15 Strumenti di Osservabilità degli Agenti IA: AgentOps & Langfuse
Gli strumenti di osservabilità degli agenti IA, come Langfuse e Arize, aiutano a raccogliere tracce dettagliate (una registrazione dell'esecuzione di un programma o transazione) e forniscono dashboard per monitorare le metriche in tempo reale.
Molti framework per agenti, come LangChain, utilizzano lo standard OpenTelemetry per condividere metadati con il monitoraggio agentico. Inoltre, molti strumenti di osservabilità forniscono strumentazione personalizzata per una maggiore flessibilità.
Abbiamo testato 15 piattaforme di osservabilità per applicazioni LLM e agenti IA. Ogni piattaforma è stata implementata manualmente configurando flussi di lavoro, integrazioni e scenari di test. Abbiamo confrontato le prestazioni di 4 strumenti di osservabilità per misurare se introducono overhead nei pipeline di produzione. Abbiamo anche mostrato un tutorial sull'osservabilità di LangChain utilizzando Langfuse.
Benchmark dell'overhead degli strumenti di monitoraggio agentico
Abbiamo integrato ciascuna piattaforma di osservabilità nel nostro sistema di pianificazione viaggi multi-agente ed eseguito 100 query identiche per misurare il loro overhead prestazionale rispetto a una baseline senza strumentazione. Leggi la nostra metodologia di benchmark.
- LangSmith ha dimostrato un’eccezionale efficienza con praticamente nessun overhead misurabile, rendendolo ideale per ambienti di produzione critici per le prestazioni.
- Laminar ha introdotto un overhead minimo pari al 5%, rendendolo altamente adatto per ambienti di produzione in cui le prestazioni sono critiche.
- AgentOps e Langfuse hanno mostrato un overhead moderato rispettivamente del 12% e del 15%, rappresentando un compromesso ragionevole tra funzionalità di osservabilità e impatto sulle prestazioni. Queste piattaforme mantengono comunque una latenza accettabile per la maggior parte dei casi d'uso in produzione.
Possibili ragioni alla base delle differenze di prestazioni
Il nostro benchmark indica che le differenze di latenza sono determinate dalla profondità della strumentazione e dal coinvolgimento nel percorso di esecuzione, in particolare nei flussi di lavoro multi-agente. Gli strumenti che offrono un'osservabilità più profonda a livello di passaggi hanno mostrato un overhead maggiore, mentre approcci di tracciamento più leggeri sono rimasti più vicini alla baseline.
1. Profondità della strumentazione sul percorso di esecuzione
Gli strumenti di osservabilità aggiungono logica al flusso di esecuzione dell'agente per catturare tracce e metadati. Quando questa logica viene eseguita in modo sincrono durante la gestione della richiesta, aumenta direttamente la latenza end-to-end perché l'agente deve completare questo lavoro extra prima di restituire una risposta.
Ad esempio:
- LangSmith non ha aggiunto praticamente nessun overhead misurabile (~0%), indicando poco lavoro sincrono,
- la strumentazione più profonda a livello di passaggi di Langfuse ha contribuito a un overhead maggiore (~15%).
2. Amplificazione degli eventi attraverso pipeline a più passaggi
Nei sistemi multi-agente, una singola richiesta utente innesca molteplici azioni dell'agente. Quando uno strumento registra dati dettagliati ad ogni passaggio, il numero totale di eventi cresce rapidamente, aumentando l'overhead di elaborazione e gestione delle tracce man mano che il flusso di lavoro diventa più profondo.
Nei risultati del benchmark:
- Langfuse e AgentOps hanno generato un overhead notevolmente più alto (15% e 12%) nel nostro flusso di lavoro di pianificazione viaggi a più passaggi
- LangSmith e Laminar hanno emesso meno eventi per ogni passaggio dell'agente.
3. Overhead di valutazione e convalida in linea
Alcune piattaforme eseguono controlli o monitoraggi aggiuntivi mentre l'agente è in esecuzione. Sebbene ogni controllo sia leggero, applicarli ripetutamente su tutti i passaggi dell'agente aggiunge latenza misurabile.
Ad esempio:
- il monitoraggio a livello di ciclo di vita di AgentOps ha coinciso con un overhead del 12%
- Laminar non ha mostrato evidenze di valutazioni in linea che influenzassero l'esecuzione, rimanendo a circa il ~5%.
4. Frequenza di serializzazione e persistenza
La cattura di dati di osservabilità dettagliati richiede la serializzazione delle tracce e la loro scrittura su storage o backend esterni. Una maggiore quantità di dettagli delle tracce aumenta la frequenza con cui ciò avviene, aggiungendo overhead di I/O a ogni richiesta.
Nel nostro benchmark:
- il tracciamento dettagliato di prompt, output e token di Langfuse ha determinato l'overhead più elevato (~15%)
- gli artefatti di traccia più leggeri di LangSmith sono rimasti vicini alla baseline.
5. Livello di integrazione con il framework dell'agente
Quanto strettamente uno strumento si integra con il framework dell'agente influisce sulle prestazioni. Integrazioni più strette riducono i passaggi di traduzione e orchestrazione, mentre SDK più generici aggiungono ulteriori livelli di elaborazione.
Ad esempio:
- l'allineamento stretto di LangSmith con l'esecuzione dell'agente è correlato a un overhead di circa lo ~0%
- AgentOps e Langfuse hanno mostrato un impatto di latenza maggiore, coerente con percorsi di integrazione più disaccoppiati.
