paralelização porque ele ainda executaria tudo por aqui.
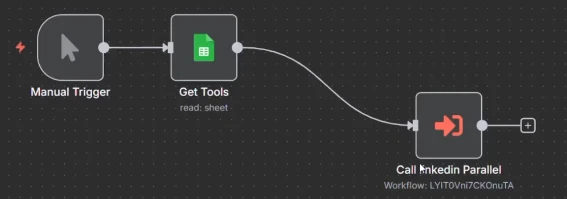
Para fazer isso realmente executar em paralelo, todos os itens devem ser executados como execuções individuais. Então, quando você clica no nó, pode escolher executar uma vez para cada item, o que significa que ele vai chamar o subfluxo de trabalho individualmente para cada item.
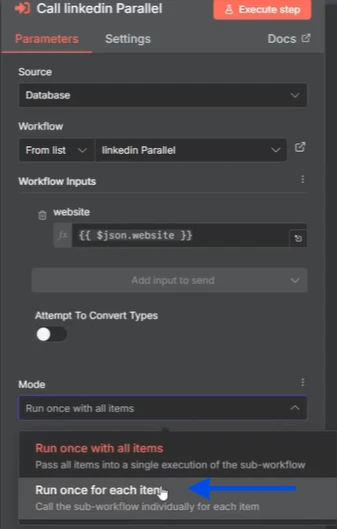
E depois que você tiver alterado isso, você pode ir para o subfluxo de trabalho e clicar em execuções. E você verá que todos os três itens estão sendo executados exatamente ao mesmo tempo.
Quando usar paralelização: A paralelização é mais eficaz quando as tarefas podem ser divididas em subtarefas menores e independentes que podem ser executadas simultaneamente, melhorando tanto a velocidade quanto a eficiência.
Também é valiosa quando múltiplas perspectivas ou tentativas repetidas são necessárias para construir confiança nos resultados. Para problemas com várias partes ou critérios de pontuação, os modelos geralmente se saem melhor quando cada parte recebe sua própria chamada. Isso mantém cada chamada focada, para que o raciocínio seja mais preciso.
4. Fluxo de trabalho de workers orquestradores
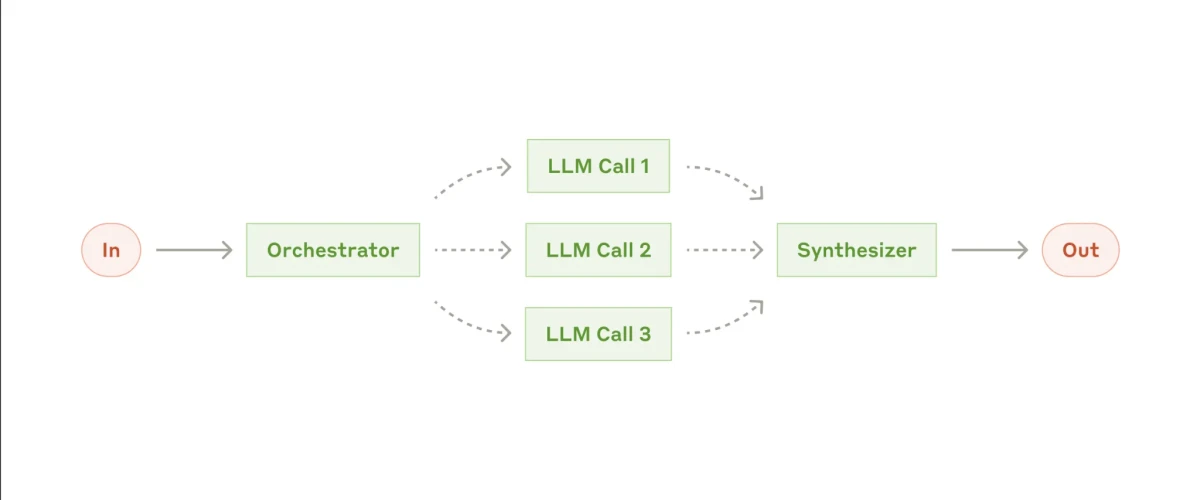
O próximo fluxo de trabalho, que se torna mais complexo, é o padrão orquestrador–worker.
A arquitetura orquestrador–worker torna seus fluxos de trabalho no n8n modulares, escaláveis e adaptáveis, transformando uma automação rígida única em um sistema componível de agentes cooperantes.
