Benchmark Reranker: 8 Modelli Principali Confrontati
Abbiamo eseguito benchmark su 8 modelli reranker su circa 145k recensioni Amazon in inglese per misurare quanto una fase di riclassificazione migliori il recupero denso. Abbiamo recuperato i primi 100 candidati con multilingual-e5-base, li abbiamo riclassificati con ciascun modello e abbiamo valutato i primi 10 risultati rispetto a 300 query, ciascuna che fa riferimento a dettagli concreti della sua recensione sorgente. Il miglior reranker ha portato Hit@1 dal 62,67% all'83,00% (+20,33pp).
Risultati del benchmark reranker
Spiegazione delle metriche:
ΔHit@1 / ΔHit@10 mostra il miglioramento rispetto alla baseline (nessun reranker) in punti percentuali (pp). Ad esempio, +20,33pp significa che il reranker ha migliorato Hit@1 di 20,33 punti percentuali rispetto al 62,67% della baseline.
Hit@K misura se qualsiasi recensione con il product_id corretto appare nei primi K risultati. La verità fondamentale è il product_id della recensione che ha generato la query. Se una recensione diversa dello stesso prodotto finisce nei primi K, questo conta come un hit. Hit@1 è il test più rigoroso: il risultato principale proviene dal prodotto giusto? Hit@10 è più permissivo: il prodotto giusto è da qualche parte nei primi 10 risultati?
MRR@10 (Mean Reciprocal Rank) media 1/rank del primo risultato corretto su tutte le query. Se il primo product_id corrispondente è al rank 1, il punteggio è 1,0. Al rank 2, è 0,5. Al rank 10, è 0,1. Questo premia i modelli che posizionano il prodotto corretto il più in alto possibile.
nDCG@10 (Normalized Discounted Cumulative Gain) valuta le posizioni di tutte le recensioni corrispondenti nei primi 10, non solo la prima. Se lo stesso prodotto ha più recensioni nel set di candidati e diverse finiscono nei primi 10, nDCG accredita ciascuna in base alla sua posizione. In pratica, la maggior parte dei prodotti ha solo 1-2 recensioni nei primi 100 candidati, quindi nDCG e MRR seguono da vicino.
Recall@10 misura la frazione di recensioni corrispondenti (stesso product_id) nei primi 10 su tutte le recensioni corrispondenti nell'intero set di candidati (primi 100). Se un prodotto ha 3 recensioni nei primi 100 e il reranker ne mette 2 nei primi 10, Recall@10 è 2/3 per quella query. Poiché la maggior parte dei prodotti ha poche recensioni duplicate nel set di candidati, Recall@10 e Hit@10 sono quasi identici in questo benchmark.
Analisi della latenza
La latenza di riclassificazione misura il tempo necessario a ciascun cross-encoder per valutare 100 documenti candidati rispetto alla query. Il tempo di ricerca vettoriale (~20ms) è escluso poiché rimane costante in tutte le esecuzioni ed è indipendente dal reranker.
Spiegazione delle metriche di latenza:
Rerank è il tempo necessario al cross-encoder per valutare tutti i 100 documenti candidati rispetto alla query. È qui che i modelli differiscono: un singolo passaggio in avanti è veloce, mentre il decoding autoregressivo è lento.
P95 è la latenza totale al 95° percentile. Alcune query hanno testi di recensione più lunghi, il che aumenta il tempo di tokenizzazione e valutazione. P95 mostra il caso peggiore che ci si dovrebbe aspettare per il 95% delle query.
Risultati chiave
Un modello da 149M eguaglia un modello da 1,2B
gte-reranker-modernbert-base ha 149M parametri, nemotron-rerank-1b ha 1,2B. Entrambi raggiungono l'83,00% Hit@1 in inglese. L'architettura ModernBERT è 8 volte più piccola e offre una precisione principale identica.
Questo non significa che la dimensione del modello sia irrilevante. nemotron è leggermente superiore su MRR@10 (0,8514 contro 0,8483) e Hit@10 (88,33% contro 88,00%), il che significa che classifica documenti pertinenti leggermente meglio in tutti i primi 10. Ma per la maggior parte delle applicazioni in cui ottenere il primo risultato corretto è ciò che conta, il modello da 149M è sufficiente.
