I 5 migliori framework open-source di AI agentica
Abbiamo sottoposto a benchmark 4 popolari framework agentici open-source su 2.000 esecuzioni (5 task, 100 esecuzioni ciascuno per framework), misurando la latenza end-to-end, il consumo di token e le differenze architetturali.
Benchmark dei framework di AI agentica
Abbiamo esaminato come i framework stessi influenzano il comportamento degli agenti e il conseguente impatto su latenza e consumo di token.
LangGraph è il framework più veloce con i valori di latenza più bassi in tutti i task, mentre LangChain registra la latenza e l'utilizzo di token più elevati.
Su 5 task e 2.000 esecuzioni, LangChain emerge come il framework più efficiente in termini di token, mentre AutoGen guida nella latenza; LangGraph e LangChain seguono da vicino. CrewAI presenta il profilo complessivamente più pesante.
Puoi consultare la nostra metodologia in dettaglio qui.
Task 1: Aggregazione di base
In primo luogo, abbiamo misurato l'overhead di ciascun framework quando chiama un singolo strumento e restituisce il risultato, senza eseguire alcun ragionamento complesso.
LangChain & LangGraph: Per task semplici, offrono prestazioni quasi veloci quanto il codice non agentico, completando entrambi in meno di 5 secondi con meno di 900 token di prompt. L'architettura a macchina a stati di LangGraph non introduce latenza percepibile rispetto a LangChain a questo livello di semplicità; l'overhead della gestione dello stato si materializza man mano che la complessità del task cresce.
AutoGen: Si colloca leggermente al di sopra di LangChain e LangGraph sia in latenza che in utilizzo di token, riflettendo il costo di base del suo ciclo di conversazione multi-agente, con due agenti che si scambiano messaggi anche per un task a passo singolo.
CrewAI: Anche quando gli viene chiesto di effettuare una singola chiamata a uno strumento, mostra quello che si potrebbe definire "overhead manageriale", consumando quasi 3 volte i token di LangChain e impiegando quasi 3 volte più tempo. Il processo di verifica multi-fase tra le sue personalità Planner e Analyst offre un approccio approfondito ma dispendioso in termini di risorse, che privilegia la completezza rispetto alla velocità. Questo costo è strutturale: si manifesta indipendentemente dalla complessità del task.
Task 2: Analisi comparativa dei ricavi (gestione dello stato)
Nel Task 2, volevamo verificare la capacità dei framework di mantenere in memoria due diversi gruppi di filtri (Persistenza dello Stato) e combinarli.
CrewAI
Dall'analisi dei log, abbiamo riscontrato che CrewAI offre il più alto livello di trasparenza dell'infrastruttura tra i framework, ma al costo del consumo di risorse più elevato.
Invece di restituire immediatamente i dati recuperati, CrewAI convalida ripetutamente i propri processi attraverso un meccanismo di auto-revisione. Questo comportamento esplorativo lo ha portato a raggiungere il limite configurato max_iter=10, lasciando alcune esecuzioni bloccate in un ciclo di pensiero continuo senza produrre un output JSON.
La causa principale di questo comportamento è che CrewAI inietta istruzioni multi-livello nel prompt di sistema, assegnando a ciascun agente un ruolo, un obiettivo e una storia passata, imponendo al contempo un ciclo in stile ReAct Pensiero → Azione → Osservazione a ogni passo. Anche per task semplici, l'LLM non può saltare questa cerimonia e produce diligentemente monologhi interni verbosi, che si sommano ulteriormente negli scenari multi-agente.
CrewAI ha consumato quasi il doppio dei token degli altri framework e ha impiegato oltre tre volte il tempo di LangChain, rendendolo più adatto a transizioni di stato complesse e processi decisionali multifattoriali piuttosto che a task di recupero dati lineari.
LangChain
Il framework più veloce ed economico. Nei nostri log, abbiamo osservato che LangChain completa il task in 5-6 passi senza deviazioni: Carica → Filtra → Calcola → Filtra → Calcola → Output. Poiché la sua gestione dello stato è molto semplice, l'overhead è quasi zero e la latenza è la più bassa tra tutti i framework.
AutoGen
Ha offerto una prestazione molto equilibrata. Nel Task 2, ha eguagliato LangGraph quasi esattamente sia nell'uso di token che nella latenza, dimostrando che l'overhead del ciclo di conversazione non si aggrava significativamente quando la catena del task rimane lineare.
Tuttavia, occasionalmente aggiunge un passo di verifica extra per confermare i parametri durante il processo di chiamata degli strumenti, rendendolo leggermente più lento di LangChain. Quando incontra un errore in una chiamata a uno strumento o i dati non tornano come previsto, aggiorna immediatamente il suo ragionamento nel passo successivo e arriva al JSON corretto. Poiché gestisce gli output degli strumenti come un flusso conversazionale, è uno dei framework più resilienti contro gli errori logici.
LangGraph
In questo task, LangGraph è il framework più stabile grazie alla sua architettura basata su grafi. Nei suoi log, abbiamo osservato che lo stato viene trasportato in modo molto pulito durante tutta l'esecuzione. Il rischio di contaminazione dei dati o di interferenza tra segmenti è al livello più basso in questo framework. In tutte le 100 esecuzioni, ha prodotto risultati pressoché nello stesso numero di passi e entro lo stesso intervallo di latenza.
Task 3: Analisi delle soglie (disciplina numerica)
In questo task, volevamo vedere con quanta precisione i framework traducono le condizioni numeriche espresse in linguaggio naturale, come "meno di 1 anno di anzianità" e "più di $70 in addebiti mensili", in parametri precisi per gli strumenti come tenure_max=12 e charges_min=70.0.
L'LLM sa come effettuare questa conversione; ciò che volevamo realmente testare era se il framework riesce a proteggere questi parametri attraverso i propri meccanismi di retry, il contesto di re-prompt e i cicli di gestione dello stato.
LangChain & LangGraph
Entrambi i framework hanno passato i parametri (tenure_max=12, charges_min=70) direttamente allo strumento esattamente come l'LLM li aveva prodotti, senza alcuna modifica o ciclo di re-prompt. Questa efficienza si riflette nei numeri: entrambi i framework hanno completato il Task 3 in meno di 9 secondi con meno di 1.800 token di prompt, il valore più basso in questo task.
Quando volevamo misurare se le soglie numeriche vengono preservate senza interferenze da parte del framework, questi due hanno soddisfatto le nostre aspettative: qualsiasi parametro fosse stato generato, è quello che è stato eseguito.
AutoGen
Autogen ha pieno successo nella correttezza numerica. In alcune esecuzioni, è stato osservato che il framework ha aggiunto un passo di verifica prima di passare il parametro generato dall'LLM allo strumento, il che significa che il framework ha impiegato un passo extra preservando il parametro. Con 2.480 token e 8 secondi, ha eguagliato la latenza di LangChain nonostante il passo extra, confermando che l'overhead di verifica è reale ma contenuto. Ha soddisfatto le nostre aspettative in termini di integrità dei parametri, con il passo di conferma che introduce un costo marginale in token piuttosto che una penalità significativa in latenza.
