15 Ferramentas de Observabilidade de Agentes de IA: AgentOps & Langfuse
As ferramentas de observabilidade de agentes de IA, como o Langfuse e o Arize, ajudam a coletar traces detalhados (um registro da execução de um programa ou transação) e fornecem dashboards para acompanhar métricas em tempo real.
Muitos frameworks de agentes, como o LangChain, usam o padrão OpenTelemetry para compartilhar metadados com o monitoramento agêntico. Além disso, muitas ferramentas de observabilidade fornecem instrumentação personalizada para maior flexibilidade.
Testamos 15 plataformas de observabilidade para aplicações LLM e agentes de IA. Cada plataforma foi implementada de forma prática, configurando workflows, integrações e executando cenários de teste. Fizemos benchmark de 4 ferramentas de observabilidade para medir se introduzem sobrecarga em pipelines de produção. Também demonstramos um tutorial de observabilidade do LangChain usando o Langfuse.
Benchmark de sobrecarga de ferramentas de monitoramento agêntico
Integramos cada plataforma de observabilidade em nosso sistema de planejamento de viagens multi-agente e executamos 100 consultas idênticas para medir sua sobrecarga de desempenho em comparação com uma linha de base sem instrumentação. Leia nossa metodologia de benchmark.
- LangSmith demonstrou eficiência excepcional com praticamente nenhuma sobrecarga mensurável, tornando-o ideal para ambientes de produção críticos em desempenho.
- Laminar introduziu sobrecarga mínima de 5%, tornando-o altamente adequado para ambientes de produção onde o desempenho é crítico.
- AgentOps e Langfuse mostraram sobrecarga moderada de 12% e 15% respectivamente, representando um equilíbrio razoável entre recursos de observabilidade e impacto no desempenho. Essas plataformas ainda mantêm latência aceitável para a maioria dos casos de uso em produção.
Possíveis razões por trás das diferenças de desempenho
Nosso benchmark indica que as diferenças de latência são impulsionadas pela profundidade da instrumentação e pelo envolvimento no caminho de execução, particularmente em workflows multi-agente. Ferramentas que oferecem observabilidade mais profunda em nível de etapa exibiram maior sobrecarga, enquanto abordagens de tracing mais leves permaneceram mais próximas da linha de base.
1. Profundidade da instrumentação no caminho de execução
As ferramentas de observabilidade adicionam lógica ao fluxo de execução do agente para capturar traces e metadados. Quando essa lógica é executada de forma síncrona durante o tratamento de solicitações, ela aumenta diretamente a latência de ponta a ponta, porque o agente deve concluir esse trabalho extra antes de retornar uma resposta.
Por exemplo:
- O LangSmith adicionou praticamente nenhuma sobrecarga mensurável (~0%), indicando pouco trabalho síncrono,
- A instrumentação mais profunda em nível de etapa do Langfuse contribuiu para uma sobrecarga maior (~15%).
2. Amplificação de eventos em pipelines de múltiplas etapas
Em sistemas multi-agente, uma única solicitação do usuário dispara múltiplas ações do agente. Quando uma ferramenta registra dados detalhados em cada etapa, o número total de eventos cresce rapidamente, aumentando a sobrecarga de processamento e tratamento de traces à medida que o workflow se torna mais profundo.
Nos resultados do benchmark:
- O Langfuse e o AgentOps geraram sobrecarga notavelmente maior (15% e 12%) em nosso workflow de planejamento de viagens de múltiplas etapas
- O LangSmith e o Laminar emitiram menos eventos por etapa do agente.
3. Sobrecarga de avaliação e validação inline
Algumas plataformas realizam verificações ou monitoramento adicionais enquanto o agente está em execução. Embora cada verificação seja leve, aplicá-las repetidamente em todas as etapas do agente adiciona latência mensurável.
Por exemplo:
- O monitoramento em nível de ciclo de vida do AgentOps coincidiu com uma sobrecarga de 12%
- O Laminar não mostrou evidências de avaliação inline afetando a execução, permanecendo em ~5%.
4. Frequência de serialização e persistência
Capturar dados detalhados de observabilidade requer serializar traces e gravá-los em armazenamento ou backends externos. Quanto maior o detalhe do trace, mais frequentemente isso acontece, adicionando sobrecarga de I/O a cada solicitação.
Em nosso benchmark:
- O tracing detalhado de prompts, outputs e tokens do Langfuse resultou na maior sobrecarga (~15%)
- Os artefatos de trace mais leves do LangSmith permaneceram próximos da linha de base.
5. Grau de integração com o framework de agente
O quão estreitamente uma ferramenta se integra ao framework de agente afeta o desempenho. Integrações mais estreitas reduzem as etapas de tradução e orquestração, enquanto SDKs mais genéricos adicionam camadas extras de processamento.
Por exemplo:
- O alinhamento estreito do LangSmith com a execução do agente correlacionou-se com ~0% de sobrecarga
- O AgentOps e o Langfuse mostraram maior impacto na latência, consistente com caminhos de integração mais desacoplados.
