RAG Framework: LangChain vs LangGraph vs LlamaIndex
Abbiamo testato 5 framework RAG: LangChain, LangGraph, LlamaIndex, Haystack e DSPy, costruendo lo stesso flusso di lavoro RAG agentico con componenti standardizzati: modelli identici (GPT-4.1-mini), embedding (BGE-small), retriever (Qdrant) e strumenti (ricerca web Tavily). Questo isola il vero sovraccarico e l'efficienza dei token di ciascun framework.
Risultati del benchmark dei framework RAG
Il benchmark consisteva in 100 query, con ciascun framework che eseguiva l'intero set 100 volte per fornire medie stabili.
- Token medi: Totale dei token consumati in tutte le chiamate LLM (router, valutatore documenti, valutatore risposte e generatore), include sia i prompt (con contesto recuperato) sia i completamenti. Più basso = minor costo API.
- Sovraccarico del framework: Tempo puro di orchestrazione (ms), l'elaborazione interna del framework (logica di routing, gestione dello stato, ecc.), escluse le chiamate LLM API e agli strumenti. Più basso = framework più snello.
Tutte le implementazioni hanno raggiunto un'accuratezza del 100% sul set di test. Sono stati utilizzati gli stessi modelli, temperature, provider di retrieval, strumento di ricerca web e un limite condiviso di token di contesto.
Risultati principali
- Ci concentriamo sul controllare ciò che è controllabile: Stessa famiglia di modelli e temperature, max_tokens a livello di nodo, retriever (Qdrant + BGE-small, k=5, normalizzazione attiva), provider web (solo Tavily), politica del router (euristica + modello), ritorno anticipato della calcolatrice, limite condiviso di token di contesto, rubrica di valutazione identica, strumentazione unificata. Questo riduce sostanzialmente i principali fattori confondenti nelle nostre misurazioni.
- Il sovraccarico del framework è misurabile ma ridotto: Abbiamo osservato circa 3–14 ms per query dalla logica di orchestrazione. Queste differenze sono reali, ma non la fonte principale dei divari di latenza superiori a 1 s; la maggior parte del tempo viene impiegata in I/O con modelli/strumenti esterni.
- Le prestazioni seguono i token (con questi vincoli): DSPy mostra il sovraccarico di framework più basso (~3,53 ms). Haystack (~5,9 ms) e LlamaIndex (~6 ms) seguono, mentre LangChain (~10 ms) e LangGraph (~14 ms) sono più alti. L'uso dei token è più basso per Haystack (~1,57k), poi LlamaIndex (~1,60k); DSPy e LangGraph sono ~2,03k, e LangChain ~2,40k.
- Il percorso di routing/strumenti è importante: Piccole variazioni nel routing iniziale (retriever vs web vs calcolatrice) e nel comportamento di fallback influenzano sia i token sia il tempo, anche quando prompt e budget sono allineati.
Perché le differenze persistono? Il "DNA del framework"
Nonostante la standardizzazione, rimangono piccole variazioni nel conteggio dei token e nella latenza. Queste sono attribuibili ai comportamenti intrinseci di basso livello di ciascun framework, il loro "DNA".
- Serializzazione di prompt e messaggi: Ogni framework racchiude lo stesso contenuto logico con una formattazione leggermente diversa prima di inviarlo all'LLM, creando piccoli ma costanti delta di token.
- Assemblaggio del contesto: L'ordinamento preciso e l'inclusione dei metadati all'interno del contesto concatenato possono differire leggermente a seconda del framework, influenzando il conteggio finale dei token.
- Sparigli decisionali del routing: Nei casi limite, sottili differenze nel modo in cui un framework analizza l'output JSON del router possono portare a una diversa scelta iniziale dello strumento.
In questa configurazione, l'impronta dei token sembra essere il fattore principale, più del tempo di esecuzione del framework.
