Migliori 12+ Agenti IA per Web Scraping (Gratuiti e a Pagamento)
I selettori CSS manuali e gli script di base non funzionano più bene. Man mano che le architetture web diventano più dinamiche e guidate dall'IA, i tradizionali metodi di scraping diventano meno efficaci.
Per mantenere i dati affidabili, il settore si sta rivolgendo ad agenti IA autonomi, scraping basato su visione (VLM) e scraper auto-riparanti. Visita i migliori strumenti IA per web scraping:
Migliori strumenti IA per web scraping
Come abbiamo creato questa lista
Abbiamo intenzionalmente escluso strumenti di data-scraping e librerie di automazione di uso generale che mancano di capacità IA integrate (come Scrapy o Playwright), anche se sono comunemente utilizzati per web scraping e possono integrare gli strumenti IA in flussi di lavoro ibridi.
Abbiamo curato questa lista utilizzando i seguenti criteri:
- Focus sulle capacità potenziate da IA: Abbiamo incluso strumenti che utilizzano l'intelligenza artificiale, come LLM e NLP, per comprendere la struttura della pagina senza regole hardcoded o estrazione di dati guidata da prompt.
- Accessibilità per gli utenti: Abbiamo categorizzato gli strumenti in base al livello tecnico, come strumenti no-code vs strumenti per sviluppatori.
Cos'è il web scraping IA?
Il web scraping IA si è evoluto in Liquidazione Autonoma dei Dati. Non si tratta più di automatizzare i clic del browser o il parsing HTML; coinvolge i Modelli Linguaggio-Visione (VLM) che 'vedono' una pagina web come un umano e il Ragionamento Agente che può navigare autenticazioni complesse e contenuti dinamici senza selettori CSS predefiniti o mappatura DOM.
Tipi di strumenti per web scraping IA
1. Piattaforme potenziate da IA
Queste soluzioni utilizzano LLM, visione artificiale o NLP per analizzare, estrarre o interpretare contenuti dalle pagine web. Ad esempio, lo scraping adattivo di Diffbot si adatta dinamicamente alle modifiche DOM o al markup incoerente tra le pagine. Molti strumenti in questa categoria supportano l'estrazione basata su schema (strutturata) o su prompt.
Dai allo strumento un'istruzione in linguaggio naturale, ad esempio, "Estrai tutti i titoli di lavoro e i nomi delle aziende da questo URL."
2. Strumenti No-Code
I scraper no-code forniscono interfacce visive che consentono agli utenti di definire i dati da catturare utilizzando funzionalità point-and-click o modelli predefiniti. Puoi definire le regole di estrazione dei dati visivamente.
Tuttavia, questi strumenti offrono un utilizzo limitato dell'IA rispetto alle piattaforme potenziate da IA, che utilizzano l'IA per il rilevamento di pattern o suggerimenti intelligenti sui campi.
3. Strumenti IA Open-Source
Questa categoria include librerie o framework che utilizzano LLM o agenti IA per estrarre dati dalle pagine web. Forniscono controllo programmatico; devi definire schemi di estrazione o prompt IA.
Tecniche e tecnologie coinvolte nel web scraping potenziato da IA
L'approccio al web scraping potenziato da IA si adatta automaticamente ai redesign dei siti web ed estrae dati caricati dinamicamente tramite JavaScript. È importante impiegare questi metodi considerando i termini del sito web e le considerazioni etiche.
1. Scraping adattivo
I metodi tradizionali di web scraping si basano sulla struttura o sul layout specifico di una pagina web. Quando i siti web aggiornano i loro design e strutture, gli scraper tradizionali possono rompersi facilmente. I metodi di raccolta dati basati su IA, come lo scraping adattivo, consentono agli strumenti di web scraping di adattarsi ai cambiamenti sui siti web, inclusi design e struttura.
Gli scraper adattivi utilizzano machine learning e IA per regolare dinamicamente il loro comportamento in base alla struttura di una pagina web. Identificano autonomamente la struttura della pagina web target analizzando il Document Object Model (DOM) o seguendo pattern specifici. Per identificare pattern o anticipare cambiamenti, lo strumento può essere addestrato utilizzando dati storici estratti.
Ad esempio, modelli IA come le reti neurali convoluzionali (CNN) possono essere utilizzati per riconoscere e analizzare elementi visivi di una pagina web come i pulsanti. Tipicamente, le tecniche di data scraping tradizionali si basano sul codice sottostante di una pagina web, come gli elementi HTML, per estrarre dati.
Estrazione visiva zero-shot:
Lo scraping adattivo tradizionale si basa ancora sull'albero DOM. Tuttavia, nel 2026, strumenti come Firecrawl e Crawl4AI sono passati all'estrazione 'Zero-Shot'. Prendendo uno snapshot visivo (VLM), l'IA identifica gli elementi in base all'intento visivo piuttosto che al codice. Questo rende gli scraper più resistenti alla randomizzazione delle classi CSS e alle trappole di codice 'Honey-pot'.
