LCMs: da tokenização LLM à representação em nível conceitual
Os modelos conceituais de grande escala (LCMs) , conforme introduzidos por Meta em seu trabalho sobre “Modelos Conceituais de Grande Escala”, representam uma mudança fundamental da previsão baseada em tokens para a representação em nível de conceito . 1
Os LCMs diferem dos LLMs tradicionais em dois aspectos principais:
- Espaço de incorporação de alta dimensão: Em vez de trabalhar com sequências discretas de tokens, os LCMs realizam toda a modelagem diretamente em um espaço de incorporação de alta dimensão.
- Abstração em nível conceitual: A modelagem é realizada no nível de conceitos semânticos e abstratos, e não dentro de uma linguagem ou modalidade específica. Isso torna os LCMs inerentemente independentes de linguagem e modalidade.
Com base na pesquisa de Meta, 2 Exploraremos os componentes principais dos LCMs e seu potencial na busca e raciocínio semânticos, com base nos seguintes parâmetros de avaliação:
Entendendo as limitações dos LLMs: de tokens a conceitos
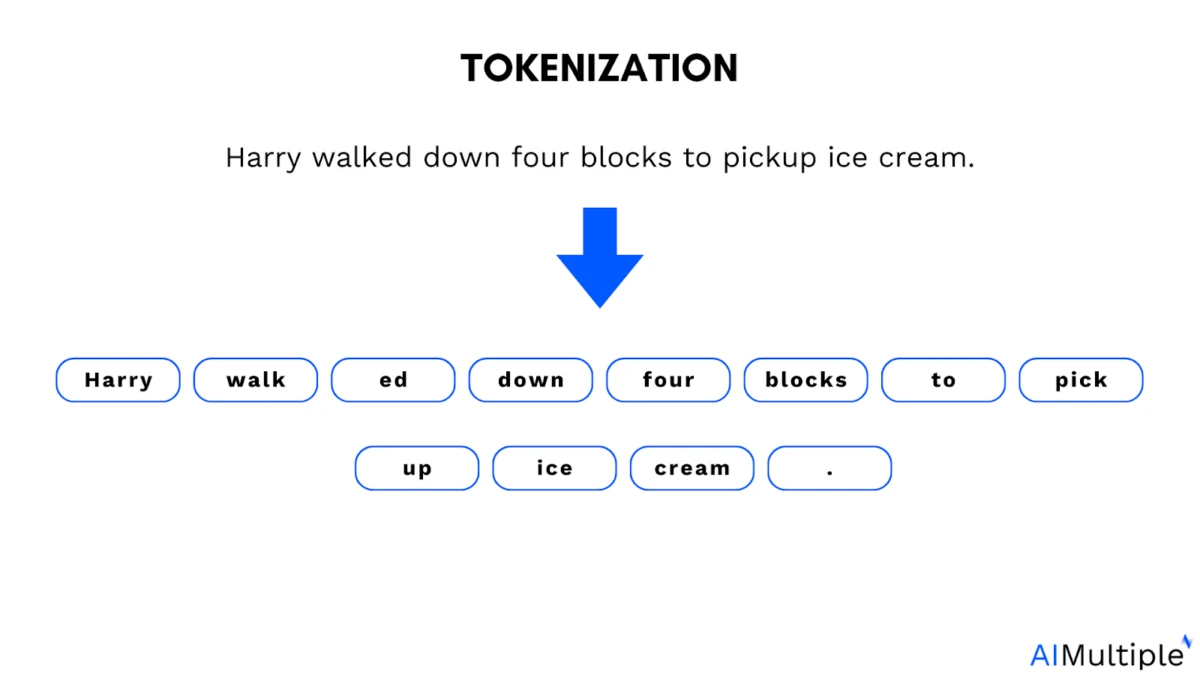
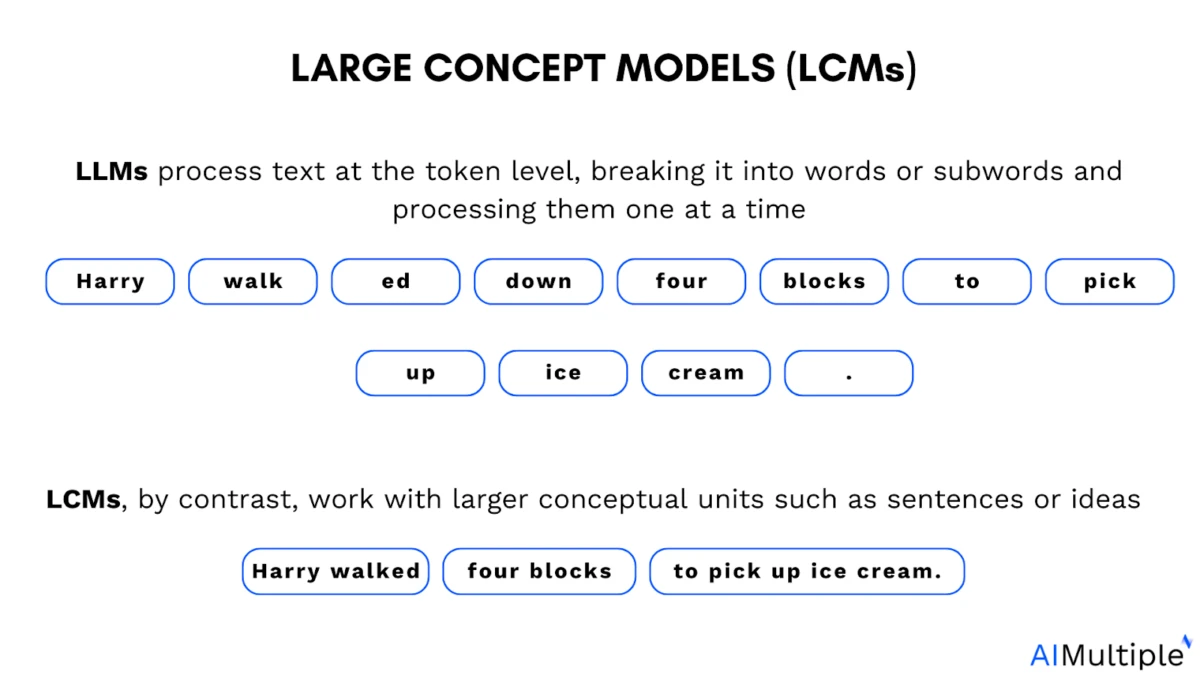
O papel da tokenização em LLMs: Os modelos de linguagem de grande porte (LLMs) são treinados com tokens. Tokens são pequenos segmentos de texto. Podem ser uma palavra inteira, parte de uma palavra ou até mesmo um único caractere que o modelo processa como uma unidade.
Exemplo de tokenização:
O problema
A tokenização ajuda os modelos a decompor a linguagem em partes gerenciáveis, mas também introduz uma restrição. A maioria dos modelos de linguagem latente opera sobre sequências de tokens discretos (por exemplo, subpalavras de texto; tokens visuais/de áudio produzidos por codificadores).
Os LLMs podem absorver múltiplas modalidades, mas seu objetivo central e sua representação permanecem vinculados à sequência , o que dificulta a modelagem direta do significado em um nível conceitual .
Os resultados da Cognition.ai com o Sonnet 4.5 mostram isso claramente: o modelo percebe quando sua janela de contexto está quase cheia, tira conclusões precipitadas e até relata os tokens restantes, embora de forma imprecisa. 3
