Le 5 Migliori Estensioni Gratuite di Chrome per il Web Scraping
Un'estensione per web scraper di Chrome ti consente di raccogliere dati come testo, tabelle, link, immagini ed elenchi direttamente dal browser. Molte estensioni offrono flussi di lavoro senza codice, rilevamento dei campi basato sull'IA, scraping pianificato, esportazioni su Google Sheets e monitoraggio delle modifiche delle pagine.
Confronta le estensioni per web scraper di Chrome più popolari in base alle loro capacità principali, opzioni di esportazione, facilità d'uso e funzionalità di monitoraggio:
Confronto rapido delle migliori estensioni scraper per Chrome
Provider | Punteggio Chrome Web Store | Esportazioni |
|---|---|---|
WebScraper.io | 4.1 out of 1K ratings | CSV, XLSX, CouchDB |
Thunderbit | 4.2 out of 167 ratings | CSV, Excel, Google Sheets, Notion, Airtable |
Data Miner | 3.9 out of 701 ratings | CSV, Excel, Google Sheets |
Simplescraper | 4.4 out of 363 ratings | CSV, JSON, Google Sheets, API |
Browse IA | 3.9 out of 45 ratings | CSV, Google Sheets, integrazioni |
Le migliori estensioni gratuito per web scraper di Chrome
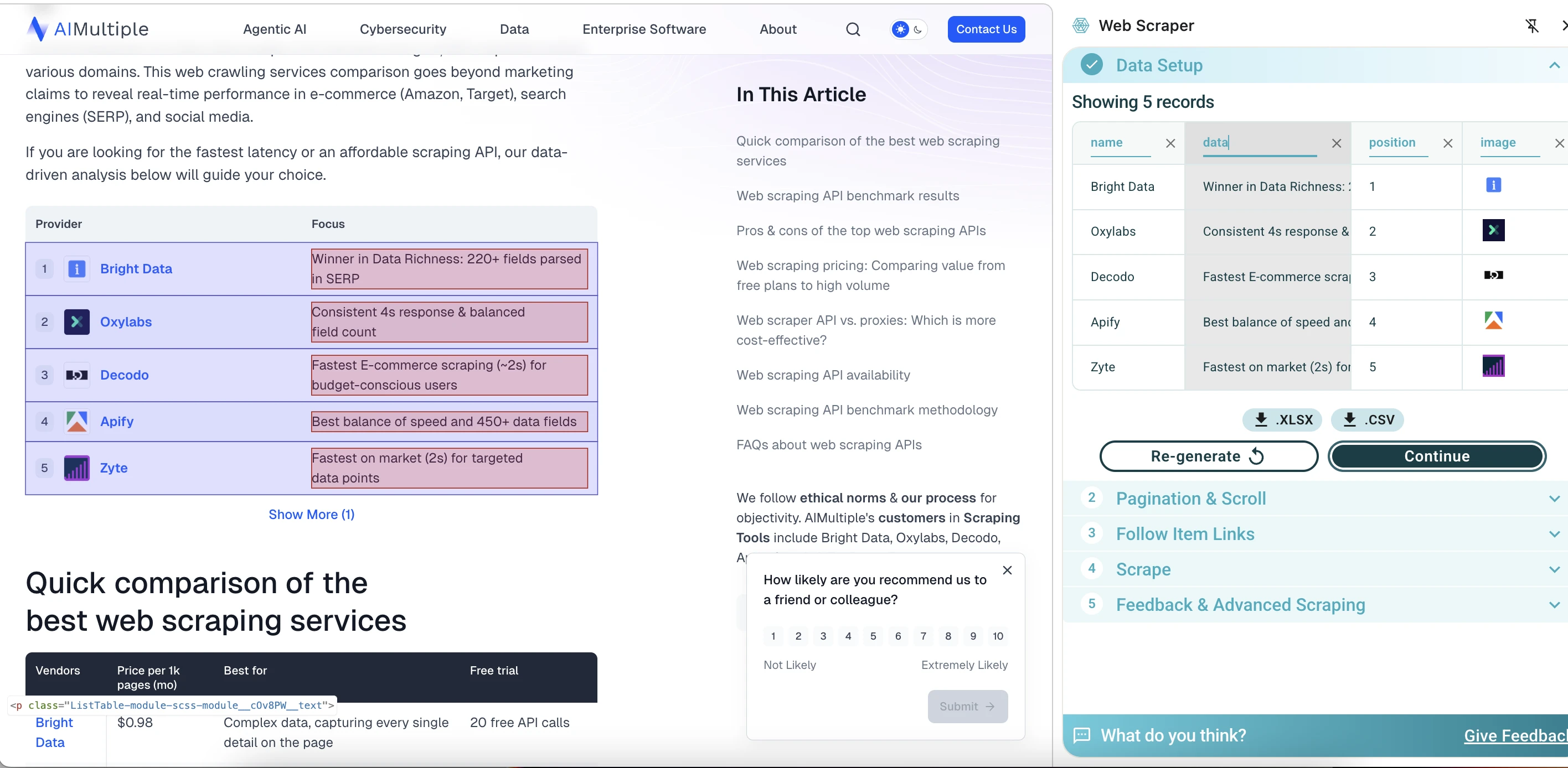
WebScraper.io ha identificato rapidamente il primo elemento sulla pagina e ha mostrato un'anteprima di 5 record, estraendo campi come nome del provider, descrizione, posizione, URL dell'immagine e URL della pagina sorgente. Un dettaglio utile è che i nomi delle colonne sono modificabili. Questo rende più facile pulire l'output prima dell'esportazione, invece di sistemare tutto in un secondo momento in un foglio di calcolo.
Tuttavia, non è riuscito a caricare o configurare il resto della pagina per uno scraping più ampio. Per l'estrazione di semplici tabelle, ha funzionato bene, offrendo velocità, un'interfaccia visiva e un facile esportazione dei dati. In questo test, è stato più limitato quando si trattava di scraping dell'intera pagina.
Il flusso di lavoro rapido di estrazione è abbastanza semplice per tabelle semplici, mentre il flusso di lavoro avanzato con sitemap offre agli utenti un maggiore controllo. Tuttavia, la modalità avanzata richiede la comprensione di concetti come URL iniziali, selettori, elementi multipli, alberi di selettori genitore-figlio e ritardi nello scraping.
