Teste de Referência de Banco de Dados de Grafos: Neo4j vs FalkorDB vs Memgraph
Realizamos testes de referência no Neo4j, FalkorDB e Memgraph em um grafo sintético derivado de 120.000 avaliações de produtos da Amazon (381K nós, 804K arestas). Executamos 12 modelos de consulta com 1.000 medições cada, testamos a ingestão em 6 tamanhos de lote, mantivemos carga concorrente por 60 segundos com até 32 threads e medimos memória, inicialização a frio, carga de trabalho mista e impacto de índices.
O FalkorDB entregou maior vazão que o Neo4j e o Memgraph em 8 threads.
Resultados do teste de referência de banco de dados de grafos
Vazão concorrente
QPS (consultas por segundo) mede quantas consultas de leitura o banco de dados responde por segundo sob carga sustentada multithread. Cada execução dura 60 segundos. Quanto maior, melhor.
Latência de consulta (p50)
O p50 é a latência mediana: metade de todas as consultas termina mais rápido que este valor. Quanto menor, melhor.
- Consulta pontual: Buscar um único nó por ID. As tabelas hash Redis do FalkorDB fazem buscas em memória O(1), aproximadamente 3x mais rápido.
- Travessia: Percorrer de um nó para seus vizinhos (1-hop) ou vizinhos-de-vizinhos (2-hop). O FalkorDB faz 2-hop em 2,9x mais rápido.
- Agregação: Contar avaliações por marca, calcular classificações médias de estrelas.
- Filtrar + varrer: Filtrar avaliações por classificação de estrelas em todo o conjunto de dados.
Vazão de ingestão
A vazão de ingestão mede quantas avaliações por segundo o banco de dados pode escrever. Cada ponto no gráfico é um tamanho de lote diferente: quantas avaliações são agrupadas em uma única consulta. Quanto maior, melhor.
No tamanho de lote 1, o Memgraph lidera (1.427/s). À medida que o tamanho do lote aumenta, o FalkorDB escala rapidamente e ultrapassa o Memgraph por volta do lote 500. O Neo4j estabiliza em ~10.600/s independentemente do tamanho do lote. No lote 5.000, o FalkorDB atinge 22.784/s, 77x seu desempenho no lote 1.
Você pode ler mais sobre nossa metodologia de teste de referência de banco de dados de grafos.
Principais descobertas
O FalkorDB atinge 6.693 QPS em 8 threads, 6,7x o Neo4j
As estruturas de dados em memória do Redis e o loop de eventos permitem combinar consultas de baixa latência com alto paralelismo. Após 8 threads, a vazão estabiliza porque o núcleo de thread única do Redis é o limite. O Neo4j atinge o pico em 16 threads (1.010 QPS) e depois cai em 32 (927 QPS), o que aponta para contenção de threads.
O FalkorDB inicia a frio em 1,1ms, 82x mais rápido que o Neo4j
O Neo4j leva 90ms para aceitar sua primeira consulta após uma reinicialização. A primeira consulta de aquecimento roda em 274ms, depois leva cerca de 3 consultas para se estabilizar em 34ms. O FalkorDB está pronto em 1,1ms, primeira consulta em 0,4ms. Em uma configuração de microsserviço ou serverless onde os pods escalam para cima e para baixo, essa diferença importa.
Índices: diferença de 1.700x no Neo4j, ~1x no FalkorDB
Sem índices, a consulta deep_feature_products do Neo4j levou 293ms. Com índices, 0,17ms. Isso é uma diferença de 1.712x. O Memgraph mostrou sensibilidade semelhante (160-898x dependendo da consulta). Os resultados do FalkorDB permaneceram aproximadamente os mesmos com ou sem índices porque as tabelas hash do Redis já funcionam como índices implícitos.
Memória: 415MB vs 2.668MB para o mesmo grafo
- Memgraph: 415MB
- FalkorDB: 496MB
- Neo4j: 2.668MB (heap JMX usado)
A JVM do Neo4j pré-aloca 4GB na inicialização, então sua memória no nível de processo (VmRSS) é sempre ~5,2GB independentemente do uso real de dados. A métrica de heap JMX é a significativa. O pico de 2,7GB é o número a usar para planejamento de capacidade.
O Neo4j venceu a agregação mais pesada
O FalkorDB teve a menor latência em 11 de 12 consultas. A exceção foi agg_feature_sentiment (agrupar por sentimento com filtragem), onde o otimizador de consultas do Neo4j produziu um plano de execução melhor: 131ms vs 152ms do FalkorDB.
