I 6 migliori strumenti open source per il rilevamento dei dati sensibili
I seguenti strumenti sono selezionati in base all'attività su GitHub e ordinati per numero di stelle GitHub in ordine decrescente. Coprono i principali casi d'uso per il rilevamento dei dati sensibili: catalogazione dei metadati con lineage, scansione senza agenti e rilevamento basato su API di PII, dati PCI e credenziali inattive.
Per saperne di più: Strumenti di rilevamento e classificazione dei dati sensibili, software DLP.
Funzionalità amministrative
Strumento | Cruscotto grafico | Basato su ricerca | Data lineage | Sistema di database federato |
|---|---|---|---|---|
DataHub | ✅ | ✅ | ✅ | ✅ |
Apache – Atlas | ✅ | ✅ | ✅ | ❌ |
Marquez | ✅ | ✅ | ✅ | Non condiviso. |
OpenDLP | ❌ | ❌ | ❌ | ❌ |
Piiano Vault – ReDiscovery | ❌ | Non condiviso. | ❌ | ❌ |
Nightfall IA – Sensitive data scanner | ✅ | ✅ | ❌ | ❌ |
Descrizioni delle funzionalità:
- Cruscotto grafico – consente di visualizzare i risultati dei dati.
- Funzionalità basata su ricerca – consente di cercare asset di dati.
- Data lineage – consente agli utenti di visualizzare come i dati vengono generati, trasformati, trasmessi e utilizzati in un sistema nel tempo.
- Sistema di database federato – mappa più sistemi di database autonomi in un unico database federato.
Queste funzionalità (in particolare il data lineage e le capacità di ricerca) consentono alle aziende di:
- Individuare la posizione delle loro informazioni personali (PII), dati del settore delle carte di pagamento (PCI), ecc., archiviati in più database, app ed endpoint utente.
- Conformarsi agli standard normativi di settore per la protezione dei dati e la privacy come il Regolamento generale sulla protezione dei dati (GDPR) e il California Consumer Privacy Act (CCPA).
Funzionalità di sicurezza dei dati