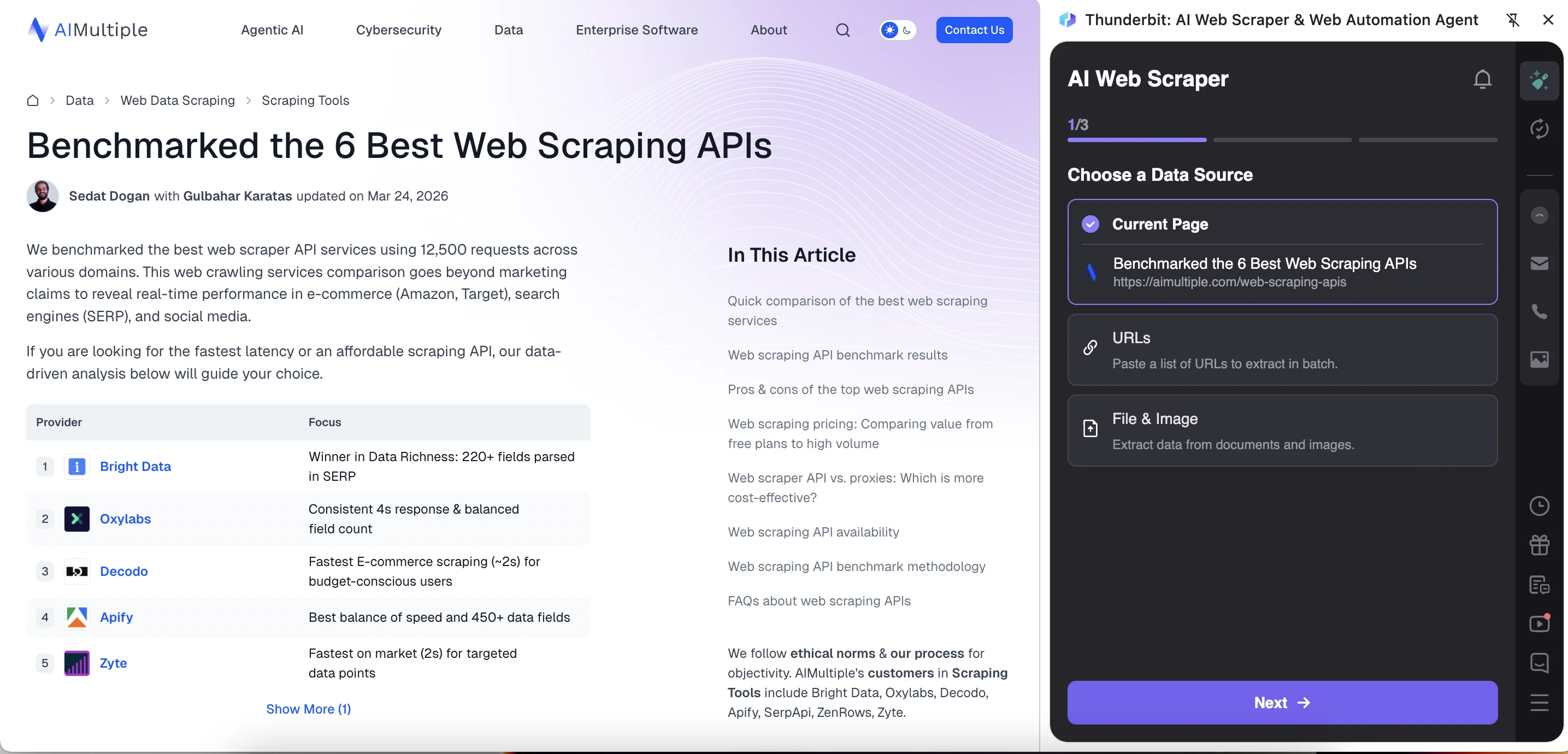
Thunderbit ha un'interfaccia più guidata e orientata all'IA. Inizia chiedendo all'utente di scegliere una fonte di dati: Pagina corrente, URL o File & Immagine. Thunderbit ha estratto più tipi di informazioni dalla pagina dell'articolo rispetto a WebScraper.io. Tuttavia, l'output non era perfettamente strutturato perché campi ripetuti dell'articolo apparivano accanto a ogni riga del provider.
Thunderbit crea o ti consente di creare un modello con campi predefiniti. Lo strumento ha creato automaticamente un modello per l'articolo e ha suggerito campi come titolo dell'articolo, URL, autore, data di pubblicazione e contenuto. Il modello è anche modificabile, quindi gli utenti possono rimuovere campi irrilevanti, aggiungerne di nuovi o utilizzare "IA Improve Fields" per perfezionare la configurazione dell'estrazione prima di eseguire lo scraper.
