Fattura OCR Benchmark: precisione di estrazione di LLM vs OCR
L'elaborazione delle fatture è un'operazione aziendale critica ma laboriosa che richiede tradizionalmente l'estrazione manuale dei dati e l'inserimento nei sistemi contabili. Questo approccio manuale è dispendioso in termini di tempo e soggetto a errori umani. Per valutare le alternative automatizzate, abbiamo condotto un'analisi comparativa delle principali soluzioni di elaborazione documenti e degli LLM:
- Amazon Textract API
- Claude Sonnet 3.5
- Docsumo
- Google Document IA
- Microsoft Azure Document Intelligence
- Rossum
Il nostro studio ha valutato le capacità di questi strumenti nell'estrarre dati in modo preciso da formati e qualità di fatture diversi, con l'obiettivo di quantificare la loro efficacia come alternative all'elaborazione manuale.
Risultati del benchmark
Abbiamo valutato le prestazioni di elaborazione delle fatture su fatture di varia qualità e livelli di contrasto. Sebbene tutti gli strumenti abbiano dimostrato buone prestazioni con immagini di alta qualità, la loro precisione è diminuita significativamente durante l'elaborazione di documenti di qualità inferiore. Tra gli strumenti testati, Claude Sonnet 3.5 ha mostrato la massima precisione complessiva e resilienza attraverso l'intero spettro di qualità documentale.
Metodologia
Misurazione: La nostra metodologia di valutazione si è concentrata sulla precisione dell'estrazione delle coppie chiave-valore. Ogni campo estratto è stato valutato tramite una classificazione binaria: estrazione corretta o estrazione errata/mancante. La metrica di precisione è stata calcolata utilizzando la seguente formula:
Precisione = (Numero di coppie chiave-valore estratte correttamente) / (Numero totale di coppie chiave-valore)
Questa metodologia ha consentito un confronto oggettivo delle prestazioni di estrazione tra diversi strumenti e tipi di documenti.
Dimensione del campione: Trovare dati su fatture è difficile poiché coinvolgono informazioni personali come email e nomi. Abbiamo utilizzato più di 400 coppie chiave-valore da 20 fatture campione pubblicamente disponibili.
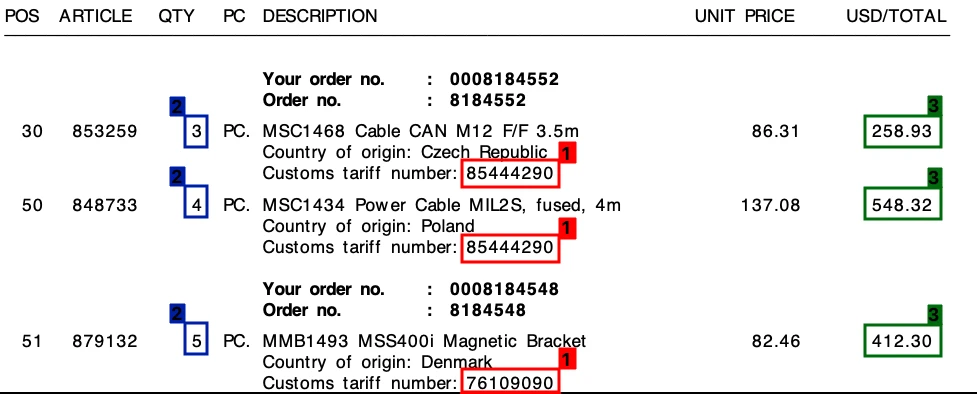
Campioni: Sebbene tutte le soluzioni abbiano elaborato correttamente immagini di alta qualità, la qualità dell'estrazione è diminuita in immagini come queste:
Fine-tuning: Sebbene i prodotti che abbiamo provato siano riusciti a trovare gli importi totali, hanno avuto problemi nell'estrarre i dettagli dei prezzi. È possibile ottenere risultati migliori effettuando il fine-tuning di alcuni prodotti. In alcuni prodotti, gli utenti possono fare clic su un valore nell'immagine per correggere l'output del modello.
Per essere equi verso tutti i fornitori, non abbiamo effettuato alcun fine-tuning. Con il fine-tuning, tutti i fornitori dovrebbero essere in grado di ottenere tassi di successo più elevati la seconda volta che elaborano questi documenti. Tuttavia, l'obiettivo di questo benchmark sono le operazioni autonome, che richiedono ai modelli di produrre risultati corretti e affidabili da documenti che non hanno mai visto prima.