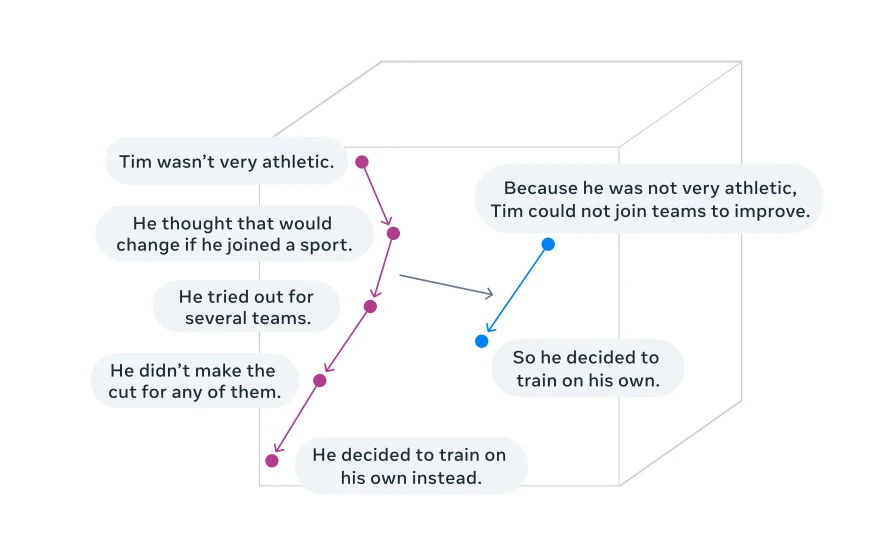
A solução (Conceitos)
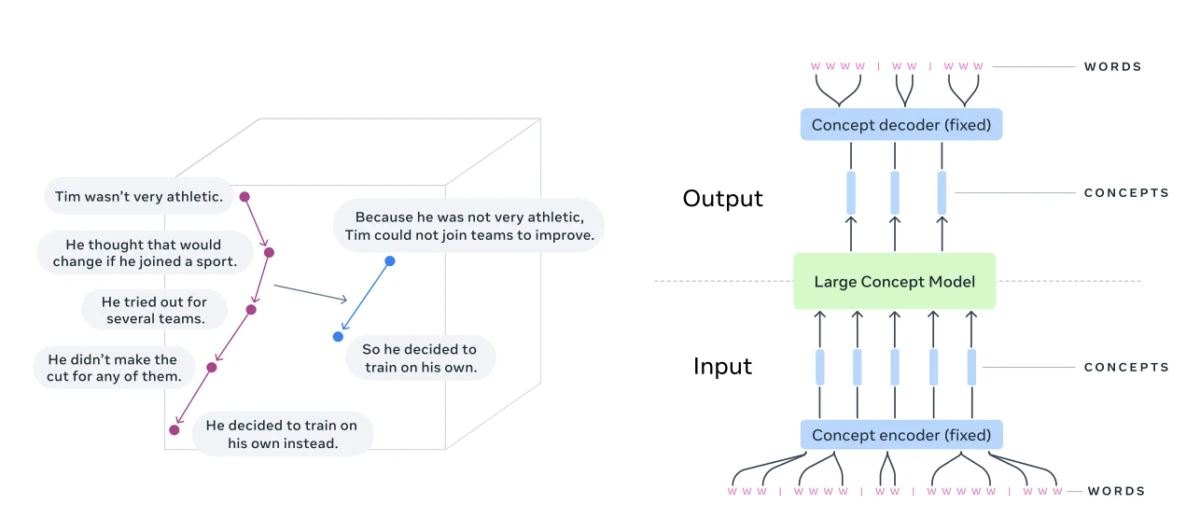
Visualização do raciocínio em um espaço de incorporação de conceitos (tarefa de sumarização) 4
Conceitos referem-se a representações de significado de ordem superior . Ao contrário dos tokens, eles não estão vinculados a nenhuma unidade linguística específica e podem ser derivados de texto, fala, portanto o processo de raciocínio permanece o mesmo.
Isso permite:
- Melhor gerenciamento de contextos longos , raciocinando sobre ideias completas em vez de tokens fragmentados.
- Raciocínio mais abstrato, uma vez que as operações são realizadas no nível do significado.
- Processo agnóstico em relação ao idioma e à modalidade para lidar com tarefas multilíngues e multimodais sem a necessidade de fluxos de processamento separados para cada tipo de entrada.
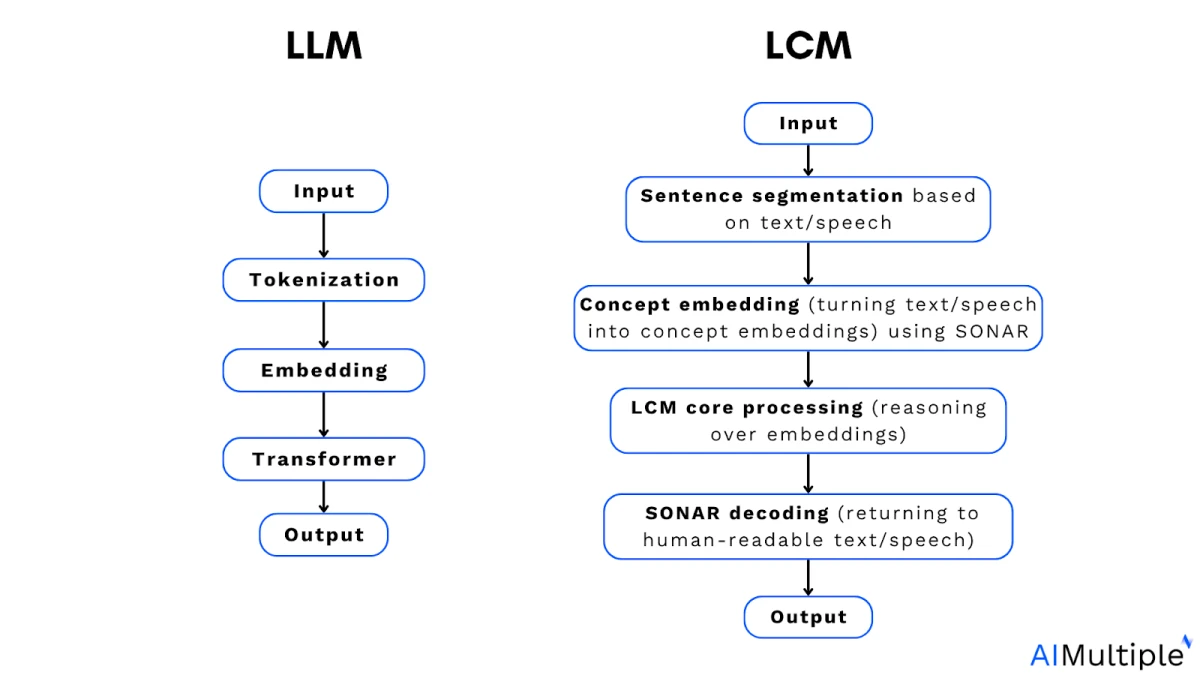
O que são modelos conceituais de grande escala?
