Análise comparativa das ferramentas de observabilidade RAG
Comparamos quatro plataformas de observabilidade RAG em um pipeline LangGraph de 7 nós em três dimensões práticas: sobrecarga de latência, esforço de integração e compensações entre plataformas.
Métricas de sobrecarga de latência
Explicação das métricas:
A média é a latência média em 150 chamadas de graph.invoke() medidas. As avaliações do LLM-judge são executadas após a parada do temporizador.
A mediana representa a latência do 50º percentil. As respostas da API LLM apresentam caudas longas, portanto, a mediana é um indicador mais preciso do desempenho típico das consultas.
P95 é o percentil 95, a latência no pior caso para 95% das consultas.
A diferença entre a latência da plataforma e a latência de referência não monitorada é chamada de sobrecarga versus linha de base.
Para entender detalhadamente nossa avaliação e métricas, consulte nossa metodologia de benchmark para as ferramentas de observabilidade RAG.
Esforço de integração pela plataforma
Principais conclusões
A variação da API LLM supera em muito a sobrecarga de monitoramento.
O desvio padrão de referência foi de 2.645 ms. A maior sobrecarga foi de 169 ms. Seria necessário remover o LLM do pipeline para medir a sobrecarga do SDK isoladamente. Os benchmarks de execução única das ferramentas de monitoramento medem a variância da API, não a sobrecarga do SDK.
LangSmith requer o mínimo de código de integração.
Foram adicionadas 12 linhas em comparação com a linha de base (2 variáveis de ambiente). Ferramentas baseadas em decoradores (Weave, Laminar, Langfuse) precisam de 29 a 40 linhas. A vantagem: o LangSmith captura tudo (incluindo chamadas internas do LangChain que você pode não precisar), enquanto as ferramentas baseadas em decoradores oferecem controle explícito sobre o que é rastreado.
Somente Langfuse e Laminar oferecem hospedagem própria gratuita.
Ambas são de código aberto (MIT e Apache 2.0). LangSmith e Weave exigem contratos corporativos para implantações auto-hospedadas.
Weave e LangSmith lideram a orquestração da avaliação.
Ambas as plataformas oferecem orquestradores de avaliação completos que lidam com iteração de conjuntos de dados, previsão, pontuação e agregação em uma única chamada. O Langfuse fornece infraestrutura de pontuação ( create_score() ), mas deixa a orquestração a cargo do desenvolvedor. Os recursos de avaliação do Laminar são menos maduros: não há interface de comparação de experimentos e os avaliadores pré-construídos são limitados.
A Langfuse tem o menor custo por unidade em grandes volumes.
US$ 6 por 100 mil unidades para mais de 50 milhões de dados. A LangSmith cobra por rastreamento (US$ 2,50 a US$ 5 por 1.000 dados). A Weave cobra por MB de dados ingeridos (US$ 0,10 por MB excedente).