Descrizioni delle funzionalità:
- Mascheramento dei dati– consente di nascondere i dati modificandone lettere e numeri originali, in modo che non abbiano valore per intrusi non autorizzati pur rimanendo utilizzabili per i dipendenti autorizzati.
- Data loss prevention (DLP) – rileva potenziali violazioni dei dati e le previene bloccando i dati sensibili.
Categorie e stelle GitHub
Selezione e ordinamento degli strumenti:
- Numero di recensioni: oltre 10 stelle GitHub.
- Aggiornamento: almeno un aggiornamento è stato rilasciato la scorsa settimana a novembre 2024.
- Ordinamento: gli strumenti sono ordinati per stelle GitHub in ordine decrescente.
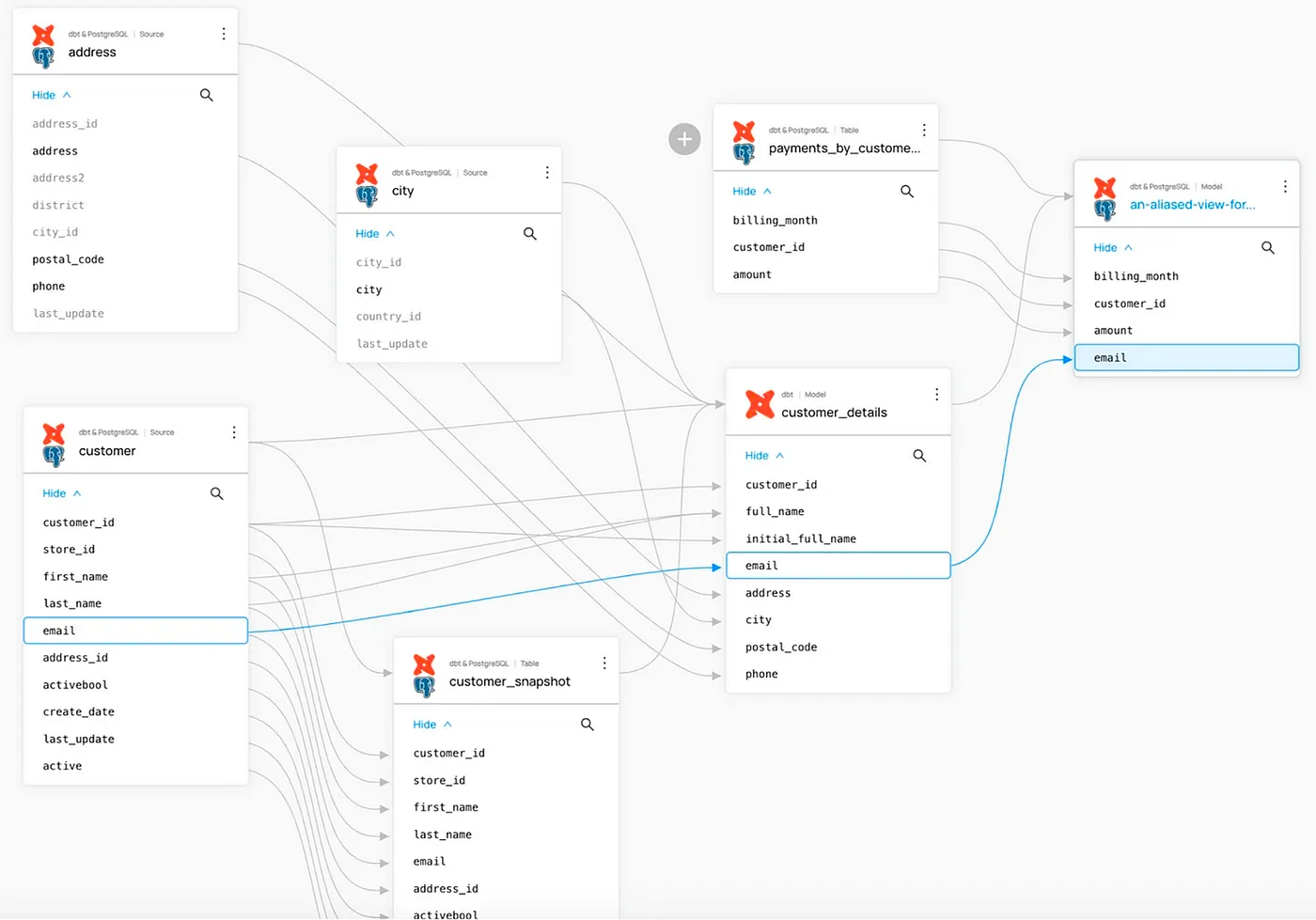
DataHub
DataHub è una piattaforma open source unificata per il rilevamento, l'osservabilità e la governance dei dati sensibili, creata da Acryl Data e LinkedIn. È anche offerto commercialmente da Acryl Data come soluzione SaaS ospitata nel cloud.
Caratteristiche principali:
- Data lineage a livello di colonna: traccia il flusso di dati dall'origine al consumo attraverso le piattaforme.
- Qualità dei dati assistita dall'IA: il rilevamento delle anomalie segnala automaticamente i problemi di qualità dei dati.
- Estensibilità: API REST, SDK Python e integrazione LangChain per creare agenti con accesso ai metadati di DataHub.
- Oltre 80 connettori nativi: Snowflake, BigQuery, Redshift, Hive, Athena, Postgres, MySQL, SQL Server, Trino, Looker, Power BI, Tableau, Okta, LDAP, S3, Delta Lake e altri.
Considerazione: l'architettura di DataHub esegue più servizi interconnessi (GMS, consumer MCE, consumer MAE, indice di ricerca, archivio grafico). I deployment in produzione richiedono tipicamente Kubernetes. La complessità di configurazione è il punto dolente più frequentemente citato nella community.