Em contrapartida, os modelos conceituais de grande escala (LCMs, na sigla em inglês) visam representar e raciocinar sobre conceitos semânticos em um espaço de incorporação contínuo, não vinculado a nenhuma linguagem ou modalidade específica.
Arquitetura fundamental de um modelo conceitual de grande escala (LCM):
Fonte: Meta 5
Componentes principais dos LCMs
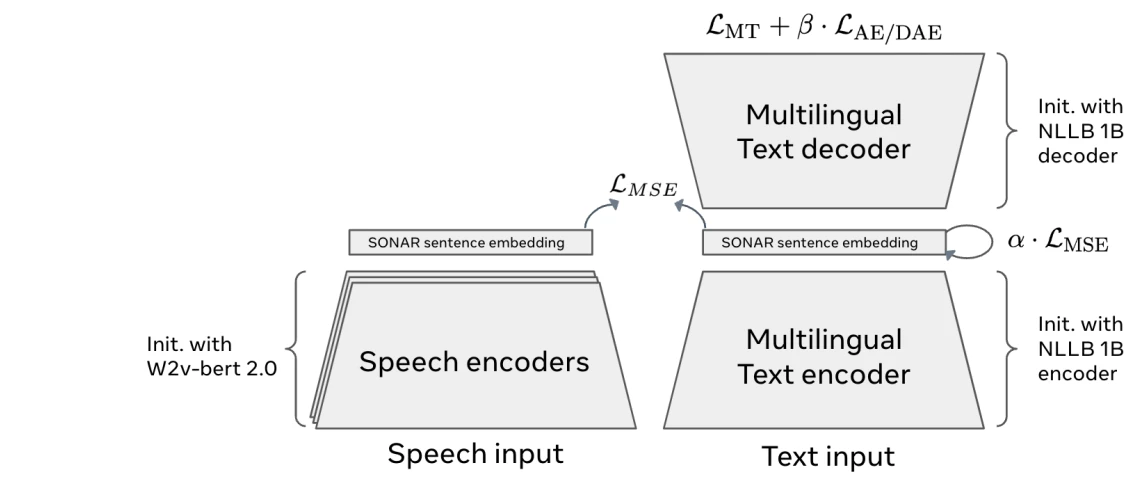
1. Codificação SONAR (transformando texto ou fala em representações conceituais)
Arquitetura SONAR 6
O primeiro estágio de um Modelo de Conceito Amplo (LCM, na sigla em inglês) é o codificador de conceitos , que converte texto ou fala em um espaço de incorporação compartilhado. Em vez de dividir a entrada em tokens, ele representa frases inteiras como incorporações matemáticas que capturam seu significado.
Os LCMs usam o SONAR , um espaço de incorporação multilíngue e multimodal que suporta mais de 200 idiomas de texto e 76 para fala.
Por exemplo, as frases “Eu te amo” em inglês e “Te quiero” em espanhol são colocadas próximas uma da outra neste espaço porque expressam a mesma ideia. Ao operar nesse nível conceitual, os LCMs ganham inclusividade, eficiência e escalabilidade que vão além dos modelos baseados em tokens.
Por que o SONAR é melhor do que as incorporações tradicionais?
Métodos tradicionais:
- mBERT : Fornece embeddings multilíngues, mas eles não estão alinhados de forma consistente no nível da frase , tornando as tarefas entre idiomas menos eficazes.
Vantagens do SONAR:
- Independente de idioma : mais de 200 idiomas para entrada e saída de texto (baseado no projeto No Language Left Behind de Meta). 76 idiomas para entrada de voz e inglês para saída de voz.
- Alinhamento entre línguas : frases com o mesmo significado aparecem próximas umas das outras, independentemente do idioma.
- Raciocínio de nível superior : Como as unidades são frases (ou conceitos), os modelos podem executar tarefas como sumarização ou tradução, manipulando ideias diretamente.
