RAG Estruturas: LangChain vs LangGraph vs LlamaIndex
Comparamos 5 frameworks RAG: LangChain, LangGraph, LlamaIndex, Haystack e DSPy, construindo o mesmo fluxo de trabalho agêntico de RAG com componentes padronizados: modelos idênticos (GPT-4.1-mini), embeddings (BGE-small), recuperador (Qdrant) e ferramentas (pesquisa na web Tavily). Isto isola a verdadeira sobrecarga e eficiência de tokens de cada framework.
Resultados do benchmark de frameworks RAG
O benchmark consistiu em 100 consultas, com cada framework executando o conjunto completo 100 vezes para fornecer médias estáveis.
- Média de Tokens: Total de tokens consumidos em todas as chamadas ao LLM (roteador, classificador de documentos, classificador de respostas e gerador), incluindo tanto prompts (com contexto recuperado) quanto conclusões. Menos = menor custo de API.
- Sobrecarga da Framework: Tempo puro de orquestração (ms), o processamento interno da framework (lógica de roteamento, gestão de estado, etc.), excluindo LLM API e chamadas a ferramentas. Menos = framework mais leve.
Todas as implementações alcançaram 100% de precisão no conjunto de teste. Usaram os mesmos modelos, temperaturas, fornecedor de recuperação, ferramenta de pesquisa na web e um limite partilhado de tokens de contexto.
Principais Descobertas
- Concentramo-nos em controlar o que é controlável: Mesma família de modelos e temperaturas, max_tokens por nó, recuperador (Qdrant + BGE-small, k=5, normalização ativada), fornecedor web (apenas Tavily), política de roteador (heurística + modelo), retorno antecipado da calculadora, limite partilhado de tokens de contexto, rubrica de classificação idêntica, instrumentação unificada. Isto reduz substancialmente os principais fatores de confusão nas nossas medições.
- A sobrecarga da framework é mensurável mas pequena: Observámos ~3–14 ms por consulta provenientes da lógica de orquestração. Estas diferenças são reais, mas não são a principal fonte dos gaps de latência superiores a 1 s; a maior parte do tempo é gasta em I/O com modelos/ferramentas externos.
- O desempenho acompanha os tokens (sob estas restrições): O DSPy apresenta a menor sobrecarga de framework (~3,53 ms). O Haystack (~5,9 ms) e o LlamaIndex (~6 ms) seguem-se, enquanto o LangChain (~10 ms) e o LangGraph (~14 ms) são mais elevados. O uso de tokens é mais baixo para o Haystack (~1,57k), seguido do LlamaIndex (~1,60k); o DSPy e o LangGraph estão em ~2,03k, e o LangChain em ~2,40k.
- O caminho de roteamento/ferramenta é importante: Pequenas alterações no roteamento inicial (recuperador vs. web vs. calculadora) e no comportamento de fallback afetam tanto os tokens como o tempo, mesmo quando os prompts e os orçamentos estão alinhados.
Por que persistem as diferenças? O “ADN da Framework”
Apesar da padronização, permanecem pequenas variações nas contagens de tokens e na latência. Estas são atribuíveis aos comportamentos intrínsecos e de baixo nível de cada framework, o seu “ADN”.
- Serialização de prompts e mensagens: Cada framework envolve o mesmo conteúdo lógico com uma formatação ligeiramente diferente antes de o enviar ao LLM, criando deltas de tokens pequenos mas consistentes.
- Montagem do contexto: A ordenação precisa e a inclusão de metadados dentro do contexto concatenado podem diferir ligeiramente conforme a framework, afetando a contagem final de tokens.
- Desempates de roteamento: Em casos limite, diferenças subtis na forma como uma framework analisa a saída JSON do roteador podem levar a uma escolha inicial de ferramenta diferente.
Nesta configuração, a pegada de tokens parece ser o principal fator, mais do que o tempo de execução da framework.
