Top 20+ Frameworks de RAG Agentic
O RAG agentic aprimora o RAG tradicional, aumentando o desempenho do LLM e permitindo maior especialização. Realizamos um benchmark para avaliar seu desempenho no roteamento entre vários bancos de dados e na geração de consultas.
Explore frameworks e bibliotecas de RAG agentic, principais diferenças em relação ao RAG padrão, benefícios e desafios para desbloquear todo o seu potencial.
Benchmark de RAG agentic: Roteamento entre múltiplos bancos de dados e geração de consultas
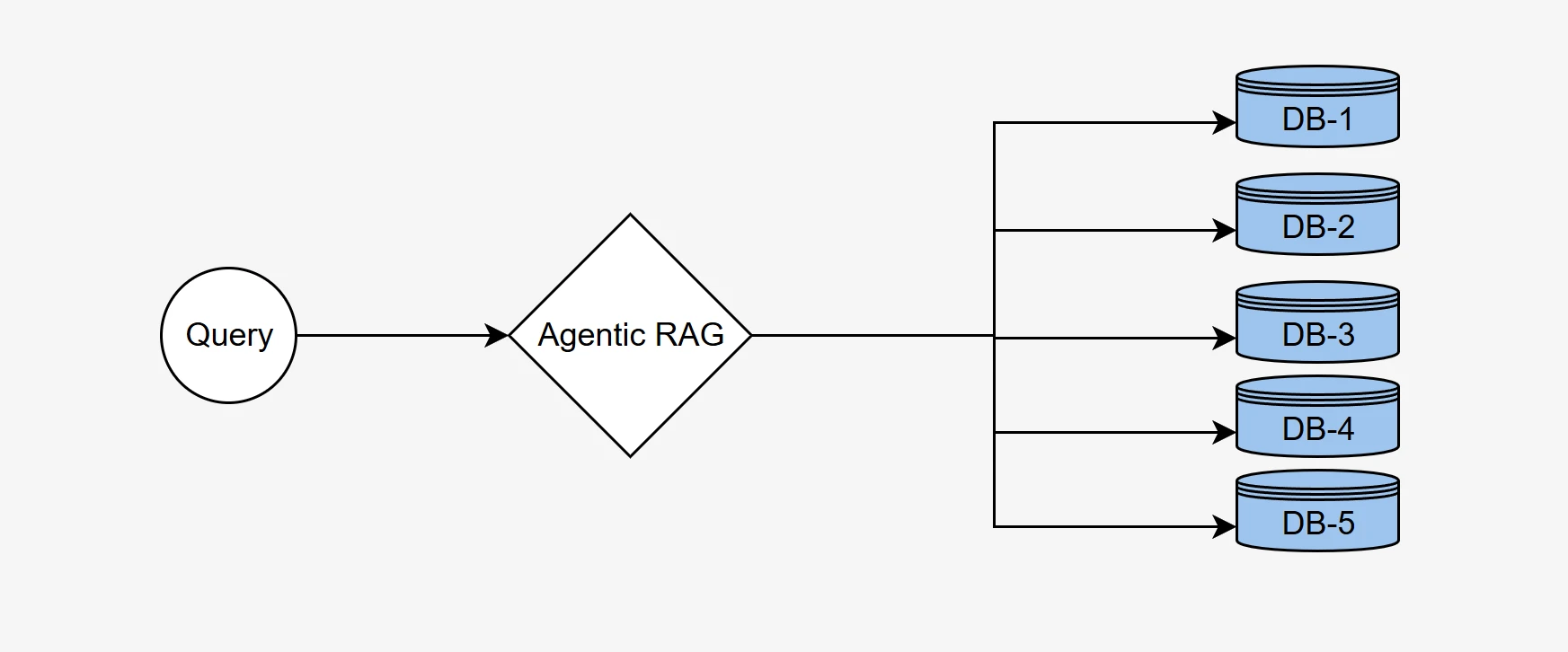
Utilizamos nossa metodologia de benchmark de RAG agentic para demonstrar a capacidade do sistema de selecionar o banco de dados correto entre um conjunto de cinco bancos distintos, cada um com informações contextuais únicas, e gerar consultas SQL semanticamente precisas para recuperar os dados corretos.
No benchmark de RAG agentic, utilizamos:
- Framework de Agente: Langchain
- Banco de dados vetorial: ChromaDB
Em muitos cenários empresariais do mundo real, os dados estão frequentemente distribuídos por vários bancos de dados, cada um contendo informações especializadas relevantes para domínios ou tarefas específicos. Por exemplo, um banco de dados pode armazenar registros financeiros, enquanto outro contém dados de clientes ou detalhes de inventário.
