Migliori Strumenti di Monitoraggio delle Prestazioni dei Database: Confronto delle Top 5 Piattaforme
I problemi del database causano guasti alle applicazioni: un picco di memoria blocca il server e una query lenta fa scadere le richieste degli utenti.
Hanno analizzato sei piattaforme di monitoraggio dei database e hanno testato estensivamente tre di esse su MySQL e MongoDB installandole da zero, eseguendo carichi di lavoro identici e documentando ogni passaggio della configurazione e dell'esperienza di monitoraggio. I risultati mostrano differenze significative nella complessità di configurazione, nelle capacità di analisi delle query e nell'accuratezza delle metriche:
Risultati del benchmark di monitoraggio DB
Hanno testato SolarWinds, New Relic e Datadog con carichi di lavoro reali del database su MySQL e MongoDB. Tutte e tre le piattaforme hanno ricevuto aggiornamenti significativi dal test. Consulta le sezioni dei singoli vendor per le ultime funzionalità, inclusi il Rilevamento di Regressione delle Query di Datadog, l'app di Monitoraggio Database di Dynatrace e gli aggiornamenti sull'indipendenza della piattaforma di Percona PMM
- Esperienza di configurazione: SolarWinds ha completato l'integrazione in 5-8 minuti con rilevamento automatico. New Relic e Datadog sono stati più lenti e hanno richiesto una configurazione manuale.
- Profilazione delle query: Solo SolarWinds fornisce un'analisi a livello di query che identifica query lente, indici mancanti e operazioni ad alta intensità di risorse.
- Accuratezza delle metriche: SolarWinds ha tracciato le operazioni con un'accuratezza del 100%. New Relic ha sottostimato significativamente le operazioni in entrambi i test e ha mancato completamente un picco di memoria.
- Consumo di risorse: Tutti e tre gli agenti sono rimasti leggeri.
Per benchmark specifici per database con passaggi dettagliati di installazione, dati sul consumo di risorse e confronti delle dashboard:
- Monitoraggio MySQL: Processo di configurazione, profilazione delle query, accuratezza delle metriche con carico di lavoro di importazione da 26GB
- MongoDB Monitoring: Funzionalità NoSQL, qualità della dashboard con inserimenti di documenti
Copertura Database On-Premises
Tutti i provider supportano questi database: MySQL, PostgreSQL, MongoDB, MariaDB, Redis.
Supporto Database Cloud
Confronta gli strumenti di monitoraggio dei database:
Le valutazioni sono raccolte da siti web di recensioni B2B.
Cosa Fa Effettivamente il Monitoraggio del Database
Il monitoraggio del database traccia prestazioni, sicurezza e disponibilità in tempo reale. L'obiettivo: cogliere i problemi prima che gli utenti se ne accorgano.
Cosa viene monitorato:
- Utilizzo delle risorse (CPU, memoria, I/O disco)
- Tempi e modelli di esecuzione delle query
- Conteggi delle connessioni e disponibilità
- Tassi e tipi di errore
- Eventi di sicurezza e anomalie di accesso
Migliori Piattaforme di Monitoraggio delle Prestazioni dei Database
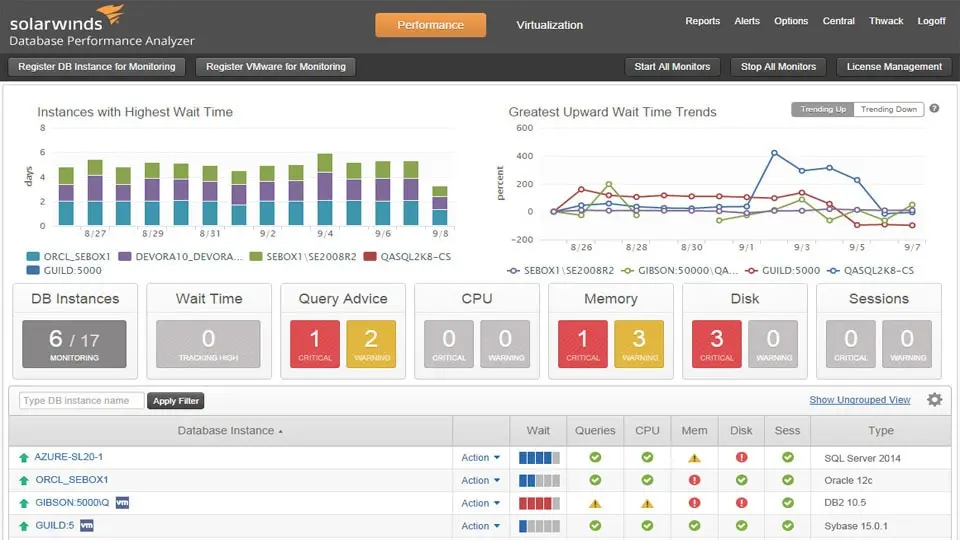
SolarWinds Database Performance Analyzer
SolarWinds Database Performance Analyzer si concentra sull'analisi dei tempi di attesa invece di tracciare solo le metriche di base. Quando il database rallenta, mostra esattamente quali query stanno aspettando e perché, sia che si tratti di I/O del disco, blocchi o vincoli CPU.