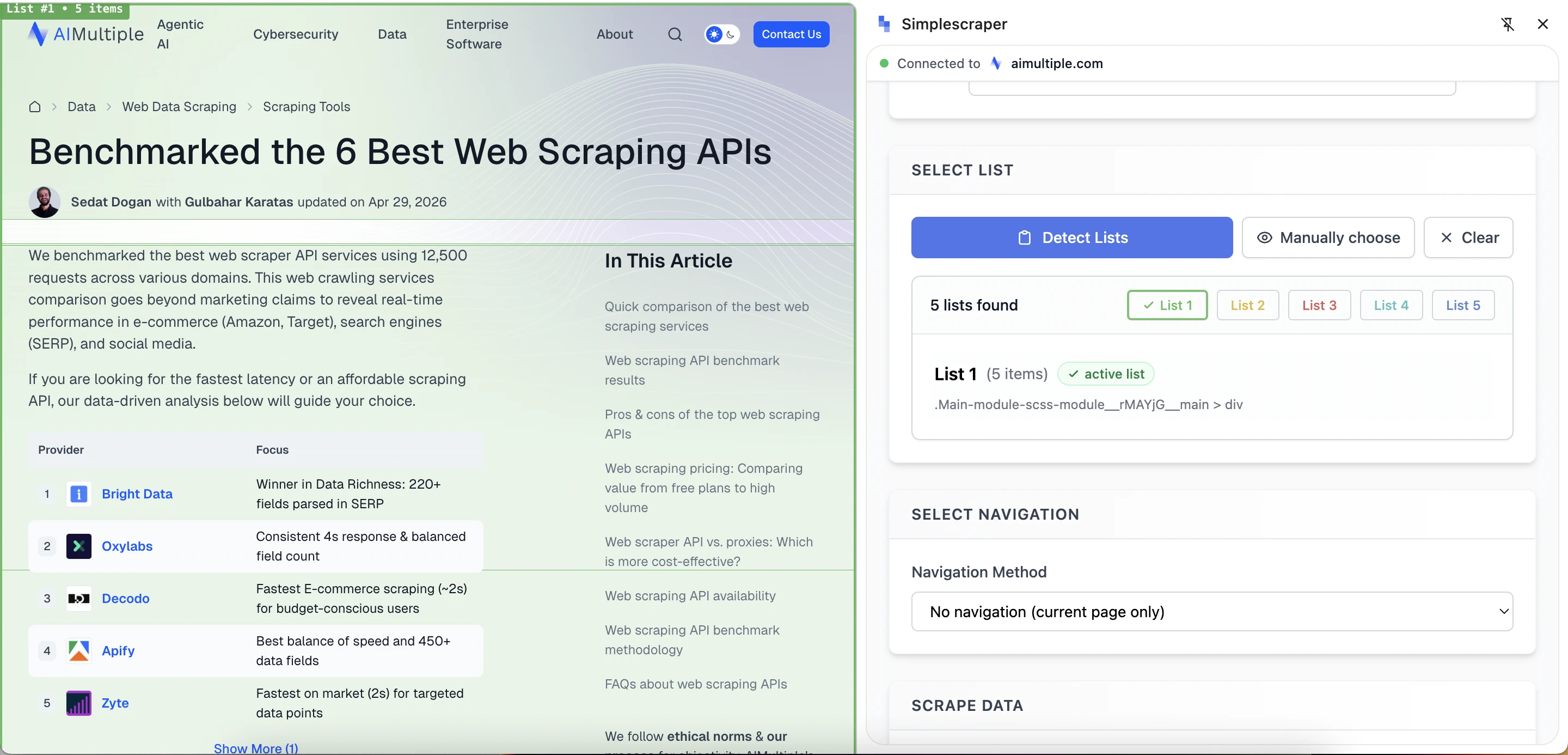
Simplescraper appare più moderno e intuitivo rispetto a WebScraper.io e Data Miner. Lo strumento offre due modalità di scraping:
- Raccolta di elenchi: Per dati ripetuti, come prodotti, articoli, risultati di ricerca o righe di tabella.
- Raccolta di dettagli: Per campi specifici da una singola pagina.
