Il futuro dei grandi modelli linguistici
Vedi il futuro dei grandi modelli linguistici approfondendo approcci promettenti, come l'auto-addestramento, la verifica dei fatti e l'expertise sparsa che potrebbero affrontare le limitazioni degli LLM.
Confronto dei tassi di successo degli LLM
Claude Sonnet 4.6 ha guidato il benchmark con un punteggio complessivo di 0.748, con le varianti base e thinking a pari merito fino al terzo decimale. Claude Opus 4.8 (0.702), Opus 4.6 base (0.706), e Opus 4.6 thinking (0.729) hanno seguito, dando ad Anthropic le prime cinque posizioni. Il primo modello non-Anthropic è stato Gemini 3.5 Flash, thinking a 0.625. Le varianti GPT si sono raggruppate tra 0.57 e 0.60, con punteggi backend più elevati compensati dall'instabilità del frontend. Vedi di più nel nostro articolo di benchmark.
LLM Metodologia di Benchmark
Abbiamo testato i principali grandi modelli linguistici su 10 attività di sviluppo software utilizzando un harness CLI agentico. Ogni modello è stato eseguito 3 volte per attività (30 campioni per modello, 270 celle di validazione per iterazione) per stabilizzare i punteggi e misurare la varianza per cella. Tutti i modelli sono stati accessibili tramite OpenRouter in condizioni identiche, stesso harness, stesse istruzioni per le attività, stesso ambiente hardware.
Modelli testati
Il benchmark copre i modelli disponibili via API a partire da giugno 2026. Tutte le varianti elencate di seguito sono state testate indipendentemente:
- Claude Sonnet 4.6 (base e thinking)
- Claude Opus 4.8
- Claude Opus 4.6 (base e thinking)
- Claude Opus 4.7
- Gemini 3.5 Flash (base e thinking)
- GPT 5.5 (thinking)
- GPT 5.4 Mini
- GPT 5.3 Codex
- MiniMax M3
- Grok 4.3
- Qwen 3.6 Plus (base e thinking)
- GLM 5.1 (base e thinking)
- Deepseek V4 Pro (base e thinking)
Ambiente di test
Ogni agente e attività inizia in un ambiente pulito. Le istruzioni per le attività sono fornite come file TASK.md. Un watchdog heartbeat di 20 minuti monitora ogni esecuzione. Registriamo i codici di uscita, il tempo di esecuzione, la creazione di file backend e frontend e l'utilizzo in tempo reale dei token per le categorie di input, output e in cache.
Le attività spaziano dai sistemi di prenotazione ai dashboard interattivi. Tutte richiedono la gestione di progetti multi-file e un deliverable full-stack funzionale.
Punteggio
Validazione backend: I progetti generati vengono distribuiti in ambienti isolati e testati rispetto a un contratto YAML canonico che copre scenari happy-path, gestione degli errori (400/403/409) e coerenza dei dati. Vengono utilizzate due modalità:
- Modalità adattiva convalida la funzionalità anche quando i nomi delle route differiscono dalla specifica
- Modalità rigorosa richiede l'aderenza esatta al contratto (route, codici di stato, campi di risposta)
Punteggio backend per cella: backend_overall = has_backend × (0.7 × adaptive_pass_rate + 0.3 × strict_pass_rate)
Validazione UI: L'automazione del browser simula flussi utente reali, inclusi preflight, rendering, invio del login e comportamento post-login. Otto passaggi suddivisi in due gruppi:
- Passaggi infrastrutturali (preflight backend, rendering frontend, modulo di login visibile, invio del login, login 2xx, nessun crash runtime)
- Passaggi comportamentali (segnale di autenticazione post-login, segnale di comportamento post-login)
Punteggio UI per cella: ui_score = (behavior_passed / (behavior_passed + behavior_failed)) × (infra_passed / infra_total)
I passaggi comportamentali bloccati vengono esclusi dal denominatore comportamentale in modo che una cella non venga penalizzata due volte quando l'app non si carica.
Punteggio finale: Final Score = (0.7 × backend_overall) + (0.3 × ui_score)
Il backend ha un peso maggiore perché i fallimenti logici a livello di API invalidano tipicamente qualsiasi successo frontend.
Misurazione dei costi
Il costo per cella è calcolato in base all'utilizzo dei token estratto dalla risposta LLM API. I token di input in cache vengono sottratti dal totale dei token di input per ottenere l'input effettivo (solo i token appena elaborati). I token di output non vengono mai memorizzati nella cache e rimangono invariati. I tassi per token sono tratti da LLM Pricing al momento del test.
Limitazioni
- Ambito delle attività: Tutte le 10 attività sono build di applicazioni web full-stack. Il benchmark non copre attività di puro ragionamento, risoluzione di problemi scientifici, riassunto o carichi di lavoro specifici per dominio (legale, medico, finanziario). I punteggi riflettono specificamente la capacità di programmazione agentica.
- Accesso solo API: Tutti i modelli sono stati testati via API. I deployment locali o on-premise degli stessi modelli possono produrre risultati diversi a seconda della quantizzazione, dell'hardware e della configurazione di inferenza.
