O Futuro dos Grandes Modelos de Linguagem
Veja o futuro dos grandes modelos de linguagem explorando abordagens promissoras, como autotreinamento, verificação de fatos e especialização esparsa, que poderiam resolver as limitações dos LLM.
Comparação da taxa de sucesso dos LLM’s
Claude Sonnet 4.6 liderou o benchmark com uma pontuação geral de 0.748, com as variantes base e thinking empatadas em três casas decimais. Claude Opus 4.8 (0.702), Opus 4.6 base (0.706) e Opus 4.6 thinking (0.729) vieram em seguida, garantindo à Anthropic as cinco primeiras posições. O primeiro modelo não-Anthropic foi o Gemini 3.5 Flash, thinking com 0.625. As variantes GPT ficaram entre 0.57 e 0.60, com pontuações de backend mais fortes compensadas pela instabilidade do frontend. Veja mais em nosso artigo de benchmark.
Metodologia do Benchmark de LLM
Comparamos os principais grandes modelos de linguagem em 10 tarefas de desenvolvimento de software usando um harness CLI agentic. Cada modelo foi executado 3 vezes por tarefa (30 amostras por modelo, 270 células de validação por iteração) para estabilizar as pontuações e medir a variância por célula. Todos os modelos foram acessados via OpenRouter sob condições idênticas, mesmo harness, mesmas instruções de tarefa e mesmo ambiente de hardware.
Modelos testados
O benchmark cobre modelos disponíveis via API a partir de junho de 2026. Todas as variantes listadas abaixo foram testadas de forma independente:
- Claude Sonnet 4.6 (base e thinking)
- Claude Opus 4.8
- Claude Opus 4.6 (base e thinking)
- Claude Opus 4.7
- Gemini 3.5 Flash (base e thinking)
- GPT 5.5 (thinking)
- GPT 5.4 Mini
- GPT 5.3 Codex
- MiniMax M3
- Grok 4.3
- Qwen 3.6 Plus (base e thinking)
- GLM 5.1 (base e thinking)
- Deepseek V4 Pro (base e thinking)
Ambiente de teste
Cada agente e tarefa começa em um ambiente limpo. As instruções da tarefa são fornecidas em um arquivo TASK.md. Um watchdog heartbeat de 20 minutos monitora cada execução. Registramos códigos de saída, tempo de execução, criação de arquivos de backend e frontend e uso de tokens em tempo real nas categorias de entrada, saída e cache.
As tarefas variam de sistemas de reserva a painéis interativos. Todas exigem gerenciamento de projetos com vários arquivos e uma entrega full-stack funcional.
Pontuação
Validação de backend: Os projetos gerados são implantados em ambientes isolados e testados em relação a um contrato YAML canônico que cobre cenários de caminho feliz, tratamento de erros (400/403/409) e consistência de dados. Dois modos são usados:
- Modo adaptativo valida a funcionalidade mesmo quando os nomes das rotas diferem da especificação
- Modo estrito requer aderência exata ao contrato (rotas, códigos de status, campos de resposta)
Backend score per cell: backend_overall = has_backend × (0.7 × adaptive_pass_rate + 0.3 × strict_pass_rate)
Validação de IU: A automação do navegador simula fluxos reais de usuário incluindo preflights, renderização, envio de login e comportamento pós-login. Oito etapas divididas em dois grupos:
- Etapas de infraestrutura (preflight de backend, renderização do frontend, formulário de login visível, envio de login, login 2xx, sem falha em tempo de execução)
- Etapas de comportamento (sinal de autenticação pós-login, sinal de comportamento pós-login)
UI score per cell: ui_score = (behavior_passed / (behavior_passed + behavior_failed)) × (infra_passed / infra_total)
As etapas de comportamento bloqueadas são excluídas do denominador de comportamento para que uma célula não seja penalizada duas vezes quando o aplicativo falha ao carregar.
Final score: Final Score = (0.7 × backend_overall) + (0.3 × ui_score)
O backend tem peso maior porque falhas de lógica no nível da API normalmente invalidam qualquer sucesso no frontend.
Medição de custo
O custo por célula é calculado a partir do uso de tokens extraído da resposta da LLM API. Os tokens de entrada em cache são subtraídos do total de tokens de entrada para obter a entrada efetiva (apenas tokens processados pela primeira vez). Os tokens de saída nunca são armazenados em cache e permanecem inalterados. As taxas por token são obtidas do LLM Pricing no momento do teste.
Limitações
- Escopo da tarefa: Todas as 10 tarefas são construções de aplicações web full-stack. O benchmark não cobre tarefas de raciocínio puro, resolução de problemas científicos, sumarização ou cargas de trabalho de domínio específico (jurídico, médico, financeiro). As pontuações refletem especificamente a capacidade de codificação agêntica.
- Acesso apenas por API: Todos os modelos foram testados via API. Implantações locais ou on-premise dos mesmos modelos podem produzir resultados diferentes dependendo da quantização, hardware e configuração de inferência.
