I 3 Migliori Generatori di Documenti Sintetici a Confronto
I generatori di documenti sintetici creano immagini di documenti annotate e realistiche che aiutano ad addestrare e valutare modelli di machine learning senza fare affidamento su grandi dataset etichettati manualmente.
Abbiamo valutato 3 generatori di documenti sintetici, Genalog, DocCreator e Tonic Textual, creando più di 2.500 documenti sintetici, confrontando la loro efficacia in termini di layout realistici, dati numerici accurati e dataset di addestramento per attività di analisi documentale.
Risultati del benchmark sulla generazione di documenti
I risultati mostrano che
- Genalog e DocCreator si comportano molto bene in termini di utilità e fedeltà, con Genalog leggermente migliore per l'accuratezza numerica.
- Tonic Textual eccelle nel realismo del layout visivo ma resta indietro in altre aree, rendendolo più adatto a compiti che richiedono documenti realistici.
Per maggiori informazioni sulle metriche, consultate la metodologia del benchmark.
- Utilità misura quanto bene i modelli addestrati su dati sintetici si comportano su documenti reali.
- Fedeltà del layout misura quanto bene la disposizione spaziale degli elementi nei documenti sintetici corrisponda a quella reale.
- Fedeltà numerica verifica se i valori numerici nei documenti sintetici assomigliano ai dati reali.
Commento sui risultati: Per comprendere meglio le differenze di prestazioni, il benchmark è stato condotto anche utilizzando il set di addestramento invece del set di test separato. Questa valutazione secondaria mirava a determinare se fornire ai modelli materiale di addestramento migliorasse la loro capacità di riprodurre output strutturati e numericamente accurati.
I risultati mostrano che, anche quando valutati sui dati di addestramento, i modelli hanno ottenuto punteggi leggermente più alti. Ciò indica che i risultati riflettono quanto bene gli strumenti gestiscano il compito stesso. I risultati moderati sono probabilmente influenzati dalle limitazioni nella qualità dell'OCR e dalla capacità del modello addestrato, piuttosto che dalla procedura di benchmark in sé.
Genalog

Genalog ha ottenuto complessivamente le migliori prestazioni. I suoi documenti sintetici sono stati molto efficaci per l'addestramento dei modelli e hanno mantenuto un buon equilibrio tra elementi di layout realistici e accuratezza numerica. I documenti generati riflettevano da vicino la struttura e la spaziatura di moduli e ricevute reali, rendendoli adatti a una varietà di attività di analisi documentale.
DocCreator

DocCreator ha anche prodotto output di alta qualità. I documenti di questo generatore sono stati quasi altrettanto utili per l'addestramento quanto quelli di Genalog. I layout erano realistici e i documenti sintetici hanno preservato le proprietà statistiche dei numeri. Il punto di forza di DocCreator risiede nella combinazione di una generazione di layout diversificati con i suoi modelli di degradazione, rendendo gli output visivamente simili a documenti reali scansionati.
Tonic Textual

Tonic Textual ha ottenuto risultati contrastanti. Sebbene questo generatore di documenti sintetici produca layout molto puliti e coerenti, i documenti sono stati meno efficaci per l'addestramento dei modelli. Inoltre, i numeri sintetici non sempre erano statisticamente simili ai dati reali. Ciò suggerisce che Tonic Textual è più adatto a compiti incentrati sull'aspetto del documento o sulla sostituzione di PII a tutela della privacy, piuttosto che sull'addestramento su larga scala per la struttura del layout e attività di estrazione di informazioni.
Nel marzo 2026, Tonic Textual ha sostituito il suo componente di collegamento delle entità da un modello basato su LLM a un modello basato su BERT per migliorare il throughput.1 La stessa versione (v391) ha inoltre aggiunto filtraggio e ordinamento migliorati nella pagina Dataset.2
Panoramica Generale
Genalog è lo strumento più equilibrato, in grado di fornire sia layout realistici che numeri accurati.
DocCreator è forte per layout complessi e diversificati e per la degradazione dei documenti, con lievi imprecisioni numeriche.
Tonic Textual è ideale per attività incentrate sul layout, ma non per quelle che richiedono dati numerici precisi.
Panoramica della Metodologia
Metriche di valutazione
Ogni dataset generato è stato valutato rispetto ai dati originali utilizzando le seguenti metriche:
Punteggio di utilità
(KIE F1 Score): Un punteggio compreso tra 0 e 1, dove più alto è meglio. È definito dal punteggio F1 del modello LayoutLMv3 addestrato sui dati sintetici quando valutato sul set di test reale. Un punteggio elevato indica che i dati sintetici sono un sostituto altamente efficace dei dati reali.
Punteggi di fedeltà
Queste metriche misurano quanto i documenti sintetici assomiglino a quelli reali.