- Istantanea nel tempo: Le versioni dei modelli cambiano. I risultati riflettono la versione API attiva al momento del test. Un aggiornamento del modello può spostare i punteggi in entrambe le direzioni senza preavviso dal provider.
- Stile di chiamata degli strumenti: I modelli differiscono nel modo in cui strutturano scritture e modifiche dei file (ad esempio, OpenAI raggruppa un diff completo di file in una singola chiamata
apply_patch; i modelli Anthropic scrivono e ri-modificano attraverso più chiamate). Il conteggio delle chiamate degli strumenti non è un proxy diretto della qualità. - Singolo harness: Tutti i test hanno utilizzato Opencode come harness dell'agente. Un harness diverso può produrre classifiche relative diverse, in particolare per i modelli il cui comportamento predefinito è ottimizzato per schemi specifici di utilizzo degli strumenti.
Tendenze future dei grandi modelli linguistici
1- Fact-Checking in tempo reale con dati live
Gli LLM accedono a fonti esterne durante le conversazioni invece di fare affidamento solo sui dati di addestramento. Il modello interroga database esterni, recupera informazioni aggiornate e fornisce citazioni.
Limitazione: Ancora commette errori. Le citazioni non garantiscono l'accuratezza; i modelli a volte citano le fonti in modo errato o interpretano male il contenuto citato.
Microsoft Copilot: Integra GPT-5.4 Thinking con dati internet in tempo reale, introducendo le modalità “Quick Response” e “Think Deeper” per un ragionamento su misura per diversi tipi di attività.1 L'agente Researcher combina GPT per la ricerca iniziale con Anthropic’s Claude che revisiona gli output per accuratezza e qualità delle citazioni prima della consegna, un miglioramento del 13.8% sul benchmark di ricerca approfondita DRACO rispetto ai sistemi autonomi.2
- ChatGPT: Cerca sul web quando gli vengono chieste informazioni su eventi recenti. Cita le fonti nelle risposte.
- Perplexity: Costruito specificamente per la ricerca con citazioni. Ogni risposta include link alle fonti.
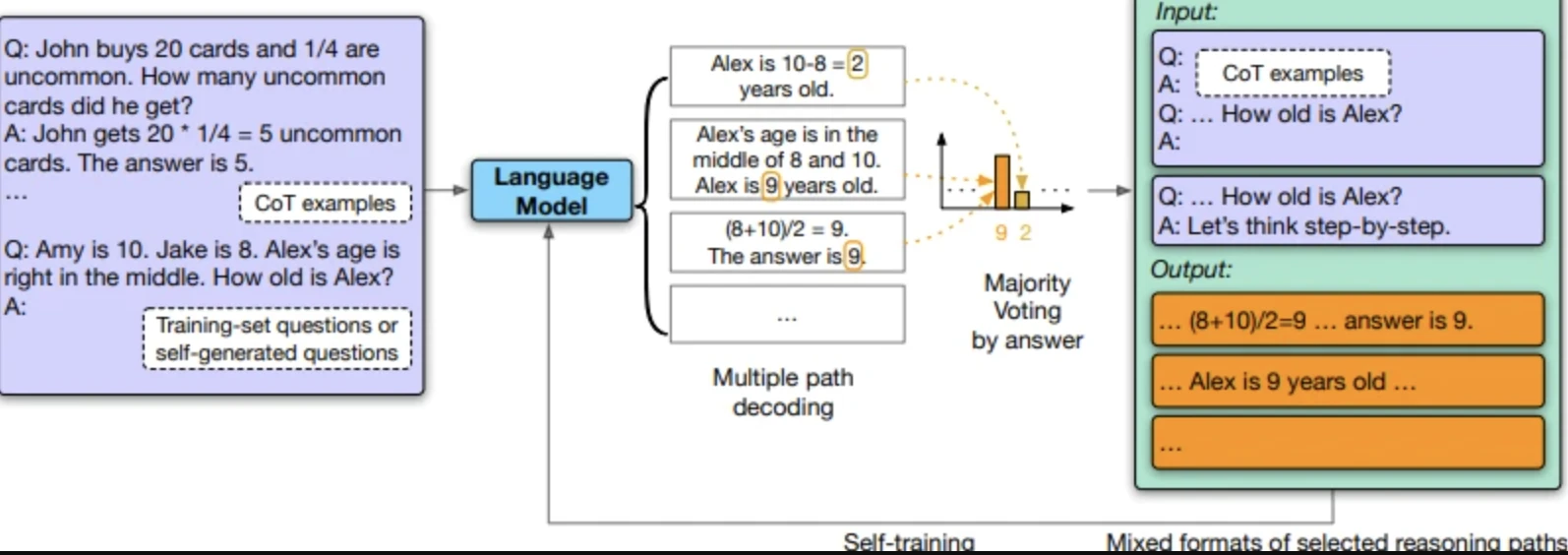
2- Dati di addestramento sintetici
I modelli generano i propri dataset di addestramento invece di richiedere dati etichettati da esseri umani.