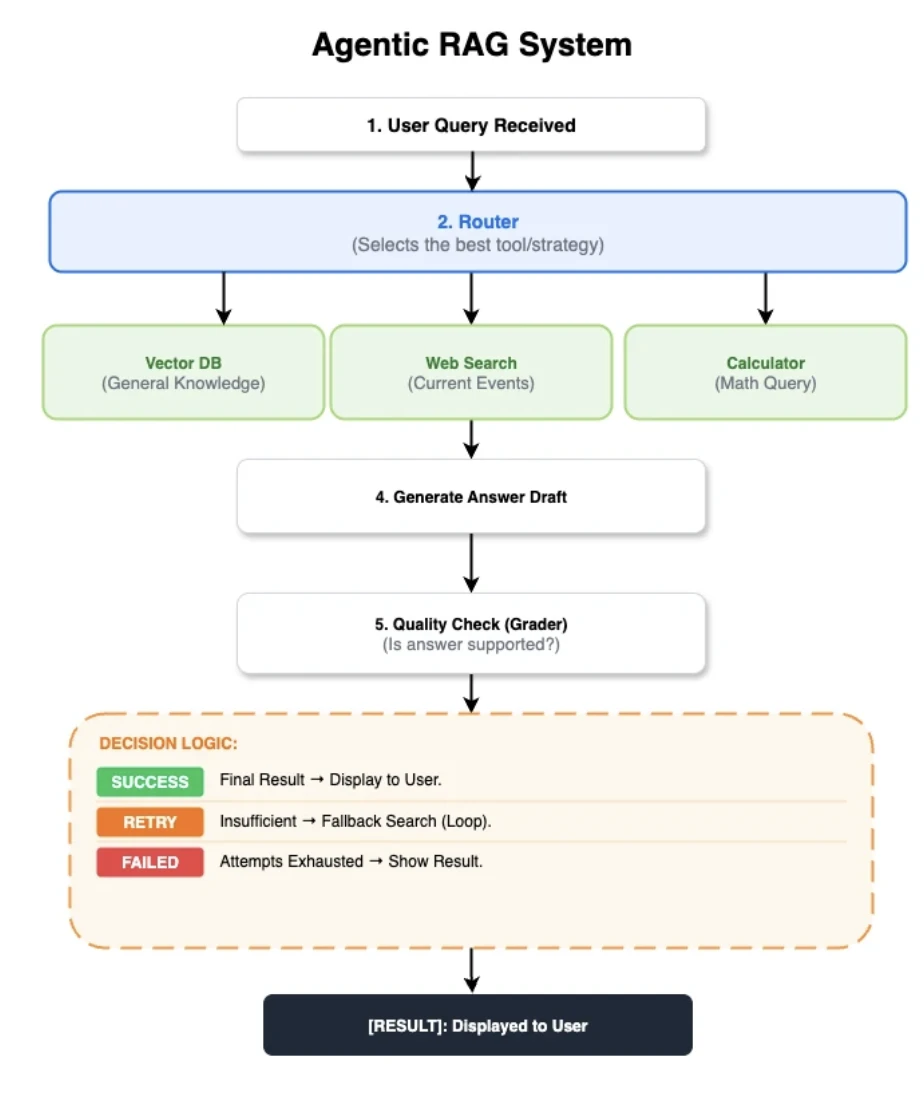
A arquitetura agêntica partilhada de RAG
Para alcançar uma comparação justa, todas as cinco implementações foram construídas sobre o mesmo fluxo de controlo:
- Roteador: Um nó híbrido modelo-e-heurística que escolhe entre recuperador, web_search ou calculadora.
- Recuperar Documentos: Obtém os 5 principais documentos do Qdrant usando embeddings BGE-small normalizados.
- Classificar Documentos: Um juiz LLM avalia a relevância dos documentos. Se irrelevantes, aciona um fallback para pesquisa na web.
- Gerar Resposta: Utiliza um LLM com temperatura=0.0 e um limite partilhado de tokens de contexto para gerar uma resposta preliminar.
- Classificar Resposta: Um segundo juiz LLM avalia a resposta preliminar quanto a fundamentação, contradições (alucinações) e completude.