- Fedeltà del Layout (Punteggio EMD): La Earth Mover’s Distance (dEMD) misura la differenza tra la distribuzione dei punti centrali dei riquadri di delimitazione nei documenti reali rispetto a quelli sintetici. Si tratta di un valore compreso tra 0 e 1, dove più basso è meglio. Un punteggio basso indica che gli elementi del layout spaziale sono ben conservati.
- Fedeltà Numerica (Distanza K-S): La distanza di Kolmogorov-Smirnov (DKS) misura la differenza massima tra le funzioni di distribuzione cumulativa (CDF) dei valori numerici (es. prezzi, quantità) nei dati reali e sintetici. Varia da 0 a 1, dove più basso è meglio. Un punteggio basso significa che il generatore riproduce accuratamente le proprietà statistiche dei numeri.
Tutte le metriche sono state normalizzate durante il calcolo.
Dataset
FUNSD: Una raccolta di 199 moduli scansionati caratterizzati da testo rumoroso, layout complessi e diversificati e annotazioni manoscritte. È stato scaricato più di 1.500 volte il mese scorso. Questo testa la capacità di un generatore di gestire dati non strutturati e imperfetti. 3
- Dividiamo il campione in due: l'80% dei dati viene utilizzato per l'addestramento del modello, mentre il restante 20% è riservato per i test dopo l'addestramento.
- Ogni strumento ha prodotto tra tre e sei documenti sintetici per ogni originale, per un totale di oltre 2.500 documenti sintetici.
Valutazione del compito
Per misurare l'utilità, un popolare modello LayoutLMv3 con 22K stelle su GitHub e oltre 750K download è stato addestrato sui dati sintetici generati da ciascuno strumento generatore di documenti sintetici. 4
Le prestazioni di questo modello sono state poi valutate su un set di test separato di documenti reali provenienti dai dataset originali. Questo misura direttamente quanto siano utili i dati sintetici per un compito del mondo reale.
Strumenti di generazione sintetica
Genalog
Una libreria Python open-source di Microsoft per generare immagini di documenti sintetici con rumore sintetico. Funziona prendendo testo + modelli di layout (scritti in HTML + CSS) e renderizzandoli tramite WeasyPrint, quindi applicando effetti di degradazione (sfocatura, trapelazione, rumore sale e pepe, operazioni morfologiche).5
DocCreator
Uno strumento multipiattaforma open-source per generare immagini di documenti sintetici con relative verità sul terreno. È stato ampiamente utilizzato nella ricerca sull'analisi e il riconoscimento di immagini di documenti (DIAR).6 ,7
Tonic Textual
Una soluzione per la redazione e la sintesi in formati di documenti reali (PDF, Word). Afferma di scansionare documenti non strutturati, identificare entità nominate (es. PII), redigerle o sostituirle con valori sintetici, e produrre documenti anonimizzati in formati simili.
