Benchmark degli Strumenti di Revisione del Codice IA
Con il crescente utilizzo degli strumenti di codifica IA, i codebase sono diventati più inclini alle vulnerabilità, il che ha aumentato la necessità di revisioni del codice efficaci. Per affrontare questo problema, introduciamo RevEval (IA Code Review Eval), che confronta i quattro migliori strumenti di revisione del codice IA su 309 pull request provenienti da repository di dimensioni variabili e ne valuta le prestazioni utilizzando il contributo di 10 sviluppatori e un LLM-as-a-judge.
Risultati del Benchmark
CodeRabbit si è classificato come lo strumento di revisione del codice di maggior successo nel 51% delle 309 PR:
Per misurare la classifica abbiamo utilizzato i punteggi LLM-as-a-judge. Abbiamo esaminato quale strumento di revisione del codice IA ha ottenuto il punteggio più alto in ogni PR (valutata utilizzando il nostro LLM-as-a-judge), e poi calcolato la percentuale di tutte le PR in cui ciascuno strumento si è classificato primo.
CodeRabbit ha ottenuto i punteggi più alti sia nelle valutazioni manuali umane che nelle valutazioni LLM-as-a-judge, seguito da Greptile e GitHub Copilot:
Nel calcolare il punteggio medio, tutte e tre le categorie di valutazione sono state ponderate equamente. I punteggi dei repository grandi e dei repository piccoli sono stati valutati da LLM-as-a-judge, e le valutazioni degli sviluppatori sono state completate manualmente per verificare i punteggi LLM-as-a-judge.
Valutazioni umane
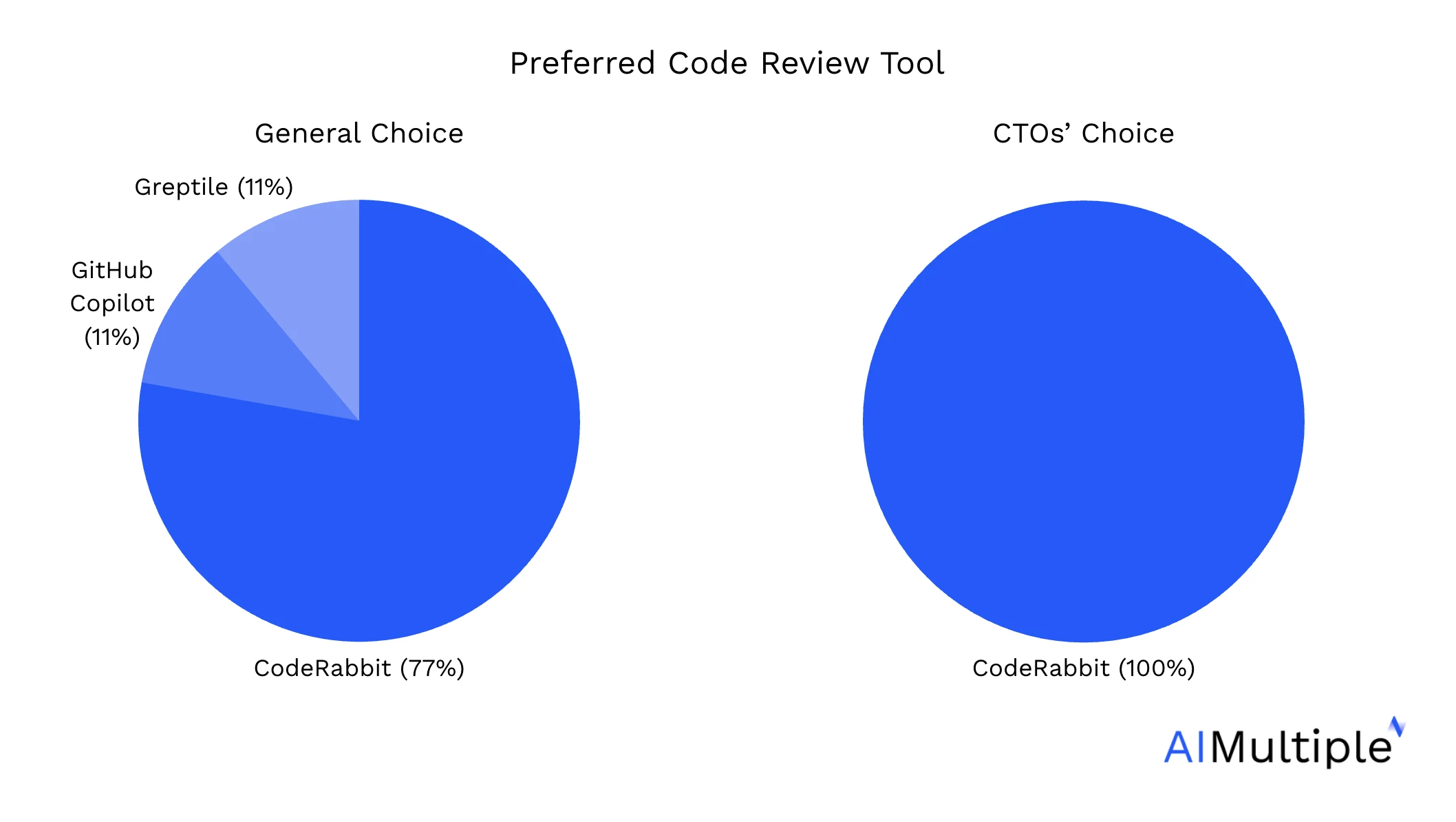
Abbiamo chiesto agli sviluppatori che hanno partecipato alle valutazioni quale strumento di revisione del codice IA preferirebbero integrare nei loro flussi di lavoro. Poiché i CTO svolgono un ruolo decisionale chiave nello sviluppo software, abbiamo evidenziato le loro risposte in un grafico separato:
Confronto dettagliato
Abbiamo calcolato il numero medio di bug per PR contando tutti i bug/problemi segnalati da ciascuno strumento di revisione del codice e dividendolo per il numero totale di PR (309). Non tutte le PR nel nostro codebase contengono bug o problemi. GitHub Copilot non segnala esplicitamente quando rileva un bug in una PR; pertanto, è stato escluso da questo confronto.
