Top 5 Frameworks de IA Agentiva de Código Aberto
Avaliamos 4 frameworks agentivos de código aberto populares em 2,000 execuções (5 tarefas, 100 execuções cada por framework), medindo latência ponta a ponta, consumo de tokens e diferenças arquitetônicas.
Benchmark de frameworks de IA agentiva
Examinamos como os próprios frameworks influenciam o comportamento do agente e o impacto resultante na latência e no consumo de tokens.
LangGraph é o framework mais rápido com os menores valores de latência em todas as tarefas, enquanto o LangChain tem a maior latência e uso de tokens.
Em 5 tarefas e 2,000 execuções, o LangChain surge como o framework mais eficiente em tokens, enquanto o AutoGen lidera em latência; LangGraph e LangChain seguem de perto. O CrewAI apresenta o perfil mais pesado no geral.
Tarefa 1: Agregação básica
Primeiro, medimos a sobrecarga de cada framework ao chamar uma única ferramenta e retornar o resultado, sem realizar nenhum raciocínio complexo.
LangChain & LangGraph: Para tarefas simples, eles têm desempenho quase tão rápido quanto código não agentivo, ambos terminando em menos de 5 segundos com menos de 900 tokens de prompt. A arquitetura de máquina de estados do LangGraph não introduz latência perceptível em comparação com o LangChain nesse nível de simplicidade; a sobrecarga do gerenciamento de estado se manifesta à medida que a complexidade da tarefa aumenta.
AutoGen: Fica ligeiramente acima do LangChain e do LangGraph tanto em latência quanto em uso de tokens, refletindo o custo básico do seu loop de conversação multiagente, dois agentes trocando mensagens mesmo para uma tarefa de uma única etapa.
CrewAI: Mesmo quando solicitado a fazer uma única chamada de ferramenta, ele exibe o que pode ser chamado de “sobrecarga gerencial”, consumindo quase 3× os tokens do LangChain e levando quase 3× mais tempo. O processo de verificação em várias etapas entre suas personas Planejador e Analista oferece uma abordagem completa, mas intensiva em recursos, que prioriza a completude em vez da velocidade. Esse custo é estrutural: ele aparece independentemente da complexidade da tarefa.
Tarefa 2: Análise comparativa de receita (gerenciamento de estado)
Na Tarefa 2, queríamos ver a capacidade dos frameworks de manter dois grupos de filtro diferentes na memória (Persistência de Estado) e combiná-los.
CrewAI
Em nossa análise de logs, descobrimos que o CrewAI oferece o mais alto nível de transparência de infraestrutura entre os frameworks, mas ao custo do maior consumo de recursos.
Em vez de retornar imediatamente os dados recuperados, o CrewAI valida repetidamente seus próprios processos por meio de um mecanismo de auto-revisão. Esse comportamento exploratório fez com que ele atingisse o limite configurado de max_iter=10, deixando algumas execuções presas em um loop contínuo de pensamento sem produzir uma saída JSON.
A causa raiz desse comportamento é que o CrewAI injeta instruções em múltiplas camadas no prompt do sistema, atribuindo a cada agente um papel, objetivo e histórico, enquanto impõe um loop ReAct Estilo Pensamento → Ação → Observação a cada etapa. Mesmo para tarefas simples, o LLM não pode pular essa cerimônia e obedientemente produz monólogos internos prolixos, o que se agrava ainda mais em cenários multiagente.
O CrewAI consumiu quase o dobro dos tokens dos outros frameworks e levou mais de três vezes o tempo do LangChain, tornando-o mais adequado para transições de estado complexas e tomada de decisão multifatorial, e não para tarefas simples de recuperação de dados.
LangChain
O framework mais rápido e com melhor relação custo-benefício. Em nossos logs, observamos que o LangChain completa a tarefa em 5-6 etapas sem desvios: Carregar → Filtrar → Calcular → Filtrar → Calcular → Saída. Como seu gerenciamento de estado é muito simples, a sobrecarga é quase zero e a latência é a mais baixa entre todos os frameworks.
AutoGen
Apresentou um desempenho muito equilibrado. Na Tarefa 2, igualou-se ao LangGraph quase exatamente tanto em uso de tokens quanto em latência, mostrando que a sobrecarga do loop de conversação não se agrava significativamente quando a cadeia de tarefas permanece linear.
No entanto, ocasionalmente adiciona uma etapa extra de verificação para confirmar parâmetros durante o processo de chamada de ferramenta, tornando-o ligeiramente mais lento que o LangChain. Quando encontra um erro em uma chamada de ferramenta ou os dados não retornam como esperado, ele imediatamente atualiza seu raciocínio na próxima etapa e chega ao JSON correto. Por gerenciar as saídas ferramentas como um fluxo conversacional, é um dos frameworks mais resilientes contra erros lógicos.
LangGraph
Nesta tarefa, o LangGraph é o framework mais estável graças à sua arquitetura baseada em grafos. Em seus logs, observamos que o estado é transportado de forma muito limpa durante toda a execução. O risco de contaminação de dados ou interferência entre segmentos está no nível mais baixo neste framework. Em todas as 100 execuções, produziu resultados em quase o mesmo número de etapas e dentro da mesma faixa de latência.
Tarefa 3: Análise de limites (disciplina numérica)
Nesta tarefa, queríamos ver com que precisão os frameworks traduzem condições numéricas em linguagem natural, como “menos de 1 ano de permanência” e “mais de $70 em cobranças mensais”, em parâmetros de ferramenta precisos, como tenure_max=12 e charges_min=70.0.
O LLM sabe como fazer essa conversão; o que realmente queríamos testar era se o framework pode proteger esses parâmetros ao longo de seus próprios mecanismos de repetição, contexto de re-prompt e ciclos de gerenciamento de estado.
LangChain & LangGraph
Ambos os frameworks passaram os parâmetros (tenure_max=12, charges_min=70) diretamente para a ferramenta exatamente como o LLM os produziu, sem nenhuma modificação ou loop de re-prompt. Essa eficiência é mostrada nos números: ambos os frameworks concluíram a Tarefa 3 em menos de 9 segundos com menos de 1,800 tokens de prompt, o menor nesta tarefa.
Quando queríamos medir se os limites numéricos são preservados sem a interferência do framework, esses dois atenderam às nossas expectativas: qualquer que fosse o parâmetro gerado, era isso que executava.