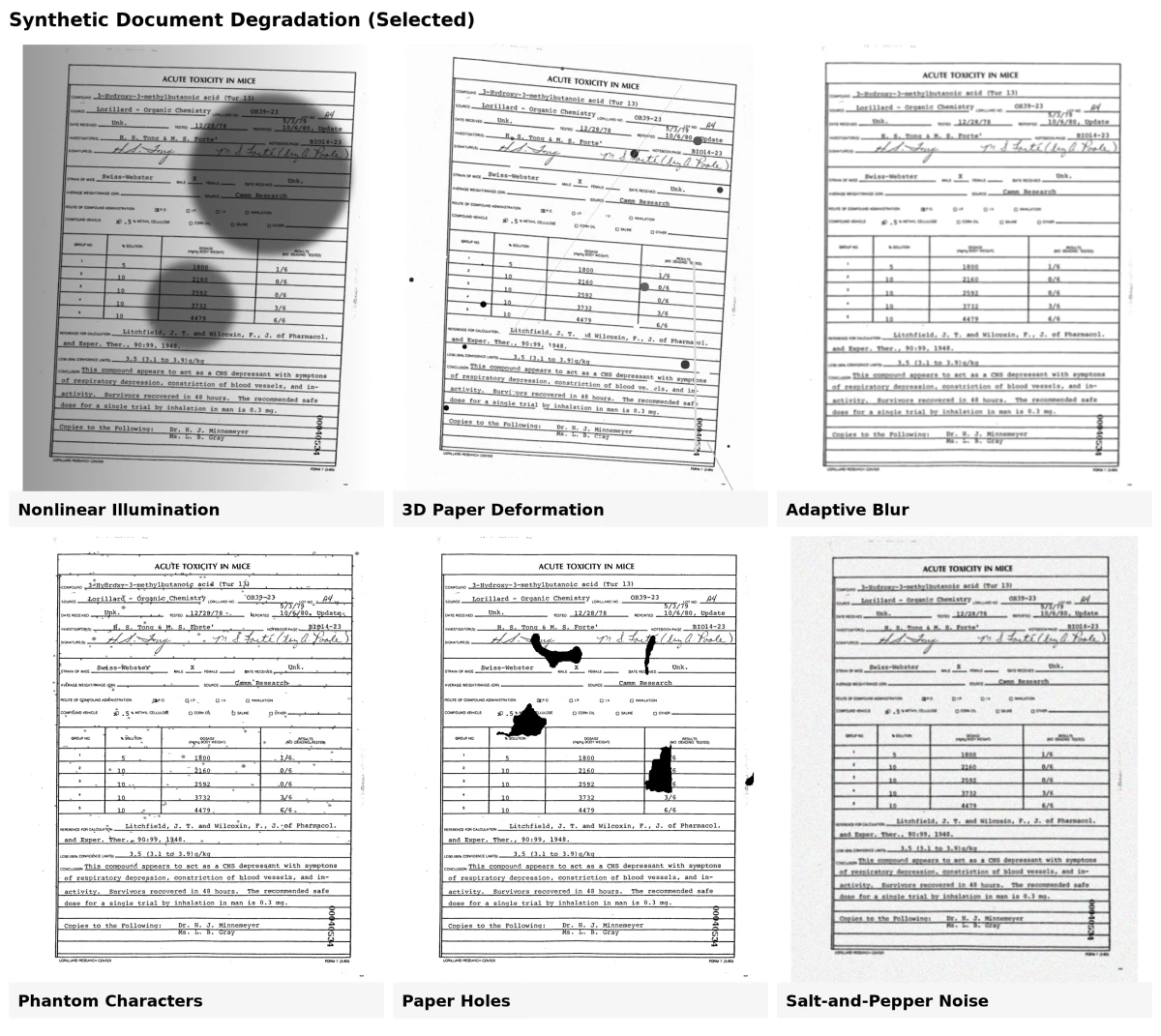
8 Metodi di degradazione dei documenti sintetici
La generazione di documenti sintetici spesso include l'aggiunta di difetti realistici per far sì che i dati artificiali assomiglino ai documenti del mondo reale. Questi difetti, o modelli di degradazione, aiutano ad addestrare modelli che funzionano meglio su documenti rumorosi, invecchiati o scansionati. Questi strumenti applicano diverse trasformazioni fisiche e visive per simulare le comuni imperfezioni dei documenti.8
1. Degradazione dell'inchiostro
Questo modello simula lo sbiadimento, le macchie o le strisce causate dall'invecchiamento o dalla stampa di bassa qualità. Aggiunge piccole macchie di inchiostro o rimuove parti di lettere per imitare il decadimento reale dell'inchiostro.
2. Caratteri fantasma
I vecchi strumenti di stampa spesso lasciavano contorni tenui o segni “fantasma” attorno alle lettere. Il modello di caratteri fantasma li ricrea inserendo difetti estratti da scansioni reali tra i caratteri stampati.
3. Fori sulla carta
Vengono aggiunti casualmente ai documenti fori di diverse forme e dimensioni, replicando strappi o segni di perforazione presenti su carte usurate.
4. Trapelazione
Questo effetto imita l'inchiostro che trapela dal retro della pagina. Utilizza sia l'immagine anteriore che quella posteriore di un documento per ricreare il modo in cui l'inchiostro si trasferisce parzialmente attraverso la carta.
5. Sfocatura adattiva
La scansione o la fotografia di documenti spesso crea una leggera sfocatura. Questo modello confronta esempi reali sfocati e applica una sfocatura simile utilizzando filtri gaussiani, mantenendo il risultato sottile e realistico.
6. Deformazione 3D della carta
I documenti possono piegarsi, piegarsi o curvarsi quando vengono scansionati o fotografati. Utilizzando mesh 3D di carte reali, questo modello ricrea queste forme ed effetti di illuminazione, aiutando ad addestrare modelli per l'analisi documentale basata su telecamera.
7. Illuminazione non lineare
Un'illuminazione non uniforme durante la scansione può far apparire un lato di un documento più scuro. Questo modello regola la luminosità in base agli angoli di luce simulati e alla curvatura della pagina, riproducendo l'effetto di una scarsa illuminazione.
8. Rumore sale e pepe
Aggiunge pixel casuali bianchi e neri per simulare polvere, texture della carta o rumore del sensore di scansione. Questo effetto “sale e pepe” aiuta a creare l'aspetto granuloso di scansioni digitali invecchiate o di bassa qualità.