Puoi consultare la nostra metodologia qui sotto.
Funzionalità
* È fornito dalla funzionalità "agentic pre-merge checks" di CodeRabbit. Convalida automaticamente le pull request rispetto agli standard di qualità e ai requisiti organizzativi personalizzati prima del merge, e restituisce risultati pass/fail con spiegazioni direttamente nel walkthrough della PR. Ogni controllo può essere configurato per avvisare gli sviluppatori o bloccare completamente i merge. Mentre GitHub Copilot, Cursor BugBot e Greptile forniscono funzionalità di revisione delle PR, funzionano come sistemi consultivi che offrono feedback e suggerimenti piuttosto che framework di validazione sistematici.
** Cursor e GitHub Copilot possono offrire più funzionalità oltre ai loro componenti di revisione del codice; solo le funzionalità di Cursor Bugbot e GitHub Copilot Code Review sono incluse nel nostro confronto.
Le funzionalità variano a seconda dei piani di abbonamento, quindi alcune funzionalità contrassegnate come disponibili sopra potrebbero non essere disponibili nel tuo abbonamento.
Nelle revisioni del codice automatizzate, CodeRabbit, GitHub Copilot e Cursor Bugbot sono stati più facili da configurare rispetto a Greptile perché le revisioni automatizzate del codice non possono essere abilitate per un repository vuoto in Greptile.
Analisi approfondita delle funzionalità
CodeRabbit
- 40+ linter e scanner di sicurezza integrati.
- Istruzioni personalizzate basate su pattern AST.
- Si adatta nel tempo in base al feedback degli sviluppatori.
- Gli sviluppatori possono taggare @coderabbitai per porre domande di follow-up, richiedere correzioni, mettere in discussione i suggerimenti.
- Supporta server MCP personalizzati per contesto aggiuntivo.
GitHub Copilot Code Review
- Il pulsante "Implementa suggerimento" passa all'agente di codifica Copilot.
- Integrazione stretta con l'ecosistema GitHub.
- Istruzioni personalizzate tramite copilot-instructions.md.
Greptile
- Apprende gli standard di codifica del team dalla cronologia dei commenti sulle PR.
