Confronta i Modelli Fondamentali Relazionali
Abbiamo eseguito benchmark su SAP-RPT-1-OSS contro il gradient boosting (LightGBM, CatBoost) su 17 dataset tabulari che coprono lo spettro semantico-numerico, tabelle a bassa/alta semantica, dataset aziendali misti e grandi dataset numerici a bassa semantica.
Il nostro obiettivo è misurare dove i priori semantici preaddestrati di un LLM relazionale possano fornire vantaggi rispetto ai modelli ad albero tradizionali e dove incontrino sfide su larga scala o con strutture a bassa semantica.
SAP-RPT-1-OSS vs. Gradient Boosting: Risultati del benchmark
- Tasso di successo: Rappresenta il punteggio normalizzato medio (da 0.0 a 1.0). Una barra più alta indica che il modello è costantemente più vicino alla migliore prestazione possibile per i dataset in quella categoria.
- 100 – 500 righe (3 Dataset):
- Inclusi: wine (178), sonar (208), vote (435).
- Risultato: SAP ottiene il miglior risultato su 2 dei 3 dataset. Raggiunge i punteggi più alti su wine e sonar, suggerendo che i priori LLM possono essere benefici quando i dati di addestramento sono scarsi. Tuttavia, CatBoost ha ottenuto una vittoria risicata sul dataset vote (entro lo 0,1%), indicando che i modelli ad albero rimangono altamente competitivi anche su piccola scala.
- 501 – 1.000 righe (3 Dataset):
- Inclusi: cylinder_bands (540), breast_cancer (569), credit_g (1.000).
- Risultato: SAP ottiene il miglior risultato su tutti e 3 i dataset. Su cylinder_bands, SAP ha superato LightGBM con un margine del 5,5%, potenzialmente dovuto a una migliore gestione delle descrizioni semantiche dei difetti industriali, sebbene siano necessari ulteriori studi di ablazione per confermare questo meccanismo.
- 1.000 – 10.000 righe (5 Dataset):
- Inclusi: titanic (1,3K), car_evaluation (1,7K), spambase (4,6K), compas (5,2K), employee_salaries (9,2K).
- Risultato: SAP ottiene i migliori risultati su 4 dei 5 dataset, performando particolarmente bene su compiti ad alto contenuto testuale come spambase e titanic. Tuttavia, CatBoost supera significativamente SAP su compas del 10,4%, indicando caratteristiche specifiche del dataset che favoriscono i modelli ad albero anche in questa fascia di dimensioni.
- 10.000+ righe (6 Dataset):
- Inclusi: california_housing (20K), house_sales (21K), default_credit (30K), adult_income (48K), diamonds (53K), higgs_100k (98K).
- Risultato: Man mano che il volume dei dati cresce, il potenziale vantaggio di "conoscenza pregressa" del LLM diminuisce. LightGBM e CatBoost ottengono i migliori risultati su 5 dei 6 dataset, offrendo una migliore accuratezza a una frazione del costo computazionale. L'unica eccezione, california_housing, mostra solo un modesto vantaggio del 1,7% per SAP.
1. Tabella dei dataset dei risultati del benchmark
Di seguito è riportata la suddivisione completa delle prestazioni del modello su tutti i 17 dataset.
2. Analisi costi ed efficienza
Abbiamo calcolato il costo computazionale diretto per ogni modello in base ai prezzi dell'istanza H200 di RunPod di 3,59 $/ora.
SAP-RPT-1-OSS comporta costi significativamente più alti a causa del tempo richiesto per il pre-processing dell'embedding testuale e dell'elevato overhead di memoria dell'architettura LLM. Al contrario, LightGBM e CatBoost completano i compiti quasi istantaneamente su questo hardware. I costi sottostanti riflettono il tempo totale di esecuzione (pre-processing + addestramento) per un'esecuzione di validazione incrociata a 3 pieghe.
Costo medio per dataset (Media di 17 Dataset)
Suddivisione dei costi per dimensione del dataset
- Dataset piccoli (<1K righe): SAP è relativamente economico (circa 0,03 $ per esecuzione). L'alto tasso di vittoria qui rende il costo trascurabile.
- Dataset grandi (>20K righe): SAP diventa costoso.