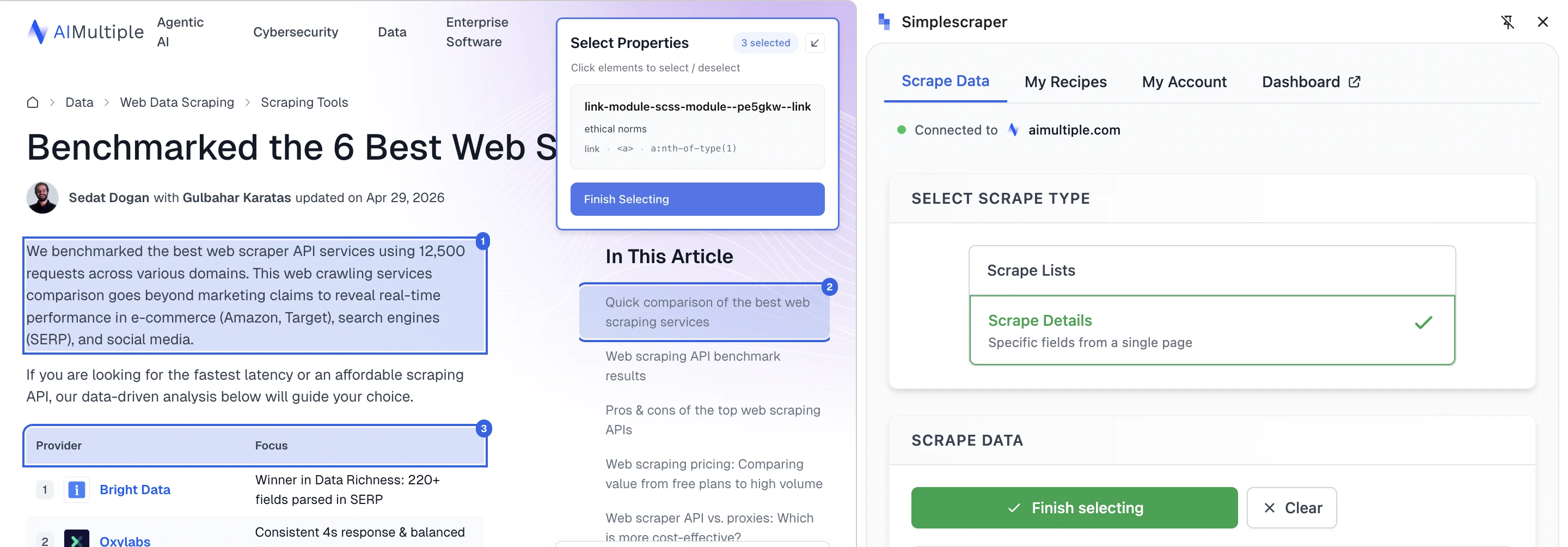
La funzione di rilevamento degli elenchi scansiona la pagina alla ricerca di potenziali elenchi, evidenziandoli ed etichettandoli. Simplescraper offre anche un'opzione di selezione manuale, consentendo agli utenti di fare clic direttamente sugli elementi della pagina.
Le funzionalità di navigazione come pagina successiva, scorrimento infinito o carica altri richiedono un account a pagamento. Per gli utenti che testano l'estensione gratuito, Simplescraper è utile principalmente per lo scraping della pagina corrente. L'output è utile, anche se alcuni campi rilevati possono risultare poco chiari a causa di nomi di colonna abbreviati o contenuti misti. Il rilevamento automatico degli elenchi identifica le strutture ripetute, ma gli utenti potrebbero dover selezionare l'elenco corretto e perfezionare i campi.
Funzione di rilevamento automatico degli elenchi:
Rilevamento manuale di campi specifici dalla pagina:
L'estensione di estrazione dati Browse IA ha due funzionalità principali: può estrarre dati da una pagina web e monitorare le modifiche nel tempo. Lo strumento offre le seguenti capacità:
Capture list estrae dati organizzati selezionando elementi ripetuti su una pagina, come righe di tabella o schede elenco, trasformandoli in una tabella scaricabile o un foglio di calcolo.