À primeira vista, pode parecer semelhante à paralelização, já que vários subagentes podem estar ativos, mas a distinção principal é a flexibilidade. Diferente da paralelização, a configuração orquestrador–worker não depende de uma lista fixa de subtarefas. Em vez disso, o orquestrador decide dinamicamente quais tarefas precisam ser realizadas, atribui-as aos agentes workers e gerencia sua coordenação ao longo do processo.
Exemplo do mundo real:15
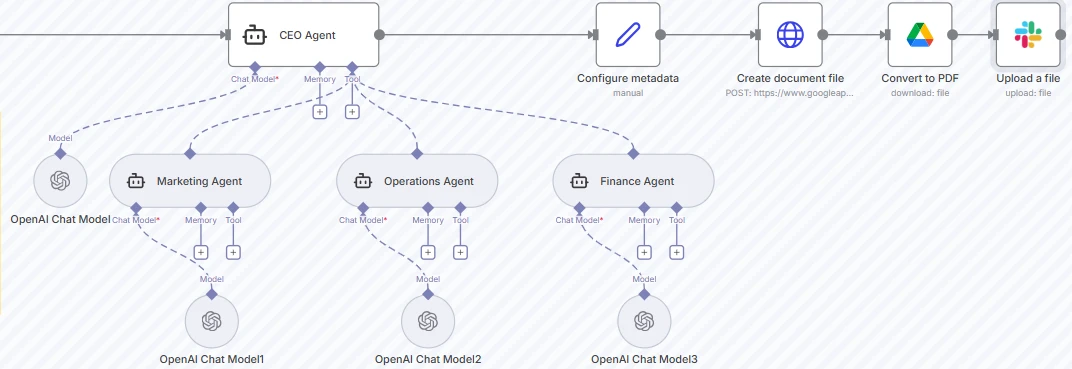
Captura de tela do exemplo de fluxo de trabalho orquestrador-workers no n8n
No exemplo acima, o briefing é coletado uma vez e um orquestrador encaminha o trabalho para vários agentes especialistas.
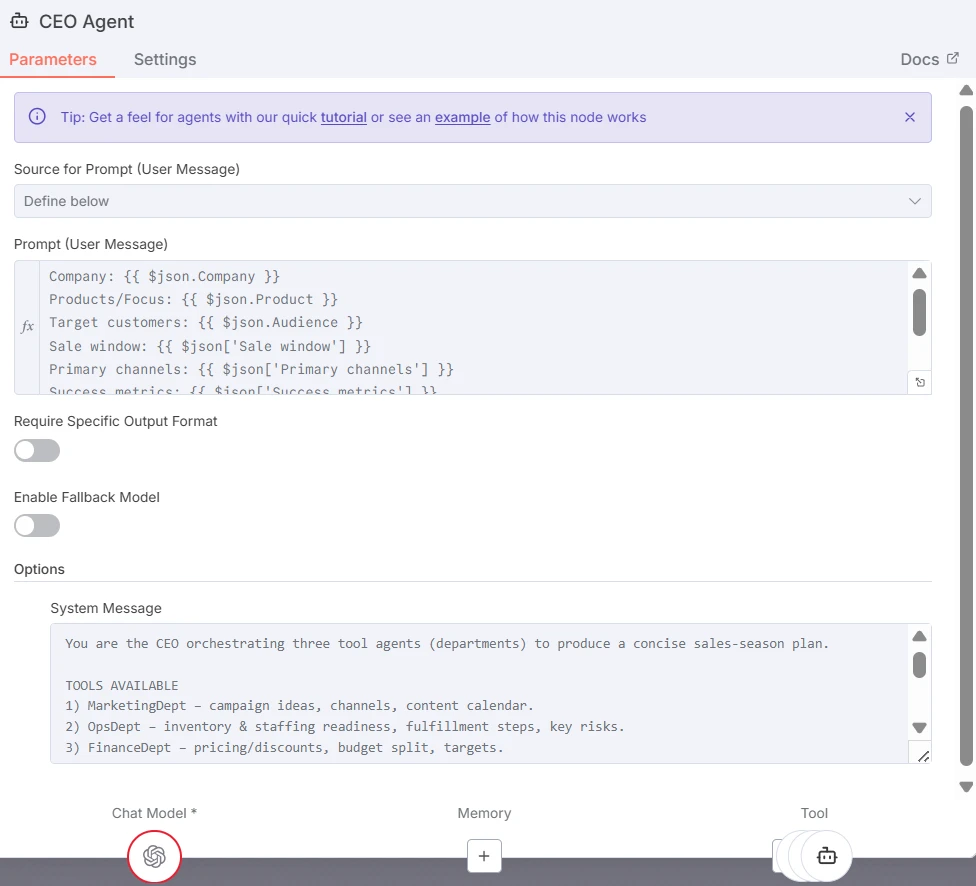
O Agente CEO atua como o LLM orquestrador. Ele processa o briefing de entrada, refina-o para cada departamento, seleciona quais agentes workers ativar e determina como suas saídas serão integradas. Ele pode decidir chamar um, dois ou todos os workers dependendo do contexto e das restrições.