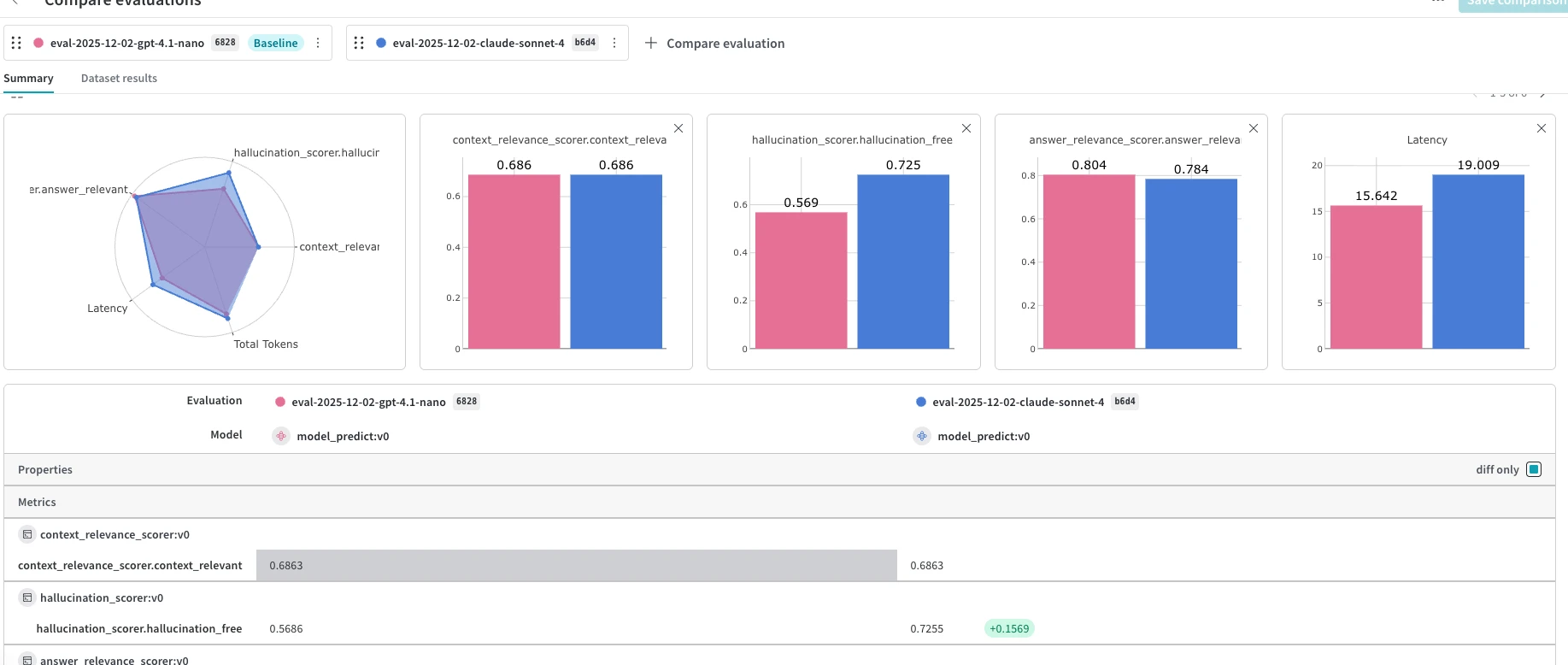
Capacidades de avaliação por plataforma
Pesos e Viéses (Trama)
- O orquestrador de avaliação:
weave.Evaluation.evaluate()lida com iteração de conjuntos de dados, previsão, pontuação e agregação em uma única chamada. 1 - Pontuadores personalizados: Subclasse
Scorerou qualquer função@weave.op() - Pontuadores pré-construídos: Alguns (correção, etc.)
- Gerenciamento de conjuntos de dados:
weave.Datasetcom versionamento,publish(),from_pandas() - Comparação de experimentos: aba Avaliações com visualização Comparar + Classificações
- Avaliação online:
EvaluationLogger, mecanismos de controle/monitoramento
LangSmith
- Orquestrador de avaliação: função
evaluate()2 - Pontuadores personalizados:
(Run, Example) -> dict - Avaliadores pré-configurados: Sim (correção de controle de qualidade, distância de incorporação, avaliador LLM baseado em critérios)
- Gerenciamento de conjuntos de dados: API CRUD completa, conjuntos de dados versionados.
- Comparação de experimentos: comparação lado a lado por conjunto de dados
- Avaliação online: filas de anotações, regras automatizadas em rastreamentos de produção.
