LCM: dalla tokenizzazione LLM alla rappresentazione a livello di concetto
I modelli concettuali di grandi dimensioni (LCM) , come introdotti da Meta nel loro lavoro sui “Large Concept Models”, rappresentano un cambiamento fondamentale che si allontana dalla predizione basata sui token per avvicinarsi alla rappresentazione a livello di concetto . 1
I modelli LCM si differenziano dai modelli LLM tradizionali in due aspetti fondamentali:
- Spazio di embedding ad alta dimensionalità: anziché lavorare con sequenze di token discrete, gli LCM eseguono tutta la modellazione direttamente nello spazio di embedding ad alta dimensionalità.
- Astrazione a livello concettuale: la modellazione viene eseguita a livello di concetti semantici e astratti, non all'interno di una lingua o modalità specifica. Questo rende i modelli LCM intrinsecamente indipendenti dalla lingua e dalla modalità.
Dalla ricerca di Meta, 2 Esploreremo i componenti principali degli LCM e il loro potenziale nella ricerca semantica e nel ragionamento, sulla base dei seguenti benchmark:
Comprendere i limiti dei modelli di apprendimento basati su logica: dai token ai concetti
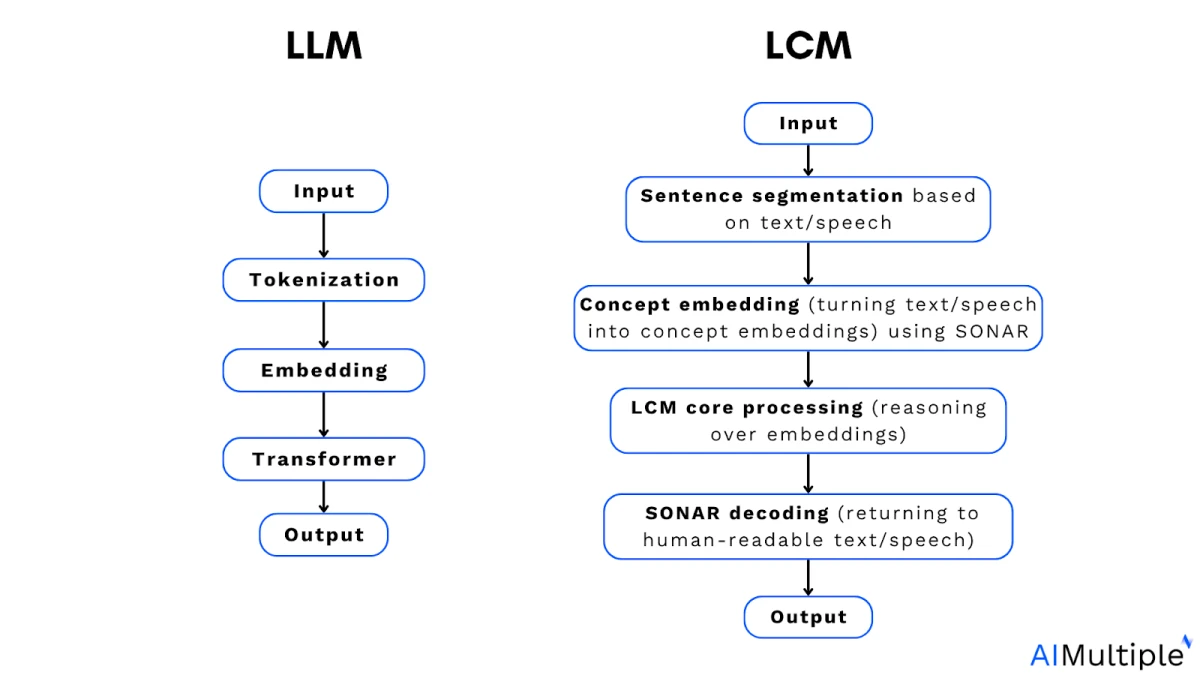
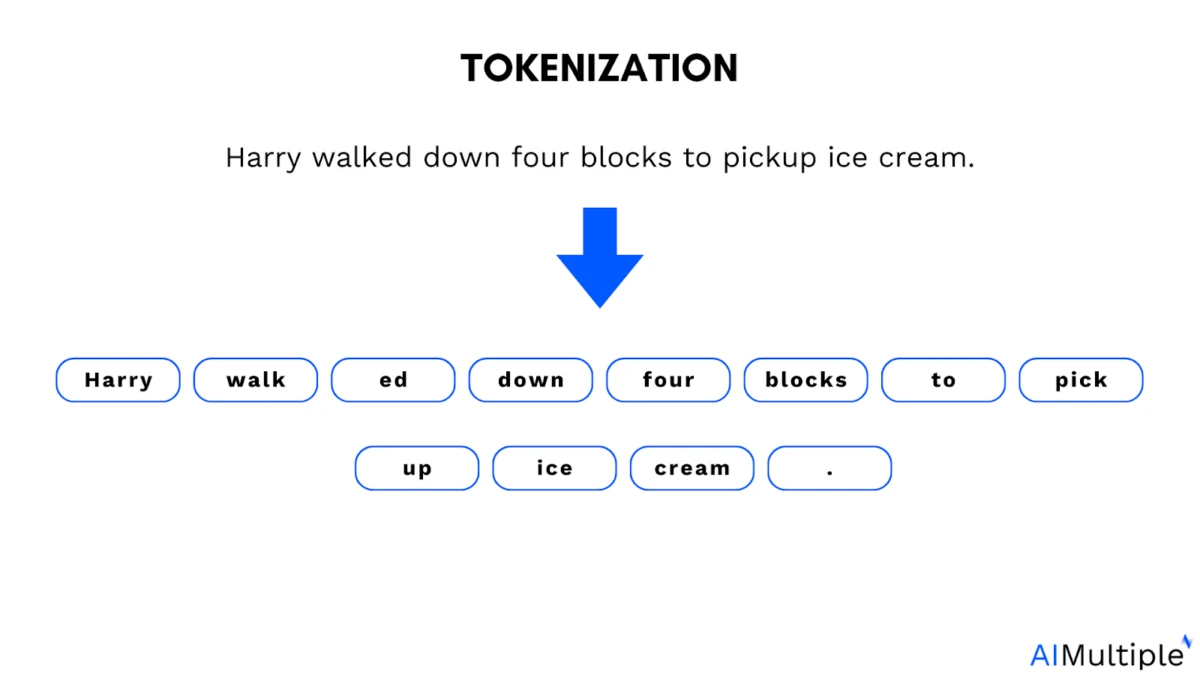
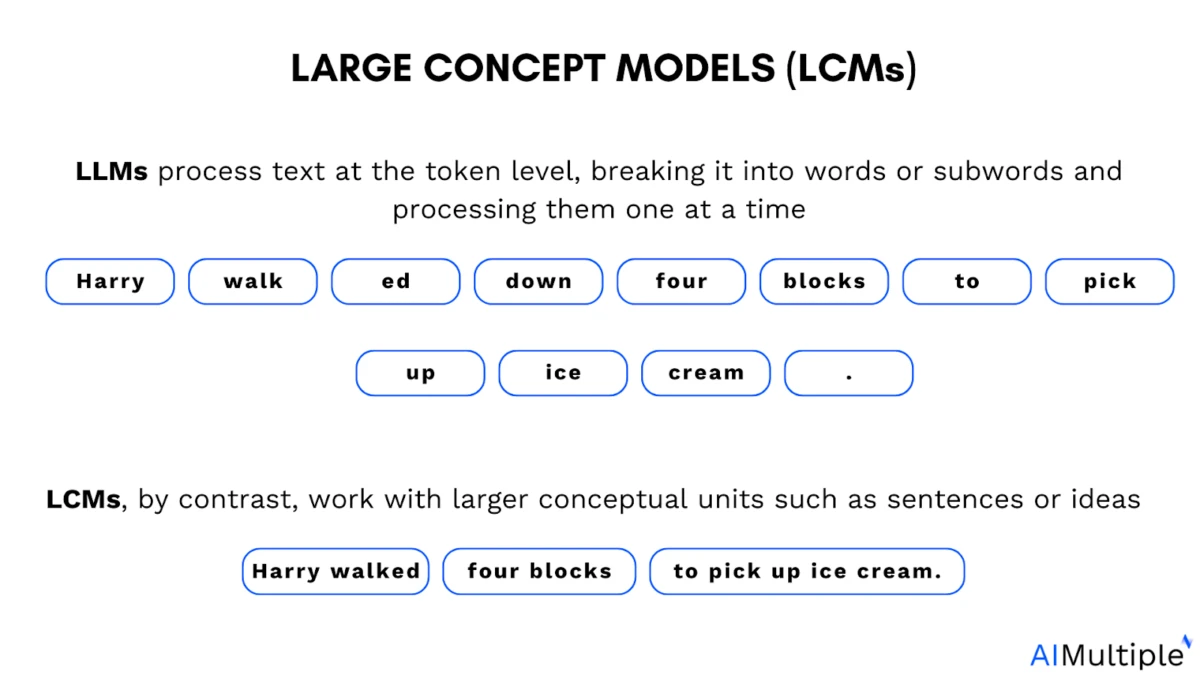
Il ruolo della tokenizzazione nei modelli linguistici di grandi dimensioni (LLM): i modelli linguistici di grandi dimensioni (LLM) vengono addestrati sui token. I token sono piccoli segmenti di testo. Possono essere parole intere, parti di parole o persino singoli caratteri che il modello elabora come unità.