- Esempio: L'addestramento su adult_income (48k righe) richiede circa 12 minuti totali per 3 pieghe.
- Costo: 12 min X 0,06 $/min = 0,72 $ per esperimento.
- Confronto: LightGBM completa lo stesso compito per 0,01 $.
Conclusione: Sebbene 0,22 $ per dataset non sia costoso in termini assoluti, SAP è 22 volte più costoso della baseline. Questa differenza di costo può essere giustificata per piccoli dataset ricchi di semantica dove SAP mostra miglioramenti significativi nell'accuratezza (ad es., cylinder_bands con un aumento del +5,5%), ma diventa più difficile da giustificare per grandi dataset dove i modelli ad albero raggiungono prestazioni uguali o migliori a una frazione del costo.
3. Framework di analisi: Lo spettro semantico
Per interpretare questi risultati, è fondamentale comprendere come abbiamo selezionato i dati. Non abbiamo scelto i dataset a caso; abbiamo curato una suite di 17 dataset scelti specificamente per coprire lo Spettro Semantico-Numerico.
La nostra ipotesi di base era che SAP (essendo basato su LLM) eccellesse dove i dati avevano significato linguistico, mentre i modelli ad albero dominassero nel calcolo numerico puro. Abbiamo classificato i nostri dataset in tre cluster distinti:
Cluster A: Dataset ad alta semantica (6 dataset)
Caratteristiche: Le caratteristiche contengono descrizioni testuali ricche, etichette categoriche con significato reale (ad es., "congelamento delle tariffe dei medici") o terminologia specifica del dominio.
- Dataset:
- cylinder_bands: Difetti di stampa industriali.
- titanic: Nomi e titoli dei passeggeri.
- vote: Registri di voto congressuale (Categorico "Sì/No" su politiche).
- breast_cancer: Descrizioni mediche dei tumori.
- spambase: Frequenze di parole nelle email.
- wine: Origini chimiche.
Cluster B: Dati aziendali misti (6 dataset)
Caratteristiche: Il formato tabulare standard trovato nella maggior parte dei database aziendali, un mix di valori numerici (stipendio, età) e stringhe categoriche (titolo del lavoro, razza, dipartimento).
- Dataset:
- employee_salaries: Titoli di lavoro vs. stipendio.
- compas: Storia criminale e demografia (Attributi sensibili).
- adult_income: Demografia del censimento.
- credit_g: Profili di rischio creditizio tedesco.
- default_credit: Dati di default creditizio taiwanese.
- car_evaluation: Parametri di acquisto veicoli.
Cluster C: Dati a bassa semantica/puri numerici (5 dataset)
Caratteristiche: Le caratteristiche sono misurazioni astratte, letture dei sensori o coordinate fisiche. I nomi delle colonne spesso non contano; contano solo le relazioni matematiche.
- Dataset:
- higgs_100k: Cinematica delle particelle fisiche.
- diamonds: Dimensioni fisiche e prezzo.
- sonar: Rimbalzi di energia a frequenza.
- california_housing: Coordinate Lat/Long e statistiche del censimento.
- house_sales: Immobili della contea di King (per lo più caratteristiche numeriche).
4. Approfondimento: Dove SAP vince vs. fallisce
Applicare il framework di analisi ai nostri risultati rivela quattro modelli di prestazioni distinti. La tabella sottostante riassume esattamente dove SAP eccelle e dove fallisce.
Fondamenti concettuali dei modelli fondamentali relazionali
Lo scopo principale di un modello fondamentale relazionale è fare previsioni accurate ed eseguire compiti diversificati su tabelle strutturate. Questi modelli devono comprendere come le informazioni sono rappresentate attraverso diverse tabelle, come le entità sono collegate attraverso relazioni e come le informazioni temporali influenzano i risultati.
Le capacità chiave di tali modelli includono:
- Generalizzazione dello schema: La capacità di adattarsi a nuovi schemi relazionali senza ri-addestramento da zero.
- Rappresentazione unificata dell'input: Gestione di diversi tipi di colonne come caratteristiche numeriche, categoriche e testuali.
- Integrazione del contesto temporale e strutturale: Cattura delle dipendenze nel tempo e tra entità collegate da chiavi primarie ed esterne.
