Benchmark de Ferramentas de Revisão de Código com IA
Com o aumento do uso de ferramentas de codificação com IA, as bases de código tornaram-se mais propensas a vulnerabilidades, o que aumentou a necessidade de revisões de código eficazes. Para resolver isto, apresentamos o RevEval (Avaliação de Revisão de Código com IA), que faz benchmark das quatro principais ferramentas de revisão de código com IA em 309 pull requests de repositórios de tamanhos variados e avalia o seu desempenho usando a contribuição de 10 programadores e um LLM-como-juiz.
Resultados do Benchmark
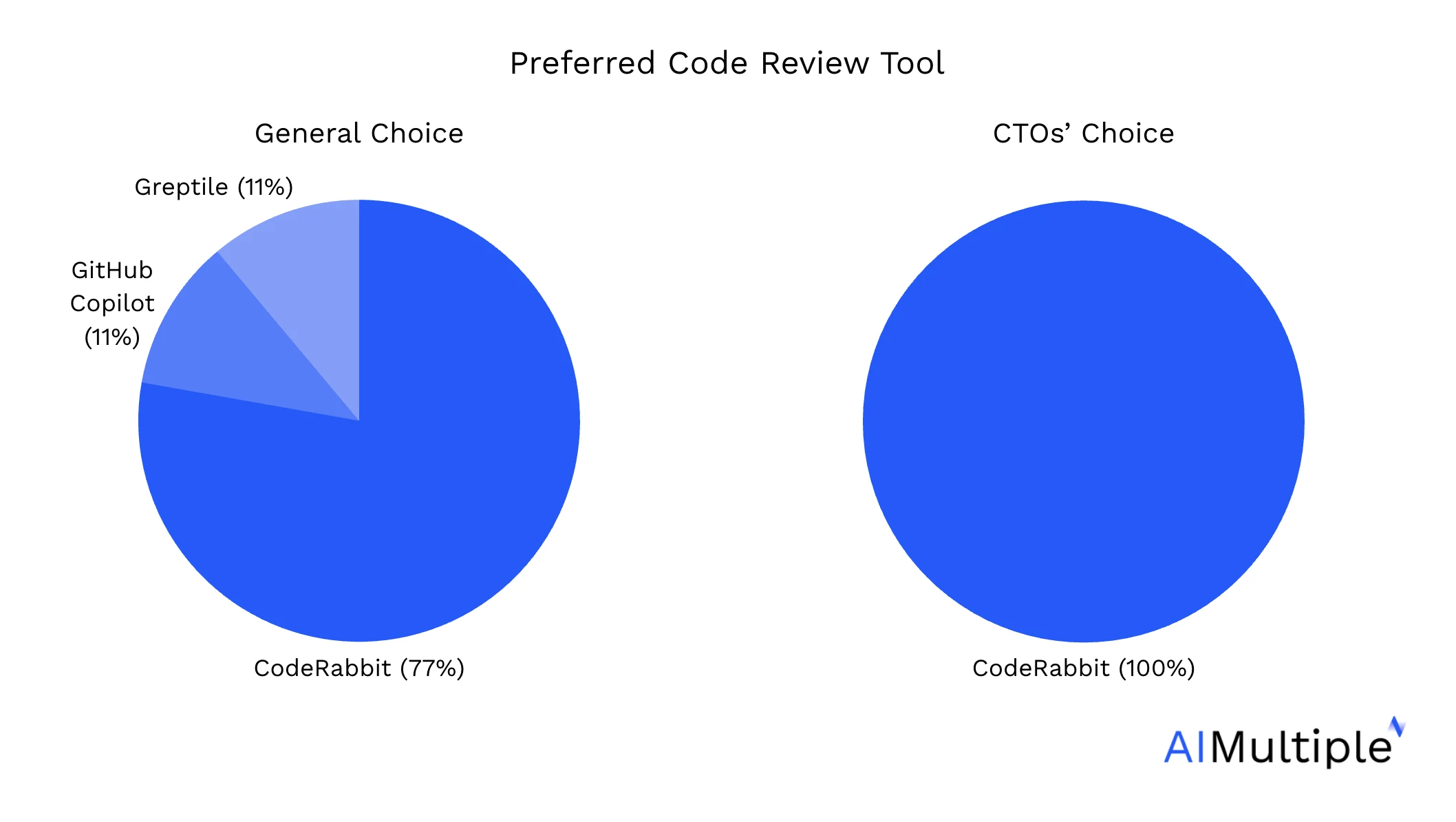
O CodeRabbit classificou-se como a ferramenta de revisão de código mais bem-sucedida em 51% dos 309 PRs:
Para medir a classificação, usámos as pontuações do LLM-como-juiz. Examinámos qual a ferramenta de revisão de código com IA que alcançou a pontuação mais alta em cada PR (pontuado usando o nosso LLM-como-juiz) e, em seguida, calculámos a percentagem de todos os PRs em que cada ferramenta ficou em primeiro lugar.