Piattaforme di osservabilità per agenti IA
Livello 1: Osservabilità dettagliata di LLM e prompt/output
* Le capacità elencate in queste colonne sono esempi illustrativi di ciò che ciascuno strumento può monitorare quando esteso tramite integrazioni o personalizzazioni. Non sono esclusive di una singola piattaforma.
Livello 2: Osservabilità di flusso di lavoro, modello e valutazione
Livello 3: Osservabilità del ciclo di vita e delle operazioni dell'agente
Livello 4: Monitoraggio di sistema e infrastruttura (non nativo per agenti)
Datadog (con il suo modulo di osservabilità LLM) e Prometheus (tramite esportatori) vengono sempre più utilizzati insieme a Langfuse/LangSmith.
Piattaforme di sviluppo e orchestrazione di agenti:
- Strumenti come Flowise, Langflow, SuperAGI e CrewAI consentono di creare, orchestrare e ottimizzare flussi di lavoro degli agenti con interfacce no-code/low-code
Editioni gratuite e prezzi
Le edizioni gratuite variano in base ai limiti di utilizzo (es. osservazioni, tracce, token o unità di lavoro). I prezzi di partenza si riferiscono in genere a un piano base, che potrebbe avere restrizioni su funzionalità, utenti o limiti di utilizzo.
Weights & Biases (W&B Weave)
Caso d'uso: Debugging dei fallimenti nei sistemi multi-agente tracciando come gli errori si propagano attraverso le chiamate degli agenti.
Weights & Biases Weave registra tracce di esecuzione strutturate per sistemi multi-agente, preservando le relazioni gerarchiche tra le chiamate degli agenti. Input, output, stati intermedi, latenza e utilizzo dei token vengono catturati per ogni agente e per ogni traccia.
Funzionalità di monitoraggio di Weave
- Tracciamento gerarchico degli agenti anziché semplici log delle richieste
- Attribuzione di costi e latenza a livello di agente
- Supporto nativo per valutatori applicati direttamente alle tracce.
Capacità di valutazione
Weave fornisce anche valutatori integrati per la valutazione, tra cui:
- HallucinationFreeScorer per rilevare le allucinazioni,
- SummarizationScorer per valutare la qualità dei riassunti,
- EmbeddingSimilarityScorer per la similarità semantica,
- ValidJSONScorer e ValidXMLScorer per la validazione del formato,
- PydanticScorer per la conformità dello schema,
- OpenAIModerationScorer per la sicurezza dei contenuti,
- Valutatori RAGAS come ContextEntityRecallScorer,
- ContextRelevancyScorer per la valutazione dei sistemi RAG.
Ideale per: Team che eseguono flussi di lavoro multi-agente o a più passaggi e necessitano di un'analisi delle cause alla radice a livello di traccia piuttosto che metriche di superficie.
Langfuse
Casi d'uso: Tracciare le interazioni LLM, gestire le versioni dei prompt e monitorare le prestazioni del modello con le sessioni utente.
Langfuse offre una profonda visibilità sul livello dei prompt, catturando prompt, risposte, costi e tracce di esecuzione per aiutare a eseguire il debug, monitorare e ottimizzare le applicazioni LLM.
Tuttavia, Langfuse potrebbe non essere adatto a team che preferiscono flussi di lavoro basati su Git per la gestione del codice e dei prompt, poiché il suo sistema di gestione esterna dei prompt potrebbe non offrire lo stesso livello di controllo delle versioni e collaborazione.
Funzionalità di monitoraggio di Langfuse
- Visibilità sull'evoluzione dei prompt e sui modelli di utilizzo
- Analisi basata sulle sessioni adatta per applicazioni rivolte agli utenti
- Modello pratico di metadati e tagging per il filtraggio e la revisione
Funzionalità di livello aziendale:
Alcune di queste funzionalità includono:
- Livelli di log: Regola la verbosità dei log per ottenere approfondimenti più granulari.
- Multimodalità: Supporta testo, immagini, audio e altri formati per applicazioni LLM multimodali.
- Rilasci e versionamento: Traccia la cronologia delle versioni e osserva come i nuovi rilasci influenzano le prestazioni del modello.
- URL delle tracce: Accedi a tracce dettagliate tramite URL univoci per ulteriori ispezioni e debugging.
- Grafici degli agenti: Visualizza le interazioni e le dipendenze degli agenti per una migliore comprensione del loro comportamento.
- Campionamento: Raccogli dati rappresentativi dalle interazioni per analizzarli senza sovraccaricare il sistema.
- Monitoraggio di token e costi: Traccia l'utilizzo dei token e i costi per ogni chiamata al modello, garantendo una gestione efficiente delle risorse.
- Mascheramento: Proteggi i dati sensibili mascherandoli nelle tracce, garantendo privacy e conformità.
Ideale per: Team che iterano sui prompt e monitorano l'utilizzo in produzione, specialmente dove le sessioni utente sono importanti.
Galileo
Casi d'uso: Monitorare costi/latenza, valutare la qualità dell'output, bloccare risposte non sicure e fornire correzioni attuabili.
Galileo traccia metriche di costo, latenza e qualità dell'output applicando al contempo controlli di sicurezza e conformità in tempo reale.
La piattaforma combina osservabilità tradizionale (latenza, costo, prestazioni) con debugging e valutazione potenziati dall'IA (rilevamento di allucinazioni, correttezza fattuale, coerenza, aderenza al contesto).
Funzionalità di monitoraggio di Galileo
- Identificazione delle modalità di fallimento oltre gli errori superficiali (es. allucinazioni che portano a input non validi per gli strumenti)
- Feedback prescrittivo come modifiche suggerite ai prompt o aggiunte di pochi esempi
- Stretta correlazione tra risultati della valutazione e correzioni consigliate.