- Trasferibilità: Esecuzione di compiti predittivi su nuovi dataset attraverso pre-addestramento e apprendimento zero-shot.
Griffin
Griffin è uno dei primi tentativi su larga scala di costruire un modello fondamentale relazionale unificato. Rappresenta i dati relazionali come un grafo temporale ed eterogeneo, dove ogni riga diventa un nodo e gli archi corrispondono a relazioni di chiave esterna. Le caratteristiche chiave includono:
Codificatore di funzionalità unificato
- Le caratteristiche categoriche e testuali sono codificate con un codificatore testuale pre-addestrato, mentre i valori numerici utilizzano un codificatore float appreso.
- I metadati come nomi di tabelle, nomi di colonne e tipi di archi sono incorporati per aiutare il modello a riconoscere lo schema relazionale.
- Gli embedding dei compiti consentono a un singolo modello di eseguire compiti di regressione e classificazione con decoder condivisi.
Passaggio di messaggi e attenzione
Griffin integra le reti neurali di passaggio dei messaggi con un modulo di attenzione incrociata. Il componente di passaggio dei messaggi aggrega informazioni all'interno e tra le relazioni, mentre l'attenzione incrociata si concentra sulle celle rilevanti all'interno di ogni riga. Questo design aiuta il modello a gestire dati diversificati e a mantenere il contesto tra entità collegate.
Pre-addestramento e fine-tuning
Il modello è pre-addestrato su dataset a tabella singola tramite un compito di completamento di celle mascherate e successivamente fine-tuned su database relazionali per compiti specifici. Gli esperimenti su grandi benchmark relazionali mostrano che Griffin supera i tradizionali baseline GNN e i modelli a tabella singola sia in accuratezza che in efficienza di apprendimento trasferito.
Figura 1: Grafico che mostra il framework del modello Griffin.1
Relational transformer
Mentre Griffin si concentra sull'aggregazione dei grafi, il Relational Transformer (RT) applica le architetture transformer direttamente ai database relazionali. Tratta ogni cella come un token arricchito con il suo valore, il nome della colonna e il nome della tabella.
Rappresentazione dell'input
Ogni token combina:
- Un embedding del valore che dipende dal suo tipo di dato (numerico, testo o data/ora).
- Un embedding dello schema generato dal testo della tabella e della colonna.
- Un token mask viene utilizzato quando il valore è nascosto durante il pre-addestramento.
Questa struttura consente a RT di elaborare database relazionali con schemi diversi mantenendo un formato di input coerente.
Attenzione relazionale
RT introduce un meccanismo di attenzione relazionale che opera a livello di cella. Include:
- Attenzione alla colonna per imparare le distribuzioni dei valori all'interno delle colonne.
- Attenzione alle funzionalità per combinare attributi all'interno della stessa riga o righe genitore collegate.
- Attenzione al vicino per aggregare informazioni dalle righe figlie collegate.
Insieme, questi livelli di attenzione formano un transformer di grafo relazionale che modella le dipendenze tra righe, colonne e tabelle.
Risultati di addestramento e trasferimento
RT è pre-addestrato su database relazionali da RelBench. Negli esperimenti, il modello pre-addestrato ha raggiunto fino al 94% delle prestazioni dei modelli completamente supervisionati in contesti zero-shot. Ha anche imparato più velocemente durante il fine-tuning, richiedendo meno passaggi di addestramento per raggiungere un'alta accuratezza.2
Questo approccio suggerisce che i database relazionali condividono modelli trasferibili tra domini e che la tokenizzazione a livello di cella fornisce una base pratica per i compiti predittivi su dati strutturati.
RelBench
RelBench è progettato per avanzare nell'apprendimento profondo relazionale, che si concentra sull'apprendimento end-to-end dai dati distribuiti su più tabelle correlate nei database relazionali.
Dato che i database relazionali rimangono il sistema di gestione dei dati dominante nell'industria e nella scienza, RelBench fornisce un framework standardizzato e riproducibile per valutare i modelli che operano direttamente sulle strutture relazionali invece di affidarsi all'appiattimento manuale delle funzionalità.
