I Migliori Strumenti di Riconoscimento Immagini a Confronto
Abbiamo confrontato le configurazioni predefinite delle API di Amazon Rekognition, Google Cloud Vision e Microsoft Azure IA Vision su 100 immagini in 5 classi di oggetti e abbiamo confrontato i loro prezzi e la copertura delle funzionalità.
Risultati del benchmark degli strumenti di riconoscimento immagini
Panoramica delle prestazioni a IoU=0.5
Sono state valutate le metriche di prestazione per tre piattaforme di riconoscimento immagini a una soglia di Intersection over Union (IoU) di 0.5, confrontando i valori di mAP, punteggio F1, richiamo e precisione.
Il mAP è la metrica di valutazione principale da considerare per le attività di rilevamento oggetti, poiché fornisce una misura completa della qualità del rilevamento attraverso diverse soglie di confidenza e classi di oggetti.
Puoi saperne di più sulla nostra metodologia di benchmark.
Precisione Media per Classe (AP) a IoU=0.5
Tutti e tre i servizi rilevano le persone in modo affidabile ma perdono precisione sui dispositivi di protezione, con i caschi che mostrano il calo più marcato.
Mentre Amazon e Google mostrano una bassa precisione nel rilevamento di guanti e cappelli, Microsoft Azure IA Vision raggiunge una precisione dello 0% per entrambe le categorie. Azure IA Vision non rileva oggetti piccoli (meno del 5% dell'immagine) o disposti molto vicini tra loro, il che potrebbe contribuire alla bassa precisione osservata nel rilevamento di guanti e cappelli.1
Nessuno dei servizi è in grado di rilevare con successo le maschere (precisione dello 0%), evidenziando una lacuna critica nelle loro capacità di riconoscimento oggetti quando vengono utilizzati con impostazioni predefinite senza etichettatura personalizzata.
Puoi saperne di più sulle limitazioni del riconoscimento immagini.
mAP a diverse soglie IoU [0.5:0.05:0.95]
Man mano che le soglie IoU si restringono da 0.5 a 0.95, il mAP diminuisce per tutti e tre i servizi, ma a tassi diversi. Amazon Rekognition resiste meglio su tutto l'intervallo, suggerendo un allineamento dei riquadri di delimitazione più preciso rispetto agli altri due servizi.
Potenziali fattori che influenzerebbero le differenze di prestazione
Focus dell'addestramento del modello e ambito del prodotto
- Amazon Rekognition include funzionalità dedicate ai DPI, che probabilmente si traducono in una migliore copertura di addestramento e rappresentazioni delle caratteristiche per oggetti come caschi e guanti.
- Google Cloud Vision e Azure IA Vision danno priorità alle attività generali di comprensione delle immagini (ad es., OCR, punti di riferimento, marchi, rilevamento web), rendendo i DPI e oggetti simili secondari nei loro obiettivi di addestramento.
Configurazione predefinita delle API e compromessi precisione-richiamo
- Tutti i servizi sono stati valutati utilizzando le impostazioni predefinite, che in genere danno priorità all'elevata precisione per ridurre al minimo i falsi positivi.
- Questa scelta progettuale porta a punteggi di precisione elevati tra i fornitori ma a un richiamo significativamente inferiore, in particolare per gli oggetti meno prominenti.
Limitazioni del rilevamento di oggetti piccoli
- Oggetti come guanti, cappelli e caschi spesso occupano una piccola frazione dell'immagine, rendendoli difficili da rilevare in modo affidabile.
- Azure IA Vision, che è documentato per avere prestazioni inferiori su oggetti piccoli o ravvicinati, mostra il degrado più pronunciato in queste categorie.
Tassonomia delle etichette e mappatura della valutazione
- Le etichette specifiche del fornitore dovevano essere mappate a una tassonomia unificata di verità di riferimento.
- I rilevamenti validi che utilizzano etichette non corrispondenti o più granulari potrebbero essere stati esclusi dalla valutazione.
Assenza di rilevamento maschere
- Nessuno dei servizi valutati espone etichette di oggetti relative alle maschere nelle loro API predefinite.
- Tutti e tre hanno quindi restituito una precisione dello 0% per le maschere.