Ideale per: Organizzazioni che danno priorità alla qualità dell'output, alla sicurezza e a cicli di iterazione rapidi con correzioni guidate.
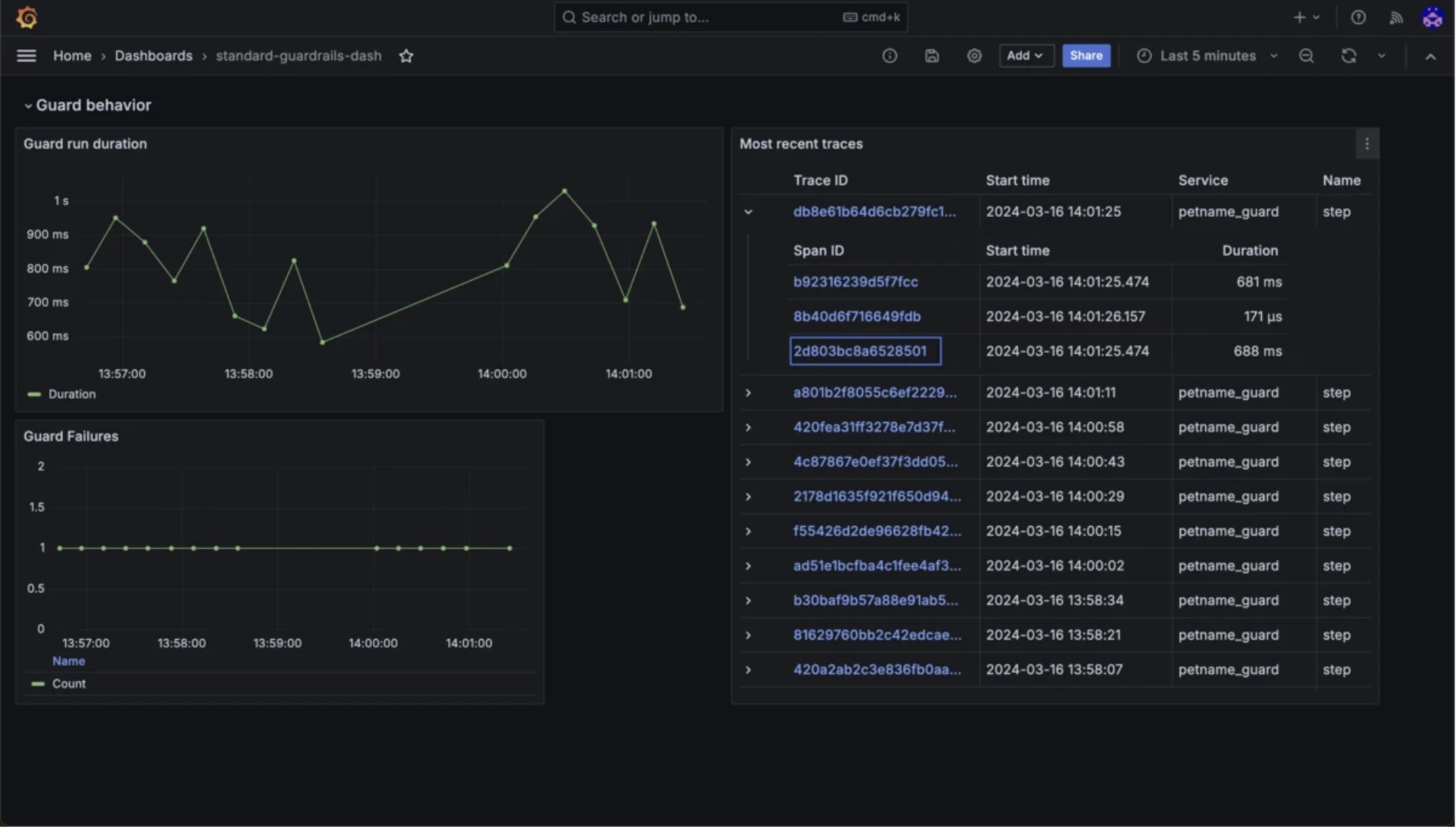
Guardrails IA
Casi d'uso: Prevenire output dannosi, convalidare le risposte LLM e garantire la conformità con le politiche di sicurezza
Guardrails convalida gli input e gli output LLM rispetto a regole configurabili, tra cui tossicità, bias, esposizione di PII, segnalazione di allucinazioni e conformità del formato.
Funzionalità di monitoraggio di Guardrails IA
- Validazione deterministica tramite specifiche RAIL
- Guardie per input per il rilevamento di prompt injection e jailbreak
- Nuovi tentativi automatici quando la validazione fallisce.
Ideale per
Team che devono applicare rigorosi requisiti di sicurezza, conformità o formattazione prima che le risposte vengano restituite.
LangSmith
Casi d'uso: Debugging del ragionamento dell'agente e delle chiamate agli strumenti (incentrato su LangChain)
LangSmith cattura le tracce di ragionamento complete per gli agenti basati su LangChain, inclusi i prompt, il contesto recuperato, la logica di selezione degli strumenti, gli input/output degli strumenti, gli errori e le eccezioni.
Funzionalità di monitoraggio di LangSmith
- Ispezione passo dopo passo dei percorsi decisionali dell'agente
- Riesecuzione della traccia e confronto affiancato tra prompt, modelli o strumenti
- Integrazione stretta con LangChain tramite callback.
Ideale per
Team che sviluppano con LangChain e necessitano di eseguire il debug del ragionamento errato o dell'invocazione degli strumenti in dettaglio.