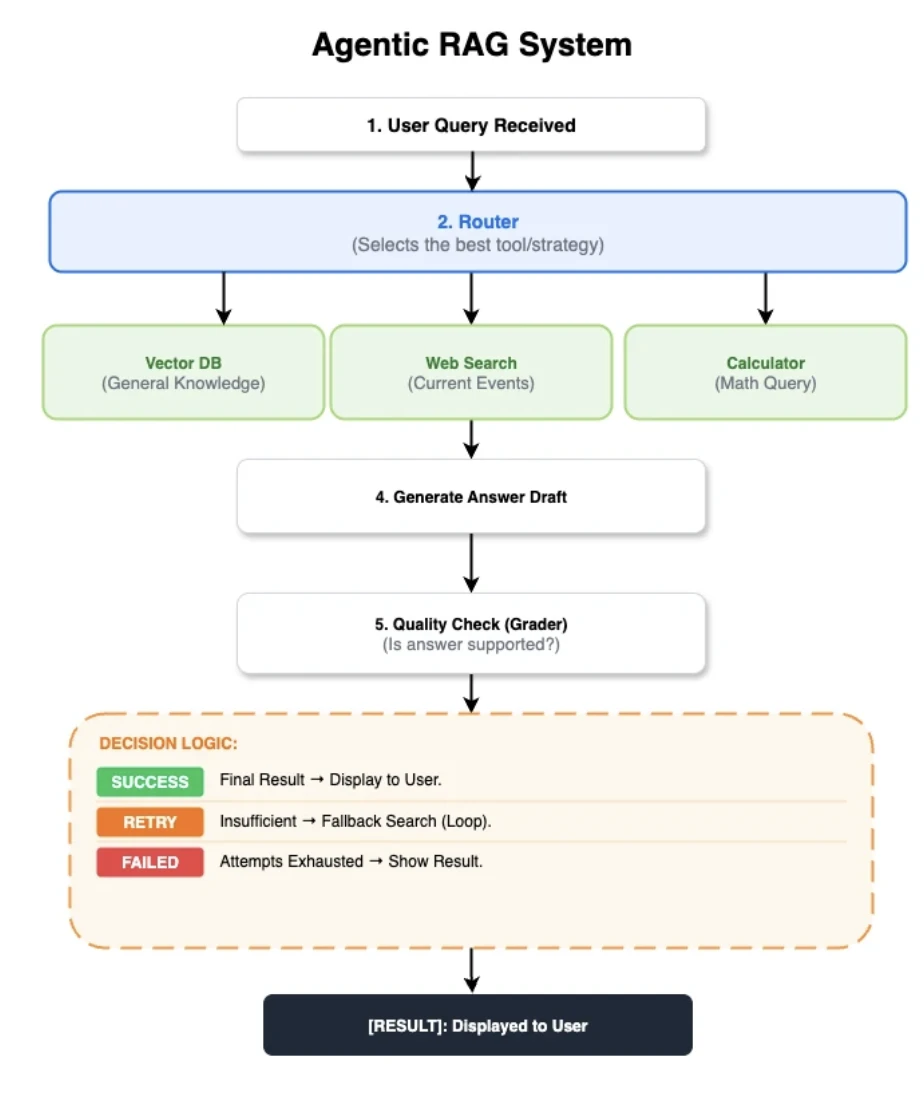
L'architettura RAG agentica condivisa
Per ottenere un confronto equo, tutte e cinque le implementazioni sono state costruite sullo stesso flusso di controllo:
- Router: Un nodo ibrido modello-euristico che sceglie tra retriever, ricerca web o calcolatrice.
- Recupera documenti: Recupera i primi 5 documenti da Qdrant utilizzando embedding BGE-small normalizzati.
- Valuta documenti: Un giudice LLM valuta la pertinenza dei documenti. Se irrilevanti, attiva un fallback di ricerca web.
- Genera risposta: Utilizza un LLM con temperatura=0,0 e un limite condiviso di token di contesto per generare una bozza di risposta.
- Valuta risposta: Un secondo giudice LLM valuta la bozza per fondatezza, contraddizioni (allucinazioni) e completezza.
- Fallback e ritorno anticipato: Viene attivata una ricerca web se il voto della risposta è insufficiente. I risultati della calcolatrice, invece, vengono restituiti direttamente, saltando i passaggi di generazione e valutazione.