Il modello più grande non è il migliore
qwen3_reranker_4b ha 4B parametri e impiega oltre un secondo per query. Raggiunge il 77,67% Hit@1, posizionandosi quarto dietro nemotron (1,2B), gte_modernbert (149M) e jina (560M). Paghi 4,5 volte la latenza di nemotron per 5,3 punti percentuali in meno di precisione.
L'architettura di qwen3 utilizza il modellamento linguistico causale con un approccio logit sì/no. Il modello legge la coppia query-documento e restituisce la probabilità di "sì, questo è pertinente". Questo è concettualmente pulito, ma l'inference è costosa a causa dell'overhead del decoding autoregressivo. I modelli SequenceClassification (gte_modernbert, bge) e l'approccio con template di prompt di nemotron elaborano la coppia in un singolo passaggio in avanti, il che è fondamentalmente più veloce.
Jina offre il miglior compromesso velocità-precisione
jina_reranker_v3 raggiunge l'81,33% Hit@1 a 188ms. nemotron raggiunge l'83,00% a 243ms. Se hai bisogno di una latenza totale inferiore a 200ms per query, Jina è l'unico modello nel livello superiore che offre. Il divario di 1,67 punti percentuali potrebbe non giustificare gli ulteriori 55ms in un sistema di produzione che serve migliaia di richieste al secondo.
Un reranker peggiora i risultati
mxbai_rerank_xsmall (70M parametri) ottiene il 64,67% Hit@1. La baseline senza alcun reranker ottiene il 62,67%. Il miglioramento è di soli 2 punti percentuali, che è entro il rumore per 300 query. Con 70M parametri, il modello manca della capacità di giudicare in modo affidabile la rilevanza query-documento su testi più lunghi o più sfumati.
Un reranker non è automaticamente benefico. Testalo sui tuoi dati reali prima di distribuirlo.
Il retriever fissa il limite massimo
Tutti i migliori reranker convergono intorno all'87-88% Hit@10. Questo limite deriva dal retriever. Se multilingual-e5-base non posiziona il documento corretto nei primi 100 candidati, nessun reranker può recuperarlo. Il restante 12% di query in cui ogni reranker fallisce rappresenta casi in cui il retriever denso ha semplicemente perso il documento pertinente.
Migliorare oltre questo limite richiede un retriever migliore, un pool di candidati più grande o entrambi. Abbiamo testato i primi 250 candidati e non abbiamo trovato quasi alcun miglioramento rispetto ai primi 100, il che significa che e5_base esaurisce i suoi candidati utili ben prima del rank 250.
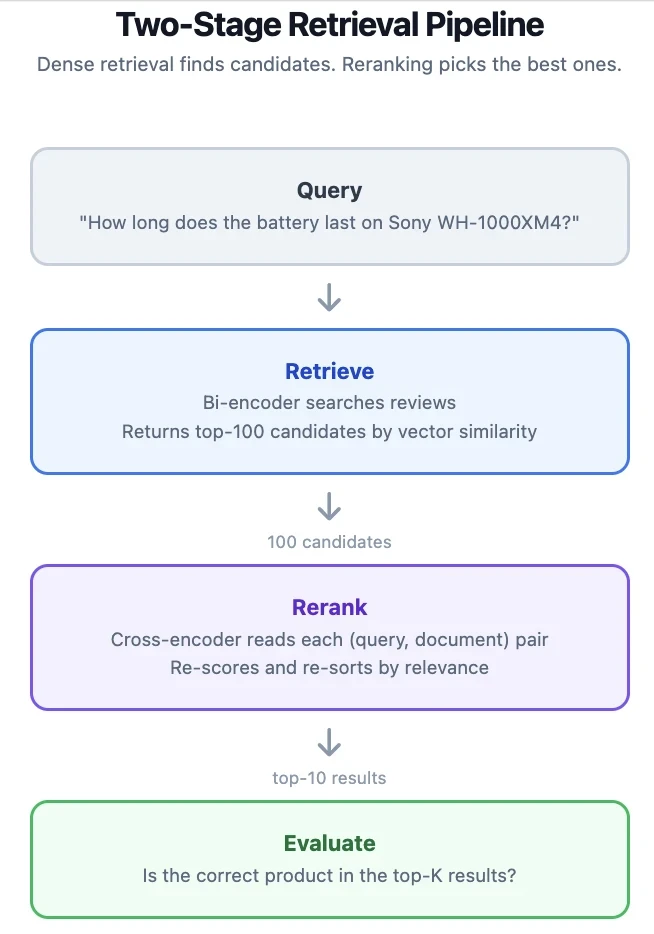
Come funzionano i reranker
Un retriever denso (bi-encoder) codifica query e documenti indipendentemente in vettori. Il recupero è una ricerca dei vicini più prossimi su questi vettori. Questo è veloce perché codifichi solo la query al momento della ricerca, ma il modello non vede mai insieme query e documento, quindi può perdere segnali di rilevanza sfumati.
