Benchmark de OCR de Faturas: Precisão de Extração de LLMs vs OCRs
O processamento de faturas é uma operação de negócio crítica, mas trabalhosa, que tradicionalmente requer extração de dados manual e inserção em sistemas de contabilidade. Esta abordagem manual é demorada e suscetível a erros humanos. Para avaliar alternativas automatizadas, realizámos uma análise comparativa das principais soluções de processamento de documentos e LLMs:
- Amazon Textract API
- Claude Sonnet 3.5
- Docsumo
- Google Document IA
- Microsoft Azure Document Intelligence
- Rossum
O nosso estudo avaliou a capacidade destas ferramentas em extrair dados com precisão a partir de diversos formatos e qualidades de faturas, com o objetivo de quantificar a sua eficácia como alternativas ao processamento manual.
Resultados do benchmark
Avaliámos o desempenho de processamento de faturas em faturas de qualidade e níveis de contraste variados. Embora todas as ferramentas tenham demonstrado um bom desempenho com imagens de alta qualidade, a sua precisão diminuiu significativamente ao processar documentos de menor qualidade. Entre as ferramentas testadas, o Claude Sonnet 3.5 exibiu a maior precisão e resiliência geral em todo o espectro de qualidades de documentos.
Metodologia
Medição: A nossa metodologia de avaliação focou-se na precisão da extração de pares chave-valor. Cada campo extraído foi avaliado usando uma classificação binária: extração correta ou extração incorreta/em falta. A métrica de precisão foi calculada usando a seguinte fórmula:
Precisão = (Número de Pares Chave-Valor Corretamente Extraídos) / (Número Total de Pares Chave-Valor)
Esta metodologia permitiu uma comparação objetiva do desempenho de extração entre diferentes ferramentas e tipos de documentos.
Tamanho da amostra: Encontrar dados de faturas é desafiante, pois envolve informações pessoais como e-mails e nomes. Utilizámos mais de 400 pares chave-valor de 20 amostras de faturas publicamente disponíveis.
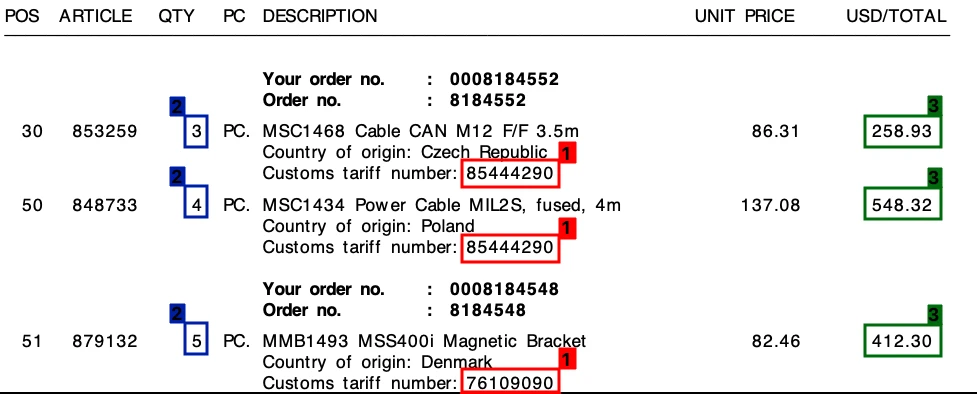
Amostras: Embora todas as soluções tenham processado corretamente imagens de alta qualidade, a qualidade da extração diminuiu em imagens como estas:
Fine-tuning: Embora os produtos que experimentámos tenham sido bem-sucedidos a encontrar montantes totais, tiveram problemas na extração de detalhes de preços. É possível obter melhores resultados fazendo fine-tuning de alguns produtos. Em alguns produtos, os utilizadores podem clicar num valor na imagem para corrigir o output do modelo.