Um sistema de RAG agentic eficaz deve rotear de forma inteligente a consulta do usuário para o banco de dados mais relevante para recuperar informações precisas. Esse processo envolve analisar a consulta, entender o contexto e selecionar a fonte de dados apropriada entre um conjunto de bancos de dados disponíveis.
Processo de pensamento do agente
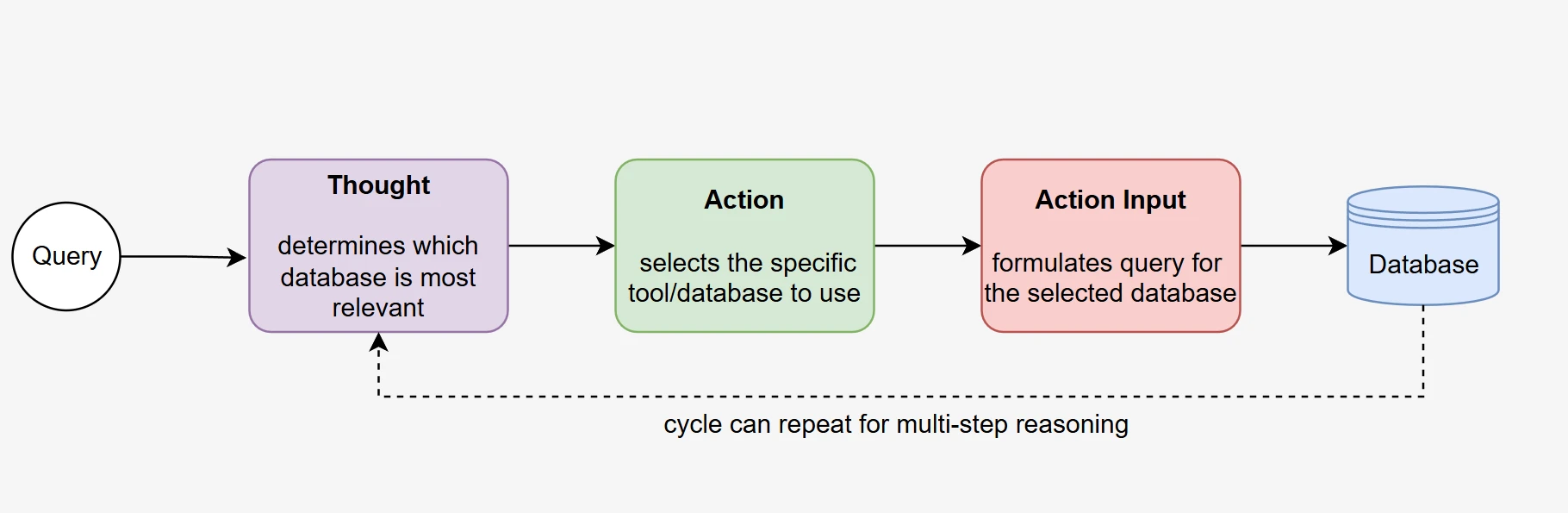
No cerne de um sistema de RAG agentic está a capacidade do LLM de raciocinar e agir de forma autônoma para atingir um objetivo. Nossa abordagem baseada em chamada de função permite que os modelos demonstrem um comportamento agentic verdadeiro por meio da seleção autodirigida de banco de dados e da coleta iterativa de informações.
Tomada de decisão autônoma: O agente analisa a consulta recebida do usuário e determina de forma autônoma qual função de banco de dados chamar com base no contexto da consulta e nas descrições das funções disponíveis. Esse processo de tomada de decisão ocorre sem regras de roteamento predeterminadas, demonstrando capacidades genuínas de raciocínio.
Execução em várias etapas: O agente normalmente realiza várias chamadas de função em sequência, primeiro para identificar e acessar o banco de dados relevante, depois para coletar informações detalhadas do esquema e, finalmente, para refinar seu entendimento antes de gerar a consulta SQL. Esse processo iterativo espelha abordagens humanas de resolução de problemas.
Capacidade de autocorreção: Quando as chamadas de função iniciais não fornecem informações suficientes, o agente pode decidir de forma autônoma fazer chamadas adicionais com parâmetros refinados, demonstrando comportamento adaptativo que vai além dos sistemas de recuperação simples.
Comportamento orientado a objetivos: Durante todo o processo, o agente mantém o foco em gerar uma consulta SQL precisa, usando cada resultado de chamada de função para informar decisões e ações subsequentes.
Esse padrão de interação autônomo e de múltiplos turnos diferencia fundamentalmente o RAG agentic dos sistemas de RAG tradicionais que seguem caminhos predeterminados e mecanismos de recuperação de tiro único.