O CodeRabbit obteve a pontuação mais alta tanto nas avaliações humanas manuais como nas avaliações do LLM-como-juiz, seguido pelo Greptile e pelo GitHub Copilot:
Ao calcular a pontuação média, todas as três categorias de avaliação foram ponderadas igualmente. As pontuações de repositórios grandes e de repositórios pequenos foram avaliadas pelo LLM-como-juiz, e as avaliações dos programadores foram concluídas manualmente para verificar novamente as pontuações do LLM-como-juiz.
Avaliações humanas
Perguntámos aos programadores que participaram nas avaliações qual a ferramenta de revisão de código com IA que prefeririam integrar nos seus fluxos de trabalho. Uma vez que os CTOs desempenham um papel fundamental na tomada de decisões no desenvolvimento de software, destacámos as suas respostas num gráfico separado:
Comparação detalhada
Calculámos o número médio de bugs por PR contando todos os bugs/problemas relatados por cada ferramenta de revisão de código e dividindo pelo número total de PRs (309). Nem todos os PRs na nossa base de código contêm bugs ou problemas. O GitHub Copilot não relata explicitamente quando deteta um bug num PR; portanto, foi excluído desta comparação.
Pode ver a nossa metodologia abaixo.
Funcionalidades
* É fornecido pela funcionalidade "verificações pré-merge agênticas" do CodeRabbit. Valida automaticamente os pull requests em relação aos padrões de qualidade e requisitos organizacionais personalizados antes da fusão e devolve resultados de aprovação/reprovação com explicações diretamente no walkthrough do PR. Cada verificação pode ser configurada para alertar os programadores ou bloquear totalmente as fusões. Embora o GitHub Copilot, o Cursor BugBot e o Greptile forneçam funcionalidades de revisão de PR, funcionam como sistemas consultivos que oferecem feedback e sugestões em vez de frameworks de validação sistemática.
** O Cursor e o GitHub Copilot podem oferecer mais capacidades para além dos seus componentes de revisão de código; apenas as funcionalidades do Cursor Bugbot e da Revisão de Código do GitHub Copilot estão incluídas na nossa comparação.
As funcionalidades variam dependendo dos planos de subscrição, pelo que algumas funcionalidades marcadas como disponíveis acima podem não estar disponíveis na sua subscrição.
Nas revisões de código automatizadas, o CodeRabbit, o GitHub Copilot e o Cursor Bugbot foram mais fáceis de configurar do que o Greptile porque as revisões de código automatizadas não podem ser ativadas para um repositório vazio no Greptile.
Análise aprofundada das funcionalidades
CodeRabbit
- 40+ linters e scanners de segurança integrados.
- Instruções personalizadas baseadas em padrões AST.
- Adapta-se ao feedback dos programadores ao longo do tempo.
- Os programadores podem marcar @coderabbitai para fazer perguntas de seguimento, solicitar correções, questionar recomendações.
- Suporta servidores MCP personalizados para contexto adicional.
GitHub Copilot Code Review
- O botão "Implementar sugestão" entrega ao agente de codificação Copilot.
- Integração estreita com o ecossistema GitHub.