Esempio di tokenizzazione:
Il problema
La tokenizzazione aiuta i modelli a scomporre il linguaggio in parti gestibili, ma introduce anche un vincolo. La maggior parte dei modelli linguistici basati sul linguaggio (LLM) opera su sequenze di token discreti (ad esempio, sottoparole di testo; token visivi/audio prodotti dai codificatori).
I modelli di apprendimento per rinforzo (LLM) possono integrare diverse modalità, tuttavia il loro obiettivo principale e la loro rappresentazione rimangono vincolati alla sequenza , il che rende più difficile modellare il significato direttamente a livello concettuale .
I risultati ottenuti da Cognition.ai con Sonnet 4.5 lo dimostrano chiaramente: il modello percepisce quando la sua finestra di contesto è quasi piena, trae conclusioni affrettate e segnala persino i token rimanenti, sebbene in modo impreciso. 3
La soluzione (Concetti)
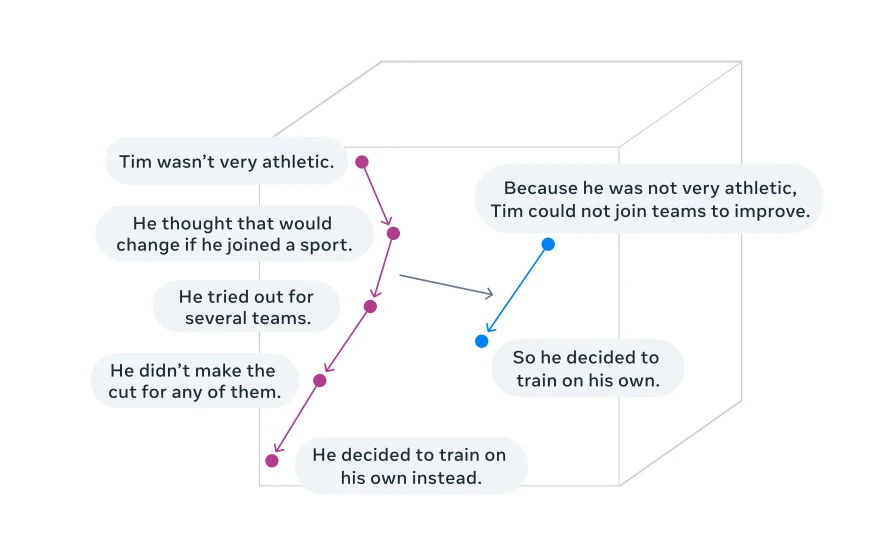
Visualizzazione del ragionamento in uno spazio di immersione dei concetti (compito di riassunto) 4
I concetti si riferiscono a rappresentazioni di significato di ordine superiore . A differenza dei token, non sono legati ad alcuna unità linguistica specifica e possono essere derivati da testo o parlato, quindi il processo di ragionamento rimane lo stesso.
Ciò consente di:
- Migliore gestione di contesti lunghi grazie al ragionamento su idee complete anziché su frammenti.
- Si tratta di un ragionamento più astratto, poiché le operazioni vengono eseguite a livello di significato.
- Processo indipendente dalla lingua e dalla modalità per gestire attività multilingue e multimodali senza la necessità di pipeline di elaborazione separate per ogni tipo di input.
Che cosa sono i modelli concettuali di grandi dimensioni?
Al contrario, i modelli concettuali di grandi dimensioni (LCM) mirano a rappresentare e ragionare sui concetti semantici in uno spazio di embedding continuo, non vincolato ad alcuna lingua o modalità specifica.
