Top 6 Ferramentas de Descoberta de Dados Sensíveis de Código Aberto
As seguintes ferramentas são selecionadas com base na atividade do GitHub e classificadas por contagem de estrelas do GitHub em ordem decrescente. Elas cobrem os principais casos de uso para descoberta de dados sensíveis: catalogação de metadados com linhagem, varredura sem agente e detecção baseada em API de PII, dados PCI e credenciais em repouso.
Ler mais: Ferramentas de descoberta e classificação de dados sensíveis, Software DLP.
Recursos administrativos
Ferramenta | Painel gráfico | Baseado em pesquisa | Linhagem de dados | Sistema de banco de dados federado |
|---|---|---|---|---|
DataHub | ✅ | ✅ | ✅ | ✅ |
Apache – Atlas | ✅ | ✅ | ✅ | ❌ |
Marquez | ✅ | ✅ | ✅ | Não compartilhado. |
OpenDLP | ❌ | ❌ | ❌ | ❌ |
Piiano Vault – ReDiscovery | ❌ | Não compartilhado. | ❌ | ❌ |
Nightfall IA – Sensitive data scanner | ✅ | ✅ | ❌ | ❌ |
Descrições de recursos:
- Painel gráfico – permite visualizar suas descobertas de dados.
- Baseado em pesquisa funcionalidade – permite pesquisar ativos de dados.
- Linhagem de dados – permite aos usuários visualizar como os dados são gerados, transformados, transmitidos e usados em um sistema ao longo do tempo.
- Sistema de banco de dados federado – mapeia vários sistemas de banco de dados autônomos em um único banco de dados federado.
Essas funcionalidades (especialmente linhagem de dados e capacidades de pesquisa) permitem que as empresas:
- Descubram a localização de suas informações pessoais (PII), indústria de cartões de pagamento (PCI) dados, etc., armazenados em vários bancos de dados, aplicativos e endpoints de usuário.
- Cumpram padrões regulatórios de proteção de dados e privacidade do setor, como Regulamento Geral sobre a Proteção de Dados (GDPR) e Lei de Privacidade do Consumidor da Califórnia (CCPA).
Recursos de segurança de dados
Descrições de recursos:
- Mascaramento de dados– permite ocultar dados modificando suas letras e números originais, de modo que não tenham valor para intrusos não autorizados, permanecendo utilizáveis para funcionários autorizados.
- Prevenção de perda de dados (DLP) – detecta possíveis violações de dados e as impede bloqueando dados sensíveis.
Categorias e estrelas do GitHub
Seleção e classificação de ferramentas:
- Número de avaliações: 10+ estrelas do GitHub.
- Lançamento de atualização: Pelo menos uma atualização foi lançada na última semana a partir de novembro de 2024.
- Classificação: As ferramentas são classificadas por estrelas do GitHub em ordem decrescente.
DataHub
DataHub é uma plataforma unificada de código aberto para descoberta de dados sensíveis, observabilidade e governança, construída pela Acryl Data e LinkedIn. Também é oferecida comercialmente pela Acryl Data como uma oferta SaaS hospedada na nuvem.
Principais recursos:
- Linhagem de dados em nível de coluna: rastreia o fluxo de dados da origem ao consumo em várias plataformas.
- Qualidade de dados assistida por IA: detecção de anomalias sinaliza automaticamente problemas de qualidade de dados.
- Extensibilidade: REST APIs, SDK Python e integração LangChain para criar agentes com acesso aos metadados do DataHub.
- 80+ conectores nativos: Snowflake, BigQuery, Redshift, Hive, Athena, Postgres, MySQL, SQL Server, Trino, Looker, Power BI, Tableau, Okta, LDAP, S3, Delta Lake e outros.
Consideração: A arquitetura do DataHub executa vários serviços interconectados (GMS, consumidor MCE, consumidor MAE, índice de pesquisa, armazenamento de gráficos). Implantações de produção geralmente exigem Kubernetes. A complexidade de configuração é o ponto de dor mais frequentemente citado na comunidade.
Apache – Atlas
Apache Atlas é uma ferramenta de código aberto para gerenciamento e governança de metadados, projetada principalmente para Hadoop e ecossistemas de big data. Ele suporta classificação, rastreamento de linhagem e pesquisa em ativos de dados em ambientes construídos sobre Hive, HBase, Kafka, Spark, Sqoop e Storm.