Le versioni precedenti di RelBench hanno introdotto 11 database relazionali che coprono domini come sanità, reti sociali, e-commerce e sport, con 70 compiti predittivi progettati per essere sia impegnativi che rilevanti per il dominio.3
Nel gennaio 2026, è stata rilasciata RelBench v2, aggiungendo quattro nuovi database (SALT, RateBeer, arXiv e MIMIC-IV) e 40 compiti predittivi aggiuntivi, inclusa una nuova classe di compiti di completamento automatico che valutano la capacità di un modello di prevedere colonne esistenti all'interno di un database relazionale.
Il rilascio ha anche ampliato l'accesso ai dati attraverso l'integrazione CTU, consentendo l'accesso a oltre 70 dataset relazionali tramite ReDeLEx; ha aggiunto la connettività diretta al database SQL; e ha incorporato sette dataset dal repository 4DBInfer nel formato RelBench.
Oltre ai dataset e ai compiti, RelBench fornisce un'implementazione di riferimento open source per l'apprendimento profondo relazionale basato su reti neurali a grafo, utilizzando PyTorch Geometric per la costruzione del grafo e PyTorch Frame per il modeling tabulare, insieme a una classifica pubblica per tracciare i progressi.
Il rilascio v2 ha anche introdotto molteplici miglioramenti di usabilità e prestazioni, inclusi etichette opzionali censurate dal tempo, supporto per la metrica NDCG nella previsione dei collegamenti, generazione più rapida di embedding di frasi e gestione della cache configurabile.4
VIEIRA
VIEIRA adotta un approccio diverso concentrandosi sulla programmazione con modelli fondamentali piuttosto che sulla costruzione di un singolo motore predittivo. Estende il compilatore di logica probabilistica SCALLOP con un linguaggio dichiarativo che integra grandi modelli linguistici, modelli di visione e altri componenti pre-addestrati come predicati esterni.5
Paradigma relazionale
In VIEIRA, i modelli fondamentali sono trattati come funzioni stateless con input e output relazionali. Ciò consente di comporre modelli come GPT, CLIP o SAM secondo regole logiche. Ad esempio:
- Un programma può usare GPT per estrarre conoscenze dal testo e memorizzarle come relazioni strutturate.
- CLIP può classificare le immagini e collegarle a etichette testuali in una tabella.
Applicazioni
Il framework supporta:
- Ragionamento su date e matematica usando GPT.
- Ragionamento sulle parentele usando l'estrazione di testo e l'inferenza logica.
- Risposta alle domande che combina recupero e ragionamento.
- Risposta visiva alle domande e modifica delle immagini attraverso composizione multimodale.
Unificando la logica simbolica e l'inferenza neurale, VIEIRA consente agli analisti di dati e agli sviluppatori di costruire sistemi interpretabili che utilizzano modelli fondamentali pre-addestrati per rispondere a query predittive su dati strutturati e immagini.