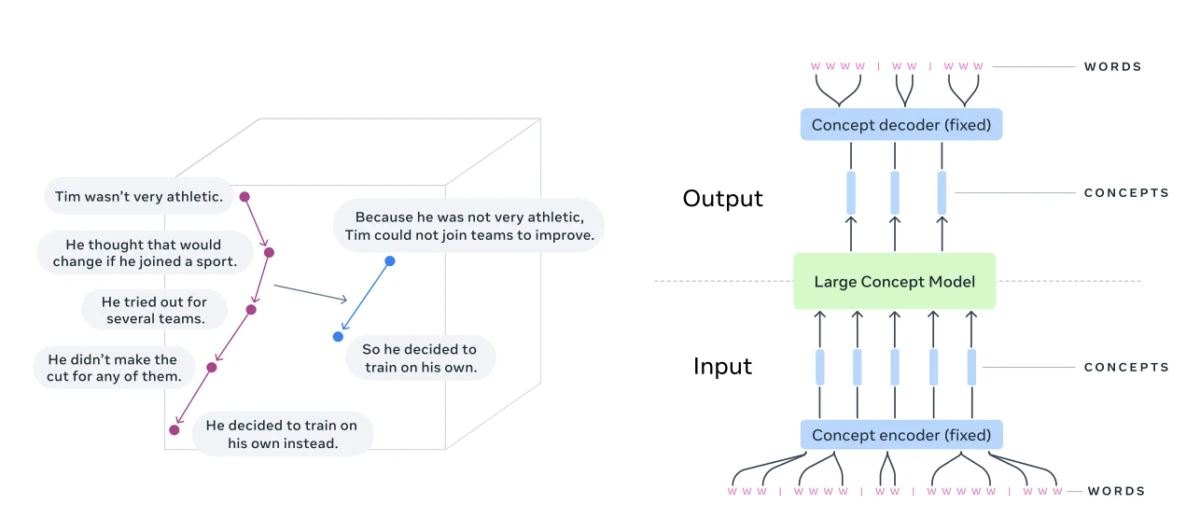
Architettura fondamentale di un modello concettuale di grandi dimensioni (LCM):
Fonte: Meta 5
Componenti principali dei LCM
1. Codifica SONAR (trasformazione di testo o parlato in rappresentazioni concettuali)
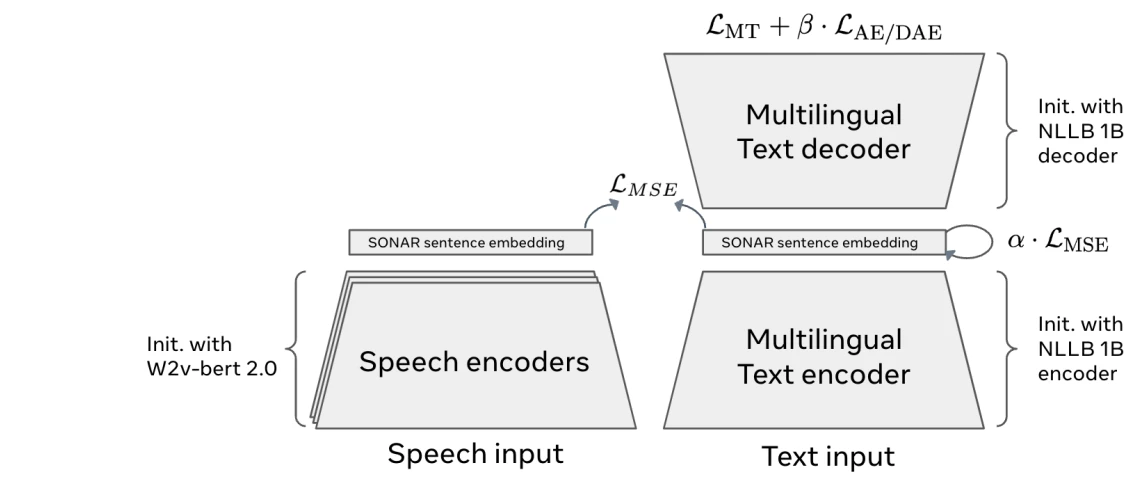
Architettura SONAR 6
La prima fase di un modello concettuale di grandi dimensioni (LCM) è il codificatore di concetti , che converte il testo o il parlato in uno spazio di embedding condiviso. Invece di suddividere l'input in token, rappresenta intere frasi come embedding matematici che ne catturano il significato.
I sistemi LCM utilizzano SONAR , uno spazio di embedding multilingue e multimodale che supporta oltre 200 lingue testuali e 76 per il parlato.
Ad esempio, le frasi "I love you" in inglese e "Te quiero" in spagnolo sono posizionate vicine in questo spazio perché esprimono la stessa idea. Operando a questo livello concettuale, i modelli LCM (Learning Content Models) acquisiscono inclusività, efficienza e scalabilità che vanno oltre i modelli basati su token.
Perché SONAR è migliore dei metodi di embedding tradizionali?
Metodi tradizionali:
- mBERT : Fornisce embedding multilingue, ma non sono allineati in modo coerente a livello di frase , rendendo meno efficaci le attività interlinguistiche.
Vantaggi del sonar:
- Indipendente dalla lingua : oltre 200 lingue per l'input e l'output di testo (basato sul progetto No Language Left Behind di Meta). 76 lingue per l'input vocale e inglese per l'output vocale.
- Allineamento interlinguistico : le frasi con lo stesso significato appaiono vicine, indipendentemente dalla lingua.
- Ragionamento di livello superiore : Poiché le unità sono frasi (o concetti), i modelli possono svolgere compiti come la sintesi o la traduzione manipolando direttamente le idee.
- Traduzione zero-shot : consente di tradurre tra lingue e modalità diverse senza necessità di addestramento specifico per ogni coppia .