- Con i repository di pattern, gli sviluppatori possono fare riferimento a repository correlati in greptile.json in modo da fornire contesto aggiuntivo.
- Gli sviluppatori possono rispondere con @greptileai per domande di follow-up o suggerimenti di correzione.
- Greptile apprende dai feedback thumbs up/down.
- Diagrammi di sequenza auto-generati per tutte le PR.
Cursor BugBot
- Dopo che un bug è stato identificato da BugBot, gli sviluppatori possono utilizzare il pulsante "Correggi in Cursor" per aprire rapidamente Cursor e correggere il bug.
- Gli sviluppatori possono personalizzare le regole di revisione del codice nei file BUGBOT.md.
Avevamo anche intenzione di confrontare Graphite; tuttavia, a causa di un bug nella loro dashboard, non siamo stati in grado di abilitare le revisioni automatizzate del codice per i nuovi repository. Abbiamo contattato il loro team di supporto il 25 ottobre 2025, ma la risposta non ha risolto il problema. Nonostante le email di follow-up e un messaggio nel loro canale Slack, il problema è rimasto irrisolto.
Componenti e integrazioni
* Tutte queste soluzioni supportano GitHub.
Metodologia
Abbiamo creato repository di benchmark separati per ciascuno strumento all'interno della nostra organizzazione GitHub dedicata.
Dopo aver abilitato le revisioni automatiche del codice per ciascuno strumento nel suo repository assegnato, abbiamo aperto le pull request in sequenza, abbiamo atteso che lo strumento completasse la sua revisione e poi abbiamo chiuso le PR per registrare i risultati. Non abbiamo modificato o regolato alcuna impostazione dello strumento. Ogni strumento è stato valutato utilizzando la sua configurazione predefinita, esattamente come installato.
Il nostro flusso di lavoro inizia clonando il repository sorgente così come esisteva in una data di base selezionata, quindi riproducendo le pull request inviate dopo quella data una per una, preservando la struttura originale del repository.
Abbiamo utilizzato le versioni di novembre 2025 di tutti i prodotti. Il nostro benchmark consisteva in 2 diverse gamme di repository sorgente:
1. Repository noti, di dimensioni medio-grandi
Abbiamo voluto vedere quanto bene gli strumenti di revisione del codice IA comprendono i repository con strutture grandi e complesse. Abbiamo esaminato complessivamente 289 PR su 7 repository.
2. Repository piccoli e nuovi
Siamo consapevoli che non possiamo fornire al nostro LLM-as-a-judge l'
intero repository nei repository grandi, poiché le loro finestre di contesto non sono sufficienti per farlo. Pertanto, per superare questo limite, abbiamo anche valutato le prime 3-5 PR di repository nuovi e piccoli. I server MCP si adattano perfettamente alle nostre esigenze. Di conseguenza, abbiamo scelto 8 server MCP ufficiali e abbiamo fatto revisionare 20 PR su di essi.
Il nostro dataset contiene codice scritto da sviluppatori esperti. Non abbiamo valutato le prestazioni su codebase interamente generati dall'IA.
Valutazioni degli Sviluppatori
Abbiamo selezionato casualmente 35 PR e le abbiamo assegnate a 10 sviluppatori, con ogni PR valutata 5 volte dagli sviluppatori. Il nostro obiettivo nel ripetere la valutazione era minimizzare il bias degli sviluppatori. Gli sviluppatori hanno valutato i risultati in modo agnostico rispetto al fornitore.
La maggior parte di loro ha raggiunto le stesse intuizioni di alto livello:
- Le revisioni dettagliate di CodeRabbit sono utili ed è efficace nel rilevamento dei bug.