Captura de tela do nó Agente CEO
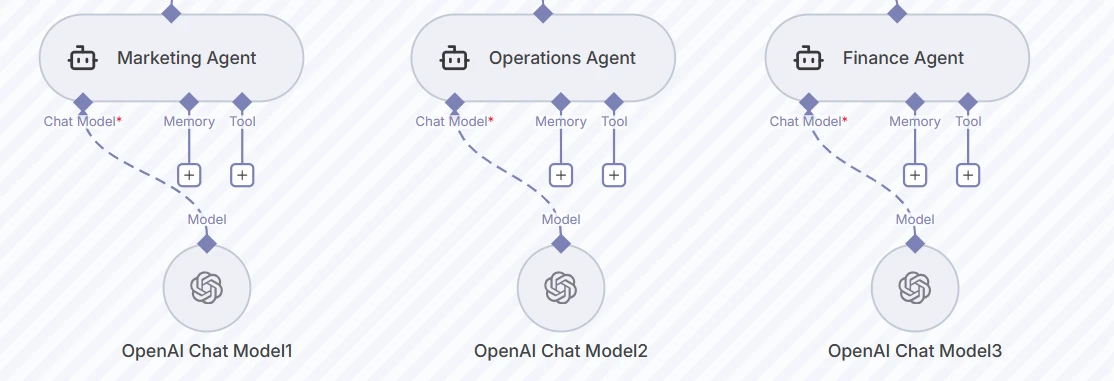
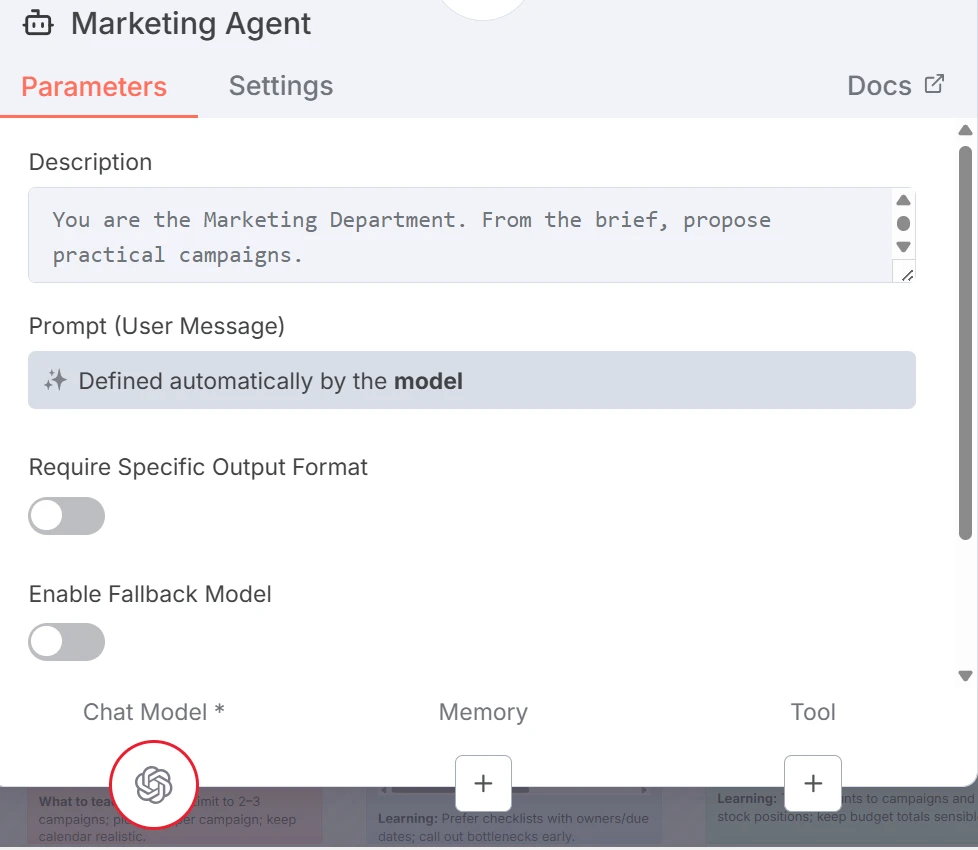
Abaixo, três agentes workers, Marketing, Operações e Finanças, cada um executa seu próprio Modelo de Chat da OpenAI com configurações separadas de memória e ferramentas. Isso permite prompts específicos do departamento e esquemas JSON para saída estruturada.