Metodologia de benchmark de RAG agentic
Este benchmark avalia a capacidade dos Modelos de Linguagem de Grande Escala (LLMs) de funcionar como agentes autônomos dentro de um pipeline de Geração Aumentada por Recuperação (RAG). Especificamente, ele mede duas competências centrais:
- Roteamento de banco de dados: A capacidade do agente de identificar e selecionar corretamente o banco de dados mais relevante entre vários candidatos, dada uma pergunta em linguagem natural.
- Geração de SQL: A capacidade do agente de gerar uma consulta SQL precisa usando o esquema do banco de dados selecionado.
Dataset
O benchmark utiliza o dataset BIRD-SQL1 , um benchmark acadêmico amplamente adotado para tarefas de texto para SQL. O BIRD-SQL fornece perguntas em linguagem natural emparelhadas com identificadores de banco de dados ground truth e consultas SQL padrão ouro, tornando-o ideal para avaliar tanto a precisão do roteamento quanto a qualidade da geração de consultas.
Do dataset completo do BIRD-SQL, selecionamos um subconjunto de 500 perguntas distribuídas por cinco bancos de dados distintos cobrindo domínios diversos:
Cada pergunta tem exatamente um banco de dados alvo correto. A resposta para cada pergunta reside em um banco de dados específico, exigindo que o agente tome uma decisão de roteamento definitiva.
Desafio de ambiguidade semântica
Para avaliar as capacidades de raciocínio do agente além da correspondência superficial de palavras-chave, introduzimos similaridade semântica entre bancos de dados como um fator de confusão deliberado durante a seleção de perguntas.
Processo de seleção de perguntas:
- Todas as perguntas candidatas dos cinco bancos de dados foram incorporadas usando sentence transformers (
all-MiniLM-L6-v2). - Pares de perguntas entre bancos de dados foram computados e classificados por similaridade de cosseno.
- Perguntas com pontuações de similaridade de cosseno entre bancos de dados acima de 0.70 foram intencionalmente priorizadas para inclusão, criando cenários onde perguntas semanticamente semelhantes pertencem a bancos de dados totalmente diferentes.
Exemplo de confusão semântica:
Pergunta A (BD financeiro): “Para o cliente cujo empréstimo foi aprovado primeiro em 1993/7/5, qual é a taxa de aumento do saldo da sua conta de 1993/3/22 para 1998/12/27?”
Pergunta B (BD cartão_débito): “Para o cliente que pagou 634.8 em 2012/8/25, qual foi a taxa de diminuição do consumo do Ano 2012 para 2013?”
Ambas as perguntas seguem padrões semânticos quase idênticos: identificam um cliente específico através de um evento de transação e, em seguida, calculam uma taxa de variação ao longo de um período de tempo. No entanto, os bancos de dados corretos diferem totalmente; um requer dados de empréstimo e conta, enquanto o outro precisa de dados de transação e consumo. Isso força o agente a realizar um raciocínio contextual mais profundo sobre o domínio dos dados, em vez de confiar em palavras-chave financeiras superficiais que corresponderiam a ambos os bancos de dados.
Ambiente de banco de dados
O esquema e uma breve descrição em linguagem natural de cada banco de dados foram armazenados no ChromaDB, um banco de dados vetorial usado para recuperação semântica eficiente. A coleção de cada banco de dados contém:
- Uma descrição de alto nível do domínio e propósito do banco de dados
- Documentos de esquema por tabela, incluindo nomes de colunas, tipos de dados e descrições de valores
Esta configuração permite que o agente recupere informações relevantes do esquema por meio de busca semântica após selecionar um banco de dados alvo.
Arquitetura do agente
Uma arquitetura agentic baseada em chamada de função foi empregada em todos os modelos para garantir uma comparação justa e padronizada. Cada um dos cinco bancos de dados foi representado como uma função chamável distinta (ferramenta) com parâmetros padronizados. Este design aproveita as capacidades nativas de chamada de função de cada modelo, permitindo que os modelos, de forma autônoma:
- Analisem a pergunta recebida
- Selecionem e invoquem a função de banco de dados apropriada
- Recebam informações do esquema como uma resposta de função
- Opcionalmente invoquem funções adicionais para refinamento
- Gerem a consulta SQL final
Esta abordagem mantém uma metodologia de avaliação consistente em diferentes famílias de modelos, incluindo modelos tradicionais e modelos otimizados para raciocínio.
Fluxo do processo agentic
O sistema implementa um loop agentic genuíno de múltiplos turnos, em vez de um pipeline fixo:
- Análise da pergunta: O agente recebe a pergunta em linguagem natural juntamente com descrições de todas as cinco funções de banco de dados disponíveis.
- Seleção de banco de dados (chamada de ferramenta): O agente seleciona e chama de forma autônoma a função de banco de dados que considera mais relevante. Esta é uma chamada de função real; o agente recebe o esquema como uma resposta de ferramenta estruturada dentro do mesmo contexto de conversa.