LLM vs LCM
2. Elaborazione di base LCM (ragionamento sugli embedding)
Il nucleo di LCM è la fase di ragionamento, in cui il modello genera nuovi concetti basandosi sul contesto. A differenza dei modelli LLM, che prevedono un token alla volta, il nucleo di LCM prevede intere frasi o concetti , operando a un livello semantico superiore.
La sfida consiste nel produrre rappresentazioni continue condizionate dal contesto. I modelli lineari lineari (LLM) generano distribuzioni di probabilità su token discreti, mentre i modelli lineari co-localizzati (LCM) devono generare direttamente vettori che catturino il significato.
Per affrontare questo problema, i ricercatori hanno proposto diversi approcci, tra cui:
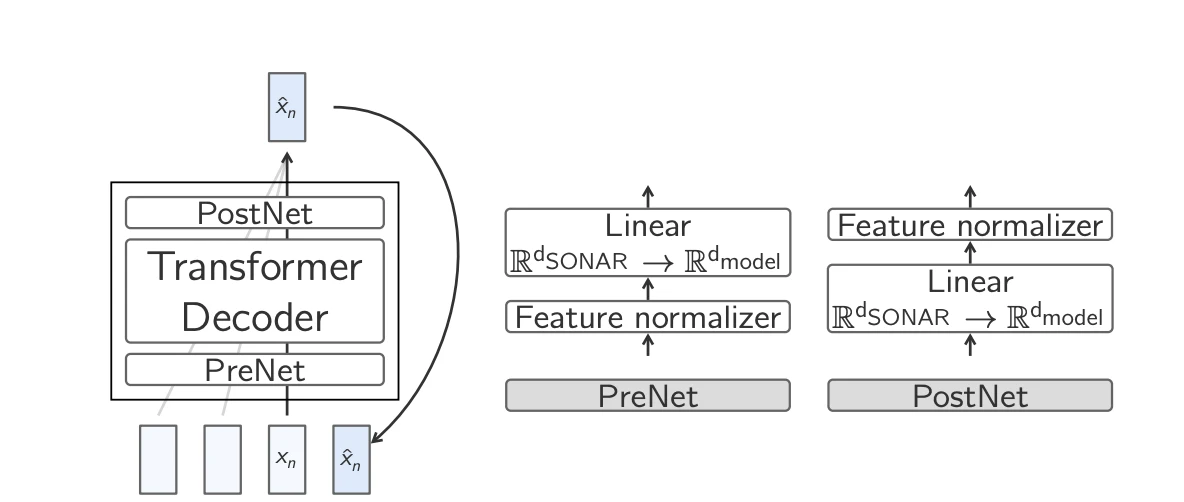
- Base-LCM: Previsione standard dell'embedding tramite Transformer: Il metodo più semplice consiste nell'addestrare un Transformer per prevedere direttamente l'embedding successivo, minimizzando la perdita dell'errore quadratico medio (MSE) . Sebbene efficace in linea di principio, questo approccio presenta delle difficoltà perché un dato contesto può portare a molteplici continuazioni valide, ma semanticamente distinte.
Base-LCM 7
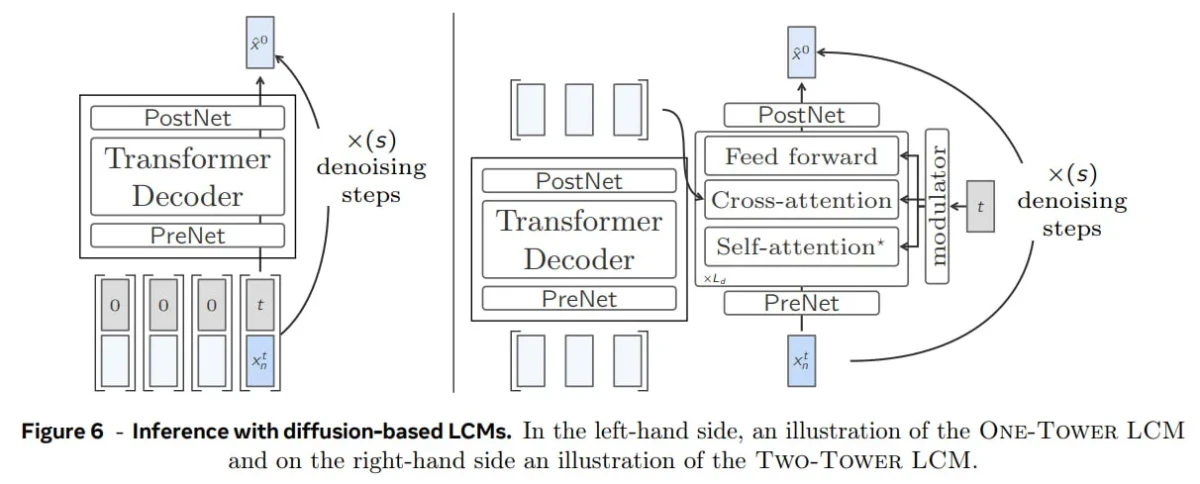
- LCM basato sulla diffusione: Variazioni strutturali per la contestualizzazione e la riduzione del rumore: Ispirata alla generazione di immagini, questa variante utilizza un processo di diffusione . Genera in modo autoregressivo i concetti, uno alla volta, eseguendo passaggi di riduzione del rumore per ciascun concetto generato.