CrewAI
Il comportamento più notevole è stato osservato in CrewAI, che ha completato il Task 3 in 30 secondi con 4.360 token, il valore più alto in questo task. Dall'analisi dei log sono emersi due modelli di fallimento distinti.
In alcune esecuzioni, un valore che avrebbe dovuto essere 68,81% è stato restituito come 0,6878 (rapporto decimale). Ciò indica che la serializzazione dell'output del framework può privare l'output dell'LLM del suo contesto originale.
I log mostrano che l'LLM aveva inizialmente prodotto i parametri corretti, tenure_max=12 e charges_min=70. Tuttavia, una volta che CrewAI è entrato in un ciclo "Failed to parse", il framework ha spinto l'LLM a riconsiderare. Nel contesto di re-prompt, l'LLM ha spostato la soglia a tenure_max=14 e ha completamente disabilitato il filtro charges_min, producendo un tasso di abbandono del 46,84%, che è in realtà il tasso di abbandono di tutti i clienti con anzianità inferiore a 14. Questo era esattamente lo scenario che volevamo osservare: il meccanismo di retry del framework può corrompere un parametro che l'LLM aveva azzeccato.
Task 4: Resilienza agli errori e capacità di pivot
In questo task, volevamo vedere come ciascun framework gestisce scenari di disturbo e osservare l'impatto su latenza e consumo di token. Lo strumento genera 3 diversi tipi di errori in successione (Rete, Timeout, Limite di Velocità), mettendo l'agente alle strette. I primi due errori istruiscono l'agente a riprovare e, dopo aver riprovato entrambi, l'errore di Limite di Velocità in arrivo dice all'agente di attendere 10 secondi. Una volta che l'agente attende e riprova, lo strumento inizia a funzionare normalmente.
LangGraph & Autogen
Questi due framework hanno trovato soluzioni alternative autonomamente quando si sono trovati di fronte a fallimenti degli strumenti in questo task.
Quando lo strumento ha restituito un avviso di limite di velocità, invece di mettersi in pausa e attendere, questi agenti hanno deciso di abbandonare completamente lo strumento in fallimento e trovare un percorso alternativo. Il loro approccio è stato: "Poiché questo strumento non funziona, filtrerò ciascun metodo di pagamento uno per uno, calcolerò il tasso di abbandono per ciascuno separatamente e poi combinerò i risultati da solo."
Metodo: Invece di portare a termine il task con una singola chiamata a uno strumento, lo hanno scomposto utilizzando due strumenti separati, uno per il filtraggio e uno per il calcolo, elaborando ciascun PaymentMethod (Electronic check, Mailed check, ecc.) individualmente.
Questi agenti operano con un ragionamento orientato all'obiettivo piuttosto che con una dipendenza dal percorso. Se il percorso più breve non è disponibile, possono costruire un piano di esecuzione alternativo nel giro di secondi.
LangGraph ha raggiunto 15.010 token di prompt nel Task 4, il conteggio di token più alto per singolo task dell'intero benchmark, perché la sua macchina a stati accumulava la cronologia crescente di ogni chiamata manuale allo strumento riportandola nel contesto a ogni passo. AutoGen ha seguito con 10.750 token, leggermente più contenuto grazie alla sua gestione conversazionale dei risultati intermedi. Nonostante ciò, entrambi hanno terminato intorno ai 24-27 secondi, confermando che il costo aggiuntivo in token non si è tradotto in una latenza significativa perché il pivot stesso è stato rapido.
CrewAI
Nonostante abbia mostrato il consumo di token più elevato nei task precedenti, CrewAI ha esibito il consumo di token più basso ma i valori di latenza più alti in questo task.
Perché il consumo di token più basso?
CrewAI non ha intrapreso una soluzione manuale di 10-15 passi come i suoi concorrenti. Quando ha incontrato errori, invece di reimmettere ripetutamente l'intera cronologia e i complessi dati intermedi nell'LLM a ogni passo, ha costruito un ciclo di ragionamento più focalizzato e modulare. Evitando verbosità non necessaria, è diventato il framework più economico in questo task.
Perché alta latenza?
La struttura manageriale di CrewAI mette in pausa e rivaluta il piano quando incontra un errore. Quando ha ricevuto l'avviso di attesa di 10 secondi, ha trascorso più tempo nella fase di "pianificazione strategica". Inoltre, invece di passare a un altro strumento per il filtraggio, ha scelto persistentemente di attendere che lo strumento principale si riprendesse o di tentare con lo strumento stabile, prolungando la durata complessiva.
LangChain
LangChain ha subito la sua trasformazione più significativa in questo task, dimostrando perché la resilienza dipende da una corretta configurazione.
Nella nostra esecuzione iniziale, LangChain è andato in crash a ogni singolo tentativo con un ConnectionError.
L'AgentExecutor predefinito di LangChain tratta le eccezioni Python grezze generate all'interno di uno strumento come errori fatali e termina il processo. A differenza dei suoi concorrenti, non applica una filosofia "gli errori sono osservazioni" per impostazione predefinita. Poiché l'agente non vede mai l'errore, non ha alcuna possibilità di ragionarci sopra.
Abbiamo racchiuso la chiamata allo strumento all'interno di langchain_agent.py con un blocco try-except. Questo ha convertito l'errore in un messaggio leggibile che l'agente ha potuto elaborare.
Comportamento post-correzione: Dopo aver applicato la correzione, abbiamo osservato nei log di LangChain che ha esibito esattamente lo stesso ragionamento di LangGraph. Ha ricevuto 3 errori dallo strumento, ha immediatamente cambiato strategia ed è passato all'utilizzo di due strumenti separati, uno per il filtraggio e uno per il calcolo, ha elaborato ciascun metodo di pagamento individualmente e ha combinato i risultati.
LangChain è in realtà altrettanto capace e adattivo quanto LangGraph, ma poiché la gestione degli errori del framework era disattivata per impostazione predefinita, non ha avuto l'opportunità di dimostrare questa capacità. Una volta configurato correttamente, ha raggiunto il risultato corretto utilizzando lo stesso approccio del percorso alternativo.
Perché si sono verificate queste differenze? (analisi dell'architettura dei framework)
Se il comportamento degli agenti dipendesse esclusivamente dall'LLM (GPT-5.2), tutti i framework avrebbero dovuto comportarsi in modo simile. Tuttavia, le chiare differenze in questi rapporti sono radicate nei meccanismi interni del ciclo di ciascun framework:
1. LangGraph & AutoGen (90% Pivot):
LangGraph opera su un'architettura a Macchina a Stati, mentre AutoGen funziona su un modello Basato su Conversazione. In entrambi i sistemi, gli errori vengono elaborati come un ciclo di feedback. In LangGraph, lo stato che riceve l'errore passa al nodo successivo; in AutoGen, l'agente Proxy inoltra l'errore all'assistente come messaggio di chat. Questo costante meccanismo di sollecitazione costringe l'agente a continuare a cercare una soluzione. Poiché l'agente viene ripetutamente confrontato con la domanda "Ho ricevuto un errore, cosa devo fare?", la probabilità che decida di intraprendere un percorso manuale alternativo sale al 90%.