Sensibilità IoU e qualità della localizzazione
- Le differenze di prestazione aumentano a soglie IoU più elevate, dove è richiesto un allineamento più rigoroso dei riquadri di delimitazione.
- Amazon Rekognition mantiene un mAP relativamente più elevato a queste soglie, suggerendo una maggiore precisione di localizzazione.
Metodologia del benchmark degli strumenti di riconoscimento immagini
Abbiamo testato le prestazioni pronte all'uso (cioè senza etichettatura personalizzata) di questi fornitori in casi reali.
Abbiamo utilizzato 100 immagini. Abbiamo ridimensionato le immagini a 512×512 pixel preservando le regioni essenziali contenenti le istanze, poiché il dataset originale comprendeva dimensioni variabili.
Vogliamo eseguire nuovamente questo test senza che i fornitori addestrino le loro soluzioni sul dataset. Pertanto, non divulghiamo il dataset che abbiamo utilizzato per questo benchmark.
Abbiamo elaborato le risposte dalle API dei fornitori di servizi nel modo seguente:
- abbiamo mappato le etichette dei fornitori di servizi alle categorie di verità di riferimento definite nella tabella sopra. Le etichette dei fornitori di servizi che non corrispondevano a queste etichette di verità di riferimento sono state escluse dalla valutazione.
- abbiamo normalizzato i formati dei riquadri di delimitazione dei diversi fornitori
- abbiamo calcolato l'IoU tra i riquadri previsti e quelli di verità di riferimento
- abbiamo abbinato le previsioni alla verità di riferimento in base alla soglia IoU
- abbiamo calcolato le metriche: precisione, richiamo, F1 e AP per categoria
- abbiamo calcolato il mAP in stile COCO utilizzando le soglie 0.5-0.95
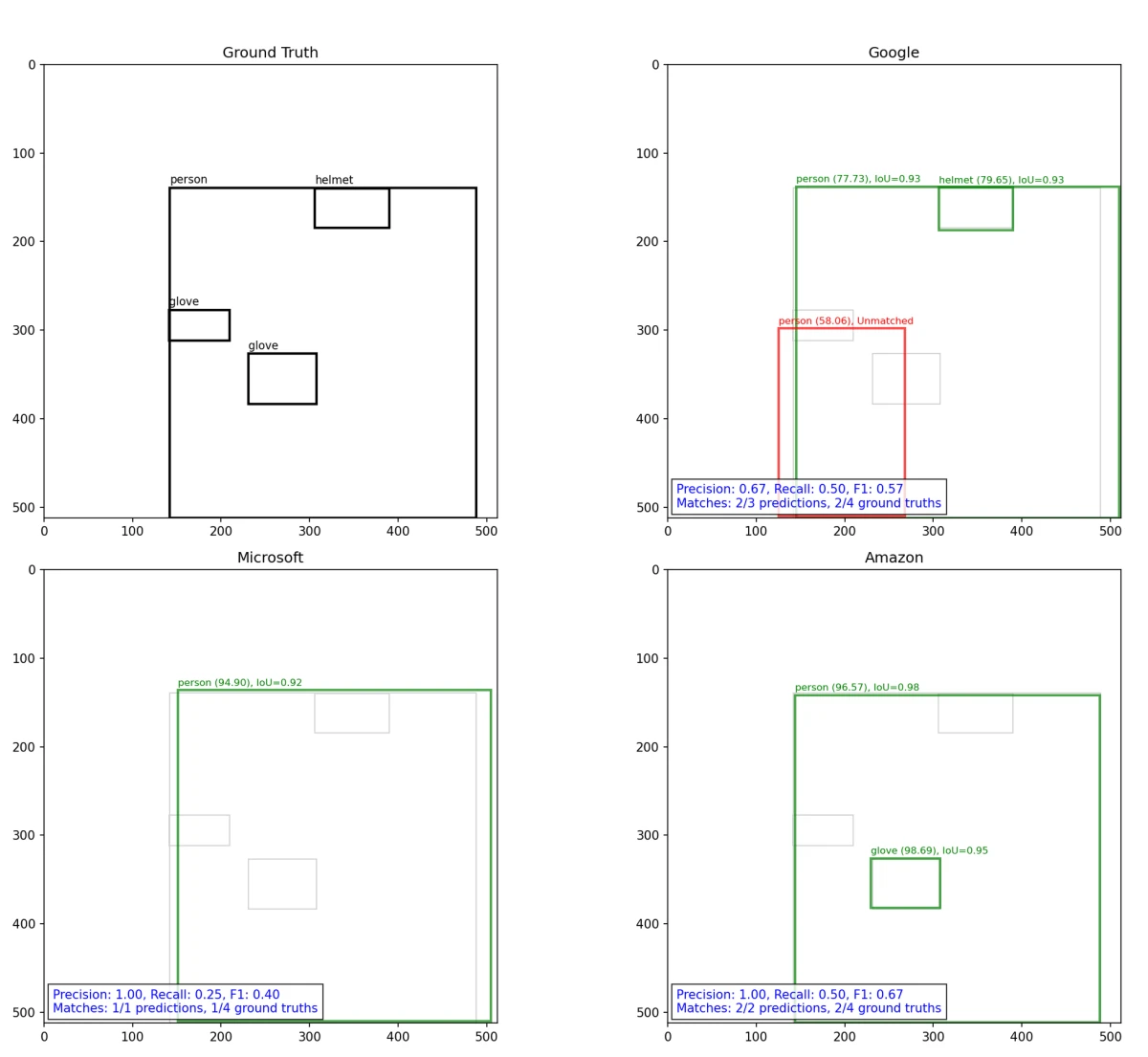
Un esempio di calcolo di IoU, precisione, richiamo e F1 è riportato nella figura seguente:
Metriche di benchmarking
Precisione
La precisione misura l'accuratezza delle previsioni positive effettuate dal modello. Nel riconoscimento immagini, per una data classe (ad es., "persona"), risponde alla domanda: "Di tutte le immagini che il modello ha etichettato come contenenti una persona, quante contengono effettivamente una persona?". Questo è cruciale in scenari in cui i falsi positivi (etichettare erroneamente un'immagine come positiva) sono costosi.