Plataformas de observabilidade de agentes de IA
Nível 1: Observabilidade detalhada de LLM e prompt / output
* As capacidades listadas nestas colunas são exemplos ilustrativos do que cada ferramenta pode monitorar quando estendida por meio de integrações ou personalizações. Estas não são exclusivas de uma única plataforma.
Nível 2: Observabilidade de workflow, modelo e avaliação
Nível 3: Observabilidade de ciclo de vida e operações do agente
Nível 4: Monitoramento de sistema e infraestrutura (não nativo para agentes)
O Datadog (com seu módulo de Observabilidade de LLM) e o Prometheus (via exportadores) são cada vez mais usados juntamente com o Langfuse/LangSmith.
Plataformas de desenvolvimento e orquestração de agentes:
- Ferramentas como Flowise, Langflow, SuperAGI e CrewAI permitem construir, orquestrar e otimizar workflows de agentes com interfaces no-code/low-code
Edições gratuitas de implantação e preços
As edições gratuitas variam conforme os limites de uso (ex.: observações, traces, tokens ou unidades de trabalho). Os preços iniciais são tipicamente para um plano básico, que pode ter restrições de recursos, usuários ou limites de uso.
Weights & Biases (W&B Weave)
Caso de uso: Depurar falhas em sistemas multi-agente rastreando como os erros se propagam entre as chamadas de agente.
O Weights & Biases Weave registra traces de execução estruturados para sistemas multi-agente, preservando relacionamentos pai-filho entre as chamadas de agente. Inputs, outputs, estados intermediários, latência e uso de tokens são capturados por agente e por trace.
Recursos de monitoramento do Weave
- Tracing hierárquico de agentes em vez de logs de solicitação planos
- Atribuição de custo e latência no nível do agente
- Suporte nativo para scorers de avaliação aplicados diretamente aos traces.
Capacidades de avaliação
O Weave também fornece scorers integrados para avaliação, incluindo:
- HallucinationFreeScorer para detectar alucinações,
- SummarizationScorer para avaliar a qualidade do resumo,
- EmbeddingSimilarityScorer para similaridade semântica,
- ValidJSONScorer e ValidXMLScorer para validação de formato,
- PydanticScorer para conformidade de esquema,
- OpenAIModerationScorer para segurança de conteúdo,
- Scorers RAGAS como ContextEntityRecallScorer,
- ContextRelevancyScorer para avaliação de sistemas RAG.
Mais adequado para: Equipes que executam workflows multi-agente ou de múltiplas etapas que precisam de análise de causa raiz em nível de trace em vez de métricas superficiais.
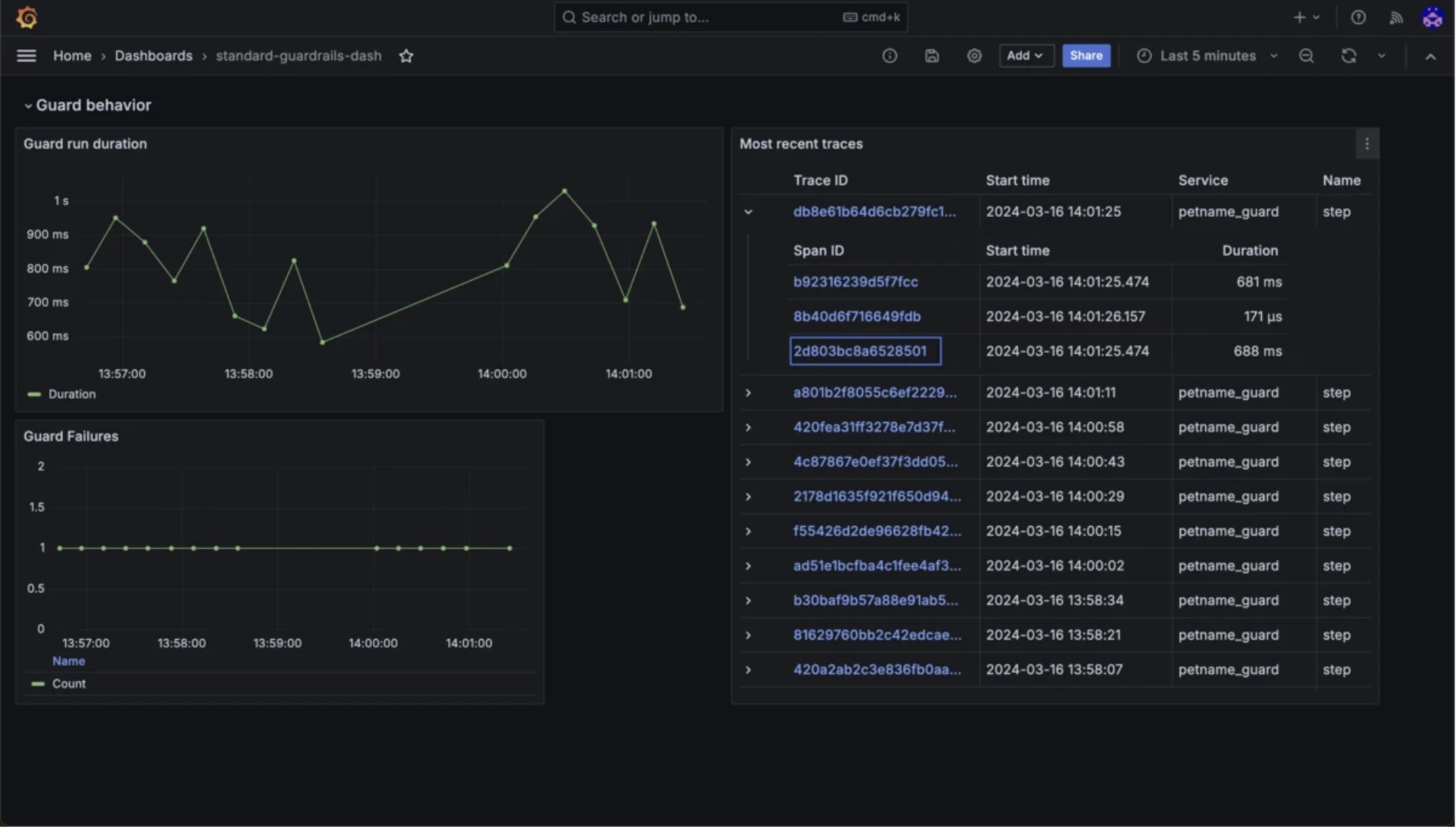
Langfuse
Casos de uso: Rastrear interações de LLM, gerenciar versões de prompts e monitorar o desempenho do modelo com sessões de usuário.