- Instruções personalizadas via copilot-instructions.md.
Greptile
- Aprende os padrões de codificação da equipa a partir do histórico de comentários dos PRs.
- Com repositórios de padrões, os programadores podem referenciar repositórios relacionados em greptile.json para que possam fornecer contexto adicional.
- Os programadores podem responder com @greptileai para perguntas de seguimento ou sugestões de correção.
- O Greptile aprende com os feedbacks de gosto/não gosto.
- Diagramas de sequência gerados automaticamente para todos os PRs.
Cursor BugBot
- Depois de um bug ser identificado pelo BugBot, os programadores podem usar o botão "Corrigir no Cursor" para abrir rapidamente o Cursor para corrigir o Bug.
- Os programadores podem personalizar as suas regras de revisão de código em ficheiros BUGBOT.md.
Também tencionávamos fazer benchmark do Graphite; no entanto, devido a um bug no seu painel de controlo, não conseguimos ativar as revisões de código automatizadas para novos repositórios. Contactámos a sua equipa de suporte a 25 de outubro de 2025, mas a resposta não resolveu o problema. Apesar dos e-mails de acompanhamento e de uma mensagem no seu canal do Slack, o problema permaneceu por resolver.
Componentes e integrações
* Todas estas soluções suportam o GitHub.
Metodologia
Criámos repositórios de benchmark separados para cada ferramenta dentro da nossa organização dedicada no GitHub.
Depois de ativar as revisões de código automáticas para cada ferramenta no seu repositório atribuído, abrimos pull requests em sequência, esperámos que a ferramenta concluísse a sua revisão e, em seguida, fechámos os PRs para registar os resultados. Não modificámos nem afinámos nenhuma configuração da ferramenta. Cada ferramenta foi avaliada usando a sua configuração padrão, exatamente como instalada.
O nosso fluxo de trabalho começa por clonar o repositório de origem tal como existia numa data de referência selecionada e, em seguida, repete os pull requests submetidos após essa data, um a um, preservando a estrutura original do repositório.
Usámos as versões de novembro de 2025 de todos os produtos. O nosso benchmark consistiu em 2 gamas diferentes de repositórios de origem:
1. Repositórios bem conhecidos, de tamanho médio a grande
O nosso objetivo era ver até que ponto as ferramentas de revisão de código com IA compreendem repositórios com estruturas grandes e complexas. Tivemos 289 PRs revistos no total em 7 repositórios.
2. Repositórios pequenos e novos
Estamos cientes de que não podemos alimentar o nosso LLM-como-juiz com o
repositório completo nos repositórios grandes, uma vez que as suas janelas de contexto não são suficientes para isso. Portanto, para contornar isto, também avaliámos os primeiros 3 a 5 PRs de repositórios novos e pequenos. Os servidores MCP ajustam-se perfeitamente às nossas necessidades. Consequentemente, escolhemos 8 servidores MCP oficiais e tivemos 20 PRs revistos neles.
O nosso dataset contém código escrito por programadores experientes. Não avaliámos o desempenho em bases de código totalmente geradas por IA.
Avaliações dos Programadores
Selecionámos aleatoriamente 35 PRs e atribuímo-los a 10 programadores, sendo cada PR avaliado 5 vezes por programadores. O nosso objetivo ao repetir a avaliação era minimizar o viés dos programadores. Os programadores avaliaram os resultados de forma agnóstica em relação ao fornecedor.
A maioria deles chegou às mesmas conclusões de alto nível:
- As revisões detalhadas do CodeRabbit são úteis, e ele é bem-sucedido na deteção de bugs.