- Instantâneo no tempo: As versões dos modelos mudam. Os resultados refletem a versão da API ativa no momento do teste. Uma atualização do modelo pode alterar as pontuações em qualquer direção sem aviso do provedor.
- Estilo de chamada de ferramenta: Os modelos diferem na forma como estruturam gravações e edições de arquivos (por exemplo, o
apply_patchdo OpenAI agrupa um diff de arquivo completo em uma única chamada; os modelos da Anthropic gravam e reeditam em várias chamadas). A contagem de chamadas de ferramenta não é um indicador direto de qualidade. - Harness único: Todos os testes usaram o Opencode como o harness do agente. Um harness diferente pode produzir classificações relativas diferentes, especialmente para modelos cujo comportamento padrão é ajustado para padrões específicos de uso de ferramentas.
Futuras tendências dos grandes modelos de linguagem
1- Verificação de Fatos em Tempo Real com Dados ao Vivo
Os LLMs acessam fontes externas durante as conversas em vez de depender apenas dos dados de treinamento. O modelo consulta bancos de dados externos, recupera informações atuais e fornece citações.
Limitação: Ainda comete erros. As citações não garantem precisão; os modelos às vezes citam fontes incorretamente ou interpretam mal o conteúdo citado.
Microsoft Copilot: Integra o GPT-5.4 Thinking com dados ao vivo da internet, introduzindo os modos “Quick Response” e “Think Deeper” para raciocínio personalizado em diferentes tipos de tarefa.1 O agente Researcher combina o GPT para pesquisa inicial com o Anthropic’s Claude revisando os resultados quanto à precisão e qualidade da citação antes da entrega, resultando em uma melhoria de 13.8% no benchmark de pesquisa profunda DRACO em relação a sistemas autônomos.2
- ChatGPT: Pesquisa na web quando perguntado sobre eventos recentes. Cita fontes nas respostas.
- Perplexity: Construído especificamente para pesquisa com citações. Cada resposta inclui links para as fontes.
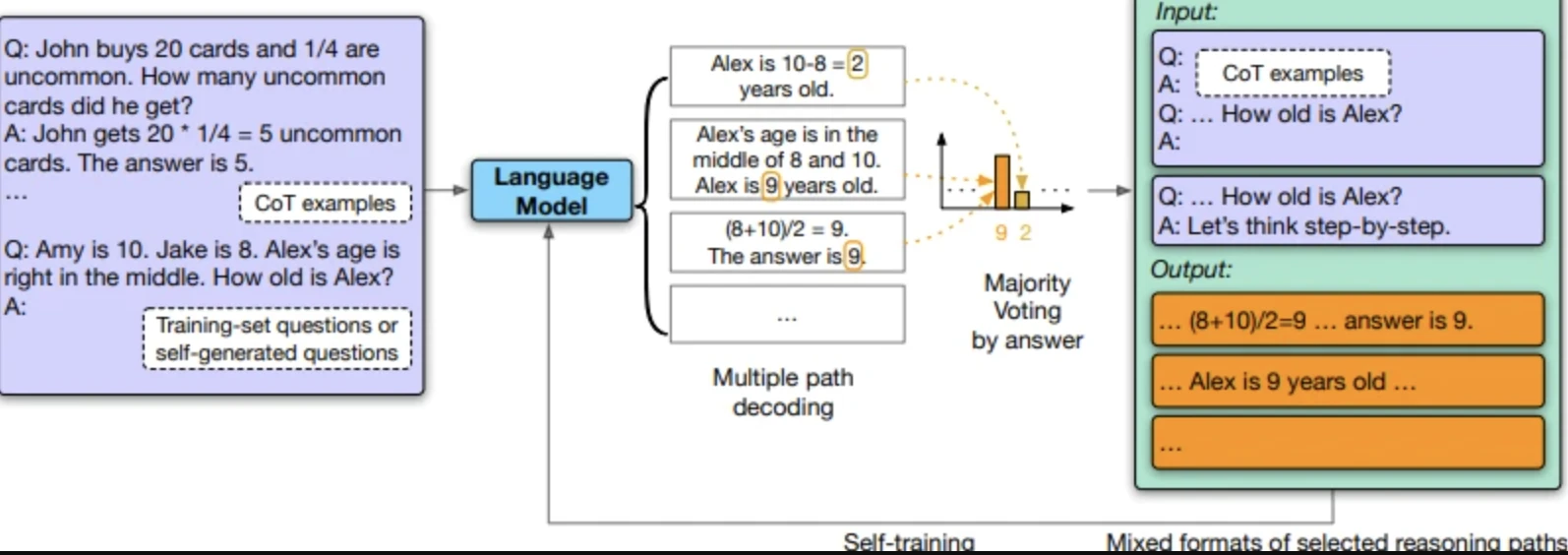
2- Dados de treinamento sintéticos
Os modelos geram seus próprios conjuntos de dados de treinamento em vez de exigir dados rotulados por humanos.