Esempi di flusso di lavoro
Scenario A — Risultato diretto dal database:
Scenario B — Evento recente attiva lo strumento web:
Scenario C — La calcolatrice fornisce un ritorno anticipato:
Scenario D — Database vettoriale insufficiente, ricorre alla ricerca web:
Metodologia dei framework RAG
Tutte e cinque le implementazioni hanno raggiunto un'accuratezza del 100% sul nostro set di test di 100 query, corrispondendo alle risposte di riferimento. Questo era il requisito fondamentale, che garantiva che ciascun framework potesse eseguire con successo lo stesso flusso di lavoro RAG agentico prima di misurare le differenze di prestazione.
1. Componenti principali e configurazione
Gli strumenti fondamentali sono stati standardizzati per eliminare le variabili di prestazione alla fonte.
- LLM:
- Modello: Tutti i nodi (router, generatore, valutatore) hanno utilizzato il modello openai/gpt-4.1-mini tramite l'OpenRouter API.
- Determinismo: la temperatura è stata impostata a 0,0 per tutte le chiamate LLM per garantire la massima coerenza nel routing, nella generazione e nella valutazione.
- Limiti di token: Sono stati imposti limiti rigorosi di max_tokens: 256 per il router e i valutatori, e 512 per il generatore. Questo previene differenze di latenza causate da un framework che genera risposte eccessivamente lunghe.
- Modello di embedding e retrieval:
- Modello: Tutti i framework hanno utilizzato BAAI/bge-small-en-v1.5 da HuggingFace.
- Normalizzazione: Un passaggio critico per le prestazioni, normalize_embeddings è stato impostato su True in tutti e cinque i framework. (LangChain/LangGraph tramite encode_kwargs; LlamaIndex tramite normalize=True; Haystack tramite normalize_embeddings; retriever DSPy normalizzato.)
- Retrieval: Il vector store Qdrant è stato interrogato con k=5 (top 5 documenti) in tutte le implementazioni.
- Strumenti:
- Ricerca web: Il benchmark è stato limitato a solo Tavily (max_results=3).
- Calcolatrice: Tutte e cinque le implementazioni hanno utilizzato la libreria sympy per l'analisi e la valutazione delle espressioni matematiche, garantendo capacità identiche.
2. Flusso di controllo e politica RAG
Il processo "decisionale" dell'agente è stato esplicitamente replicato in tutti i framework.
- Logica di routing: Una strategia di routing ibrida è stata implementata in tutti e cinque gli script per bilanciare l'intelligenza del modello con regole deterministiche:
- Un'euristica basata su regex heuristic_route verifica prima modelli ovvi di calcolatrice o ricerca web (es. simboli matematici, anni come "2024").
- Un router_node LLM prende poi la propria decisione.
- La decisione finale dà priorità all'euristica per le calcolatrici, altrimenti si affida alla scelta dell'LLM.
- Budget del contesto: Questa è una delle standardizzazioni più critiche. Prima che il nodo generate_answer venga chiamato, tutto il contesto dei documenti recuperati e i risultati della ricerca web vengono concatenati e poi troncati a un limite condiviso di 2000 token utilizzando un'utilità comune truncate_to_token_budget. Questo garantisce che l'LLM generatore in ciascun framework riceva un input della stessa identica dimensione, impedendo che un singolo framework venga avvantaggiato o svantaggiato dalla verbosità del suo contesto recuperato.
- Politica di valutazione delle risposte:
- Rubrica indulgente: Il nodo grade_answer utilizza un prompt identico e indulgente in tutti i framework, istruendo il giudice LLM ad accettare risposte semanticamente simili e ragionevolmente complete.
- Gestione dei fallimenti: La logica per gestire un parsing JSON fallito dal valutatore è stata standardizzata. Se l'output del valutatore non è un JSON valido, il sistema predefinisce un voto permissivo (grounded=True, complete=True), imitando uno scenario reale in cui non si vorrebbe che un parser fragile facesse fallire una risposta altrimenti buona. DSPy restituisce campi strutturati (nessun parsing JSON), questo viene registrato come una differenza di robustezza, non un vantaggio di prestazione.