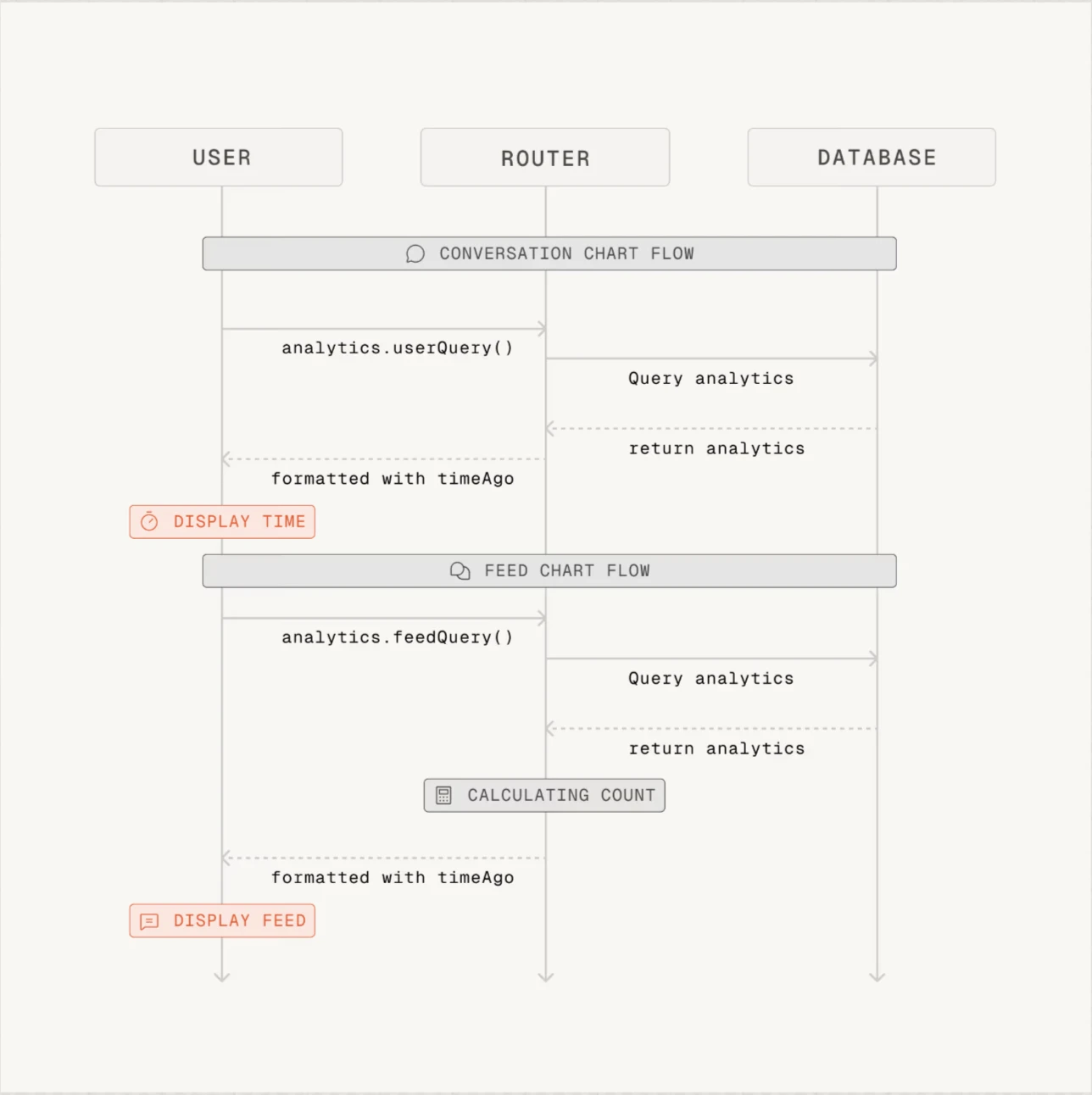
- O Greptile forneceu resumos bem-sucedidos, mas os diagramas de sequência que gerou não são necessários para alguns PRs.
Figura 1: Exemplo de diagrama de sequência fornecido pelo Greptile. O Greptile gera os diagramas para cada PR.1
- O GitHub Copilot é muito bem-sucedido a encontrar erros de digitação no código e faz sugestões certeiras; a sua análise é mais curta do que as do CodeRabbit e do Greptile.
- O Cursor Bugbot fornece análises menos detalhadas e menos precisas.