Modello auto-migliorante di Google (ricerca 2023):
- Il modello crea domande
- Seleziona le risposte
- Si auto-raffina sui dati generati
Prestazioni migliorate: da 74.2% a 82.1% nei problemi matematici GSM8K, da 78.2% a 83.0% nella comprensione della lettura DROP.
OpenAI, Anthropic e Google stanno tutti utilizzando dati sintetici per integrare i dataset etichettati da esseri umani. Ciò riduce i costi di etichettatura dei dati ma introduce nuovi rischi di bias; i modelli possono amplificare i propri errori.
Fonte: “I grandi modelli linguistici possono auto-migliorarsi”
Un sondaggio di marzo 2026 ha rilevato che il 76% dei ricercatori di IA ritiene che i guadagni derivanti dal ridimensionamento del calcolo e dei dati abbiano raggiunto un plateau, con i principali laboratori che segnalano rendimenti decrescenti nonostante gli investimenti massicci. La scoperta suggerisce che il prossimo balzo in avanti nelle capacità degli LLM ha maggiori probabilità di derivare da innovazioni architetturali, come una migliore efficienza dell'addestramento, architetture sparse o miglioramenti del ragionamento, piuttosto che dal semplice ridimensionamento degli approcci esistenti.3
3- Modelli Esperti Sparse (Mixture of Experts)
Invece di attivare l'intera rete neurale per ogni input, solo un sottoinsieme rilevante di parametri viene attivato, a seconda del compito. Il modello indirizza l'input verso "esperti" specializzati all'interno della rete. Solo gli esperti attivati elaborano la query.
Esempi reali:
- Llama 4 Scout: 109B di parametri totali, 17B attivi per token. L'architettura Mixture of Experts (MoE) offre una finestra di contesto di 10M token su una singola H100 GPU.
- Mistral Devstral 2: Progettato appositamente per attività di ingegneria del software. 123B di parametri, finestra di contesto di 256K token. Raggiunge il 72.2% su SWE-bench Verified, affermandosi come il principale modello di codifica open-weight. Una variante più piccola, Devstral Small 2 (24B di parametri), funziona localmente su hardware consumer con licenza Apache 2.0.4
- Nel nostro A-CODE-LLM Bench, sia la variante base che quella thinking di DeepSeek V4 Pro hanno ottenuto un punteggio complessivo inferiore a 0.45, con tempi di completamento superiori a 1.700 secondi per attività. La capacità di programmazione agentica del modello è inferiore alle sue solide prestazioni nei benchmark a singola query, riflettendo probabilmente una minore maturità nell'uso degli strumenti rispetto ai modelli di frontiera di Anthropic e Google in questa fase.
4- Integrazione del flusso di lavoro aziendale
Gli LLM sono integrati direttamente nei processi aziendali anziché essere utilizzati come strumenti autonomi.
Esempi reali:
- Salesforce Agentforce (precedentemente Einstein Copilot): Integra gli LLM nelle operazioni CRM. Risponde alle domande dei clienti, genera contenuti ed esegue azioni in Salesforce, basandosi sui dati e metadati CRM dell'organizzazione tramite l'Einstein Trust Layer.5
- Microsoft 365 Copilot: Integrato in Word, Excel, PowerPoint e Outlook. Redige documenti, analizza fogli di calcolo, genera presentazioni e riassume thread di posta elettronica, attingendo ai dati aziendali tramite Microsoft Graph per fondare le risposte nel contesto organizzativo.6 L'agente Researcher utilizza un'architettura multi-modello in cui GPT gestisce la ricerca iniziale e Claude revisiona gli output prima della consegna, il primo deployment commerciale confermato di fornitori di IA concorrenti all'interno di un singolo prodotto aziendale.
- Anthropic Claude for Enterprise: La separazione della memoria basata su progetto mantiene distinti i contesti di lavoro tra i team. Claude Opus 4.6 ha introdotto i team di agenti, consentendo a più agenti Claude di suddividere compiti più grandi in flussi di lavoro paralleli, ciascuno con un segmento e coordinato con gli altri simultaneamente. La stessa release ha integrato Claude direttamente in PowerPoint come pannello laterale nativo (anteprima di ricerca), consentendo di creare e modificare presentazioni all'interno dell'applicazione senza trasferimenti di file.7
5- LLM ibridi con capacità multimodali
I grandi modelli multimodali integrano molteplici forme di dati, come testo, immagini e audio, consentendo loro di comprendere e generare contenuti su diversi tipi di media.
- Nel nostro A-CODE-LLM Bench, GPT 5.5 thinking ha ottenuto 0.597 con un tempo medio di completamento di 276 secondi, il modello più veloce sopra 0.50 in termini di tempo. Il costo API per cella era di $0.41–$0.45 per le varianti mini, circa un terzo del costo di Claude Sonnet 4.6 a intervalli di punteggio simili.