O Langfuse oferece visibilidade profunda na camada de prompts, capturando prompts, respostas, custos e traces de execução para ajudar a depurar, monitorar e otimizar aplicações de LLM.
No entanto, o Langfuse pode não ser adequado para equipes que preferem workflows baseados em Git para gerenciamento de código e prompts, pois seu sistema externo de gerenciamento de prompts pode não oferecer o mesmo nível de controle de versão e colaboração.
Recursos de monitoramento do Langfuse
- Visibilidade sobre a evolução dos prompts e padrões de uso
- Análise baseada em sessões adequada para aplicações voltadas ao usuário
- Modelo prático de metadados e marcação para filtragem e revisão
Recursos de nível empresarial:
Alguns desses recursos incluem:
- Níveis de log: Ajustar a verbosidade dos logs para insights mais granulares.
- Multimodalidade: Suporta texto, imagens, áudio e outros formatos para aplicações multimodais de LLM.
- Releases e versionamento: Rastrear o histórico de versões e ver como novas releases afetam o desempenho do modelo.
- URLs de trace: Acessar traces detalhados via URLs exclusivas para inspeção e depuração adicionais.
- Grafos de agentes: Visualizar interações e dependências do agente para uma melhor compreensão do comportamento do agente.
- Amostragem: Coletar dados representativos das interações para analisar sem sobrecarregar o sistema.
- Rastreamento de tokens e custos: Rastrear o uso de tokens e custos para cada chamada de modelo, garantindo gerenciamento eficiente de recursos.
- Mascaramento: Proteger dados sensíveis mascarando-os nos traces, garantindo privacidade e conformidade.
Mais adequado para: Equipes que iteram em prompts e monitoram o uso em produção, especialmente onde as sessões de usuário são importantes.
Galileo
Casos de uso: Monitorar custo/latência, avaliar a qualidade do output, bloquear respostas inseguras e fornecer correções acionáveis.
O Galileo rastreia métricas de custo, latência e qualidade de output enquanto aplica verificações de segurança e conformidade em tempo real.
A plataforma combina observabilidade tradicional (latência, custo, desempenho) com depuração e avaliação alimentadas por IA (detecção de alucinações, correção factual, coerência, aderência ao contexto).
Recursos de monitoramento do Galileo
- Identificação de modos de falha além de erros superficiais (ex.: alucinações que levam a inputs de ferramenta inválidos)
- Feedback prescritivo, como alterações de prompt sugeridas ou adições de few-shot
- Acoplamento estreito entre resultados de avaliação e correções recomendadas.
Mais adequado para: Organizações que priorizam qualidade de output, segurança e ciclos rápidos de iteração com remediação guiada.
Guardrails IA
Casos de uso: Prevenir outputs prejudiciais, validar respostas de LLM e garantir conformidade com políticas de segurança
O Guardrails valida inputs e outputs de LLM contra regras configuráveis, incluindo toxicidade, viés, exposição de PII, sinalização de alucinações e conformidade de formato.
Recursos de monitoramento do Guardrails IA
- Validação determinística via especificações RAIL
- Guardas de input para detecção de injeção de prompt e jailbreak
- Tentativas automáticas quando a validação falha.
Mais adequado para
Equipes que devem impor garantias rigorosas de segurança, conformidade ou formatação antes que as respostas sejam retornadas.