Laminar
- Orquestrador de avaliação: A
evaluate()básica está disponível, mas é menos utilizada. 3 - Pontuadores personalizados: funções decoradas
@observe() - Marcadores pré-configurados: Mínimos
- Gerenciamento de conjuntos de dados: interface do usuário + SDK limitado
- Comparação de experimentos: Manual
- Avaliação online:
@observe()em funções de produção
Langfuse
- Orquestrador de avaliação: Nenhum orquestrador integrado. Loop manual +
create_score()por traço. 4 - Pontuadores personalizados: Qualquer código +
create_score(trace_id, name, value) - Avaliadores pré-configurados: Configurações de avaliação baseadas em modelos na interface do usuário
- Gerenciamento de conjuntos de dados: conjuntos de dados de interface do usuário + API
- Comparação de experimentos: Manual (filtragem de sessão)
- Avaliação online:
create_score()em rastreamentos em tempo real, filas de anotações humanas
Comparação de preços
Nível gratuito e retenção de dados
Planos pagos e preços de uso
Os preços apresentados são referentes a março de 2026 e podem sofrer alterações ao longo do tempo. Consulte o site de cada fornecedor para obter as tarifas mais recentes.
Implantação em nuvem, autohospedada e de código aberto
Visibilidade de rastreamento e depuração
- O Weave exibe uma visualização em árvore das chamadas decoradas com
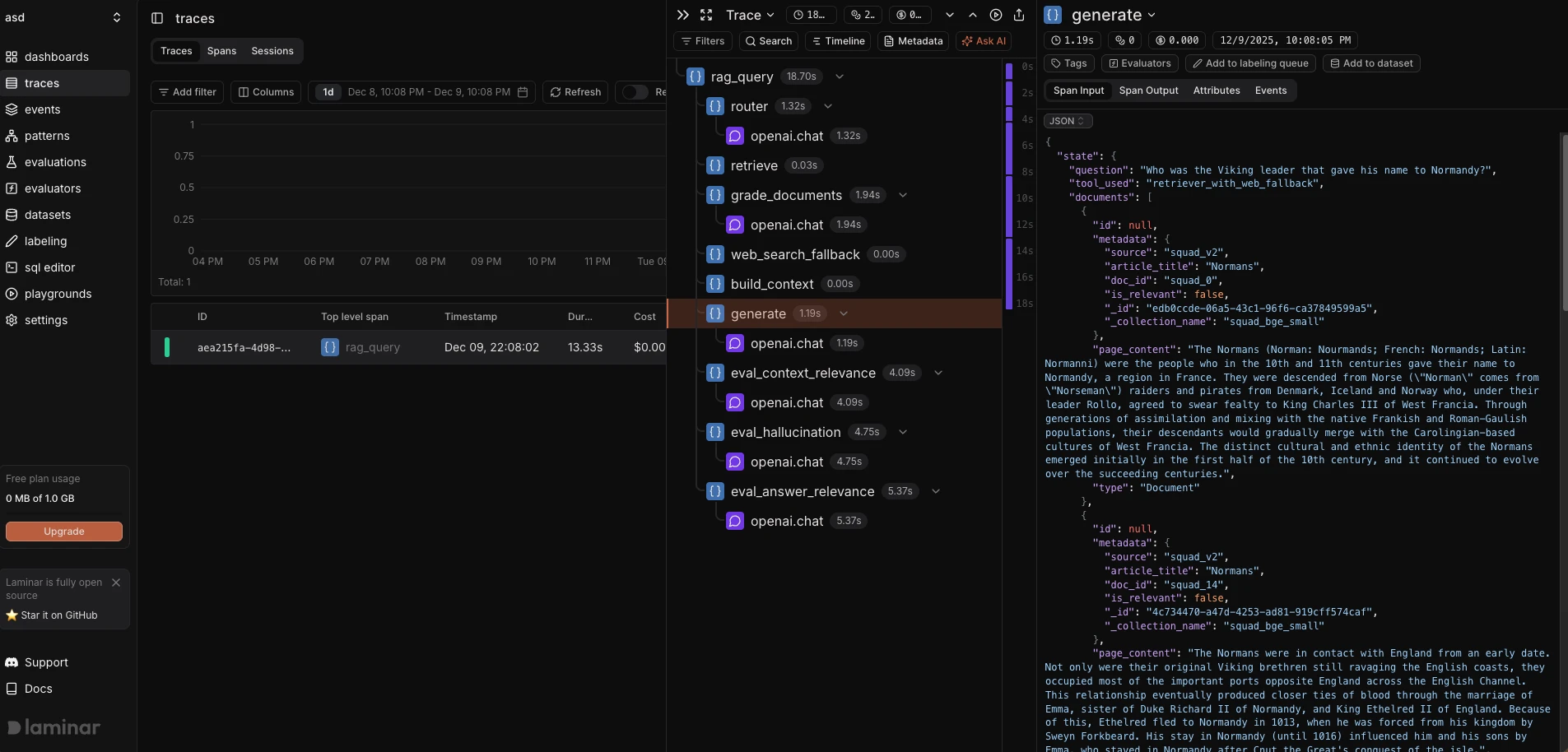
@weave.op(). Clicar em um nó revela as entradas, saídas e tempos de execução. A aba "Evals" vincula os rastreamentos aos resultados da avaliação. - O LangSmith captura automaticamente todo o gráfico de execução do LangChain, incluindo as etapas internas da cadeia. A visualização do rastreamento inclui a contagem de tokens, a análise da latência e as estimativas de custo por chamada LLM.
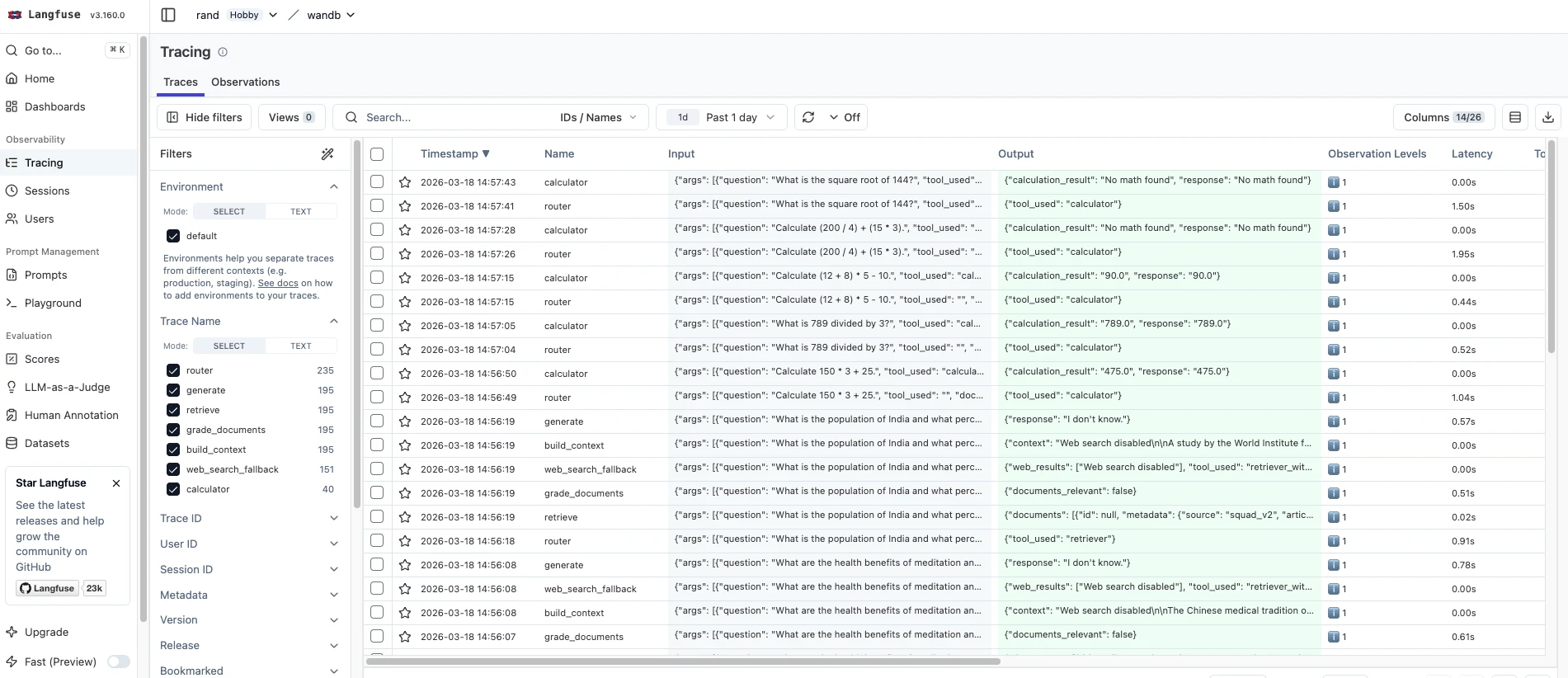
- O Langfuse exibe rastreamentos com intervalos. O rastreamento de sessão agrupa várias consultas do mesmo usuário. O rastreamento de custos está integrado à visualização de rastreamento.