- Fallback e Retorno Antecipado: Uma pesquisa na web é acionada se a classificação da resposta for insuficiente. No entanto, os resultados da calculadora são devolvidos diretamente, ignorando os passos de geração e classificação.
Exemplos de Fluxo de Trabalho
Cenário A — Acerto direto na base de dados:
Cenário B — Evento recente aciona a ferramenta web:
Cenário C — A calculadora fornece um retorno antecipado:
Cenário D — Base de Dados Vetorial insuficiente, recorre à pesquisa na web:
Metodologia das frameworks RAG
Todas as cinco implementações alcançaram 100% de precisão no nosso conjunto de teste de 100 consultas, correspondendo às respostas de referência. Este foi o requisito fundamental, assegurando que cada framework podia executar com sucesso o mesmo fluxo de trabalho agêntico de RAG antes de medir as diferenças de desempenho.
1. Componentes principais e configuração
As ferramentas fundamentais foram padronizadas para eliminar variáveis de desempenho na origem.
- LLMs:
- Modelo: Todos os nós (roteador, gerador, classificador) utilizaram o modelo openai/gpt-4.1-mini através da API do OpenRouter.
- Determinismo: a temperatura foi definida como 0.0 para todas as chamadas ao LLM, garantindo a máxima consistência no roteamento, geração e classificação.
- Limites de tokens: Foram aplicados limites rigorosos de max_tokens: 256 para o roteador e classificadores, e 512 para o gerador. Isto evita diferenças de latência causadas por uma framework gerar respostas excessivamente longas.
- Modelo de embeddings e recuperação:
- Modelo: Todas as frameworks usaram BAAI/bge-small-en-v1.5 do HuggingFace.
- Normalização: Um passo crítico para o desempenho, normalize_embeddings foi definido como True em todas as cinco frameworks. (LangChain/LangGraph via encode_kwargs; LlamaIndex via normalize=True; Haystack via normalize_embeddings; recuperador DSPy normalizado.)
- Recuperação: A base de dados vetorial Qdrant foi consultada com k=5 (5 principais documentos) em todas as implementações.
- Ferramentas:
- Pesquisa na web: O benchmark foi restrito apenas ao Tavily (max_results=3).
- Calculadora: Todas as cinco implementações utilizaram a biblioteca sympy para análise e avaliação de expressões matemáticas, garantindo capacidades idênticas.
2. Fluxo de controlo e política de RAG
O processo de “tomada de decisão” do agente foi explicitamente espelhado em todos os casos.
- Lógica de roteamento: Uma estratégia de roteamento híbrida foi implementada em todos os cinco scripts para equilibrar a inteligência do modelo com regras determinísticas:
- Uma heurística baseada em regex (heuristic_route) verifica primeiro padrões óbvios de calculadora ou pesquisa na web (por exemplo, símbolos matemáticos, anos como “2024”).
- Um nó roteador LLM toma então a sua própria decisão.
- A decisão final prioriza a heurística para calculadoras, recorrendo caso contrário à escolha do LLM.
- Orçamento de contexto: Esta é uma das padronizações mais críticas. Antes de o nó generate_answer ser chamado, todo o contexto do documento recuperado e os resultados da pesquisa na web são concatenados e depois truncados para um limite partilhado de 2000 tokens usando um utilitário comum truncate_to_token_budget. Isto garante que o LLM gerador em cada framework recebe uma entrada exatamente do mesmo tamanho, impedindo que qualquer framework seja favorecida ou prejudicada pela verbosidade do seu contexto recuperado.
- Política de classificação de respostas:
- Rubrica leniente: O nó grade_answer utiliza um prompt leniente idêntico em todas as frameworks, instruindo o juiz LLM a aceitar respostas semanticamente semelhantes e razoavelmente completas.
- Tratamento de falhas: A lógica para lidar com uma análise JSON falhada do classificador foi padronizada. Se a saída do classificador não for um JSON válido, o sistema assume por defeito uma classificação permissiva (grounded=True, complete=True), imitando um cenário do mundo real onde não se desejaria que um parser frágil reprovasse uma resposta que de outra forma seria boa. Os campos estruturados do DSPy são devolvidos (sem análise de JSON); isto é registado como uma diferença de robustez, não como uma vantagem de desempenho.