Para sermos justos com todos os fornecedores, não realizámos qualquer fine-tuning. Com fine-tuning, todos os fornecedores deverão conseguir alcançar taxas de sucesso mais elevadas na segunda vez que processam estes documentos. No entanto, o nosso foco neste benchmark são as operações autónomas, que exigem que os modelos produzam resultados corretos e fiáveis a partir de documentos que nunca viram antes.
Linha temporal: Todos os testes foram concluídos em dezembro de 2024.
Próximos passos
Aumentar os participantes: Uma vez que este estudo fornece insights sobre as capacidades atuais de processamento de faturas em Large Language Models (LLMs), tecnologias de OCR e ferramentas especializadas de processamento de faturas, planeamos expandir a nossa análise incorporando LLMs de última geração adicionais para fornecer um benchmark mais abrangente de soluções automatizadas de processamento de faturas.
Aumentar o tamanho e a diversidade da amostra.
O que é OCR de faturas?
O parsing de faturas utiliza ferramentas automatizadas como NLP, NLU, OCR e outras tecnologias de extração de dados para extrair dados de faturas em vários formatos, como PDFs e imagens.
Um parser de faturas é um programa de software que extrai informações como
Nome do fornecedor
Número da fatura
Montante devido
e insere-as num formato legível por máquina. Estes dados podem ser utilizados para múltiplas funções, como automatizar contas a pagar, concluir fechos contabilísticos mensais e gerir faturas.
O software parser está geralmente integrado num sistema de processamento de faturas que automatiza todo o processo desde a receção de uma fatura até ao pagamento.
Como funcionam as ferramentas de OCR de faturas?
Documentos escritos numa determinada linguagem de marcação são lidos e tratados por parsers. Estes dividem o documento em partes mais pequenas, chamadas tokens, e examinam cada token para determinar o que significa e onde se enquadra na estrutura do documento.
Para fazer isto, os parsers precisam de conhecer bem a gramática da linguagem de marcação em questão. Isto permite-lhes reconhecer cada token e determinar as relações exatas entre eles.
O processo inclui 5 passos:
1. Input
As faturas podem ser recebidas numa variedade de formatos, incluindo papel, e-mail ou formatos eletrónicos como PDF ou XML. O software parser de faturas irá normalmente aceitar estas faturas como input.
2. Reconhecimento Ótico de Caracteres (OCR)
Se a fatura estiver em formato de papel digitalizado ou imagem, o parser usará tecnologia de OCR para extrair texto da imagem. Isto permite ao parser aceder aos dados contidos na fatura.
Algumas soluções de parsing de faturas usam ferramentas de OCR com IA ou LLMs que extraem automaticamente informações de PDFs, fotos e documentos digitalizados sem necessidade de novas regras ou templates. Isto porque a IA pode lidar com documentos semiestruturados e desconhecidos e melhorar ao longo do tempo. As informações extraídas podem ser personalizadas para incluir apenas tabelas ou entradas de dados específicas.
3. Extração de dados
O parser irá então extrair informações específicas da fatura, como o nome do fornecedor, número da fatura, data e detalhes dos itens. Isto é tipicamente alcançado usando uma combinação de reconhecimento de padrões e algoritmos de machine learning.
Alguns softwares de parsing de faturas têm a capacidade de extrair informações-chave como a data da fatura, número, números de identificação fiscal e vários totais usando filtros predefinidos:
Algumas ferramentas de parser oferecem a capacidade de extrair informações de itens de linha de faturas com um formato consistente, criando um parser de documentos separado para cada layout específico de fornecedor ou parceiro comercial:
4. Validação de dados
Uma vez extraídos os dados, o parser irá validar as informações para garantir que estão corretas e completas. Isto pode incluir verificar se a data está no formato correto, se o nome do fornecedor corresponde a uma lista predefinida de fornecedores ou se os detalhes dos itens correspondem ao formato esperado.
5. Output de dados
Os dados extraídos e validados são depois disponibilizados como output num formato que pode ser facilmente importado para o sistema de contabilidade ou ERP do utilizador. Isto pode ser sob a forma de um ficheiro CSV, registo de base de dados ou diretamente num software de contabilidade.