- Gemini 2.5 Pro: Gestisce nativamente testo, audio, immagini, video e interi repository di codice all'interno di una finestra di contesto di 1M token. Disponibile su Google IA Studio, Vertex IA e NotebookLM. I prezzi partono da $1.25 per milione di token di input e $10 per milione di token di output tramite API.8
- Llama 4 Scout e Maverick: I modelli open-weight di Meta utilizzano token multimodali testo e visione a fusion precoce, addestrati insieme fin dall'inizio anziché aggiunti come moduli separati. I modelli sono stati pre-addestrati in 200 lingue e hanno fornito supporto specifico per il fine-tuning in 12 lingue, tra cui arabo, spagnolo, tedesco e hindi.9
La capacità multimodale è standard tra i modelli di frontiera. La sfida rimanente è la coerenza: i modelli funzionano bene su combinazioni comuni di immagini e testo, ma degradano su contesti visivi rari, input a bassa risoluzione e ragionamento cross-modale che richiede di collegare prove visive e testuali.
6- Modelli di ragionamento
Modelli che ragionano sui problemi passo dopo passo anziché generare risposte immediate.
Questo passaggio dalla previsione al ragionamento è fondamentale per consentire:
- Comportamento agentico, in cui i modelli pianificano, eseguono e adattano i compiti in modo autonomo.
- IA interpretabile, in cui gli output sono passo dopo passo e logicamente validi, non solo plausibili.
- Claude Sonnet 4.6: L'attuale leader di produzione di Anthropic nei benchmark di codifica agentica, con un punteggio di 0.748 nell'A-CODE-LLM Bench di AIMultiple, al di sopra di ogni variante Opus. Utilizza il pensiero adattivo, in cui il modello determina dinamicamente la profondità del ragionamento in base alla complessità del compito senza richiedere il passaggio manuale della modalità. Il prezzo è di $3/$15 per milione di token. Su SWE-bench Verified, Sonnet 4.6 raggiunge il 79.6%, entro un punto dal 80.8% di Opus 4.7, a un quinto del costo.
- Claude Opus 4.7: Il fiore all'occhiello di Anthropic nel ragionamento complesso a più fasi e nella visione (98.5% sul benchmark di acuità visiva di XBOW, contro il 54.5% della generazione precedente). Prezzo di $5/$25 per milione di token. Nel benchmark di AIMultiple, Opus 4.7 ha ottenuto 0.61, al di sotto di Sonnet 4.6 (0.748) e Opus 4.8 (0.702), principalmente a causa della maggiore latenza (1.562 secondi medi per attività) che degrada i punteggi UI. Il divario rispetto a Sonnet si amplia nei compiti di ragionamento astratto come ARC-AGI-2.
- Claude Opus 4.8: Rilasciato dopo Opus 4.7, recuperando dalla regressione della codifica agentica di 4.7. Ha ottenuto 0.702 nell'A-CODE-LLM Bench, quinto in assoluto. Ha completato l'attività di base in 34 secondi, il modello più veloce del benchmark in quell'attività utilizzando solo 6 chiamate di strumenti. Prezzo: $2.92 per cella in condizioni di benchmark ($15/$75 per milione di token).
7- Modelli Fine-Tuned Specifici per Dominio
Modelli addestrati su dati specializzati per settori specifici anziché su addestramento generalista.
Google, Microsoft e Meta hanno tutti rilasciato importanti modelli proprietari specifici per dominio e fine-tuned mirati a casi d'uso aziendali, in aggiunta alle loro offerte generaliste.
Questi LLM specializzati possono comportare meno allucinazioni e una maggiore accuratezza sfruttando il pre-addestramento specifico per dominio, l'allineamento del modello e il fine-tuning supervisionato.
Programmazione
GitHub Copilot: Addestrato su repository di codice. A luglio 2025, 20 milioni di sviluppatori utilizzano GitHub Copilot, con un aumento del 400% anno su anno, e il 90% delle aziende Fortune 100 lo utilizza. Completa automaticamente il codice, genera funzioni e suggerisce correzioni di bug.10
Finanza
BloombergGPT: LLM da 50 miliardi di parametri addestrato su un dataset di 363 miliardi di token di documenti finanziari Bloomberg, superando modelli di dimensioni comparabili nei benchmark NLP finanziari, tra cui analisi del sentiment, riconoscimento di entità nominate e risposta a domande.11
Sanità
Med-PaLM 2 di Google: Addestrato su dataset medici, ha raggiunto una precisione superiore all'85% su domande in stile USMLE (United States Medical Licensing Examination), il primo LLM a raggiungere prestazioni di livello esperto su questo benchmark. Alimenta MedLM, la famiglia di modelli fondamentali per la sanità di Google Cloud.12
Legge
ChatLAW: Un modello linguistico open-source appositamente addestrato su dataset del dominio legale cinese.13
8- IA etica e mitigazione dei bias
Le aziende si stanno concentrando sempre di più sull'IA etica e sulla mitigazione dei bias nello sviluppo e nell'implementazione dei grandi modelli linguistici.
