I migliori 20+ Framework Agentic RAG
L'Agentic RAG potenzia il RAG tradizionale migliorando le prestazioni degli LLM e consentendo una maggiore specializzazione. Abbiamo condotto un benchmark per valutarne le capacità di routing tra più database e di generazione delle query.
Esplora i framework e le librerie agentic RAG, le differenze chiave rispetto al RAG standard, i vantaggi e le sfide per sbloccarne tutto il potenziale.
Benchmark Agentic RAG: routing multi-database e generazione di query
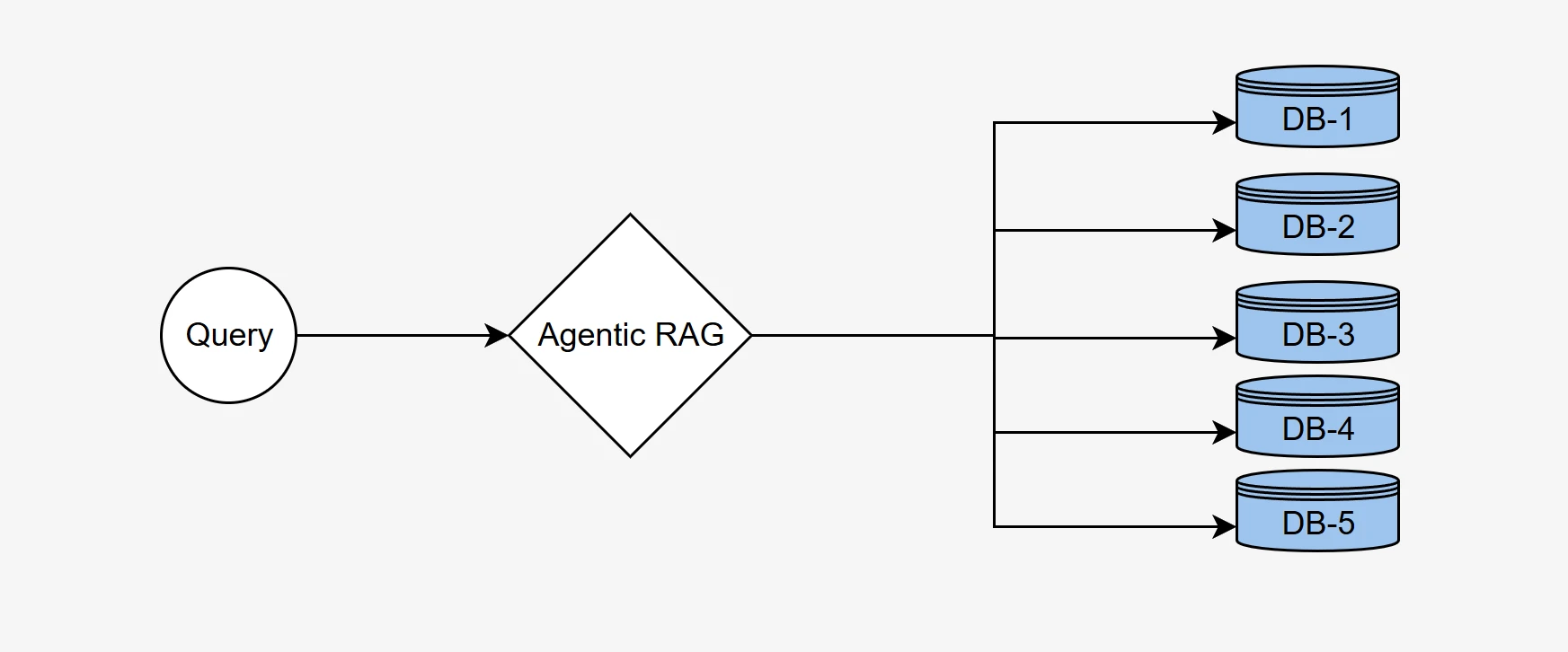
Abbiamo utilizzato la nostra metodologia di benchmark agentic RAG per dimostrare la capacità del sistema di selezionare il database corretto tra cinque database distinti, ciascuno con informazioni contestuali uniche, e di generare query SQL semanticamente accurate per recuperare i dati corretti.
Nel benchmark agentic RAG, abbiamo utilizzato:
- Framework agentico: Langchain
- Database vettoriale: ChromaDB
In molti scenari aziendali reali, i dati sono spesso distribuiti su più database, ciascuno contenente informazioni specializzate pertinenti a domini o compiti specifici. Ad esempio, un database potrebbe memorizzare registri finanziari, mentre un altro contiene dati dei clienti o dettagli di inventario.
Un sistema Agentic RAG efficace deve instradare in modo intelligente la query di un utente verso il database più pertinente per recuperare informazioni accurate. Questo processo implica l'analisi della query, la comprensione del contesto e la selezione della fonte dati appropriata da un insieme di database disponibili.