Richiamo
Il richiamo misura la completezza delle previsioni positive, rispondendo alla domanda: "Di tutte le immagini che contengono effettivamente la classe, quante sono state identificate correttamente dal modello?" Questo è fondamentale quando la mancata rilevazione di un'istanza positiva (falso negativo) è critica.
Punteggio F1
Il punteggio F1 è la media armonica di precisione e richiamo, fornendo una misura bilanciata particolarmente utile quando c'è una distribuzione non uniforme delle classi (ad es., poche immagini di caschi rispetto a immagini senza caschi). È una metrica singola che cattura sia i falsi positivi che i falsi negativi.
mAP
Il mAP, o mean Average Precision, è una metrica utilizzata principalmente nelle attività di rilevamento oggetti nell'ambito del riconoscimento immagini. Valuta l'accuratezza del modello attraverso diverse classi calcolando la media della Precisione Media (AP) di ciascuna classe. L'AP stessa è l'area sotto la curva precisione-richiamo, generata variando la soglia di confidenza per i rilevamenti.
Questo strumento interattivo consente di confrontare i risultati di rilevamento tra i fornitori utilizzando immagini di esempio dal dataset. Utilizzare i pulsanti in alto per selezionare Amazon, Google, Microsoft o tutti i fornitori. Attivare/disattivare la verità di riferimento con la casella di controllo. Navigare tra le immagini di test utilizzando i pulsanti numerati a sinistra. I riquadri colorati mostrano ogni rilevamento con i punteggi di confidenza.
Migliori API di Riconoscimento Immagini
Amazon Rekognition
Amazon Rekognition include API dedicate al rilevamento DPI insieme al rilevamento generale di oggetti e volti, il che gli conferisce una copertura di etichette più ampia su classi come caschi e guanti rispetto agli altri due servizi. Questo ambito di prodotto è coerente con i risultati AP per classe nel benchmark.
Le sue API per immagini sono suddivise in due gruppi:
- Gruppo 1 (identificazione facciale): CompareFaces, IndexFaces, SearchFaces, utilizzati per la verifica dell'identità e la ricerca di volti tra raccolte di immagini.