Un reranker (cross-encoder) prende una coppia query-documento come input singolo. Il modello presta attenzione a entrambi i testi congiuntamente, cogliendo relazioni che la codifica indipendente perde. Il costo è che devi eseguire il modello una volta per candidato, quindi puoi permetterti di valutare solo un piccolo pool.
Architetture in questo benchmark
Abbiamo testato quattro diverse architetture cross-encoder:
I modelli SequenceClassification (bge_base, bge_v2_m3, mxbai_xsmall, gte_modernbert) prendono una [query, document] coppia come input e restituiscono un singolo punteggio logit. Questo è l'approccio più semplice e comune.
Nemotron utilizza un formato di template di prompt: "question:{q} passage:{p}". L'input sembra testo semplice piuttosto che una coppia strutturata, ma il modello restituisce comunque un singolo punteggio di rilevanza tramite SequenceClassification. Il pretraining LLM (basato su Llama) gli conferisce una forte comprensione del linguaggio.
I reranker Qwen3 utilizzano il modellamento linguistico causale. Il modello legge la coppia e genera un giudizio sì/no. Il punteggio è log P(sì) / (P(sì) + P(no)). Questo richiede l'intera macchina autoregressiva, il che spiega la latenza più elevata.
Jina v3 utilizza un API personalizzato (model.rerank()) che gestisce la tokenizzazione e la valutazione internamente. L'architettura sottostante utilizza l'attenzione incrociata, ma l'interfaccia astrae i dettagli.
Metodologia del benchmark reranker
- GPU: NVIDIA H100 PCIe 80GB tramite Runpod
- Database vettoriale: Qdrant 1.12.0 (binario locale), distanza coseno
- Retriever: multilingual-e5-base (768-dim). Prefisso query:
"query: ", prefisso documento:"passage: " - Software: transformers 5.2.0, PyTorch 2.8.0, CUDA 12.8.1
- Dataset: Sottogruppo in inglese di Amazon Reviews Multi (Kaggle).1 ~145k recensioni dopo il filtraggio per minimo 100 caratteri. Ogni recensione ha un product_id, testo della recensione e valutazione a stelle.
- Generazione query: Claude Sonnet 4.6 tramite OpenRouter. 300 query in inglese (5 tipi: fattuale, opinione, utilizzo, risoluzione problemi, confronto funzionalità). Ogni query deve fare riferimento a dettagli specifici della sua recensione sorgente; le domande generiche (punteggio di specificità < 4/5) vengono filtrate.
- Formato documento:
"Review Title: {title}\nReview: {body}" - Pipeline: Recupera i primi 100 candidati con multilingual-e5-base, riclassifica con cross-encoder, restituisci i primi 10. La baseline salta la riclassificazione e restituisce direttamente i primi 10 del retriever.
- Verità fondamentale: solo corrispondenza esatta del product_id. Nessun fallback di similarità coseno. Nessun credito parziale per prodotti semanticamente simili.
- Variabile controllata: Solo il modello reranker cambia tra gli esperimenti. Retriever, numero di candidati, set di query e criteri di valutazione sono identici in tutte le esecuzioni.
- Nessun fine-tuning: Tutti i modelli valutati zero-shot con i pesi predefiniti di HuggingFace.