Processo di pensiero dell'agente
Al cuore di un sistema Agentic RAG risiede la capacità dell'LLM di ragionare e agire autonomamente per raggiungere un obiettivo. Il nostro approccio basato sulla chiamata di funzioni consente ai modelli di dimostrare un vero comportamento agentico attraverso la selezione autonoma del database e la raccolta iterativa di informazioni.
Processo decisionale autonomo: l'agente analizza la query in arrivo e determina autonomamente quale funzione di database chiamare in base al contesto della query e alle descrizioni delle funzioni disponibili. Questo processo decisionale avviene senza regole di instradamento predefinite, dimostrando autentiche capacità di ragionamento.
Esecuzione multi-step: l'agente esegue tipicamente più chiamate di funzione in sequenza, prima per identificare e accedere al database pertinente, poi per raccogliere informazioni dettagliate sullo schema e infine per affinare la sua comprensione prima di generare la query SQL. Questo processo iterativo rispecchia gli approcci umani alla risoluzione dei problemi.
Capacità di autocorrezione: quando le chiamate iniziali non forniscono informazioni sufficienti, l'agente può decidere autonomamente di effettuare chiamate aggiuntive con parametri perfezionati, dimostrando un comportamento adattivo che va oltre i semplici sistemi di recupero.
Comportamento orientato agli obiettivi: durante tutto il processo, l'agente mantiene l'attenzione sulla generazione di una query SQL accurata, utilizzando il risultato di ogni chiamata di funzione per informare le decisioni e le azioni successive.
Questo pattern di interazione autonomo e multi-turno differenzia fondamentalmente l'agentic RAG dai sistemi RAG tradizionali che seguono percorsi prestabiliti e meccanismi di recupero a colpo singolo.
Metodologia del benchmark Agentic RAG
Questo benchmark valuta la capacità dei Large Language Models (LLM) di operare come agenti autonomi all'interno di una pipeline di Retrieval-Augmented Generation (RAG). In particolare, misura due competenze fondamentali:
- Instradamento del database: la capacità dell'agente di identificare e selezionare correttamente il database più pertinente tra più candidati data una domanda in linguaggio naturale.
- Generazione di SQL: la capacità dell'agente di generare una query SQL accurata utilizzando lo schema del database selezionato.
Dataset
Il benchmark utilizza il dataset BIRD-SQL1 , un benchmark accademico ampiamente adottato per compiti text-to-SQL. BIRD-SQL fornisce domande in linguaggio naturale abbinate a identificatori di database di riferimento e query SQL gold-standard, rendendolo ideale per valutare sia l'accuratezza dell'instradamento che la qualità della generazione delle query.
Dal dataset completo BIRD-SQL, abbiamo curato un sottoinsieme di 500 domande distribuite su cinque database distinti che coprono diversi domini:
Ogni domanda ha esattamente un database di destinazione corretto. La risposta a ogni domanda risiede in un database specifico, richiedendo all'agente di prendere una decisione di instradamento definitiva.
Sfida dell'ambiguità semantica
Per valutare le capacità di ragionamento dell'agente al di là del semplice abbinamento di parole chiave superficiali, abbiamo introdotto la similarità semantica tra database diversi come fattore confondente deliberato durante la selezione delle domande.
Processo di selezione delle domande:
- Tutte le domande candidate dai cinque database sono state incorporate utilizzando sentence transformers (
all-MiniLM-L6-v2). - Sono state calcolate e classificate per similarità coseno le coppie di domande tra database diversi.
- Le domande con punteggi di similarità coseno superiori a 0.70 sono state intenzionalmente prioritarie per l'inclusione, creando scenari in cui domande semanticamente simili appartengono a database completamente diversi.
Esempio di confondimento semantico:
Domanda A (DB finanziario): “Per il cliente il cui prestito è stato approvato per primo il 1993/7/5, qual è il tasso di incremento del suo saldo del conto dal 1993/3/22 al 1998/12/27?”
Domanda B (DB carte di debito): “Per il cliente che ha pagato 634.8 nel 2012/8/25, qual è stato il tasso di diminuzione dei consumi dall'anno 2012 al 2013?”
Entrambe le domande seguono pattern semantici quasi identici: identificano un cliente specifico attraverso un evento transazionale, poi calcolano una variazione percentuale su un periodo di tempo. Eppure i database corretti sono completamente diversi; uno richiede dati su prestiti e conti, mentre l'altro necessita di dati su transazioni e consumi. Questo costringe l'agente a eseguire un ragionamento contestuale più approfondito sul dominio dei dati anziché basarsi su parole chiave finanziarie superficiali che corrisponderebbero a entrambi i database.