- Raciocínio sobre o esquema: O agente observa o esquema retornado e raciocina sobre quais tabelas e colunas são relevantes para a pergunta.
- Recuperação opcional: Se o agente determinar que o banco de dados selecionado não contém as informações necessárias, ele pode chamar uma função de banco de dados diferente, permitindo autocorreção sem intervenção externa.
- Geração de SQL: Com base no contexto acumulado (pergunta + observação do esquema), o agente produz a consulta SQL final.
Esse fluxo de conversação de múltiplos turnos diferencia o benchmark das abordagens tradicionais de RAG de tiro único. O agente mantém contexto completo entre os turnos, pode observar os resultados de suas ações e pode refinar iterativamente sua abordagem, marcas de um comportamento agentic verdadeiro.
Propriedades arquiteturais chave:
- A conversa é contínua, o agente vê seu próprio raciocínio anterior e respostas de ferramentas
- Não são impostos limites artificiais de turnos; o agente decide quando possui informações suficientes
- Tanto a seleção do banco de dados quanto a geração de SQL ocorrem dentro da mesma sessão agentic
- O número de chamadas de ferramenta por pergunta é registrado como uma métrica adicional para analisar a eficiência do agente
Processo de avaliação
Para cada pergunta no benchmark:
Passo 1: Avaliação do roteamento do banco de dados
A primeira chamada de função de banco de dados do agente é registrada como sua decisão de roteamento. Isso é comparado com o banco de dados ground truth especificado no dataset BIRD-SQL.
Métrica: Precisão do roteamento do banco de dados (% de seleções corretas do total de perguntas)
Passo 2: Avaliação da qualidade do SQL
A consulta SQL gerada pelo agente é avaliada usando uma abordagem de LLM-como-Juiz. Um modelo juiz separado (Claude 4 Sonnet) recebe tanto o SQL gerado pelo agente quanto o SQL ground truth do BIRD-SQL, e atribui uma pontuação de similaridade semântica em uma escala de 0–5:
Decisão de design importante: A qualidade do SQL é avaliada quando o agente seleciona o banco de dados correto. Se o agente roteou para o banco de dados errado, ele recebe uma pontuação automática de 0, pois uma consulta SQL contra o esquema errado é inerentemente sem sentido. Isso garante que a métrica de qualidade do SQL reflita puramente a capacidade de geração de consultas, não contaminada por erros de roteamento.
Métricas:
- Pontuação média de qualidade do SQL (de 5.0), calculada sobre perguntas roteadas corretamente
- Taxa de correspondência perfeita: porcentagem de perguntas roteadas corretamente com pontuação 5/5
Variáveis controladas
Para garantir uma comparação justa entre modelos:
- Todos os modelos recebem prompts de sistema e definições de ferramentas idênticos
- A temperatura é definida como 0 para saídas determinísticas
- Nenhuma engenharia de prompt específica do modelo ou exemplos few-shot são fornecidos (avaliação zero-shot)
- O campo de evidência do BIRD-SQL (dicas específicas do domínio) é retido de todos os modelos para medir o raciocínio não assistido
- Todos os modelos acessam a mesma instância do ChromaDB com incorporações de esquema idênticas
Frameworks & bibliotecas de RAG agentic
Os frameworks de RAG agentic permitem que sistemas de IA encontrem informações, raciocinem, tomem decisões e ajam. Principais ferramentas e bibliotecas que potencializam o RAG agentic:
Esta lista inclui ferramentas que atendem aos seguintes critérios:
- 50+ estrelas no GitHub.
- Uso comum em projetos de RAG agentic.
Note que na tabela:
- Uso de ferramenta refere-se à capacidade nativa de um sistema de rotear e chamar ferramentas dentro de seu ambiente.
- Tipo de ferramenta refere-se à área de uso principal das ferramentas, como:
- Frameworks de RAG agentic são projetados especificamente para construir, implantar ou configurar sistemas de RAG agentic.
- Bibliotecas de agentes permitem a criação de agentes inteligentes que podem raciocinar, tomar decisões e executar tarefas de várias etapas.
- Frameworks LLMOps gerenciam o ciclo de vida de LLMs e otimizam a implantação e o uso de LLMs dentro de sistemas baseados em agentes.
- LLMs que possuem capacidades integradas para chamada e roteamento de ferramentas, permitindo tomada de decisão dinâmica. Outros LLMs podem exigir APIs externas ou integrações para habilitar a funcionalidade de agente.
- Verificação do uso de ferramentas e tipos de agentes é obtida por meio de fontes públicas.
O que é o RAG agentic?
A Geração Aumentada por Recuperação Agentic (RAG) é um framework de IA que combina técnicas de recuperação com modelos generativos para permitir tomada de decisão dinâmica e síntese de conhecimento. Esta abordagem integra a precisão do RAG tradicional com as capacidades generativas da IA avançada, visando aumentar a eficiência e a eficácia de tarefas orientadas por IA.