- O Laminar exibe uma linha do tempo de intervalos semelhante às ferramentas de rastreamento distribuído. As funções decoradas com
@observe()aparecem como intervalos com captura de entrada/saída.
Qual ferramenta para qual caso de uso
- Pipeline LangChain, rastreamento sem esforço: LangSmith. Instrumentação automática de variáveis de ambiente, +12 linhas de código.
- Já utiliza o W&B, precisa de orquestração de avaliação: Weave.
weave.Evaluation+ versionamento de conjuntos de dados + rankings. - Precisa de hospedagem própria sem contrato empresarial? Langfuse. Código aberto (MIT), Docker Compose, região de dados da UE.
- Deseja observabilidade de código aberto, sem precisar de um orquestrador de avaliação: Laminar. Apache 2.0, decorador
@observe()leve. - Produção em grande volume, sensível a custos: Langfuse. US$ 6 por 100 mil unidades com volume superior a 50 milhões.
- Necessário rastreamento e avaliação integrada: Weave ou LangSmith. Orquestradores de avaliação completos com gerenciamento de conjuntos de dados.
Metodologia de referência para ferramentas de observabilidade RAG
Hardware : Apple M4, 16 GB de RAM, macOS 26.3
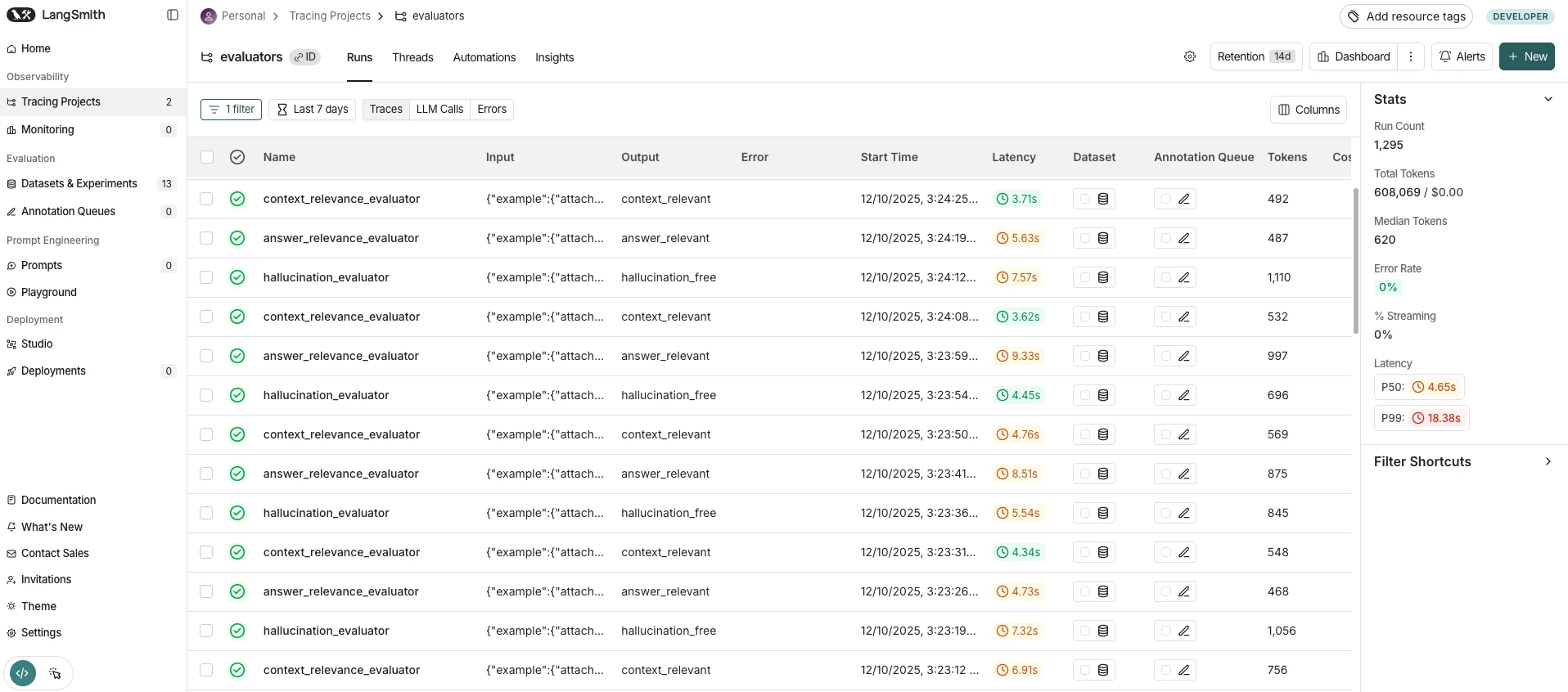
Pipeline RAG : Grafo de estados LangGraph com 7 nós (roteador, recuperador, avaliador de documentos, fallback para pesquisa na web, calculadora, construtor de contexto, gerador)
LLM : openai/gpt-4.1-nano via OpenRouter (temperatura 0.0)