Ambiente dei database
Lo schema e una breve descrizione in linguaggio naturale di ciascun database sono stati memorizzati in ChromaDB, un database vettoriale utilizzato per un recupero semantico efficiente. La collezione di ogni database contiene:
- Una descrizione di alto livello del dominio e dello scopo del database
- Documenti dello schema per tabella, inclusi nomi delle colonne, tipi di dati e descrizioni dei valori
Questa configurazione consente all'agente di recuperare informazioni pertinenti sullo schema tramite ricerca semantica dopo aver selezionato un database di destinazione.
Architettura dell'agente
Un'architettura agentica basata sulla chiamata di funzioni è stata impiegata su tutti i modelli per garantire un confronto equo e standardizzato. Ciascuno dei cinque database è stato rappresentato come una funzione chiamabile distinta (strumento) con parametri standardizzati. Questo design sfrutta le capacità native di chiamata di funzione di ciascun modello, consentendo ai modelli di:
- Analizzare la domanda in arrivo
- Selezionare e invocare la funzione di database appropriata
- Ricevere informazioni sullo schema come risposta della funzione
- Invocare opzionalmente funzioni aggiuntive per il perfezionamento
- Generare la query SQL finale
Questo approccio mantiene una metodologia di valutazione coerente tra diverse famiglie di modelli, inclusi modelli tradizionali e modelli ottimizzati per il ragionamento.
Flusso del processo agentico
Il sistema implementa un autentico ciclo agentico multi-turno anziché una pipeline fissa:
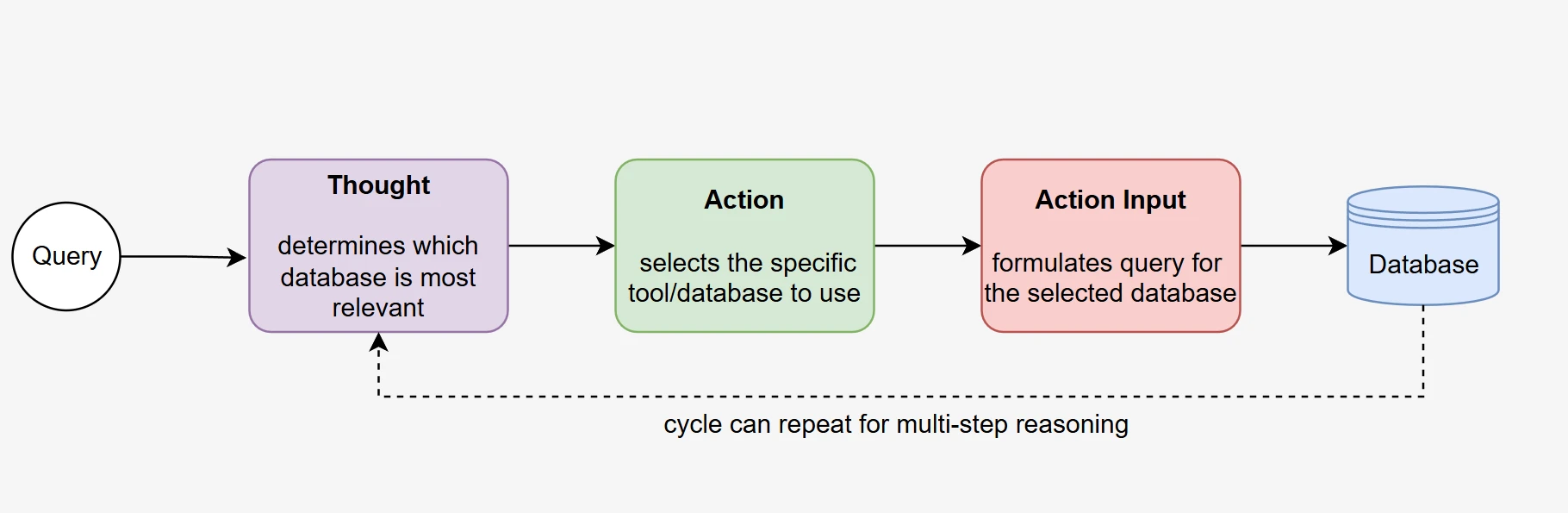
- Analisi della domanda: l'agente riceve la domanda in linguaggio naturale insieme alle descrizioni di tutte e cinque le funzioni di database disponibili.
- Selezione del database (chiamata dello strumento): l'agente seleziona e chiama autonomamente la funzione di database che ritiene più pertinente. Si tratta di una vera chiamata di funzione; l'agente riceve lo schema come risposta strutturata dello strumento all'interno dello stesso contesto conversazionale.
- Ragionamento sullo schema: l'agente osserva lo schema restituito e ragiona su quali tabelle e colonne siano pertinenti alla domanda.
- Ripristino opzionale: se l'agente determina che il database selezionato non contiene le informazioni richieste, può chiamare una funzione di database diversa, consentendo l'autocorrezione senza intervento esterno.
- Generazione di SQL: sulla base del contesto accumulato (domanda + osservazione dello schema), l'agente produce la query SQL finale.