- Gruppo 2 (analisi dei contenuti): DetectLabels (rilevamento generale di oggetti), DetectModerationLabels, DetectText, RecognizeCelebrities, DetectPPE.
Si integra con il resto di AWS (S3 per l'archiviazione, Lambda per l'elaborazione guidata dagli eventi, SageMaker per l'addestramento di modelli personalizzati).
Google Cloud Vision
Google Cloud Vision ha superato l'89% di precisione a IoU=0.5, lo stesso livello di precisione degli altri due servizi, ma ha prodotto un richiamo inferiore su oggetti piccoli e dispositivi di protezione. Il suo ambito di prodotto tende verso la comprensione delle immagini per scopi generici piuttosto che il rilevamento industriale: OCR, riconoscimento dei punti di riferimento, identificazione di loghi e marchi e Rilevamento Web (confronto di un'immagine con immagini indicizzate pubblicamente).
Funzionalità principali:
- Localizzazione di oggetti e rilevamento di etichette
- OCR per testo stampato e manoscritto in più lingue
- Rilevamento di punti di riferimento, loghi e celebrità
- Rilevamento Web per la ricerca inversa di immagini
- Addestramento di modelli personalizzati tramite Vertex IA
Si integra con Cloud Storage, BigQuery e Google Workspace e accetta una gamma più ampia di formati di file rispetto a Rekognition (JPEG, PNG, GIF, BMP, WEBP, RAW, ICO, PDF, TIFF).
Microsoft Azure IA Vision
Microsoft Azure IA Vision fornisce analisi delle immagini, OCR, didascalizzazione delle immagini e un servizio separato di rimozione dello sfondo. La sua documentazione nota che il rilevatore di oggetti non gestisce in modo affidabile oggetti piccoli o ravvicinati, quindi si posiziona più verso la comprensione generale delle immagini e la lettura del testo piuttosto che il rilevamento preciso degli oggetti.
Le funzionalità principali sono suddivise in due gruppi:
- Gruppo 1 (rilevamento elementi visivi): etichettatura, volto, rilevamento oggetti, rilevamento marchi e punti di riferimento, ritaglio intelligente, OCR.
- Gruppo 2 (output consapevole della lingua): descrizione immagine, didascalie dense, lettura completa (OCR documenti).
Caratteristiche distintive dei fornitori di servizi
Panoramica dei prezzi delle API
Creazione di modelli di visione personalizzati
Le API ospitate come Amazon Rekognition, Google Cloud Vision e Microsoft Azure IA Vision restituiscono previsioni da un insieme fisso di etichette definito dal fornitore. Quando una classe di oggetti richiesta è assente da tale insieme, o quando l'accuratezza su un dominio specifico è troppo bassa, l'alternativa è addestrare un modello personalizzato. Roboflow è un esempio che copre questo flusso di lavoro.
Roboflow
Roboflow è una piattaforma di visione artificiale che copre l'annotazione dei dati, l'addestramento dei modelli e la distribuzione. Funziona con un modello diverso rispetto alle API di rilevamento ospitate sopra: gli utenti addestrano i modelli sui propri dataset etichettati ed eseguono l'inferenza sul proprio hardware, anziché chiamare un endpoint gestito. Questo è il percorso che i team intraprendono quando le API cloud predefinite non espongono etichette per una classe di oggetti specifica, come le maschere che hanno restituito una precisione dello 0% in tutti e tre i servizi confrontati.
Roboflow include tre componenti principali:
- RF-DETR: un modello basato su transformer in tempo reale per il rilevamento e la segmentazione di oggetti, destinato a input di telecamere dal vivo e video.2
- AutoDistill: uno strumento che utilizza grandi modelli di base per etichettare automaticamente i dataset di immagini senza annotazione manuale.3
- Inference: un pacchetto di distribuzione che supporta più backend (ONNX, TensorRT, PyTorch), con esecuzione su GPU, CPU o dispositivi edge come NVIDIA Jetson tramite un servizio Dockerizzato.4
Edge computing nel riconoscimento immagini
Il riconoscimento immagini basato su cloud invia ogni fotogramma a un data center remoto per l'analisi. L'edge computing esegue il modello sul dispositivo che ha catturato il fotogramma, così il risultato (un'etichetta, un avviso, un flag) lascia il dispositivo.