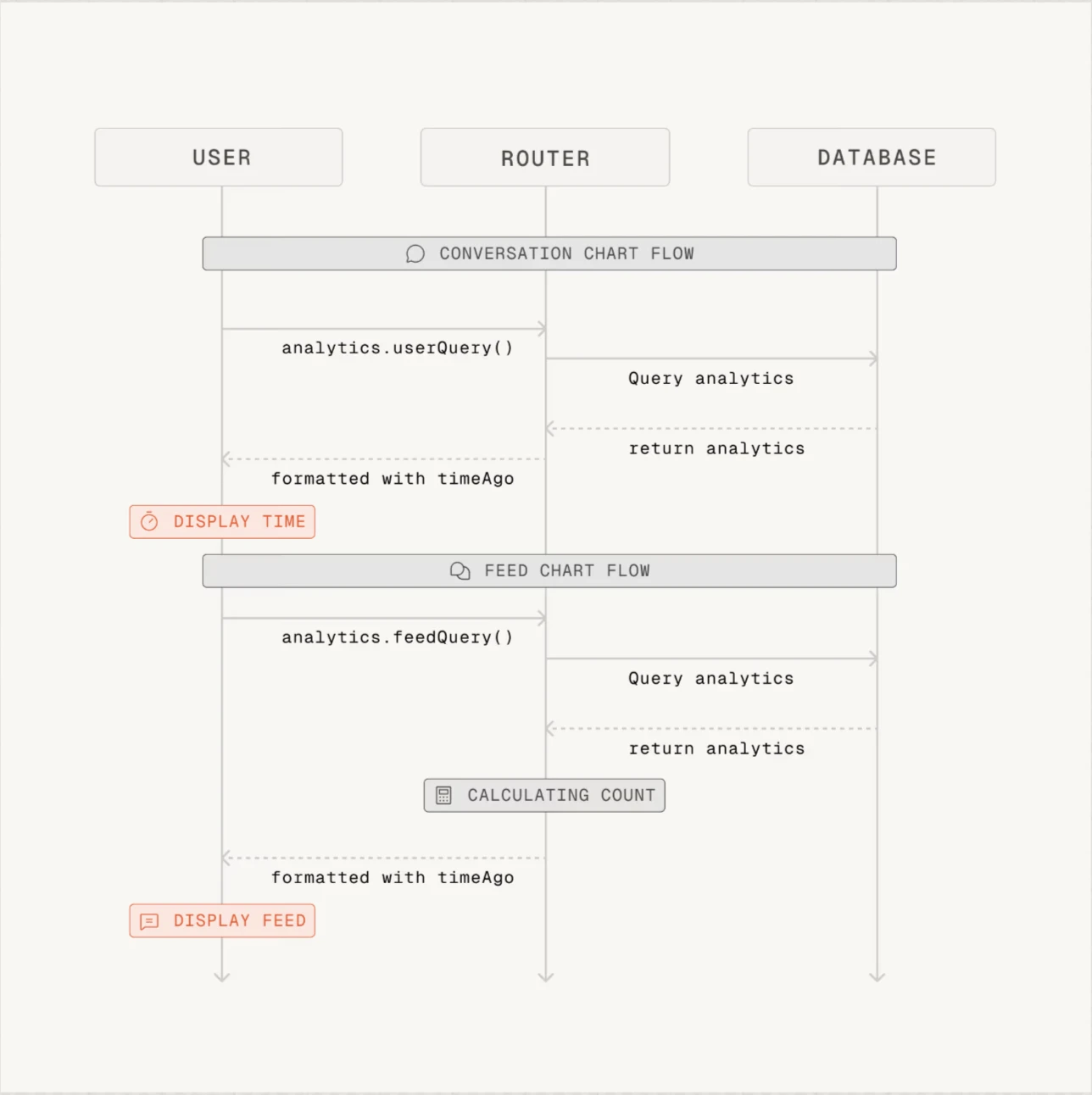
- Greptile ha fornito riepiloghi efficaci, ma i diagrammi di sequenza generati non sono necessari per alcune PR.
Figura 1: Esempio di diagramma di sequenza fornito da Greptile. Greptile genera i diagrammi per ogni PR.1
- GitHub Copilot è molto efficace nel trovare errori di battitura nel codice e fornisce suggerimenti azzeccati; la sua analisi è più breve di quelle di CodeRabbit e Greptile.
- Cursor Bugbot fornisce un'analisi meno dettagliata e meno accurata.
Dopo le valutazioni, hanno anche dichiarato che inizieranno a usarli nei propri repository come strumento di supporto per gli sviluppatori.
LLM-as-a-Judge
Abbiamo utilizzato GPT-5 per valutare le revisioni. Dopo la valutazione, abbiamo utilizzato GPT-4o per strutturare l'output in formato JSON.