Questo flusso conversazionale multi-turno differenzia il benchmark dagli approcci tradizionali a colpo singolo del RAG. L'agente mantiene il contesto completo attraverso i turni, può osservare i risultati delle sue azioni e può affinare iterativamente il suo approccio, segni distintivi di un autentico comportamento agentico.
Proprietà architetturali chiave:
- La conversazione è continua; l'agente vede il proprio ragionamento precedente e le risposte degli strumenti
- Non vengono imposti limiti artificiali ai turni; l'agente decide quando ha informazioni sufficienti
- Sia la selezione del database che la generazione di SQL avvengono all'interno della stessa sessione agentica
- Il numero di chiamate agli strumenti per domanda viene registrato come metrica aggiuntiva per analizzare l'efficienza dell'agente
Processo di valutazione
Per ogni domanda nel benchmark:
Fase 1: Valutazione dell'instradamento del database
La prima chiamata di funzione di database dell'agente viene registrata come la sua decisione di instradamento. Questa viene confrontata con il database di riferimento specificato nel dataset BIRD-SQL.
Metrica: accuratezza dell'instradamento del database (percentuale di selezioni corrette sul totale delle domande)
Fase 2: Valutazione della qualità dell'SQL
La query SQL generata dall'agente viene valutata utilizzando un approccio LLM-come-Giudice. Un modello giudice separato (Claude 4 Sonnet) riceve sia l'SQL generato dall'agente che l'SQL di riferimento BIRD-SQL, e assegna un punteggio di similarità semantica su una scala 0–5:
Decisione di progettazione importante: la qualità dell'SQL viene valutata quando l'agente seleziona il database corretto. Se l'agente ha instradato verso il database sbagliato, riceve un punteggio automatico di 0, poiché una query SQL su uno schema errato è intrinsecamente priva di significato. Ciò garantisce che la metrica di qualità dell'SQL rifletta puramente la capacità di generazione delle query, non contaminata da errori di instradamento.
Metriche:
- Punteggio medio di qualità dell'SQL (su 5.0), calcolato sulle domande instradate correttamente
- Tasso di corrispondenza perfetta: percentuale di domande instradate correttamente che ottengono 5/5
Variabili controllate
Per garantire un confronto equo tra i modelli:
- Tutti i modelli ricevono prompt di sistema e definizioni degli strumenti identici
- La temperatura è impostata a 0 per output deterministici
- Nessuna ingegneria dei prompt specifica per modello o esempi few-shot forniti (valutazione zero-shot)
- Il campo evidence di BIRD-SQL (suggerimenti specifici del dominio) è negato a tutti i modelli per misurare il ragionamento non assistito
- Tutti i modelli accedono alla stessa istanza ChromaDB con embedding dello schema identici
Framework e librerie Agentic RAG
I framework Agentic RAG consentono ai sistemi IA di trovare informazioni, ragionare, prendere decisioni e agire. Principali strumenti e librerie che alimentano l'Agentic RAG:
Questo elenco include strumenti che soddisfano i seguenti criteri:
- 50+ stelle su GitHub.
- Uso comune in progetti Agentic RAG.
Nota bene: nella tabella:
- Uso degli strumenti si riferisce alla capacità nativa di un sistema di instradare e chiamare strumenti all'interno del suo ambiente.
- Tipo di strumento si riferisce all'area di utilizzo principale degli strumenti, come ad esempio:
- Framework Agentic RAG sono progettati specificamente per costruire, distribuire o configurare sistemi Agentic RAG.
- Librerie per agenti consentono la creazione di agenti intelligenti in grado di ragionare, prendere decisioni ed eseguire compiti multi-step.
- Framework LLMOps gestiscono il ciclo di vita degli LLM e ottimizzano la distribuzione e l'uso degli LLM all'interno di sistemi basati su agenti.
- LLM che hanno capacità integrate di chiamata e instradamento degli strumenti, consentendo un processo decisionale dinamico. Altri LLM possono richiedere API esterne o integrazioni per abilitare la funzionalità di agente.
- Verifica dell'uso degli strumenti e dei tipi di agenti è ottenuta tramite fonti pubbliche.
Cos'è l'Agentic RAG?
L'Agentic Retrieval-Augmented Generation (RAG) è un framework di IA che combina tecniche di recupero con modelli generativi per consentire un processo decisionale dinamico e la sintesi della conoscenza. Questo approccio integra l'accuratezza del RAG tradizionale con le capacità generative dell'IA avanzata, con l'obiettivo di migliorare l'efficienza e l'efficacia dei compiti guidati dall'IA.
Limitazioni dei sistemi RAG tradizionali
L'Agentic RAG mira a superare le limitazioni riscontrate nel sistema RAG standard, quali:
- Difficoltà nella prioritizzazione delle informazioni: i sistemi RAG spesso faticano a gestire e prioritizzare efficientemente i dati all'interno di grandi dataset, il che può ridurre le prestazioni complessive.