Modelo auto-melhorante do Google (pesquisa de 2023):
- O modelo cria perguntas
- Faz curadoria de respostas
- Faz fine-tune em si mesmo com os dados gerados
Melhoria de desempenho: 74.2% para 82.1% nos problemas de matemática GSM8K, 78.2% para 83.0% na compreensão de leitura DROP.
OpenAI, Anthropic e Google estão todos usando dados sintéticos para complementar conjuntos de dados rotulados por humanos. Isso reduz os custos de rotulagem de dados, mas introduz novos riscos de viés; os modelos podem amplificar seus próprios erros.
Fonte: “Large Language Models Can Self-Improve”
Uma pesquisa de março de 2026 descobriu que 76% dos pesquisadores de IA acreditam que os ganhos com escala de computação e dados estagnaram, com os principais laboratórios relatando retornos decrescentes apesar dos investimentos maciços. A descoberta sugere que o próximo salto na capacidade dos LLM é mais provável de vir de inovação arquitetural, como maior eficiência de treinamento, arquiteturas esparsas ou melhorias de raciocínio, do que simplesmente escalar ainda mais as abordagens existentes.3
3- Modelos de Especialistas Esparsos (Mistura de Especialistas)
Em vez de ativar toda a rede neural para cada entrada, apenas um subconjunto relevante de parâmetros é ativado, dependendo da tarefa. O modelo encaminha a entrada para “especialistas” especializados dentro da rede. Apenas os especialistas ativados processam a consulta.
Exemplos da vida real:
- Llama 4 Scout: 109B parâmetros totais, 17B ativos por token. A arquitetura de Mistura de Especialistas (MoE) oferece uma janela de contexto de 10M tokens em uma única H100 GPU.
- Mistral Devstral 2: Desenvolvido especificamente para tarefas de engenharia de software. 123B parâmetros, janela de contexto de 256K tokens. Alcança 72.2% no SWE-bench Verified, estabelecendo-se como o principal modelo de codificação de peso aberto. Uma variante menor, Devstral Small 2 (24B parâmetros), roda localmente em hardware de consumo sob a licença Apache 2.0.4
- Em nosso A-CODE-LLM Bench, tanto as variantes base quanto thinking do DeepSeek V4 Pro pontuaram abaixo de 0.45 no geral, com tempos de conclusão excedendo 1,700 segundos por tarefa. A capacidade de codificação agêntica do modelo fica atrás de seu forte desempenho em benchmarks de consulta única, provavelmente refletindo menor maturidade no uso de ferramentas em relação aos modelos de fronteira da Anthropic e do Google nesta fase.
4- Integração ao Fluxo de Trabalho Empresarial
Os LLMs são incorporados diretamente aos processos de negócios em vez de serem usados como ferramentas independentes.
Exemplos da vida real:
- Salesforce Agentforce (anteriormente Einstein Copilot): Integra LLMs nas operações de CRM. Responde a consultas de clientes, gera conteúdo e executa ações no Salesforce, fundamentado nos dados e metadados de CRM da organização por meio da Camada de Confiança Einstein.5
- Microsoft 365 Copilot: Incorporado no Word, Excel, PowerPoint e Outlook. Redige documentos, analisa planilhas, gera apresentações e resume threads de e-mail, usando dados da empresa por meio do Microsoft Graph para fundamentar respostas no contexto organizacional.6 O agente Researcher usa uma arquitetura multi-modelo onde o GPT cuida da pesquisa inicial e o Claude revisa os resultados antes da entrega — a primeira implementação comercial confirmada de fornecedores de IA concorrentes dentro de um único produto empresarial.
- Anthropic Claude para Empresas: A separação de memória baseada em projetos mantém os contextos de trabalho distintos entre as equipes. O Claude Opus 4.6 introduziu equipes de agentes, permitindo que vários agentes Claude dividam tarefas maiores em fluxos de trabalho paralelos, cada um responsável por um segmento e coordenando-se com os outros simultaneamente. Na mesma versão, o Claude foi integrado diretamente ao PowerPoint como um painel lateral nativo (visualização de pesquisa), permitindo que apresentações sejam construídas e editadas dentro do aplicativo sem transferências de arquivos.7
5- LLMs Híbridos com Capacidades Multimodais
Grandes modelos multimodais integram várias formas de dados, como texto, imagens e áudio, permitindo-lhes compreender e gerar conteúdo em diferentes tipos de mídia.
- Em nosso A-CODE-LLM Bench, o GPT 5.5 thinking pontuou 0.597 com um tempo médio de conclusão de 276 segundos, o modelo mais rápido acima de 0.50 em tempo. O custo por célula da API foi de $0.41–$0.45 para as variantes mini, aproximadamente um terço do custo do Claude Sonnet 4.6 em faixas de pontuação semelhantes.