- Anthropic e OpenAI hanno condotto una valutazione reciproca dell'allineamento a metà del 2025, testando i rispettivi modelli pubblici per l'adulazione, le tendenze a denunciare e i comportamenti di autoconservazione. L'esercizio ha rilevato adulazione in tutti i modelli testati, compresi casi in cui i modelli convalidavano decisioni dannose da parte di utenti simulati che mostravano convinzioni deliranti. Anthropic ha successivamente sviluppato il framework di test Bloom specificamente per valutare questo comportamento nei nuovi modelli.
- Anthropic ha anche rilasciato Claude Mythos Preview (Project Glasswing), un modello solo su invito reso disponibile a un piccolo insieme di organizzazioni specificamente per trovare e correggere le vulnerabilità di sicurezza informatica nei principali sistemi operativi e browser web. Anthropic ha dichiarato che non intende rendere questo modello generalmente disponibile. L'approccio ad accesso controllato rappresenta un nuovo framework per l'implementazione di modelli specialistici altamente capaci laddove il profilo di rischio richiede un rilascio limitato.14
- Google DeepMind: Ha pubblicato “The Ethics of Advanced IA Assistants”, offrendo il primo trattamento sistematico delle questioni etiche e sociali sollevate dagli agenti di IA, coprendo l'allineamento dei valori, i rischi di manipolazione, l'antropomorfismo, la privacy e l'equità. La valutazione Responsible IA dell'azienda ha incluso oltre 350 esercizi di red-team avversari e ha introdotto un nuovo livello di capacità critica specificamente per la manipolazione dannosa, trattandola come un rischio di frontiera al pari degli attacchi informatici e delle minacce CBRN.
Limitazioni dei grandi modelli linguistici (LLMs)
1- Allucinazioni
I modelli generano informazioni plausibili ma errate.
La classifica delle allucinazioni di Vectara è il benchmark di riassunto fondato più ampiamente citato del settore. Sul dataset originale di Vectara, i modelli Gemini di Google occupano costantemente le prime posizioni, con le varianti Gemini Flash che raggiungono tassi di allucinazione inferiori al 1%. La famiglia GPT di OpenAI si raggruppa tra lo 0.8% e il 2.0%.