Langtrace IA
Casi d'uso: Identificare i colli di bottiglia di costo e latenza nelle app LLM
Langtrace traccia il conteggio dei token, la durata dell'esecuzione, i costi delle API e i parametri delle richieste attraverso pipeline LLM utilizzando tracce compatibili con OpenTelemetry.
Funzionalità di monitoraggio di Langtrace IA
- Allineamento con OpenTelemetry per l'integrazione con backend esistenti
- Visibilità sui fattori di costo e latenza per ogni passaggio
- Versionamento leggero dei prompt e sandbox di test.
Ideale per: Team che ottimizzano le prestazioni e la spesa nei flussi di lavoro LLM piuttosto che valutare la qualità dell'output.
Arize (Phoenix)
Casi d'uso: Monitorare il drift del modello, rilevare i bias e valutare gli output LLM con sistemi di punteggio completi
Phoenix si concentra sul drift comportamentale, sul rilevamento dei bias e sul punteggio LLM-come-giudice per pertinenza, tossicità e accuratezza.
Tuttavia, presenta un overhead di integrazione maggiore rispetto ai proxy leggeri e non gestisce il versionamento dei prompt in modo pulito come gli strumenti dedicati.
Funzionalità di monitoraggio di Phoenix
- Nucleo open-source con estensioni aziendali opzionali
- Sandbox interattiva per i prompt per lo sviluppo
- Rilevamento del drift per tracciare i cambiamenti comportamentali nel tempo
- Controlli sui bias per identificare bias nelle risposte,
- Punteggio LLM-come-giudice per accuratezza, tossicità e pertinenza.
Ideale per: Team che monitorano il comportamento a lungo termine del modello e il rischio di regressione piuttosto che l'iterazione dei prompt.
Agenta
Casi d'uso: Trovare quale prompt funziona meglio su quale modello
Agenta confronta le risposte del modello in termini di costo, latenza e qualità dell'output utilizzando input condivisi e contesto controllato.
Funzionalità di monitoraggio di Agenta
- Valutazione affiancata dei modelli
- Supporto decisionale in fase di pre-produzione.
Ideale per: Valutazione in fase iniziale e selezione del modello.
AgentOps.ai
Casi d'uso: Monitorare il ragionamento dell'agente, tracciare i costi ed eseguire il debug delle sessioni in produzione
AgentOps cattura le tracce di ragionamento, le chiamate a strumenti/API, lo stato della sessione, il comportamento di caching e le metriche di costo per gli agenti distribuiti.
Funzionalità di monitoraggio di AgentOps
- Replay della sessione per il debug in produzione
- Attenzione al comportamento dell'agente in esecuzione piuttosto che alla valutazione offline.
Ideale per: Team che eseguono agenti in produzione e necessitano di visibilità operativa.
Braintrust
Casi d'uso: Trovare quale prompt, dataset o modello funziona meglio con una valutazione dettagliata e un'analisi degli errori
Braintrust valuta prompt, dataset e modelli rispetto agli output attesi, tracciando latenza, costo, errori degli strumenti e metriche di esecuzione.
Funzionalità di monitoraggio di Braintrust
- Valuta dataset di test con input e output attesi, quindi confronta prompt o modelli affiancati utilizzando variabili come
{{input}},{{expected}}e{{metadata}}. - Scomposizione delle metriche, inclusa la qualità dell'esecuzione degli strumenti
Ideale per: Team che confrontano modelli e prompt prima del rilascio.
AgentNeo
Casi d'uso: Debugging delle interazioni multi-agente, tracciamento dell'utilizzo degli strumenti e valutazione dei flussi di lavoro di coordinamento
AgentNeo traccia la comunicazione tra agenti, l'utilizzo degli strumenti, i grafici di esecuzione e i costi e la latenza per agente tramite un SDK Python.
Funzionalità di monitoraggio di AgentNeo
- Open-source ed eseguibile localmente
- Dashboard locale interattiva (
localhost:3000) per il monitoraggio in tempo reale dei flussi di lavoro multi-agente. - Integrazione tramite decoratori (es.
@tracer.trace_agent,@tracer.trace_tool)
Ideale per: Team di ingegneri che sperimentano con sistemi multi-agente.
Laminar
Caso d'uso: Tracciare le prestazioni tra diversi framework e modelli LLM.
Laminar traccia le span di esecuzione, i costi, l'utilizzo dei token e i percentili di latenza attraverso framework e modelli LLM.
Funzionalità di monitoraggio di Laminar
- Analisi delle prestazioni indipendente dal framework
- Ispezione granulare delle span.
Ideale per: Analisi comparativa delle prestazioni su stack eterogenei.
Helicone
Casi d'uso: Tracciare flussi di lavoro multi-agente a più passaggi e analizzare i modelli di sessione utente.
Helicone cattura i volumi delle richieste, i costi, gli errori, le tendenze di latenza e i flussi di lavoro a livello di sessione dell'agente.
Funzionalità di monitoraggio di Helicone
- Visibilità del percorso dell'utente
- Analisi delle tendenze storiche.
Ideale per: Team di prodotto che monitorano i modelli di utilizzo e il comportamento a livello utente.
Coval
Casi d'uso: Simulare migliaia di conversazioni tra agenti, testare interazioni vocali/chat e convalidare il comportamento prima della distribuzione.
Coval simula migliaia di conversazioni per misurare il completamento delle attività, la correttezza e l'efficacia delle chiamate agli strumenti.