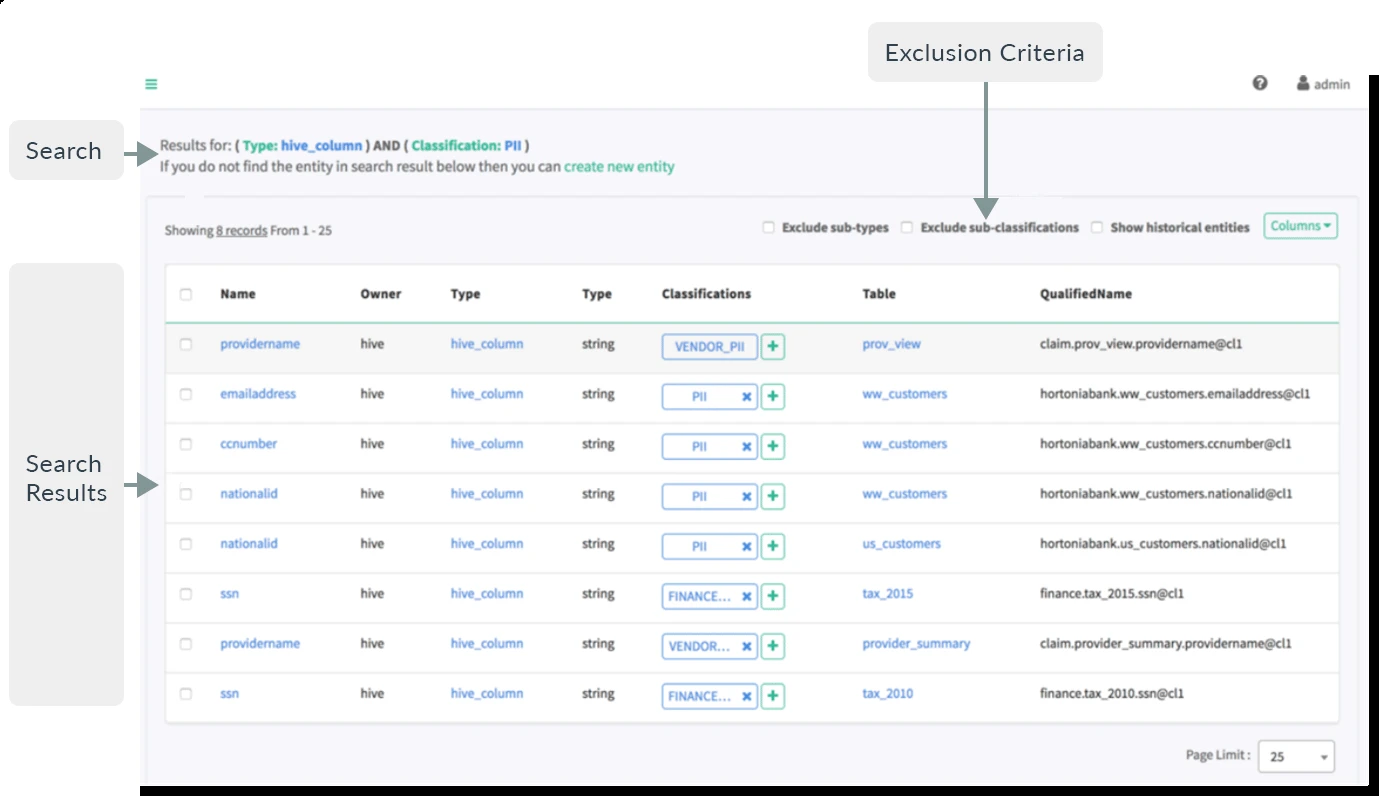
Apache – Atlas
Apache Atlas è uno strumento open source per la gestione e la governance dei metadati, progettato principalmente per ecosistemi Hadoop e big data. Supporta la classificazione, il tracciamento del lineage e la ricerca tra gli asset di dati in ambienti basati su Hive, HBase, Kafka, Spark, Sqoop e Storm.
Caratteristiche principali
- Classificazione dinamica: Apache Atlas consente di creare classificazioni personalizzate come PII (Personally Identifiable Information), EXPIRES_ON, DATA_QUALITY e SENSITIVE.
- Tipi di metadati: la piattaforma fornisce tipi di metadati predefiniti per ambienti Hadoop e non Hadoop. Ciò consente agli utenti di gestire i metadati per diverse origini dati, come HBase, Hive, Sqoop, Kafka e Storm.
- Linguaggio di query simile a SQL (DSL): la piattaforma supporta un linguaggio specifico di dominio (DSL) che fornisce funzionalità di query simili a SQL per cercare entità. Ciò lo rende accessibile agli utenti che hanno familiarità con SQL.
- Integrazione con strumenti esterni: Apache Hive, Apache Spark, Kafka e Presto, rendendolo adattabile agli ambienti big data.
Considerazioni:
- La configurazione di Atlas in un ambiente multi-cloud è complessa, in particolare quando si collegano le API di AWS, Azure e Databricks. Atlas non dispone di connettori nativi per queste piattaforme; è necessaria una configurazione aggiuntiva per registrare il lineage da AWS Redshift o Azure Synapse.
- I servizi di catalogazione cloud-native (ad es. AWS Glue) possono offrire un tracciamento del lineage con meno overhead per i team già impegnati con un unico fornitore cloud.