- Struttura a torre singola: un singolo stack Transformer gestisce sia la contestualizzazione che la riduzione del rumore, mantenendo il design efficiente e compatto.
- Architettura a due torri: suddivide il processo in due parti: un contestualizzatore per comprendere il contesto e un denoiser per perfezionare gli embedding, offrendo maggiore flessibilità a scapito della complessità.
- LCM quantizzato: embedding discretizzati: un'altra opzione è quella di discretizzare gli embedding in unità simboliche più grandi. Questo rende il compito più simile a quello dei LLM, dove il modello genera elementi discreti, ma qui i "token" rappresentano porzioni di significato molto più grandi e semanticamente più ricche.
3. Decodifica SONAR (riconversione in testo o parlato comprensibile all'uomo)
La fase finale di un LCM è il decodificatore di concetti , che trasforma gli embedding astratti in testo o parlato naturale.
Poiché i concetti sono memorizzati in uno spazio di embedding condiviso , possono essere decodificati in qualsiasi linguaggio o modalità supportati senza dover ripetere il processo di ragionamento.
Questo design indipendente dalla lingua significa che un LCM potrebbe ricevere input in tedesco, ragionare in termini di concetti e produrre output in giapponese. Consente inoltre una facile scalabilità: è possibile aggiungere nuovi codificatori o decodificatori (ad esempio per il linguaggio dei segni o per i sistemi di riconoscimento vocale) senza dover riaddestrare l'intero modello.
Mantenendo separata la fase di "pensiero" da quella di espressione, il decodificatore garantisce che i modelli LCM rimangano flessibili e adattabili ad applicazioni multilingue e multimodali.
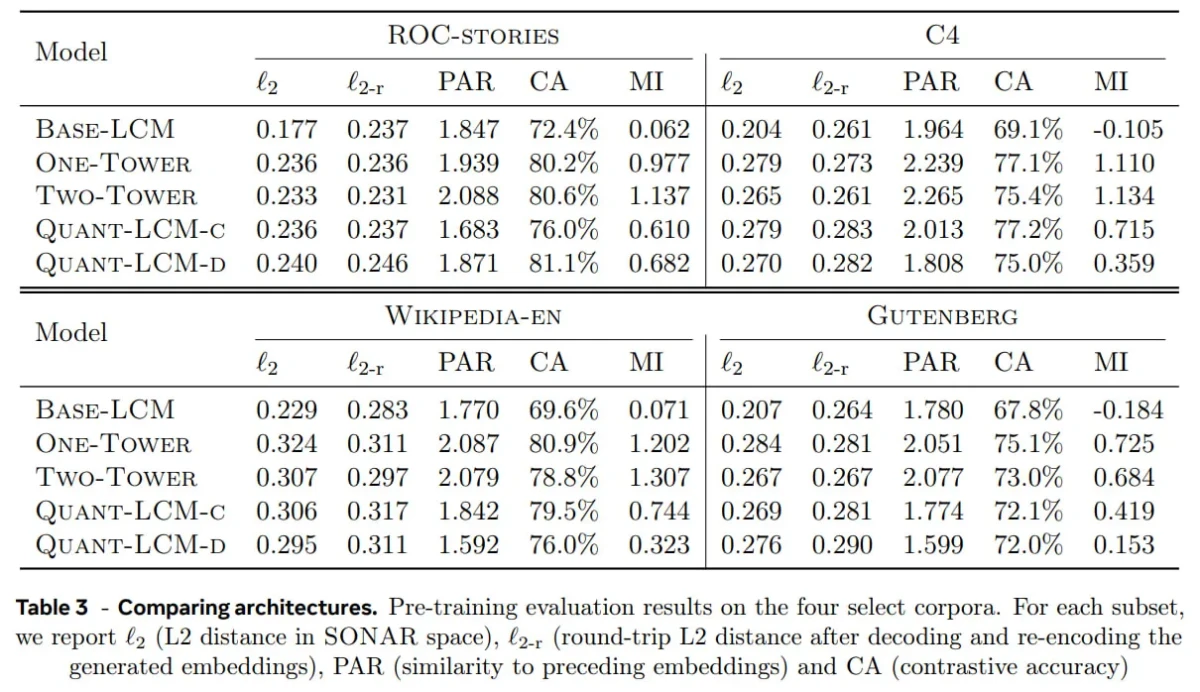
Analisi comparativa delle architetture LCM
Meta ha pre-addestrato modelli LCM sul dataset FineWeb-Edu (solo in inglese) e li ha valutati su quattro benchmark:
- ROC-Stories (ragionamento narrativo),
- C4 (testo in scala web),
- Wikipedia-en (conoscenza enciclopedica),
- Gutenberg (testo esteso).