Il nostro flusso di lavoro di valutazione include:
- Per i repository grandi: Il corpo della PR originale, il diff e i commenti/revisioni degli strumenti.
- Per i repository piccoli: L'intero codebase, il corpo della PR originale, il diff e i commenti/revisioni degli strumenti.
Ecco il prompt completo che abbiamo utilizzato:
Valuta ogni strumento su queste dimensioni (scala 1-5):
1. Correttezza
I problemi identificati sono realmente problemi/bug/correzioni reali nel codice?
– 5 (Eccellente): Tutti i problemi identificati sono problemi reali
– 4 (Buono): La maggior parte dei problemi sono reali, piccole identificazioni errate
– 3 (Accettabile): Mix di problemi reali e discutibili
– 2 (Scarso): La maggior parte dei problemi identificati non sono problemi reali
– 1 (Fallito): Impossibile identificare problemi reali, tutti i risultati sono errati
2. Completezza
Ha individuato i problemi importanti? Quanto è completa la revisione?
– 5 (Eccellente): Individua tutti i problemi critici e la maggior parte di quelli importanti.
– 4 (Buono): Individua i problemi principali, ne perde alcuni minori
– 3 (Accettabile): Individua alcuni problemi importanti ma presenta lacune notevoli
– 2 (Scarso): Perde diversi problemi critici
– 1 (Fallito): Perde tutti o quasi tutti i problemi critici
3. Attuabilità
I suggerimenti sono chiari e implementabili? Include patch/correzioni? Se non ci sono bug nel codice, scrivi "null" in attuabilità per tutti gli strumenti, non assegnare alcun punteggio a nessuno strumento per quella PR.
– 5 (Eccellente): Tutti i suggerimenti includono patch/correzioni chiare e sono direttamente implementabili
– 4 (Buono): La maggior parte dei suggerimenti ha una guida chiara, alcuni includono patch
– 3 (Accettabile): I suggerimenti sono abbastanza chiari ma mancano patch per alcuni problemi
– 2 (Scarso): I suggerimenti sono per lo più poco chiari o non implementabili
– 1 (Fallito): Nessun suggerimento o guida chiara fornita
4. Profondità
Dimostra comprensione della logica e dello scopo del codice?
– 5 (Eccellente): Dimostra una profonda comprensione della logica del codice, dell'architettura e dello scopo
– 4 (Buono): Mostra una buona comprensione con piccole lacune
– 3 (Accettabile): Comprensione superficiale, perde parte del contesto
– 2 (Scarso): Spiegazioni superficiali o errate del comportamento del codice
– 1 (Fallito): Nessuna comprensione della logica e dello scopo del codice
Formato di Output
Per ogni strumento, fornisci:
1. Ragionamento dettagliato: Cosa ha trovato? Ha perso problemi importanti? Patch incluse? Comprensione approfondita del codebase? Esempi specifici.
2. Punteggi individuali (1-5 per ogni dimensione, usando la scala sopra)
Esempio di Output
Strumento A:
Ragionamento: Lo Strumento A ha dimostrato un'eccellente correttezza identificando una vera perdita di memoria nella logica di pooling delle connessioni alla riga 145, fornendo una patch specifica utilizzando un context manager. Ha anche individuato la gestione degli errori mancante nell'endpoint API con codice attuabile. Il punteggio di completezza riflette che, sebbene abbia trovato i problemi principali, ha perso la race condition nel gestore asincrono che potrebbe causare problemi in produzione. Tutti e 4 i commenti erano sostanziali e direttamente implementabili. La profondità è stata forte, mostrando una comprensione dei modelli di gestione delle risorse e della propagazione degli errori nel codebase.
Correttezza: 5
Completezza: 4
Attuabilità: 5
Profondità: 4
Strumento B:
Ragionamento: Lo Strumento B ha identificato correttamente la vulnerabilità di validazione dell'input alla riga 89 e ha fornito una chiara correzione utilizzando la sanitizzazione dei parametri. Tuttavia, la completezza ha sofferto significativamente poiché ha perso la vulnerabilità di sicurezza critica nel flusso di autenticazione che consente il riutilizzo dei token. L'attuabilità è stata per lo più buona – i suggerimenti includevano frammenti di codice. La profondità è stata accettabile ma superficiale, concentrandosi su controlli a livello di superficie piuttosto che comprendere il modello di sicurezza o le implicazioni del flusso di dati.