- Tradução sem exemplos : Permite traduzir entre idiomas e modalidades sem treinamento direto para cada par .
LLMs vs LCMs
2. Processamento central do LCM (raciocínio sobre incorporações)
O núcleo do LCM é o estágio de raciocínio, onde o modelo gera novos conceitos com base no contexto. Ao contrário dos LLMs, que predizem um token por vez, o núcleo do LCM prediz frases ou conceitos inteiros , operando em um nível semântico superior.
O desafio reside em produzir representações contínuas condicionadas ao contexto. Os LLMs geram distribuições de probabilidade sobre tokens discretos, mas os LCMs devem gerar diretamente vetores que capturem o significado.
Para solucionar esse problema, os pesquisadores propuseram diversas abordagens, incluindo:
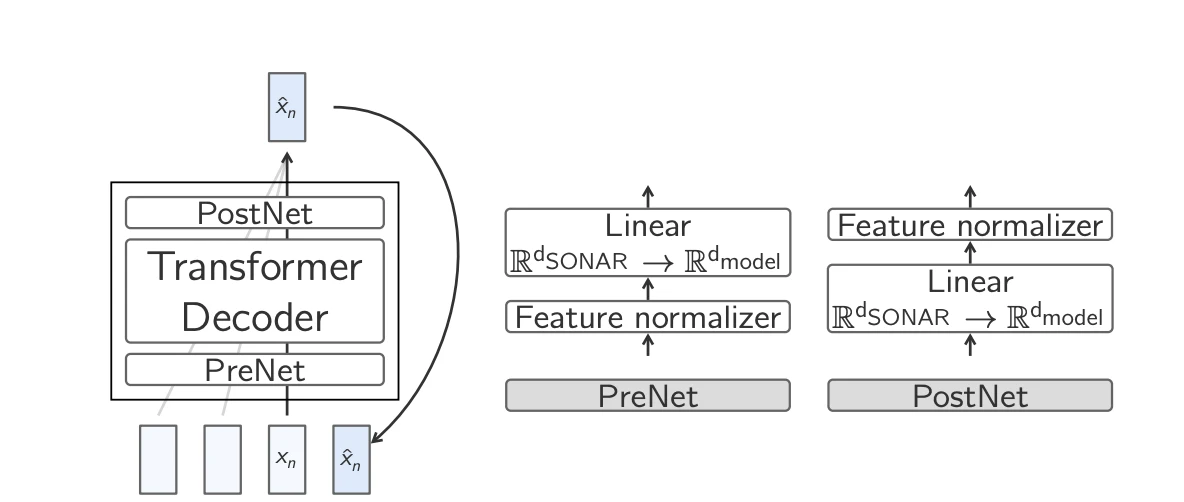
- Base-LCM: Transformer padrão prevendo o embedding: O método mais simples é treinar um Transformer para prever diretamente o próximo embedding, minimizando a perda do Erro Quadrático Médio (MSE) . Embora eficaz em princípio, essa abordagem enfrenta desafios porque um determinado contexto pode levar a múltiplas continuações válidas, porém semanticamente distintas.
Base-LCM 7
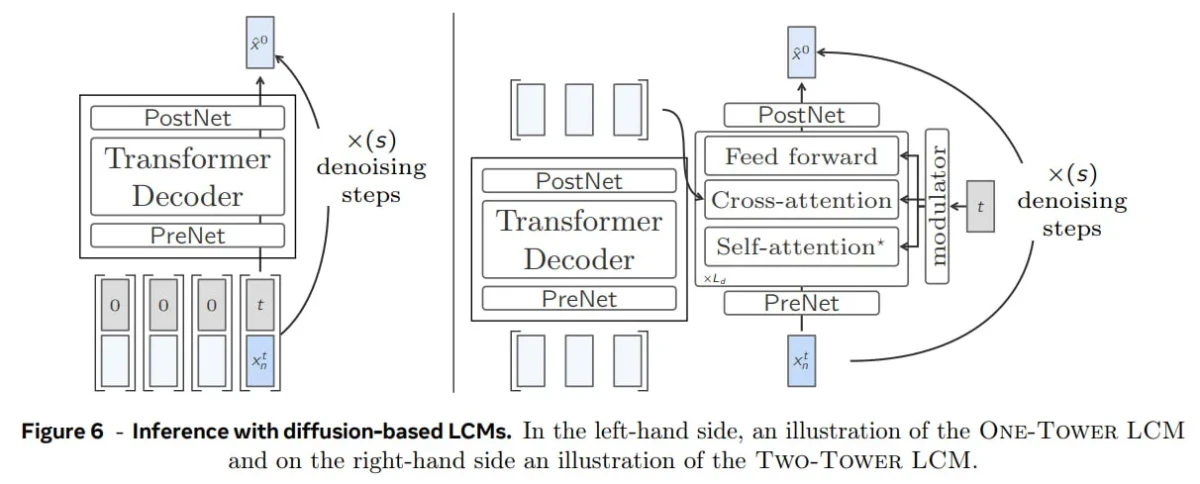
- LCM baseado em difusão: Variações estruturais para contextualização e redução de ruído: Inspirada na geração de imagens, esta variante utiliza um processo de difusão . Ela gera conceitos de forma autorregressiva, um de cada vez, realizando etapas de redução de ruído para cada conceito gerado.
