I migliori 50+ agenti IA open source elencati
Tutti stanno costruendo agenti IA, quindi dopo test pratici con i più popolari agenti di codifica IA, builder di agenti IA e benchmark di utilizzo degli strumenti per valutare le loro capacità nel mondo reale, abbiamo messo insieme una lista curata dei migliori 50+ agenti IA open source. Clicca sulle intestazioni delle categorie per andare direttamente alle nostre scelte migliori:
Sviluppo e infrastruttura per agenti
Applicazioni agentive per domini specifici
- Agenti di automazione e navigazione web
- Strumenti di codifica e sviluppo
- Strumenti di cybersecurity
- Creatori di contenuti video IA
- Assistenti finanziari
- Assistenti sanitari
- Agenti di ricerca
- Assistenti di analisi dati
- Assistenti personali
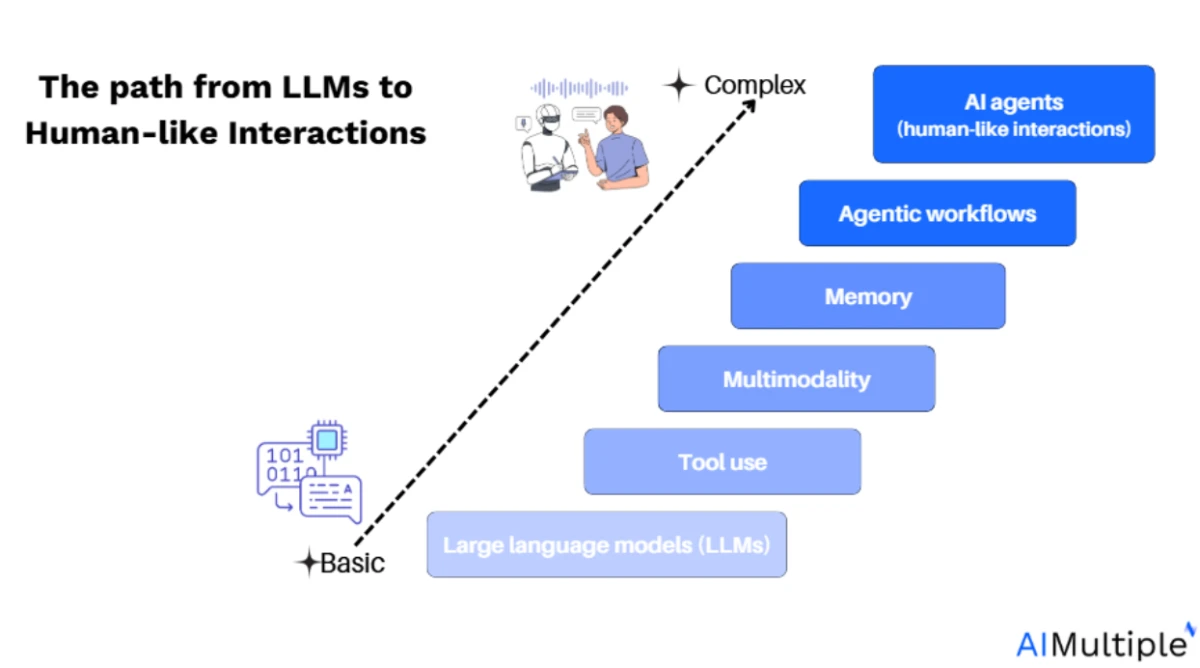
Come pensare agli agenti IA?
Un agente IA è un sistema componibile che combina pianificazione, memoria, uso di strumenti ed esecuzione iterativa. Forma un ciclo strutturato attorno a un LLM che può prendere decisioni, eseguire azioni e adattarsi a nuove informazioni.
Ecco come pensarci:
- Autonomia e workflow: Gli agenti IA spaziano dall'automazione di base basata su workflow predefiniti a sistemi completamente autonomi capaci di scomposizione degli obiettivi, uso della memoria e interazione con strumenti. La sfida tecnica principale sta nel mantenere il contesto attraverso i passaggi e coordinare operazioni a più fasi.