Carga de trabalho mista (80% leitura, 20% escrita)
8 threads, 60 segundos, zero erros em todos os três bancos de dados:
- FalkorDB: 50.223 ops (837 QPS)
- Neo4j: 44.256 ops (738 QPS)
- Memgraph: 28.040 ops (467 QPS)
Operações de escrita não degradaram perceptivelmente o desempenho de leitura em nenhum deles.
Arquiteturas neste teste de referência
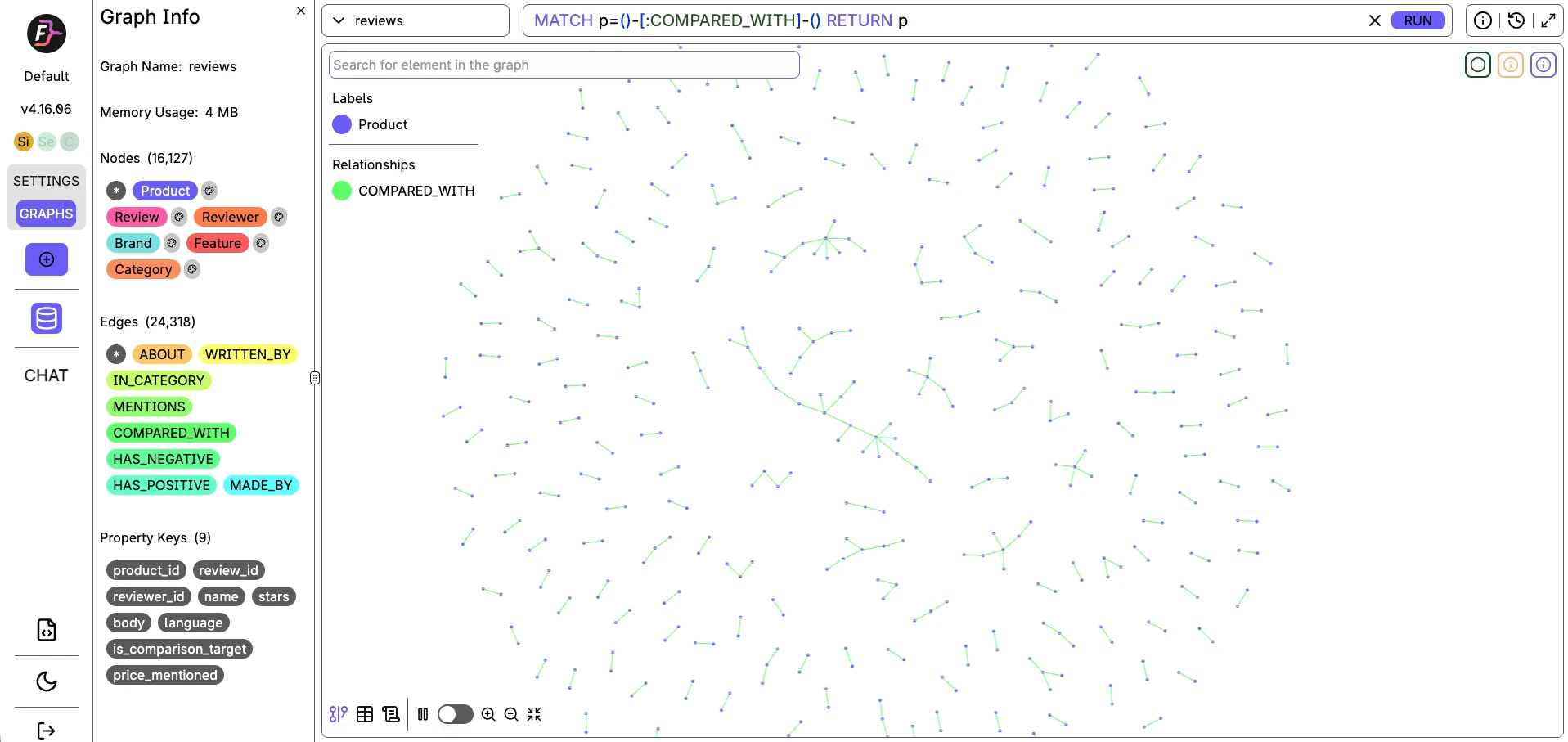
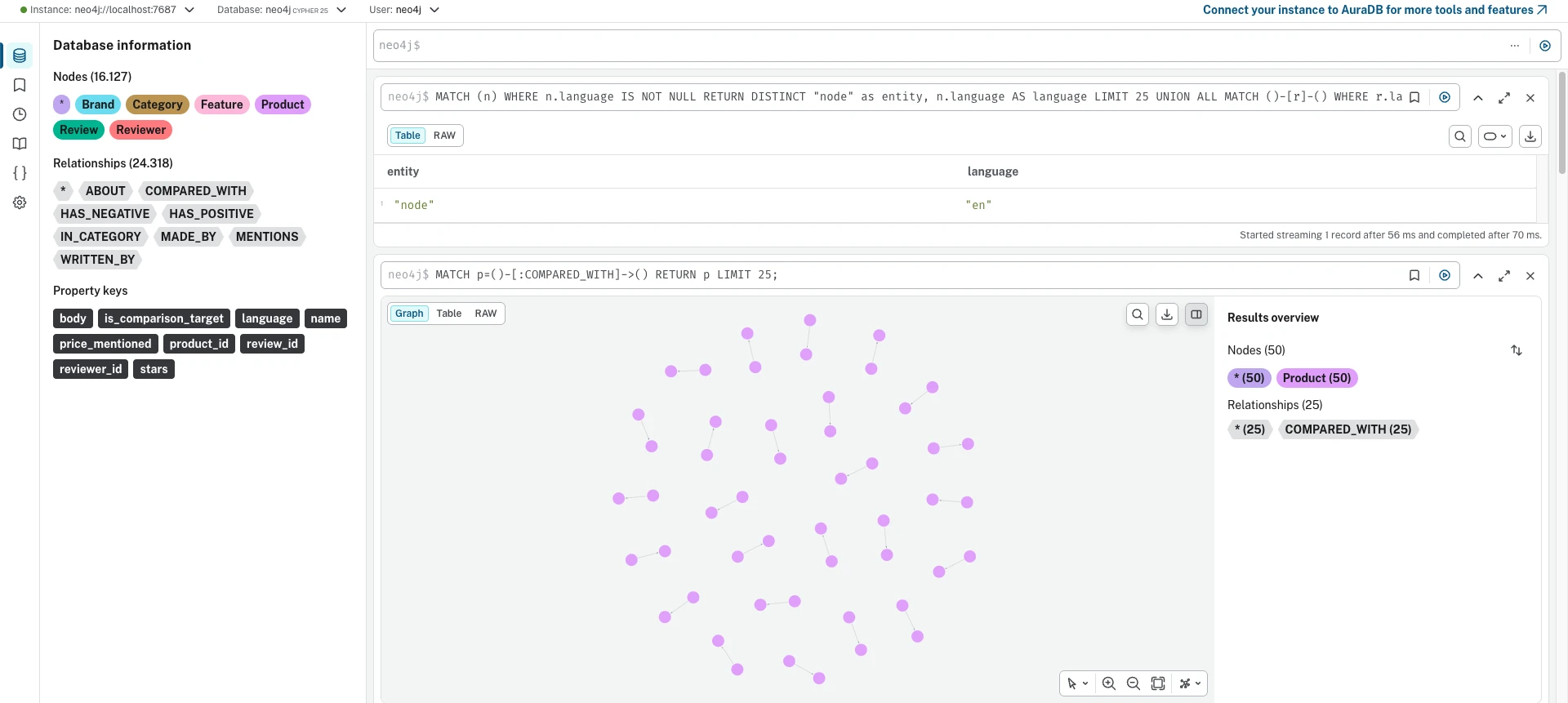
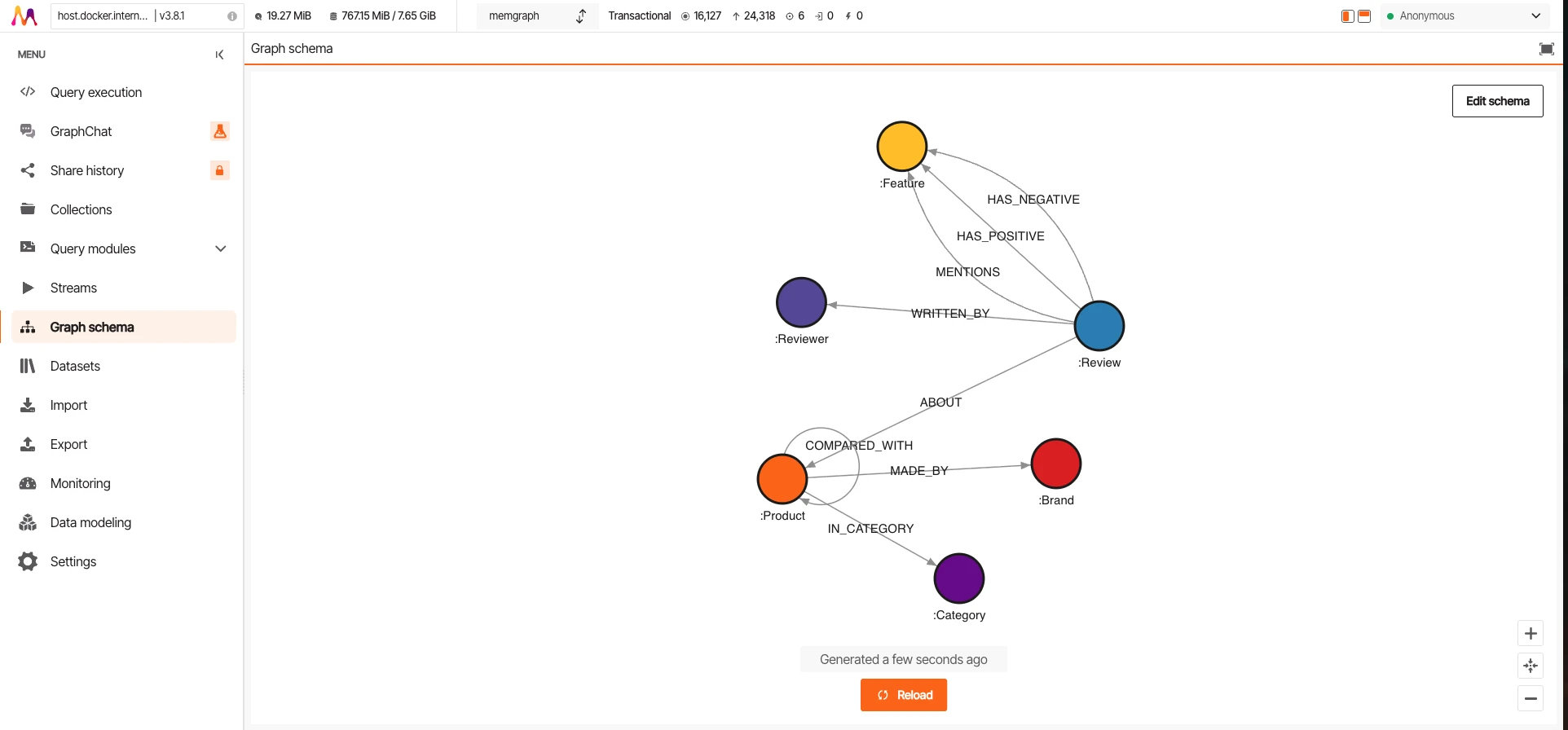
Cada banco de dados entrega sua própria interface de gerenciamento. Estas capturas de tela mostram o mesmo conjunto de dados (16.127 nós, 24.318 arestas) carregado em todos os três, executando a mesma consulta de travessia COMPARED_WITH.