Correttezza: 4
Completezza: 1
Attuabilità: 4
Profondità: 2
Strumenti da valutare: CodeRabbit, Cursor Bugbot, Github Copilot, Greptile
Sii obiettivo e approfondito. Usa esempi specifici dalle revisioni per supportare i tuoi punteggi.
Che cos'è la revisione del codice IA?
La revisione del codice IA è l'analisi automatizzata del codice sorgente utilizzando modelli di machine learning, principalmente large language model (LLM), per identificare bug, inefficienze e potenziali vulnerabilità. Oltre a rilevare i problemi, questi sistemi possono fornire spiegazioni consapevoli del contesto, suggerire correzioni concrete e generare patch che aiutano gli sviluppatori a migliorare sia la qualità che la manutenibilità del codice. Molti strumenti di revisione IA assistono anche con la documentazione riepilogando le modifiche e producendo commenti descrittivi o spiegazioni per il codice appena aggiunto.
Poiché i modelli IA possono valutare il codice rapidamente e su larga scala, accelerano significativamente il processo di revisione e rendono più facile individuare i problemi tempestivamente mantenendo standard di codifica coerenti in progetti grandi o in rapida evoluzione.
Nei moderni ambienti di sviluppo assistiti dall'IA come Cursor o Claude Code, gli sviluppatori possono involontariamente perdere traccia di come evolve il loro codebase durante il "vibe coding" o quando fanno molto affidamento su suggerimenti auto-generati. Questo può introdurre vulnerabilità nascoste o incoerenze logiche. Gli strumenti di revisione del codice IA aiutano a mitigare questi rischi fornendo un ulteriore livello di analisi strutturata e sistematica per convalidare e migliorare il codice generato dall'IA.
Vantaggi della revisione del codice IA
Efficienza e velocità
Gli strumenti di revisione del codice IA possono analizzare il codice in tempo reale, fornendo feedback immediato e segnalando potenziali problemi mentre gli sviluppatori lavorano. Sono in grado di rilevare errori e vulnerabilità di sicurezza che i revisori umani potrebbero trascurare, in particolare nei codebase grandi o in rapida evoluzione. Automatizzando i controlli di routine, questi strumenti consentono agli sviluppatori di concentrarsi sul ragionamento di livello superiore, sulla risoluzione di problemi complessi e sulle decisioni architetturali.
Migliore qualità del codice
Gli strumenti di revisione del codice IA aiutano a mantenere standard di codifica coerenti tra i team identificando incoerenze stilistiche e deviazioni dalle migliori pratiche. Offrono anche feedback dettagliati e raccomandazioni su un'ampia gamma di problemi di codifica, dai miglioramenti minori ai bug significativi. Nel tempo, gli sviluppatori possono imparare da questo feedback, affinare le loro abitudini di codifica e adottare nuove tecniche che rafforzano la qualità complessiva del loro lavoro.
Limitazioni e sfide
Eccessiva dipendenza dagli strumenti IA
Una preoccupazione comune con la revisione del codice IA è l'eccessiva dipendenza dal feedback automatizzato. Sebbene l'IA possa essere una preziosa fonte di approfondimenti, non dovrebbe essere trattata come un sostituto completo dell'esperienza umana. Le revisioni automatizzate possono accelerare i flussi di lavoro, ma i revisori umani rimangono essenziali per garantire correttezza, consapevolezza del contesto e allineamento con gli obiettivi del progetto. Nel nostro benchmark, gli sviluppatori hanno costantemente affermato che non si affiderebbero a questi strumenti ciecamente. Li consideravano assistenti che integrano il giudizio umano piuttosto che sostituirlo.
Gestione dei falsi positivi e dei falsi negativi
I falsi positivi si verificano quando lo strumento identifica erroneamente il codice funzionante come problematico, mentre i falsi negativi si verificano quando i problemi reali non vengono rilevati. Nella nostra valutazione, la preoccupazione più significativa sono stati i falsi negativi. Gli strumenti erano più propensi a trascurare problemi importanti che a sollevare avvisi errati. Questo evidenzia la necessità di un miglioramento continuo nei modelli e negli algoritmi sottostanti.