Limitações dos sistemas de RAG tradicionais
O RAG agentic visa superar as limitações enfrentadas pelo sistema de RAG padrão, tais como:
- Dificuldade na priorização de informações: Os sistemas de RAG frequentemente têm dificuldade em gerenciar e priorizar dados eficientemente dentro de grandes conjuntos de dados, o que pode reduzir o desempenho geral.
- Integração limitada de conhecimento especializado: Esses sistemas podem subvalorizar conteúdo especializado e de alta qualidade, favorecendo informações gerais.
- Compreensão contextual fraca: Embora capazes de recuperar dados, eles frequentemente falham em compreender plenamente sua relevância ou como se alinham com a consulta específica.
Como construir um RAG agentic
1. Uso de ferramentas
- Empregar roteadores: O primeiro passo envolve empregar roteadores para determinar se deve recuperar documentos, realizar cálculos ou reescrever a consulta. Esta abordagem adiciona capacidades de tomada de decisão para rotear solicitações para múltiplas ferramentas, permitindo que modelos de linguagem de grande escala (LLMs) selecionem pipelines apropriados.
- Integração de chamada de ferramenta: Isso se refere à criação de uma interface para agentes se conectarem com ferramentas selecionadas. Os usuários podem aproveitar LLMs com capacidades de chamada de ferramenta ou construir os seus próprios para:
- Escolher uma função para executar.
- Inferir os argumentos necessários para essa função.
- Aprimorar a compreensão da consulta além dos pipelines tradicionais de RAG, permitindo tarefas como consultas a bancos de dados ou raciocínio complexo.
2. Implementação do agente
- Agentes de chamada única: Uma consulta aciona uma única chamada para a ferramenta apropriada, retornando a resposta. Isso é eficaz para tarefas simples, mas pode ter dificuldades com consultas vagas ou complexas.
- Agentes de múltiplas chamadas: Essa abordagem envolve dividir tarefas entre agentes especializados, com cada agente focando em uma subtarefa específica. Por exemplo:
- Agente recuperador: Otimiza a recuperação de consultas em tempo real.
- Agente gerenciador: Lida com a delegação e orquestração de tarefas.
3. Raciocínio multi-etapa
Para fluxos de trabalho complexos, os agentes usam loops de raciocínio para realizar raciocínio iterativo de várias etapas, mantendo a memória das etapas intermediárias. Esses loops envolvem:
- Chamar várias ferramentas.
- Recuperar dados e validar sua relevância.
- Reescrever consultas conforme necessário.
Os frameworks frequentemente definem múltiplos agentes para lidar com subtarefas específicas, garantindo a execução eficiente do processo geral.
4. Abordagens híbridas: combinando recuperação e execução
Uma abordagem híbrida combina pipelines de recuperação com estratégias de execução dinâmica:
- Estratégias de incorporação e recuperação baseada em vetores para acesso a documentos.
- Capacidades de chamada de ferramenta para resolução dinâmica de consultas.
- Colaboração multi-agente para subtarefas especializadas.
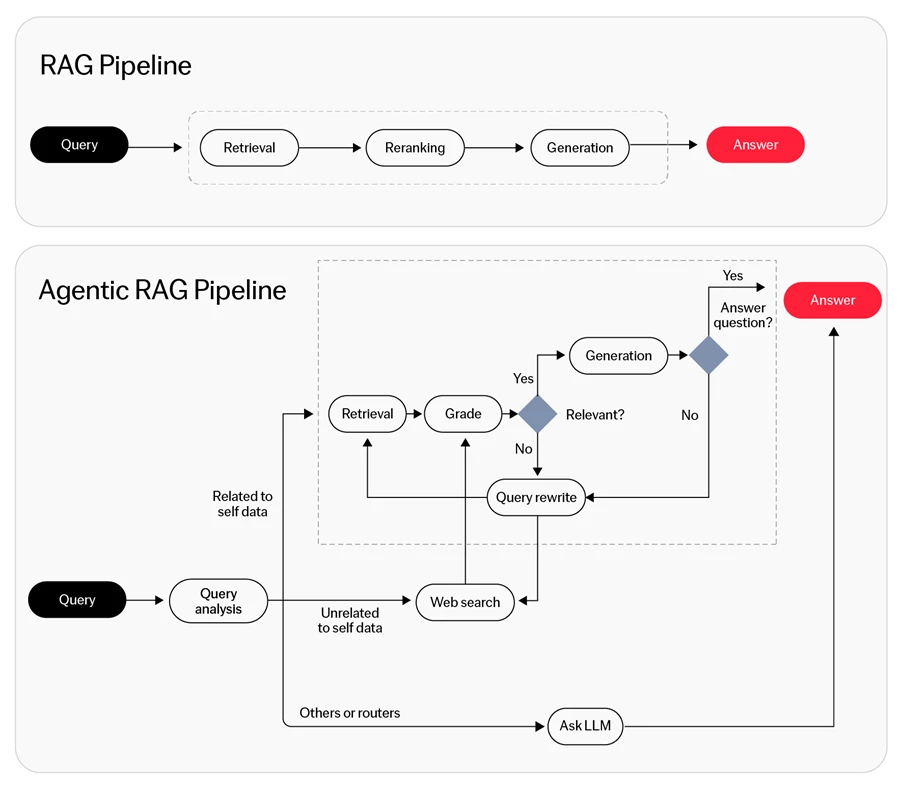
Qual é a diferença entre RAG e RAG agentic?