Casi di studio
SAP Hana Cloud
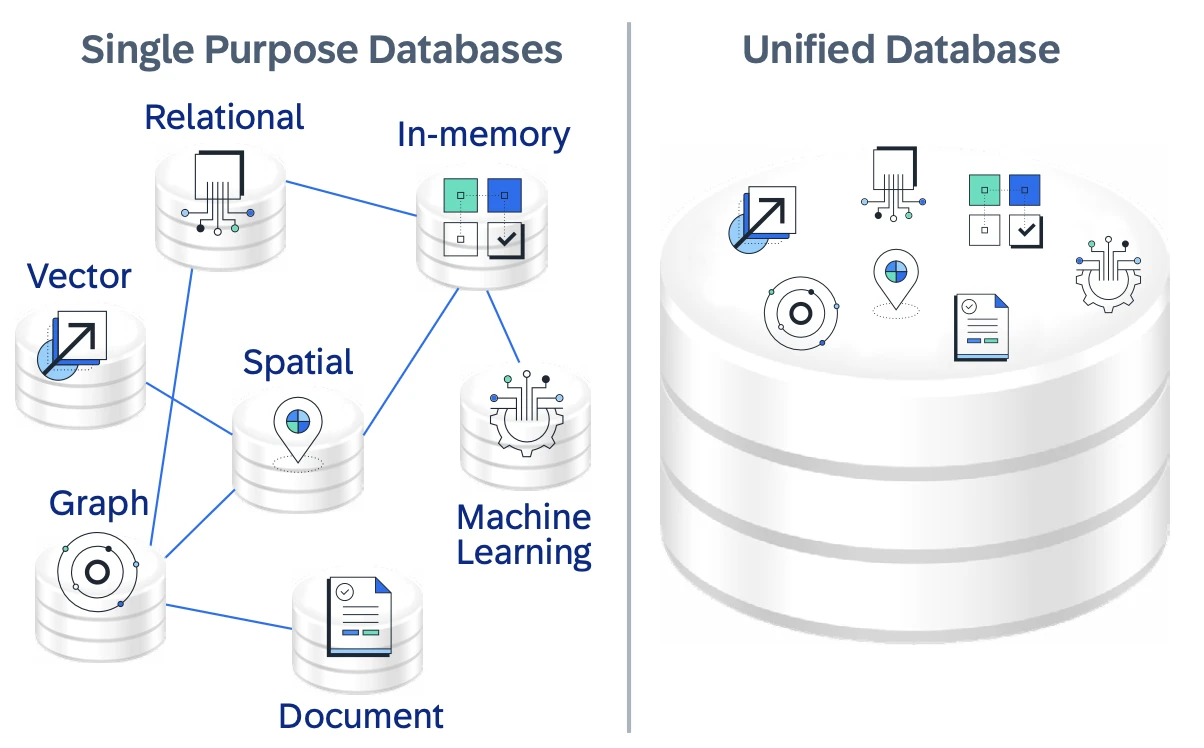
SAP HANA Cloud è un database-as-a-service nativo del cloud e completamente gestito progettato per agire come una base dati unificata per le applicazioni aziendali che combinano transazioni, analisi e IA. Piuttosto che servire come database relazionale a scopo singolo, SAP HANA Cloud è posizionato come una piattaforma multi-modello che consente alle organizzazioni di costruire "applicazioni dati intelligenti" sopra i dati aziendali operativi.
SAP HANA Cloud combina l'elaborazione in memoria con l'archiviazione su disco e l'integrazione del data lake per supportare diversi requisiti di prestazioni e costi. Questo design flessibile supporta carichi di lavoro in tempo reale mentre scala dinamicamente man mano che i volumi di dati e l'utilizzo fluttuano.
Un differenziatore chiave è il suo motore nativo multi-modello, che supporta dati relazionali, JSON/documenti, grafi, spaziali e vettoriali all'interno di un singolo database. Ciò consente alle applicazioni di combinare query SQL, relazioni di grafo e ricerca di similarità vettoriale senza spostare i dati tra sistemi separati, semplificando così l'architettura e riducendo la latenza.
Come parte della SAP Business Technology Platform, SAP HANA Cloud si integra direttamente con fonti di dati SAP e non SAP, inclusa l'accesso live senza replica, e fornisce sicurezza, disponibilità e conformità di livello aziendale per impostazione predefinita.
Complessivamente, SAP HANA Cloud è una piattaforma dati nativa IA e centrata sui relazionali, in cui il database relazionale funge da livello fondamentale per analisi, dati multi-modello e applicazioni aziendali IA.
Figura 2: Immagine che mostra il database unificato di Hana e
l'elaborazione dei dati multi-modello.6
sap-rpt-1 di SAP
sap-rpt-1 introduce un singolo modello fondamentale relazionale che esegue una vasta gamma di compiti predittivi attraverso l'apprendimento in contesto. Invece di ri-addestrare un nuovo modello per ogni caso d'uso, gli utenti forniscono alcuni esempi del loro modello target, come "clienti che hanno pagato in tempo" e "clienti che hanno pagato in ritardo". Il modello riconosce quindi il modello e produce immediatamente previsioni accurate per i nuovi dati.
Il modello è progettato con un meccanismo di attenzione bidimensionale che cattura le relazioni tra righe e colonne, incorporando anche metadati, come nomi di tabelle e colonne, in embedding vettoriali. Questo design gli permette di comprendere la semantica degli schemi relazionali e le informazioni temporali all'interno delle tabelle aziendali.
L'approccio di SAP porta diversi vantaggi per gli analisti di dati e gli utenti aziendali:
- Un singolo modello che funziona su più tabelle e domini.