Generazione sintetica di documenti come soluzione per le sfide dell'analisi del layout
La sfida dell'analisi del layout
Comprendere la struttura dei documenti è più difficile che leggere il testo. Gli strumenti di OCR possono estrarre parole, ma non spiegano il ruolo di ciascun blocco, come titoli, tabelle o figure.
Per affrontare questa sfida, sono stati sviluppati dei metodi:
I metodi iniziali per l'analisi del layout erano basati su regole. Si basavano su regole geometriche e analisi della texture per suddividere le pagine in blocchi. Sebbene utili, questi approcci richiedevano una pesante regolazione manuale e non generalizzavano bene.
Gli approcci di machine learning come le Support Vector Machines (SVM) e i modelli di miscela gaussiana (GMM) hanno migliorato questo aspetto imparando dai dati.9 Tuttavia, dipendevano ancora da caratteristiche progettate manualmente e avevano difficoltà con la diversità dei documenti del mondo reale.
Il deep learning ha trasformato il campo. Le reti neurali convoluzionali (CNN) hanno reso possibile trattare il riconoscimento del layout come il rilevamento di oggetti, identificando tabelle, figure o formule nello stesso modo in cui i modelli rilevano oggetti nelle immagini naturali.10 Alcuni modelli combinano anche caratteristiche testuali e immagini per risultati più accurati.
La sfida del deep learning: richiede grandi dataset etichettati per l'addestramento.
Dati sintetici come soluzione: Il processo di generazione sintetica dei documenti offre un modo scalabile per creare dati di addestramento annotati senza il costo dell'etichettatura manuale.
I modelli generativi offrono ora possibilità più avanzate. Gli autoencoder variazionali (VAE), i modelli basati sull'attenzione e le GAN possono apprendere modelli strutturali di documenti e produrre nuovi layout realistici.11
Differenze Chiave tra i Generatori di Documenti Sintetici
I tre generatori di documenti sintetici messi a confronto differiscono per focus, qualità dell'output e usabilità:
- Genalog: Il migliore equilibrio tra layout realistici e accuratezza numerica. Il suo flusso di lavoro basato su Python con modelli HTML/CSS e modelli di degradazione lo rende ideale per l'addestramento di modelli di machine learning in diverse attività di analisi documentale.
- DocCreator: Forte nella generazione di documenti visivamente complessi e degradati, preservando la diversità del layout. Leggermente meno accurato numericamente di Genalog, ma efficace per compiti che richiedono una simulazione realistica di documenti scansionati.
- Tonic Textual: Eccelle nei layout puliti e visivamente coerenti e nella sintesi di dati per la tutela della privacy. Meno adatto per l'accuratezza numerica o dataset di addestramento completi, rendendolo migliore per attività incentrate sul layout o la sostituzione di PII.
Queste differenze riflettono i loro approcci principali: Genalog bilancia realismo e fedeltà dei dati, DocCreator enfatizza la varietà del layout e la degradazione dei documenti, e Tonic Textual dà priorità all'aspetto e alla privacy. Ciò aiuta gli utenti a selezionare lo strumento giusto in base a se la priorità è l'efficacia dell'addestramento, il realismo del layout o la de-identificazione dei dati.
Altri generatori di documenti sintetici comunemente utilizzati
YData SDK: Offre un generatore di documenti sintetici in grado di produrre documenti sintetici di alta qualità nei formati PDF, DOCX o HTML, spesso utilizzato per aggirare gli ostacoli di conformità alla privacy.12
DoGe: Uno strumento open-source specificamente progettato per sintetizzare scansioni realistiche di documenti con testo, intestazioni e tabelle significativi per l'addestramento di Document IA.13
DocXPand: Specializzato nella generazione di documenti d'identità (passaporti, carte d'identità) basati su standard ISO, riempiendo modelli con informazioni false e volti generati dall'IA.14
Ulteriori letture
- Benchmark e Migliori Pratiche per la Generazione di Dati Sintetici
- I 25 Migliori Casi d'Uso dei Dati Sintetici
- Utenti Sintetici Spiegati: I 7 Migliori Strumenti di Ricerca sugli Utenti Basati sull'IA
Cita questo benchmark
Scegli il formato adatto a dove pubblicherai. Incollare la versione con link nel tuo CMS preserva il backlink.
@misc{phd2026,
author = {PhD., Ezgi Arslan,},
title = {{I 3 Migliori Generatori di Documenti Sintetici a Confronto}},
year = {2026},
month = mar,
howpublished = {\url{https://aimultiple.com/synthetic-document-generator}},
note = {AIMultiple. Consultato il 18 Marzo 2026}
}
Sii il primo a commentare
Il tuo indirizzo email non verrà pubblicato. Tutti i campi sono obbligatori. I commenti vengono lasciati nella loro lingua originale.