- Integrazione limitata della conoscenza esperta: questi sistemi possono sottovalutare contenuti specializzati e di alta qualità, favorendo invece informazioni generiche.
- Comprensione contestuale debole: pur essendo in grado di recuperare dati, spesso non riescono a comprenderne appieno la pertinenza o il modo in cui si allineano con la query specifica.
Come costruire un Agentic RAG
1. Uso degli strumenti
- Utilizzare i router: il primo passo consiste nell'impiegare router per determinare se recuperare documenti, eseguire calcoli o riscrivere la query. Questo approccio aggiunge capacità decisionali per instradare le richieste a più strumenti, consentendo ai large language models (LLM) di selezionare le pipeline appropriate.
- Integrazione della chiamata degli strumenti: si riferisce alla creazione di un'interfaccia che consenta agli agenti di connettersi con gli strumenti selezionati. Gli utenti possono sfruttare LLM con capacità di chiamata degli strumenti o costruirne di propri per:
- Scegliere una funzione da eseguire.
- Dedurre gli argomenti necessari per quella funzione.
- Migliorare la comprensione delle query oltre le pipeline RAG tradizionali, consentendo compiti come interrogazioni di database o ragionamento complesso.
2. Implementazione dell'agente
- Agenti a chiamata singola: una query attiva una singola chiamata allo strumento appropriato, restituendo la risposta. Questo è efficace per compiti semplici, ma può incontrare difficoltà con query vaghe o complesse.
- Agenti a più chiamate: questo approccio prevede la suddivisione dei compiti tra agenti specializzati, con ciascun agente focalizzato su un sottocompito specifico. Ad esempio:
- Agente recuperatore: ottimizza il recupero delle query in tempo reale.
- Agente gestore: gestisce la delega e l'orchestrazione dei compiti.
3. Ragionamento multi-step
Per flussi di lavoro complessi, gli agenti utilizzano cicli di ragionamento per eseguire ragionamenti iterativi multi-step, conservando la memoria dei passaggi intermedi. Questi cicli comportano:
- Chiamare più strumenti.
- Recuperare dati e convalidarne la pertinenza.
- Riscrivere le query secondo necessità.
I framework spesso definiscono più agenti per gestire sottocompiti specifici, garantendo un'esecuzione efficiente del processo complessivo.
4. Approcci ibridi: combinare recupero ed esecuzione
Un approccio ibrido combina le pipeline di recupero con strategie di esecuzione dinamica:
- Strategie di embedding e recupero vettoriale per l'accesso ai documenti.
- Capacità di chiamata degli strumenti per la risoluzione dinamica delle query.
- Collaborazione multi-agente per sottocompiti specializzati.
Qual è la differenza tra RAG e Agentic RAG?
Ecco i punti di forza e di debolezza del RAG rispetto all'Agentic RAG in base a diversi aspetti:
- Ingegneria dei prompt
- RAG tradizionale: si basa fortemente sull'ottimizzazione manuale dei prompt.
- Agentic RAG: adatta dinamicamente i prompt in base al contesto e agli obiettivi, riducendo la necessità di intervento manuale.
- Consapevolezza contestuale
- RAG tradizionale: ha una consapevolezza contestuale limitata e si basa su processi di recupero statici.
- Agentic RAG: considera la cronologia della conversazione e adatta dinamicamente le strategie di recupero in base al contesto.
- Autonomia
- RAG tradizionale: manca di azioni autonome e non può adattarsi a situazioni in evoluzione.
- Agentic RAG: esegue azioni in tempo reale e si adatta in base a feedback e osservazioni in tempo reale.
- Ragionamento
- RAG tradizionale: richiede classificatori e modelli aggiuntivi per il ragionamento multi-step e l'uso degli strumenti.
- Agentic RAG: gestisce il ragionamento multi-step internamente, eliminando la necessità di modelli esterni.
- Qualità dei dati
- RAG tradizionale: non ha un meccanismo integrato per valutare la qualità dei dati o garantire l'accuratezza.
- Agentic RAG: valuta la qualità dei dati ed esegue controlli post-generazione per garantire output accurati.
- Flessibilità
- RAG tradizionale: opera su regole statiche, limitando l'adattabilità.
- Agentic RAG: impiega strategie di recupero dinamiche e adatta il suo approccio secondo necessità.
- Efficienza di recupero
- RAG tradizionale: il recupero è statico e spesso costoso a causa di inefficienze.
- Agentic RAG: ottimizza i recuperi per ridurre al minimo le operazioni non necessarie, riducendo i costi e migliorando l'efficienza.
- Semplicità
- RAG tradizionale: presenta una configurazione semplice con minori complessità di configurazione.
- Agentic RAG: comporta configurazioni più complesse per supportare operazioni dinamiche e consapevoli del contesto.