AutoGen
O AutoGen é totalmente bem-sucedido na correção numérica. Em algumas execuções, observou-se que o framework adicionou uma etapa de verificação antes de passar o parâmetro gerado pelo LLM para a ferramenta, significando que o framework gastou uma etapa extra preservando o parâmetro. Com 2,480 tokens e 8 segundos, igualou a latência do LangChain apesar da etapa extra, confirmando que a sobrecarga de verificação é real, mas pequena. Atendeu às nossas expectativas em termos de integridade do parâmetro, com a etapa de confirmação introduzindo um custo marginal de token, em vez de uma penalidade de latência significativa.
CrewAI
O comportamento mais notável foi observado no CrewAI, que concluiu a Tarefa 3 em 30 segundos com 4,360 tokens, o maior nesta tarefa. Dois padrões distintos de falha emergiram da análise de logs.
Em algumas execuções, um valor que deveria ser 68.81% foi retornado como 0.6878 (proporção decimal). Isso indica que a serialização da saída do framework pode remover a saída do LLM do seu contexto original.
Os logs mostram que o LLM inicialmente produziu os parâmetros corretos, tenure_max=12 e charges_min=70. No entanto, uma vez que o CrewAI entrou em um loop “Falha ao analisar”, o framework pressionou o LLM a reconsiderar. No contexto de re-prompt, o LLM mudou o limite para tenure_max=14 e desabilitou completamente o filtro charges_min, produzindo uma taxa de churn de 46.84%, que é na verdade a taxa de churn de todos os clientes com permanência inferior a 14. Esse era exatamente o cenário que queríamos observar: o mecanismo de repetição do framework pode corromper um parâmetro que o LLM havia acertado.
Tarefa 4: Resiliência a erros e capacidade de pivotamento
Nesta tarefa, queríamos ver como cada framework lida com cenários disruptivos e observar o impacto na latência e no consumo de tokens. A ferramenta lança 3 tipos diferentes de erros em sucessão (Rede, Tempo Limite, Limite de Taxa), encurralando o agente. Os dois primeiros erros instruem o agente a tentar novamente, e depois de tentar ambos, o erro de Limite de Taxa recebido diz ao agente para esperar 10 segundos. Uma vez que o agente espera e tenta novamente, a ferramenta começa a funcionar normalmente.
LangGraph & Autogen
Estes dois frameworks encontraram soluções alternativas autonomamente quando confrontados com falhas de ferramenta nesta tarefa.
Quando a ferramenta retornou um aviso de limite de taxa, em vez de pausar e esperar, esses agentes decidiram abandonar completamente a ferramenta com falha e encontrar um caminho alternativo. Sua abordagem foi: “Já que esta ferramenta não está funcionando, vou filtrar cada método de pagamento um por um, calcular a taxa de churn para cada um separadamente e depois combinar os resultados eu mesmo.”
Método: Em vez de realizar a tarefa com uma única chamada de ferramenta, eles a dividiram usando duas ferramentas separadas, uma para filtragem e outra para cálculo, processando cada PaymentMethod (Cheque eletrônico, Cheque enviado por correio, etc.) individualmente.
Esses agentes operam com raciocínio orientado a objetivos, em vez de dependência de caminho. Se o caminho mais curto não estiver disponível, eles podem construir um plano de execução alternativo em segundos.
O LangGraph atingiu 15,010 tokens de prompt na Tarefa 4, a maior contagem de tokens em uma única tarefa em todo o benchmark, porque sua máquina de estados acumulou o histórico crescente de cada chamada manual de ferramenta de volta ao contexto a cada etapa. O AutoGen seguiu com 10,750 tokens, um pouco mais contido devido ao seu tratamento conversacional dos resultados intermediários. Apesar disso, ambos terminaram em torno de 24-27 segundos, confirmando que o custo adicional de tokens não se traduziu em latência significativa porque o pivotamento em si foi rápido.
CrewAI
Apesar de mostrar o maior consumo de tokens em tarefas anteriores, o CrewAI exibiu o menor uso de tokens) mas os maiores valores de latência nesta tarefa.
Por que o menor token?
O CrewAI não passou por uma solução alternativa manual de 10-15 etapas como seus concorrentes. Quando encontrou erros, em vez de bombear repetidamente todo o histórico e dados intermediários complexos de volta para o LLM a cada etapa, ele construiu um loop de raciocínio mais focado e modular. Ao evitar verborragia desnecessária, tornou-se o framework com melhor relação custo-benefício nesta tarefa.
Por que alta latência?
A estrutura gerencial do CrewAI pausa e reavalia o plano quando encontra um erro. Quando recebeu o aviso de espera de 10 segundos, passou mais tempo na fase de “planejamento estratégico”. Além disso, em vez de pivotar para outra ferramenta para filtragem, escolheu persistentemente esperar que a ferramenta principal se recuperasse ou tentasse com a ferramenta estável, o que prolongou a duração total.
LangChain
LangChain passou por sua transformação mais significativa nesta tarefa, provando por que a resiliência depende da configuração adequada.
Em nossa execução inicial, o LangChain travou em todas as tentativas com um ConnectionError.
O AgentExecutor padrão do LangChain trata exceções Python brutas lançadas de dentro de uma ferramenta como erros fatais e encerra o processo. Ao contrário de seus concorrentes, ele não aplica uma filosofia de “erros são observações” por padrão. Como o agente nunca vê o erro, ele não tem chance de raciocinar sobre ele.
Envolvemos a chamada de ferramenta dentro do langchain_agent.py com um bloco try-except. Isso converteu o erro em uma mensagem legível que o agente pôde processar.
Comportamento pós-correção: Após aplicar a correção, observamos nos logs do LangChain que ele exibiu exatamente o mesmo raciocínio que o LangGraph. Recebeu 3 erros da ferramenta, mudou imediatamente de estratégia e pivotou para usar duas ferramentas separadas, uma para filtragem e outra para cálculo, processou cada método de pagamento individualmente e combinou os resultados.
Na verdade, o LangChain é tão capaz e adaptável quanto o LangGraph, mas como o tratamento de erros do framework estava desativado por padrão, ele não teve oportunidade de demonstrar essa capacidade. Uma vez configurado corretamente, alcançou o resultado correto usando a mesma abordagem de caminho alternativo.
Por que essas diferenças ocorreram? (análise da arquitetura dos frameworks)
Se o comportamento do agente dependesse apenas do LLM (GPT-5.2), todos os frameworks deveriam ter se comportado de forma semelhante. No entanto, as diferenças claras nessas proporções estão enraizadas nos próprios mecanismos de loop interno dos frameworks:
1. LangGraph & AutoGen (90% de Pivot):
O LangGraph opera em uma arquitetura de Máquina de Estados, enquanto o AutoGen trabalha em um modelo baseado em Conversação. Em ambos os sistemas, os erros são processados como um loop de feedback. No LangGraph, o estado que recebe o erro passa para o próximo nó; no AutoGen, o agente Proxy encaminha o erro para o assistente como uma mensagem de chat. Esse mecanismo constante de cutucada força o agente a continuar procurando uma solução. Como o agente é repetidamente confrontado com a pergunta “Recebi um erro, o que devo fazer?”, a probabilidade de ele decidir tomar um caminho manual alternativo sobe para 90%.