FalkorDB
O FalkorDB é um módulo de grafo construído sobre o armazenamento de chave-valor em memória do Redis. As consultas são openCypher, mas por baixo é tabelas hash Redis. É por isso que as consultas pontuais ficam em 0,044-0,048ms.
Os outros dois bancos de dados neste teste mediram 2-3x mais alto nas mesmas consultas. A compensação é que o núcleo de thread única do Redis significa que a vazão concorrente para de escalar além de 8 threads
Neo4j
O Neo4j roda na JVM. A compilação JIT significa que consultas repetidas ficam mais rápidas com o tempo (aquecimento: 274ms -> 34ms). Pausas de GC afetam a latência de cauda, mas são capturadas pela remoção de outliers IQR. O otimizador de consultas lida bem com planos de agregação complexos, e é de lá que vem a vitória do agg_feature_sentiment. O custo é a pré-alocação de heap de 4GB e sobrecarga de GC.
Memgraph
O Memgraph é escrito em C++. Sem sobrecarga de JVM. 415MB para o conjunto de dados completo, o menor dos três. Mais rápido em inserções individuais (1.427/s) graças à sobrecarga mínima por consulta. Mas fica para trás na vazão concorrente (684 QPS de pico). Compatível com Bolt, então funciona com o driver Neo4j.