- Gemini 2.5 Pro: Lida nativamente com texto, áudio, imagens, vídeo e repositórios de código inteiros dentro de uma janela de contexto de 1M tokens. Disponível no Google IA Studio, Vertex IA e NotebookLM. O preço começa em $1.25 por milhão de tokens de entrada e $10 por milhão de tokens de saída via API.8
- Llama 4 Scout e Maverick: Os modelos de código aberto da Meta usam tokens multimodais de texto e visão com early-fusion, treinados juntos desde o início, em vez de adicionados como módulos separados. Os modelos foram pré-treinados em 200 idiomas e ofereceram suporte específico de fine-tuning para 12 idiomas, incluindo árabe, espanhol, alemão e hindi.9
A capacidade multimodal é padrão nos modelos de fronteira. O desafio restante é a consistência: os modelos têm bom desempenho em combinações comuns de imagem e texto, mas se degradam em contextos visuais raros, entradas de baixa resolução e raciocínio intermodal que exige conectar evidências visuais e textuais.
6- Modelos de raciocínio
Modelos que pensam nos problemas passo a passo em vez de gerar respostas imediatas.
Essa mudança de previsão para raciocínio é fundamental para possibilitar:
- Comportamento agêntico, onde os modelos planejam, executam e adaptam tarefas de forma autônoma.
- IA interpretável, onde as saídas são passo a passo e logicamente sólidas, não apenas plausíveis.
- Claude Sonnet 4.6: Líder de produção atual da Anthropic em benchmarks de codificação agêntica, pontuando 0.748 no A-CODE-LLM Bench da AIMultiple, acima de todas as variantes Opus. Usa pensamento adaptativo, onde o modelo determina dinamicamente a profundidade do raciocínio com base na complexidade da tarefa, sem exigir troca manual de modo. O preço é de $3/$15 por milhão de tokens. No SWE-bench Verified, o Sonnet 4.6 atinge 79.6%, a um ponto do 80.8% do Opus 4.7, com um quinto do custo.
- Claude Opus 4.7: Carro-chefe da Anthropic em raciocínio complexo de múltiplas etapas e visão (98.5% no benchmark de acuidade visual XBOW, vs 54.5% da geração anterior). Preço de $5/$25 por milhão de tokens. No benchmark da AIMultiple, o Opus 4.7 marcou 0.61, abaixo do Sonnet 4.6 (0.748) e do Opus 4.8 (0.702), principalmente devido à latência mais alta (média de 1,562 segundos por tarefa) que degradou as pontuações de IU. A diferença em relação ao Sonnet aumenta em tarefas de raciocínio abstrato, como ARC-AGI-2.
- Claude Opus 4.8: Lançado após o Opus 4.7, recuperando-se da regressão do 4.7 em codificação agêntica. Marcou 0.702 no A-CODE-LLM Bench, quinto lugar geral. Concluiu a tarefa de linha de base em 34 segundos — o modelo mais rápido no benchmark nessa tarefa usando apenas 6 chamadas de ferramenta. Preço: $2.92 por célula em condições de benchmark ($15/$75 por milhão de tokens).
7- Modelos Ajustados para Domínios Específicos
Modelos treinados em dados especializados para setores específicos em vez de treinamento geral.
Google, Microsoft e Meta lançaram importantes modelos proprietários de domínio específico e ajustados, visando casos de uso empresariais, além de suas ofertas de propósito geral.
Esses LLMs especializados podem resultar em menos alucinações e maior precisão, aproveitando o pré-treinamento específico do domínio, o alinhamento do modelo e o fine-tuning supervisionado.
Programação
GitHub Copilot: Ajustado em repositórios de código. Em julho de 2025, 20 milhões de desenvolvedores usam o GitHub Copilot, um aumento de 400% em relação ao ano anterior, e 90% das empresas da Fortune 100 o utilizam. Ele autocompleta código, gera funções e sugere correções de bugs.10
Finanças
BloombergGPT: 50 bilhões de parâmetros, LLM treinado em um conjunto de dados de 363 bilhões de tokens de documentos financeiros da Bloomberg, superando modelos de tamanho comparável em benchmarks de PLN financeiro, incluindo análise de sentimento, reconhecimento de entidades nomeadas e resposta a perguntas.11
Saúde
Google’s Med-PaLM 2: Ajustado em conjuntos de dados médicos, alcançou precisão de mais de 85% em perguntas no estilo do Exame de Licenciamento Médico dos EUA (USMLE), sendo o primeiro LLM a atingir desempenho de nível especializado neste benchmark. Ele alimenta o MedLM, a família de modelos de base para saúde do Google Cloud.12
Direito
ChatLAW: Um modelo de linguagem de código aberto treinado especificamente em conjuntos de dados do domínio jurídico chinês.13
8- IA Ética e Mitigação de Viés
As empresas estão cada vez mais focadas em IA ética e mitigação de viés no desenvolvimento e implantação de grandes modelos de linguagem.
- Anthropic e OpenAI conduziram uma avaliação mútua de alinhamento em meados de 2025, testando os modelos públicos uma da outra quanto a bajulação, tendências de denúncia e comportamentos de autopreservação. O exercício encontrou bajulação em todos os modelos testados, incluindo casos em que os modelos validaram decisões prejudiciais de usuários simulados que exibiam crenças delirantes. A Anthropic posteriormente desenvolveu o framework de teste Bloom especificamente para avaliar esse comportamento em novos modelos.