2. LangChain (65% de Pivot / 35% de Espera):
LangChain roda em uma arquitetura AgentExecutor sequencial. Mesmo com tratamento de erros implementado, seu loop de execução tem uma estrutura mais linear e está focado principalmente em produzir uma Resposta Final. Se a ferramenta lançar erros por 3-4 etapas, o LangChain às vezes prefere esperar que a ferramenta tenha sucesso na próxima tentativa ou produza um resultado a partir do contexto existente, em vez de pivotar para uma estratégia alternativa. Como o bloqueio de estado do LangChain é mais flexível que o do LangGraph, sua proporção de espera/solução direta fica em torno de 35%.
3. CrewAI (0% de Pivot):
O CrewAI opera em uma arquitetura de Processo Gerencial. Seus agentes são envolvidos em definições de Papel e Tarefa. Quando ocorrem erros, sua arquitetura interna normalmente aciona lógica de Autocorreção ou Repetição. No entanto, uma mudança radical de estratégia como “vamos descartar todo o plano e fazer filtragem manual em 5 etapas” entra em conflito com a estrutura de plano gerencial do CrewAI. Ele opera com a disciplina de “devo consertar a ferramenta que me foi dada ou usar a alternativa mais próxima”, em vez de abandonar completamente seu plano. Esta é fundamentalmente uma abordagem centrada no plano, em oposição a uma centrada no objetivo.
Tarefa 5: Orquestração de dados não estruturados (roteamento de dados não estruturados)
Na tarefa 5, observamos como os frameworks se comportam quando encontram colunas JSON e texto longo (LongText) dentro de um CSV. Os agentes precisavam primeiro descobrir o tipo de dados dessas colunas e, em seguida, selecionar as ferramentas de processamento corretas, sequencialmente ou em paralelo.
No mundo real, o gerenciamento de dados não estruturados exige que um agente vá além dos dados tabulares padrão e trabalhe com blobs JSON, parágrafos de gratuito-text ou objetos aninhados.
Para um framework lidar corretamente com esse tipo de dados, ele precisa fazer bem duas coisas:
1- uma inteligência de descoberta que entenda qual ferramenta se adequa a qual tipo de dado
2- um mecanismo de orquestração que coordene várias chamadas de ferramentas independentes.
Projetamos a Tarefa 5 especificamente para medir essas duas capacidades separadamente.
AutoGen
O AutoGen apresentou um desempenho forte nesta tarefa, terminando com 8,170 tokens de prompt e uma latência mediana de 47 segundos, o resultado mais rápido e com maior eficiência de tokens na Tarefa 5.
O loop de conversação no núcleo de sua arquitetura, a troca de mensagens entre AssistantAgent e UserProxyAgent, é tipicamente visto como uma estrutura que leva à verborragia. No entanto, na Tarefa 5, essa estrutura se transformou em uma vantagem.
Ao olhar o histórico de conversa, o LLM reconheceu que as colunas Metadata e SupportNotes eram independentes uma da outra. Ele então enviou uma única resposta TOOL CALLS listando 4 ferramentas simultaneamente: inspect_column(Metadata), inspect_column(SupportNotes), parse_json_column(…) e summarize_text_column(…) todas rodaram em paralelo. Isso permitiu que concluísse a tarefa em 3 turnos do LLM, com o menor número de tokens e o menor número de etapas.
A razão técnica por trás desse comportamento é clara: o mecanismo de execução de ferramentas do AutoGen executa a lista tool_calls retornada pelo LLM atomicamente e coleta os resultados em uma única etapa de conversa. A filosofia de “gerenciar a conversa” do framework naturalmente permite que vários canais paralelos sejam abertos ao mesmo tempo, e os números de tokens e latência confirmam isso diretamente.
LangGraph
O LangGraph terminou com 9,150 tokens de prompt e 70 segundos de mediana, próximo ao AutoGen em tokens, mas mais lento no tempo. Sua arquitetura de Máquina de Estados exibiu simultaneamente sua maior força e sua fraqueza mais notável na Tarefa 5.
Em cada execução, o loop nó llm → nó tools → llm acumula todas as saídas de ferramentas anteriores no estado e as passa para o LLM. Essa estrutura garante que o agente nunca esqueça nada, o que normalmente é uma vantagem significativa.
No entanto, na Tarefa 5 essa força jogou contra ele. O LangGraph estava encontrando as ferramentas corretas e construindo o segmento correto. Mas mesmo após a análise estar completa, detectou ambiguidades no estado acumulado, interpretando etapas concluídas como ainda pendentes, e repetidamente disparou chamadas de ferramentas adicionais. Mesmo tendo recuperado os dados necessários e prestes a produzir a resposta correta, o sinal de “etapa faltante” da máquina de estados entrou em ação e o agente entrou em loops desnecessários. Como resultado, o número de chamadas de ferramenta por execução variou entre 6 e 16. O poder do estado de “nunca esquecer nada” às vezes fez com que etapas concluídas parecessem incompletas, puxando o agente de volta para ciclos redundantes e elevando a latência 23 segundos acima do AutoGen, apesar de uma contagem de tokens comparável.
CrewAI
O desempenho do CrewAI na Tarefa 5 produziu a maior variância em todo o benchmark. Em algumas execuções, seguiu uma sequência impecável com 5 chamadas de ferramenta, sem desvios, executando como um script. Nessas execuções, a estrutura gerencial definida por papel e tarefa do CrewAI funcionou exatamente como pretendido: quando o agente entendeu claramente seu papel, comportou-se de forma previsível e disciplinada.
No entanto, em outras execuções (por exemplo, execução 16: 35 chamadas de ferramenta), o caos completo se seguiu. A causa raiz foi o monólogo interno (Thought) que o CrewAI gera a cada etapa. Após construir corretamente o segmento com o filtro correto, o monólogo interno do agente começou a questionar se filtros adicionais também deveriam ser aplicados. Após ver o resultado, duvidou se o segmento atual era válido ou se o anterior deveria ter precedência. Essa dúvida o levou a recarregar os dados do zero. Então filtrou novamente, entrou em outro loop de verificação, duvidou novamente e repetiu essa espiral 8 vezes.