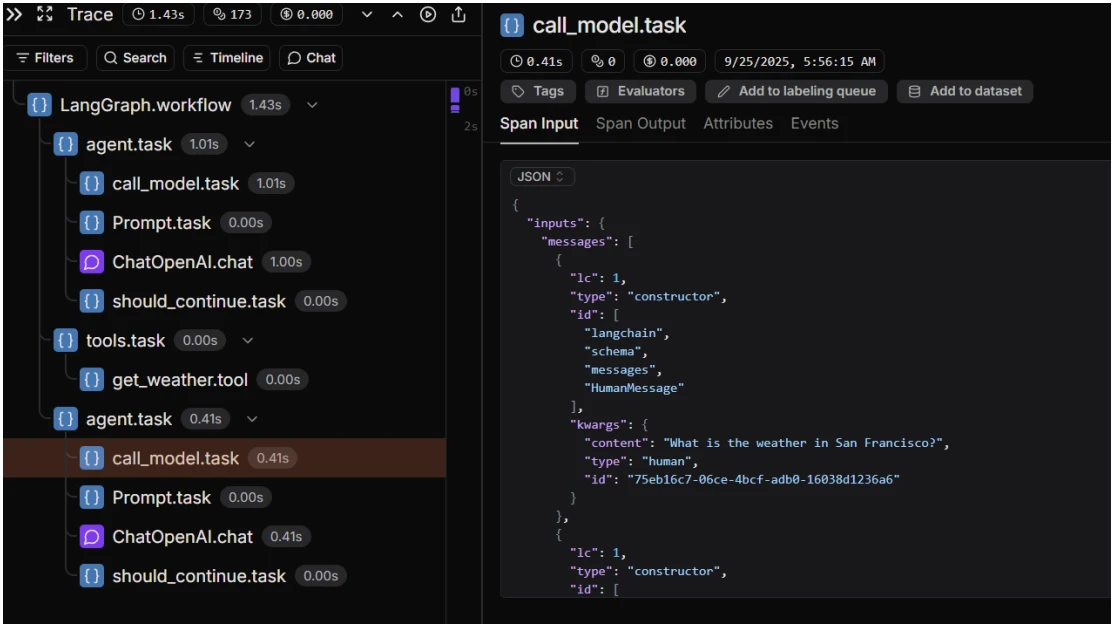
LangSmith
Casos de uso: Depuração de raciocínio do agente e chamadas de ferramentas (centrado no LangChain)
O LangSmith captura traces completos de raciocínio para agentes baseados no LangChain, incluindo prompts, contexto recuperado, lógica de seleção de ferramentas, inputs/outputs de ferramentas, erros e exceções.
Recursos de monitoramento do LangSmith
- Inspeção passo a passo dos caminhos de decisão do agente
- Repetição de execução e comparação lado a lado entre prompts, modelos ou ferramentas
- Integração estreita com o LangChain via callbacks.
Mais adequado para
Equipes que constroem com LangChain e precisam depurar raciocínio incorreto ou invocação de ferramentas em detalhes.
Langtrace IA
Casos de uso: Identificar gargalos de custo e latência em aplicações de LLM
O Langtrace rastreia contagens de tokens, duração da execução, custos de API e parâmetros de solicitação em pipelines de LLM usando traces compatíveis com OpenTelemetry.
Recursos de monitoramento do Langtrace IA
- Alinhamento com OpenTelemetry para integração com backends existentes
- Visibilidade sobre os fatores de custo e latência por etapa
- Versionamento leve de prompts e ambiente de teste.
Mais adequado para: Equipes que otimizam desempenho e gastos em workflows de LLM em vez de avaliar a qualidade do output.
Arize (Phoenix)
Casos de uso: Monitorar drift de modelo, detectar viés e avaliar outputs de LLM com sistemas abrangentes de pontuação
O Phoenix foca em drift comportamental, detecção de viés e pontuação de LLM-como-juiz para relevância, toxicidade e precisão.
No entanto, ele tem maior sobrecarga de integração em comparação com proxies leves e não gerencia o versionamento de prompts tão bem quanto ferramentas dedicadas.
Recursos de monitoramento do Phoenix
- Núcleo open-source com extensões empresariais opcionais
- Ambiente interativo de teste de prompts para desenvolvimento
- Detecção de drift para rastrear mudanças comportamentais ao longo do tempo
- Verificações de viés para identificar vieses de resposta,
- Pontuação de LLM-como-juiz para precisão, toxicidade e relevância.
Mais adequado para: Equipes que monitoram o comportamento do modelo a longo prazo e o risco de regressão em vez de iteração de prompts.
Agenta
Casos de uso: Descobrir qual prompt funciona melhor em qual modelo
O Agenta compara respostas de modelos em termos de custo, latência e qualidade de output usando inputs compartilhados e contexto controlado.
Recursos de monitoramento do Agenta
- Avaliação lado a lado de modelos
- Suporte à decisão pré-produção.
Mais adequado para: Avaliação em estágio inicial e seleção de modelos.
AgentOps.ai
Casos de uso: Monitorar o raciocínio do agente, rastrear custos e depurar sessões em produção
O AgentOps captura traces de raciocínio, chamadas de ferramentas/API, estado da sessão, comportamento de cache e métricas de custo para agentes implantados.
Recursos de monitoramento do AgentOps
- Replay de sessão para depuração em produção
- Foco no comportamento do agente ao vivo em vez de avaliação offline.
Mais adequado para: Equipes que executam agentes em produção e precisam de visibilidade operacional.