Funzionalità di monitoraggio di Coval
- Test degli agenti basato su simulazione
- Rilevamento automatico delle regressioni
- Supporto per agenti vocali e testuali.
Ideale per: Validazione pre-distribuzione e rilevamento delle regressioni.
Datadog
Casi d'uso: Osservabilità di infrastruttura e applicazioni con correlazione dei segnali LLM.
Datadog raccoglie metriche di infrastruttura (CPU, memoria, rete), dati sulle prestazioni delle applicazioni (latenza, tassi di errore, throughput) e log. Per le applicazioni LLM, può acquisire l'utilizzo dei token, il costo per richiesta, la latenza del modello e segnali relativi alla sicurezza come tentativi di prompt injection.
Funzionalità di monitoraggio di Datadog
- Osservabilità estesa a livello di sistema su infrastruttura, applicazioni e carichi di lavoro IA
- Ampio ecosistema di integrazioni (900+ integrazioni) che consente la correlazione tra comportamento IA e stato dell'infrastruttura
Ideale per: Organizzazioni che desiderano correlare il comportamento LLM con le prestazioni dell'infrastruttura e delle applicazioni sottostanti piuttosto che ispezionare il ragionamento dell'agente o i prompt
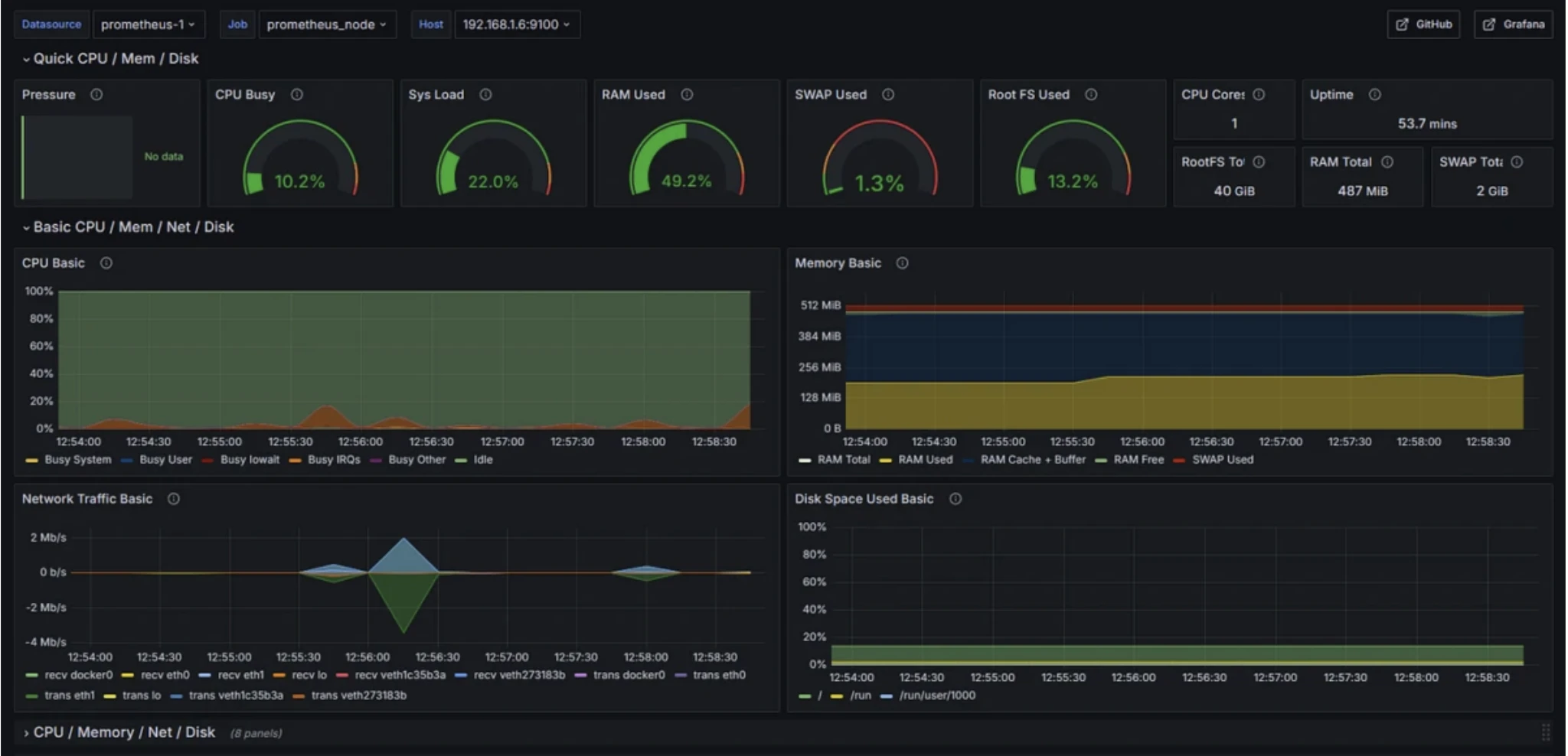
Prometheus
Casi d'uso: Monitorare le prestazioni del sistema, tracciare le metriche delle applicazioni e impostare avvisi per problemi infrastrutturali.
Prometheus è un sistema di monitoraggio open-source che raccoglie metriche time-series da endpoint HTTP a intervalli regolari per tracciare metriche di infrastruttura, applicazioni, database, container e metriche aziendali personalizzate.
Funzionalità di monitoraggio di Prometheus
- Raccolta di metriche time-series tramite scraping basato su pull
- PromQL per l'interrogazione, l'aggregazione e le condizioni di avviso
- Ecosistema di esportatori (es. Node Exporter) per un'ampia copertura del sistema
Ideale per: Monitoraggio di infrastrutture e applicazioni con avvisi basati su regole.