- Retorno antecipado da calculadora: Como visto no código, uma chamada bem-sucedida ao nó calculator_node define diretamente a final_answer e termina o fluxo de trabalho antecipadamente. Esta é uma otimização significativa que é aplicada de forma consistente, impedindo que o caminho da calculadora invoque desnecessariamente os LLMs de geração e classificação de respostas.
- Alinhamento com DSPy. Para manter a equidade com as linhas de base não-CoT, o DSPy utiliza dspy.Predict (sem CoT) para o Roteador e o Gerador de Respostas. As assinaturas refletem os contratos dos nós das outras frameworks; sempre que disponível, as contagens de tokens usam o uso reportado pelo modelo, caso contrário recorre-se ao tiktoken.
3. Instrumentação e métricas
O processo de medição foi idêntico, utilizando utilitários e princípios partilhados.
- Latência: Foi utilizado time.perf_counter() de alta precisão para todas as temporizações. A Sobrecarga da Framework é calculada consistentemente como Latência Total – Latência das Chamadas Externas.
- Tokenização: Todas as contagens de tokens para prompts e conclusões foram calculadas usando tiktoken, a codificação cl100k_base, assegurando uma única fonte de verdade para as métricas de tokens. A métrica “Média de Tokens” reportada nos resultados representa a soma cumulativa de todos os tokens de entrada (prompt) e saída (conclusão) para cada chamada ao LLM (por exemplo, roteador, classificadores, gerador) dentro de um único fluxo de trabalho de consulta.
- Gestão de estado: Embora a sintaxe de implementação varie (TypedDict do LangGraph, classe do LlamaIndex, dicionário do LangChain), a estrutura de estado é funcionalmente idêntica. Cada framework passa o mesmo conjunto de chaves (question, documents, web_results, etc.) entre nós, assegurando que a lógica do fluxo de controlo opera sobre a mesma informação.
Ao impor estas rigorosas padronizações a nível de código, este benchmark visa ir além das comparações superficiais e oferecer uma análise replicável do desempenho das frameworks sob uma política fixa de RAG.
Interpretação dos resultados:
- Pode concluir-se que: Nesta configuração específica e altamente controlada, a sobrecarga de orquestração tende a ser menor; as diferenças são impulsionadas principalmente pelas contagens de tokens e pelos caminhos das ferramentas.
- Nesta configuração específica e altamente controlada, a sobrecarga da framework é insignificante.
- As diferenças de desempenho foram impulsionadas pela contagem de tokens e pelas variações nos caminhos das ferramentas.
- Não se pode generalizar: Os resultados são específicos para esta arquitetura, modelos, prompts, recuperador e fornecedor web; alterar estes elementos pode mudar as classificações.
Experiência do programador: Uma comparação qualitativa
O desempenho não é o único fator; a forma como uma framework se sente ao construir com ela é igualmente importante.
- LangGraph: O grafo declarativo
Utiliza um paradigma baseado em grafos. Definem-se nós e ligam-se com arestas (incluindo add_conditional_edges), pelo que o fluxo de controlo faz parte da arquitetura. O estado é tipado através de um TypedDict com atualizações ao estilo redutor (Annotated[…, add]).- Escolha o LangGraph para: fluxos de trabalho complexos com múltiplos ramos, tentativas e ciclos; a sua estrutura escala em robustez e manutenibilidade à medida que os agentes crescem.
- LlamaIndex: Orquestração imperativa
Um script procedimental onde o fluxo de controlo é Python if/else padrão; o “grafo” reside no seu código. O estado é uma classe PipelineState dedicada, e a framework fornece primitivas de recuperação limpas (VectorStoreIndex → .as_retriever(k=5)).- Escolha o LlamaIndex para: fluxos de trabalho legíveis, num único ficheiro, onde valoriza uma lógica procedimental clara e depuração fácil.