Questi set di dati sono stati scelti per includere diverse tipologie di testo, da brevi narrazioni a grandi basi di conoscenza e documenti estesi.
Punti chiave:
I modelli LCM basati sulla diffusione (QUANT-LCM-C, QUANT-LCM-D) sono i più performanti . Il loro processo iterativo di riduzione del rumore si è dimostrato più efficace nella modellazione delle continuazioni concettuali, portando a una maggiore accuratezza semantica e coerenza.
Come interpretare i dati di riferimento:
- ℓ₂, ℓ₂-r: Minore = incorporamenti più accurati e coerenti.
- PAR: La via di mezzo è la soluzione migliore, mostra coerenza senza collasso.
- CA: Più alto = migliore allineamento semantico.
- MI: Più alto = risultati più informativi.
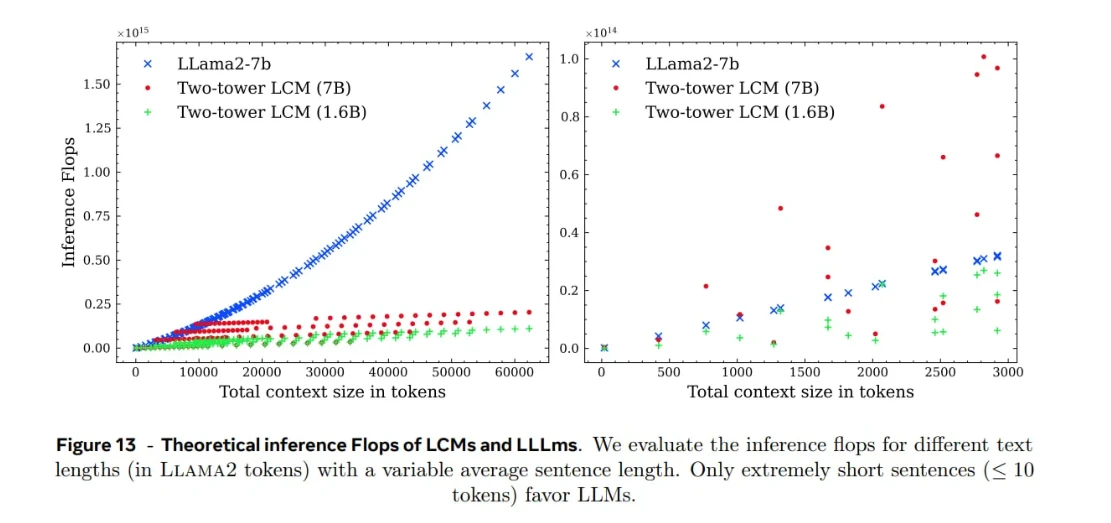
Valutazione comparativa dell'efficienza del ciclo di vita
Gli esperimenti di Meta hanno dimostrato che i modelli LCM scalano bene con la lunghezza del contesto rispetto ai modelli LLM quando gestiscono la stessa quantità di testo. Questo vantaggio deriva dal fatto che un concetto corrisponde a una frase completa , che include più token. Poiché ci sono meno concetti che token, il modello ha meno unità da elaborare e l'attenzione quadratica diventa meno impegnativa.
Punti chiave:
È importante notare che questi miglioramenti in termini di efficienza dipendono fortemente da come il testo viene segmentato in frasi . La suddivisione dei paragrafi in frasi più brevi o più lunghe influirà sul numero di concetti e, di conseguenza, sul carico computazionale.
Ogni inferenza LCM prevede anch'essa tre fasi:
- Codifica SONAR (testo o parlato: embedding)
- Ragionamento Transformer-LCM (elaborazione degli embedding)
- Decodifica SONAR (embedding: testo o parlato)
Questa pipeline introduce un overhead, soprattutto per input di breve lunghezza:
Per frasi brevi (meno di ~10 token), i modelli LLM possono essere più efficienti dei modelli LCM, poiché le fasi di codifica e decodifica superano i vantaggi dell'elaborazione a livello di concetto.