Come funziona l'edge computing
In una configurazione cloud, le telecamere fungono da raccoglitori di dati e trasmettono i fotogrammi grezzi a monte; il modello risiede nel data center. In una configurazione edge, il dispositivo esegue la rete neurale localmente e trasmette l'output rilevante: "persona rilevata", "inventario basso", "difetto trovato".
Perché è importante per il riconoscimento immagini
- Latenza: l'inferenza locale elimina il round trip cloud, il che è importante per veicoli autonomi, robot di produzione e qualsiasi sistema che debba agire sulla previsione entro millisecondi.
- Privacy: le immagini non lasciano il dispositivo, il che è utile dove si applicano requisiti di residenza dei dati o GDPR (imaging medico, CCTV in negozio).
- Larghezza di banda e costi: vengono caricati i metadati, non l'intero video, riducendo i costi di rete e delle API cloud per distribuzioni su larga scala.
- Funzionamento offline: i dispositivi edge continuano a funzionare quando la rete fallisce, il che è necessario per i sistemi di sicurezza e i siti industriali remoti.
Esempi reali di IA edge nel riconoscimento immagini
SDK su dispositivo Captur
L'elaborazione su dispositivo è la forma più comune di IA edge in contesti mobili. Captur fornisce un SDK di verifica immagini su dispositivo che esegue modelli di visione artificiale localmente su dispositivi mobili in circa 30ms, anche offline.5 Il fornitore logistico GoBolt ha integrato l'SDK di Captur nella sua app per conducenti per la verifica della prova di consegna e ha segnalato un calo del 30% nei reclami di mancata consegna nella prima settimana.6
Ultralytics YOLO26
YOLO26 di Ultralytics è un modello di visione artificiale open-source progettato per dispositivi edge e a basso consumo. La sua architettura completamente end-to-end, gratuito da NMS, rimuove le fasi di post-elaborazione come la soppressione non massima, riducendo la latenza e migliorando l'esportabilità verso hardware edge, supportando al contempo rilevamento oggetti, segmentazione, classificazione e stima della posa all'interno di un'unica famiglia di modelli.7
Vision transformer nel riconoscimento immagini
Le API di riconoscimento immagini confrontate qui utilizzano rilevatori basati su CNN. I Vision Transformer (ViT) sono un'architettura alternativa che suddivide l'immagine in patch di dimensioni fisse (tipicamente 16×16 pixel) ed elabora tutte le patch in parallelo, consentendo al modello di mettere in relazione regioni distanti dell'immagine fin dal primo strato anziché costruire tale contesto gradualmente attraverso convoluzioni impilate.
Per il rilevamento oggetti, questo è importante quando l'identità di un oggetto dipende dalla scena circostante (un cappello su una persona rispetto a un cappello su uno scaffale). Le CNN catturano questo attraverso convoluzioni impilate; i ViT lo catturano attraverso l'attenzione su tutte le patch contemporaneamente.
I tre servizi cloud in questo benchmark eseguono tutti modelli basati su CNN in produzione. Architetture ibride CNN-Transformer stanno comparendo in modelli open-source più recenti (ad esempio, RF-DETR di Roboflow utilizza un backbone transformer DINOv2), ma le API cloud di produzione non sono ancora migrate.
Modelli vision transformer per il riconoscimento immagini
- Google ViT: il Vision Transformer originale, addestrato su ImageNet per la classificazione delle immagini. Disponibile su Hugging Face con pesi pre-addestrati.
- Swin Transformer: utilizza un meccanismo a finestre scorrevoli per catturare sia i dettagli globali che quelli locali, utilizzato per rilevamento e segmentazione.
- DINOv2 (Meta): modello auto-supervisionato addestrato senza etichette manuali, che produce embedding di immagini per scopi generici.
- Segment Anything Model (SAM): segmentatore basato su ViT in grado di isolare oggetti su cui non è stato addestrato.