Braintrust
Casos de uso: Descobrir qual prompt, dataset ou modelo tem melhor desempenho com avaliação detalhada e análise de erros
O Braintrust avalia prompts, datasets e modelos em relação a outputs esperados, rastreando latência, custo, erros de ferramentas e métricas de execução.
Recursos de monitoramento do Braintrust
- Avaliar datasets de teste com inputs e outputs esperados e, em seguida, comparar prompts ou modelos lado a lado usando variáveis como
{{input}},{{expected}}e{{metadata}}. - Discriminações de métricas incluindo qualidade de execução de ferramentas
Mais adequado para: Equipes que fazem benchmark de modelos e prompts antes da implantação.
AgentNeo
Casos de uso: Depurar interações multi-agente, rastrear o uso de ferramentas e avaliar workflows de coordenação
O AgentNeo rastreia comunicação entre agentes, uso de ferramentas, grafos de execução e custo e latência por agente via um SDK Python.
Recursos de monitoramento do AgentNeo
- Open-source e executável localmente
- Dashboard local interativo (
localhost:3000) para monitoramento em tempo real de workflows multi-agente. - Integração usando decoradores (ex.:
@tracer.trace_agent,@tracer.trace_tool)
Mais adequado para: Equipes de engenharia que experimentam sistemas multi-agente.
Laminar
Caso de uso: Rastrear o desempenho em diferentes frameworks e modelos de LLM.
O Laminar rastreia spans de execução, custos, uso de tokens e percentis de latência em frameworks e modelos de LLM.
Recursos de monitoramento do Laminar
- Análise de desempenho independente de framework
- Inspeção granular de spans.
Mais adequado para: Análise comparativa de desempenho em stacks heterogêneas.
Helicone
Casos de uso: Rastrear workflows de agentes de múltiplas etapas e analisar padrões de sessão de usuário.
O Helicone captura volumes de solicitações, custos, erros, tendências de latência e workflows de agentes em nível de sessão.
Recursos de monitoramento do Helicone
- Visibilidade da jornada do usuário
- Análise de tendências históricas.
Mais adequado para: Equipes de produto que monitoram padrões de uso e comportamento em nível de usuário.
Coval
Casos de uso: Simular milhares de conversas de agente, testar interações de voz/chat e validar o comportamento antes da implantação.
O Coval simula milhares de conversas para medir a conclusão de tarefas, correção e eficácia das chamadas de ferramentas.
Recursos de monitoramento do Coval
- Teste de agente baseado em simulação
- Detecção automática de regressão
- Suporte a agentes de voz e texto.
Mais adequado para: Validação pré-implantação e detecção de regressão.
Datadog
Casos de uso: Observabilidade de infraestrutura e aplicação com correlação de sinais de LLM.
O Datadog coleta métricas de infraestrutura (CPU, memória, rede), dados de desempenho de aplicação (latência, taxas de erro, throughput) e logs. Para aplicações de LLM, ele pode ingerir uso de tokens, custo por solicitação, latência do modelo e sinais relacionados à segurança, como tentativas de injeção de prompt.
Recursos de monitoramento do Datadog
- Observabilidade ampla em todo o sistema, abrangendo infraestrutura, aplicações e cargas de trabalho de IA
- Grande ecossistema de integração (900+ integrações) permitindo correlação entre o comportamento de IA e a saúde da infraestrutura