- Torre única: Uma única pilha de transformadores lida tanto com a contextualização quanto com a redução de ruído, mantendo o design eficiente e compacto.
- Two-tower: Divide o processo em duas partes: um contextualizador para entender o contexto e um removedor de ruído para refinar as representações vetoriais, oferecendo mais flexibilidade ao custo de maior complexidade.
- LCM quantizado: Incorporações discretizadas: Outra opção é discretizar as incorporações em unidades simbólicas maiores. Isso torna a tarefa mais próxima daquela dos LLMs, onde o modelo gera elementos discretos, mas aqui os "tokens" representam blocos de significado muito maiores e semanticamente mais ricos.
3. Decodificação SONAR (retorno a texto ou fala legíveis para humanos)
A etapa final de um LCM é o decodificador de conceitos , que transforma representações abstratas de volta em texto natural ou fala.
Como os conceitos são armazenados em um espaço de incorporação compartilhado , eles podem ser decodificados em qualquer idioma ou modalidade compatível sem a necessidade de executar novamente o processo de raciocínio.
Esse design agnóstico em relação ao idioma significa que um LCM pode receber entradas em alemão, raciocinar em conceitos e gerar saídas em japonês. Ele também permite fácil escalabilidade: novos codificadores ou decodificadores (como para linguagem de sinais ou sistemas de conversão de fala em texto) podem ser adicionados sem a necessidade de treinar todo o modelo novamente.
Ao manter o "pensamento" separado da expressão, o decodificador garante que os LCMs permaneçam flexíveis e adaptáveis para aplicações multilíngues e multimodais.
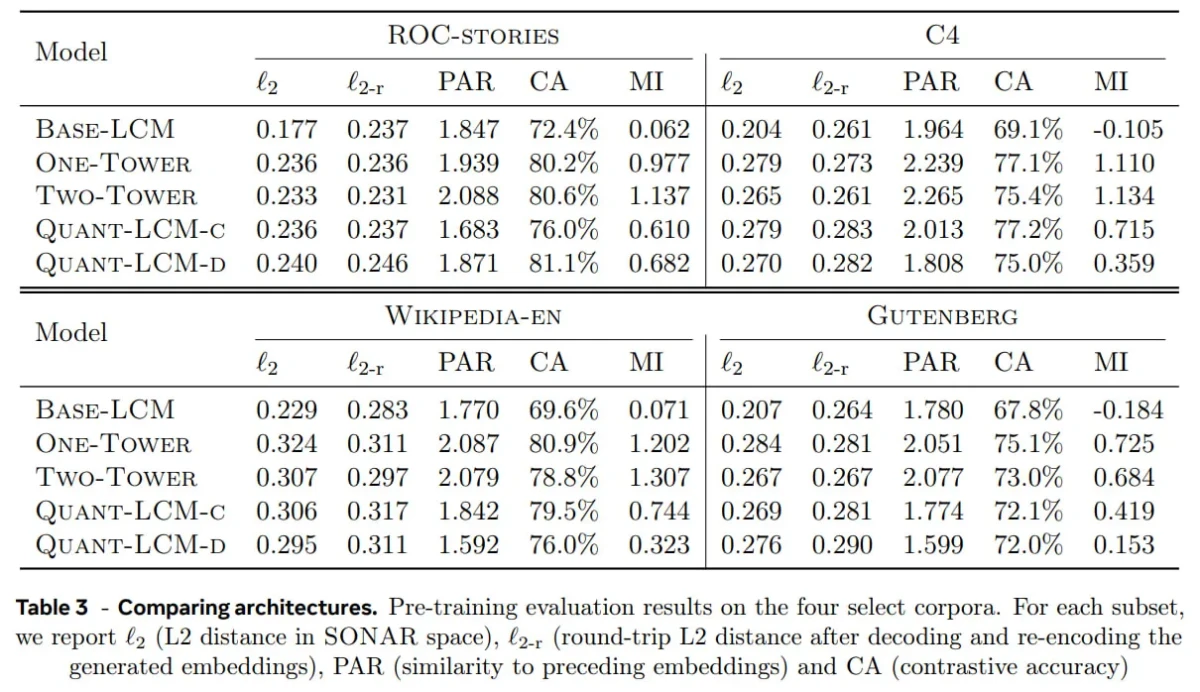
Análise comparativa de arquiteturas LCM
Meta modelos de classificação de classes latentes (LCMs) pré-treinados no conjunto de dados FineWeb-Edu (somente em inglês) e avaliados em quatro benchmarks:
- Histórias ROC (raciocínio narrativo),
- C4 (texto em escala web),
- Wikipédia em inglês (conhecimento enciclopédico),
- Gutenberg (texto longo).