- Contesto e controllo: La vera sfida negli agenti IA è garantire che l'LLM abbia il contesto appropriato ad ogni passaggio. Questo include la gestione dei contenuti forniti all'LLM e l'assicurarsi che l'agente esegua compiti pertinenti basati su un contesto aggiornato.
- Integrazione degli strumenti: Costruire agenti efficaci richiede un'integrazione fluida con strumenti esterni, API e fonti di dati. Framework come LangChain possono aiutare a integrare queste risorse esterne, ma il controllo sul workflow è essenziale per adattare il comportamento dell'agente a nuovi input.
- Vantaggi dei framework per agenti: Tutti i sistemi agentici, siano essi semplici workflow o agenti autonomi complessi, possono beneficiare delle funzionalità principali fornite dai framework agentici. Queste funzionalità possono essere costruite da zero o sfruttate da una piattaforma open source esistente, a seconda delle tue esigenze.
Nuovi standard
- Model Context Protocol (MCP): Lo standard del settore per come gli agenti comunicano con fonti di dati esterne. LangGraph integra l'MCP per consentire agli agenti di "plug and play" con database e strumenti locali senza wrapper personalizzati.
- Stripe Agentic Commerce Protocol (ACP): Questo è il primo standard di settore attivo che consente agli agenti IA di gestire pagamenti, inventario e spedizioni in modo sicuro. Abilita l'"Agentic Checkout", dove l'agente può completare un acquisto per l'utente all'interno di un'interfaccia di chat.
Cos'è esattamente un agente IA?
Non esiste una definizione universalmente condivisa di ciò che costituisce un "agente IA".
- L'IA tradizionale definisce gli agenti come sistemi che interagiscono con il loro ambiente.
- Il sondaggio di Simon Willison tra i professionisti presenta una varietà di definizioni operative da parte dei partecipanti del settore.2
- La definizione di Anthropic delinea principi di progettazione per costruire agenti IA efficaci e allineati.3
- Le principali società di consulenza sottolineano il ruolo degli agenti nell'automatizzare i workflow aziendali e il processo decisionale.4 .
Molte di queste includono esplicitamente workflow e autonomia alla fine di uno spettro.
Siamo d'accordo con questi punti di vista, pertanto non forniamo una definizione rigida. Elenchiamo invece i fattori che fanno sì che un sistema IA sia considerato più agentico:
- Ambiente e obiettivi:
- I sistemi IA in ambienti complessi, come quelli con compiti multipli e cambiamenti inaspettati, sono agentici.
- I sistemi IA che seguono obiettivi senza essere istruiti sono agentici.
- Interfaccia utente e supervisione: I sistemi IA che possono apprendere linguaggi naturali e i sistemi che necessitano di meno supervisione umana sono agentici.
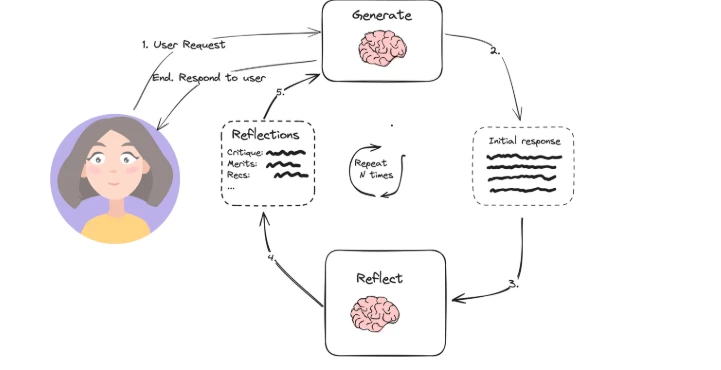
- Progettazione del sistema: I sistemi che utilizzano pattern di progettazione come l'uso di strumenti (es. ricerca web, programmazione) o la pianificazione (es. riflessione, scomposizione in sotto-obiettivi) sono agentici.