- Ritorno anticipato della calcolatrice: Come visto nel codice, una chiamata riuscita al calculator_node imposta direttamente la final_answer e termina anticipatamente il flusso di lavoro. Questa è un'ottimizzazione significativa che viene applicata coerentemente, impedendo al percorso della calcolatrice di invocare inutilmente gli LLM di generazione e valutazione.
- Allineamento DSPy. Per mantenere l'equità con le baseline non-CoT, DSPy utilizza dspy.Predict (nessun CoT) per Router e AnswerGenerator. Le firme rispecchiano i contratti dei nodi degli altri framework; ove disponibile, il conteggio dei token utilizza l'uso riportato dal modello, altrimenti fallback tiktoken.
3. Strumentazione e metriche
Il processo di misurazione è stato identico, utilizzando utilità e principi condivisi.
- Latenza: time.perf_counter() ad alta precisione è stato utilizzato per tutte le misurazioni temporali. Il sovraccarico del framework è calcolato coerentemente come Latenza Totale – Latenza Chiamate Esterne.
- Tokenizzazione: Tutti i conteggi dei token per prompt e completamenti sono stati calcolati utilizzando tiktoken, la codifica cl100k_base, garantendo un'unica fonte di verità per le metriche dei token. La metrica "Token medi" riportata nei risultati rappresenta la somma cumulativa di tutti i token di input (prompt) e output (completamento) per ogni chiamata LLM (es. router, valutatori, generatore) all'interno di un singolo flusso di lavoro di query.
- Gestione dello stato: Sebbene la sintassi di implementazione vari (TypedDict di LangGraph, classe di LlamaIndex, dizionario di LangChain), la struttura dello stato è funzionalmente identica. Ogni framework passa lo stesso insieme di chiavi (question, documents, web_results, ecc.) tra i nodi, garantendo che la logica del flusso di controllo operi sulle stesse informazioni.
Imponendo queste rigorose standardizzazioni a livello di codice, questo benchmark mira a superare i confronti superficiali e offrire un'analisi replicabile delle prestazioni dei framework sotto una politica RAG fissa.
Interpretare i risultati:
- Si può concludere: In questa configurazione specifica e altamente controllata, il sovraccarico di orchestrazione tende ad essere minore; le differenze sono determinate principalmente dal conteggio dei token e dai percorsi degli strumenti.
- In questa configurazione specifica e altamente controllata, il sovraccarico del framework è trascurabile.
- Le differenze di prestazione sono state determinate dal conteggio dei token e dalle variazioni dei percorsi degli strumenti.
- Non si può generalizzare: I risultati sono specifici per questa architettura, modelli, prompt, retriever e provider web; cambiarli può alterare le classifiche.
Esperienza dello sviluppatore: un confronto qualitativo
Le prestazioni non sono l'unico fattore; anche come ci si sente a sviluppare con un framework è ugualmente importante.
- LangGraph: Il grafo dichiarativo
Utilizza un paradigma graph-first. Si definiscono i nodi e li si collegano con archi (inclusi add_conditional_edges), così il flusso di controllo fa parte dell'architettura. Lo stato è tipizzato tramite un TypedDict con aggiornamenti in stile reducer (Annotated[…, add]).- Scegli LangGraph per: flussi di lavoro complessi con rami multipli, tentativi e cicli; la sua struttura scala in robustezza e manutenibilità man mano che gli agenti crescono.
- LlamaIndex: Orchestrazione imperativa
Uno script procedurale dove il flusso di controllo è standard Python if/else; il "grafo" vive nel codice. Lo stato è una classe PipelineState dedicata e il framework fornisce primitive di retrieval pulite (VectorStoreIndex → .as_retriever(k=5)).- Scegli LlamaIndex per: flussi di lavoro leggibili in un singolo file dove si apprezza una chiara logica procedurale e un facile debugging.
