RAG Strumenti di osservabilità - Benchmark
Abbiamo effettuato un benchmark di quattro piattaforme di osservabilità RAG su una pipeline LangGraph a 7 nodi, valutandole in base a tre dimensioni pratiche: overhead di latenza, sforzo di integrazione e compromessi tra le piattaforme.
Metriche del sovraccarico di latenza
Spiegazione delle metriche:
La media rappresenta la latenza media calcolata su 150 chiamate graph.invoke() misurate. Le valutazioni di LLM-judge vengono eseguite dopo l'arresto del timer.
La mediana corrisponde alla latenza al 50° percentile. Le risposte dell'API LLM presentano code lunghe, pertanto la mediana è un indicatore migliore delle prestazioni tipiche delle query.
P95 rappresenta il 95° percentile, ovvero la latenza peggiore per il 95% delle query.
Overhead vs baseline è la differenza di latenza media tra la piattaforma e la linea di base non monitorata.
Per comprendere nel dettaglio la nostra valutazione e le metriche utilizzate, consultare la metodologia di benchmarking per gli strumenti di osservabilità RAG.
Sforzo di integrazione da parte della piattaforma
Principali risultati
La varianza dell'API LLM è trascurabile rispetto al sovraccarico di monitoraggio.
La deviazione standard di base era di 2.645 ms. Il sovraccarico maggiore era di 169 ms. Sarebbe necessario rimuovere LLM dalla pipeline per misurare il sovraccarico dell'SDK in isolamento. I benchmark a singola esecuzione degli strumenti di monitoraggio misurano la varianza dell'API, non il sovraccarico dell'SDK.
LangSmith richiede il minor codice di integrazione
12 righe aggiunte rispetto alla versione base (2 variabili d'ambiente). Gli strumenti basati su decoratori (Weave, Laminar, Langfuse) richiedono 29-40 righe. Il compromesso: LangSmith cattura tutto (incluse le chiamate interne di LangChain che potrebbero non essere necessarie), mentre gli strumenti basati su decoratori offrono un controllo esplicito su ciò che viene tracciato.