2. LangChain (65% Pivot / 35% Attesa):
LangChain gira su un'architettura AgentExecutor sequenziale. Anche con la gestione degli errori attiva, il suo ciclo di esecuzione ha una struttura più lineare ed è principalmente focalizzato sulla produzione di una Risposta Finale. Se lo strumento genera errori per 3-4 passi, LangChain a volte preferisce attendere che lo strumento abbia successo al tentativo successivo o produrre un risultato dal contesto esistente, piuttosto che passare a una strategia alternativa. Poiché il blocco dello stato di LangChain è più flessibile di quello di LangGraph, il suo rapporto attesa/soluzione diretta si attesta intorno al 35%.
3. CrewAI (0% Pivot):
CrewAI opera su un'architettura a Processo Manageriale. I suoi agenti sono racchiusi in definizioni di Ruolo e Task. Quando si verificano errori, la sua architettura interna tipicamente attiva logiche di Auto-Correzione o Retry. Tuttavia, un cambiamento radicale di strategia come "scartiamo l'intero piano e facciamo il filtraggio manuale in 5 passi" entra in conflitto con la struttura del piano manageriale di CrewAI. Opera con la disciplina del "dovrei riparare lo strumento che mi è stato dato o usare l'alternativa più vicina" piuttosto che abbandonare del tutto il suo piano. Questo è fondamentalmente un approccio incentrato sul piano anziché centrato sull'obiettivo.
Task 5: Orchestrazione di dati non strutturati (instradamento di dati non strutturati)
Nel task 5, abbiamo osservato come i framework si comportano quando incontrano colonne JSON e testo lungo (LongText) all'interno di un CSV. Gli agenti dovevano prima scoprire il tipo di dati di queste colonne, quindi selezionare gli strumenti di elaborazione corretti in modo sequenziale o parallelo.
Nel mondo reale, la gestione dei dati non strutturati richiede che un agente vada oltre i dati tabulari standard e lavori con blob JSON, paragrafi di free-text o oggetti annidati.
Affinché un framework gestisca correttamente questo tipo di dati, deve fare bene due cose:
1- un'intelligenza di scoperta che comprenda quale strumento si adatta a quale tipo di dato
2- un meccanismo di orchestrazione che coordini più chiamate indipendenti agli strumenti.
Abbiamo progettato il Task 5 specificamente per misurare queste due capacità separatamente.
AutoGen
AutoGen ha offerto una prestazione solida in questo task, terminando con 8.170 token di prompt e una latenza mediana di 47 secondi, il risultato più veloce ed efficiente in token del Task 5.
Il ciclo di conversazione al centro della sua architettura, la messaggistica tra AssistantAgent e UserProxyAgent, è tipicamente visto come una struttura che porta alla verbosità. Tuttavia, nel Task 5, questa struttura si è trasformata in un vantaggio.
Osservando la cronologia della conversazione, l'LLM ha riconosciuto che le colonne Metadata e SupportNotes erano indipendenti l'una dall'altra. Ha quindi inviato una singola risposta TOOL CALLS elencando 4 strumenti simultaneamente: inspect_column(Metadata), inspect_column(SupportNotes), parse_json_column(…) e summarize_text_column(…) sono stati eseguiti tutti in parallelo. Questo gli ha permesso di completare il task in 3 turni dell'LLM, con il minor numero di token e il minor numero di passi.
La ragione tecnica dietro questo comportamento è chiara: il motore di esecuzione degli strumenti di AutoGen esegue atomicamente la lista tool_calls restituita dall'LLM e raccoglie i risultati in un singolo passo di conversazione. La filosofia del framework di "gestire la conversazione" consente naturalmente l'apertura simultanea di più canali paralleli, e i numeri di token e latenza lo confermano direttamente.
LangGraph
LangGraph ha terminato con 9.150 token di prompt e 70 secondi di mediana, vicino ad AutoGen sui token ma più lento sul tempo. La sua architettura a Macchina a Stati ha mostrato simultaneamente sia la sua più grande forza che la sua più notevole debolezza nel Task 5.
In ogni esecuzione, il ciclo nodo llm → nodo tools → nodo llm accumula tutti gli output precedenti degli strumenti nello stato e li passa all'LLM. Questa struttura garantisce che l'agente non dimentichi mai nulla, il che è normalmente un vantaggio significativo.
Tuttavia, nel Task 5 questa forza ha giocato a suo sfavore. LangGraph stava trovando gli strumenti corretti e costruendo il segmento corretto. Ma anche dopo che l'analisi era completa, rilevava ambiguità nello stato accumulato, interpretando i passi completati come ancora in sospeso, e attivava ripetutamente chiamate aggiuntive agli strumenti. Anche se aveva recuperato i dati necessari ed era sul punto di produrre la risposta corretta, il segnale di "passo mancante" della macchina a stati si attivava e l'agente entrava in cicli non necessari. Di conseguenza, il numero di chiamate agli strumenti per esecuzione variava tra 6 e 16. Il potere dello stato di "non dimenticare mai nulla" a volte faceva apparire i passi completati come incompleti, riportando l'agente in cicli ridondanti e spingendo la latenza 23 secondi sopra AutoGen nonostante un conteggio di token comparabile.
CrewAI
La prestazione di CrewAI nel Task 5 ha prodotto la varianza più alta dell'intero benchmark. In alcune esecuzioni, ha seguito una sequenza impeccabile con 5 chiamate agli strumenti, senza deviazioni, eseguendo come uno script. In queste esecuzioni, la struttura manageriale definita da ruolo e task di CrewAI ha funzionato esattamente come previsto: quando l'agente comprendeva chiaramente il suo ruolo, si comportava in modo prevedibile e disciplinato.
Tuttavia, in altre esecuzioni (ad es., esecuzione 16: 35 chiamate agli strumenti), è seguito il caos completo. La causa principale era il monologo interno (Thought) che CrewAI genera a ogni passo. Dopo aver costruito correttamente il segmento con il filtro giusto, il monologo interno dell'agente iniziava a chiedersi se dovessero essere applicati anche filtri aggiuntivi. Dopo aver visto il risultato, dubitava che il segmento corrente fosse valido o se quello precedente dovesse avere la precedenza. Questo dubbio lo spingeva a ricaricare i dati da zero. Poi filtrava di nuovo, entrava in un altro ciclo di verifica, dubitava di nuovo e ripeteva questa spirale 8 volte.
In CrewAI, ogni Thought produce una valutazione indipendente, e queste valutazioni occasionalmente invalidano i passi precedentemente verificati. Il riflesso di "verifica continua" del Processo Manageriale, in alcune esecuzioni, ha spinto l'agente a rimettere in discussione le proprie decisioni corrette.
LangChain
La struttura AgentExecutor di LangChain è intrinsecamente sequenziale, e il Task 5 è dove quel vincolo è stato più visibile. Con 10.070 token di prompt e 86 secondi di mediana, è stato il framework più lento in questo task pur non avendo il conteggio di token più alto.