Tempistica: Tutti i test sono stati completati a dicembre 2024.
Prossimi passi
Aumento dei partecipanti: Poiché questo studio fornisce approfondimenti sulle attuali capacità di elaborazione delle fatture attraverso i modelli linguistici di grandi dimensioni (LLM), le tecnologie OCR e gli strumenti specializzati di elaborazione delle fatture, prevediamo di ampliare la nostra analisi incorporando altri LLM all'avanguardia per fornire un benchmark più completo delle soluzioni automatizzate di elaborazione delle fatture.
Aumento della dimensione e della diversità del campione.
Che cos'è l'OCR per fatture?
L'analisi delle fatture utilizza strumenti automatizzati come NLP, NLU, OCR e altre tecnologie di estrazione dati per estrarre dati da fatture in vari formati, come PDF e immagini.
Un parser di fatture è un programma software che estrae informazioni quali
Nome del fornitore
Numero fattura
Importo dovuto
e le inserisce in un formato leggibile dalla macchina. Questi dati possono essere utilizzati per molteplici funzioni, come l'automazione della contabilità fornitori, la chiusura contabile di fine mese e la gestione delle fatture.
Il software parser è solitamente integrato in un sistema di elaborazione delle fatture che automatizza l'intero processo dalla ricezione di una fattura al pagamento.
Come funzionano gli strumenti OCR per fatture?
I documenti scritti in un determinato linguaggio di markup vengono letti e gestiti dai parser. Essi suddividono il documento in parti più piccole, chiamate token, ed esaminano ciascun token per determinarne il significato e la posizione all'interno della struttura del documento.
Per fare ciò, i parser devono conoscere bene la grammatica del linguaggio di markup in questione. Ciò consente loro di riconoscere ciascun token e determinare le esatte connessioni tra di essi.
Il processo comprende 5 fasi:
1. Input
Le fatture possono essere ricevute in vari formati, tra cui cartaceo, email o formati elettronici come PDF o XML. Il software parser di fatture in genere accetta queste fatture come input.
2. Riconoscimento ottico dei caratteri (OCR)
Se la fattura è in formato cartaceo scansionato o immagine, il parser utilizzerà la tecnologia OCR per estrarre il testo dall'immagine. Ciò consente al parser di accedere ai dati contenuti nella fattura.
Alcune soluzioni di analisi delle fatture utilizzano strumenti OCR basati sull'IA o LLM che estraggono automaticamente informazioni da PDF, foto e documenti scansionati senza la necessità di nuove regole o modelli. Questo perché l'IA può gestire documenti semi-strutturati e non familiari e migliorare nel tempo. Le informazioni estratte possono essere personalizzate per includere solo tabelle o voci di dati specifiche.
3. Estrazione dei dati
Il parser estrarrà quindi informazioni specifiche dalla fattura, come il nome del fornitore, il numero della fattura, la data e i dettagli degli articoli. Ciò si ottiene tipicamente utilizzando una combinazione di riconoscimento di pattern e algoritmi di apprendimento automatico.
Alcuni software di analisi delle fatture hanno la capacità di estrarre informazioni chiave come la data della fattura, il numero, i numeri di identificazione fiscale e vari totali utilizzando filtri predefiniti:
Alcuni strumenti parser offrono la possibilità di estrarre informazioni sulle righe di dettaglio da fatture con un formato coerente creando un parser di documenti separato per ogni specifico fornitore o layout del partner commerciale:
4. Validazione dei dati
Una volta estratti i dati, il parser convaliderà le informazioni per garantire che siano accurate e complete. Ciò può includere il controllo che la data sia nel formato corretto, che il nome del fornitore corrisponda a un elenco predefinito di fornitori o che i dettagli degli articoli corrispondano al formato previsto.
5. Output dei dati
I dati estratti e convalidati vengono quindi restituiti in un formato che può essere facilmente importato nel sistema contabile o ERP dell'utente. Ciò può avvenire sotto forma di file CSV, record di database o direttamente in un software di contabilità.