Solo Langfuse e Laminar offrono l'hosting autonomo gratuito
Entrambi sono open source (MIT e Apache 2.0). LangSmith e Weave richiedono contratti aziendali per le implementazioni self-hosted.
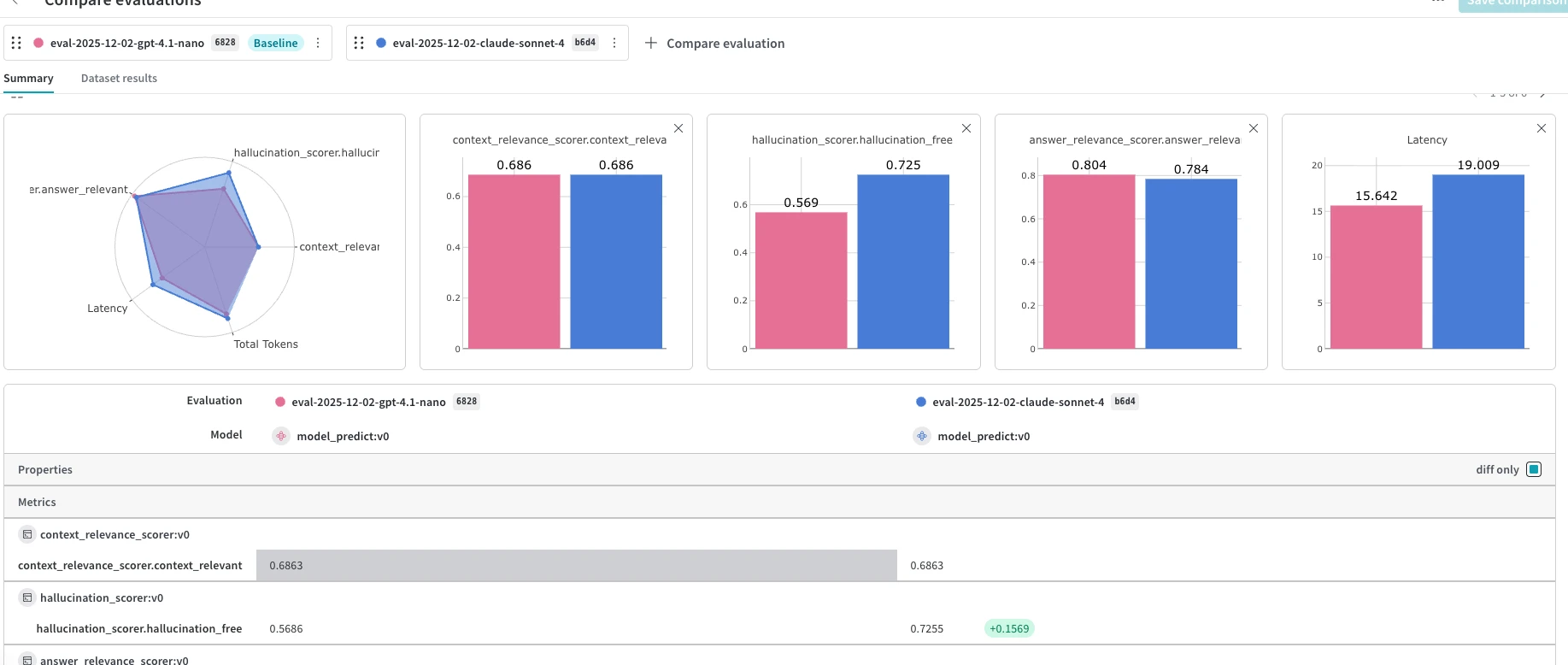
Weave e LangSmith guidano il coordinamento della valutazione.
Entrambi offrono orchestratori di valutazione completi che gestiscono l'iterazione del dataset, la previsione, l'assegnazione dei punteggi e l'aggregazione in un'unica chiamata. Langfuse fornisce l'infrastruttura per l'assegnazione dei punteggi ( create_score() ) ma lascia l'orchestrazione allo sviluppatore. Le funzionalità di valutazione di Laminar sono meno mature: manca un'interfaccia utente per il confronto degli esperimenti e i scorer predefiniti sono limitati.
Langfuse ha il costo unitario più basso in termini di volume
6 dollari ogni 100.000 unità per oltre 50 milioni di dati. LangSmith addebita per traccia (da 2,50 a 5 dollari ogni 1.000 unità). Weave addebita per MB di dati ingeriti (0,10 dollari per MB in eccesso).
Capacità di valutazione per piattaforma
Pesi e diagonali (Tessuta)
- L'orchestratore di valutazione:
weave.Evaluation.evaluate()gestisce l'iterazione del dataset, la previsione, l'assegnazione del punteggio e l'aggregazione in un'unica chiamata. 1 - Scorer personalizzati: sottoclasse
Scorero qualsiasi funzione@weave.op() - Valutatori predefiniti: Alcuni (correttezza, ecc.)
- Gestione del dataset:
weave.Datasetcon versioning,publish(),from_pandas() - Confronto degli esperimenti: scheda Valutazioni con vista Confronta + Classifiche
- Valutazione online:
EvaluationLogger, guardrail/monitor
LangSmith
- Orchestratore Eval: funzione
evaluate()2 - Punteggio personalizzati:
(Run, Example) -> dict - Valutatori predefiniti: Sì (correttezza del controllo qualità, distanza di embedding, giudice LLM basato su criteri)
- Gestione dei dataset: API CRUD completa, dataset con versioni.
- Confronto degli esperimenti: confronto affiancato per ciascun set di dati.