Desafios da extração manual de dados de faturas
Extrair manualmente dados de faturas e inseri-los num sistema pode ser desafiante para as empresas, uma vez que existem várias complexidades:
Erro humano
As faturas podem conter uma grande quantidade de dados, e a inserção manual aumenta o risco de erros, como gralhas, transposição de números e inserção incorreta de dados. As imprecisões na inserção de dados são responsáveis por cerca de $600 mil milhões em perdas anuais.1 Processos como contas a pagar precisam de uma exportação correta de dados de documentos financeiros.
Demorado
Em média, são necessários 17 dias, ou aproximadamente 75% de um mês, para processar manualmente uma única fatura.2
Muitas informações importantes estão incluídas nas faturas, e são todas apresentadas num estilo chave-valor onde cada item serve simultaneamente como chave e valor. O processo de extrair manualmente estes pares é demorado e requer múltiplas inspeções para garantir a precisão. Até mesmo alguns algoritmos de OCR têm dificuldade em detetar valores extraídos sem contexto. O processamento automatizado de faturas pode ajudar os funcionários a concentrarem-se em tarefas mais complexas.
Falta de padronização
Faturas de diferentes fornecedores podem ter formatos diferentes. Cada fatura é gerada com um formato único que pode colocar dificuldades ao processar e interpretar estes padrões. Os documentos, como e-mails, papel e PDFs, podem passar por muitos registos digitais e em papel antes de serem aprovados para pagamento, tornando a extração manual de dados desafiante e propensa a erros.
Ineficiência do processo
O tratamento manual de faturas, que incorre num custo médio de quase $23 por fatura3 , pode ser simultaneamente demorado e dispendioso, levando a um processo ineficiente e repetitivo.
Potencial de perda de dados
Existe o risco de perder dados se as faturas forem perdidas ou danificadas ou se os dados não forem introduzidos corretamente no sistema.
Os softwares de OCR enfrentam frequentemente dificuldades em extrair itens de linha de faturas também. Isto deve-se ao facto de as tabelas de transações poderem não ter linhas horizontais ou verticais, dificultando ao processamento de faturas por ocr estabelecer contexto para os itens extraídos. Faturas digitais recolhidas ou imagens de faturas podem ser usadas neste processo.
Como escolher o seu fornecedor de processamento de faturas?
1. Fornece uma solução alinhada com as políticas de privacidade de dados da sua empresa.
A política de privacidade de dados da sua empresa pode ser um fator impeditivo para usar APIs externas como a Amazon AWS Textract. A maioria dos fornecedores oferece soluções on-premise, pelo que as políticas de privacidade de dados não impediriam necessariamente a sua empresa de usar uma solução de captura de faturas. O fluxo de trabalho de contas a pagar deve ser tratado com consideração cuidadosa, uma vez que envolve frequentemente informações confidenciais de negócio e financeiras.
2. Fornece uma estrutura de dados consistente independentemente do texto nos documentos.
Existem duas formas de funcionamento das empresas de captura de faturas baseadas em deep learning. Empresas como a Textract devolvem pares chave-valor. Assim, por exemplo, se uma fatura chamar ao montante total "Gross amount", outra lhe chamar "Total amount" e uma fatura alemã lhe chamar "Summe", a Textract fornece-lhe os dados em 3 estruturas diferentes para estes 3 documentos.
Num, tem um par chave-valor com a chave "Gross amount", noutro "Total amount" e no alemão, obtém "Summe". Outros fornecedores conceberam estruturas de dados consistentes que funcionam para todas as faturas. Em todos os 3 cenários, obteria "Total amount", que é a chave que usam no seu ficheiro de output. Isto facilita a análise e o processamento, pois não precisa de lidar com muitos formatos de dados estruturados diferentes.
3. Pergunte pelas taxas de falsos positivos e de extração manual de dados
Depois execute um projeto de Prova de Conceito (PoC) para ver as taxas reais nas faturas recebidas pela sua empresa.