Capture text monitora testo o immagini specifici selezionando gli elementi che si desidera tracciare. Browse IA controllerà automaticamente questi elementi a ogni esecuzione. Puoi scegliere il numero di righe da estrarre, ad esempio 10 o 100, o qualsiasi altra quantità desiderata. Il sistema ti chiederà quindi di selezionare un tipo di impaginazione, utile per navigare tra elenchi che si estendono su più pagine o richiedono opzioni come "Mostra di più".
Capture screenshot offre opzioni per acquisire screenshot visivi. Puoi catturare un'area selezionata, l'intera pagina o la porzione visibile dello schermo. Dopo aver catturato uno screenshot o selezionato un elemento della pagina, Browse IA ti consente di configurare una pianificazione di monitoraggio e regole di avviso per le modifiche. Ad esempio, puoi impostare la soglia di sensibilità a una piccola modifica (1%), il che significa che puoi ricevere una notifica anche quando una piccola porzione dello screenshot catturato cambia.
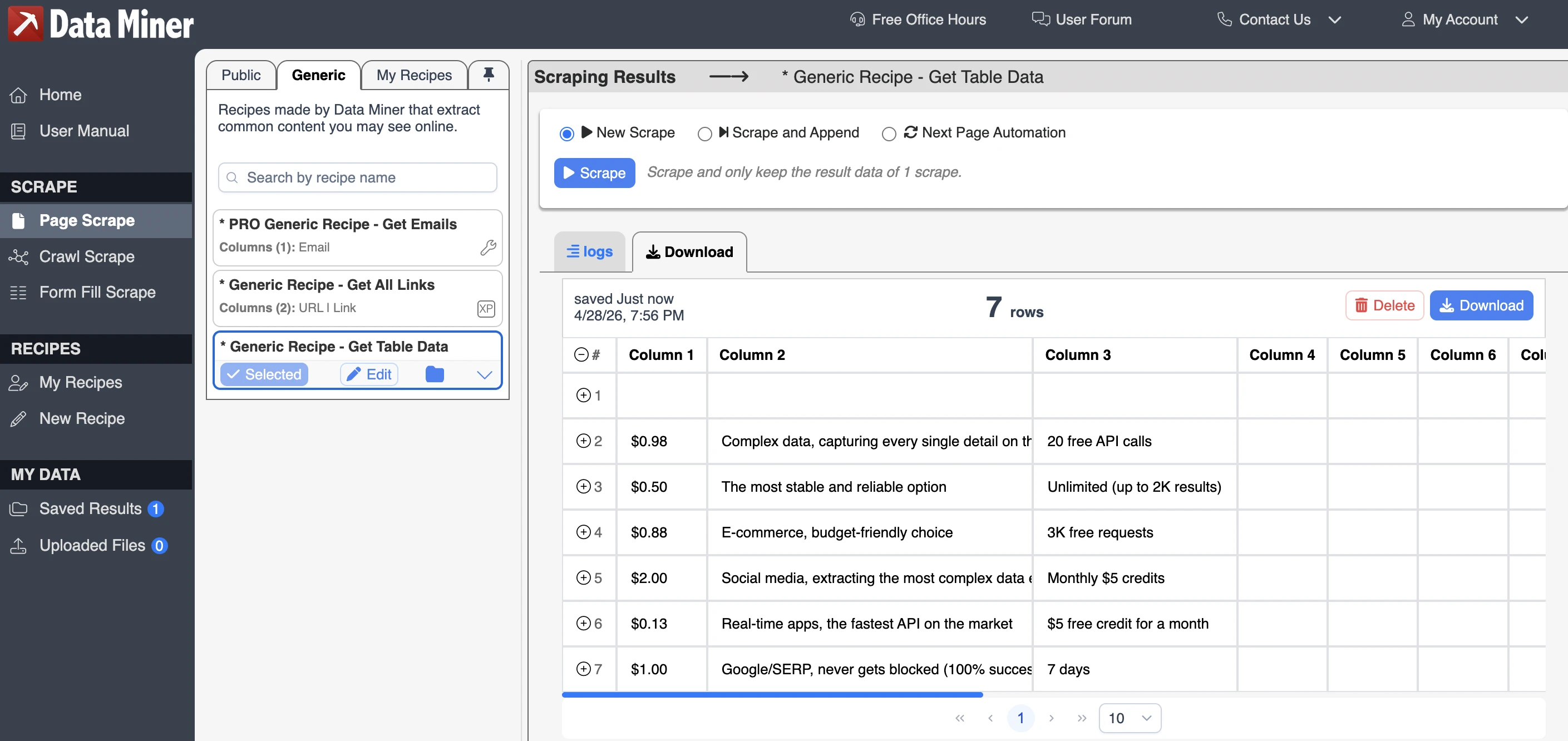
Data Miner
Data Miner richiede agli utenti di registrarsi o accedere prima di utilizzare l'estensione. Il piano gratuito include 500 scrape di pagine al mese, accesso a script specifici per sito esistenti, scraping su più pagine ed esportazioni in file CSV o XLS.