Casi d'uso del software di riconoscimento immagini
Nel panorama digitale odierno, le tecnologie di visione artificiale ed elaborazione delle immagini hanno trasformato il modo in cui le aziende sfruttano i dati visivi. Algoritmi avanzati di classificazione delle immagini consentono strumenti di riconoscimento immagini sofisticati che stanno rimodellando le operazioni in tutti i settori.
Queste tecnologie di riconoscimento immagini combinano potenti approcci di addestramento dei modelli con interfacce intuitive che consentono agli utenti di automatizzare complesse attività visive. Dalle soluzioni di visione personalizzate per esigenze aziendali specifiche ai sistemi di riconoscimento facciale per la sicurezza, questi strumenti possono identificare modelli, oggetti e caratteristiche all'interno delle immagini.
Ispezione visiva
Il riconoscimento immagini consente l'ispezione visiva automatizzata in diversi settori. Questi sistemi identificano oggetti, rilevano caratteristiche e verificano la compatibilità analizzando i dati visivi.
Ad esempio, Chamberlain Group ha implementato Amazon Rekognition nella loro app myQ, consentendo agli utenti di catturare automaticamente immagini del proprio apriporta da garage per verificare la compatibilità. Questa soluzione semplificata ha sostituito un complesso processo manuale e ha aumentato significativamente i tassi di connessione degli utenti.8
Elaborazione documenti
La tecnologia OCR estrae testo da immagini e documenti, automatizzando l'immissione dei dati in più lingue. I sistemi moderni possono elaborare testo manoscritto e layout complessi, trasformando i flussi di lavoro cartacei e rendendo i documenti ricercabili.
Ad esempio, il gruppo assicurativo francese LSA Courtage utilizza Google Cloud Vision API per riconoscere il testo da patenti di guida e documenti di immatricolazione. Questa implementazione OCR ha ridotto il tempo di elaborazione dei documenti del 45% per pagina e aumentato la produttività dei sottoscrittori del 20%, consentendo loro di elaborare 1.500 documenti al giorno.9
Puoi consultare il nostro benchmark OCR per vedere l'accuratezza dei vari strumenti OCR per diversi tipi di documenti.
Monitoraggio agricolo
Gli agricoltori utilizzano immagini da droni con riconoscimento immagini per monitorare la salute delle colture, rilevare malattie e ottimizzare l'irrigazione. Identificando le aree di stress delle colture prima che compaiano sintomi visibili, gli agricoltori possono intervenire precocemente e ridurre l'uso delle risorse.
Ad esempio, Project FarmBeats di Microsoft (ora Azure Data Manager for Agriculture) utilizza sensori, droni e apprendimento automatico per consentire un'agricoltura basata sui dati in ambienti con alimentazione e connettività internet limitate. Il sistema aiuta ad aumentare la produttività agricola e ridurre i costi combinando i dati visivi con la conoscenza degli agricoltori sulla loro terra.10
Sicurezza e sorveglianza
I sistemi di sicurezza utilizzano il riconoscimento facciale e il rilevamento oggetti per identificare attività, controllare l'accesso e localizzare persone. Questi sistemi monitorano i feed video e avvisano il personale in caso di minacce. Ad esempio, Sun Finance utilizza Amazon Rekognition per verificare l'identità del cliente confrontando i selfie con i documenti d'identità, accelerando la verifica e prevenendo le frodi, ampliando al contempo l'inclusione finanziaria.11
Moderazione dei contenuti
Le piattaforme di social media utilizzano il riconoscimento immagini per filtrare contenuti inappropriati come nudità, violenza o immagini grafiche dai caricamenti degli utenti. La generazione di didascalie può aggiungere un secondo livello descrivendo il contesto dell'immagine che i classificatori a livello di pixel non colgono, ad esempio rilevando simboli d'odio sullo sfondo di una foto altrimenti innocua. Secondo AWS, il filtraggio automatico riduce in genere il volume che i moderatori umani devono esaminare all'1–5% del totale.12
Ad esempio, CoStar Group utilizza Amazon Rekognition per la moderazione dei contenuti e l'analisi video di circa 150.000 caricamenti giornalieri di immagini e video sulla loro piattaforma immobiliare commerciale. Questa soluzione di moderazione dei contenuti analizza le immagini, classifica i contenuti, rileva materiale indesiderato e sfrutta la tecnologia di didascalizzazione delle immagini per comprendere il contesto, risparmiando tempo e garantendo conformità e dati di alta qualità.13
Puoi saperne di più sulle applicazioni del riconoscimento immagini.