Vectara ha lanciato un benchmark significativamente più difficile alla fine del 2025: 7.700 articoli (rispetto ai 1.000 precedenti), documenti più lunghi fino a 32K token e contenuti che spaziano tra diritto, medicina, finanza e tecnologia. I risultati sul nuovo dataset rivelano uno schema controintuitivo: i modelli di ragionamento e di pensiero che eccellono nei compiti complessi allucinano spesso di più nel riassunto fondato rispetto ai modelli più piccoli e veloci. La maggior parte dei modelli di classe 'thinking' mostra tassi di allucinazione superiori al 10% sul dataset più difficile, mentre i modelli più leggeri come le varianti Gemini Flash mantengono tassi inferiori.15
Nota: Nessun singolo benchmark fornisce un "tasso di allucinazione" definitivo per alcun modello. Una valutazione responsabile incrocia almeno due benchmark che misurano cose diverse: un compito fondato (Vectara), un compito di conoscenza aperta e specifica la versione esatta del modello e le condizioni di chiamata.
Tutti i modelli allucinano. La frequenza si è ridotta sostanzialmente da circa il 21% nel 2021 a meno del 5% per i migliori risultati nei benchmark standard, ma non è stata eliminata. Le applicazioni critiche richiedono ancora la verifica umana.
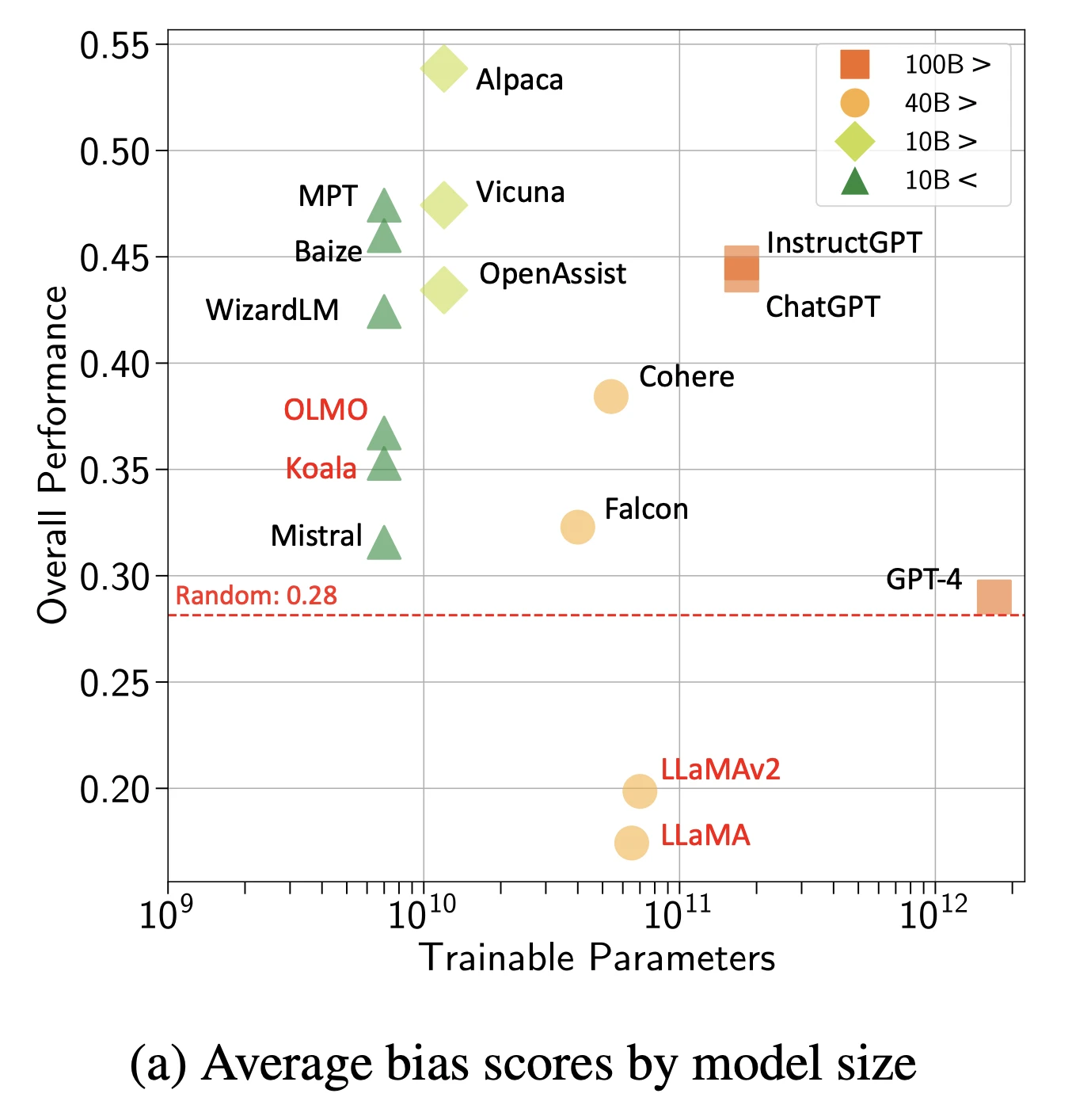
2- Bias
I modelli assorbono e amplificano i pregiudizi sociali dai dati di addestramento.
Figura: Punteggi di bias complessivi per modelli e dimensione
Fonte: Arxiv16
Tipi di bias osservati:
- Pregiudizi di genere nei suggerimenti di occupazione
- Pregiudizi razziali nelle simulazioni di screening dei curriculum
- Pregiudizi di età nelle raccomandazioni sanitarie
- Pregiudizi socioeconomici nei contenuti educativi
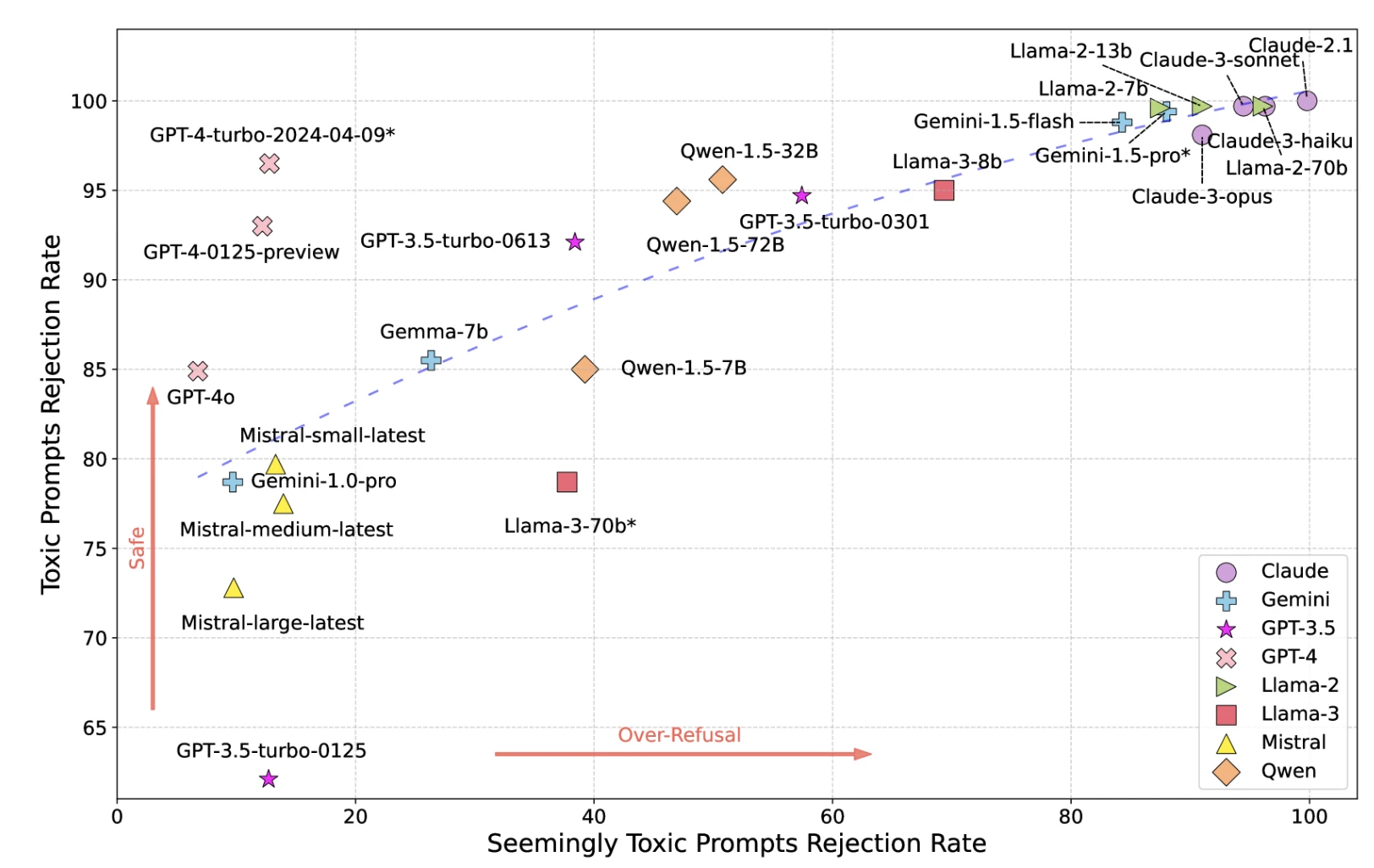
3- Tossicità
I modelli possono generare contenuti dannosi, offensivi o tossici nonostante le misure di sicurezza.