- Anthropic também lançou o Claude Mythos Preview (Projeto Glasswing), um modelo apenas para convidados, disponibilizado a um pequeno conjunto de organizações especificamente para encontrar e corrigir vulnerabilidades de segurança cibernética nos principais sistemas operacionais e navegadores da web. A Anthropic afirmou que não planeja disponibilizar esse modelo para o público geral. A abordagem de acesso controlado representa um novo framework para implantar modelos especialistas altamente capazes onde o perfil de risco exige uma implementação restrita.14
- Google DeepMind: Publicou “The Ethics of Advanced IA Assistants”, oferecendo o primeiro tratamento sistemático das questões éticas e sociais levantadas pelos agentes de IA, cobrindo alinhamento de valores, riscos de manipulação, antropomorfismo, privacidade e equidade. A avaliação de IA Responsável da empresa incluiu mais de 350 exercícios adversariais de equipe vermelha e introduziu um novo Nível de Capacidade Crítica especificamente para manipulação prejudicial, tratando-o como um risco de nível de fronteira, juntamente com ataques cibernéticos e ameaças QBRN.
Limitações dos grandes modelos de linguagem (LLMs)
1- Alucinações
Os modelos geram informações que parecem plausíveis, mas são incorretas.
O ranking de alucinações da Vectara é o benchmark de sumarização fundamentada mais amplamente referenciado do setor. No conjunto de dados original da Vectara, os modelos Gemini do Google ocupam consistentemente as primeiras posições, com as variantes Gemini Flash alcançando taxas de alucinação abaixo de 1%. A família GPT da OpenAI se agrupa entre 0.8% e 2.0%.
A Vectara lançou um benchmark significativamente mais difícil no final de 2025, com 7,700 artigos (acima dos 1,000), documentos mais longos de até 32K tokens e conteúdo abrangendo direito, medicina, finanças e tecnologia. As descobertas no novo conjunto de dados revelam um padrão contra-intuitivo: os modelos de raciocínio e pensamento que se destacam em tarefas complexas frequentemente alucinam mais na sumarização fundamentada do que modelos menores e mais rápidos. A maioria dos modelos da classe thinking mostra taxas de alucinação acima de 10% no conjunto de dados mais difícil, enquanto modelos mais leves como as variantes Gemini Flash mantêm taxas mais baixas.15