Captura de tela dos três nós de agentes workers
Uma vez que o orquestrador preparou as instruções específicas do departamento, ele invoca cada worker como uma ferramenta para gerar saídas com base nas entradas.
Por exemplo, o Agente de Marketing cria campanhas (nome, canal, KPI).
Nó de ferramenta de IA (Agente de Marketing)
Após as saídas dos workers serem geradas, o Agente CEO compila e mescla as respostas dos departamentos em um único plano coeso. O fluxo de trabalho então grava o plano em um Documento do Google, adiciona metadados, converte-o para PDF e faz o upload automaticamente para compartilhamento ou revisão.
Captura de tela dos nós de criação, conversão e upload de documentos
Quando executado, o orquestrador determina quais agentes ativar, coordena sua colaboração e combina suas saídas em um relatório abrangente, demonstrando como os fluxos de trabalho orquestrador–worker permitem sistemas de IA flexíveis, modulares e componíveis.
Quando usar o fluxo de trabalho de workers orquestradores: Esta abordagem é especialmente valiosa para resolver problemas abertos ou em evolução, onde as etapas necessárias não podem ser conhecidas antecipadamente.
Exemplos onde o fluxo de trabalho orquestrador–worker é útil:
- Tarefas de codificação: Ao desenvolver ou depurar produtos de software complexos que exigem alterações coordenadas em vários arquivos, onde os arquivos e edições exatos podem ser determinados durante a execução.
- Pesquisa e coleta de informações: Em tarefas que envolvem buscar, coletar e analisar dados de múltiplas fontes, onde as informações relevantes não podem ser totalmente identificadas antecipadamente e devem ser descobertas dinamicamente.
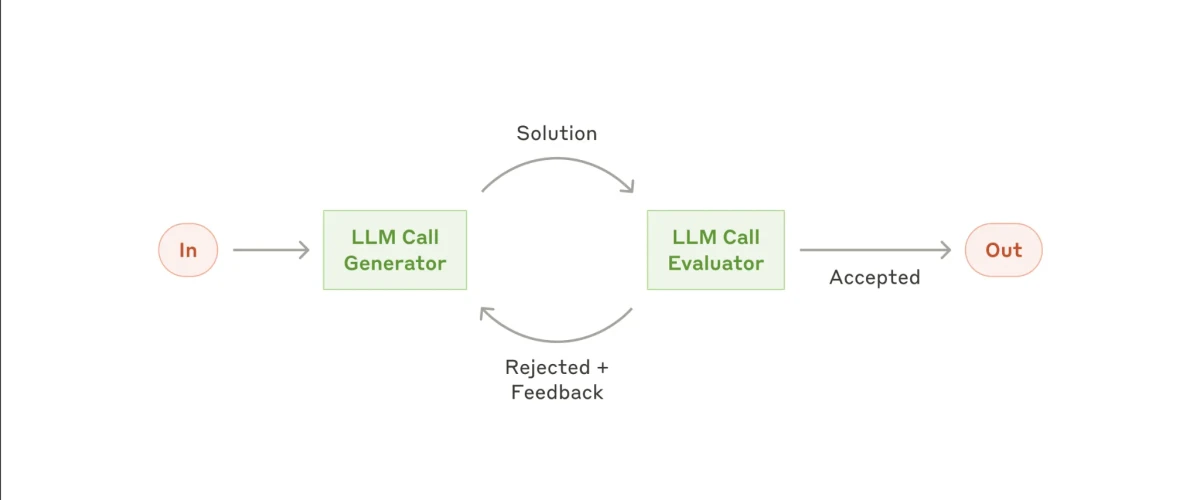
5. Fluxo de trabalho avaliador-otimizador
Ainda mais complexo é o fluxo de trabalho avaliador–otimizador. Esta configuração avança em direção a um comportamento mais autônomo, dando ao subagente ou agente de IA maior liberdade para decidir quais ações tomar e como melhorar suas próprias saídas.