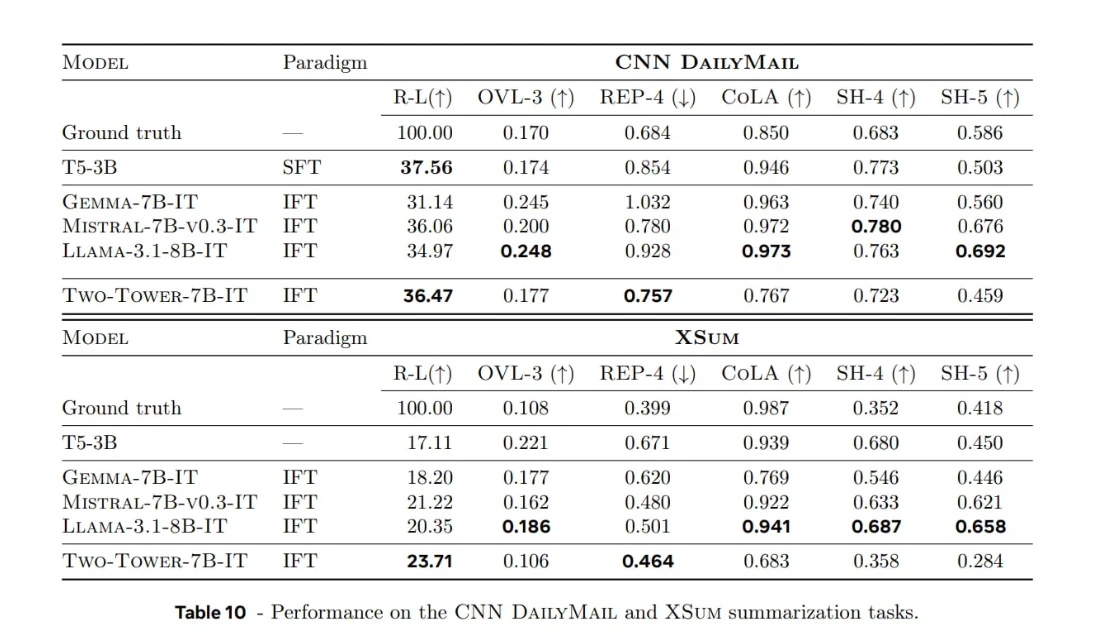
LCM contro LLM tradizionali nei compiti di riassunto
Meta ha inoltre effettuato un benchmark di un LCM basato sulla diffusione (7B parametri) su set di dati di riassunto di notizie (ad esempio, CNN/DailyMail, XSum) e lo ha confrontato con i modelli lineari lineari tradizionali.
Descrizione dei paradigmi:
- SFT : formazione specializzata su esempi di riassunto.
- IFT : addestramento più ampio su set di dati di istruzioni, in modo che il modello impari la sintesi come una delle tante abilità.
Descrizione dei parametri:
- ROUGE-L : Sovrapposizione con i riepiloghi di riferimento.
- OVL-3 : Rapporto di sovrapposizione dei trigrammi di input, che misura la ridondanza dal testo sorgente.
- REP-4 : Rapporto di ripetizione di quattro grammi in uscita, che misura la ripetizione nei riepiloghi generati.
- Indicatori SEAHORSE per il quarto e quinto trimestre : misure di qualità e coerenza.
- Classificatore basato su CoLA : Valutazione dell'accettabilità linguistica delle frasi generate.
Punti chiave:
Forza:
- Il modello LCM di diffusione dimostra una forte coerenza e un allineamento contestuale nella sintesi di testi lunghi, soprattutto quando si elaborano contesti ampi.
Avvertenze e considerazioni:
- La valutazione si concentra principalmente su attività generative (come la sintesi di informazioni) piuttosto che su parametri di riferimento generali come l'MMLU.
- Il modo in cui i paragrafi vengono suddivisi in frasi (ad esempio, come si definiscono i "concetti") influisce notevolmente sulle prestazioni.
- In termini di fluidità linguistica e accettabilità, i modelli linguistici basati su token come LLaMA-3.1-8B e Mistral-7B mantengono ancora un vantaggio. Sebbene i modelli LCM si dimostrino promettenti, non offrono ancora miglioramenti evidenti in tutte le metriche, soprattutto in termini di fluidità o flessibilità.
Cita questa ricerca
Scegli il formato adatto a dove pubblicherai. Incollare la versione con link nel tuo CMS preserva il backlink.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{LCM: dalla tokenizzazione LLM alla rappresentazione a livello di concetto}},
year = {2026},
month = jan,
howpublished = {\url{https://aimultiple.com/large-concept-models}},
note = {AIMultiple. Retrieved Gennaio 23, 2026}
}

Sii il primo a commentare
Il tuo indirizzo email non verrà pubblicato. Tutti i campi sono obbligatori. I commenti vengono lasciati nella loro lingua originale.