Aqui estão os pontos fortes e fracos do RAG vs. RAG agentic com base em diferentes aspectos:
- Engenharia de prompt
- RAG tradicional: Depende fortemente da otimização manual de prompts.
- RAG agentic: Ajusta dinamicamente os prompts com base no contexto e nos objetivos, reduzindo a necessidade de intervenção manual.
- Consciência de contexto
- RAG tradicional: Tem consciência contextual limitada e depende de processos de recuperação estáticos.
- RAG agentic: Considera o histórico da conversa e adapta as estratégias de recuperação dinamicamente com base no contexto.
- Autonomia
- RAG tradicional: Carece de ações autônomas e não pode se adaptar a situações em evolução.
- RAG agentic: Realiza ações em tempo real e ajusta-se com base em feedback e observações em tempo real.
- Raciocínio
- RAG tradicional: Requer classificadores e modelos adicionais para raciocínio multi-etapa e uso de ferramentas.
- RAG agentic: Lida com raciocínio multi-etapa internamente, eliminando a necessidade de modelos externos.
- Qualidade dos dados
- RAG tradicional: Não possui mecanismo integrado para avaliar a qualidade dos dados ou garantir precisão.
- RAG agentic: Avalia a qualidade dos dados e realiza verificações pós-geração para garantir saídas precisas.
- Flexibilidade
- RAG tradicional: Opera com regras estáticas, limitando a adaptabilidade.
- RAG agentic: Emprega estratégias de recuperação dinâmica e ajusta sua abordagem conforme necessário.
- Eficiência de recuperação
- RAG tradicional: A recuperação é estática e muitas vezes custosa devido a ineficiências.
- RAG agentic: Otimiza as recuperações para minimizar operações desnecessárias, reduzindo custos e melhorando a eficiência.
- Simplicidade
- RAG tradicional: Apresenta uma configuração direta com menos complexidades de configuração.
- RAG agentic: Envolve configurações mais complexas para suportar operações dinâmicas e conscientes do contexto.
- Previsibilidade
- RAG tradicional: Consistente e baseado em regras, mas rígido no comportamento.
- RAG agentic: O comportamento pode variar dinamicamente com base no contexto e observações em tempo real.
- Custo em implantações
- RAG tradicional: Mais barato para configurações básicas, mas pode incorrer em custos operacionais mais altos a longo prazo.
- RAG agentic: Requer um investimento inicial mais alto devido a recursos avançados e capacidades dinâmicas.
Modelos de contexto longo vs RAG agentic: Quando a recuperação se torna desnecessária
A revolução da janela de contexto de 2025-2026 desafia uma suposição central na arquitetura do RAG. Os modelos agora suportam de 1 a 2 milhões de tokens, forçando uma questão fundamental: quando o processamento direto de contexto supera os complexos agentes de recuperação?
O cenário de contexto em mudança
As janelas de contexto expandiram-se dramaticamente de 128k tokens no início de 2024 para mais de 1M em 2026. Pesquisas recentes usando romances completos como dados de teste revelam que essa expansão cria novas compensações arquiteturais que os engenheiros devem considerar.4
O custo computacional do processamento de contextos massivos deve ser ponderado em relação à complexidade de engenharia e aos potenciais pontos de falha dos sistemas de recuperação. Processar 1M tokens elimina a compressão com perdas da fragmentação e indexação, mas a um alto custo por consulta.
O problema do gargalo de recuperação
Pesquisas sobre documentos de formato longo identificam uma limitação severa nas abordagens tradicionais de RAG. A recuperação top-k padrão cria o que os pesquisadores chamam de “gargalo de recuperação”: quando a busca inicial não encontra o fragmento relevante, o sistema carece de um mecanismo de recuperação.