- Valutazione online: code di annotazione, regole automatizzate sulle tracce di produzione
Laminare
- Orchestratore di valutazione: è disponibile
evaluate()di base, ma è meno utilizzata. 3 - Scorer personalizzati: funzioni decorate
@observe() - Segnapunti predefiniti: Minimo
- Gestione dei dataset: interfaccia utente + SDK limitato
- Confronto degli esperimenti: Manuale
- Valutazione online:
@observe()sulle funzioni di produzione
Langfuse
- Orchestratore di valutazione: nessun orchestratore integrato. Ciclo manuale +
create_score()per traccia 4 - Punteggio personalizzato: qualsiasi codice +
create_score(trace_id, name, value) - Scorer preconfigurati: configurazioni di valutazione basate su modelli nell'interfaccia utente
- Gestione dei dataset: dataset UI + API
- Confronto degli esperimenti: Manuale (filtraggio della sessione)
- Valutazione online:
create_score()su tracce in tempo reale, code di annotazione umana
Confronto prezzi
Piano gratuito e conservazione dei dati
Piani a pagamento e prezzi in base all'utilizzo.
I prezzi indicati si riferiscono a marzo 2026 e potrebbero subire variazioni nel tempo. Si prega di consultare il sito web di ciascun fornitore per le tariffe più aggiornate.
Implementazione in cloud, self-hosted e open-source
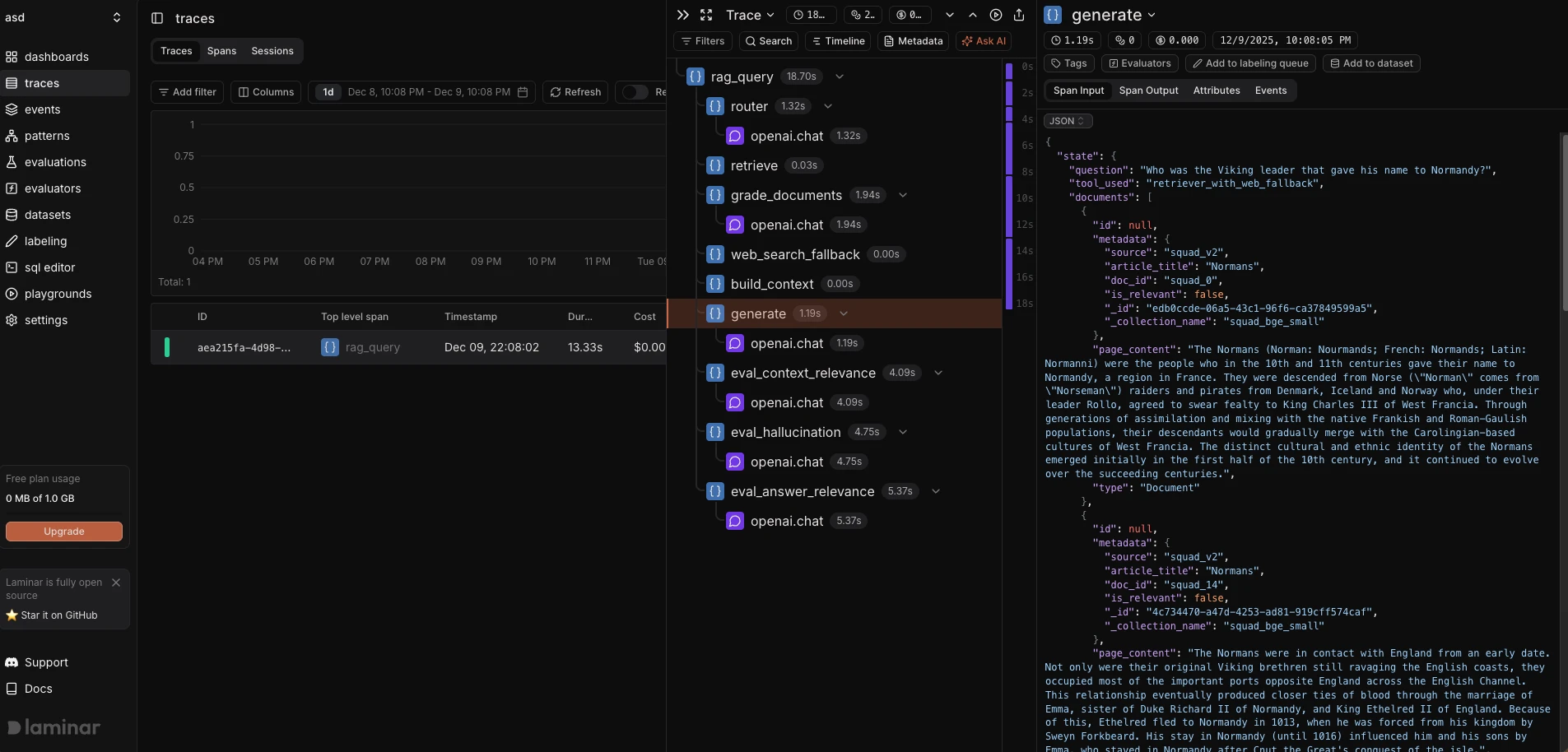
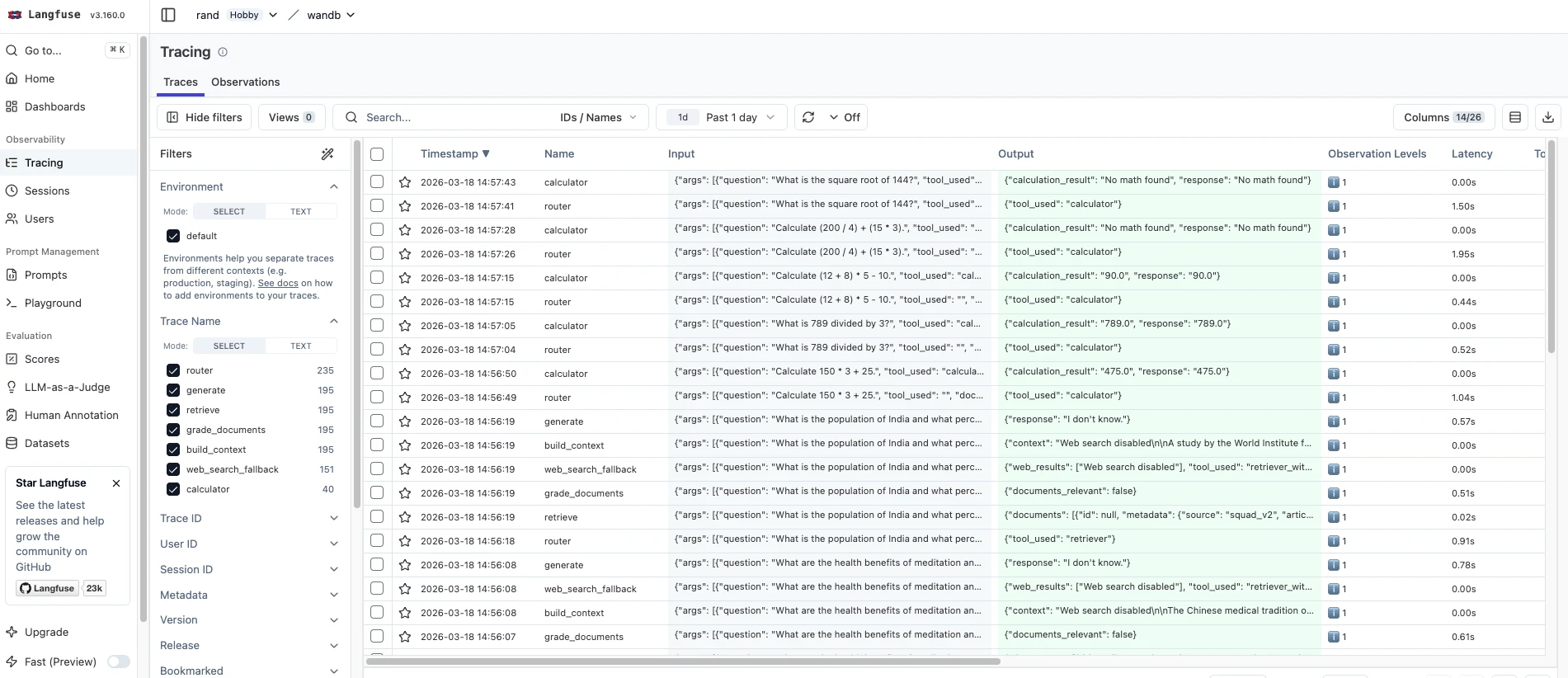
Visibilità di tracciamento e debug
- Weave mostra una visualizzazione ad albero delle chiamate decorate con
@weave.op(). Cliccando su un nodo vengono visualizzati input, output e tempi. La scheda Evals collega le tracce ai risultati della valutazione. - LangSmith acquisisce automaticamente l'intero grafico di esecuzione di LangChain, inclusi i passaggi interni della catena. La visualizzazione della traccia include il conteggio dei token, la ripartizione della latenza e le stime dei costi per ogni chiamata LLM.