No CrewAI, cada Thought produz uma avaliação independente, e essas avaliações ocasionalmente invalidam etapas previamente verificadas. O reflexo de “verificação contínua” do Processo Gerencial, em algumas execuções, empurrou o agente a requestionar suas próprias decisões corretas.
LangChain
A estrutura AgentExecutor do LangChain é inerentemente sequencial, e a Tarefa 5 é onde essa restrição foi mais visível. Com 10,070 tokens de prompt e 86 segundos de mediana, foi o framework mais lento nesta tarefa, apesar de não ter a maior contagem de tokens.
Ele faz uma única chamada de ferramenta em cada etapa, recebe o resultado e depois prossegue, o que significa que 4 ferramentas independentes exigiram 4 turnos separados do LLM com 4 períodos de espera separados. A mediana de 47 segundos do AutoGen contra os 86 segundos do LangChain é uma medição direta do custo da execução sequencial versus paralela.
Na Tarefa 5, a contagem de ferramentas do LangChain se estabeleceu em 9 ou 15. Esses dois agrupamentos apontam para duas estratégias típicas: em algumas execuções, ele pulou a etapa de inspeção e foi diretamente para análise e sumarização (9 ferramentas), enquanto em outras inspecionou cada coluna primeiro antes de processar (15 ferramentas). A identidade de executor linear do LangChain ficou clara aqui: ele não exibiu nem a eficiência paralela do AutoGen nem o caos do monólogo do CrewAI.
Gerenciamento de dados não estruturados e arquitetura dos frameworks
Os resultados desta tarefa revelam que a eficiência com que um framework pode gerenciar dados não estruturados (JSON, LongText) está diretamente ligada ao seu mecanismo de loop interno:
Frameworks capazes de chamadas paralelas de ferramentas (AutoGen) podem processar colunas de dados independentes em uma única etapa. Em cenários do mundo real envolvendo grandes objetos JSON e inúmeras colunas de texto, essa diferença se traduz em uma enorme vantagem de custo e velocidade.
Frameworks com loops orientados a estado (LangGraph) se destacam na consistência de dados, mas carregam o risco de reavaliar etapas concluídas acumuladas no histórico.
Frameworks baseados em monólogo (CrewAI) são profundamente capazes de entender o tipo e o significado dos dados, mas essa profundidade às vezes se transforma em questionamento excessivo e loop.
Frameworks de execução linear (LangChain) processam diferentes ramificações de dados não estruturados separadamente, produzindo um resultado intermediário de ambos os mundos.
GitHub crescimento de estrelas dos frameworks agentivos
Comparar frameworks de IA agentiva
Os frameworks de IA agentiva variam em várias dimensões-chave, e entender essas diferenças é essencial para fazer comparações significativas.
Orquestração multiagente
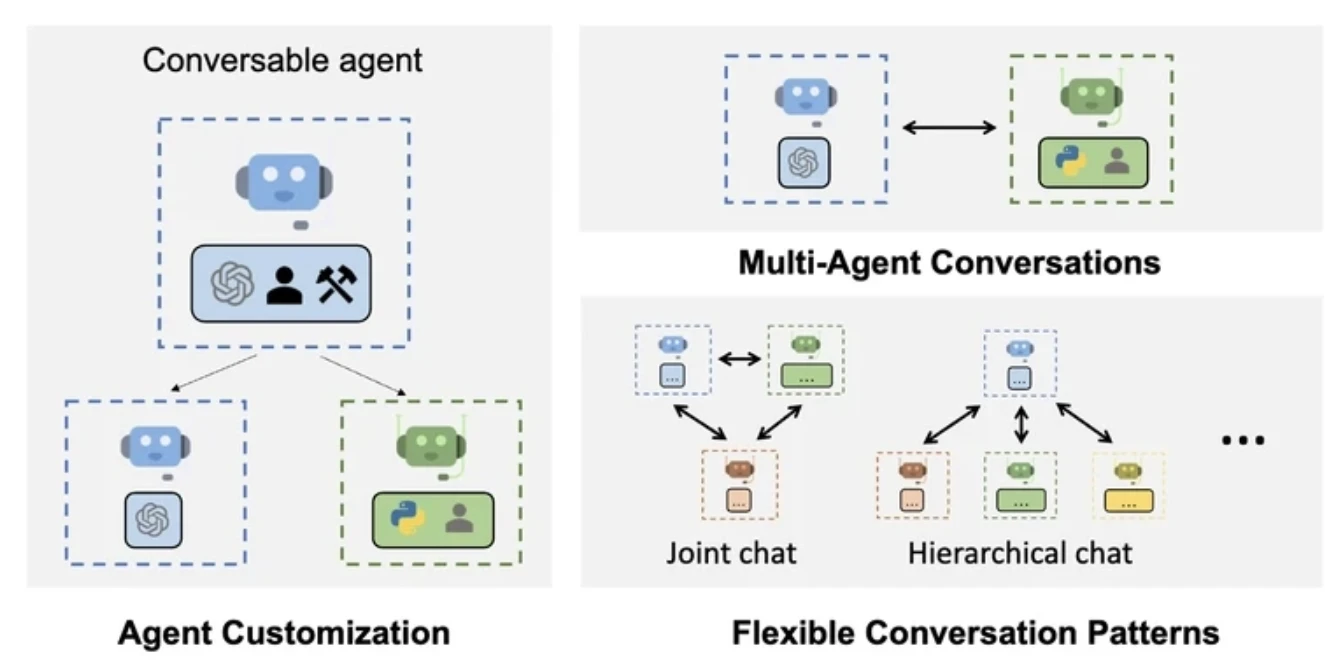
Orquestração multiagente coordena vários agentes de IA especializados para lidar com fluxos de trabalho complexos que excedem as capacidades de um único agente. Em vez de construir um agente monolítico, a orquestração divide o trabalho entre agentes com papéis, ferramentas e conhecimentos distintos. Cada framework oferece abordagens diferentes para a coordenação de agentes.
LangGraph
O LangGraph é um framework relativamente conhecido e se destaca como uma opção chave para desenvolvedores que constroem sistemas de agentes.
Coordenação multiagente explícita: Você pode modelar múltiplos agentes como nós ou grupos individuais, cada um com sua própria lógica, memória e papel no sistema.