Mais adequado para: Organizações que desejam correlacionar o comportamento de LLM com a infraestrutura subjacente e o desempenho da aplicação em vez de inspecionar o raciocínio do agente ou prompts
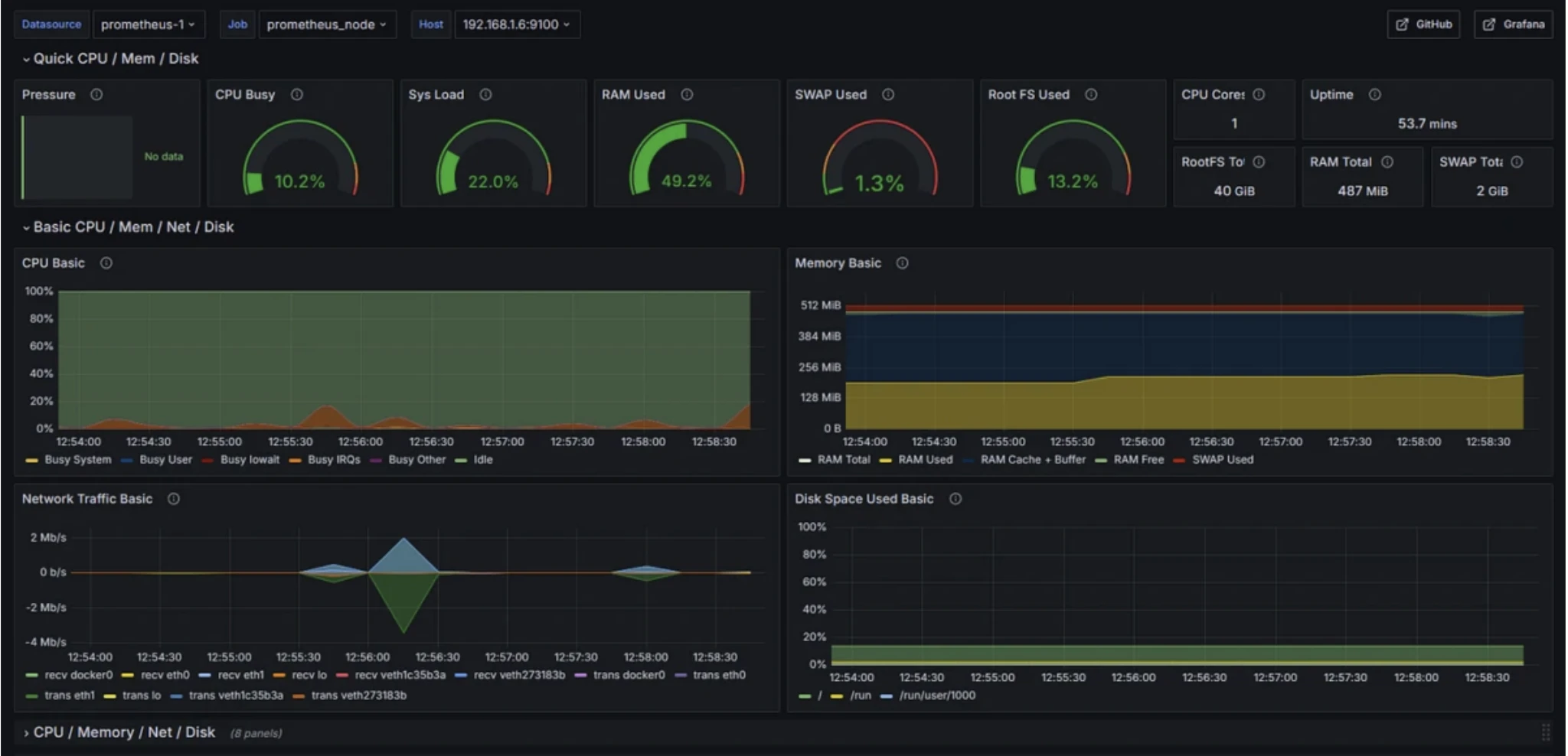
Prometheus
Casos de uso: Monitorar o desempenho do sistema, rastrear métricas de aplicação e configurar alertas para problemas de infraestrutura.
O Prometheus é um sistema de monitoramento open-source que coleta métricas de séries temporais de endpoints HTTP em intervalos regulares para rastrear métricas de infraestrutura, aplicação, banco de dados, contêineres e negócios personalizadas.
Recursos de monitoramento do Prometheus
- Coleta de métricas de séries temporais via scraping baseado em pull
- PromQL para consulta, agregação e condições de alerta
- Ecossistema de exportadores (ex.: Node Exporter) para ampla cobertura do sistema
Mais adequado para: Monitoramento de infraestrutura e aplicação com alertas baseados em regras.
Grafana
Casos de uso: Visualizar métricas, construir dashboards e rotear alertas entre dados de LLM, agente e infraestrutura.
O Grafana é uma plataforma de visualização e análise open-source que se integra com fontes de dados como Prometheus, OpenTelemetry e Datadog para fornecer dashboards de observabilidade unificados.
Recursos de monitoramento do Grafana
- Dashboards abrangendo métricas, logs e traces
- Correlação entre sistemas para sinais de LLM, agente e infraestrutura
- Roteamento de alertas e gerenciamento de notificações.
Mais adequado para: Visualização centralizada de observabilidade e resposta a incidentes.
Tutorial: Observabilidade do LangChain com Langfuse
Construímos um pipeline de múltiplas etapas com LangChain com três estágios:
- análise de perguntas
- geração de respostas
- verificação de respostas
Após configurar o pipeline, nós o conectamos ao Langfuse para monitorar e rastrear a execução em tempo real. Ao fazer isso, pudemos explorar como o Langfuse nos ajuda a obter insights detalhados sobre o desempenho, custos e comportamento da aplicação de IA.
Aqui está o que observamos através do Langfuse:
Visão geral do dashboard
O Langfuse nos forneceu vários dashboards que nos dão visibilidade sobre diferentes aspectos do desempenho do pipeline:
- Dashboard de Custos: Rastreia os gastos em todas as chamadas de API, com detalhamentos por modelo e período de tempo.
- Gerenciamento de Uso: Monitora métricas de execução, como contagens de observações e alocação de recursos, ajudando-nos a rastrear como os recursos são usados durante a execução.
- Dashboard de Latência: Este dashboard nos ajudou a analisar os tempos de resposta, detectar gargalos e visualizar tendências de desempenho.
Métricas de uso
O dashboard de métricas de uso nos deu os seguintes insights sobre como o sistema se comportou:
- Contagem total de traces: Rastreamos oito traces, cada um representando um ciclo completo de pergunta-resposta no pipeline.
- Contagem total de observações: Em média, cada trace teve 16 observações, refletindo a natureza de múltiplas etapas do processo.
Além disso, o Langfuse nos permite rastrear padrões de uso, alocação de recursos e horários de pico nos últimos 7 dias, ajudando-nos a entender quando o sistema está mais ativo e como os recursos são distribuídos ao longo do tempo.