Grafana
Casi d'uso: Visualizzare metriche, creare dashboard e instradare avvisi attraverso dati LLM, agenti e infrastruttura.
Grafana è una piattaforma di visualizzazione e analisi open-source che si integra con fonti di dati come Prometheus, OpenTelemetry e Datadog per fornire dashboard di osservabilità unificate.
Funzionalità di monitoraggio di Grafana
- Dashboard su metriche, log e tracce
- Correlazione tra sistemi per segnali LLM, agenti e infrastruttura
- Instradamento degli avvisi e gestione delle notifiche.
Ideale per: Visualizzazione centralizzata dell'osservabilità e risposta agli incidenti.
Tutorial: Osservabilità di LangChain con Langfuse
Abbiamo costruito una pipeline LangChain a più passaggi con tre fasi:
- analisi della domanda
- generazione della risposta
- verifica della risposta
Dopo aver impostato la pipeline, l'abbiamo collegata a Langfuse per monitorare e tracciare l'esecuzione in tempo reale. In questo modo, abbiamo potuto esplorare come Langfuse ci aiuta a raccogliere approfondimenti dettagliati sulle prestazioni, i costi e il comportamento delle applicazioni IA.
Ecco cosa abbiamo osservato attraverso Langfuse:
Panoramica della dashboard
Langfuse ci ha fornito diverse dashboard che ci danno visibilità su diversi aspetti delle prestazioni della pipeline:
- Dashboard dei costi: Tiene traccia della spesa su tutte le chiamate API, con scomposizioni dettagliate per modello e periodo di tempo.
- Gestione dell'utilizzo: Monitora le metriche di esecuzione, come il conteggio delle osservazioni e l'allocazione delle risorse, aiutandoci a tracciare l'utilizzo delle risorse durante l'esecuzione.
- Dashboard della latenza: Questa dashboard ci ha aiutato ad analizzare i tempi di risposta, rilevare i colli di bottiglia e visualizzare le tendenze delle prestazioni.
Metriche di utilizzo
La dashboard delle metriche di utilizzo ci ha fornito i seguenti approfondimenti sul funzionamento del sistema:
- Conteggio totale delle tracce: Abbiamo tracciato otto tracce, ognuna delle quali rappresenta un ciclo completo domanda-risposta nella pipeline.
- Conteggio totale delle osservazioni: In media, ogni traccia aveva 16 osservazioni, riflettendo la natura multi-step del processo.
Inoltre, Langfuse ci consente di tracciare modelli di utilizzo, allocazione delle risorse e ore di punta negli ultimi 7 giorni, aiutandoci a capire quando il sistema è più attivo e come le risorse vengono distribuite nel tempo.
Ispezione delle tracce
Analizzando una singola traccia, siamo stati in grado di vedere informazioni dettagliate sull'esecuzione:
- Righe delle tracce: Ogni riga rappresenta un'esecuzione completa della pipeline con un ID di traccia univoco.
- Metriche di latenza: Il tempo di esecuzione variava da 0.00s a 34.08s.
- Conteggio dei token: La dashboard ha tracciato l'utilizzo dei token in input/output, utile per la gestione dei costi e dell'efficienza.
- Filtro per ambiente: Abbiamo potuto filtrare le tracce in base agli ambienti di distribuzione (es. sviluppo, produzione).
Dettagli della singola traccia
Abbiamo ulteriormente esplorato la traccia in modo più dettagliato per comprendere la scomposizione dell'esecuzione:
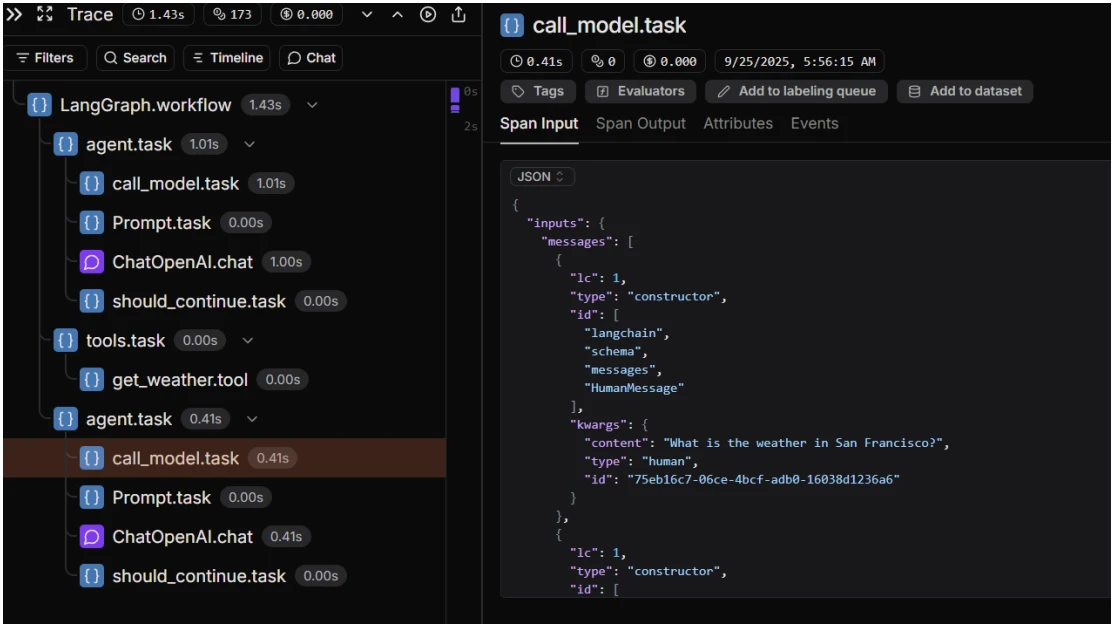
- Architettura a catena sequenziale: La traccia mostrava un flusso visivo di ogni fase, a partire da SequentialChain → LLMChain → ChatOpenAI, con struttura gerarchica.