Per una spiegazione più dettagliata, abbiamo precedentemente elencato questi fattori e discusso come essi definiscono i sistemi IA agentici.
Questi agenti sono completamente autonomi?
Non ancora. La maggior parte degli agenti IA open source migliora l'autonomia degli LLM abilitando l'uso di strumenti, il processo decisionale e la risoluzione dei problemi, ma richiedono ancora input strutturati e un essere umano nel ciclo.
Esempi come Devon e PR-Agent seguono logiche predefinite o workflow RL piuttosto che dimostrare un comportamento agentico completo. Altri agenti IA mancano ancora di capacità di (Apprendimento Autonomo + Generalizzazione).
Quando (e quando non) usare gli agenti IA
Non tutte le applicazioni LLM richiedono complessità agentica. Molti casi d'uso sono meglio serviti da una leggera generazione aumentata da recupero (RAG).
I sistemi agentici introducono un sovraccarico architetturale: gestione della memoria, orchestrazione degli strumenti, gestione degli errori e cicli di controllo che aumentano latenza e costi. Ad esempio, nei nostri benchmark, abbiamo osservato che i tassi di successo degli agenti IA diminuivano dopo 35 minuti di interazione umana.
Per mitigare questi rischi, è essenziale testare i sistemi agentici in ambienti controllati e implementare solidi guardrail prima del deployment.
Gli agenti sono più preziosi quando i passaggi non possono essere facilmente previsti o codificati. Sono particolarmente adatti per situazioni in cui:
- I compiti sono dinamici e multi-step, con logica ramificata o sotto-obiettivi poco chiari.
- L'uso degli strumenti è condizionale o adattivo, richiedendo al sistema di scegliere quale strumento invocare in base all'input o allo stato precedente.
- È richiesta memoria a lungo termine o contesto, attraverso sessioni o fasi di esecuzione.
- L'esecuzione deve rispondere al feedback ambientale, come risultati di API, output di ricerca o azioni fallite.
- È necessaria la collaborazione human-in-the-loop, dove autonomia e supervisione devono essere bilanciate (es. IA copilot).
D'altra parte, workflow o chiamate LLM senza stato sono preferibili quando:
- La logica del compito è statica o prevedibile, come la compilazione di moduli o la trasformazione di contenuti.
- La bassa latenza è critica, come nelle interazioni rivolte all'utente.
- Minimizzare i costi è essenziale, specialmente evitando chiamate LLM ricorsive e orchestrazioni complesse.
Approfondisci
Ecco i nostri benchmark più recenti sull'infrastruttura comunemente utilizzata dai sistemi agentici:
- Browser remoti: Come l'infrastruttura dei browser consente agli agenti di interagire con il web in modo sicuro.
- Benchmark Browser MCP: I migliori server MCP per l'uso di strumenti e l'accesso web.
Esempi di agenti IA open source
Alcuni strumenti descritti come "agenti IA" non sono in realtà così agentici; questi sistemi (es. Devon PR-agent) sono in gran parte workflow IA basati su RL, con LLM organizzati attraverso percorsi di codice predefiniti.
1. Framework per agenti (Costruisci il tuo)
Librerie modulari e SDK per sviluppatori per costruire agenti con controllo su logica, memoria, strumenti e orchestrazione.
✳️ Alcuni agenti come SmolAgents e Agno rientrano sia nella categoria dei framework per agenti che in quella dell'automazione dei workflow.
Framework generici per agenti
Framework che si concentrano sulla costruzione di agenti, offrendo strumenti flessibili e personalizzabili per orchestrare workflow, configurazioni multi-agente e casi d'uso generici.
- LangGraph – Orchestrazione di workflow LLM basata su grafi – LangGraph è un software proprietario, ma fornisce una libreria open source per lo sviluppo di agenti. Ideale per pipeline RAG, memoria degli agenti/ gestione dello stato e configurazioni multi-agente.