- Prevedibilità
- RAG tradizionale: coerente e basato su regole, ma rigido nel comportamento.
- Agentic RAG: il comportamento può variare dinamicamente in base al contesto e alle osservazioni in tempo reale.
- Costo nelle implementazioni
- RAG tradizionale: più economico per configurazioni di base, ma può comportare costi operativi a lungo termine più elevati.
- Agentic RAG: richiede un investimento iniziale più elevato a causa delle funzionalità avanzate e delle capacità dinamiche.
Modelli a contesto lungo vs Agentic RAG: quando il recupero diventa superfluo
La rivoluzione della finestra di contesto del 2025-2026 mette in discussione un presupposto fondamentale nell'architettura RAG. I modelli ora supportano 1-2 milioni di token, sollevando una domanda fondamentale: quando l'elaborazione diretta del contesto supera i complessi agenti di recupero?
Il panorama contestuale in evoluzione
Le finestre di contesto si sono ampliate notevolmente da 128k token all'inizio del 2024 a oltre 1M nel 2026. Ricerche recenti che utilizzano romanzi completi come dati di test rivelano che questa espansione crea nuovi compromessi architetturali che gli ingegneri devono considerare.4
Il costo computazionale dell'elaborazione di contesti enormi deve essere soppesato rispetto alla complessità ingegneristica e ai potenziali punti di fallimento dei sistemi di recupero. Elaborare 1M token elimina la compressione con perdita di suddivisione in chunk e indicizzazione, ma a un costo per query elevato.
Il problema del collo di bottiglia del recupero
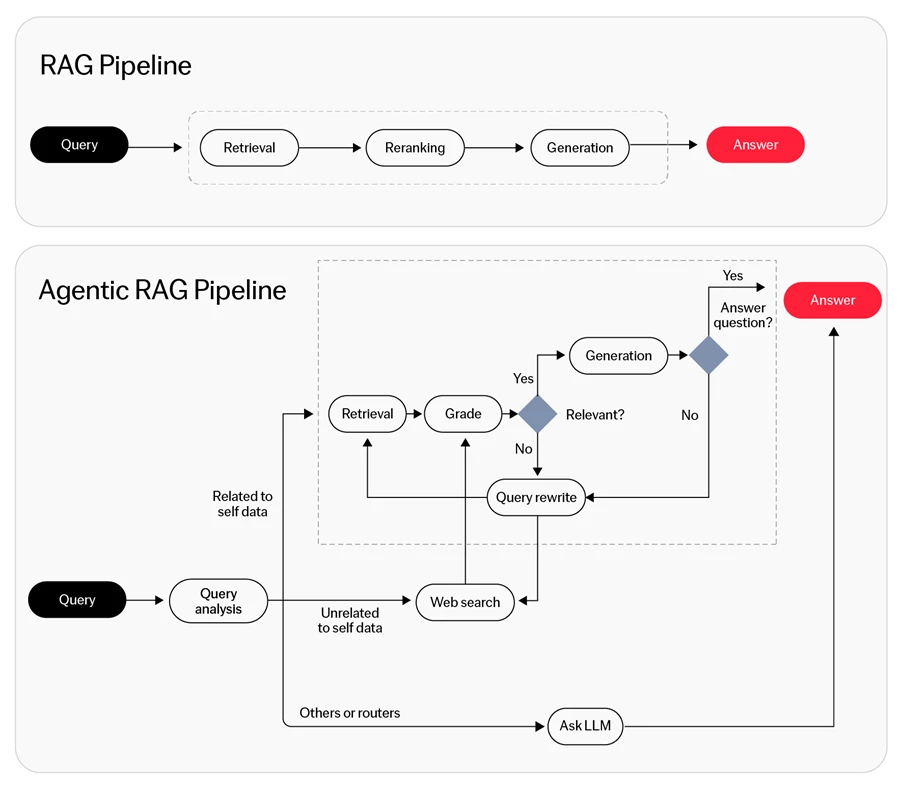
La ricerca sui documenti di lunga durata identifica una grave limitazione negli approcci RAG tradizionali. Il recupero top-k standard crea ciò che i ricercatori chiamano un "collo di bottiglia del recupero": quando il recupero iniziale non coglie il chunk pertinente, il sistema manca di un meccanismo di ripristino.
L'Agentic RAG affronta questo problema attraverso il perfezionamento iterativo delle query. Gli studi dimostrano che i sistemi agentici risolvono con successo una parte significativa dei problemi che falliscono completamente con il recupero a colpo singolo. Il ciclo autonomo consente agli agenti di riformulare le query quando i tentativi iniziali restituiscono informazioni insufficienti.5
Tuttavia, quando i dati rientrano nelle finestre di contesto ampliate, l'elaborazione diretta a contesto lungo supera anche i sofisticati sistemi di recupero agentico. Il divario prestazionale esiste perché il modello può ragionare sull'intero documento simultaneamente, evitando la frammentazione intrinseca nel recupero basato su chunk.