Roteador LLM : google/gemini-2.5-flash via OpenRouter (saída estruturada)
Avaliação LLM : google/gemini-2.5-pro via OpenRouter
Banco de dados de vetores : Qdrant 1.12 (Docker local), distância cosseno, 1.204 documentos SQuAD
Incorporações : BAAI/bge-small-en-v1.5 (384 dimensões, inferência por CPU)
Recuperação de candidatos : os 5 principais documentos por consulta
Conjunto de consultas : 30 consultas selecionadas, 20 factuais (recuperação de base de conhecimento), 5 de múltiplos saltos (que exigem a combinação de informações), 5 matemáticas (encaminhadas para o nó da calculadora).
Pipeline : Aquecimento com 3 consultas descartado. 5 passagens completas pelas 30 consultas em cada plataforma. Total: 150 execuções medidas por plataforma. Temporizador: time.perf_counter() engloba apenas graph.invoke() . As avaliações do LLM-judge são executadas após a parada do temporizador. gc.collect() é executado entre iterações e plataformas. Primeiro a linha de base e, em seguida, cada plataforma sequencialmente.
Variável controlada : Todas as plataformas compartilham o mesmo código de pipeline, instâncias LLM, configuração do recuperador e conjunto de consultas. A única variável é a camada de observabilidade.
Testes estatísticos: IC de 95% via distribuição t, teste U de Mann-Whitney (não paramétrico, bicaudal) para significância, d de Cohen para tamanho do efeito, método IQR para detecção de outliers.