O RAG agentic aborda isso por meio do refinamento iterativo de consultas. Estudos mostram que sistemas agentic resolvem com sucesso uma porção significativa de problemas que falham completamente sob recuperação de tiro único. O loop autônomo permite que os agentes reformulem consultas quando as tentativas iniciais retornam informações insuficientes.5
No entanto, quando os dados cabem dentro das janelas de contexto expandidas, o processamento direto de contexto longo supera até mesmo os sofisticados sistemas de recuperação agentic. A lacuna de desempenho existe porque o modelo pode raciocinar sobre todo o documento simultaneamente, evitando a fragmentação inerente à recuperação baseada em fragmentos.
Diferentes tipos de modelos de RAG agentic
Alguns dos agentes que aproveitam Modelos de Linguagem de Grande Escala (LLMs) dentro de frameworks de Geração Aumentada por Recuperação (RAG) incluem:
- Agente de roteamento: Usa um Modelo de Linguagem de Grande Escala (LLM) para raciocínio agentic para selecionar o pipeline de Geração Aumentada por Recuperação (RAG) mais apropriado (por exemplo, sumarização ou resposta a perguntas) para uma determinada consulta. O agente determina o melhor ajuste analisando a consulta de entrada.
- Agente de planejamento de consulta de tiro único: Decompõe consultas complexas em subconsultas menores, executa-as em vários pipelines de RAG com diferentes fontes de dados e combina os resultados em uma resposta abrangente.
- Agente de uso de ferramentas: Aprimora os frameworks padrão de RAG incorporando fontes de dados externas (por exemplo, APIs, bancos de dados) para fornecer contexto adicional. Isso permite um processamento mais enriquecido de consultas usando LLMs.
- Agente ReAct: Integra raciocínio e ação para lidar com consultas sequenciais e multipartes. Ele mantém um estado em memória e invoca ferramentas iterativamente, processa suas saídas e determina os próximos passos até que a consulta seja totalmente resolvida.
- Agente de planejamento e execução dinâmica: Destinado a gerenciar consultas mais complexas, este agente separa o planejamento de alto nível da execução. Ele usa um LLM como planejador para projetar um gráfico computacional das etapas necessárias para responder à consulta e emprega um executor para realizar essas etapas de forma eficiente. O foco está na confiabilidade, observabilidade, paralelização e otimização para ambientes de produção.
Benefícios do RAG agentic
O RAG agentic melhora os LLMs por meio de:
- Abordagem autônoma e orientada a objetivos: Ao contrário do RAG tradicional, o RAG agentic age como um agente autônomo, tomando decisões para atingir objetivos definidos e buscar interações mais profundas e significativas.
- Melhor consciência e sensibilidade ao contexto: O RAG agentic considera dinamicamente o histórico da conversa, as preferências do usuário, interações anteriores e o contexto atual para fornecer respostas relevantes e informadas e tomada de decisão.
- Recuperação dinâmica e raciocínio avançado: Utiliza métodos de recuperação inteligentes adaptados às consultas, enquanto avalia e verifica a precisão e confiabilidade dos dados recuperados.
- Orquestração multi-agente: Coordena múltiplos agentes especializados, dividindo consultas em tarefas gerenciáveis e garantindo coordenação perfeita para entregar resultados precisos.
- Maior precisão com verificação pós-geração: Os modelos de RAG agentic realizam verificações de qualidade no conteúdo gerado, garantindo a melhor resposta possível e combinando LLMs com sistemas baseados em agentes para desempenho superior.
- Adaptabilidade e aprendizado: Esses sistemas aprendem e melhoram continuamente ao longo do tempo, aprimorando as habilidades de resolução de problemas, precisão e eficiência, e adaptando-se a vários domínios para tarefas específicas.
- Utilização flexível de ferramentas: Os agentes podem aproveitar ferramentas externas como motores de busca, bancos de dados ou APIs para aprimorar a coleta, processamento e personalização de dados para diversas aplicações.
Desafios do RAG agentic
- Qualidade dos dados: Saídas confiáveis exigem dados de alta qualidade e curados. Surgem desafios ao integrar e processar conjuntos de dados diversos, incluindo dados textuais e visuais, para atender aos requisitos de consulta do usuário. Além disso, os processos de recuperação de dados devem garantir precisão e consistência.
- Dica: Implemente ferramentas automatizadas de limpeza de dados e técnicas de validação de dados orientadas por IA para garantir integração de dados consistente e de alta qualidade em conjuntos de dados textuais e visuais.
- Escalabilidade: O gerenciamento eficiente dos recursos do sistema e dos processos de recuperação é crítico à medida que o sistema cresce. À medida que as consultas do usuário e os volumes de dados aumentam, lidar com processamento em tempo real e em lote para recuperação adicional de dados torna-se um desafio significativo.
- Dica: Utilize infraestrutura escalável baseada em nuvem e frameworks de computação distribuída para lidar com cargas de dados crescentes de forma eficiente. Incorpore balanceamento de carga dinâmico para manipulação de consultas em tempo real.