Após as avaliações, também afirmaram que começarão a usá-los nos seus próprios repositórios como uma ferramenta de suporte para os programadores.
LLM-como-Juiz
Usámos o GPT-5 para avaliar as revisões. Após a avaliação, usámos o GPT-4o para estruturar a saída em formato JSON.
O nosso fluxo de trabalho de avaliação inclui:
- Para repositórios grandes: O corpo do PR original, diff e comentários/revisões das ferramentas.
- Para repositórios pequenos: Toda a base de código, o corpo do PR original, diff e comentários/revisões das ferramentas.
Aqui está o prompt completo que usámos:
Avalie cada ferramenta nestas dimensões (escala de 1 a 5):
1. Correção
Os problemas identificados são realmente problemas/bugs/correções reais no código?
– 5 (Excelente): Todos os problemas identificados são problemas reais
– 4 (Bom): A maioria dos problemas são reais, pequenas más identificações
– 3 (Aceitável): Mistura de problemas reais e questionáveis
– 2 (Fraco): A maioria dos problemas identificados não são problemas reais
– 1 (Falhou): Não consegue identificar problemas reais, todas as conclusões estão incorretas
2. Completude
Detetou problemas importantes? Quão abrangente é a revisão?
– 5 (Excelente): Deteta todos os problemas críticos e a maioria dos importantes.
– 4 (Bom): Deteta problemas importantes, não deteta alguns menores
– 3 (Aceitável): Deteta alguns problemas importantes, mas tem lacunas notáveis
– 2 (Fraco): Não deteta vários problemas críticos
– 1 (Falhou): Não deteta todos ou quase todos os problemas críticos
3. Acionabilidade
As sugestões são claras e implementáveis? Inclui patches/correções? Se não houver bugs no código, escreva "null" na acionabilidade para todas as ferramentas, não dê nenhuma pontuação a nenhuma ferramenta para esse PR.
– 5 (Excelente): Todas as sugestões incluem patches/correções claros e são diretamente implementáveis
– 4 (Bom): A maioria das sugestões tem orientação clara, algumas incluem patches
– 3 (Aceitável): As sugestões são um tanto claras, mas faltam patches para alguns problemas
– 2 (Fraco): As sugestões são na sua maioria pouco claras ou não implementáveis
– 1 (Falhou): Nenhuma sugestão ou orientação clara fornecida
4. Profundidade
Demonstra compreensão da lógica e do propósito do código?
– 5 (Excelente): Demonstra compreensão profunda da lógica, arquitetura e propósito do código
– 4 (Bom): Mostra boa compreensão com pequenas lacunas
– 3 (Aceitável): Compreensão superficial, perde algum contexto
– 2 (Fraco): Explicações superficiais ou incorretas do comportamento do código
– 1 (Falhou): Nenhuma compreensão da lógica e propósito do código
Formato de Saída
Para cada ferramenta, forneça:
1. Raciocínio detalhado: O que encontrou? Perdeu problemas importantes? Patches incluídos? Compreensão profunda da base de código? Exemplos específicos.
2. Pontuações individuais (1-5 para cada dimensão, usando a escala acima)
Exemplo de Saída
Ferramenta A:
Raciocínio: A Ferramenta A demonstrou excelente correção ao identificar um vazamento de memória real na lógica de pool de conexões na linha 145, fornecendo um patch específico usando um gerenciador de contexto. Também detetou a falta de tratamento de erros no endpoint da API com código acionável. A pontuação de completude reflete que, embora tenha encontrado problemas importantes, não detetou a condição de corrida no manipulador assíncrono que poderia causar problemas de produção. Todos os 4 comentários foram substantivos e diretamente implementáveis. A profundidade foi forte, mostrando compreensão dos padrões de gestão de recursos e propagação de erros na base de código.