Principali differenze:
- Le linee di base del machine learning si adattano ai tuoi specifici modelli di database
- L'analisi delle query funziona su SQL Server, Oracle, MySQL, PostgreSQL e MongoDB in un'unica interfaccia
- Il rilevamento delle anomalie storiche risale a mesi fa per confrontare i problemi attuali con gli incidenti passati
- Le raccomandazioni sono collegate direttamente a specifici piani di esecuzione delle query
LogicMonitor
LogicMonitor utilizza un'architettura senza agenti per il monitoraggio dei database in ambienti IT ibridi. Invece di installare software su ogni server di database, un collettore leggero interroga i database tramite standard API e protocolli.
Principali differenze:
- Intelligenza degli Eventi: Ingestisce metriche, log, tracce e ticket in un unico flusso correlato con correlazione cross-domain, riducendo il rumore degli avvisi del 90-95 1
- Agenti IA: Agenti IA all'avanguardia progettati per scopi specifici gestiscono l'intero ciclo di vita dell'incidente con risoluzione dei problemi conversazionale, analisi della causa radice utilizzando modelli di dati correlati e risoluzione automatica
- Funzionalità Specifiche per Database: Rileva automaticamente le anomalie nelle query lente, nei picchi di connessione e nei colli di bottiglia delle risorse con riepiloghi degli incidenti in linguaggio semplice
- Oltre 3.000 Integrazioni di Strumenti: Connette strumenti di osservabilità, APM, sicurezza e CMDB per una risposta unificata agli incidenti
Percona Monitoring and Management (PMM)
Percona si concentra sui database open source, con profonda esperienza in MySQL, PostgreSQL e MongoDB. La piattaforma fornisce strumenti di analisi delle query e ottimizzazione delle prestazioni senza i costi di licenza del software aziendale.
Principali differenze:
- Consulenti Integrati: Tutti i consulenti del database e i modelli di avviso (precedentemente suddivisi in Basic, Standard, Premium) sono ora inclusi di default senza necessità di abbonamento. Funziona completamente offline senza dipendenze da Internet.
- Supporto Valkey & Redis: Monitoraggio nativo per Valkey (alternativa ad alte prestazioni a Redis) e Redis con dieci dashboard dedicate che coprono prestazioni, rilevamento della latenza, problemi di replica e risoluzione dei colli di bottiglia.
- PostgreSQL 18: Supporto completo per PostgreSQL 18 Community Edition.
- Funzionalità Enterprise Kubernetes: Supporto completo OpenShift 4.16 per entrambe le distribuzioni Client e Server. Configurazione centralizzata di VMagent tramite variabili d'ambiente che applica automaticamente le impostazioni a tutti i client connessi, ottimizzando l'uso della memoria condivisa di Kubernetes
Dynatrace
Dynatrace offre osservabilità basata sull'IA con il suo motore Davis IA, fornendo insight dal frontend al database con focus sull'esperienza utente.
App di Monitoraggio Database: Ha lanciato un'applicazione dedicata di monitoraggio dei database che fornisce visibilità unificata su tutto il patrimonio di database con punteggio proattivo della salute, analisi a livello di query che cattura i piani di esecuzione effettivi e integrazione senza soluzione di continuità che collega le prestazioni del database al monitoraggio delle applicazioni per una più rapida analisi della causa radice.
Funzionalità Davis IA Potenziate: Funzionalità IA predittive, causali e generative espanso, tra cui:
- Generazione di artefatti basata sull'IA per flussi di lavoro di risoluzione automatica (ad es. aggiustamenti delle risorse di distribuzione Kubernetes)
- Riepiloghi dei problemi in linguaggio naturale con passaggi specifici di risoluzione
- Apprendimento della base di conoscenze intelligente dagli incidenti storici per operazioni preventive
Osservabilità Aziendale: Dynatrace Intelligence posizionato come primo "agentic OS", combinando Causal IA con la topologia Smartscape per operazioni autonome. Il data lakehouse Grail fornisce un contesto unificato tra database, modelli IA, applicazioni e infrastruttura.