- LangChain: Imperativo com componentes declarativos
A orquestração permanece um script Python, mas as tarefas individuais são pequenas cadeias componíveis usando o operador | (por exemplo, prompt | llm | parser). O estado é um dicionário Python flexível e não tipado.- Escolha o LangChain para: Prototipagem rápida ou equipas já no ecossistema LangChain que preferem compor pequenas unidades declarativas dentro de um controlador imperativo maior.
- Haystack: Baseado em componentes, orquestração manual Componentes reutilizáveis e tipados (@component) com I/O explícito, enquanto o fluxo de controlo permanece em Python puro (if/else). Fácil de trocar backends de LLM/recuperador/web, mais instrumentação de primeira classe por passo (tempo externo vs. tempo da framework).
- Escolha o Haystack para: pipelines prontas para produção, testáveis, com contratos claros e controlo refinado.
- DSPy: Programas orientados a assinaturas (menos linhas de código)
Define uma tarefa através de uma assinatura (inputs/outputs + intenção) e depois implementa-a com Módulos que encapsulam a criação de prompts e chamadas ao LLM. Centraliza o tratamento de prompts/usos e remove código de ligação; trocar componentes internos (por exemplo, Predict ↔ CoT) não altera o contrato.- Escolha o DSPy para: boilerplate mínimo, fluxos legíveis num único ficheiro, desenvolvimento orientado a contratos (com otimizadores opcionais).
Trocar desempenho ótimo por comparabilidade
- LangGraph pode sobressair com as suas otimizações nativas de grafos quando é permitido usar execução paralela, cache de estado e o seu sistema de arestas condicionais para lógicas de ramificação complexas.
- DSPy poderia mostrar resultados drasticamente diferentes ao utilizar os seus otimizadores de assinatura (como o MIPROv2) e o prompting Chain-of-Thought, que podem melhorar significativamente a qualidade das respostas.
- Haystack pode aproveitar as suas funcionalidades de cache prontas para produção, processamento em lote e otimizações a nível de componentes que desativámos para garantir a equidade.
- LlamaIndex poderia beneficiar das suas estratégias avançadas de indexação, motores de consulta e capacidades multimodais que não foram exercitadas neste benchmark.
- LangChain pode brilhar com o seu extenso ecossistema de ferramentas e otimizações de LCEL (LangChain Expression Language) quando não está restrito ao nosso conjunto de ferramentas padronizado.
A “melhor” framework depende daquilo que se otimiza: velocidade de desenvolvimento, manutenibilidade, desempenho ou padrões arquitetónicos específicos.
Conclusão
Numa pipeline agêntica de RAG fortemente controlada, a sobrecarga de orquestração é normalmente uma fatia pequena. O que faz a diferença é o número de tokens processados e as ferramentas invocadas, ambos moldados pelos prompts, pela recuperação e pelo roteamento. A framework “certa” depende, em última análise, do estilo de orquestração preferido pela sua equipa: grafos declarativos (LangGraph), scripts imperativos (LlamaIndex), cadeias componíveis (LangChain), componentes modulares (Haystack) ou programas orientados a assinaturas (DSPy) que minimizam o boilerplate.
Leitura adicional
Explore outros benchmarks de RAG, tais como:
- Modelos de Embedding: OpenAI vs Gemini vs Cohere
- Principais Bases de Dados Vetoriais para RAG: Qdrant vs Weaviate vs Pinecone
- Benchmark de RAG agêntico: roteamento multi-base de dados e geração de consultas
- RAG Híbrido: Aumentando a Precisão do RAG
Cite este benchmark
Escolha o formato adequado ao local onde você vai publicar. Colar a versão com link no seu CMS preserva o backlink.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Sarı, Ekrem},
title = {{RAG Estruturas: LangChain vs LangGraph vs LlamaIndex}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/rag-frameworks}},
note = {AIMultiple. Acessado em 3 Junho 2026}
}
Seja o primeiro a comentar
Seu endereço de e-mail não será publicado. Todos os campos são obrigatórios. Os comentários são deixados em seu idioma original.