Correção: 5
Completude: 4
Acionabilidade: 5
Profundidade: 4
Ferramenta B:
Raciocínio: A Ferramenta B identificou corretamente a vulnerabilidade de validação de entrada na linha 89 e forneceu uma correção clara usando sanitização de parâmetros. No entanto, a completude sofreu significativamente, pois não detetou a vulnerabilidade de segurança crítica no fluxo de autenticação que permite a reutilização de tokens. A acionabilidade foi na sua maioria boa – as sugestões incluíram trechos de código. A profundidade foi aceitável, mas superficial, focando-se em verificações de nível superficial em vez de compreender o modelo de segurança ou as implicações do fluxo de dados.
Correção: 4
Completude: 1
Acionabilidade: 4
Profundidade: 2
Ferramentas a avaliar: CodeRabbit, Cursor Bugbot, Github Copilot, Greptile
Seja objetivo e minucioso. Use exemplos específicos das revisões para apoiar as suas pontuações.
O que é a revisão de código com IA?
A revisão de código com IA é a análise automatizada do código-fonte usando modelos de machine learning, principalmente grandes modelos de linguagem (LLMs), para identificar bugs, ineficiências e potenciais vulnerabilidades. Além de detetar problemas, estes sistemas podem fornecer explicações sensíveis ao contexto, sugerir correções concretas e gerar patches que ajudam os programadores a melhorar a qualidade e a manutenibilidade do código. Muitas ferramentas de revisão de IA também auxiliam na documentação, resumindo as alterações e produzindo comentários ou explicações descritivas para o código recém-adicionado.
Como os modelos de IA podem avaliar o código rapidamente e em escala, aceleram significativamente o processo de revisão e tornam mais fácil detetar problemas precocemente, mantendo padrões de codificação consistentes em projetos grandes ou de ritmo acelerado.
Em ambientes de desenvolvimento modernos assistidos por IA, como o Cursor ou o Claude Code, os programadores podem perder involuntariamente o rasto de como a sua base de código evolui ao fazer "vibe coding" ou ao confiar fortemente em sugestões geradas automaticamente. Isto pode introduzir vulnerabilidades ocultas ou inconsistências lógicas. As ferramentas de revisão de código com IA ajudam a mitigar estes riscos, fornecendo uma camada adicional de análise estruturada e sistemática para validar e melhorar o código gerado por IA.
Benefícios da revisão de código com IA
Eficiência e velocidade
As ferramentas de revisão de código com IA podem analisar o código em tempo real, fornecendo feedback imediato e sinalizando potenciais problemas à medida que os programadores trabalham. São capazes de detetar erros e vulnerabilidades de segurança que os revisores humanos podem ignorar, particularmente em bases de código grandes ou em rápida evolução. Ao automatizar as verificações de rotina, estas ferramentas permitem que os programadores se concentrem em raciocínio de nível superior, resolução de problemas complexos e decisões arquitetónicas.
Melhoria da qualidade do código
As ferramentas de revisão de código com IA ajudam a manter padrões de codificação consistentes em todas as equipas, identificando inconsistências estilísticas e desvios das melhores práticas. Também oferecem feedback detalhado e recomendações sobre uma vasta gama de problemas de codificação, desde pequenas melhorias a bugs significativos. Com o tempo, os programadores podem aprender com este feedback, refinar os seus hábitos de codificação e adotar novas técnicas que fortalecem a qualidade geral do seu trabalho.
Limitações e desafios
Dependência excessiva de ferramentas de IA
Uma preocupação comum com a revisão de código com IA é a dependência excessiva do feedback automatizado. Embora a IA possa ser uma fonte valiosa de conhecimento, não deve ser tratada como um substituto completo para a experiência humana. As revisões automatizadas podem acelerar os fluxos de trabalho, mas os revisores humanos permanecem essenciais para garantir a correção, a consciência do contexto e o alinhamento com os objetivos do projeto. No nosso benchmark, os programadores afirmaram consistentemente que não confiariam cegamente nestas ferramentas. Viam-nas como assistentes que complementam o julgamento humano em vez de o substituir.
Gestão de falsos positivos e falsos negativos
Os falsos positivos ocorrem quando a ferramenta identifica incorretamente um código funcional como problemático, enquanto os falsos negativos ocorrem quando problemas genuínos não são detetados. Na nossa avaliação, a preocupação mais significativa foram os falsos negativos. As ferramentas eram mais propensas a ignorar problemas importantes do que a levantar avisos incorretos. Isto destaca a necessidade de melhoria contínua nos modelos e algoritmos subjacentes.