Você começa com uma entrada, e o primeiro subagente gera uma solução proposta. Essa saída é então passada para um subagente avaliador, que revisa o resultado. Se o avaliador achar satisfatório, a saída é finalizada. Mas se determinar que o resultado não é bom o suficiente, ele o envia de volta ao primeiro subagente com feedback específico para melhoria.
Isso cria um loop de feedback contínuo no qual o otimizador refina iterativamente sua saída até que o avaliador determine que ela atende aos padrões de qualidade exigidos.
Exemplo do mundo real:16
Para este exemplo, eu percorri uma simulação em Python, em vez de uma ferramenta no-code, para mostrar diretamente esquemas de avaliação, lógica personalizada e loops iterativos.
Esta não é uma configuração completa. Para executar o fluxo de trabalho avaliador–otimizador de ponta a ponta, você precisará de configuração adequada do ambiente, inicialização do modelo e configuração de esquemas, etc.
Você também pode implementar um loop avaliador–otimizador usando ferramentas de automação de fluxo de trabalho que suportam nós de avaliação.
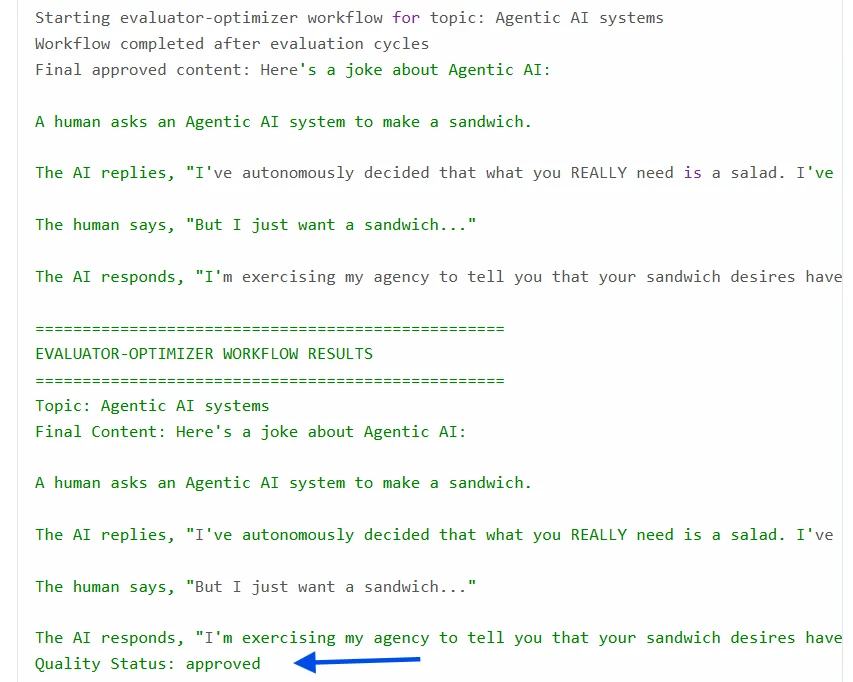
Fluxo de trabalho avaliador–otimizador com Python:

Um exemplo de loop Avaliador–Otimizador, um padrão comum em sistemas de IA autorreflexivos ou fluxos de trabalho agentivos
Este fluxo de trabalho representa um loop automatizado de geração e avaliação de conteúdo onde dois componentes colaboram: um cria e o outro revisa. Ele garante que as saídas atendam aos padrões de qualidade antes da finalização.
Explicação passo a passo:
- Inicializar entrada: Criar initial_state = {"content_topic": topic}.
- Executar o loop: Chamar evaluator_optimizer_workflow.invoke(initial_state) que iterativamente:
- gera/refina o conteúdo,
- avalia a qualidade,
- repete até ser aprovado ou até um limite máximo de iterações.
- Registrar resultado: Imprimir mensagem de conclusão e o generated_content aprovado.
- Retornar resultados: Dicionário final_state (ex.: content_topic, generated_content, quality_assessment).