New Relic
New Relic tratta i database come parte del monitoraggio delle prestazioni delle applicazioni piuttosto che come infrastruttura isolata. Il loro approccio collega le chiamate del database a transazioni specifiche nel codice.
Principali differenze:
- Il tracciamento delle transazioni mostra l'intero percorso dalla richiesta dell'utente alle query del database
- L'analisi delle query lente include la riga esatta del codice dell'applicazione che ha attivato ogni query
- Operazioni della dashboard per utenti in sola lettura limitate alla visualizzazione
- Supporta MySQL, PostgreSQL, MongoDB, Redis e Elasticsearch
- Monitoraggio database potenziato con tracciamento ID Istanza RDS per Amazon RDS (migliore correlazione tra PMM e console AWS)
- Molteplici annunci di Fine Vita: regole di eliminazione eventi infrastruttura, regole di eliminazione UI IA Monitoring, grafici incorporati APM legacy
Datadog Database Monitoring
Datadog integra le metriche del database con l'intera pila delle applicazioni. Vedi le prestazioni del database insieme a log, tracce e metriche infrastrutturali nella stessa dashboard.
Principali differenze:
- Campioni di query catturano piani di esecuzione effettivi e spiegano le dichiarazioni automaticamente
- Le metriche a livello di host correlano la CPU del database con l'utilizzo delle risorse a livello di sistema
- Le tracce APM collegano le query lente a specifiche richieste dell'applicazione
- Funziona con PostgreSQL, MySQL, SQL Server, Oracle e database cloud
- Rilevamento di Regressione delle Query: Stabilisce linee di base storiche e utilizza il rilevamento delle anomalie per identificare automaticamente degradazioni delle prestazioni delle query non intenzionali nelle query utilizzate frequentemente. Il sistema esegue automaticamente diagnosi quando la durata della query aumenta inaspettatamente, aiutando a identificare e risolvere i problemi prima che impattino gli utenti.
Funzionalità Standard negli Strumenti di Monitoraggio dei Database
Ogni strumento di monitoraggio dei database traccia metriche simili, ma la profondità e la presentazione variano significativamente.
Metriche delle Prestazioni
Utilizzo CPU: Mostra il consumo di potenza di elaborazione. Quando la CPU raggiunge l'80%, il database fatica a gestire le richieste. I picchi si verificano durante query complesse o picchi di traffico.
Consumo di Memoria: Traccia l'utilizzo della RAM per la memorizzazione nella cache dei dati e dei risultati delle query. La mancanza di memoria costringe il database a leggere dal disco, che è ordini di grandezza più lento della RAM.
Tassi I/O Disco: Misura la velocità di lettura/scrittura. Un I/O elevato blocca l'intero sistema. Questo rivela se hai bisogno di archiviazione più veloce o se le query scansionano dati non necessari.
Throughput di Rete: Monitora il trasferimento di dati tra il database e le applicazioni. Un elevato utilizzo della rete può indicare un trasferimento eccessivo di dati per query.
Esecuzione delle Query
Query Lente: Identifica le query che superano le soglie di tempo (tipicamente 1-5 secondi). Una query lenta può bloccare le risorse e causare un rallentamento a livello di sistema.
Piani di Esecuzione: Mostra la strategia del database, quali indici utilizza e come unisce le tabelle. Rivela perché le query sono lente.
Conteggi delle Query: Traccia la frequenza di esecuzione. Una query moderatamente lenta eseguita 10.000 volte al minuto causa più danni di una query molto lenta eseguita una volta all'ora.
Tempi di Risposta Medi: Stabilisce le linee di base per il rilevamento del degrado delle prestazioni.
Monitoraggio delle Connessioni
Connessioni Attive: Ogni connessione consuma memoria. Troppe connessioni esauriscono le risorse.
Utilizzo del Pool di Connessioni: Traccia quanto efficientemente le applicazioni riutilizzano le connessioni. Il pooling previene l'overhead costante di apertura/chiusura.
Tentativi di Connessione Falliti: Segnala il raggiungimento del limite di connessione, problemi di rete o problemi di autenticazione.
Contenzione delle Risorse
Attese di Blocco: Una query ha bisogno di dati che un'altra query ha bloccato. La query in attesa rimane inattiva.
Deadlock: Due query attendono ciascuna i blocchi detenuti dall'altra. Il database deve ucciderne una per procedere.