- AutoGen – Collaborazione asincrona multi-agente – Progettato per coordinare agenti che usano strumenti attraverso API simili a chat. Ideale per automatizzare workflow complessi, in particolare nella generazione autonoma di codice.
- CrewAI – Framework multi-agente no-code/low-code – Uno degli strumenti più facili con cui iniziare, offre template di agenti pronti all'uso (es. agente per la preparazione di riunioni).
Framework specializzati per agenti
Framework con un focus specializzato su tipi specifici di comportamenti agentici o integrazioni di agenti.
- Camel – Simulazione di agenti basata su ruoli – Ottimizzato per agenti collaborativi di role-playing che utilizzano ragionamento strutturato. Ideale per automazione dei workflow e generazione di dati sintetici.
- Mastra – Sviluppo di agenti integrati nel frontend – Basato su JavaScript, ideale per incorporare agenti in applicazioni rivolte all'utente.
- PydanticAI – Controllo minimo degli agenti con type safety – Fornisce validazione rigorosa e percorsi logici trasparenti con Pydantic.
- Cybersecurity IA (CAI) – Framework agentico per la cybersecurity basato su IA – Fornisce penetration testing, scoperta di vulnerabilità e red teaming con capacità human-in-the-loop, sfruttando large language model e integrazioni con strumenti come Nmap.
- Atomic Agents – Builder di agenti personalizzati granulari schema-first – Costruito per una struttura granulare degli agenti e logica componibile.
- SmolAgents – SDK leggero per agenti per sviluppatori – Astrazione minima, indirizza la logica tramite Python invece di JSON.
Runtime per agenti (agenti autonomi pre-costruiti)
Agenti pre-costruiti e autonomi che puoi eseguire immediatamente (come un'app). Tipicamente supportano l'esecuzione autonoma di compiti a partire da obiettivi in linguaggio naturale.
Completamente autonomi:
- Auto-GPT – Scomposizione degli obiettivi ed esecuzione autonoma – Scompone gli obiettivi in sotto-compiti e li completa usando strumenti, memoria e ragionamento. Offre agenti pre-costruiti e un'interfaccia low-code.
- AIlice – Esecuzione di compiti generici in locale – Esegue compiti complessi sul dispositivo, supporta strumenti locali e manipolazione di file. Mira a creare un assistente IA, simile a JARVIS, basato su LLM open source.
- Manus IA – Operazioni generiche in sandbox. Esegue strumenti e workflow in una sandbox sicura, capace di gestire operazioni multi-dominio e multi-step in modo autonomo. È stato acquisito da Meta, integrandosi nell'ecosistema "Personal Ambient Intelligence" di Meta.5
Parzialmente autonomi:
- BabyAGI – Esecutore iterativo di cicli di compiti – Crea, priorizza ed esegue liste di compiti in un ciclo di feedback. Ideale per esperimenti di generazione di compiti.
Basati su browser/interfaccia:
- AgentGPT – Agente autonomo distribuito via browser – Consente agli utenti di creare ed eseguire agenti di compiti attraverso un'interfaccia web. Leggero, ideale per la sperimentazione.
- OpenManus – Agente browser persistente – Progettato per workflow che coprono più sessioni in ambienti browser. Utilizza strumenti come Playwright per automatizzare le interazioni web. Adatto per l'uso in pipeline di automazione esistenti. La configurazione è rapida con Conda.
2. Automazione e orchestrazione dei workflow
Strumenti che automatizzano i workflow e integrano più piattaforme o servizi, spesso con la capacità di integrare agenti IA.
Agenti generici di automazione e integrazione dei workflow
Piattaforme che connettono API, attivano eventi e automatizzano compiti, rendendo facile costruire e integrare workflow tra diversi sistemi.
- n8n – Automazione visuale dei workflow e integrazione di API – Connette app, trigger e flussi di dati usando un editor a nodi. Combina la costruzione visuale no-code con JavaScript/Python personalizzato e supporta 400+ integrazioni. Puoi auto-ospitarlo, eseguire workflow di agenti IA con LangChain. Ideale per persone tecniche.