- Langfuse visualizza le tracce con intervalli. Il tracciamento delle sessioni raggruppa più query dello stesso utente. Il tracciamento dei costi è integrato nella visualizzazione della traccia.
- Laminar mostra una timeline di span simile agli strumenti di tracciamento distribuito. Le funzioni decorate con
@observe()appaiono come span con acquisizione di input/output.
Quale strumento per quale caso d'uso
- Pipeline LangChain, desidero una tracciatura senza sforzo: LangSmith. Strumentazione automatica delle variabili d'ambiente, +12 righe di codice.
- Utilizzo già W&B, ho bisogno di un'orchestrazione per la valutazione: Weave.
weave.Evaluation+ versioning del dataset + classifiche. - Necessario hosting autonomo senza contratto aziendale: Langfuse. Open source (MIT), Docker Compose, regione dati UE.
- Desideri l'osservabilità OSS, ma non hai bisogno di un orchestratore eval? Ecco Laminar. Apache 2.0, decoratore
@observe()leggero. - Produzione ad alto volume, sensibile ai costi: Langfuse. 6 dollari ogni 100.000 unità per volumi superiori a 50 milioni di unità.
- Necessari sia il tracciamento che la valutazione integrata: Weave o LangSmith. Orchestratori di valutazione completi con gestione dei dataset.
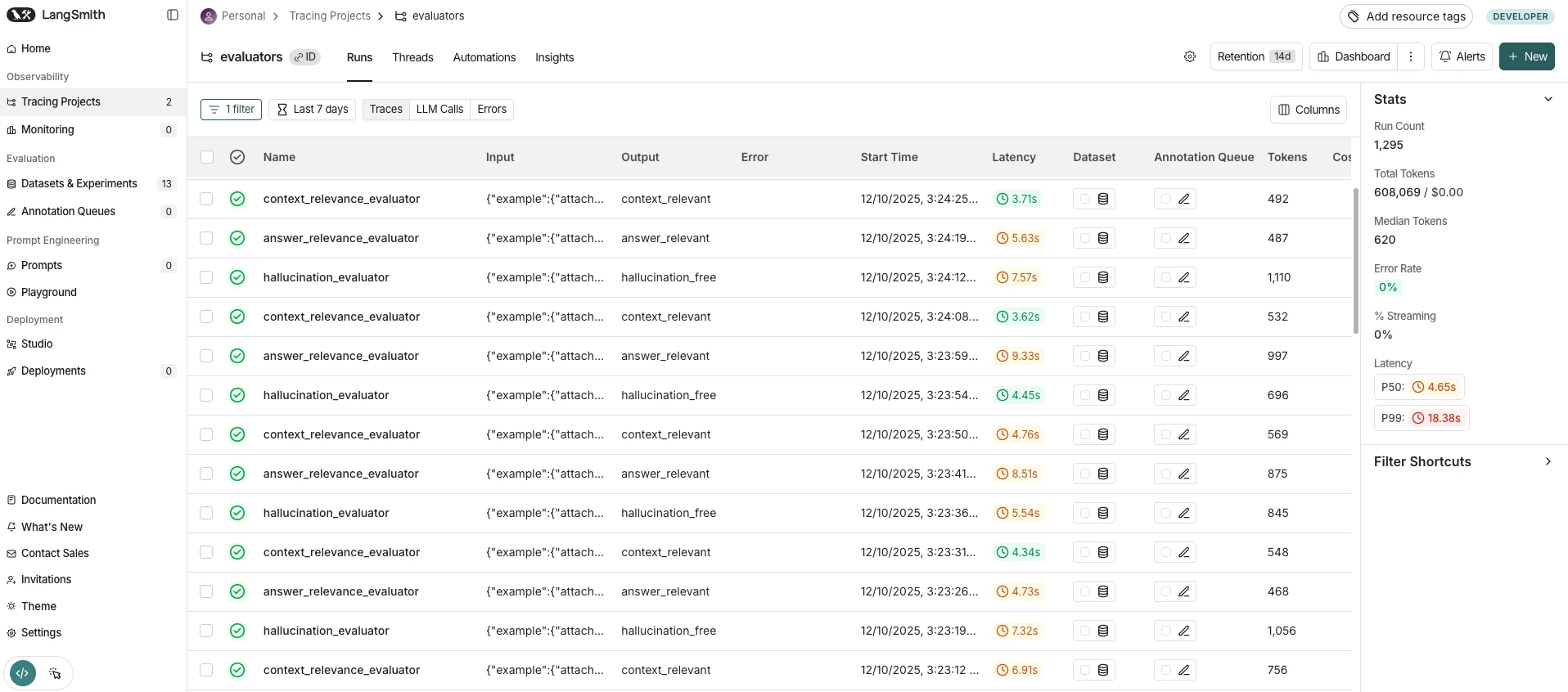
Metodologia di riferimento per gli strumenti di osservabilità RAG
Hardware : Apple M4, 16 GB di RAM, macOS 26.3
Pipeline RAG : LangGraph StateGraph con 7 nodi (router, retriever, document grader, web search fallback, calculator, context builder, generator)