- Tracciamento input/output: La domanda originale, "Quali sono i vantaggi dell'utilizzo di Langfuse per l'osservabilità degli agenti IA?" è stata tracciata in ogni fase, insieme ai rispettivi output prodotti dall'IA in ogni passaggio.
- Analisi dei token: Abbiamo osservato che sono stati utilizzati 1.203 token per l'input e 1.516 token per l'output, il che ha implicazioni di costo relative all'utilizzo dei token e aiuta a ottimizzare la gestione delle risorse.
- Dati temporali: La latenza totale per l'intera traccia è stata di 34.08s, suddivisa tra i vari componenti:
- SequentialChain → 14.02s
- LLMChain → 10.25s
- ChatOpenAI → 9.81s
- Informazioni sul modello: Langfuse ha confermato l'utilizzo del modello Anthropic Claude-Sonnet-4, con dettagli sulle impostazioni specifiche, inclusa la configurazione della temperatura.
- Output formattato: Sono state fornite sia la vista Anteprima che quella JSON per il debug, offrendo informazioni sulla risposta del modello in formato leggibile dall'uomo e in formato leggibile dalla macchina.
Analisi automatizzata
Langfuse ha anche fornito valutazioni automatizzate delle nostre risposte:
- Valutazione della qualità: Il sistema ha valutato la struttura, la coerenza e la completezza delle risposte, evidenziando sezioni ben organizzate, ma suggerendo che le risposte avrebbero potuto essere più concise.
- Suggerimenti per il miglioramento: Ha identificato sezioni con ridondanza, suggerendo dove la formulazione avrebbe potuto essere migliorata, e ha combinato punti correlati per rendere la risposta più trasparente ed efficiente.
- Approfondimenti sulle prestazioni: Il sistema ha fornito feedback sull'utilizzo dei token e sulla pertinenza della risposta, aiutandoci a ottimizzare l'efficienza garantendo al contempo che l'output rimanesse utile e pertinente.
- Feedback strutturato: Il feedback è stato organizzato per categorie, consentendoci di affrontare aree specifiche di miglioramento in modo mirato.
Analisi degli utenti
Langfuse traccia le interazioni dettagliate tra gli utenti e l'agente IA:
- Sequenza temporale delle attività degli utenti: Mostra la prima e l'ultima interazione per ogni utente, aiutando a identificare gli utenti attivi rispetto a quelli inattivi. Possiamo vedere quando gli utenti hanno interagito con il sistema per la prima e l'ultima volta.
- Tracciamento del volume degli eventi: Tiene traccia del numero di eventi attivati da ciascun utente. Ad esempio, alcuni utenti hanno generato oltre 2.000 eventi, mostrando il loro livello di coinvolgimento con il sistema.
- Analisi del consumo di token: Monitora il numero totale di token consumati da ciascun utente. L'utilizzo dei token variava da 6.59K a 357K token, fornendo approfondimenti sull'utilizzo delle risorse.
- Attribuzione dei costi: Suddivide i costi associati a ciascun utente, facilitando il monitoraggio della spesa e l'ottimizzazione dell'allocazione del budget per l'uso delle risorse.
- Identificazione dell'utente: Utilizza ID utente anonimizzati per mantenere la privacy tracciando al contempo le interazioni individuali degli utenti, aiutando l'analisi dell'utilizzo senza compromettere la riservatezza dell'utente.
La vista sessione ci consente di tracciare i dettagli granulari delle interazioni dell'utente:
- Flusso di conversazione completo: Mostra l'intera interazione domanda-risposta, facilitando il tracciamento dell'intera conversazione dall'inizio alla fine.
- Visibilità dell'implementazione: Mostra il codice Python effettivo utilizzato durante la sessione, fornendo informazioni sull'implementazione tecnica.
- Correlazione input/output: Collega le domande dell'utente alle corrispondenti risposte del sistema, aiutandoci a risolvere i problemi e a identificare dove potrebbero essersi verificati problemi nella conversazione.
- Metadati della sessione: Include dettagli tecnici come tempistica, contesto utente e dati di implementazione specifici, offrendo una visione completa dell'esecuzione della sessione.
Quando non utilizzare gli strumenti di osservabilità
- Sviluppo in fase iniziale: Se stai ancora verificando l'adattamento del prodotto al mercato o costruendo i tuoi primi flussi di lavoro con agenti, l'attenzione dovrebbe essere sulla funzionalità principale piuttosto che su un'osservabilità estesa.
- Colli di bottiglia delle API: Se i problemi principali sono i costi delle API, la latenza o il caching, la priorità immediata dovrebbe essere l'ottimizzazione di queste aree, non il monitoraggio delle metriche a livello di sistema.
- Ottimizzazione del modello: Se i miglioramenti sono principalmente guidati dalla selezione del modello, dal fine-tuning o dall'ingegneria dei prompt, gli strumenti di osservabilità per drift e bias potrebbero non essere ancora necessari.
Quando utilizzare gli strumenti di osservabilità
- Produzione su larga scala: Quando operi con più modelli, agenti o catene, gli strumenti di osservabilità sono essenziali per monitorare le prestazioni e garantire lo stato del sistema.