Diversi tipi di modelli Agentic RAG
Alcuni degli agenti che sfruttano i Large Language Models (LLM) all'interno dei framework di Retrieval-Augmented Generation (RAG) includono:
- Agente di instradamento: utilizza un Large Language Model (LLM) per il ragionamento agentico al fine di selezionare la pipeline di Retrieval-Augmented Generation (RAG) più appropriata (ad esempio, riassunto o risposta a domande) per una data query. L'agente determina la scelta migliore analizzando la query in input.
- Agente di pianificazione delle query a colpo singolo: scompone query complesse in sotto-query più piccole, le esegue su varie pipeline RAG con diverse fonti di dati e combina i risultati in una risposta completa.
- Agente per l'uso degli strumenti: migliora i framework RAG standard incorporando fonti di dati esterne (ad esempio, API, database) per fornire contesto aggiuntivo. Ciò consente un'elaborazione più arricchita delle query utilizzando gli LLM.
- Agente ReAct: integra ragionamento e azione per gestire query sequenziali e multi-parte. Mantiene uno stato in memoria e invoca iterativamente strumenti, elabora i loro output e determina i passaggi successivi fino a quando la query non è completamente risolta.
- Agente di pianificazione ed esecuzione dinamica: mirato a gestire query più complesse, questo agente separa la pianificazione di alto livello dall'esecuzione. Utilizza un LLM come pianificatore per progettare un grafo computazionale dei passaggi necessari per rispondere alla query e impiega un esecutore per svolgere questi passaggi in modo efficiente. L'attenzione è rivolta all'affidabilità, all'osservabilità, alla parallelizzazione e all'ottimizzazione per ambienti di produzione.
Vantaggi dell'Agentic RAG
L'Agentic RAG migliora gli LLM attraverso:
- Approccio autonomo e orientato agli obiettivi: a differenza del RAG tradizionale, l'Agentic RAG agisce come un agente autonomo, prendendo decisioni per raggiungere obiettivi definiti e perseguire interazioni più profonde e significative.
- Maggiore consapevolezza e sensibilità contestuale: l'Agentic RAG considera dinamicamente la cronologia della conversazione, le preferenze dell'utente, le interazioni precedenti e il contesto attuale per fornire risposte pertinenti e informate e un processo decisionale.
- Recupero dinamico e ragionamento avanzato: utilizza metodi di recupero intelligenti adattati alle query, valutando e verificando al contempo l'accuratezza e l'affidabilità dei dati recuperati.
- Orchestrazione multi-agente: coordina più agenti specializzati, suddividendo le query in compiti gestibili e garantendo un coordinamento senza soluzione di continuità per fornire risultati accurati.
- Maggiore accuratezza con verifica post-generazione: i modelli Agentic RAG eseguono controlli di qualità sul contenuto generato, garantendo la migliore risposta possibile e combinando gli LLM con sistemi basati su agenti per prestazioni superiori.
- Adattabilità e apprendimento: questi sistemi apprendono e migliorano continuamente nel tempo, potenziando le capacità di risoluzione dei problemi, l'accuratezza e l'efficienza, e adattandosi a vari domini per compiti specifici.
- Utilizzo flessibile degli strumenti: gli agenti possono sfruttare strumenti esterni come motori di ricerca, database o API per migliorare la raccolta, l'elaborazione e la personalizzazione dei dati per diverse applicazioni.
Sfide dell'Agentic RAG
- Qualità dei dati: output affidabili richiedono dati curati e di alta qualità. Le sfide sorgono quando si integrano ed elaborano dataset diversi, inclusi dati testuali e visivi, per soddisfare i requisiti delle query degli utenti. Inoltre, i processi di recupero dei dati devono garantire accuratezza e coerenza.
- Suggerimento: implementare strumenti automatizzati di pulizia dei dati e tecniche di validazione dei dati guidate dall'IA per garantire un'integrazione dei dati coerente e di alta qualità tra dataset testuali e visivi.
- Scalabilità: una gestione efficiente delle risorse di sistema e dei processi di recupero è fondamentale man mano che il sistema cresce. Con l'aumentare del volume delle query degli utenti e dei dati, gestire sia l'elaborazione in tempo reale che quella batch per un ulteriore recupero dei dati diventa una sfida significativa.
- Suggerimento: utilizzare un'infrastruttura cloud scalabile e framework di calcolo distribuito per gestire in modo efficiente i carichi di dati crescenti. Incorporare il bilanciamento dinamico del carico per la gestione delle query in tempo reale.
- Spiegabilità: garantire la trasparenza nel processo decisionale crea fiducia. Fornire chiare indicazioni su come vengono generate le risposte alle query degli utenti, in particolare quando si sfruttano dati testuali e visivi, rimane una sfida persistente.