Figura: LLM mappa della tossicità
Fonte: Ricercatori di UCLA, UC Berkeley17
*GPT-4-turbo-2024-04-09*, Llama-3-70b* e Gemini-1.5-pro* vengono utilizzati come moderatore, i risultati potrebbero essere influenzati da questi 3 modelli.
Le misure di sicurezza rigorose riducono la tossicità ma aumentano i falsi positivi (rifiuto di richieste innocue). Le misure permissive consentono il passaggio della tossicità.
4- Limitazioni della Finestra di Contesto
Ogni modello ha una capacità di memoria fissa, il numero di token che può elaborare in una singola sessione. Superato quel limite, il modello tronca i contenuti precedenti o rifiuta la richiesta. Il divario pratico tra i modelli è abbastanza ampio da essere rilevante per i carichi di lavoro reali.
Finestre di contesto più recenti:
- Llama 4 Scout (Meta): 10M token (~7.5M parole), la più ampia finestra di contesto verificata in produzione tra i modelli leader.18 In pratica, ciò significa caricare interi codebase, archivi legali o cronologie di conversazioni di più giorni senza suddivisioni.
- Gemini 2.5 Pro: 1,048,576 token (~780,000 parole), con input multimodale nativo su testo, audio, immagini e video all'interno della stessa finestra. Il richiamo si mantiene al 100% fino a 530,000 token e al 99.7% al limite completo di 1 milione di token
- Claude Sonnet 4.6: 1M token (~750,000 parole) a prezzo standard, disponibile senza intestazioni beta o configurazioni speciali.19
- GPT-5.5: finestra di contesto di 1M token a livello API.20
Una grande finestra di contesto non significa automaticamente migliori prestazioni su tutta la sua lunghezza. Il richiamo si degrada verso la metà di contesti molto lunghi nella maggior parte dei modelli e i costi aumentano con la lunghezza dell'input: elaborare 1M token costa significativamente di più che elaborare 10K token sullo stesso modello. Per la maggior parte dei carichi di lavoro di produzione, la domanda pratica non è quale modello abbia la finestra più grande, ma quale modello recuperi in modo affidabile alle lunghezze di contesto effettivamente richieste dal tuo caso d'uso.
5- Cutoff di Conoscenza Statico
I modelli si basano sulla conoscenza pre-addestrata con una data di cutoff specifica. Non hanno accesso alle informazioni successive all'addestramento a meno che non siano collegati a fonti esterne.
Problemi:
- Informazioni obsolete sugli eventi attuali
- Incapacità di gestire gli sviluppi recenti
- Minore rilevanza nei domini dinamici (tecnologia, finanza, medicina)
Soluzione: Integrazione della ricerca web. ChatGPT, Claude e Perplexity offrono tutti la ricerca in tempo reale. Ma la ricerca non elimina le allucinazioni; a volte i modelli interpretano male i risultati della ricerca.
Principali piattaforme LLM
GPT-5.5
Il fiore all'occhiello attuale di OpenAI è stato rilasciato il 23 aprile 2026. Costruito attorno a uno sforzo di ragionamento configurabile, gli sviluppatori impostano la profondità di pensiero per richiesta (da none a xhigh), in modo che le query semplici non consumino risorse computazionali riservate a problemi complessi. Il modello eccelle nella codifica agentica, nell'uso del computer e nei compiti a lungo termine in cui deve mantenere il contesto su sistemi di grandi dimensioni e verificare il proprio lavoro durante l'esecuzione.21
Chi lo utilizza: Sviluppatori, aziende e creatori di contenuti. La più ampia base di utenti tra gli LLM.