- Explicabilidade: Garantir transparência na tomada de decisão constrói confiança. Fornecer insights claros sobre como as respostas às consultas do usuário são geradas, particularmente ao aproveitar dados textuais e visuais, permanece um desafio persistente.
- Dica: Aproveite ferramentas de explicabilidade de IA como SHAP ou LIME para tornar as previsões do modelo interpretáveis e integre painéis de visualização para esclarecer o raciocínio por trás das respostas.
- Privacidade e segurança: Proteção de dados forte e protocolos de comunicação seguros são essenciais. Gerenciar dados sensíveis ou confidenciais requer criptografia robusta e mecanismos de conformidade durante o armazenamento, recuperação adicional de dados e processamento.
- Dica: Empregue criptografia de ponta a ponta e soluções de gerenciamento de acesso, e garanta conformidade com regulamentos de proteção de dados como GDPR ou CCPA. Use gateways de API seguros para recuperação adicional de dados.
- Preocupações éticas: Abordar viés, justiça e uso indevido é crucial para a implantação responsável de IA. Garantir respostas não tendenciosas a diversas consultas de usuários permanece uma consideração chave no design de IA ética.
- Dica: Implante plataformas de IA responsável e ferramentas de governança de IA para lidar com viés de IA e cumprir com os quatro princípios orientadores da IA.
Perspectivas futuras
As pesquisas mais recentes sobre RAG agentic incluem áreas de melhoria como:
- Integração de grafos de conhecimento: Melhora o raciocínio aproveitando relacionamentos de dados complexos.
- Tecnologias emergentes: Incorporação de ferramentas como ontologias e a web semântica para avançar as capacidades do sistema.
- Colaboração de agentes especializados: Agentes com experiência em diferentes domínios (por exemplo, vendas, marketing, finanças) trabalham juntos em um fluxo de trabalho coordenado para abordar tarefas complexas.
- Otimização da qualidade: Abordar saídas inconsistentes para melhorar a confiabilidade e precisão de sistemas multi-agentes.
Leitura adicional
Explore outros benchmarks de RAG, como:
- Top 10 Modelos de Embedding Multilíngue para RAG
- Modelos de Embedding: OpenAI vs Gemini vs Cohere
- Top 16 Modelos de Embedding de Código Aberto para RAG
- Top Banco de Dados Vetorial para RAG: Qdrant vs Weaviate vs Pinecone
- Benchmark de Re-rankers: Top 8 Modelos Comparados
- Modelos de Embedding Multimodal: Apple vs Meta vs OpenAI
Perguntas frequentes
Geração Aumentada por Recuperação (RAG) é uma técnica que combina métodos baseados em recuperação com modelos generativos para aprimorar a recuperação de informações e a geração de respostas.
Explore mais sobre a técnica de geração aumentada por recuperação e modelos comuns.
Um agente é um programa de computador projetado para observar seu ambiente, tomar decisões e executar ações de forma autônoma para atingir objetivos específicos sem intervenção humana direta.
Uso em Sistemas de IA
Agentes são usados para automatizar tarefas, otimizar processos e tomar decisões inteligentes em ambientes dinâmicos. Dependendo de sua complexidade, os agentes podem variar de sistemas simples baseados em regras a modelos avançados que usam técnicas de aprendizado.
Tipos de Agentes
Agentes Reativos: Operam com base no estado atual do ambiente e seguem regras predefinidas, sem usar experiências passadas.
Agentes Cognitivos: Armazenam experiências passadas e as usam para analisar padrões e tomar decisões, permitindo aprendizado a partir de interações anteriores.
Agentes Colaborativos: Interagem com outros agentes ou sistemas para alcançar objetivos compartilhados, muitas vezes dentro de sistemas multi-agentes onde a coordenação e o compartilhamento de informações são fundamentais.
O RAG agentic pode ser melhor para tarefas que exigem tomada de decisão mais dinâmica e consciente do contexto e interações iterativas, mas sua eficácia depende do caso de uso específico e das necessidades de implementação.
O RAG vanilla recupera e gera respostas passivamente com base em um modelo estático de consulta-resposta, enquanto o RAG agentic incorpora processos iterativos, tomada de decisão e interações dinâmicas para refinar respostas ou lidar com tarefas complexas.
Cite este benchmark
Escolha o formato adequado ao local onde você vai publicar. Colar a versão com link no seu CMS preserva o backlink.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Sarı, Ekrem},
title = {{Top 20+ Frameworks de RAG Agentic}},
year = {2026},
month = jul,
howpublished = {\url{https://aimultiple.com/agentic-rag}},
note = {AIMultiple. Acessado em 17 Julho 2026}
}




Seja o primeiro a comentar
Seu endereço de e-mail não será publicado. Todos os campos são obrigatórios. Os comentários são deixados em seu idioma original.