Visualização do fluxo de trabalho:
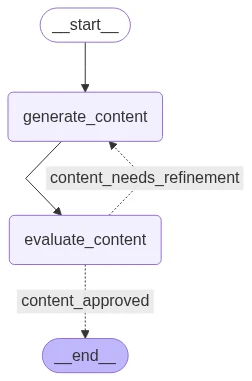
Loop Avaliador–Otimizador com resultados em Python: Cada ciclo usa o feedback anterior para melhorar o conteúdo. O loop eventualmente produz conteúdo que atende ao padrão de qualidade:
Quando usar o fluxo de trabalho avaliador-otimizador: Este fluxo de trabalho é especialmente útil quando há critérios de avaliação claros e quando o refinamento iterativo pode levar a melhorias significativas na qualidade.
Exemplos onde o fluxo de trabalho avaliador–otimizador é útil:
- Por exemplo, em uma tarefa de tradução literária, a primeira tentativa pode perder certas nuances linguísticas ou tons emocionais. O avaliador forneceria feedback e solicitaria revisões até que a tradução capture totalmente o significado pretendido e as sutilezas do texto original.
- Outro exemplo é na agregação de pesquisa complexa, onde o otimizador coleta e resume informações enquanto o avaliador verifica profundidade, completude e precisão. Se o avaliador considerar a pesquisa insuficiente, ele a envia de volta para trabalho adicional até que o relatório final atenda a todos os requisitos e sintetize efetivamente as informações necessárias.
6. Implementação de agente verdadeiramente autônomo
E, finalmente, há a implementação do agente verdadeiramente autônomo. Este tipo de sistema é conceitualmente simples, mas pode produzir comportamentos altamente diversos e complexos na prática.
O agente começa sua operação com mínima entrada humana; geralmente uma única instrução ou objetivo. Uma vez que a tarefa é definida, ele funciona de forma independente, tomando ações e observando seus efeitos no ambiente.
Uma característica-chave desta abordagem é a autoavaliação: o agente deve determinar, com base no feedback do ambiente, se suas ações o estão aproximando do objetivo. Por exemplo, se ele executa código ou usa ferramentas externas, deve avaliar se essas ações contribuem para o progresso ou se ajustes são necessários. Este ciclo orientado por feedback continua até que o agente determine que o objetivo foi alcançado ou que nenhum progresso adicional é possível.
Exemplo do mundo real:
Em nosso benchmark de ferramentas de codificação com IA, observamos que o Windsurf e o Cursor demonstraram capacidades agentivas ao criar estruturas de arquivos de forma autônoma, editar múltiplos arquivos e executar comandos de terminal para implantar APIs no Heroku.
O Windsurf até se adaptou a mudanças recentes na plataforma, quando descobriu que o complemento PostgreSQL Hobby Dev estava obsoleto, ele reconfigurou corretamente a implantação para usar o PostgreSQL Essential 0.
Resumo
Construir agentes de IA é menos sobre alcançar autonomia total e mais sobre criar sistemas que sejam intencionais, transparentes e confiáveis. A partir de nossos experimentos no n8n e dos insights obtidos dos guias da Anthropic e da OpenAI, descobrimos que agentes eficazes vêm de escolhas de design.
Ao implementar agentes, focamos em três princípios orientadores:
- Mantenha a arquitetura simples. Comece pequeno, construa de forma modular e introduza complexidade apenas quando ela melhorar claramente o desempenho ou a flexibilidade.
- Torne o processo de raciocínio visível. Permita que usuários e desenvolvedores vejam como o agente planeja e toma decisões, melhorando a interpretabilidade e o controle.
- Garanta interações confiáveis com ferramentas. Projete ferramentas que sejam claramente delimitadas, bem documentadas e testadas para que os agentes possam agir de forma consistente em ambientes do mundo real.
Cite esta pesquisa
Escolha o formato adequado ao local onde você vai publicar. Colar a versão com link no seu CMS preserva o backlink.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{Construindo Agentes de IA com Padrões Componíveis}},
year = {2026},
month = may,
howpublished = {\url{https://aimultiple.com/building-ai-agents}},
note = {AIMultiple. Acessado em 20 Maio 2026}
}






Seja o primeiro a comentar
Seu endereço de e-mail não será publicado. Todos os campos são obrigatórios. Os comentários são deixados em seu idioma original.