- PlanExe – Strumento di pianificazione da LLM a Gantt/WBS – Pianificatore IA simile alla deep research di OpenAI. Converte obiettivi in linguaggio naturale in tempistiche strutturate usando LlamaIndex.
- Agno ✳️ – Builder di workflow e agenti per sviluppatori – Si adatta sia come strumento di automazione dei workflow (aiutando ad automatizzare compiti e workflow) che come builder di agenti.
- SmolAgents ✳️ – SDK leggero per agenti per sviluppatori – SmolAgents è abbastanza flessibile da adattarsi sia come SDK leggero per agenti (per framework agentici) che come strumento di workflow (poiché si integra con i modelli di Hugging Face).
- Windmill – Piattaforma di sviluppo open source e motore di workflow – Converte script in UI, API e cron job; supporta Python, TypeScript, Go e altri linguaggi.
- Activepieces – Piattaforma di automazione open source – Builder di workflow visuale auto-ospitato per automatizzare compiti e integrare app con codifica minima. Supporta 280+ server MCP per eseguire compiti IA distribuiti e catene di agenti su scala.
- Huginn – Automazione web e gestione degli agenti – Costruisce agenti per automatizzare compiti basati sul web e monitoraggio.
- Node-RED – Sviluppo basato su flussi per IoT e dati in tempo reale – Integra servizi e automatizza compiti con un editor di flussi basato su browser.
Orchestrazione di workflow multi-agente
Framework progettati per coordinare agenti interagenti attraverso workflow strutturati e integrare sistemi multi-agente.
- HyperAgent – Orchestrazione di agenti per l'intero ciclo di vita del software – Gli agenti lavorano insieme per pianificare, codificare e verificare compiti ingegneristici.
- Supercog – agentic – Orchestrazione modulare con blocchi logici riutilizzabili – Progettato per un'automazione scalabile, strutturata e basata su team.
3. Automazione e navigazione web
Agenti che navigano autonomamente siti web ed eseguono compiti multi-step, come la compilazione di moduli, l'estrazione di dati e l'automazione della navigazione web.
Agenti web autonomi e copiloti
Agenti autonomi generici (con capacità web):
- AgenticSeek – Agente di navigazione web completamente autonomo – Manus IA completamente locale. Specializzato nell'estrazione di dati e nella compilazione di moduli, automatizzando compiti basati sul web.
- Agent-E – Agente di automazione browser DOM-aware – Si concentra sull'interazione con le pagine web analizzando il DOM (Document Object Model), ideale per cliccare pulsanti e compilare moduli.
- AutoWebGLM – Agente web basato su LLM – Utilizza l'apprendimento per rinforzo e la semplificazione dell'HTML per una migliore navigazione attraverso siti web complessi.
Agenti di navigazione web basati sulla visione (multimodali):
- Estensione Autogen WebSurfer – Agente web multimodale – Combina input testuali e visivi (screenshot) per migliorare l'interazione web.
- Skyvern – Agente IA con visione artificiale – Automatizza i workflow utilizzando LLM e visione artificiale, gestendo sia elementi testuali che visivi.
- WebVoyager – Agente web abilitato alla visione – Utilizza testo e screenshot per migliorare la navigazione su siti web ricchi di immagini.
Per ulteriori informazioni sull'automazione e la navigazione web open source, ecco una panoramica strutturata di alcuni dei migliori strumenti e agenti:
Toolkit di automazione web e scraping
RPA web basati su LLM ed estensioni browser
4. Agenti di codifica e sviluppo
Agenti IA progettati per assistere nelle attività di codifica, fornendo supporto in tempo reale agli sviluppatori attraverso suggerimenti di codice, debugging e automazione dei compiti.
Agenti di codifica basati su CLI
- Codex CLI – Strumento di interazione multi-modale (suggerisci, modifica, esegui) – Migliora i workflow degli sviluppatori tramite la riga di comando offrendo suggerimenti e modifiche di codice.