- Suggerimento: sfruttare strumenti di spiegabilità dell'IA come SHAP o LIME per rendere interpretabili le previsioni del modello e integrare dashboard di visualizzazione per chiarire il ragionamento alla base delle risposte.
- Privacy e sicurezza: sono essenziali una solida protezione dei dati e protocolli di comunicazione sicuri. La gestione di dati sensibili o confidenziali richiede meccanismi di crittografia e conformità robusti durante l'archiviazione, l'ulteriore recupero dei dati e l'elaborazione.
- Suggerimento: impiegare la crittografia end-to-end e soluzioni di gestione degli accessi, e garantire la conformità alle normative sulla protezione dei dati come il GDPR o il CCPA. Utilizzare gateway API sicuri per un ulteriore recupero dei dati.
- Preoccupazioni etiche: affrontare i pregiudizi, l'equità e l'uso improprio è fondamentale per un'implementazione responsabile dell'IA. Garantire risposte imparziali alle diverse query degli utenti rimane una considerazione chiave nella progettazione di un'IA etica.
- Suggerimento: implementare piattaforme di IA responsabile e strumenti di governance dell'IA per far fronte ai pregiudizi dell'IA e rispettare i quattro principi guida dell'IA.
Prospettive future
Le ricerche più recenti sull'Agentic RAG includono aree di miglioramento come:
- Integrazione di grafi di conoscenza: migliora il ragionamento sfruttando relazioni complesse tra i dati.
- Tecnologie emergenti: incorporazione di strumenti come ontologie e web semantico per avanzare le capacità del sistema.
- Collaborazione tra agenti specializzati: agenti con esperienza in diversi domini (ad esempio, vendite, marketing, finanza) lavorano insieme in un flusso di lavoro coordinato per affrontare compiti complessi.
- Ottimizzazione della qualità: affrontare l'incoerenza dell'output per migliorare l'affidabilità e la precisione dei sistemi multi-agente.
Ulteriori letture
Esplora altri benchmark RAG, come:
- I migliori 10 modelli di embedding multilingue per il RAG
- Modelli di embedding: OpenAI vs Gemini vs Cohere
- I migliori 16 modelli di embedding open source per il RAG
- Il miglior database vettoriale per il RAG: Qdrant vs Weaviate vs Pinecone
- Benchmark dei reranker: i migliori 8 modelli a confronto
- Modelli di embedding multimodali: Apple vs Meta vs OpenAI
FAQ
La Retrieval-Augmented Generation (RAG) è una tecnica che combina metodi basati sul recupero con modelli generativi per migliorare il recupero delle informazioni e la generazione di risposte.
Scopri di più sulla tecnica della retrieval-augmented generation e sui modelli comuni.
Un agente è un programma per computer progettato per osservare il proprio ambiente, prendere decisioni ed eseguire azioni in modo autonomo per raggiungere obiettivi specifici senza un intervento umano diretto.
Utilizzo nei sistemi IA
Gli agenti sono utilizzati per automatizzare compiti, ottimizzare i processi e prendere decisioni intelligenti in ambienti dinamici. A seconda della loro complessità, gli agenti possono variare da semplici sistemi basati su regole a modelli avanzati che utilizzano tecniche di apprendimento.
Tipi di agenti
Agenti reattivi: operano in base allo stato attuale dell'ambiente e seguono regole predefinite, senza utilizzare esperienze passate.
Agenti cognitivi: memorizzano le esperienze passate e le utilizzano per analizzare schemi e prendere decisioni, consentendo l'apprendimento dalle interazioni precedenti.
Agenti collaborativi: interagiscono con altri agenti o sistemi per raggiungere obiettivi condivisi, spesso all'interno di sistemi multi-agente dove il coordinamento e la condivisione delle informazioni sono fondamentali.
L'Agentic RAG può essere migliore per compiti che richiedono un processo decisionale più dinamico e consapevole del contesto e interazioni iterative, ma la sua efficacia dipende dal caso d'uso specifico e dalle esigenze di implementazione.
Il RAG vanilla recupera e genera risposte passivamente sulla base di un modello statico di query-risposta, mentre l'Agentic RAG incorpora processi iterativi, processo decisionale e interazioni dinamiche per perfezionare le risposte o gestire compiti complessi.
Cita questo benchmark
Scegli il formato adatto a dove pubblicherai. Incollare la versione con link nel tuo CMS preserva il backlink.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Sarı, Ekrem},
title = {{I migliori 20+ Framework Agentic RAG}},
year = {2026},
month = jul,
howpublished = {\url{https://aimultiple.com/agentic-rag}},
note = {AIMultiple. Consultato il 17 Luglio 2026}
}




Sii il primo a commentare
Il tuo indirizzo email non verrà pubblicato. Tutti i campi sono obbligatori. I commenti vengono lasciati nella loro lingua originale.