Limitazioni della tecnologia di riconoscimento immagini
Riduzione dei dettagli negli oggetti piccoli
Quando gli oggetti appaiono piccoli nelle immagini, contengono meno pixel, con conseguenti dati visivi limitati. Inoltre, le CNN tendono a perdere importanti dettagli fini durante l'elaborazione attraverso strati di downsampling, ostacolando significativamente le capacità di rilevamento.
Rilevamenti mancati
I sistemi di riconoscimento immagini favoriscono tipicamente gli oggetti più grandi durante le fasi di addestramento e analisi, con conseguenti frequenze più elevate di oggetti piccoli mancati o falsi negativi.
Interferenza dello sfondo
Gli oggetti più piccoli sono più vulnerabili all'essere oscurati da rumore visivo, disordine dello sfondo o elementi sovrapposti, rendendoli più difficili da identificare con precisione. Anche un'occlusione parziale può influenzare in modo sproporzionato gli oggetti piccoli, poiché hanno un'area distinguibile inferiore in partenza.
Variabilità di scala
Gli oggetti che appaiono a distanze o scale diverse pongono difficoltà per i modelli non specificamente progettati per rilevare dettagli fini attraverso dimensioni variabili degli oggetti.
Requisiti computazionali
Le tecniche per migliorare il rilevamento di oggetti piccoli, come l'estrazione di caratteristiche multi-scala o input a risoluzione più elevata, richiedono maggiore potenza di elaborazione, limitando l'applicabilità in tempo reale.
Bias di addestramento
I dataset spesso sottorappresentano gli oggetti piccoli o mancano di annotazioni sufficienti per essi, riducendo la generalizzazione del modello a tali casi in scenari reali.
FAQ
Il software di riconoscimento immagini è un tipo di tecnologia di visione artificiale che utilizza algoritmi di apprendimento automatico per analizzare dati non strutturati come immagini digitali e dati video. Va oltre l'identificazione di oggetti specifici; i sistemi avanzati mirano alla comprensione della scena, interpretando il contesto e le relazioni all'interno di un'immagine per fornire un'analisi più completa. Ciò consente ai computer di vedere e classificare efficacemente le informazioni visive.
Nessun singolo software di riconoscimento immagini o software di visione artificiale è universalmente il migliore. La scelta ideale tra le tecnologie di riconoscimento immagini dipende dalle tue esigenze specifiche. Considera fattori come l'accuratezza richiesta, il tipo di attività che devi svolgere (come il rilevamento oggetti o l'OCR, e anche considerare se è necessario integrarsi con l'elaborazione del linguaggio naturale per attività che combinano la comprensione delle immagini con l'analisi del testo), la facilità d'uso, la scalabilità, il budget, le opzioni di personalizzazione e le competenze tecniche del tuo team. Provare diverse opzioni è il modo migliore per trovare le tecnologie di riconoscimento immagini che forniscono al meglio le capacità di visione artificiale necessarie per la tua applicazione.
Sebbene il riconoscimento immagini sia migliorato significativamente, l'accuratezza non è garantita. I fattori che influenzano le prestazioni includono la qualità dell'immagine (illuminazione, risoluzione), la complessità della scena, le variazioni nell'aspetto degli oggetti e la qualità dei dati di addestramento utilizzati per gli algoritmi di deep learning. Ottenere una comprensione robusta della scena e rilevare accuratamente oggetti specifici può essere difficile in dati visivi complessi o rumorosi.
Link Esterni
Cita questo benchmark
Scegli il formato adatto a dove pubblicherai. Incollare la versione con link nel tuo CMS preserva il backlink.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{I Migliori Strumenti di Riconoscimento Immagini a Confronto}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/image-recognition-software}},
note = {AIMultiple. Consultato il 17 Giugno 2026}
}
Sii il primo a commentare
Il tuo indirizzo email non verrà pubblicato. Tutti i campi sono obbligatori. I commenti vengono lasciati nella loro lingua originale.