- OpenDevin – Assistente di codifica IA open source – Assiste nelle attività di programmazione, offrendo suggerimenti di codice per vari linguaggi. Nota: OpenDevin è stato recentemente rinominato OpenHands per riflettere la sua missione più ampia di "All Hands IA".6
- Aider – Assistente di programmazione IA in coppia – Integrato nel tuo terminale per assistenza nella codifica, supportando autocompletamento, debugging e automazione dei compiti.
Editor di codice IA
- Neovim – Editor di codice integrato con IA – Plugin basati su IA che forniscono completamenti di codice e refactoring.
- Visual Studio Code (VS Code) – Strumento di completamento del codice e debugging basato su IA – Offre suggerimenti di codice e autocompletamento tramite GitHub Copilot, integrato con ambienti IDE per sviluppatori.
- Cursor – Editor di codice integrato con IA – Costruito con completamento del codice in tempo reale basato su IA.
Builder da prompt ad app (Vibe coding)
Alternative open source a v0 / lovable / Bolt:
- Dyad – Builder di app IA open source – Strumento local-first, no-code per costruire applicazioni guidate dall'IA con comandi in linguaggio naturale.
- vx.dev – Builder di app IA open source – Uno strumento local-first, low-code focalizzato sulla trasformazione di prompt in linguaggio naturale in app.
5. Agenti di cybersecurity
Agenti IA progettati per migliorare le operazioni di cybersecurity, inclusi compiti come penetration testing, scoperta di vulnerabilità, red teaming e rilevamento autonomo delle minacce.
- YAWNING TITAN – Simulazione di cybersecurity astratta e basata su grafi – Supporta l'addestramento di agenti per operazioni cyber autonome con un focus su ambienti basati su grafi.
- bumpgen – Agente di gestione pacchetti – Aggiorna automaticamente i pacchetti npm (gestore di pacchetti di Node.js).
- Cyber-Security LLM Agents – Compiti di cybersecurity guidati da LLM – Costruito su AutoGen. Utilizzato in varie applicazioni di ricerca per dimostrare l'automazione EDR con ChatGPT e CI/CD automatizzato per l'ingegneria del rilevamento.
6. Agenti di creazione di contenuti video IA
Agenti IA che assistono nella generazione, modifica e miglioramento di contenuti visivi e multimediali, inclusi arte, immagini e video.
- Mochi – Generazione text-to-video – Converte prompt testuali in video, con un focus sulla creazione di video di breve durata. Adatto per generare rapidamente video da descrizioni testuali.
- CogVideo – Generazione text-to-video – Converte prompt testuali in video con alta fedeltà, consentendo la creazione da immagine a video. Uno strumento più avanzato per la generazione di video di alta qualità da testo o immagini.
- Allegro – Generazione text-to-video – Converte prompt testuali in video con un focus sulla creazione di contenuti creativi. Questo strumento enfatizza la sintesi video creativa dal testo per produrre narrazioni visive uniche.
- DALL·E (Versioni open-source) – Generazione text-to-video – Genera immagini da descrizioni testuali, trasformando prompt scritti in contenuti visivi dettagliati e creativi.
7. Agenti finanziari
Agenti IA che forniscono miglioramento automatizzato tramite apprendimento per rinforzo o analisi di dati finanziari in tempo reale.
- FinRL – Apprendimento per rinforzo automatizzato per il trading – Apprende ed esegue autonomamente strategie di trading basate sui dati di mercato, adattandosi ad ambienti finanziari dinamici.
- OpenBB Terminal – Analisi di dati finanziari – Fornisce approfondimenti finanziari autonomi per il trading in tempo reale, consentendo ai professionisti degli investimenti di prendere decisioni di trading informate.
8. Agenti sanitari
Agenti IA che assistono nella diagnostica medica, nel monitoraggio delle malattie e negli approfondimenti sulla salute analizzando i dati dei pazienti e i referti medici.