Esses conjuntos de dados foram escolhidos para abranger diversos tipos de texto, desde narrativas curtas até grandes bases de conhecimento e documentos extensos.
Principais conclusões:
Os LCMs baseados em difusão (QUANT-LCM-C, QUANT-LCM-D) apresentaram o melhor desempenho . Seu processo iterativo de redução de ruído mostrou-se mais eficaz na modelagem de continuações de conceitos, resultando em maior precisão semântica e coerência.
Como interpretar os dados de referência:
- ℓ₂, ℓ₂-r: Valores menores indicam incorporações mais precisas e consistentes.
- PAR: O meio-termo é o melhor, demonstra coerência sem colapso.
- CA: Quanto maior, melhor o alinhamento semântico.
- MI: Quanto maior o nível de detalhamento, mais informativos serão os resultados.
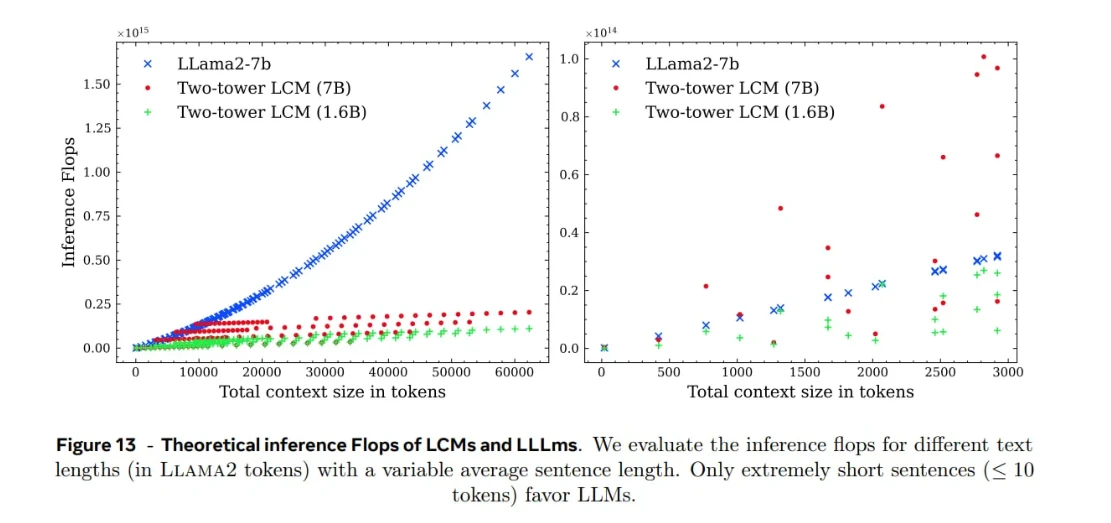
Avaliação comparativa da eficiência do LCM
Os experimentos de Meta mostraram que os LCMs escalam bem com o comprimento do contexto em comparação com os LLMs ao lidar com a mesma quantidade de texto. Essa vantagem decorre do fato de que um conceito corresponde a uma frase completa , que inclui múltiplos tokens. Como há menos conceitos do que tokens, o modelo tem menos unidades para processar e a atenção quadrática torna-se menos exigente.
Principais conclusões:
Vale ressaltar que esses ganhos de eficiência dependem muito de como o texto é segmentado em frases . Parágrafos divididos em frases mais curtas ou mais longas afetarão o número de conceitos e, portanto, a carga computacional.
Cada inferência LCM também envolve três etapas:
- Codificação SONAR (texto ou fala: incorporações)
- Raciocínio Transformer-LCM (processamento de embeddings)
- Decodificação SONAR (incorporações: texto ou fala)
Este processo introduz sobrecarga, especialmente para entradas curtas:
Para frases curtas (menos de ~10 tokens), os LLMs podem ser mais eficientes que os LCMs, uma vez que as etapas de codificação e decodificação superam os benefícios do processamento em nível conceitual.