Per affrontare queste sfide, gli strumenti di revisione del codice IA devono evolversi attraverso un migliore addestramento, una gestione del contesto potenziata e capacità di ragionamento più accurate.
Migliori pratiche per l'utilizzo delle revisioni del codice IA
Consigli dagli esperti
Abbina le revisioni IA agli approfondimenti umani: Usa le revisioni del codice IA insieme alle revisioni umane per garantire che il codice sia tecnicamente solido che allineato agli obiettivi del progetto.
Personalizza le regole per adattarle al tuo progetto: Regola le regole dello strumento IA per corrispondere agli standard di codifica del tuo progetto per ridurre gli avvisi non necessari.
Usa il feedback IA come strumento di apprendimento: Tratta i suggerimenti dell'IA come un modo per imparare e migliorare, discutendoli con il tuo team per capire perché e come evitare problemi simili in futuro.
Ringraziamenti
Estendiamo la nostra sincera gratitudine agli sviluppatori che hanno contribuito con il loro tempo e la loro esperienza per eseguire le valutazioni manuali:
Aziz Durmaz (CTO presso un'azienda di trasporti e logistica)
Berk Kalelioğlu (co-fondatore di uno studio di sviluppo di giochi)
Elif Ece Örnek (ingegnere software presso un sito web di viaggi)
Haydar Külekçi (consulente presso un'azienda di tecnologie di ricerca e IA)
Mehmet Şirin Can (responsabile dello sviluppo presso AIMultiple)
Mehmet Korkmaz (CTO presso un'azienda media nel settore degli e-sport e dei videogiochi)
Murat Orno (ex CTO presso una piattaforma di pagamento regionale con più di 500 dipendenti)
Orçun Candan (sviluppatore full-stack presso AIMultiple)
Yalçın Börlü (ingegnere software senior presso un'azienda di salute e benessere)
Yiğit Dinç (co-fondatore di un'azienda di tecnologia legale)
Ringraziamo anche gli sviluppatori e i maintainer dei repository open-source inclusi nel nostro benchmark per il loro lavoro e i preziosi contributi alla comunità.
Anonimizzazione delle identità originali degli sviluppatori
Per condurre il benchmark in modo responsabile, abbiamo anonimizzato tutti i nomi e gli indirizzi email originali degli sviluppatori durante la riproduzione delle pull request dai repository upstream. Poiché i repository del benchmark sono pubblici, preservare le informazioni originali degli autori potrebbe esporre involontariamente dati personali e creare il rischio di notificare gli sviluppatori ogni volta che una pull request ricreata viene aperta o aggiornata. Sebbene GitHub in genere non notifichi gli autori quando i loro commit vengono riprodotti in un repository separato, abbiamo ritenuto una buona pratica evitare qualsiasi possibilità di notifiche indesiderate, problemi di attribuzione o preoccupazioni sulla privacy.
L'anonimizzazione garantisce che:
- Gli sviluppatori non vengano disturbati da migliaia di eventi PR automatizzati.
- Le informazioni personali non vengano ripubblicate in un diverso repository pubblico.
- I benchmark rimangano imparziali, impedendo che gli strumenti o i giudici LLM siano influenzati da nomi di autori riconoscibili.
- Gli standard etici e di privacy siano mantenuti quando si lavora con contributi open-source.
Solo i metadati dell'identità sono stati alterati; tutto il codice, i diff, l'ordinamento dei commit e le strutture dei file sono stati preservati esattamente per mantenere l'autenticità e la riproducibilità del benchmark.
Cita questo benchmark
Scegli il formato adatto a dove pubblicherai. Incollare la versione con link nel tuo CMS preserva il backlink.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Alper, Şevval},
title = {{Benchmark degli Strumenti di Revisione del Codice IA}},
year = {2026},
month = mar,
howpublished = {\url{https://aimultiple.com/ai-code-review-tools}},
note = {AIMultiple. Consultato il 13 Marzo 2026}
}
Sii il primo a commentare
Il tuo indirizzo email non verrà pubblicato. Tutti i campi sono obbligatori. I commenti vengono lasciati nella loro lingua originale.