- HIA (Health Insights Agent) – Analisi dei referti medici – Analizza i referti medici e fornisce approfondimenti sulla salute.
- IA-HealthCare-Assistant – Diagnosi e monitoraggio delle malattie – Diagnostica e monitora le malattie utilizzando i dati dei pazienti.
9. Agenti di ricerca
Agenti IA che assistono nella raccolta dati, nelle revisioni della letteratura e nei test di ipotesi, semplificando il processo di ricerca.
- ChemCrow – Agente autonomo di ricerca chimica – Integra gli LLM con strumenti chimici per pianificare ed eseguire compiti sperimentali e computazionali complessi nell'analisi chimica.
- GPT Researcher – Assistente di ricerca generale autonomo – Esegue ricerche online strutturate, analizza contenuti e compila report di ricerca dettagliati con un input minimo da parte dell'utente.
10. Agenti di analisi dati
Agenti IA che elaborano, analizzano e interpretano dati per fornire approfondimenti azionabili e supportare il processo decisionale.
Finanza
- FinRobot – Agente di analisi dei dati finanziari – Automatizza l'interpretazione e il reporting dei dati finanziari utilizzando large language model.
Agenti di business intelligence e interrogazione
- Wren IA – Agente di approfondimenti aziendali text-to-SQL – Converte domande in linguaggio naturale in query SQL per il reporting aziendale.
- Entaoai – Strumento di data engineering assistito da GenAI – Fornisce un'interfaccia di chat per compiti di interrogazione e trasformazione dei dati.
- Vanna IA – Agente da linguaggio naturale a SQL – Genera query SQL basate sui prompt dell'utente per esplorare dataset strutturati.
Agenti per social media
- Twitter Personality Agent – Agente di analisi dei social media – Analizza la cronologia dei tweet per dedurre tratti comportamentali e di personalità.
11. Agenti di assistenza personale
Agenti IA che aiutano nella gestione dei compiti, nella pianificazione e nell'organizzazione personale, migliorando la produttività e la gestione del tempo.