Effettua una singola chiamata allo strumento a ogni passo, riceve il risultato, poi procede, il che significa che 4 strumenti indipendenti hanno richiesto 4 turni separati dell'LLM con 4 periodi di attesa separati. I 47 secondi di mediana di AutoGen contro gli 86 secondi di LangChain sono una misura diretta del costo dell'esecuzione sequenziale rispetto a quella parallela.
Nel Task 5, il conteggio degli strumenti di LangChain si è attestato su 9 o 15. Questi due cluster indicano due strategie tipiche: in alcune esecuzioni, ha saltato il passo di ispezione ed è andato direttamente all'analisi e al riepilogo (9 strumenti), mentre in altre ha ispezionato ogni colonna prima dell'elaborazione (15 strumenti). L'identità di esecutore lineare di LangChain è emersa chiaramente qui: non ha mostrato né l'efficienza parallela di AutoGen né il caos da monologo di CrewAI.
Gestione dei dati non strutturati e architettura dei framework
I risultati di questo task rivelano che l'efficienza con cui un framework può gestire i dati non strutturati (JSON, LongText) è direttamente legata al suo meccanismo di ciclo interno:
I framework capaci di chiamate parallele agli strumenti (AutoGen) possono elaborare colonne di dati indipendenti in un unico passo. Negli scenari del mondo reale che coinvolgono grandi oggetti JSON e numerose colonne di testo, questa differenza si traduce in un enorme vantaggio in termini di costi e velocità.
I framework con cicli guidati dallo stato (LangGraph) eccellono nella coerenza dei dati ma comportano il rischio di rivalutare i passi completati accumulati nella cronologia.
I framework basati su monologo (CrewAI) sono profondamente capaci di comprendere il tipo e il significato dei dati, ma questa profondità a volte si trasforma in eccessivi dubbi e cicli.
I framework a esecuzione lineare (LangChain) elaborano separatamente i diversi rami dei dati non strutturati, producendo un risultato intermedio tra i due mondi.
Crescita delle stelle GitHub dei framework agentici
Confronto dei framework di AI agentica
I framework di AI agentica variano su diverse dimensioni chiave, e comprendere queste differenze è essenziale per fare confronti significativi.
Orchestrazione multi-agente
L'orchestrazione multi-agente coordina più agenti AI specializzati per affrontare flussi di lavoro complessi che superano le capacità di un singolo agente. Invece di costruire un agente monolitico, l'orchestrazione divide il lavoro tra agenti con ruoli, strumenti e competenze distinti. Ogni framework offre approcci diversi al coordinamento degli agenti.
LangGraph
LangGraph è un framework relativamente noto e si distingue come opzione chiave per gli sviluppatori che costruiscono sistemi di agenti.
Coordinamento multi-agente esplicito: Puoi modellare più agenti come nodi individuali o gruppi, ciascuno con la propria logica, memoria e ruolo nel sistema.
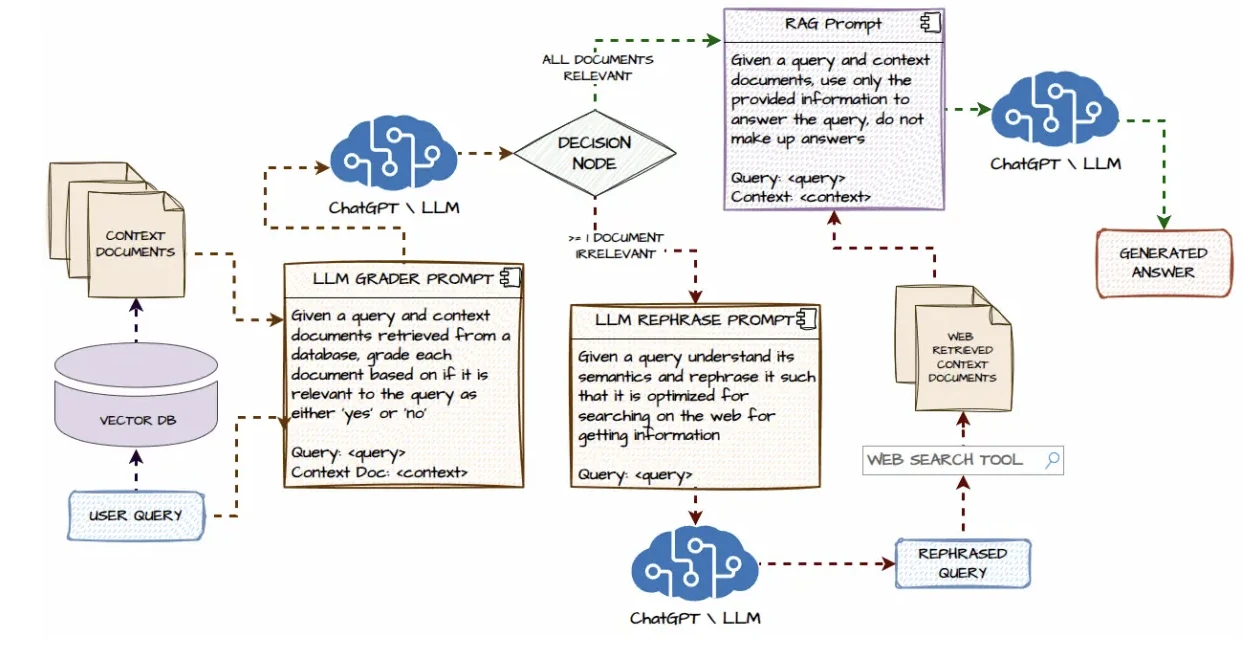
Crea flussi di lavoro AI attraverso API e strumenti. Pertanto, è una buona scelta per RAG e pipeline personalizzate.