LLM : openai/gpt-4.1-nano via OpenRouter (temperatura 0.0)
Router LLM : google/gemini-2.5-flash via OpenRouter (output strutturato)
Valutazione LLM : google/gemini-2.5-pro tramite OpenRouter
Database vettoriale : Qdrant 1.12 (Docker locale), distanza coseno, 1.204 documenti SQuAD
Incorporamenti : BAAI/bge-small-en-v1.5 (384 dimensioni, inferenza CPU)
Ricerca candidati : i 5 documenti principali per ogni query
Set di query : 30 query curate, 20 fattuali (recupero da base di conoscenza), 5 multi-hop (richiedono la combinazione di informazioni), 5 matematiche (instradate al nodo calcolatore).
Pipeline : riscaldamento a 3 query scartato. 5 passaggi completi su tutte le 30 query per piattaforma. Totale: 150 esecuzioni misurate per piattaforma. Timer: time.perf_counter() incapsula solo graph.invoke() . Le valutazioni di LLM-judge vengono eseguite dopo l'arresto del timer. gc.collect() tra iterazioni e piattaforme. Prima la baseline, poi ogni piattaforma in sequenza.
Variabile controllata : tutte le piattaforme condividono lo stesso codice della pipeline, le stesse istanze LLM, la stessa configurazione del retriever e lo stesso set di query. L'unica variabile è il livello di osservabilità.
Test statistici: intervallo di confidenza al 95% tramite distribuzione t, test U di Mann-Whitney (non parametrico, a due code) per la significatività, d di Cohen per la dimensione dell'effetto, metodo IQR per l'individuazione di valori anomali.