Metodologia de teste de referência de banco de dados de grafos
Ambiente
- RunPod 8 vCPU (AMD EPYC x86_64), 32GB RAM, Ubuntu 24.04 LTS
- Instalação nativa, sem Docker. Todos os três bancos de dados na mesma máquina, conexões localhost.
- Python 3.12.3. Sessões persistentes para testes de thread única, sessões por chamada de um pool de conexões para testes multithread.
Dados
- 120.000 avaliações sintéticas geradas a partir de Zipf (marcas, recursos) e Poisson (entidades, relacionamentos) distribuições, seed fixo=42.
- 6 tipos de nó: Avaliação, Produto, Avaliador, Marca, Recurso, Categoria
- 8 tipos de aresta: ABOUT, WRITTEN_BY, IN_CATEGORY, MADE_BY, HAS_POSITIVE, HAS_NEGATIVE, MENTIONS, COMPARED_WITH
Consultas
12 modelos Cypher em 5 categorias: consulta pontual (3), travessia 1-hop (2), travessia 2-hop (2), agregação (3), filtro (1), varredura completa (1). Cada consulta parametrizada roda com 10 valores de parâmetro diferentes, 100 vezes cada, para 1.000 medições por consulta por banco de dados.
Os parâmetros são amostrados do espaço completo de IDs usando seleção ponderada por Zipf, para que itens populares e raros sejam testados.
Três exemplos:
Consulta pontual: Buscar um único nó por ID indexado
Travessia 2-hop: Percorrer de uma marca através de seus produtos para suas avaliações
Agregação: Varredura completa do grafo com join multi-hop e computação
Medição
- Temporização:
time.perf_counter_ns(), 500 consultas de aquecimento, 100 execuções por consulta no mínimo - Estatísticas: 10.000 amostras bootstrap, IC 95%, remoção de outliers IQR (fator 3,0x). Ambos os dados brutos e filtrados são relatados.
- Memória: Neo4j via heap JMX usado (VmRSS é sem sentido porque a JVM pré-aloca), FalkorDB via Redis
used_memory_rss, Memgraph via/proc/{pid}/statusVmRSS.
Justiça
- Mesmo tamanho de pool de conexões, contagem de aquecimento, consultas Cypher, dados e máquina em todos os três bancos de dados.
- Teste concorrente: carga sustentada de 60 segundos em 1, 2, 4, 8, 16 e 32 threads com pool_size=32 fixo. Mistura de consultas: 40% travessia 1-hop, 30% travessia 2-hop, 20% agregação, 10% travessia 3-hop.
Bancos de dados testados
Limitações
Máquina única, nó único por banco de dados. Sem teste de referência distribuído ou de cluster. Clusterização Enterprise do Neo4j e replicação do Memgraph estão fora do escopo.
Dados sintéticos com distribuições derivadas de avaliações reais da Amazon. Pode não corresponder a padrões específicos de carga de trabalho de produção.
Não medido: persistência/recuperação de disco, pesquisa de texto completo, algoritmos de grafo (PageRank, detecção de comunidade) e cargas de trabalho pesadas em escrita (>50% escritas).
Drivers diferentes: Neo4j e Memgraph usaram o driver Python Neo4j, FalkorDB usou o seu próprio. A diferença de sobrecarga foi
Conclusão
O FalkorDB venceu 11 de 12 consultas, atingiu 6.693 QPS e iniciou a frio em 1,1ms. Para cargas de trabalho de grafo pesadas em leitura, é a opção mais rápida neste teste de referência. O Memgraph é a opção mais eficiente em memória (415MB vs 2,7GB). O Neo4j oferece o ecossistema mais amplo: RBAC, clusterização, monitoramento e um otimizador de consultas que lida com planos de agregação complexos melhor que qualquer alternativa.
A arquitetura determina o limite. Clusters distribuídos, grafos de 1M+ nós e cargas de trabalho pesadas em escrita são os testes que poderiam reorganizar esses rankings.
Cite esta pesquisa
Escolha o formato adequado ao local onde você vai publicar. Colar a versão com link no seu CMS preserva o backlink.
@misc{sari2026,
author = {Sarı, Ekrem},
title = {{Teste de Referência de Banco de Dados de Grafos: Neo4j vs FalkorDB vs Memgraph}},
year = {2026},
month = apr,
howpublished = {\url{https://aimultiple.com/graph-databases}},
note = {AIMultiple. Acessado em 15 Abril 2026}
}
Seja o primeiro a comentar
Seu endereço de e-mail não será publicado. Todos os campos são obrigatórios. Os comentários são deixados em seu idioma original.