AutoGen
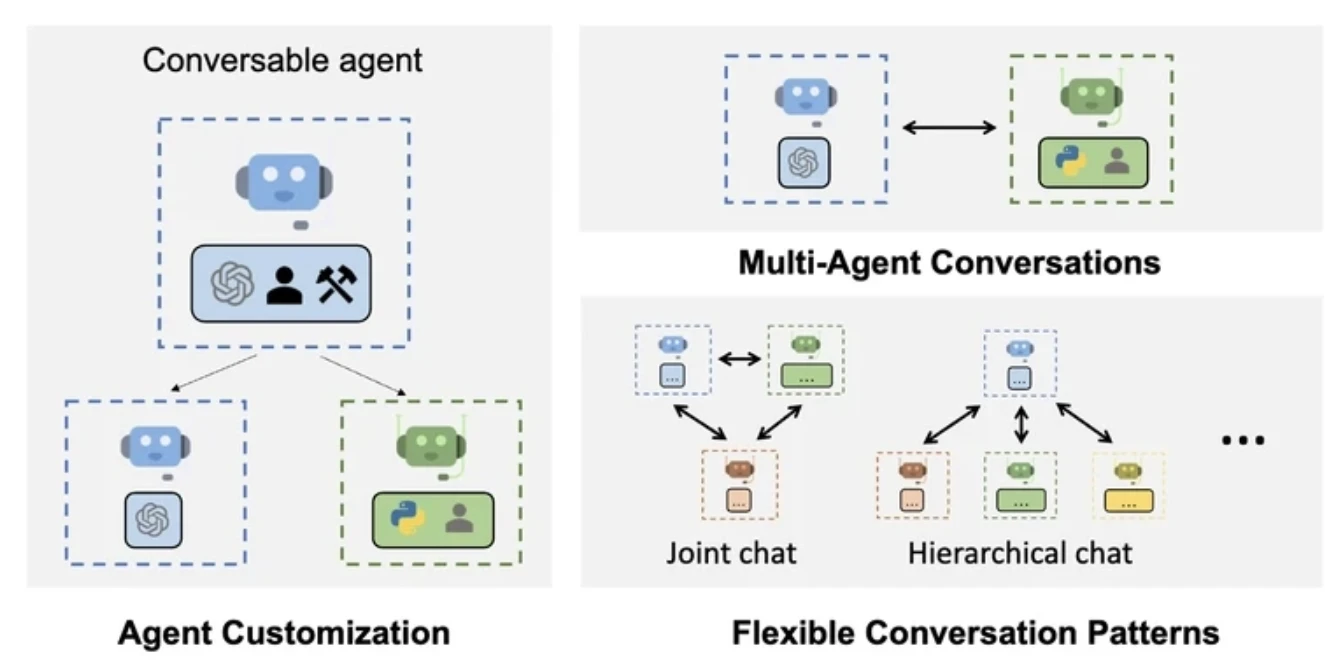
AutoGen consente a più agenti di comunicare scambiandosi messaggi in un ciclo. Ogni agente può rispondere, riflettere o chiamare strumenti in base alla propria logica interna.
Dispone di una collaborazione asincrona tra agenti, che lo rende particolarmente utile per scenari di ricerca e prototipazione in cui il comportamento degli agenti richiede sperimentazione o raffinamento iterativo.
CrewAI
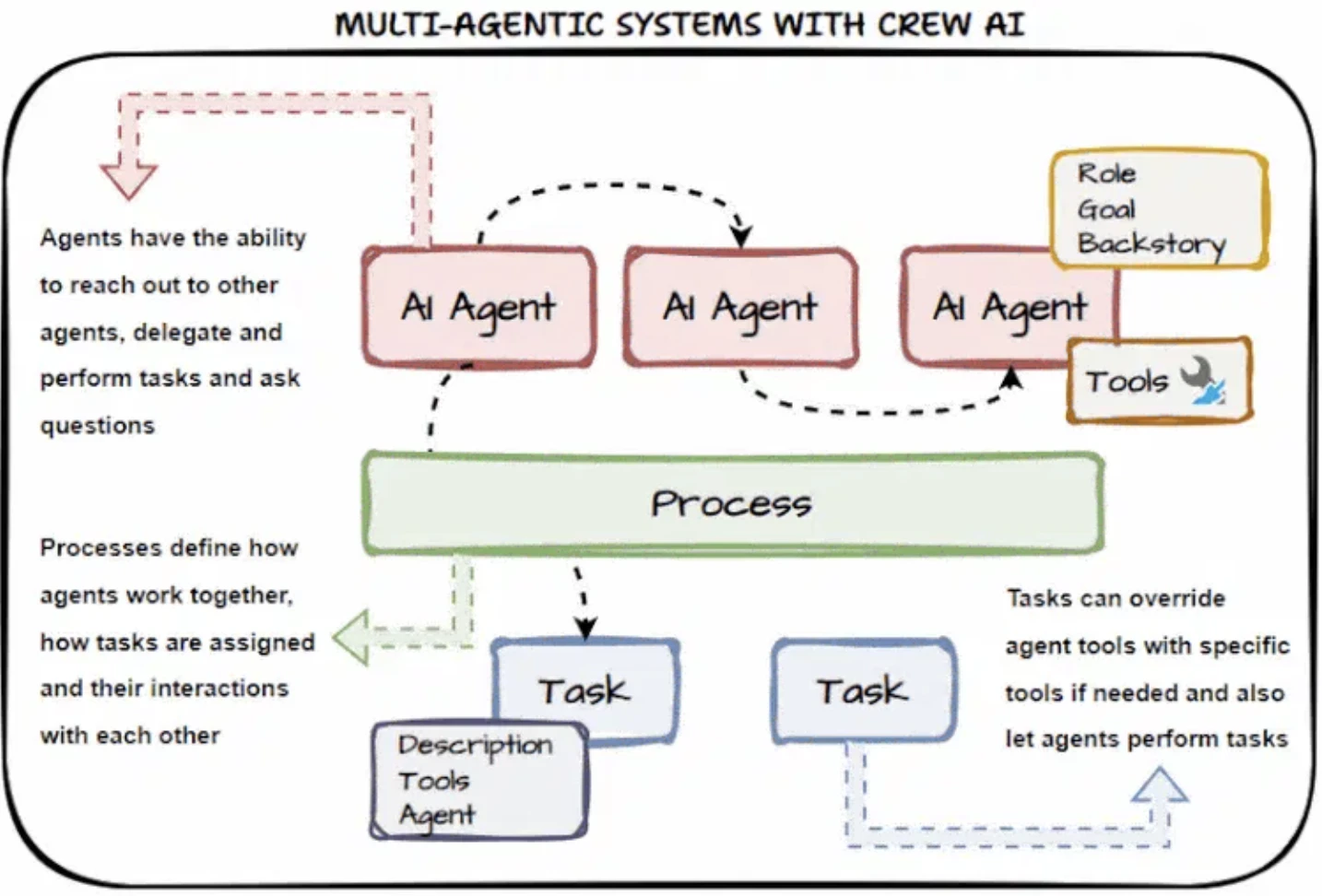
CrewAI gestisce la maggior parte della logica di basso livello per te e fornisce orchestrazione multi-agente:
- Si integra con strumenti di monitoraggio per il tracciamento e il debugging
- Controllo dell'esecuzione integrato tramite Flows con logica condizionale, cicli e gestione dello stato
- Supporta il coordinamento multi-agente gerarchico (manager-lavoratore) e strutturato
OpenAI Swarm
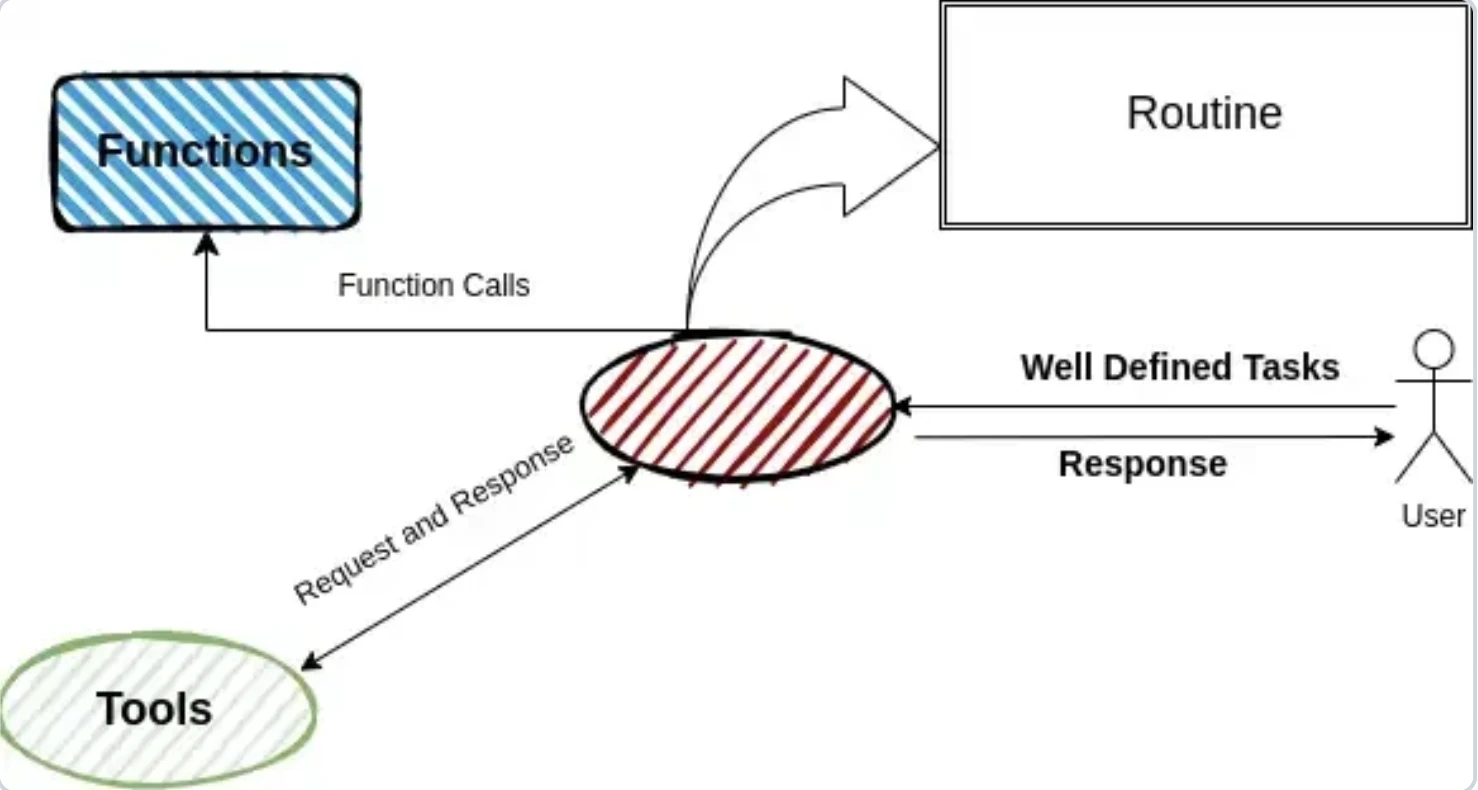
Swarm è un framework multi-agente leggero e sperimentale per la prototipazione. Gli agenti lavorano sequenzialmente tramite passaggi di consegne, trasferendo i task mantenendo un contesto condiviso. Utilizza routine in linguaggio naturale e strumenti Python per flussi di lavoro flessibili.
LangChain
LangChain è un framework per la costruzione di applicazioni LLM con singolo agente e strumenti RAG. Fornisce componenti modulari tra cui catene, strumenti, memoria e recupero per flussi di lavoro di elaborazione documentale.
LangChain opera principalmente attraverso schemi di esecuzione a singolo agente in cui un agente gestisce il flusso di lavoro.
Definizione di agenti e funzioni
LangGraph
LangGraph adotta un approccio basato su grafi al design degli agenti, dove ogni agente è rappresentato come un nodo che mantiene il proprio stato. Questi nodi sono collegati attraverso un grafo diretto, consentendo logica condizionale, coordinamento multi-team e controllo gerarchico. Questo ti permette di costruire e visualizzare grafi multi-agente con nodi supervisori per un'orchestrazione scalabile.
LangGraph utilizza funzioni annotate e strutturate che collegano gli strumenti agli agenti. Puoi costruire nodi, collegarli a vari supervisori e visualizzare come interagiscono i diversi team. Pensalo come dare a ciascun membro del team una descrizione dettagliata del lavoro. Questo rende più facile costruire e testare agenti che lavorano insieme.
AutoGen
AutoGen definisce gli agenti come unità adattive capaci di instradamento flessibile e comunicazione asincrona. Gli agenti interagiscono tra loro (e opzionalmente con gli umani) scambiandosi messaggi, consentendo la risoluzione collaborativa dei problemi. Come LangGraph utilizza funzioni annotate e strutturate.