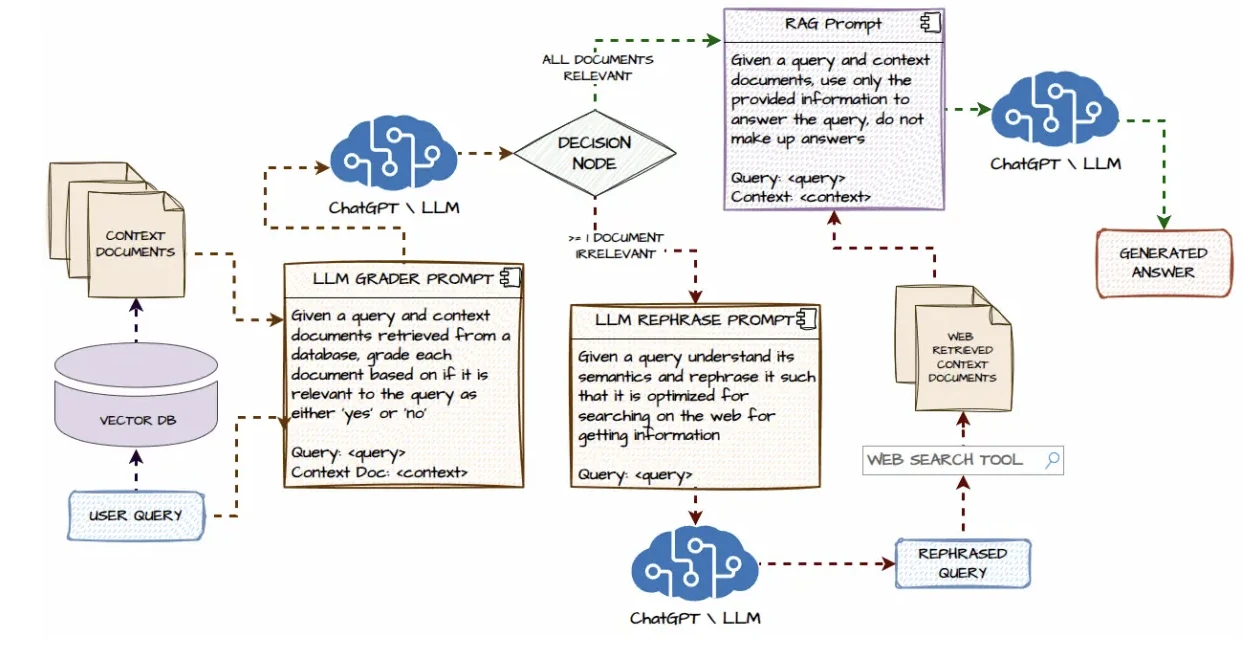
Ele cria fluxos de trabalho de IA através de APIs e ferramentas. Assim, é adequado para RAG e pipelines personalizados.
AutoGen
O AutoGen permite que vários agentes se comuniquem passando mensagens em um loop. Cada agente pode responder, refletir ou chamar ferramentas com base em sua lógica interna.
Ele possui colaboração assíncrona de agentes, tornando-o particularmente útil para cenários de pesquisa e prototipagem onde o comportamento do agente requer experimentação ou refinamento iterativo.
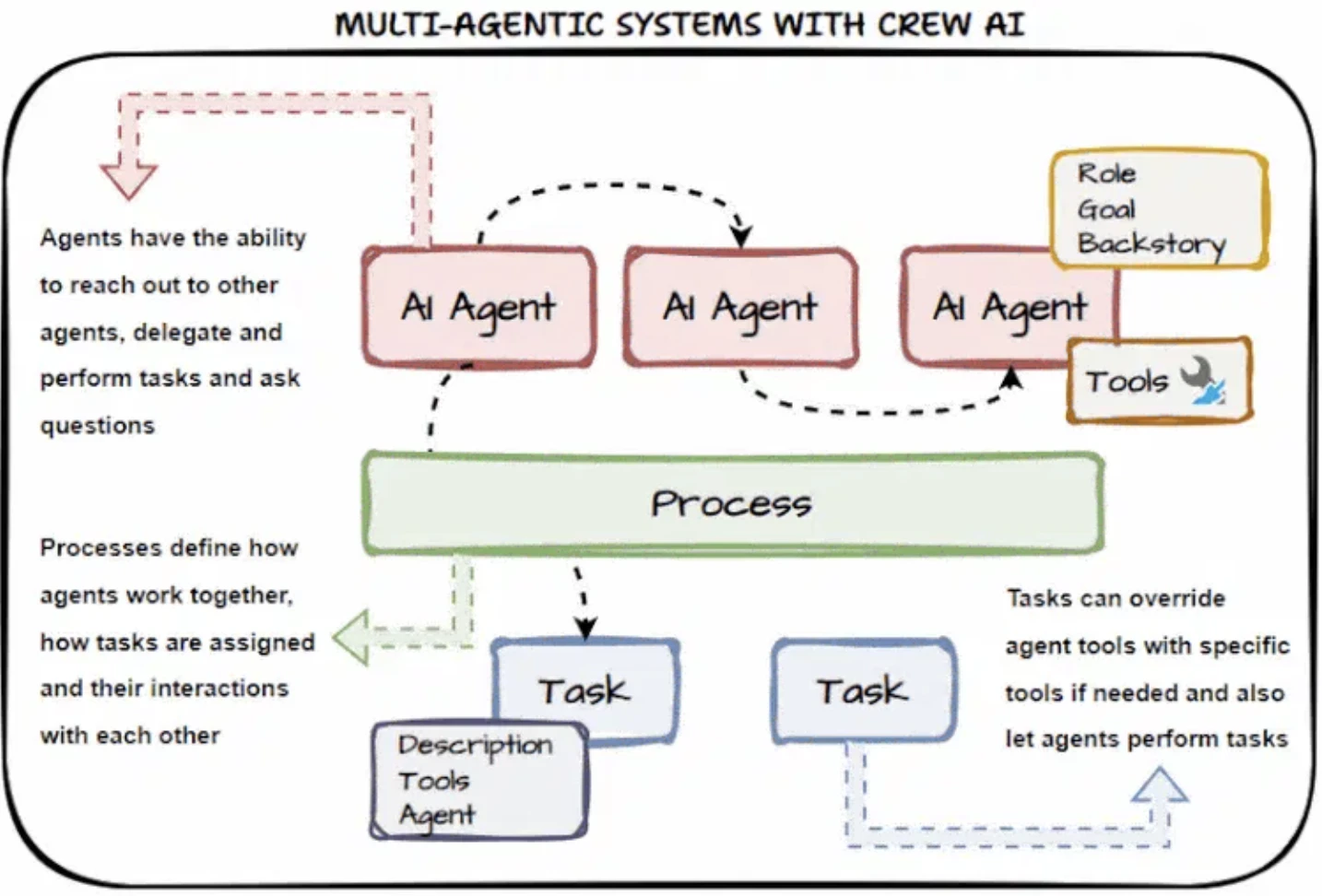
CrewAI
O CrewAI lida com a maior parte da lógica de baixo nível para você e fornece orquestração multiagente:
- Integra-se com ferramentas de monitoramento para rastreamento e depuração
- Controle de execução integrado por meio de Flows com lógica condicional, loops e gerenciamento de estado
- Suporta coordenação multiagente hierárquica (gerente-trabalhador) e estruturada
OpenAI Swarm
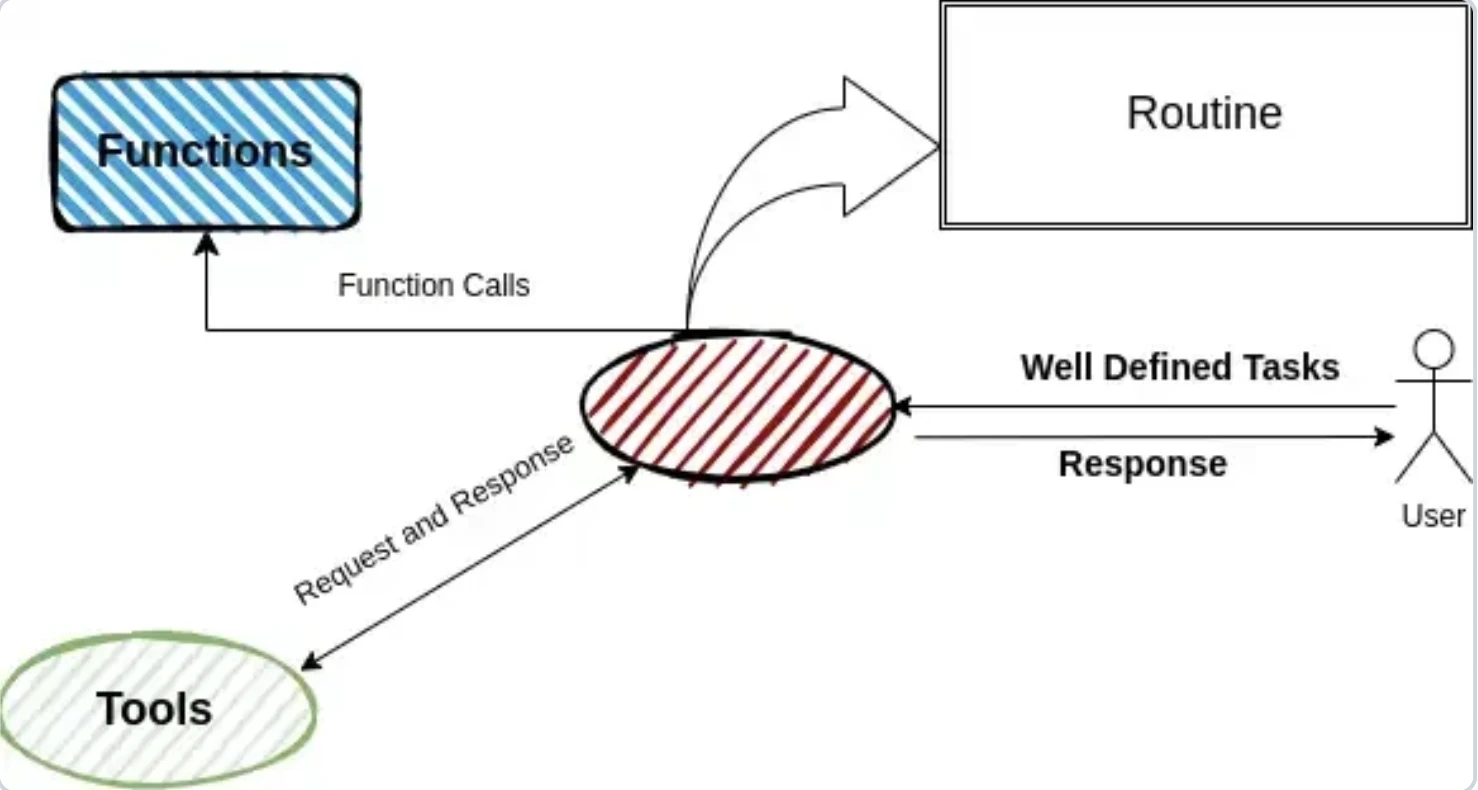
Swarm é um framework multiagente leve e experimental para prototipagem. Os agentes trabalham sequencialmente por meio de handoffs, transferindo tarefas enquanto mantêm o contexto compartilhado. Utiliza rotinas de linguagem natural e ferramentas Python para fluxos de trabalho flexíveis.
LangChain
LangChain é um framework para construir aplicações de agente único baseadas em LLM com ferramental RAG. Ele fornece componentes modulares, incluindo cadeias, ferramentas, memória e recuperação para fluxos de trabalho de processamento de documentos.
LangChain opera principalmente por meio de padrões de execução de agente único, onde um agente gerencia o fluxo de trabalho.
Definição de agente e função
LangGraph