- Latenza: Riclassificazione (valutazione cross-encoder di 100 candidati). Misurata per query su GPU.
Modelli testati
Limitazioni
Questo benchmark utilizza un singolo retriever (multilingual-e5-base). Un retriever diverso produrrebbe set di candidati diversi e potrebbe cambiare i ranking dei reranker. I risultati riflettono quanto bene ogni reranker funzioni con questo specifico retriever, non la qualità del reranker in isolamento.
Abbiamo testato su recensioni di prodotti in inglese di Amazon. Le prestazioni su altri domini (articoli scientifici, documenti legali, codice) o altre lingue saranno diverse.
Il numero di candidati è fissato a 100. Alcuni reranker potrebbero classificare diversamente con 20 o 200 candidati. Abbiamo testato 250 candidati e non abbiamo trovato miglioramenti trascurabili, suggerendo che 100 è sufficiente per e5_base, ma altri retriever potrebbero comportarsi diversamente.
300 query è una dimensione del campione moderata. I primi tre modelli (nemotron, gte_modernbert, jina) sono separati da meno di 2 punti percentuali. Con un set di query più grande, questi ranking potrebbero cambiare. Il divario tra il livello superiore e quello inferiore (20+ punti percentuali) è robusto.
Conclusione
I reranker funzionano. Il miglior modello in questo benchmark porta Hit@1 dal 62,67% all'83,00% (+20,33pp), il che significa che 20 su ogni 100 query che in precedenza restituivano il documento sbagliato per prime ora restituiscono quello corretto. Questo è un guadagno significativo per un componente che aggiunge meno di 250ms di latenza.
Il risultato più utile è che la dimensione del modello non determina la qualità del reranker. gte-reranker-modernbert-base a 149M parametri eguaglia nemotron-rerank-1b a 1,2B su Hit@1. Il modello Qwen3 da 4B parametri finisce quarto. Se stai scegliendo un reranker per un sistema di produzione, inizia con i modelli più piccoli. Potresti non aver mai bisogno di quelli più grandi.
Per applicazioni sensibili alla latenza, jina-reranker-v3 è l'opzione più forte sotto i 200ms. Per la massima precisione senza vincoli di latenza, nemotron-rerank-1b e gte-reranker-modernbert-base condividono il primo posto. Per i team con un budget GPU, gte-modernbert è il chiaro vincitore: stessa precisione del modello da 1,2B a una frazione dell'occupazione di memoria.
Un modello è rimasto costante in tutti gli esperimenti: il retriever fissa il limite massimo. Nessun reranker ha spinto Hit@10 oltre l'88%, perché il restante 12% di documenti corretti non è mai apparso nei primi 100 candidati. Investire in un retriever migliore probabilmente produrrà guadagni maggiori rispetto al passaggio tra i primi tre reranker.
Ulteriori letture
Esplora altri benchmark RAG, come:
- Modelli di embedding: OpenAI vs Gemini vs Cohere
- I 16 migliori modelli di embedding open source per RAG
- Il miglior database vettoriale per RAG: Qdrant vs Weaviate vs Pinecone
- Benchmark Agentic RAG: instradamento multi-database e generazione query
- Modelli di embedding multimodali: Apple vs Meta vs OpenAI
- RAG ibrido: potenziamento della precisione RAG
- I 10 migliori modelli di embedding multilingue per RAG
Cita questo benchmark
Scegli il formato adatto a dove pubblicherai. Incollare la versione con link nel tuo CMS preserva il backlink.
@misc{sari2026,
author = {Sarı, Ekrem},
title = {{Benchmark Reranker: 8 Modelli Principali Confrontati}},
year = {2026},
month = feb,
howpublished = {\url{https://aimultiple.com/rerankers}},
note = {AIMultiple. Consultato il 26 Febbraio 2026}
}Risultati e timestamp di 9 punti dati. Scarica i dati utilizzati in questo articolo come file ZIP contenente un file CSV e un README.

Sii il primo a commentare
Il tuo indirizzo email non verrà pubblicato. Tutti i campi sono obbligatori. I commenti vengono lasciati nella loro lingua originale.