CrewAI
CrewAI adotta un approccio di design basato su ruoli. A ogni agente viene assegnato un ruolo (ad es., Ricercatore, Sviluppatore) e un insieme di competenze, funzioni o strumenti a cui può accedere. La definizione delle funzioni avviene tramite annotazioni strutturate.
OpenAI Swarm
OpenAI Swarm utilizza un modello basato su routine in cui gli agenti sono definiti tramite prompt e docstring di funzioni. Non dispone di orchestrazione formale o modelli di stato, basandosi invece su flussi di lavoro strutturati manualmente. Il comportamento delle funzioni è dedotto dall'LLM attraverso le docstring (Swarm identifica cosa fa una funzione leggendone la descrizione), rendendo questa configurazione flessibile ma meno precisa.
LangChain
LangChain utilizza un'architettura basata su catene in cui un singolo agente orchestratore gestisce le chiamate ai modelli linguistici e ai vari strumenti. Definisce le funzioni attraverso interfacce esplicite come toolkit e template di prompt.
Sebbene sia principalmente focalizzato su flussi di lavoro centralizzati, LangChain supporta estensioni per configurazioni multi-agente ma manca di comunicazione nativa agente-agente.
Memoria
Capacità di memoria:
- Con stato: Se il framework supporta la memoria persistente tra un'esecuzione e l'altra.
- Contestuale: Se supporta la memoria a breve termine tramite cronologia dei messaggi o passaggio di contesto.
Le funzionalità di memoria sono una parte fondamentale della costruzione di sistemi agentici per ricordare il contesto e adattarsi nel tempo:
- Memoria a breve termine: Tiene traccia delle interazioni recenti, consentendo agli agenti di gestire conversazioni multi-turno o flussi di lavoro passo-passo.
- Memoria a lungo termine: Memorizza informazioni persistenti tra le sessioni, come le preferenze dell'utente o la cronologia dei task.
- Memoria delle entità: Tiene traccia e aggiorna la conoscenza su oggetti, persone o concetti specifici menzionati durante le interazioni (ad es., ricordare il nome di un'azienda o un ID progetto menzionato in precedenza).
LangGraph
LangGraph utilizza due tipi di memoria: memoria in-thread, che memorizza informazioni durante un singolo task o conversazione, e memoria cross-thread, che salva i dati tra le sessioni. Gli sviluppatori possono usare MemorySaver per salvare il flusso di un task e collegarlo a uno specifico thread_id. Per l'archiviazione a lungo termine, LangGraph supporta strumenti come InMemoryStore o altri database. Questo fornisce un controllo flessibile su come la memoria è delimitata e conservata tra le esecuzioni.