O LangGraph adota uma abordagem baseada em grafos para o design de agentes, onde cada agente é representado como um nó que mantém seu próprio estado. Esses nós são conectados por meio de um grafo direcionado, permitindo lógica condicional, coordenação de várias equipes e controle hierárquico. Isso permite que você construa e visualize grafos multiagente com nós supervisores para orquestração escalável.
O LangGraph usa funções estruturadas e anotadas que anexam ferramentas a agentes. Você pode construir nós, conectá-los a vários supervisores e visualizar como diferentes equipes interagem. Pense nisso como dar a cada membro da equipe uma descrição detalhada do trabalho. Isso facilita a construção e o teste de agentes que trabalham juntos.
AutoGen
O AutoGen define agentes como unidades adaptativas capazes de roteamento flexível e comunicação assíncrona. Os agentes interagem entre si (e opcionalmente com humanos) trocando mensagens, permitindo a resolução colaborativa de problemas. Assim como o LangGraph, usa funções estruturadas e anotadas.
CrewAI
O CrewAI adota uma abordagem de design baseado em papéis. Cada agente recebe um papel (por exemplo, Pesquisador, Desenvolvedor) e um conjunto de habilidades, funções ou ferramentas que pode acessar. A definição de funções é feita por meio de anotações estruturadas.
OpenAI Swarm
OpenAI Swarm usa um modelo baseado em rotinas onde os agentes são definidos por meio de prompts e docstrings de funções. Não possui modelos formais de orquestração ou estado, dependendo em vez disso de fluxos de trabalho estruturados manualmente. O comportamento das funções é inferido pelo LLM por meio de docstrings (o Swarm identifica o que uma função faz lendo sua descrição), tornando essa configuração flexível, mas menos precisa.