- Nessuna necessità di ripetuti fine-tuning o sviluppo personalizzato.
- Accesso a informazioni predittive in minuti invece che in settimane.
- Integrazione con data warehouse esistenti e sistemi SAP.
Incorporando sap-rpt-1 all'interno dell'ecosistema SAP, gli esperti aziendali possono interagire direttamente con i propri dati e ricevere previsioni attraverso interfacce intuitive. Il risultato è un percorso più veloce dai dati strutturati alle decisioni attuabili senza ingegneria manuale delle funzionalità.
Figura 3: Fattore di riduzione dell'errore di sap-rpt-1-large rispetto alle baseline narrow-IA attraverso i domini SAP.
A partire dalla fine del 2025, SAP ha confermato che SAP-RPT-1 è generalmente disponibile attraverso l'hub IA generativa in SAP IA Foundation (SAP IA Core).
Il modello è offerto in due varianti di produzione:
- SAP-RPT-1-small, ottimizzato per previsioni a bassa latenza e alto throughput,
- SAP-RPT-1-large, progettato per dare priorità all'accuratezza predittiva.
Questo rilascio formalizza il ruolo di SAP-RPT-1 come modello fondamentale distribuibile all'interno dello stack IA aziendale di SAP, piuttosto che una capacità solo di ricerca.
Inoltre, SAP offre il SAP-RPT Playground, un ambiente no-code basato sul web dove gli utenti possono testare l'apprendimento in contesto utilizzando i propri dati o dati di esempio forniti da SAP.
SAP-ABAP-1
SAP-ABAP-1 è un modello fondamentale progettato per supportare casi d'uso di produttività degli sviluppatori basati su IA per i clienti e i partner SAP.
È disponibile attraverso l'hub IA generativa di SAP ed è addestrato su oltre 250 milioni di righe di codice ABAP, 30 milioni di righe di codice CDS e documentazione tecnica estesa. Il modello è ottimizzato per comprendere e spiegare il codice ABAP, evidenziare le migliori pratiche e fornire accesso alla conoscenza di sviluppo SAP aggiornata.
SAP offre accesso di prova gratuito a SAP-ABAP-1 tramite l'hub IA generativa, con capacità aggiuntive pianificate per il rilascio nel 2026.7
KumoRFM di Kumo.IA: un transformer di grafo relazionale per l'analisi predittiva
Kumo.IA, fondata dal professore di Stanford Jure Leskovec, ha creato KumoRFM, un modello fondamentale relazionale che utilizza un transformer di grafo relazionale per analizzare database relazionali e data warehouse. Rappresenta i dati relazionali come un grafo temporale ed eterogeneo, dove ogni entità è un nodo e le chiavi primarie ed esterne formano archi tra le tabelle.
Questo approccio basato su grafi consente a KumoRFM di imparare da più tabelle simultaneamente e adattarsi a nuovi schemi relazionali. Il modello è pre-addestrato su diverse fonti di dati e può generalizzare a nuovi dataset senza costruire modelli separati per ogni compito predittivo.
KumoRFM può essere utilizzato attraverso diverse interfacce a seconda dell'esperienza dell'utente:
- PQL (Linguaggio di query predittive): Un linguaggio di query specializzato per definire query predittive su dati strutturati.
- Interfaccia in linguaggio naturale: Per gli utenti non tecnici, gli input in linguaggio naturale vengono automaticamente tradotti in query PQL.
- SDK Python: Consente agli sviluppatori di integrare il modello nelle pipeline e nelle applicazioni IA aziendali.
L'architettura KumoRFM campiona dinamicamente il database per creare sottografi di contesto e sottografi di previsione. Questi sottografi sono elaborati dal transformer di grafo relazionale, che cattura le dipendenze e le informazioni temporali tra entità correlate. Attraverso l'apprendimento in contesto, il modello fornisce previsioni accurate e può spiegare il suo processo di ragionamento.