AutoGen
AutoGen utilizza un modello di memoria contestuale. Ogni agente mantiene un contesto a breve termine attraverso un oggetto context_variables, che memorizza la cronologia delle interazioni. Non dispone di memoria persistente integrata.
CrewAI
CrewAI fornisce memoria a livelli pronta all'uso. Memorizza la memoria a breve termine in un vector store ChromaDB, i risultati recenti dei task in SQLite e la memoria a lungo termine in una tabella SQLite separata (basata sulle descrizioni dei task). Inoltre, supporta la memoria delle entità utilizzando embedding vettoriali. Questa configurazione di memoria viene configurata automaticamente quando memory=True è abilitato,
OpenAI Swarm
Swarm è senza stato e non gestisce la memoria in modo nativo. Gli sviluppatori possono passare la memoria a breve termine attraverso context_variables manualmente e, opzionalmente, integrare strumenti esterni o livelli di memoria di terze parti (ad es., mem0) per memorizzare il contesto a più lungo termine.
LangChain
LangChain supporta sia la memoria a breve termine che quella a lungo termine attraverso componenti flessibili. La memoria a breve termine è tipicamente gestita tramite buffer in-memory che tracciano la cronologia delle conversazioni all'interno di una sessione. Per la memoria a lungo termine, LangChain si integra con vector store esterni o database per persistere embedding e dati di recupero.
Gli sviluppatori possono personalizzare gli ambiti e le strategie di memoria utilizzando le classi di memoria integrate, consentendo una gestione efficiente della memoria contestuale e specifica delle entità attraverso le interazioni.
Human-in-the-loop
LangGraph
LangGraph supporta breakpoint personalizzati (interrupt_before) per mettere in pausa il grafo e attendere l'input dell'utente a metà esecuzione.
AutoGen
AutoGen supporta nativamente agenti umani tramite UserProxyAgent, consentendo agli umani di rivedere, approvare o modificare i passi durante la collaborazione tra agenti.
CrewAI:
CrewAI abilita il feedback dopo ogni task impostando human_input=True; l'agente si mette in pausa per raccogliere input in linguaggio naturale dall'utente.
OpenAI Swarm
OpenAI Swarm non offre HITL integrato.
LangChain
LangChain consente di inserire breakpoint personalizzati all'interno di catene o agenti per mettere in pausa l'esecuzione e richiedere input umano. Questo supporta revisione, feedback o intervento manuale in punti definiti del flusso di lavoro.
Integrazione del Model Context Protocol (MCP) nei framework di AI agentica
Gli agenti AI devono interagire con strumenti esterni come database, API, file system e applicazioni aziendali. Senza uno standard, ogni framework doveva costruire integrazioni personalizzate per ogni strumento, creando un ecosistema frammentato. MCP risolve questo problema fornendo un protocollo universale che consente a qualsiasi agente di connettersi a qualsiasi strumento attraverso un'unica interfaccia.
Come ciascun framework si integra con MCP
LangGraph
LangGraph si connette ai server MCP attraverso un adattatore che scopre automaticamente gli strumenti disponibili e li converte in un formato compatibile con LangChain. Gli agenti possono quindi utilizzare questi strumenti senza soluzione di continuità insieme alle loro capacità native.
AutoGen
AutoGen fornisce un'integrazione MCP integrata attraverso il suo modulo di estensione. Gli sviluppatori possono connettersi ai server MCP e rendere tutti i loro strumenti disponibili agli agenti AutoGen con poche righe di codice.
CrewAI
Gli agenti CrewAI possono fare riferimento direttamente ai server MCP nella loro configurazione utilizzando semplici URL o impostazioni strutturate. Il framework gestisce automaticamente il ciclo di vita della connessione e la gestione degli errori.
OpenAI Swarm
Swarm beneficia del supporto MCP nativo di OpenAI in tutto il suo ecosistema. Poiché OpenAI ha integrato MCP in ChatGPT e nel suo Agents SDK, Swarm può sfruttare direttamente questa infrastruttura.
LangChain
LangChain offre funzionalità di chiamata degli strumenti MCP in cui le funzioni Python fungono da ponte verso i server MCP. Questo consente di prelevare strumenti da varie fonti e integrarli in catene, agenti e altri componenti LangChain senza wrapper personalizzati.
Cosa fanno effettivamente i framework di AI agentica?
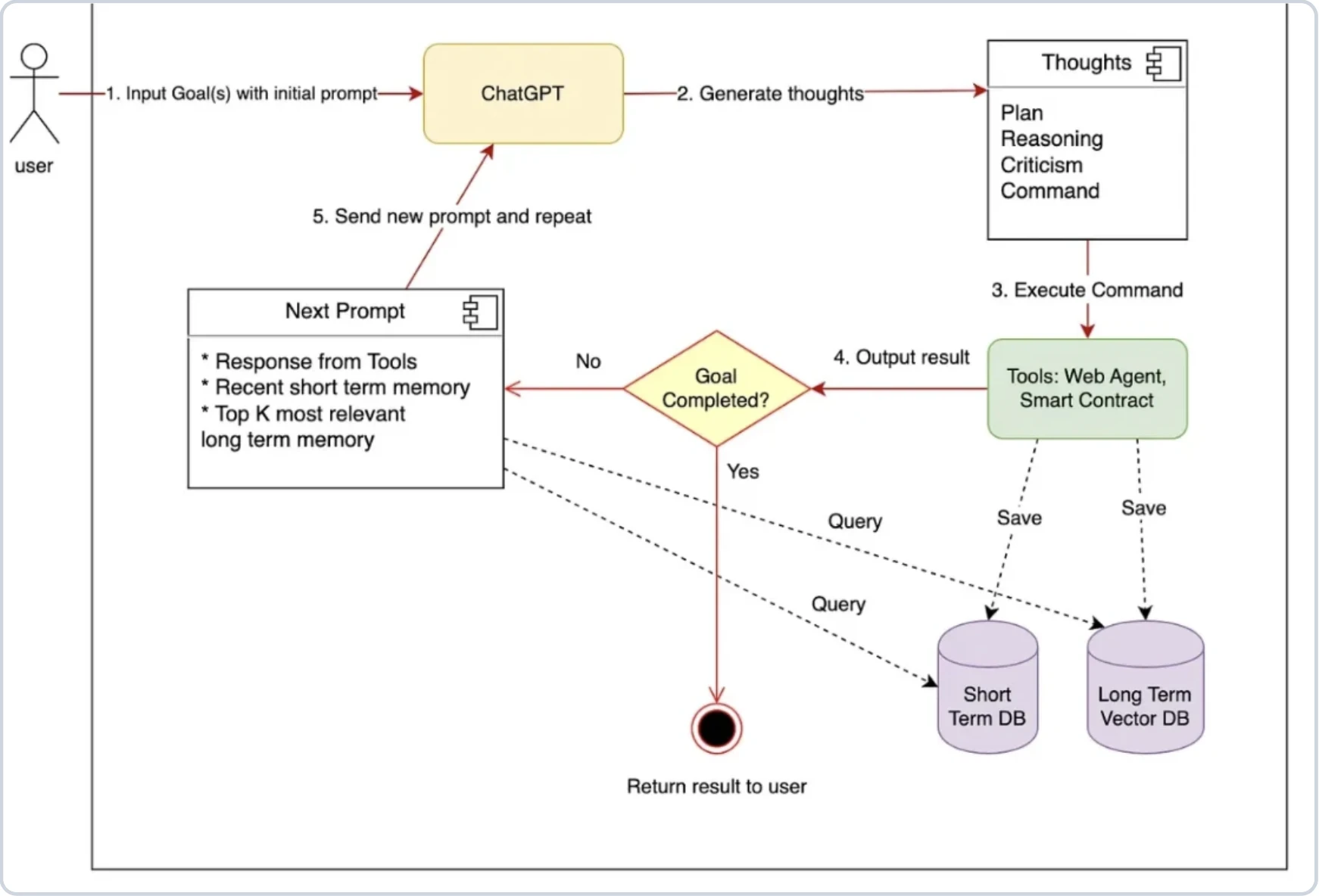
I framework di AI agentica assistono con il prompt engineering e la gestione di come i dati fluiscono verso e dagli LLM. A un livello base, aiutano a strutturare i prompt in modo che l'LLM risponda in un formato prevedibile e instradino le risposte allo strumento, all'API o al documento giusto.