Sessioni di Blocco: Mostra quali query impediscono ad altre di essere eseguite. Una lunga transazione può bloccarne dozzine.
Tracciamento dell'Archiviazione
Crescita delle Dimensioni del Database: Aiuta la pianificazione della capacità. Devi sapere quando lo spazio su disco si esaurisce.
Utilizzo dello Spazio Tabella: Identifica quali tabelle consumano la maggior parte dell'archiviazione.
Fragmentazione degli Indici: Man mano che i dati cambiano, gli indici si disperdono su disco. Gli indici frammentati rallentano le query.
Monitoraggio dei Backup
Stato del Lavoro di Backup: Conferma che i backup siano effettivamente eseguiti. I backup falliti significano nessuna opzione di recupero.
Dimensioni dei File di Backup: Traccia le dimensioni nel tempo. I cambiamenti improvvisi indicano problemi.
Obiettivi di Punto di Recupero: Misura la potenziale perdita di dati. I backup giornalieri rischiano una perdita di dati di 24 ore.
Salute della Replica
Lag tra Primario e Repliche: Mostra quanto sono indietro le repliche. Un alto lag crea dati obsoleti e problemi di coerenza.
Errori di Replica: Avvisa quando i dati non riescono a essere copiati sulle repliche, rischiando la perdita di dati.
Stato di Sincronizzazione: Conferma che le repliche ricevano attivamente aggiornamenti.
Meccanismi di Avviso
Gli strumenti inviano notifiche tramite email, Slack, PagerDuty (rotazioni di reperibilità), webhook (integrazioni personalizzate) e SMS (emergenze critiche).
Personalizzazione della Dashboard
Va da interfacce drag-and-drop (facili per i principianti) a file di configurazione JSON (potenti ma tecnici).
La differenza chiave: Tutti gli strumenti coprono queste basi. Differiscono nella profondità dell'analisi delle query, nel supporto dei database e nella qualità dell'integrazione. I nostri benchmark hanno rivelato che solo SolarWinds forniva una profilazione a livello di query, mentre gli altri mostravano solo metriche aggregate.
Analisi delle funzionalità differenzianti
Insight potenziati da IA e machine learning
SolarWinds utilizza ML per prevedere le anomalie in base ai modelli del database. L'IA Davis di Dynatrace fornisce un'analisi automatica della causa radice cross-stack, fondamentale per ambienti complessi ad alta transazione.
Monitoraggio senza agenti
LogicMonitor è l'unico strumento che offre monitoraggio senza agenti, utilizzando un collettore leggero per raccogliere dati tramite protocolli standard e API, il che semplifica la distribuzione in ambienti ibridi e cloud complessi.
Funzionalità di sicurezza e conformità
Datadog si distingue con l'oscuramento automatico dei PII e il controllo degli accessi basato sui ruoli granulare. Questo pulisce automaticamente le informazioni di identificazione personale dai dati delle query, garantendo la conformità alle normative sulla protezione dei dati per settori regolamentati (ad es. sanità, servizi finanziari).
Osservabilità full-stack
Dynatrace e New Relic forniscono visibilità oltre il database, tracciando le transazioni dalle interazioni dell'utente finale attraverso il codice dell'applicazione fino alle query del database. Questo accelera la risoluzione dei problemi fornendo una visione completa di come le prestazioni del database influenzano l'esperienza utente.
Analisi dei tempi di attesa
SolarWinds eccelle nell'analisi dei tempi di attesa, che si concentra sull'identificazione della causa radice del rallentamento del database (ad es. I/O del disco, contenzione dei blocchi) invece di riconoscere semplicemente che è lento. Questo fornisce insight più azionabili per l'ottimizzazione mirata.
Ecosistema di integrazione
Datadog guida con oltre 600 integrazioni predefinite, consentendo flussi di lavoro senza soluzione di continuità con strumenti DevOps esistenti, pipeline CI/CD e sistemi di gestione degli incidenti.
Ulteriori letture
Cita questa ricerca
Scegli il formato adatto a dove pubblicherai. Incollare la versione con link nel tuo CMS preserva il backlink.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{Migliori Strumenti di Monitoraggio delle Prestazioni dei Database: Confronto delle Top 5 Piattaforme}},
year = {2026},
month = mar,
howpublished = {\url{https://aimultiple.com/database-monitoring-tools}},
note = {AIMultiple. Consultato il 16 Marzo 2026}
}

Sii il primo a commentare
Il tuo indirizzo email non verrà pubblicato. Tutti i campi sono obbligatori. I commenti vengono lasciati nella loro lingua originale.