- VacAIgent (agente CrewAI pre-costruito) – Assistente di pianificazione viaggi –Genera autonomamente itinerari di viaggio completi utilizzando Streamlit e LLM.
- Inbox Zero – Assistente email – priorizza, classifica e riassume i messaggi utilizzando l'elaborazione del linguaggio naturale e l'integrazione con Gmail.
- Cal – Agente di pianificazione del calendario – Automatizza la creazione, la riprogrammazione e il riassunto delle riunioni tramite interazione basata su LLM.
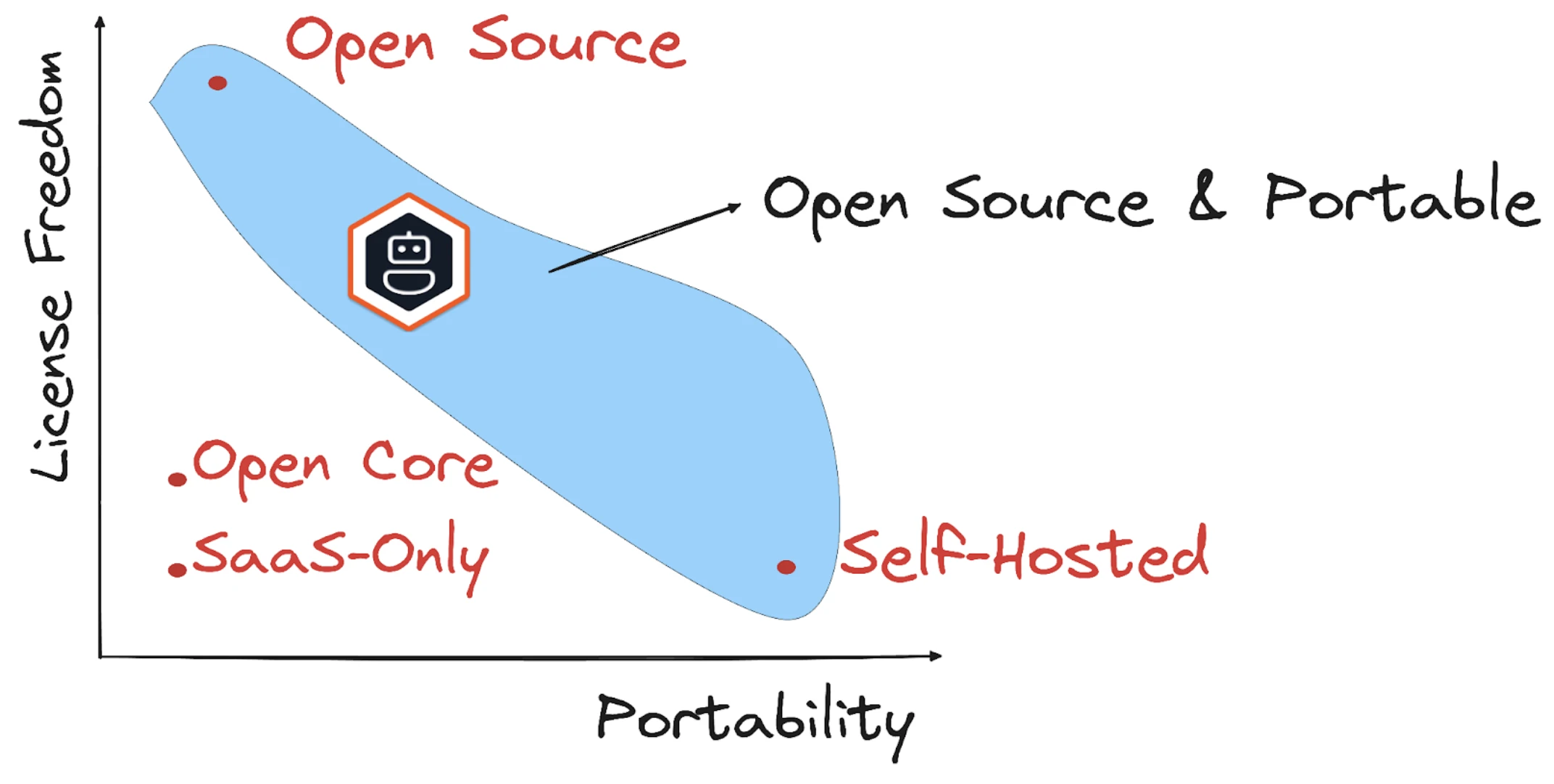
Costruire sistemi di agenti IA
Molti framework IA sono controllati da un singolo fornitore o da repo pubblici, ma strettamente governati.
Questi progetti spesso si spostano verso modelli open core: il codice di base rimane gratuito, ma l'orchestrazione multi-agente, l'osservabilità o il controllo granulare possono essere vincolati a licenze commerciali. In alcuni ecosistemi "aperti", l'uso in produzione spesso richiede l'acquisto di un backend proprietario.
Fonte7
Progetti reali di agenti IA
In base alla nostra esperienza, ecco alcuni agenti IA e le loro applicazioni:
- Editor di codice IA per lo sviluppo di API e la creazione di App
- Da screenshot a esecuzione del codice per la generazione di siti web IA
- Agenti per l'uso del computer per ordinare consegne, fare una prenotazione al ristorante o progettare una stanza.
Altri progetti autonomi di agenti IA:
Altri progetti di agenti IA basati su framework:
Ulteriori letture
Cita questa ricerca
Scegli il formato adatto a dove pubblicherai. Incollare la versione con link nel tuo CMS preserva il backlink.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{I migliori 50+ agenti IA open source elencati}},
year = {2026},
month = may,
howpublished = {\url{https://aimultiple.com/open-source-ai-agents}},
note = {AIMultiple. Consultato il 14 Maggio 2026}
}
Sii il primo a commentare
Il tuo indirizzo email non verrà pubblicato. Tutti i campi sono obbligatori. I commenti vengono lasciati nella loro lingua originale.