Data Miner utilizza un sistema di scraping basato su ricette. Una ricetta è un modello di scraping dati predefinito che indica all'estensione quali parti di una pagina web estrarre. Invece di selezionare manualmente ogni campo ogni volta, gli utenti possono eseguire una ricetta esistente, crearne una propria o utilizzare una ricetta pubblica condivisa da altri utenti.
L'output non era perfettamente strutturato per ottenere dati da tabelle. Non ha rilevato la colonna del nome del fornitore, utilizzando nomi di colonna generici come "Column 1" e "Column 2". I valori estratti erano per lo più accurati, ma il risultato richiedeva una pulizia manuale prima di poter essere utilizzato come dataset pulito.
FAQ
Un'estensione per web scraper di Chrome estrae dati dalle pagine web ed esporta i dati estratti come file CSV o XLSX in un formato strutturato. Puoi selezionare testo, tabelle, link, immagini o elenchi ed esportarli. Molte estensioni non richiedono competenze di programmazione.
No. La maggior parte delle estensioni per lo scraping di Chrome funziona senza programmazione, offrendo un'interfaccia punta e clicca. Installa l'estensione, apri una pagina web, seleziona i dati ed esportali. Per pagine complesse, usa selettori o regole personalizzate.
Un web scraper per Chrome può estrarre nomi di prodotti, prezzi, link, immagini, recensioni, tabelle, risultati di ricerca, annunci commerciali, offerte di lavoro, titoli di articoli e voci di directory. Alcuni strumenti possono estrarre dati da più pagine o elenchi di URL.
Sì. Molte estensioni per lo scraping dati possono elaborare pagine con pulsanti pagina successiva o carica altri, ed elenchi di URL. Puoi raccogliere dati da cataloghi, risultati di ricerca, directory o tabelle su più pagine. Uno scraper browser viene eseguito nel tuo browser per lo scraping locale.
Un'estensione scraper per Chrome di solito viene eseguita all'interno del browser ed è utile per uno scraping rapido, visivo e locale. Un web scraper cloud viene eseguito su server remoti ed è più adatto per lavori pianificati, scansioni più grandi, automazione e scraping quando il computer è offline.
Cita questa ricerca
Scegli il formato adatto a dove pubblicherai. Incollare la versione con link nel tuo CMS preserva il backlink.
@misc{karatas2026,
author = {Karatas, Gulbahar},
title = {{Le 5 Migliori Estensioni Gratuite di Chrome per il Web Scraping}},
year = {2026},
month = apr,
howpublished = {\url{https://aimultiple.com/web-scraper-chrome-extension}},
note = {AIMultiple. Consultato il 30 Aprile 2026}
}




Sii il primo a commentare
Il tuo indirizzo email non verrà pubblicato. Tutti i campi sono obbligatori. I commenti vengono lasciati nella loro lingua originale.