Sponsorizzato
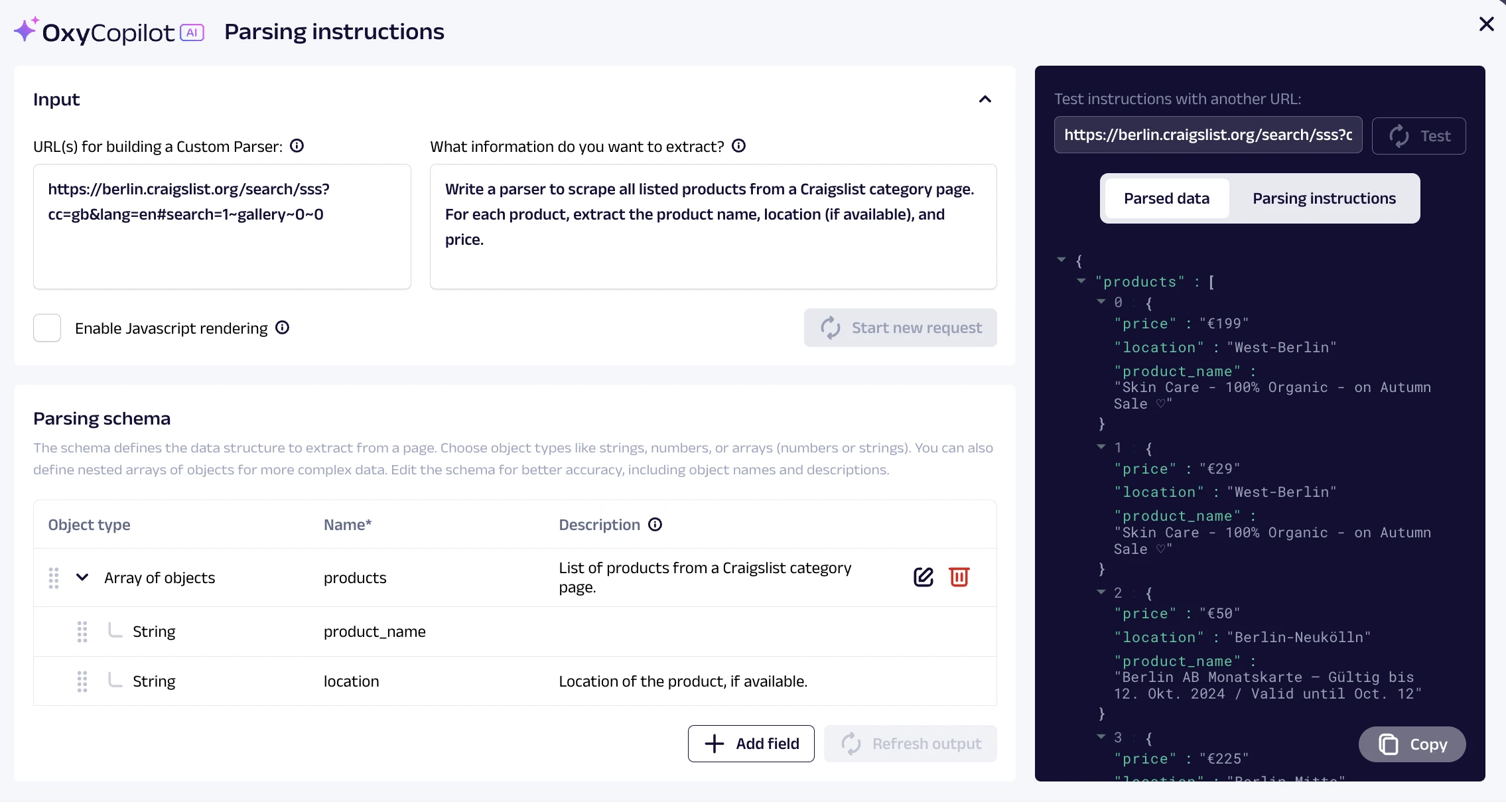
Oxylabs fornisce un costruttore di parser personalizzati basato su ML, chiamato OxyCopilot, che potenzia l'API dello Web Scraper di Oxylab API, consentendo agli utenti di raffinare e organizzare i dati raccolti utilizzando prompt. Questo semplifica il processo eliminando la necessità di setacciare campi di dati irrilevanti o eseguire la pulizia manuale dei dati.
2. Generazione di pattern di navigazione simili a quelli umani
La maggior parte dei siti web impiega misure anti-scraping, come CAPTCHA, per impedire agli scraper web di accedere e scansionare il loro contenuto. Gli strumenti di web scraping potenziati da IA possono simulare comportamenti simili a quelli umani come velocità, movimenti del mouse e pattern di clic.
3. Modelli IA generativi
Nel 2025/2026, abbiamo smesso di chiedere all'IA di scrivere codice BeautifulSoup. Invece, usiamo Agenti di Scraping (come Skyvern o Browser-use).
- Come funziona: Fornisci un obiettivo in inglese semplice (ad esempio, 'Trova il laptop più economico su questo sito ed esporta in JSON').
- Pattern Reason-act (ReAct): L'agente esplora il sito, risolve il CAPTCHA, gestisce la paginazione e valida la qualità dei dati in tempo reale senza una singola riga di codice manuale.
4. Elaborazione del linguaggio naturale (NLP)
L'NLP, un sottoinsieme del ML, ti consente di eseguire attività come analisi del sentiment, riassunto dei contenuti e riconoscimento delle entità. È necessario derivare approfondimenti dai dati estratti.
Ad esempio, se hai estratto una quantità significativa di dati di recensioni di prodotti, devi determinare il tono emotivo dietro ogni parola, come positivo, negativo o neutro. L'analisi del sentiment ti consente di categorizzare i dati estratti come positivi o negativi. Questo aiuta le aziende a rispondere alle preoccupazioni dei clienti e migliorare le loro offerte.
Cita questa ricerca
Scegli il formato adatto a dove pubblicherai. Incollare la versione con link nel tuo CMS preserva il backlink.
@misc{karatas2026,
author = {Karatas, Gulbahar},
title = {{Migliori 12+ Agenti IA per Web Scraping (Gratuiti e a Pagamento)}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/ai-web-scraping}},
note = {AIMultiple. Consultato il 5 Giugno 2026}
}
Sii il primo a commentare
Il tuo indirizzo email non verrà pubblicato. Tutti i campi sono obbligatori. I commenti vengono lasciati nella loro lingua originale.