- LangChain: Imperativo con componenti dichiarativi
L'orchestrazione rimane uno script Python, ma i singoli task sono piccole catene componibili che utilizzano l'operatore | (es. prompt | llm | parser). Lo stato è un dizionario Python flessibile e non tipizzato.- Scegli LangChain per: Prototipazione rapida o team già nell'ecosistema LangChain che preferiscono comporre piccole unità dichiarative all'interno di un driver imperativo più ampio.
- Haystack: Basato su componenti, orchestrazione manuale Componenti tipizzati e riutilizzabili (@component) con I/O esplicito, mentre il flusso di controllo rimane Python puro (if/else). Facile da scambiare backend LLM/retriever/web, oltre a una strumentazione di prima classe per ogni passaggio (tempo esterno vs tempo del framework).
- Scegli Haystack per: pipeline pronte per la produzione, testabili con contratti chiari e controllo a grana fine.
- DSPy: Programmi signature-first (meno righe di codice)
Definisce un task tramite una firma (input/output + intento), poi lo implementa con Moduli che incapsulano il prompting e le chiamate LLM. Centralizza la gestione di prompt/uso e rimuove il codice collante; scambiare gli interni (es. Predict ↔ CoT) non cambia il contratto.- Scegli DSPy per: codice boilerplate minimo, flussi leggibili in un singolo file, sviluppo guidato dai contratti (con ottimizzatori opzionali).
Scambiare prestazioni ottimali per la comparabilità
- LangGraph potrebbe eccellere con le sue ottimizzazioni native dei grafi quando gli è consentito utilizzare l'esecuzione parallela, la cache di stato e il suo sistema di archi condizionali per logiche di ramificazione complesse.
- DSPy potrebbe mostrare risultati radicalmente diversi utilizzando i suoi ottimizzatori di firma (come MIPROv2) e il prompting Chain-of-Thought, che possono migliorare significativamente la qualità delle risposte.
- Haystack potrebbe sfruttare la sua cache pronta per la produzione, le funzionalità di batching e le ottimizzazioni a livello di componente che abbiamo disabilitato per equità.
- LlamaIndex potrebbe beneficiare delle sue strategie di indicizzazione avanzate, dei motori di query e delle capacità multimodali che non sono state esercitate in questo benchmark.
- LangChain potrebbe brillare con il suo ampio ecosistema di strumenti e le ottimizzazioni LCEL (LangChain Expression Language) quando non vincolato al nostro set di strumenti standardizzato.
Il framework "migliore" dipende da cosa si ottimizza: velocità di sviluppo, manutenibilità, prestazioni o pattern architetturali specifici.
Conclusione
In una pipeline RAG agentica strettamente abbinata, il sovraccarico di orchestrazione è di solito una fetta ridotta. Ciò che fa la differenza è quanti token vengono elaborati e quali strumenti vengono invocati, entrambi influenzati da prompt, retrieval e routing. Il framework "giusto" dipende in ultima analisi dallo stile di orchestrazione preferito dal team: grafi dichiarativi (LangGraph), script imperativi (LlamaIndex), catene componibili (LangChain), componenti modulari (Haystack) o programmi signature-first (DSPy) che riducono al minimo il boilerplate.
Ulteriori letture
Esplora altri benchmark RAG, come:
- Modelli di Embedding: OpenAI vs Gemini vs Cohere
- I migliori database vettoriali per RAG: Qdrant vs Weaviate vs Pinecone
- Benchmark RAG agentico: routing multi-database e generazione di query
- RAG ibrido: aumentare l'accuratezza del RAG
Cita questo benchmark
Scegli il formato adatto a dove pubblicherai. Incollare la versione con link nel tuo CMS preserva il backlink.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Sarı, Ekrem},
title = {{RAG Framework: LangChain vs LangGraph vs LlamaIndex}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/rag-frameworks}},
note = {AIMultiple. Consultato il 3 Giugno 2026}
}
Sii il primo a commentare
Il tuo indirizzo email non verrà pubblicato. Tutti i campi sono obbligatori. I commenti vengono lasciati nella loro lingua originale.