Ferramentas testadas
Como funciona a observabilidade RAG
Cada ferramenta empacota chamadas de função instrumentadas como um "rastreamento" (uma árvore de "spans") e as envia para um servidor. A sobrecarga vem de três operações em cada chamada: (1) criação do span na entrada, (2) serialização da carga útil no retorno e (3) transmissão em segundo plano. A maioria das ferramentas transmite de forma assíncrona, mas a criação e a serialização do span ocorrem em linha.
Variáveis de ambiente vs. decoradores vs. instrumentação do SDK
Instrumentação de variáveis de ambiente (LangSmith). Definir LANGCHAIN_TRACING_V2=true ativa os recursos de rastreamento integrados ao LangChain e ao LangGraph. Cada chamada LLM, invocação de retriever e nó do grafo é capturado automaticamente. Nenhuma alteração no código do pipeline é necessária.
(Weave, Laminar, Langfuse). O desenvolvedor envolve cada função com um decorador ( @weave.op() , @observe() ). Funções sem decorador não são rastreadas.
Limitações
Carga de trabalho de consulta sequencial de thread única. Requisições simultâneas em produção podem alterar o perfil de sobrecarga devido à contenção de liberação assíncrona.
APIs externas do LLM (OpenRouter) dominam a latência total, comprimindo a sobrecarga relativa de monitoramento. A inferência local (por exemplo, Ollama) tornaria a sobrecarga proporcionalmente maior.
Apenas para backends em nuvem. Implantações auto-hospedadas do Langfuse e do Laminar podem ter sobrecargas diferentes, já que evitam a transmissão de dados pela rede para um serviço de rastreamento externo.
A fase de aquecimento elimina os custos de inicialização a frio. Implantações sem servidor teriam uma sobrecarga maior na primeira solicitação devido à inicialização do SDK.
O LangSmith captura todas as chamadas internas do LangChain, não apenas as dos 7 nós do pipeline. Outras plataformas rastreiam apenas funções decoradas. Isso faz com que a comparação se baseie em diferentes escopos de instrumentação, e não em cargas de trabalho equivalentes.
Dados de preços coletados em março de 2026. Verifique as tarifas atuais no site de cada fornecedor.
Conclusão
A latência não é um critério útil para escolher entre essas ferramentas. Todas as quatro adicionaram menos de 170 ms a um pipeline onde as chamadas da API do LLM levam de 1.000 a 3.000 ms, e nenhuma das diferenças foi estatisticamente significativa.
O LangSmith é o mais rápido para integrar se você estiver usando o LangChain de 12 linhas e tiver rastreamento completo. Tanto o Weave quanto o LangSmith oferecem orquestração de avaliação, algo que o Langfuse e o Laminar não oferecem. Langfuse e Laminar são as únicas opções se você precisar de hospedagem própria sem um contrato corporativo.
Leitura complementar
Explore outros benchmarks RAG, como:
- Modelos de incorporação: OpenAI vs Gemini vs Cohere
- Os 16 principais modelos de incorporação de código aberto para RAG
- Banco de dados de vetores principais para RAG: Qdrant vs Weaviate vs Pinecone
- Análise comparativa do Reranker: Comparação dos 8 melhores modelos
- Modelos de Incorporação Multimodal: Apple vs Meta vs OpenAI
- Comparação entre Graph RAG e Vector RAG
- Os 10 principais modelos de incorporação multilíngue para RAG
Cite esta pesquisa
Escolha o formato adequado ao local onde você vai publicar. Colar a versão com link no seu CMS preserva o backlink.
@misc{sar2026,
author = {Sarı, Ekrem},
title = {{Análise comparativa das ferramentas de observabilidade RAG}},
year = {2026},
month = mar,
howpublished = {\url{https://aimultiple.com/rag-monitoring}},
note = {AIMultiple. Retrieved Março 23, 2026}
}
Seja o primeiro a comentar
Seu endereço de e-mail não será publicado. Todos os campos são obrigatórios. Os comentários são deixados em seu idioma original.