Limitazioni: $5/$30 per milione di token, il prezzo base più alto in questo elenco. Allucina ancora. Richiede l'integrazione della ricerca web per qualsiasi cosa dopo il cutoff di addestramento.
Claude Opus 4.8 / Sonnet 4.6
Claude Sonnet 4.6 guida l'A-CODE-LLM Bench di AIMultiple con un punteggio complessivo di 0.748 a $1.26–$1.33 per cella, al di sopra di ogni variante Opus testata. Claude Opus 4.8 segue a 0.702, riprendendosi dalla regressione di Opus 4.7 (0.61) a $2.92 per cella. Opus 4.7 rimane il miglior performer nei compiti complessi di ragionamento a più fasi e visione (98.5% sul benchmark di acuità visiva di XBOW), ma il suo tempo medio di completamento di 1.562 secondi nei flussi di lavoro agentici porta il costo totale a $3.08 per cella, il modello più costoso del benchmark.
Sia Sonnet 4.6 che le varianti Opus utilizzano il pensiero adattivo: il modello determina la profondità del ragionamento in base alla complessità del compito senza richiedere un cambio manuale di modalità. Sonnet 4.6 ha effettuato il minor numero di chiamate di strumenti per attività tra i modelli Anthropic (51 base, 48 thinking), raggiungendo il punteggio più alto del benchmark con meno iterazioni rispetto alle varianti Opus (56–70 chiamate di strumenti). I team di agenti, disponibili sulla linea di produzione di Anthropic, consentono a più istanze di Claude di suddividere un compito in flussi di lavoro paralleli coordinati in tempo reale.
Chi lo utilizza: Sviluppatori e aziende che eseguono codifica agentica, flussi di lavoro di ricerca o pipeline multi-agente. I team che danno priorità all'efficienza dei costi utilizzano Sonnet 4.6; i team che eseguono carichi di lavoro pesanti sulla visione o sul ragionamento complesso utilizzano Opus 4.7.
Limitazioni: Il pensiero esteso è più lento e più costoso per token. Il divario di prestazioni rispetto a Sonnet si amplia nei compiti di ragionamento astratto (ARC-AGI-2). Opus 4.8 ha un prezzo di $15/$75 per milione di token.
Gemini 3.5 Flash
Gemini 3.5 Flash thinking ha ottenuto 0.625, il risultato non-Anthropic più alto a $1.30 per cella e 390 secondi medi di completamento. La variante base ha ottenuto un punteggio inferiore al thinking a un costo più elevato ($0.56 per cella di base), a causa della sovrascrittura (131 righe per un'attività la cui soluzione di riferimento è di circa 50 righe).
Llama 4 Scout
Il modello MoE open-weight di Meta. 109B parametri totali, 17B attivi per token, funziona su una singola NVIDIA H100 GPU con quantizzazione int4. L'implicazione pratica è che una finestra di contesto di 10M token è accessibile senza un contratto con un data center.22 La multimodalità a fusion precoce significa che testo e visione vengono elaborati congiuntamente dal primo strato anziché combinati nella fase di output. Disponibile con la licenza Llama 4 Community di Meta.
Chi lo utilizza: Ricercatori, organizzazioni che necessitano di deployment on-premise, sviluppatori che evitano il vendor lock-in e team in cui i costi su larga scala rendono i prezzi delle API insostenibili.
Limitazioni: Le prestazioni dipendono fortemente dalla configurazione dell'hosting e dalle scelte di quantizzazione. Richiede investimenti in infrastrutture e capacità di ML ops. Meno rifiniture di produzione rispetto ai modelli commerciali.
DeepSeek V4
Il modello di quarta generazione di DeepSeek è disponibile in anteprima. Utilizza un'architettura MoE da 1 trilione di parametri, circa il 50% più grande di V3, con capacità multimodali su testo, immagini e video. Il 'Thinking in Tool-Use' consente al modello di ragionare internamente prima di chiamare strumenti esterni e verificare i risultati degli strumenti rispetto alla propria logica, che rappresenta il principale elemento di differenziazione per i flussi di lavoro agentici. Il prezzo di input delle API parte da $0.27 per milione di token (cache-miss), circa 18x più economico di GPT-5.5.23
FAQ
Un grande modello linguistico è un modello di IA progettato per generare e comprendere testo simile a quello umano analizzando grandi quantità di dati.
Questi modelli fondamentali si basano su tecniche di apprendimento profondo e coinvolgono tipicamente reti neurali con molti strati e un gran numero di parametri, consentendo loro di catturare modelli complessi nei dati su cui sono addestrati.
Cita questa ricerca
Scegli il formato adatto a dove pubblicherai. Incollare la versione con link nel tuo CMS preserva il backlink.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Sezer, Sena},
title = {{Il futuro dei grandi modelli linguistici}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/future-of-large-language-models}},
note = {AIMultiple. Consultato il 25 Giugno 2026}
}
Sii il primo a commentare
Il tuo indirizzo email non verrà pubblicato. Tutti i campi sono obbligatori. I commenti vengono lasciati nella loro lingua originale.