Nota: Nenhum benchmark único fornece uma “taxa de alucinação” definitiva para qualquer modelo. Uma avaliação responsável cruza pelo menos dois benchmarks medindo coisas diferentes: uma tarefa fundamentada (Vectara), uma tarefa de conhecimento aberto, e especifica a versão exata do modelo e as condições de chamada.
Todos os modelos alucinam. A frequência foi reduzida substancialmente, de aproximadamente 21% em 2021 para menos de 5% para os melhores desempenhos em benchmarks padrão, mas não foi eliminada. Aplicações críticas ainda exigem verificação humana.
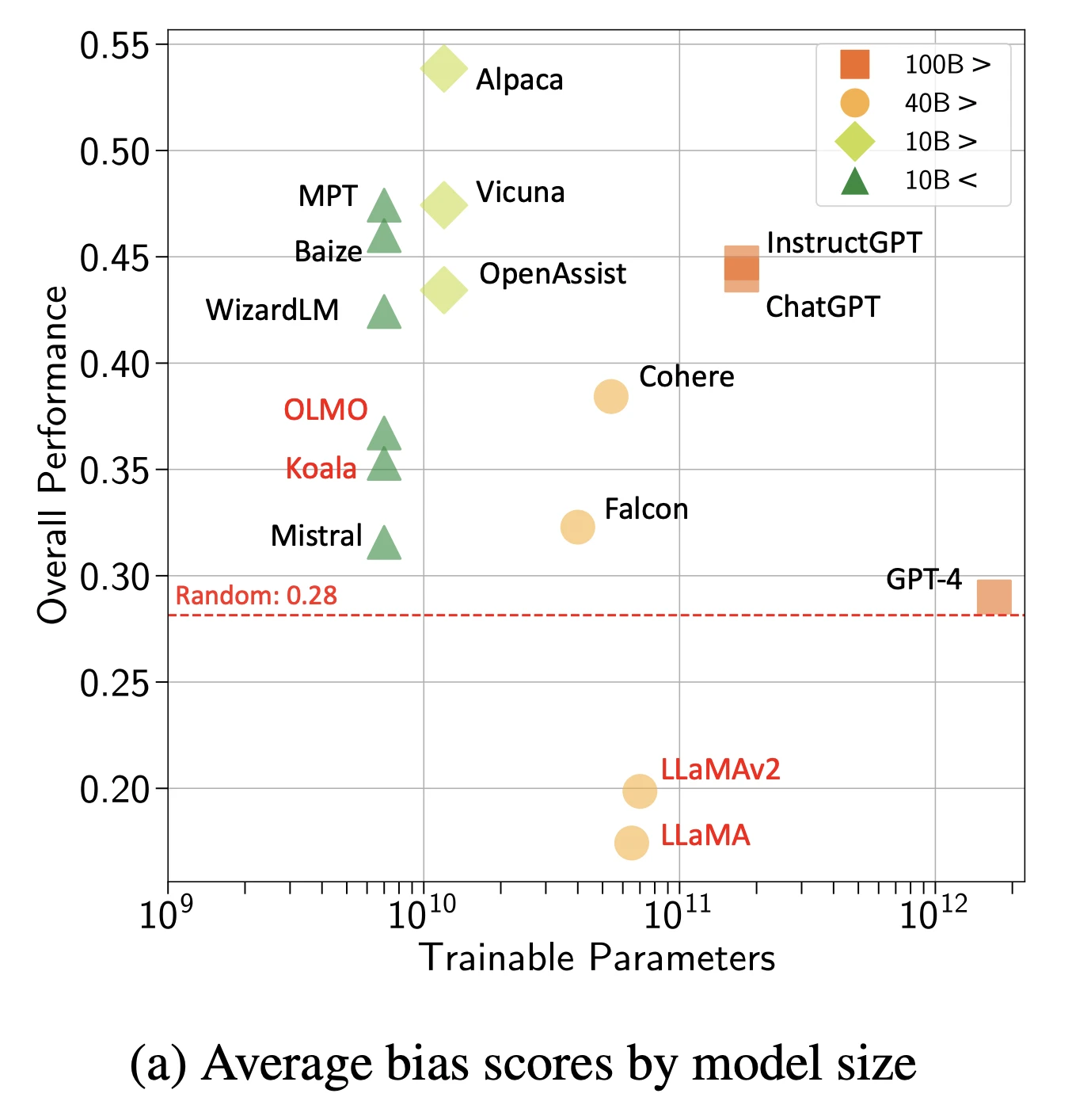
2- Viés
Os modelos absorvem e amplificam vieses sociais dos dados de treinamento.
Figura: Pontuações gerais de viés por modelos e tamanho
Fonte: Arxiv16
Tipos de viés observados:
- Viés de gênero nas sugestões de ocupação
- Viés racial nas simulações de triagem de currículos
- Viés etário nas recomendações de saúde
- Viés socioeconômico no conteúdo educacional
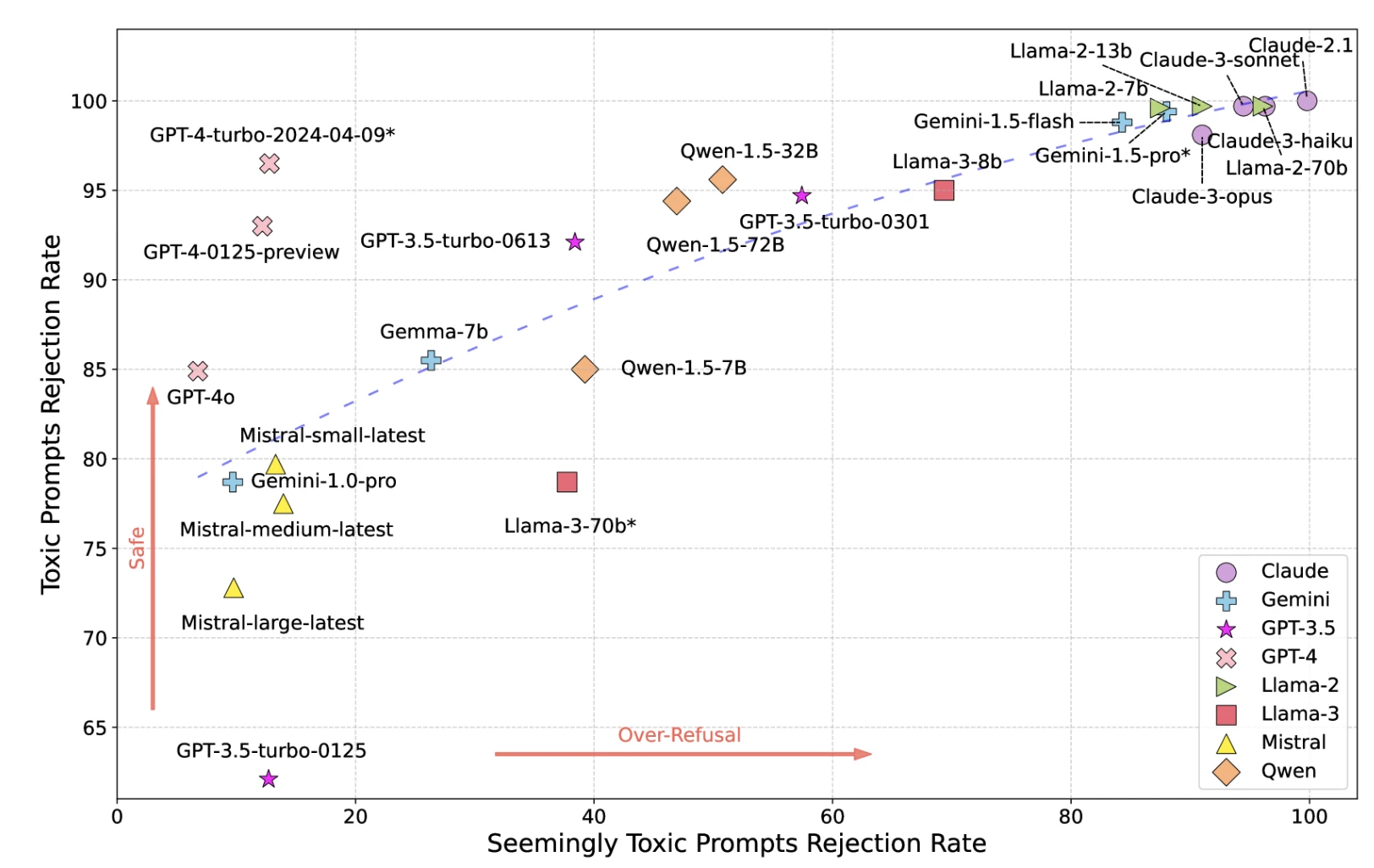
3- Toxicidade
Os modelos podem gerar conteúdo prejudicial, ofensivo ou tóxico, apesar das medidas de segurança.
Figura: Mapa de toxicidade dos LLMs
Fonte: Pesquisadores da UCLA, UC Berkeley17
*GPT-4-turbo-2024-04-09*, Llama-3-70b* e Gemini-1.5-pro* são usados como moderador, os resultados podem ser tendenciosos para esses 3 modelos.
Medidas de segurança rígidas reduzem a toxicidade, mas aumentam os falsos positivos (recusando solicitações inofensivas). Medidas brandas permitem a passagem de toxicidade.
4- Janela de Contexto Limitações
Cada modelo tem uma capacidade de memória fixa — o número de tokens que pode processar em uma única sessão. Se exceder esse limite, o modelo trunca o conteúdo anterior ou recusa a solicitação. A diferença prática entre os modelos é grande o suficiente para importar em cargas de trabalho reais.
Janelas de contexto mais recentes:
- Llama 4 Scout (Meta): 10M tokens (~7.5M palavras) — a maior janela de contexto verificada em produção entre os principais modelos.18 Na prática, isso significa carregar bases de código inteiras, arquivos jurídicos ou históricos de conversas de vários dias sem a necessidade de segmentar.