Falsos positivos são faturas que são auto-processadas, mas têm erros na extração de dados. Estes são difíceis de identificar e podem perturbar as operações. Por exemplo, a extração incorreta de montantes de pagamento seria problemática. Minimizar isto deve ser o foco absoluto.
A extração manual de dados é necessária quando o sistema automatizado de extração de dados tem confiança limitada no seu resultado. Isto pode dever-se a um formato de fatura diferente, má qualidade de imagem ou um erro de impressão do fornecedor. Isto também é importante minimizar, mas há um compromisso entre falsos positivos e extração manual de dados. Ter mais extração manual de dados pode ser preferível a ter falsos positivos.
Este é o primeiro benchmarking quantitativo que vimos neste espaço e seguiremos uma metodologia semelhante para preparar o nosso próprio benchmarking.
4. Aproveite um PoC para medir a taxa potencial de automação
Isto depende do número de campos que espera capturar dos documentos. Um conjunto típico de ~10 campos, incluindo itens como ID da ordem de compra, nome do fornecedor, etc., pode permitir a inserção de dados no ERP e pagamentos.
Fornecedores de melhores práticas alcançam ~80% de STP extraindo todos estes ~10 campos praticamente sem erros ~80% das vezes. Embora possam ocorrer erros ocasionalmente, a verificação manual dos pagamentos maiores pode garantir que nenhum pagamento errado significativo escape.
5. Pergunte pelas opções avançadas de processamento fornecidas pelo fornecedor
A extração é o primeiro passo na recolha de dados; precisa de ser seguida pelo processamento de dados na maioria dos casos. Por exemplo, as faturas precisam de ser verificadas quanto à conformidade com o IVA (por exemplo, faturas domésticas sem IVA precisam de explicar porque é que o IVA está excluído), e a não conformidade pode resultar em multas significativas para a empresa, dependendo do país.
6. Pergunte como a solução aprende sobre novas faturas
As melhores soluções têm uma interface para permitir que a sua equipa ajude a orientar a solução. À medida que o funcionário da sua empresa seleciona os pares chave-valor, a solução de captura de faturas toma nota para poder estar mais confiante numa fatura semelhante da próxima vez.
7. Avalie a facilidade de uso da sua solução de entrada manual de dados
Será usada pelo pessoal de back-office da sua empresa ao processar manualmente faturas que não podem ser processadas automaticamente com confiança.
Além disto, fazem sentido questões de procurement de melhores práticas. Por exemplo:
- Quão amplamente adotada é a sua solução? Têm clientes da Fortune 500?
- Os seus clientes estão satisfeitos com a sua solução e suporte? Pode ser bom perguntar a um conhecido de uma empresa que já esteja a usar a solução deles. Uma vez que a automação de faturas não é uma solução que melhoraria o marketing ou as vendas de uma empresa, até concorrentes podem partilhar entre si a sua visão das soluções de automação de faturas.
- Quais são as opções para integrar a solução nos sistemas da sua empresa (por exemplo, ERP)? O departamento de TI está de acordo com a abordagem de integração?
- Qual é o seu Custo Total de Propriedade (TCO)? Diferentes soluções usam diferentes unidades de preço (por exemplo, preço por página ou preço por documento), o que dificulta esta comparação. No entanto, usando uma amostra dos seus arquivos, pode ter uma estimativa do custo.
Leitura adicional
Cite este benchmark
Escolha o formato adequado ao local onde você vai publicar. Colar a versão com link no seu CMS preserva o backlink.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{Benchmark de OCR de Faturas: Precisão de Extração de LLMs vs OCRs}},
year = {2026},
month = jan,
howpublished = {\url{https://aimultiple.com/invoice-ocr}},
note = {AIMultiple. Acessado em 22 Janeiro 2026}
}

Seja o primeiro a comentar
Seu endereço de e-mail não será publicado. Todos os campos são obrigatórios. Os comentários são deixados em seu idioma original.