Para enfrentar estes desafios, as ferramentas de revisão de código com IA devem evoluir através de melhor treino, tratamento de contexto melhorado e capacidades de raciocínio mais precisas.
Melhores práticas para usar revisões de código com IA
Dicas de especialistas
Combine revisões de IA com conhecimentos humanos: Use revisões de código com IA juntamente com revisões humanas para garantir que o código é tecnicamente sólido e está alinhado com os objetivos do projeto.
Personalize as regras para se ajustarem ao seu projeto: Ajuste as regras da ferramenta de IA para corresponder aos padrões de codificação do seu projeto para reduzir alertas desnecessários.
Use o feedback da IA como ferramenta de aprendizagem: Trate as sugestões da IA como uma forma de aprender e melhorar, discutindo-as com a sua equipa para entender porquê e como evitar problemas semelhantes no futuro.
Agradecimentos
Estendemos a nossa sincera gratidão aos programadores que contribuíram com o seu tempo e experiência para realizar as avaliações manuais:
Aziz Durmaz (CTO numa empresa de transporte e logística)
Berk Kalelioğlu (cofundador de um estúdio de desenvolvimento de jogos)
Elif Ece Örnek (engenheira de software num website de viagens)
Haydar Külekçi (consultor numa empresa de tecnologias de pesquisa e IA)
Mehmet Şirin Can (chefe de desenvolvimento na AIMultiple)
Mehmet Korkmaz (CTO numa empresa de media na indústria de e-sports e videojogos)
Murat Orno (ex-CTO numa plataforma de pagamentos regional com mais de 500 funcionários)
Orçun Candan (programador full-stack na AIMultiple)
Yalçın Börlü (engenheiro de software sénior numa empresa de saúde e bem-estar)
Yiğit Dinç (cofundador de uma empresa de legal tech)
Agradecemos também aos programadores e mantenedores dos repositórios de código aberto incluídos no nosso benchmark pelo seu trabalho e valiosas contribuições para a comunidade.
Anonimização das identidades dos programadores originais
Para conduzir o benchmark de forma responsável, anonimizámos todos os nomes e endereços de e-mail dos programadores originais ao replicar os pull requests dos repositórios upstream. Como os repositórios de benchmark são públicos, preservar as informações originais do autor poderia expor involuntariamente dados pessoais e criar o risco de notificar os programadores sempre que um pull request recriado é aberto ou atualizado. Embora o GitHub normalmente não notifique os autores quando os seus commits são replicados num repositório separado, considerámos uma boa prática evitar qualquer possibilidade de notificações indesejadas, problemas de atribuição ou preocupações de privacidade.
A anonimização garante que:
- Os programadores não sejam perturbados por milhares de eventos de PR automatizados.
- As informações pessoais não sejam republicadas num repositório público diferente.
- Os benchmarks permaneçam imparciais, impedindo que as ferramentas ou juízes LLM sejam influenciados por nomes de autores reconhecíveis.
- Os padrões éticos e de privacidade sejam mantidos ao trabalhar com contribuições de código aberto.
Apenas os metadados de identidade foram alterados; todo o código, diffs, ordenação de commits e estruturas de ficheiros foram preservados exatamente para manter a autenticidade e a reprodutibilidade do benchmark.
Cite este benchmark
Escolha o formato adequado ao local onde você vai publicar. Colar a versão com link no seu CMS preserva o backlink.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Alper, Şevval},
title = {{Benchmark de Ferramentas de Revisão de Código com IA}},
year = {2026},
month = mar,
howpublished = {\url{https://aimultiple.com/ai-code-review-tools}},
note = {AIMultiple. Acessado em 13 Março 2026}
}
Seja o primeiro a comentar
Seu endereço de e-mail não será publicado. Todos os campos são obrigatórios. Os comentários são deixados em seu idioma original.