- Gemini 2.5 Pro: 1,048,576 tokens (~780,000 palavras), com entrada multimodal nativa em texto, áudio, imagens e vídeo na mesma janela. A recuperação se mantém em 100% até 530,000 tokens e 99.7% no limite total de 1 milhão de tokens
- Claude Sonnet 4.6: 1M tokens (~750,000 palavras) com preço padrão, disponível sem cabeçalhos beta ou configuração especial.19
- GPT-5.5: Janela de contexto de 1M tokens no nível da API.20
Uma grande janela de contexto não significa automaticamente melhor desempenho em toda a sua extensão. A recuperação se degrada em direção ao meio de contextos muito longos na maioria dos modelos, e os custos escalam com o comprimento da entrada — processar 1M tokens custa significativamente mais do que processar 10K tokens no mesmo modelo. Para a maioria das cargas de trabalho de produção, a questão prática não é qual modelo tem a maior janela, mas qual modelo recupera de forma confiável nos comprimentos de contexto que seu caso de uso realmente exige.
5- Corte de Conhecimento Estático
Os modelos dependem de conhecimento pré-treinado com uma data de corte específica. Não têm acesso a informações posteriores ao treinamento, a menos que estejam conectados a fontes externas.
Problemas:
- Informações desatualizadas sobre eventos atuais
- Incapacidade de lidar com desenvolvimentos recentes
- Menor relevância em domínios dinâmicos (tecnologia, finanças, medicina)
Solução: Integração de busca na web. ChatGPT, Claude e Perplexity oferecem pesquisa em tempo real. Mas a pesquisa não elimina as alucinações; os modelos às vezes interpretam mal os resultados da pesquisa.
Principais Plataformas de LLM
GPT-5.5
O atual carro-chefe da OpenAI foi lançado em 23 de abril de 2026. Construído em torno de um esforço de raciocínio configurável, os desenvolvedores definem a profundidade do pensamento por solicitação (de nenhum a xhigh), para que consultas simples não consumam computação reservada para problemas difíceis. O modelo se destaca em codificação agêntica, uso de computador e tarefas de longo horizonte, onde precisa manter o contexto em sistemas grandes e verificar seu próprio trabalho durante a execução.21
Quem usa: Desenvolvedores, empresas e criadores de conteúdo. A maior base de usuários entre os LLMs.