Kumo offre due opzioni di distribuzione adatte agli ambienti aziendali:
- Piattaforma SaaS: Un servizio basato sul cloud costruito su Apache Spark per un facile accesso e scalabilità
- Nativo del data warehouse: Consente alle organizzazioni di utilizzare i propri dati in Snowflake o Databricks senza spostarli al di fuori del loro ambiente sicuro
A differenza dei tradizionali grafi della conoscenza che richiedono la definizione manuale dello schema, KumoRFM costruisce automaticamente il proprio grafo relazionale da fonti strutturate. Questo lo rende adatto per l'eCommerce, finanza e sanità, dove relazioni, modelli temporali e contesto in evoluzione sono essenziali per previsioni affidabili.
Le capacità chiave di KumoRFM includono:
- Flessibilità tra diverse tabelle e strutture di schema.
- Compatibilità con una varietà di tipi di colonne e identificatori personalizzati.
- Adattamento a compiti specifici durante il tempo di inferenza.
- Alta accuratezza e interpretabilità nei compiti predittivi.
Figura 4: L'immagine mostra come i Modelli Fondamentali Relazionali (RFM) funzionano attraverso più domini, come eCommerce, finanza e sanità, per fare previsioni, fornire spiegazioni e valutare i risultati.8
Metodologia del benchmark
Configurazione e ambiente del benchmark
Per garantire confronti equi tra alberi limitati dalla CPU e modelli accelerati dalla GPU, abbiamo utilizzato un ambiente ad alte prestazioni in grado di gestire entrambi in modo efficiente.
- Hardware: Istanza RunPod con NVIDIA H200 140GB GPU.
- Software: Python 3.12 con librerie bloccate per la riproducibilità:
- scikit-learn 1.5.2, lightgbm 4.5.0, catboost 1.2.7
- torch 2.5.1, pandas 2.2.3, numpy 2.1.3
- sap-rpt-oss (Fonte: GitHub Ufficiale)
- Riproducibilità: random_state=42 è stato utilizzato coerentemente in tutte le divisioni, inizializzazioni e modelli.
Dataset: Lo spettro semantico
Abbiamo valutato i modelli su 17 dataset di apprendimento supervisionato provenienti da OpenML e Scikit-Learn. Invece di una selezione casuale, abbiamo curato questa suite per coprire lo "Spettro Semantico-Numerico" testando l'ipotesi che gli LLM eccellano dove le caratteristiche contengono significato linguistico piuttosto che semplici statistiche grezze.
L'inventario:
- Piccoli e semantici (<1K righe):
- wine (178), sonar (208), vote (435), cylinder_bands (540), breast_cancer (569).
- Medi/misti (1K – 10K righe):
- credit_g (1K), titanic (1,3K), car_evaluation (1,7K), spambase (4,6K), compas (5,2K), employee_salaries (9,2K).
- Grandi/numerici (10K+ righe):
- california_housing (20K), house_sales (21K), default_credit (30K), adult_income (48K), diamonds (53K), higgs (campionato a 100K).
Compiti coperti:
- 11 compiti di classificazione binaria
- 2 compiti di classificazione multiclasse
- 4 compiti di regressione
Configurazioni del modello e pre-processing
Abbiamo mirato a un realistico "confronto del professionista", utilizzando impostazioni predefinite forti invece di un'ottimizzazione esaustiva degli iperparametri.
LightGBM & CatBoost
Per garantire un confronto equo contro il modello SAP computazionalmente pesante, abbiamo aumentato gli stimatori robusti predefiniti.
- LightGBM: n_estimators=500, learning_rate=0.05, num_leaves=31. Esegue su CPU (n_jobs=-1).
- CatBoost: iterations=500, learning_rate=0.05, depth=6. Esegue su GPU (task_type="GPU").
- Pre-processing: Semplice Label Encoding per le categoriche; nessuna scalatura per i numerici; imputazione mediana/mode per i valori mancanti.
SAP-RPT-1-OSS
Abbiamo configurato SAP per bilanciare prestazioni e costi in base ai nostri esperimenti di configurazione preliminari.
- Configurazione: max_context_size=4096, bagging=4.
- Nota:
- Contesto: Il test su adult_income ha mostrato che aumentare il contesto da 4096 a 8192 ha triplicato il tempo di esecuzione (da 4 a 12 minuti) per un guadagno di accuratezza trascurabile (0,917 vs 0,917 ROC-AUC).