Se si costruisse da zero, si definirebbe manualmente il prompt, si estrarrebbe lo strumento che l'LLM vuole utilizzare e si attiverebbe la corrispondente chiamata API. I framework semplificano questo processo attraverso:
- Orchestrazione dei prompt: Costruzione, gestione e instradamento di prompt complessi verso gli LLM
- Integrazione degli strumenti: Consentire agli agenti di chiamare API esterne, database, funzioni di codice, ecc.
- Memoria: Mantenere lo stato attraverso i turni o le sessioni (a breve e lungo termine)
- Integrazione RAG: Abilitare il recupero di conoscenza da fonti esterne
- Coordinamento multi-agente: Strutturare come gli agenti collaborano o delegano i task
Framework di AI agentica: Casi d'uso reali
LangGraph – Pianificatore di viaggio multi-agente
Un progetto di produzione costruito con LangGraph dimostra un assistente di viaggio multi-agente con stato che recupera dati di voli e hotel (utilizzando le Google Flights & Hotels API) e genera raccomandazioni di viaggio.4
CrewAI – Creatore di contenuti agentico
Il repository di esempi ufficiali di CrewAI include flussi come pianificazione di viaggi, strategia di marketing, analisi azionaria e assistenti per il reclutamento, dove agenti con ruoli specifici (ad es., "Ricercatore", "Scrittore") collaborano ai task.5
CrewAI trasforma un brief di contenuto di alto livello in un articolo completo utilizzando Groq.
Funzionalità principali dei framework di AI agentica
Supporto dei modelli:
- La maggior parte sono agnostici rispetto al modello, supportando più fornitori di LLM (ad es., OpenAI, Anthropic, modelli open-source).
- Tuttavia, le strutture dei prompt di sistema variano in base al framework e possono funzionare meglio con alcuni modelli rispetto ad altri.
- L'accesso e la personalizzazione dei prompt di sistema è spesso essenziale per risultati ottimali.
Strumentazione:
- Tutti i framework supportano l'uso di strumenti, una parte fondamentale per abilitare le azioni degli agenti.
- Offrono astrazioni semplici per definire strumenti personalizzati.
- La maggior parte supporta Model-Context-Protocol (MCP), nativamente o tramite estensioni della comunità.
Memoria / Stato:
- Utilizzano il tracciamento dello stato per mantenere la memoria a breve termine attraverso i passi o le chiamate all'LLM.
- Alcuni aiutano gli agenti a conservare interazioni o contesto precedenti all'interno di una sessione.
RAG (Retrieval-Augmented Generation):
- La maggior parte include opzioni di configurazione semplice per RAG, integrando database vettoriali o archivi documentali.
- Questo consente agli agenti di fare riferimento a conoscenza esterna durante l'esecuzione.
Altre funzionalità comuni
- Supporto per esecuzione asincrona, consentendo chiamate concorrenti ad agenti o strumenti.
- Gestione integrata per output strutturati (ad es., JSON).
- Supporto per output in streaming dove il modello genera risultati in modo incrementale.
- Funzionalità di osservabilità di base per il monitoraggio e il debugging delle esecuzioni degli agenti.
Metodologia del benchmark
1. Struttura dei Task
Task 1: Misura se una singola chiamata a uno strumento può essere effettuata con il parametro corretto. L'overhead dell'infrastruttura di base del framework viene rivelato più chiaramente in questo scenario semplice.
Task 2: Richiede di mantenere in memoria i risultati di due gruppi di filtri separati e combinarli in un unico output. Vengono testate la gestione dello stato e il coordinamento multi-segmento.
Task 3: Misura se le condizioni numeriche in linguaggio naturale vengono tradotte in parametri per gli strumenti senza distorsioni. Il vero test è se i meccanismi di retry e re-prompt del framework riescono a preservare questi parametri.
Task 4: Uno strumento genera errori di Rete, Timeout e RateLimit in successione. Si misura se il framework cambia strategia di fronte a questi errori.
Task 5: L'agente deve prima scoprire le colonne JSON e LongText, quindi chiamare gli strumenti corretti con i parametri di ambito corretti. Si osserva se il framework esegue strumenti indipendenti in parallelo o in sequenza.
2. Configurazione
Tutti i framework hanno utilizzato lo stesso modello LLM (openai/gpt-5.2) e lo stesso valore di temperatura (0.1). Per tutti i task, a ciascun agente sono stati forniti gli stessi strumenti e gli stessi prompt. Ogni framework è stato configurato nella sua struttura nativa: LangChain con AgentExecutor, LangGraph con StateGraph, AutoGen con AssistantAgent + UserProxyAgent e CrewAI con Agent + Task + Crew.
È stato utilizzato il dataset IBM Telco Customer Churn (7.032 clienti). Lo stato degli strumenti è stato resettato prima di ogni esecuzione. Sono state eseguite 100 esecuzioni indipendenti per ogni combinazione di framework e task.
I limiti massimi di iterazione sono stati impostati in base alla complessità del task: 10 per i Task 1, 2 e 3; 20 per il Task 4 a causa del ciclo di strumenti instabili; e 20 per il Task 5 a causa della catena di scoperta in 4 passi.
Cita questo benchmark
Scegli il formato adatto a dove pubblicherai. Incollare la versione con link nel tuo CMS preserva il backlink.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Şipi, Nazlı},
title = {{I 5 migliori framework open-source di AI agentica}},
year = {2026},
month = jul,
howpublished = {\url{https://aimultiple.com/agentic-frameworks}},
note = {AIMultiple. Consultato il 6 Luglio 2026}
}
Commenti 1
Condividi i tuoi pensieri
Il tuo indirizzo email non verrà pubblicato. Tutti i campi sono obbligatori. I commenti vengono lasciati nella loro lingua originale.
Thank you for this informative and detailed article! It helped me get a reading on these frameworks.