- Applicazioni aziendali o rivolte al cliente: Per le applicazioni in cui affidabilità, sicurezza e conformità sono irrinunciabili, gli strumenti di osservabilità forniscono la visibilità e il controllo necessari.
- Monitoraggio continuo: Quando è necessario monitorare drift, bias, prestazioni e problemi di sicurezza nel tempo, che non possono essere facilmente catturati con script di base o controlli manuali, gli strumenti di osservabilità sono cruciali.
- Scenari ad alto rischio: In ambienti in cui il costo di un fallimento (es. allucinazioni, output non sicuri) è significativo, l'osservabilità garantisce che i rischi siano ridotti al minimo e i problemi vengano rilevati tempestivamente.
Metodologia del benchmark
Per valutare l'overhead prestazionale delle piattaforme di osservabilità nelle applicazioni LLM in produzione, abbiamo sviluppato un approccio di benchmarking sistematico utilizzando un flusso di lavoro agentico reale.
Applicazione di test
Abbiamo costruito un sistema di pianificazione viaggi multi-agente sequenziale utilizzando LangChain che elabora richieste di viaggio in linguaggio naturale attraverso cinque fasi:
- Agente parser: Estrae dati strutturati (origine, destinazione, date, durata) dall'input dell'utente
- Agente cercatore voli: Recupera i voli disponibili tramite l'API Amadeus
- Agente meteorologo: Recupera le previsioni meteo della destinazione utilizzando WeatherAPI
- Agente consigliere attività: Suggerisce attività in base alle condizioni meteorologiche
- Agente pianificatore di viaggio: Sintetizza tutti gli output in un itinerario completo
Il sistema utilizza Claude 4 Haiku tramite OpenRouter per tutte le chiamate LLM e integra API esterne per dati in tempo reale.
Progettazione del benchmark
Definizione della baseline: Abbiamo prima misurato le prestazioni dell'applicazione senza alcuna strumentazione di osservabilità, eseguendo 100 query identiche per stabilire una baseline di confronto.
Integrazione della piattaforma: Abbiamo poi integrato cinque principali piattaforme di osservabilità (LangSmith, Laminar, AgentOps, Langfuse) una alla volta, strumentando gli stessi punti di tracciamento su tutte le piattaforme per coerenza.
Esecuzione sequenziale: Ogni piattaforma è stata testata indipendentemente eseguendo tutte le 100 query consecutivamente prima di passare alla piattaforma successiva. Questo approccio minimizza la variabilità dovuta a fattori esterni come le condizioni di rete o i limiti di velocità delle API.
Ambiente controllato: Tutti i test sono stati eseguiti sulla stessa infrastruttura server con set di query identici per garantire un confronto equo. Per isolare l'overhead dalle variazioni di latenza indotte dal LLM, abbiamo configurato il modello con temperatura=0 e prompt strutturati per ridurre al minimo la variabilità delle risposte tra le esecuzioni.
Metriche raccolte
Per ogni piattaforma, abbiamo misurato la latenza media e calcolato l'overhead come latenza aggiuntiva introdotta rispetto alla baseline: ((Platform Latency - Base Latency) / Base Latency) × 100
FAQ
L'osservabilità è la capacità di comprendere il funzionamento interno di un agente IA esaminando segnali esterni come log, metriche e tracce.
Per gli agenti IA, ciò comporta il monitoraggio delle azioni, dell'utilizzo degli strumenti, delle interazioni con i modelli e delle risposte per risolvere i problemi e migliorare le prestazioni.
L'osservabilità degli agenti è fondamentale per tracciare e migliorare le prestazioni dell'IA consentendo di:
Comprendere i compromessi: Aiuta a misurare metriche chiave come l'accuratezza e il costo, facilitando il bilanciamento tra prestazioni e utilizzo delle risorse.
Misurare la latenza: Il monitoraggio della latenza in tempo reale offre approfondimenti sui tempi di risposta, aiutando a ottimizzare le prestazioni dell'agente.
Rilevare input dannosi: L'osservabilità aiuta a identificare linguaggi dannosi e tentativi di prompt injection, consentendo un intervento tempestivo per prevenire problemi.
Monitoraggio del feedback degli utenti: Osservando le interazioni e il feedback degli utenti, l'osservabilità fornisce dati preziosi per il miglioramento continuo e il fine-tuning degli agenti.
I componenti chiave includono:
– Tracciamento delle azioni: Monitoraggio di ogni passo compiuto dall'agente.
– Utilizzo degli strumenti: Osservazione degli strumenti e delle risorse utilizzate dall'agente.
– Misurazione della latenza: Monitoraggio dei tempi di risposta per ottimizzare le prestazioni.
– Valutazioni: Valutazione del comportamento dell'agente e delle prestazioni del modello.
– Rilevamento di input dannosi: Identificazione di prompt dannosi o attacchi.
Cita questa ricerca
Scegli il formato adatto a dove pubblicherai. Incollare la versione con link nel tuo CMS preserva il backlink.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{15 Strumenti di Osservabilità degli Agenti IA: AgentOps & Langfuse}},
year = {2026},
month = jul,
howpublished = {\url{https://aimultiple.com/agentic-monitoring}},
note = {AIMultiple. Consultato il 2 Luglio 2026}
}














.")





Sii il primo a commentare
Il tuo indirizzo email non verrà pubblicato. Tutti i campi sono obbligatori. I commenti vengono lasciati nella loro lingua originale.