LangChain
LangChain usa uma arquitetura baseada em cadeias onde um único agente orquestrador gerencia chamadas para modelos de linguagem e várias ferramentas. Ele define funções por meio de interfaces explícitas, como toolkits e modelos de prompt.
Embora focado principalmente em fluxos de trabalho centralizados, o LangChain suporta extensões para configurações multiagente, mas carece de comunicação agente-a-agente integrada.
Memória
Capacidades de memória:
- Com estado: Se o framework suporta memória persistente entre execuções.
- Contextual: Se suporta memória de curto prazo via histórico de mensagens ou passagem de contexto.
Recursos de memória são uma parte fundamental para construir sistemas agentivos que lembram do contexto e se adaptam ao longo do tempo:
- Memória de curto prazo: Acompanha interações recentes, permitindo que os agentes lidem com conversas de várias etapas ou fluxos de trabalho passo a passo.
- Memória de longo prazo: Armazena informações persistentes entre sessões, como preferências do usuário ou histórico de tarefas.
- Memória de entidade: Rastreia e atualiza o conhecimento sobre objetos, pessoas ou conceitos específicos mencionados durante as interações (por exemplo, lembrar o nome de uma empresa ou ID de projeto mencionado anteriormente).
LangGraph
O LangGraph usa dois tipos de memória: memória em thread, que armazena informações durante uma única tarefa ou conversa, e memória entre threads, que salva dados entre sessões. Os desenvolvedores podem usar MemorySaver para salvar o fluxo de uma tarefa e vinculá-lo a um thread_id específico. Para armazenamento de longo prazo, o LangGraph suporta ferramentas como InMemoryStore ou outros bancos de dados. Isso proporciona controle flexível sobre como a memória é delimitada e retida entre execuções.
AutoGen
O AutoGen usa um modelo de memória contextual. Cada agente mantém contexto de curto prazo por meio de um objeto context_variables, que armazena o histórico de interações. Não possui memória persistente integrada.
CrewAI
O CrewAI fornece memória em camadas pronta para uso. Ele armazena memória de curto prazo em um armazenamento vetorial ChromaDB, resultados recentes de tarefas em SQLite e memória de longo prazo em uma tabela SQLite separada (com base nas descrições das tarefas). Além disso, suporta memória de entidade usando embeddings vetoriais. Essa configuração de memória é automaticamente configurada quando memory=True está ativado.
OpenAI Swarm
O Swarm é sem estado (stateless) e não gerencia memória nativamente. Os desenvolvedores podem passar memória de curto prazo por meio de context_variables manualmente e, opcionalmente, integrar ferramentas externas ou camadas de memória de terceiros (por exemplo, mem0) para armazenar contexto de longo prazo.
LangChain
LangChain suporta tanto memória de curto prazo quanto de longo prazo por meio de componentes flexíveis. A memória de curto prazo é normalmente gerenciada por buffers em memória que rastreiam o histórico de conversas dentro de uma sessão. Para memória de longo prazo, o LangChain integra-se com armazenamentos vetoriais externos ou bancos de dados para persistir embeddings e dados de recuperação.
Os desenvolvedores podem personalizar os escopos e estratégias de memória usando classes de memória integradas, permitindo o gerenciamento eficiente da memória contextual e específica de entidade entre interações.
Humano no circuito
LangGraph
O LangGraph suporta pontos de interrupção personalizados (interrupt_before) para pausar o grafo e aguardar a entrada do usuário no meio da execução.
AutoGen
O AutoGen suporta nativamente agentes humanos via UserProxyAgent, permitindo que humanos revisem, aprovem ou modifiquem etapas durante a colaboração do agente.
CrewAI:
O CrewAI permite feedback após cada tarefa configurando human_input=True; o agente pausa para coletar entrada em linguagem natural do usuário.
OpenAI Swarm
OpenAI Swarm não oferece humano no circuito integrado.
LangChain
LangChain permite inserir pontos de interrupção personalizados dentro de cadeias ou agentes para pausar a execução e solicitar entrada humana. Isso suporta revisão, feedback ou intervenção manual em pontos definidos do fluxo de trabalho.
Integração do Model Context Protocol (MCP) em frameworks de IA agentiva
Os agentes de IA precisam interagir com ferramentas externas como bancos de dados, APIs, sistemas de arquivos e aplicações de negócios. Sem um padrão, cada framework tinha que construir integrações personalizadas para cada ferramenta, criando um ecossistema fragmentado. O MCP resolve isso fornecendo um protocolo universal que permite que qualquer agente se conecte a qualquer ferramenta por meio de uma única interface.
Como cada framework se integra ao MCP
LangGraph
O LangGraph conecta-se a servidores MCP por meio de um adaptador que descobre automaticamente as ferramentas disponíveis e as converte para o formato compatível com o LangChain. Os agentes podem então usar essas ferramentas de forma transparente junto com suas capacidades nativas.
AutoGen
O AutoGen fornece integração MCP integrada por meio de seu módulo de extensão. Os desenvolvedores podem se conectar a servidores MCP e disponibilizar todas as suas ferramentas para os agentes do AutoGen com apenas algumas linhas de código.
CrewAI
Os agentes do CrewAI podem referenciar diretamente servidores MCP em sua configuração usando URLs simples ou configurações estruturadas. O framework gerencia automaticamente o ciclo de vida da conexão e o tratamento de erros.
OpenAI Swarm
O Swarm se beneficia do suporte nativo ao MCP do OpenAI em todo o seu ecossistema. Como o OpenAI integrou o MCP no ChatGPT e em seu SDK de Agentes, o Swarm pode aproveitar essa infraestrutura diretamente.
LangChain
LangChain oferece capacidades de chamada de ferramentas MCP onde funções Python atuam como pontes para servidores MCP. Isso permite extrair ferramentas de várias fontes e integrá-las em cadeias, agentes e outros componentes do LangChain sem wrappers personalizados.
O que os frameworks de IA agentiva realmente fazem?
Os frameworks de IA agentiva auxiliam na engenharia de prompts e no gerenciamento de como os dados fluem de e para os LLMs. Em um nível básico, ajudam a estruturar prompts para que o LLM responda em um formato previsível e roteie as respostas para a ferramenta, API ou documento corretos.
Se estivesse construindo do zero, você definiria manualmente o prompt, extrairia a ferramenta que o LLM deseja usar e acionaria a chamada de API correspondente. Os frameworks simplificam isso:
- Orquestração de prompts: Construir, gerenciar e rotear prompts complexos para LLMs
- Integração de ferramentas: Permitir que os agentes chamem APIs externas, bancos de dados, funções de código, etc.