Inspeção de traces
Ao detalhar um trace individual, pudemos ver informações detalhadas de execução:
- Linhas de trace: Cada linha representa uma execução completa do pipeline com um ID de trace exclusivo.
- Métricas de latência: O tempo de execução variou, variando de 0,00s a 34,08s.
- Contagens de tokens: O dashboard rastreou o uso de tokens de input/output, o que ajuda no gerenciamento de custos e eficiência.
- Filtragem por ambiente: Pudemos filtrar traces com base nos ambientes de implantação (ex.: desenvolvimento, produção).
Detalhes individuais do trace
Exploramos ainda mais o trace em detalhes para entender o detalhamento da execução:
- Arquitetura de cadeia sequencial: O trace exibiu um fluxo visual mostrando cada etapa, começando de SequentialChain → LLMChain → ChatOpenAI, com estrutura hierárquica.
- Rastreamento de input/output: A pergunta original, "Quais são os benefícios de usar o Langfuse para observabilidade de agentes de IA?" foi rastreada em cada estágio, juntamente com os respectivos outputs produzidos pela IA em cada etapa.
- Análise de tokens: Observamos que 1.203 tokens foram usados para input e 1.516 tokens para output, o que tem implicações de custo relacionadas ao uso de tokens e ajuda a otimizar o gerenciamento de recursos.
- Dados de temporização: A latência total para o trace completo foi de 34,08s, dividida em cada componente:
- SequentialChain → 14,02s
- LLMChain → 10,25s
- ChatOpenAI → 9,81s
- Informações do modelo: O Langfuse confirmou o uso do modelo Anthropic Claude-Sonnet-4, com detalhes sobre as configurações específicas, incluindo a configuração de temperatura.
- Output formatado: As visualizações Preview e JSON foram fornecidas para depuração, oferecendo insights sobre a resposta do modelo em formato legível por humanos e em formato legível por máquina.
Análise automatizada
O Langfuse também forneceu avaliações automatizadas de nossas respostas:
- Avaliação de qualidade: O sistema avaliou a estrutura, coerência e completude das respostas, destacando seções bem organizadas, mas sugerindo que as respostas poderiam ser mais concisas.
- Sugestões de melhoria: Identificou seções com redundância, sugerindo onde a redação poderia ser melhorada e combinou pontos relacionados para tornar a resposta mais transparente e mais eficiente.
- Insights de desempenho: O sistema deu feedback sobre o uso de tokens e relevância da resposta, ajudando-nos a otimizar a eficiência, garantindo que o output permaneça útil e dentro do tópico.
- Feedback estruturado: O feedback foi organizado em categorias, permitindo-nos abordar áreas específicas para melhoria de forma direcionada.
Análises de usuário
O Langfuse rastreia interações detalhadas entre usuários e o agente de IA:
- Linha do tempo de atividade do usuário: Exibe a primeira e a última interação de cada usuário, ajudando a identificar usuários ativos versus inativos. Podemos ver quando os usuários interagiram com o sistema pela primeira e última vez.
- Rastreamento de volume de eventos: Rastreia o número de eventos que cada usuário disparou. Por exemplo, alguns usuários geraram mais de 2.000 eventos, mostrando seu nível de engajamento com o sistema.
- Análise de consumo de tokens: Monitora o número total de tokens consumidos por cada usuário. O uso de tokens variou de 6,59K a 357K tokens, fornecendo insights sobre o uso de recursos.
- Atribuição de custos: Detalha os custos associados a cada usuário, facilitando o rastreamento de gastos e a otimização da alocação de orçamento para uso de recursos.
- Identificação do usuário: Usa IDs de usuário anonimizados para manter a privacidade enquanto rastreia interações individuais do usuário, ajudando na análise de uso sem comprometer a confidencialidade do usuário.
A visualização de sessão nos permite rastrear detalhes granulares das interações do usuário:
- Fluxo completo da conversa: Mostra a interação completa de pergunta-resposta, facilitando o acompanhamento de toda a conversa do início ao fim.
- Visibilidade da implementação: Exibe o código Python real usado durante a sessão, fornecendo insights sobre a implementação técnica.
- Correlação de input/output: Vincula as perguntas do usuário às respostas correspondentes do sistema, ajudando-nos a solucionar problemas e identificar onde podem ter ocorrido problemas na conversa.
- Metadados da sessão: Inclui detalhes técnicos como temporização, contexto do usuário e dados específicos de implementação, oferecendo uma visão abrangente da execução da sessão.
Quando não usar ferramentas de observabilidade
- Desenvolvimento em estágio inicial: Se você ainda está validando o product-market fit ou construindo seus primeiros workflows de agente, o foco deve estar na funcionalidade principal e não em observabilidade extensiva.
- Gargalos de API: Se seus principais problemas são custos de API, latência ou cache, a prioridade imediata deve ser otimizar essas áreas, não rastrear métricas em nível de sistema.
- Otimização de modelo: Se as melhorias são impulsionadas principalmente pela seleção de modelo, fine-tuning ou engenharia de prompts, as ferramentas de observabilidade para drift e viés podem ainda não ser necessárias.