Sfide dell'estrazione manuale dei dati delle fatture
L'estrazione manuale dei dati dalle fatture e il loro inserimento in un sistema può essere impegnativa per le aziende, poiché presenta diverse complessità:
Errore umano
Le fatture possono contenere una grande quantità di dati e l'inserimento manuale aumenta il rischio di errori, come errori di battitura, trasposizione di numeri e immissione di dati errati. Le imprecisioni nell'immissione dei dati sono responsabili di una perdita annua stimata di 600 miliardi di dollari.1 Processi come la contabilità fornitori richiedono un'esportazione corretta dei dati dai documenti finanziari.
Dispendioso in termini di tempo
In media, occorrono 17 giorni, ovvero circa il 75% di un mese, per elaborare manualmente una singola fattura.2
Molte informazioni importanti sono incluse nelle fatture e sono tutte presentate in uno stile chiave-valore in cui ogni voce funge sia da chiave che da valore. Il processo di estrazione manuale di queste coppie richiede tempo e richiede molteplici controlli per garantire la precisione. Persino alcuni algoritmi OCR faticano a rilevare i valori estratti senza contesto. L'elaborazione automatizzata delle fatture può aiutare i dipendenti a concentrarsi su attività più complesse.
Mancanza di standardizzazione
Le fatture di fornitori diversi possono avere formati diversi. Ogni fattura viene generata con un formato unico che può creare difficoltà nell'elaborazione e nell'interpretazione di questi modelli. I documenti, come email, carta e PDF, possono passare attraverso molti record digitali e cartacei prima di essere approvati per il pagamento, rendendo l'estrazione manuale dei dati difficile e soggetta a errori.
Inefficienza del processo
La gestione manuale delle fatture, che comporta un costo medio di quasi $23 per fattura3 , può essere sia dispendiosa in termini di tempo che costosa, portando a un processo inefficiente e ripetitivo.
Potenziale perdita di dati
C'è il rischio di perdere dati se le fatture vengono smarrite o danneggiate o se i dati non vengono inseriti correttamente nel sistema.
I software OCR spesso incontrano difficoltà anche nell'estrarre le righe di dettaglio dalle fatture. Questo perché le tabelle delle transazioni potrebbero mancare di linee orizzontali o verticali, rendendo difficile per l'elaborazione OCR delle fatture stabilire il contesto per gli elementi estratti. In questo processo è possibile utilizzare immagini di fatture digitali o scansionate.
Come scegliere il fornitore di elaborazione delle fatture?
1. Fornisce una soluzione in linea con le politiche sulla privacy dei dati della tua azienda.
La politica sulla privacy dei dati della tua azienda può rappresentare un ostacolo all'utilizzo di API esterne come Amazon AWS Textract. La maggior parte dei fornitori offre soluzioni on-premise, quindi le politiche sulla privacy dei dati non impedirebbero necessariamente alla tua azienda di utilizzare una soluzione di acquisizione delle fatture. Il flusso di lavoro della contabilità fornitori deve essere trattato con attenzione poiché coinvolge spesso informazioni aziendali e finanziarie riservate.
2. Fornire una struttura dati coerente indipendentemente dal testo presente sui documenti.
Esistono due modalità di funzionamento delle aziende di acquisizione fatture basate sul deep learning. Aziende come Textract restituiscono coppie chiave-valore. Quindi, ad esempio, se una fattura chiama l'importo totale “Importo lordo”, un'altra lo chiama “Importo totale” e una fattura tedesca lo chiama “Summe”, Textract fornisce i dati in 3 strutture diverse per questi 3 documenti.
In uno si ha una coppia chiave-valore con la chiave “Importo lordo”, in un altro “Importo totale” e in quello tedesco si ottiene “Summe”. Altri fornitori hanno progettato strutture dati coerenti che funzionano per tutte le fatture. In tutti e 3 gli scenari, si otterrebbe “Importo totale”, che è la chiave utilizzata nel loro file di output. Ciò semplifica l'analisi e l'elaborazione poiché non è necessario gestire molti formati di dati strutturati diversi.
3. Chiedere i tassi di falsi positivi e di estrazione manuale dei dati
Quindi eseguire un progetto Proof of Concept (PoC) per vedere i tassi effettivi sulle fatture ricevute dalla tua azienda.