- Memória: Manter o estado entre turnos ou sessões (curto e longo prazo)
- Integração de RAG: Habilitar a recuperação de conhecimento de fontes externas
- Coordenação multiagente: Estruturar como os agentes colaboram ou delegam tarefas
Frameworks de IA agentiva: Casos de uso reais
LangGraph – Planejador de viagens multiagente
Um projeto de produção construído com LangGraph demonstra um assistente de viagens multiagente com estado que obtém dados de voos e hotéis (usando as APIs do Google Flights e Hotels) e gera recomendações de viagem.4
CrewAI – Criador de conteúdo agentivo
O repositório de exemplos oficiais do CrewAI inclui fluxos como planejamento de viagens, estratégia de marketing, análise de ações e assistentes de recrutamento, onde agentes específicos de cada papel (por exemplo, “Pesquisador”, “Escritor”) colaboram em tarefas.5
O CrewAI transforma um briefing de conteúdo de alto nível em um artigo completo usando Groq.
Recursos principais dos frameworks de IA agentiva
Suporte a modelos:
- A maioria é agnóstica a modelos, suportando vários provedores de LLM (por exemplo, OpenAI, Anthropic, modelos de código aberto).
- No entanto, as estruturas de prompt do sistema variam de acordo com o framework e podem ter melhor desempenho com alguns modelos do que com outros.
- O acesso e a personalização dos prompts do sistema são frequentemente essenciais para resultados ótimos.
Ferramentas:
- Todos os frameworks suportam uso de ferramentas, uma parte central para habilitar as ações dos agentes.
- Oferecem abstrações simples para definir ferramentas personalizadas.
- A maioria suporta Model-Context-Protocol (MCP), seja nativamente ou por meio de extensões da comunidade.
Memória / Estado:
- Usam rastreamento de estado para manter a memória de curto prazo entre etapas ou chamadas ao LLM.
- Alguns ajudam os agentes a reter interações ou contexto anteriores dentro de uma sessão.
RAG (Geração Aumentada por Recuperação):
- A maioria inclui opções de configuração fáceis para RAG, integrando bancos de dados vetoriais ou armazenamentos de documentos.
- Isso permite que os agentes referenciem conhecimento externo durante a execução.
Outros recursos comuns
- Suporte a execução assíncrona, permitindo chamadas concorrentes de agentes ou ferramentas.
- Tratamento integrado para saídas estruturadas (por exemplo, JSON).
- Suporte a saídas de streaming onde o modelo gera resultados de forma incremental.
- Recursos básicos de observabilidade para monitorar e depurar execuções de agentes.
Metodologia do benchmark
1. Estrutura das tarefas
Tarefa 1: Mede se uma única chamada de ferramenta pode ser feita com o parâmetro correto. A sobrecarga de infraestrutura base do framework é revelada mais claramente nesse cenário simples.
Tarefa 2: Requer manter os resultados de dois grupos de filtro separados na memória e combiná-los em uma única saída. O gerenciamento de estado e a coordenação de múltiplos segmentos são testados.
Tarefa 3: Mede se condições numéricas em linguagem natural são traduzidas em parâmetros de ferramenta sem distorção. O verdadeiro teste é se os mecanismos de repetição e re-prompt do framework podem preservar esses parâmetros.
Tarefa 4: Uma ferramenta lança erros de Rede, Timeout e RateLimit em sucessão. Mede-se o framework muda de estratégia diante desses erros.
Tarefa 5: O agente deve primeiro descobrir colunas JSON e LongText, depois chamar as ferramentas corretas com os parâmetros de escopo corretos. Observa-se o framework executa ferramentas independentes em paralelo ou sequencialmente.
Como é realmente uma tarefa
Para tornar a configuração concreta, aqui está a Tarefa 5, a tarefa mais complexa no benchmark de frameworks de IA agentiva. Cada framework recebeu o mesmo prompt e o mesmo conjunto de ferramentas; apenas o framework que envolvia o LLM mudou.
Prompt dado ao agente:
Analise clientes que cancelaram (Churn=’Yes’) que pagam mais de 100 em MonthlyCharges.
- Filtrar o conjunto de dados para Churn=’Yes’.
- Inspecionar as colunas ‘Metadata’ e ‘SupportNotes’ para descobrir seus tipos de dados.
- Extrair a distribuição de ‘device_type’ da coluna JSON ‘Metadata’.
- Contar palavras-chave de reclamações da coluna de texto gratuito ‘SupportNotes’.
Retornar o resultado apenas como JSON.
Saída JSON exigida:
Por que essa tarefa discrimina entre frameworks: o agente precisa planejar uma cadeia de quatro chamadas de ferramenta, manter o segmento filtrado no estado em cada chamada e reconhecer que uma coluna é JSON enquanto a outra é texto gratuito. Um framework que executa as colunas independentes em paralelo (AutoGen) termina muito mais rápido do que um que as executa sequencialmente (LangChain), e um framework que reavalia etapas concluídas (LangGraph, CrewAI) entra em loop desnecessariamente. O esquema JSON estrito nos permite pontuar a correção automaticamente.
2. Configuração
Todos os frameworks usaram o mesmo modelo de LLM (openai/gpt-5.2) e o mesmo valor de temperatura (0.1). Para todas as tarefas, cada agente recebeu as mesmas ferramentas e os mesmos prompts. Cada framework foi configurado em sua estrutura nativa: LangChain com AgentExecutor, LangGraph com StateGraph, AutoGen com AssistantAgent + UserProxyAgent e CrewAI com Agent + Task + Crew.
O conjunto de dados IBM Telco Customer Churn (7,032 clientes) foi usado. O estado das ferramentas foi redefinido antes de cada execução. 100 execuções independentes foram realizadas para cada combinação de framework e tarefa.
Os limites máximos de iteração foram definidos de acordo com a complexidade da tarefa: 10 para as Tarefas 1, 2 e 3; 20 para a Tarefa 4 devido ao loop instável da ferramenta; e 20 para a Tarefa 5 devido à cadeia de descoberta de 4 etapas.
Cite este benchmark
Escolha o formato adequado ao local onde você vai publicar. Colar a versão com link no seu CMS preserva o backlink.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Şipi, Nazlı},
title = {{Top 5 Frameworks de IA Agentiva de Código Aberto}},
year = {2026},
month = jul,
howpublished = {\url{https://aimultiple.com/agentic-frameworks}},
note = {AIMultiple. Acessado em 6 Julho 2026}
}

Comentários 1
Compartilhe suas ideias
Seu endereço de e-mail não será publicado. Todos os campos são obrigatórios. Os comentários são deixados em seu idioma original.
Thank you for this informative and detailed article! It helped me get a reading on these frameworks.