- Bagging: Aumentare il bagging da 4 a 8 (impostazione predefinita di SAP utilizzata nell'articolo9 ) ha offerto rendimenti decrescenti.
- Pre-processing: Nessuno. Il DataFrame pandas grezzo viene passato direttamente. Il modello codifica utilizzando embedding testuali (sentence-transformers/all-MiniLM-L6-v2).
Protocollo di valutazione
Strategia di validazione incrociata
Abbiamo utilizzato la Validazione Incrociata a 3 Pieghe con mescolamento.
- Abbiamo ridotto la standard 5-fold a 3-fold per adattarci ai tempi di inferenza lenti di SAP (risparmio del 40% di tempo) mantenendo la validità statistica.
- Divisione: StratifiedKFold per la classificazione; Standard K-Fold per la regressione.
Metriche e diagnostica
Siamo andati oltre la semplice accuratezza per catturare una visione olistica delle prestazioni del modello:
- Metriche di ranking primarie: ROC-AUC (Binario), Balanced Accuracy (Multiclasse), R² (Regressione).
- Diagnostica secondaria: Abbiamo tracciato il coefficiente di correlazione di Matthews (MCC) e la log loss per garantire che le vittorie non fossero artefatti dello squilibrio delle classi, e il MAPE per la calibrazione dell'errore di regressione.
- Calcolo dei costi: Basato sul tempo totale di esecuzione (pre-processing + addestramento + inferenza) sull'istanza RunPod H200 (3,59 $/ora).
Significatività statistica
Abbiamo applicato un test dei ranghi con segno di Wilcoxon (p<0,05) ai confronti a coppie dei modelli per determinare se le differenze di prestazioni fossero statisticamente significative o rumore casuale.
Limitazioni e validità interna
Acknowledgiamo esplicitamente i seguenti vincoli nella nostra metodologia:
- Configurazioni standardizzate vs tuning: Abbiamo utilizzato configurazioni predefinite fisse e forti per tutti i modelli invece di eseguire un'ottimizzazione esaustiva degli iperparametri (ad es., CV nidificato o scansioni Optuna). Sebbene ciò garantisca una baseline coerente, vale la pena notare che i modelli ad albero spesso vedono guadagni di prestazioni con un tuning specifico del dataset, che potrebbe restringere i margini nel cluster "Competitivo".
- Confini di scala dei dati: La nostra analisi si è concentrata su dataset sotto le 100k righe per simulare scenari aziendali di medie dimensioni tipici. Abbiamo osservato il vantaggio dell'LLM diminuire man mano che il volume dei dati cresceva, ma non abbiamo esteso i test a scale di milioni di righe dove la latenza di inferenza e i costi sarebbero probabilmente diventati i vincoli principali.
- Uniformità dell'infrastruttura: Per mantenere un ambiente di test coerente, abbiamo eseguito tutti i modelli sullo stesso hardware NVIDIA H200. LightGBM e CatBoost sono altamente ottimizzati per CPU commodity; quindi, in un ambiente di produzione dedicato esclusivamente ai modelli ad albero, la differenza di costi sarebbe probabilmente più ampia.
- Generalizzazione oltre la semantica: La nostra ipotesi "Spettro Semantico" ha previsto con successo molti esiti, ma le forti prestazioni dell'LLM su dataset astratti come sonar e california_housing suggeriscono capacità oltre la comprensione linguistica. Ciò indica che il modello potrebbe anche sfruttare modelli di regolarizzazione ad alta dimensionalità, un fenomeno che merita ulteriori indagini oltre la portata di questo studio iniziale.
Cita questa ricerca
Scegli il formato adatto a dove pubblicherai. Incollare la versione con link nel tuo CMS preserva il backlink.
@misc{ermut2026,
author = {Ermut, Sıla and Sarı, Ekrem},
title = {{Confronta i Modelli Fondamentali Relazionali}},
year = {2026},
month = jul,
howpublished = {\url{https://aimultiple.com/relational-foundation-model}},
note = {AIMultiple. Consultato il 2 Luglio 2026}
}


 attraverso più domini.")
Sii il primo a commentare
Il tuo indirizzo email non verrà pubblicato. Tutti i campi sono obbligatori. I commenti vengono lasciati nella loro lingua originale.