Falsi positivi sono fatture che vengono elaborate automaticamente (auto) ma presentano errori nell'estrazione dei dati. Sono difficili da identificare e possono interrompere le operazioni. Ad esempio, l'estrazione errata degli importi dei pagamenti sarebbe problematica. Ridurre al minimo questo dovrebbe essere l'obiettivo assoluto.
Estrazione manuale dei dati è necessaria quando il sistema di estrazione automatica dei dati ha una fiducia limitata nel proprio risultato. Ciò potrebbe essere dovuto a un formato di fattura diverso, a una scarsa qualità dell'immagine o a un errore di stampa del fornitore. Anche questo è importante da ridurre al minimo, ma esiste un compromesso tra falsi positivi ed estrazione manuale dei dati. Avere più estrazione manuale dei dati può essere preferibile rispetto ad avere falsi positivi.
Questo è il primo benchmarking quantitativo che abbiamo visto in questo settore e seguiremo una metodologia simile per preparare il nostro benchmarking.
4. Sfruttare un PoC per misurare il potenziale tasso di automazione
Ciò dipende dal numero di campi che ci si aspetta di acquisire dai documenti. Un insieme tipico di circa 10 campi, inclusi elementi come ID dell'ordine di acquisto, nome del fornitore, ecc., può consentire l'immissione dei dati nell'ERP e nei pagamenti.
I fornitori che adottano le migliori pratiche raggiungono un tasso STP di circa 80% estraendo tutti questi circa 10 campi con quasi nessun errore circa 80% delle volte. Anche se possono verificarsi errori di tanto in tanto, il controllo manuale dei pagamenti più elevati può garantire che nessun pagamento errato significativo sfugga.
5. Chiedere opzioni di elaborazione avanzate fornite dal fornitore
L'estrazione è il primo passo nella raccolta dei dati; nella maggior parte dei casi deve essere seguita dall'elaborazione dei dati. Ad esempio, le fatture devono essere verificate per la conformità IVA (ad esempio, le fatture nazionali senza IVA devono spiegare perché l'IVA è esclusa) e la mancata osservanza potrebbe comportare multe significative per l'azienda, a seconda del paese.
6. Chiedere come la soluzione apprende nuove fatture
Le migliori soluzioni dispongono di un'interfaccia che consente al team di guidare la soluzione. Quando il dipendente della tua azienda seleziona le coppie chiave-valore, la soluzione di acquisizione delle fatture ne prende nota in modo da poter essere più sicura su una fattura simile in futuro.
7. Valutare la facilità d'uso della loro soluzione di inserimento manuale dei dati
Sarà utilizzata dal personale di back-office della tua azienda quando elabora manualmente le fatture che non possono essere elaborate automaticamente con sicurezza.
Oltre a questo, hanno senso le domande di approvvigionamento basate sulle migliori pratiche. Ad esempio:
- Quanto è diffusa la loro soluzione? Hanno clienti Fortune 500?
- I loro clienti sono soddisfatti della soluzione e del supporto? Potrebbe essere utile chiedere a un conoscente di un'azienda che utilizza già la loro soluzione. Poiché l'automazione delle fatture non è una soluzione che migliorerebbe il marketing o le vendite di un'azienda, anche i concorrenti potrebbero condividere reciprocamente la loro opinione sulle soluzioni di automazione delle fatture.
- Quali sono le opzioni per integrare la soluzione nei sistemi della tua azienda (ad esempio, ERP)? L'IT è d'accordo con l'approccio di integrazione?
- Qual è il costo totale di proprietà (TCO)? Soluzioni diverse utilizzano unità di prezzo diverse (ad esempio, prezzo per pagina o prezzo per documento), il che rende difficile questo confronto. Tuttavia, utilizzando un campione dei tuoi archivi, potresti avere una stima del costo.
Ulteriori letture
Cita questo benchmark
Scegli il formato adatto a dove pubblicherai. Incollare la versione con link nel tuo CMS preserva il backlink.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{Fattura OCR Benchmark: precisione di estrazione di LLM vs OCR}},
year = {2026},
month = jan,
howpublished = {\url{https://aimultiple.com/invoice-ocr}},
note = {AIMultiple. Consultato il 22 Gennaio 2026}
}

Sii il primo a commentare
Il tuo indirizzo email non verrà pubblicato. Tutti i campi sono obbligatori. I commenti vengono lasciati nella loro lingua originale.