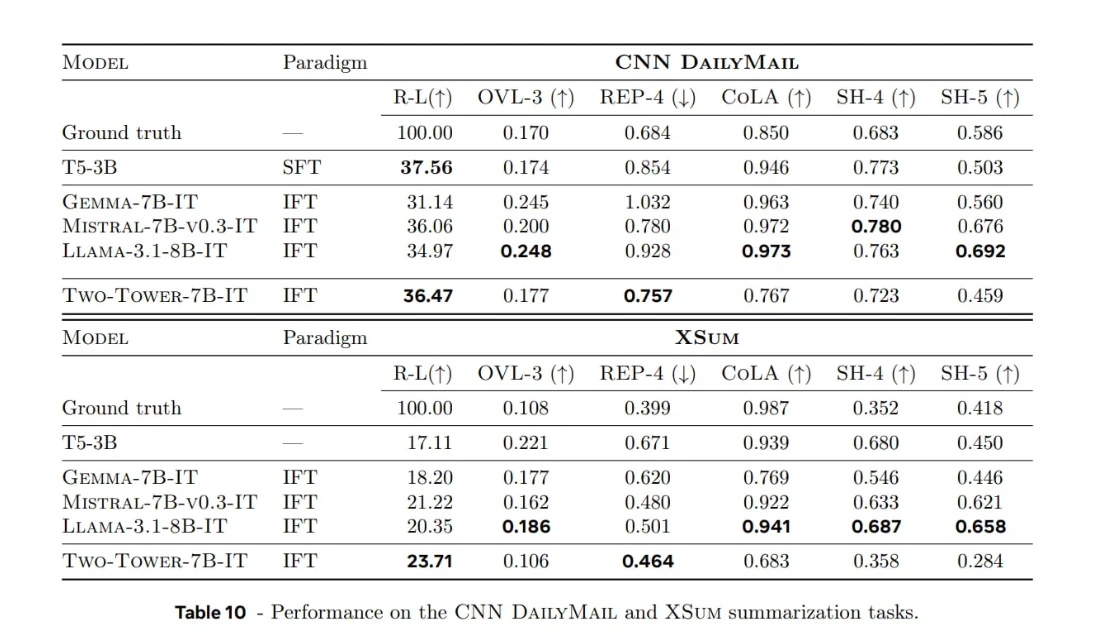
LCM versus LLMs tradicionais em tarefas de sumarização
Meta também avaliou um LCM baseado em difusão (7 bilhões de parâmetros) em conjuntos de dados de sumarização de notícias (por exemplo, CNN/DailyMail, XSum) e o comparou com LLMs tradicionais.
Descrição dos paradigmas:
- SFT : treinamento especializado em exemplos de sumarização.
- IFT : treinamento mais amplo em conjuntos de dados de instruções, para que o modelo aprenda a sumarização como uma de suas muitas habilidades.
Descrição dos parâmetros:
- ROUGE-L : Sobreposição com resumos de referência.
- OVL-3 : Taxa de sobreposição de trigramas de entrada, que mede a redundância em relação ao texto de origem.
- REP-4 : Taxa de repetição de quatro gramas, que mede a repetição nos resumos gerados.
- Métricas do SEAHORSE para o 4º e 5º trimestres : Medidas de qualidade e coerência.
- Classificador baseado em CoLA : Avaliou a aceitabilidade linguística das frases geradas.
Principais conclusões:
Força:
- O modelo LCM de difusão demonstra forte coerência e alinhamento contextual na sumarização de textos longos, especialmente ao processar contextos extensos.
Advertências e considerações:
- A avaliação foca-se principalmente em tarefas generativas (sumarização) em vez de benchmarks amplos como o MMLU.
- A forma como os parágrafos são divididos em frases (por exemplo, como você define "conceitos") impacta fortemente o desempenho.
- Em termos de fluência e aceitabilidade linguística , os LLMs baseados em tokens, como o LLaMA-3.1-8B e o Mistral-7B, ainda apresentam vantagem. Embora os LCMs sejam promissores, ainda não demonstram ganhos claros em todas as métricas, especialmente em fluência ou flexibilidade.
Cite esta pesquisa
Escolha o formato adequado ao local onde você vai publicar. Colar a versão com link no seu CMS preserva o backlink.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{LCMs: da tokenização LLM à representação em nível conceitual}},
year = {2026},
month = jan,
howpublished = {\url{https://aimultiple.com/large-concept-models}},
note = {AIMultiple. Retrieved Janeiro 23, 2026}
}

Seja o primeiro a comentar
Seu endereço de e-mail não será publicado. Todos os campos são obrigatórios. Os comentários são deixados em seu idioma original.