Strumenti testati
Come funziona l'osservabilità RAG
Ogni strumento impacchetta le chiamate di funzione strumentate come una "traccia" (un albero di "span") e le invia a un backend. L'overhead deriva da tre operazioni su ogni chiamata: (1) creazione dello span all'ingresso, (2) serializzazione del payload al ritorno e (3) trasmissione in background. La maggior parte degli strumenti trasmette in modo asincrono, ma la creazione e la serializzazione dello span avvengono in linea.
Variabili d'ambiente vs decoratori vs strumentazione SDK
Strumentazione tramite variabili d'ambiente (LangSmith). Impostando LANGCHAIN_TRACING_V2=true si attivano i meccanismi di tracciamento integrati in LangChain e LangGraph. Ogni chiamata LLM, invocazione del retriever e nodo del grafo viene acquisito automaticamente. Non sono necessarie modifiche al codice della pipeline.
(Weave, Laminar, Langfuse). Lo sviluppatore avvolge ogni funzione con un decoratore ( @weave.op() , @observe() ). Le funzioni non decorate non vengono tracciate.
Limitazioni
Carico di lavoro di query sequenziali a thread singolo. Le richieste simultanee in produzione potrebbero modificare il profilo di overhead a causa della contesa per lo svuotamento asincrono.
Le API LLM esterne (OpenRouter) dominano la latenza totale, comprimendo l'overhead di monitoraggio relativo. L'inferenza locale (ad esempio, Ollama) renderebbe l'overhead proporzionalmente maggiore.
Solo backend cloud. Le implementazioni self-hosted di Langfuse e Laminar potrebbero avere un overhead diverso poiché non prevedono la trasmissione di rete a un servizio di tracciamento esterno.
La fase di riscaldamento elimina i costi di avvio a freddo. Le implementazioni serverless registrerebbero un overhead maggiore alla prima richiesta dovuto all'inizializzazione dell'SDK.
LangSmith cattura tutte le chiamate interne di LangChain, non solo quelle dei 7 nodi della pipeline. Altre piattaforme tracciano solo le funzioni decorate. Questo fa sì che il confronto si basi su ambiti di strumentazione diversi, non su carichi di lavoro equivalenti.
I dati sui prezzi sono stati raccolti a marzo 2026. Si consiglia di verificare le tariffe aggiornate sul sito web di ciascun fornitore.
Conclusione
La latenza non è un criterio utile per scegliere tra questi strumenti. Tutti e quattro hanno aggiunto meno di 170 ms a una pipeline in cui le chiamate API LLM richiedono dai 1.000 ai 3.000 ms, e nessuna delle differenze è risultata statisticamente significativa.
LangSmith è la soluzione più veloce da integrare se si utilizza LangChain a 12 linee e si dispone di tracciamento completo. Sia Weave che LangSmith offrono l'orchestrazione della valutazione, funzionalità assente in Langfuse e Laminar. Langfuse e Laminar sono le uniche opzioni se si necessita di un hosting autonomo senza un contratto enterprise.
Per approfondire
Esplora altri parametri di riferimento RAG, come ad esempio:
- Modelli di embedding: OpenAI vs Gemini vs Cohere
- I 16 migliori modelli di embedding open source per RAG
- Principale database vettoriale per RAG: Qdrant vs Weaviate vs Pinecone
- Benchmark di Reranker: confronto tra gli 8 migliori modelli
- Modelli di embedding multimodali: Apple vs Meta vs OpenAI
- Confronto tra RAG grafico e RAG vettoriale
- I 10 migliori modelli di embedding multilingue per RAG
Cita questa ricerca
Scegli il formato adatto a dove pubblicherai. Incollare la versione con link nel tuo CMS preserva il backlink.
@misc{sar2026,
author = {Sarı, Ekrem},
title = {{RAG Strumenti di osservabilità - Benchmark}},
year = {2026},
month = mar,
howpublished = {\url{https://aimultiple.com/rag-monitoring}},
note = {AIMultiple. Retrieved Marzo 23, 2026}
}
Sii il primo a commentare
Il tuo indirizzo email non verrà pubblicato. Tutti i campi sono obbligatori. I commenti vengono lasciati nella loro lingua originale.