- Atlas è più adatto alle organizzazioni che eseguono Hadoop, Spark e Hive su larga scala. I team senza uno stack incentrato su Hadoop troveranno che la sua architettura aggiunge complessità non necessaria.
Marquez
Marquez è un catalogo dati open source per raccogliere, aggregare e visualizzare i metadati da un ecosistema di dati. Fornisce un'interfaccia Web e API REST per esplorare i dataset, comprenderne le dipendenze e tracciare le modifiche attraverso le pipeline di dati.
- Ricerca dataset: gli utenti possono facilmente cercare dataset, visualizzarne gli attributi e comprenderne le dipendenze nell'ecosistema dei dati.
- Visualizzare il lineage: il grafico del lineage in Marquez fornisce una visione chiara e interattiva di come i dataset sono connessi e trasformati attraverso i flussi di lavoro. Questo è fondamentale per comprendere le pipeline di dati, tracciare gli errori e garantire l'affidabilità dei dati.
- Repository centralizzato dei metadati: Marquez aggrega i metadati da fonti diverse, consolidandoli in un unico sistema per un facile accesso e gestione.
Esempio di flusso di lavoro: per ispezionare i metadati del lineage, accedi all'interfaccia utente di Marquez e cerca un job (ad es. etl_delivery_7_days) utilizzando la casella di ricerca. Dal dataset di output del job (public.delivery_7_daysYou can view the dataset name, schema, description, and upstream inputs.
Piiano Vault – ReDiscovery
Piiano Vault è un vault per la privacy per archiviare e proteggere i dati personali sensibili all'interno del proprio ambiente cloud. Piuttosto che scansionare i database esistenti alla ricerca di dati sensibili, Vault è progettato come archivio autorevole per i campi più sensibili: numeri di carta di credito, numeri di conto bancario, ID nazionali (SSN), nomi, email e numeri di telefono, installato insieme ai database applicativi esistenti.
Vault viene distribuito nella tua architettura tramite Docker o Kubernetes (Helm chart disponibili). Sono disponibili SDK per Python (Django ORM), TypeScript, Java e Go. Il repository vault-releases è stato aggiornato l'ultima volta ad agosto 2025.
Distinzione dei casi d'uso: Vault non è uno scanner per il rilevamento dei dati. È un sistema di archiviazione strutturato per i dati sensibili che le organizzazioni desiderano centralizzare e proteggere, non uno strumento per trovare dati sensibili già dispersi nei sistemi esistenti.
Nightfall
Nightfall è una piattaforma DLP commerciale nativa per l'IA, non uno strumento completamente open source. I suoi repository GitHub includono script di scansione open source (Apache 2.0) che utilizzano l'API di Nightfall per scansionare directory, esportazioni e backup. L'esecuzione delle scansioni richiede una chiave API Nightfall e chiama il motore di rilevamento commerciale di Nightfall. Il piano gratuito consente fino a 100 scansioni al mese su repository pubblici e privati.
Funzionalità dello scanner open source (piano gratuito):
- Scansiona l'intera cronologia dei commit di repository pubblici e privati.
- Rileva credenziali, segreti, PII e numeri di carta di credito.
- Esegue fino a 100 scansioni al mese.
Caratteristica distintiva: Nightfall può inviare avvisi a Slack quando vengono rilevate violazioni e inviare i risultati a un SIEM, strumento di reporting o endpoint webhook.
Esempio di caso d'uso: scansionare un backup Salesforce per rilevare dati sensibili inattivi. Lo scanner (1) invia i file di backup all'API di Nightfall per la scansione, (2) esegue un server webhook locale per ricevere i risultati e (3) esporta i risultati in un file CSV.
L'URL sopra è fornito da Nightfall. È l'URL S3 firmato temporaneamente per recuperare i risultati sensibili identificati da Nightfall.
Ulteriori letture
Cita questa ricerca
Scegli il formato adatto a dove pubblicherai. Incollare la versione con link nel tuo CMS preserva il backlink.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Sezer, Sena},
title = {{I 6 migliori strumenti open source per il rilevamento dei dati sensibili}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/open-source-sensitive-data-discovery}},
note = {AIMultiple. Consultato il 24 Giugno 2026}
}


Sii il primo a commentare
Il tuo indirizzo email non verrà pubblicato. Tutti i campi sono obbligatori. I commenti vengono lasciati nella loro lingua originale.