Limitações: $5/$30 por milhão de tokens — o preço base mais alto desta lista. Ainda alucina. Requer integração de busca na web para qualquer coisa após seu corte de treinamento.
Claude Opus 4.8 / Sonnet 4.6
O Claude Sonnet 4.6 lidera o A-CODE-LLM Bench da AIMultiple com uma pontuação geral de 0.748 a $1.26–$1.33 por célula, acima de todas as variantes Opus testadas. O Claude Opus 4.8 segue com 0.702, recuperando-se da regressão do Opus 4.7 (0.61) a $2.92 por célula. O Opus 4.7 permanece o melhor desempenho em tarefas complexas de raciocínio em várias etapas e visão (98.5% no benchmark de acuidade visual XBOW), mas seu tempo médio de conclusão de 1,562 segundos em fluxos de trabalho agênticos eleva o custo total para $3.08 por célula, o modelo mais caro do benchmark.
Tanto o Sonnet 4.6 quanto as variantes Opus usam pensamento adaptativo: o modelo determina a profundidade do raciocínio com base na complexidade da tarefa, sem exigir troca manual de modo. O Sonnet 4.6 fez o menor número de chamadas de ferramenta por tarefa entre os modelos da Anthropic (51 base, 48 thinking), alcançando a pontuação máxima do benchmark com menos iterações do que as variantes Opus (56–70 chamadas de ferramenta). As equipes de agentes, disponíveis na linha de produção da Anthropic, permitem que várias instâncias do Claude dividam uma tarefa em fluxos de trabalho paralelos coordenados em tempo real.
Quem usa: Desenvolvedores e empresas que executam codificação agêntica, fluxos de trabalho de pesquisa ou pipelines de múltiplos agentes. Equipes que priorizam a eficiência de custos usam o Sonnet 4.6; equipes com cargas de trabalho pesadas em visão ou raciocínio complexo usam o Opus 4.7.
Limitações: O pensamento estendido é mais lento e mais caro por token. A diferença de desempenho em relação ao Sonnet aumenta em tarefas de raciocínio abstrato (ARC-AGI-2). O Opus 4.8 custa $15/$75 por milhão de tokens.
Gemini 3.5 Flash
O Gemini 3.5 Flash thinking pontuou 0.625, o melhor resultado não-Anthropic, a $1.30 por célula e com tempo médio de conclusão de 390 segundos. A variante base pontuou abaixo do thinking com um custo mais alto ($0.56 por célula de linha de base), devido à substituição excessiva (131 linhas para uma tarefa cuja solução de referência tem aproximadamente 50 linhas).
Llama 4 Scout
Modelo MoE de código aberto da Meta. 109B parâmetros totais, 17B ativos por token, roda em uma única NVIDIA H100 GPU com quantização int4. A implicação prática é que uma janela de contexto de 10M tokens é acessível sem necessidade de contrato com data center.22 A multimodalidade com early-fusion significa que texto e visão são processados conjuntamente desde a primeira camada, em vez de combinados no estágio de saída. Disponível sob a Licença Comunitária Llama 4 da Meta.
Quem usa: Pesquisadores, organizações que precisam de implantação on-premise, desenvolvedores que evitam dependência de fornecedor e equipes onde o custo em escala torna os preços da API inviáveis.
Limitações: O desempenho depende muito da configuração de hospedagem e das escolhas de quantização. Requer investimento em infraestrutura e capacidade de operações de ML. Menos polimento de produção do que os modelos comerciais.
DeepSeek V4
O modelo de quarta geração da DeepSeek está disponível como pré-visualização. Usa uma arquitetura MoE de 1 trilhão de parâmetros, aproximadamente 50% maior que o V3, com capacidades multimodais em texto, imagem e vídeo. O Thinking in Tool-Use permite que o modelo raciocine internamente antes de chamar ferramentas externas e verifique as saídas das ferramentas em relação à sua própria lógica, o que é o principal diferencial para fluxos de trabalho agênticos. O preço de entrada da API começa em $0.27 por milhão de tokens (cache-miss), aproximadamente 18x mais barato que o GPT-5.5.23
Perguntas frequentes
Um grande modelo de linguagem é um modelo de IA projetado para gerar e compreender texto semelhante ao humano, analisando grandes quantidades de dados.
Esses modelos fundamentais são baseados em técnicas de aprendizado profundo e geralmente envolvem redes neurais com muitas camadas e um grande número de parâmetros, permitindo-lhes capturar padrões complexos nos dados em que foram treinados.
Cite esta pesquisa
Escolha o formato adequado ao local onde você vai publicar. Colar a versão com link no seu CMS preserva o backlink.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Sezer, Sena},
title = {{O Futuro dos Grandes Modelos de Linguagem}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/future-of-large-language-models}},
note = {AIMultiple. Acessado em 25 Junho 2026}
}
Seja o primeiro a comentar
Seu endereço de e-mail não será publicado. Todos os campos são obrigatórios. Os comentários são deixados em seu idioma original.