Quando usar ferramentas de observabilidade
- Produção em escala: Quando você está operando com vários modelos, agentes ou cadeias, as ferramentas de observabilidade são essenciais para monitorar o desempenho e garantir a saúde do sistema.
- Aplicações empresariais ou voltadas ao cliente: Para aplicações onde confiabilidade, segurança e conformidade são inegociáveis, as ferramentas de observabilidade fornecem a visibilidade e o controle necessários.
- Monitoramento contínuo: Quando você precisa monitorar drift, viés, desempenho e problemas de segurança ao longo do tempo, que não podem ser facilmente capturados com scripts básicos ou verificações manuais, as ferramentas de observabilidade são cruciais.
- Cenários de alto risco: Em ambientes onde o custo da falha (ex.: alucinações, outputs inseguros) é significativo, a observabilidade garante que os riscos sejam minimizados e os problemas sejam detectados precocemente.
Metodologia do benchmark
Para avaliar a sobrecarga de desempenho das plataformas de observabilidade em aplicações de LLM em produção, desenvolvemos uma abordagem sistemática de benchmarking usando um workflow agêntico do mundo real.
Aplicação de teste
Construímos um sistema de planejamento de viagens multi-agente sequencial usando LangChain que processa solicitações de viagem em linguagem natural através de cinco estágios:
- Agente analisador: Extrai dados estruturados (origem, destino, datas, duração) do input do usuário
- Agente de busca de voos: Recupera voos disponíveis via API da Amadeus
- Agente de previsão do tempo: Obtém previsões do tempo do destino usando a WeatherAPI
- Agente recomendador de atividades: Sugere atividades com base nas condições climáticas
- Agente planejador de viagem: Sintetiza todos os outputs em um itinerário abrangente
O sistema usa Claude 4 Haiku via OpenRouter para todas as chamadas de LLM e integra APIs externas para dados em tempo real.
Design do benchmark
Estabelecimento da linha de base: Primeiro medimos o desempenho da aplicação sem qualquer instrumentação de observabilidade, executando 100 consultas idênticas para estabelecer uma linha de base para comparação.
Integração da plataforma: Em seguida, integramos cinco plataformas líderes de observabilidade (LangSmith, Laminar, AgentOps, Langfuse) uma de cada vez, instrumentando os mesmos pontos de tracing em todas as plataformas para consistência.
Execução sequencial: Cada plataforma foi testada independentemente, executando todas as 100 consultas consecutivamente antes de passar para a próxima plataforma. Essa abordagem minimiza a variabilidade de fatores externos, como condições de rede ou limites de taxa de API.
Ambiente controlado: Todos os testes foram executados na mesma infraestrutura de servidor com conjuntos de consultas idênticos para garantir uma comparação justa. Para isolar a sobrecarga das variações de latência induzidas pelo LLM, configuramos o modelo com temperature=0 e prompts estruturados para minimizar a variabilidade de resposta entre as execuções.
Métricas coletadas
Para cada plataforma, medimos a latência média e calculamos a sobrecarga como a latência adicional introduzida em comparação com a linha de base: ((Platform Latency - Base Latency) / Base Latency) × 100
Perguntas frequentes
Observabilidade é a capacidade de entender o funcionamento interno de um agente de IA examinando sinais externos, como logs, métricas e traces.
Para agentes de IA, isso envolve monitorar ações, uso de ferramentas, interações com modelos e respostas para solucionar problemas e melhorar o desempenho.
A observabilidade de agentes é crucial para rastrear e melhorar o desempenho da IA, permitindo:
Compreender trade-offs: Ajuda a medir métricas-chave como precisão e custo, facilitando o equilíbrio entre desempenho e uso de recursos.
Medir latência: O rastreamento de latência em tempo real oferece insights sobre os tempos de resposta, ajudando a otimizar o desempenho do agente.
Detectar inputs maliciosos: A observabilidade ajuda a identificar linguagem prejudicial e injeções de prompt, permitindo intervenção imediata para evitar problemas.
Monitoramento de feedback do usuário: Ao observar as interações e o feedback do usuário, a observabilidade fornece dados valiosos para melhoria contínua e fine-tuning de agentes.
Os componentes-chave incluem:
– Rastreamento de ações: Monitorar cada etapa realizada pelo agente.
– Uso de ferramentas: Observar as ferramentas e recursos que o agente utiliza.
– Medição de latência: Monitorar os tempos de resposta para otimizar o desempenho.
– Avaliações: Avaliar o comportamento do agente e o desempenho do modelo.
– Detecção de inputs maliciosos: Identificar prompts ou ataques prejudiciais.
Cite esta pesquisa
Escolha o formato adequado ao local onde você vai publicar. Colar a versão com link no seu CMS preserva o backlink.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{15 Ferramentas de Observabilidade de Agentes de IA: AgentOps & Langfuse}},
year = {2026},
month = jul,
howpublished = {\url{https://aimultiple.com/agentic-monitoring}},
note = {AIMultiple. Acessado em 2 Julho 2026}
}














.")





Seja o primeiro a comentar
Seu endereço de e-mail não será publicado. Todos os campos são obrigatórios. Os comentários são deixados em seu idioma original.