Principais recursos
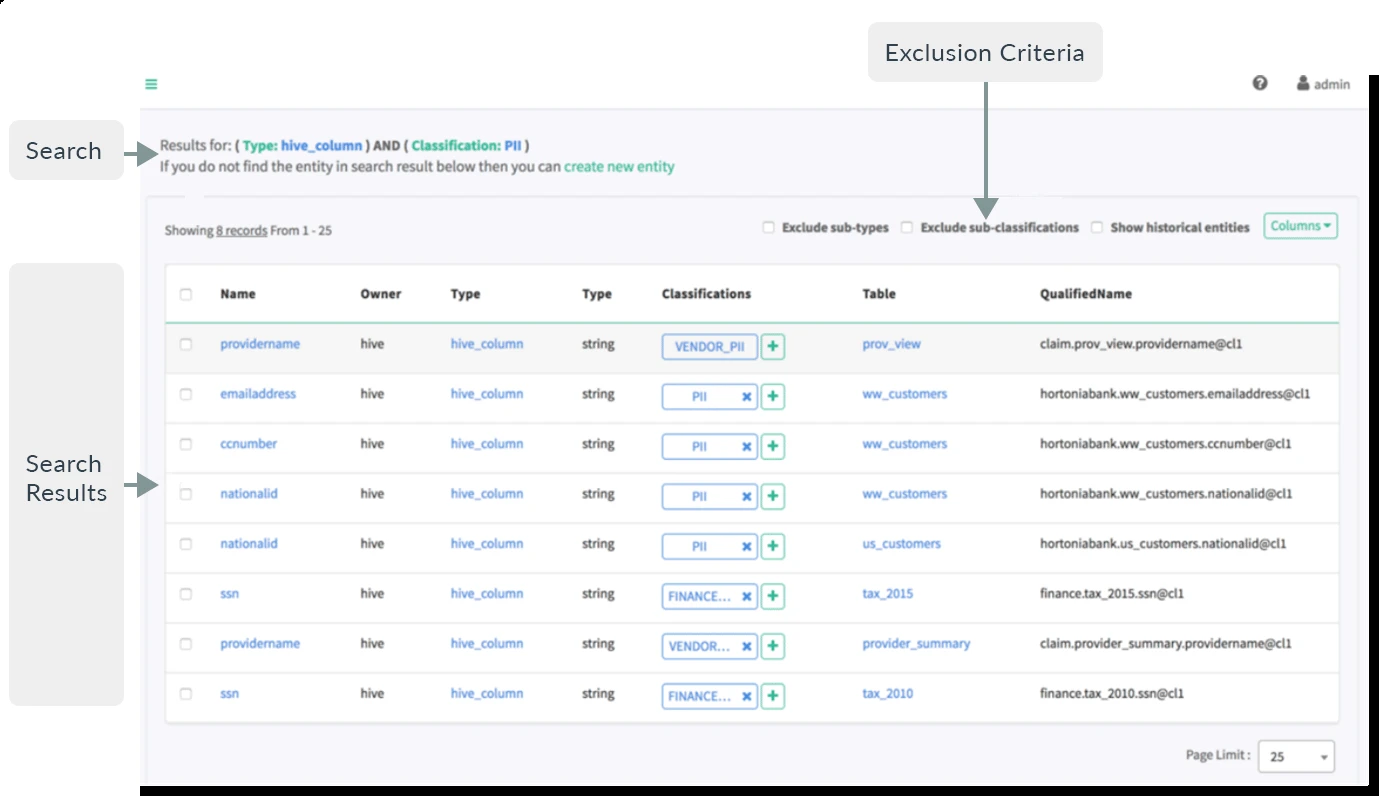
- Classificação dinâmica: Apache Atlas permite criar classificações personalizadas, como PII (Informação Pessoalmente Identificável), EXPIRES_ON, DATA_QUALITY e SENSITIVE.
- Tipos de metadados: A plataforma fornece tipos de metadados pré-definidos para ambientes Hadoop e não Hadoop. Isso permite que os usuários gerenciem metadados para várias fontes de dados, como HBase, Hive, Sqoop, Kafka e Storm.
- SQL-linguagem de consulta tipo (DSL): A plataforma suporta uma linguagem específica de domínio (DSL) que fornece funcionalidade de consulta tipo SQL para pesquisar entidades. Isso o torna acessível para usuários familiarizados com SQL.
- Integração com ferramentas externas: Apache Hive, Apache Spark, Kafka e Presto, tornando-o adaptável para ambientes de big data.
Considerações:
- Configurar o Atlas em um ambiente de nuvem múltipla é complexo, especialmente ao conectar AWS, Azure e Databricks APIs. O Atlas não possui conectores nativos para essas plataformas; configuração adicional é necessária para registrar linhagem do AWS Redshift ou Azure Synapse.
- Serviços de catalogação nativos da nuvem (por exemplo, AWS Glue) podem oferecer rastreamento de linhagem com menor sobrecarga para equipes já comprometidas com um único provedor de nuvem.
- O Atlas é mais adequado para organizações que executam Hadoop, Spark e Hive em escala. Equipes sem uma stack centrada no Hadoop acharão que sua arquitetura adiciona complexidade desnecessária.
Marquez
Marquez é um catálogo de dados de código aberto para coletar, agregar e visualizar metadados de um ecossistema de dados. Ele fornece uma interface de usuário Web e REST API para navegar em conjuntos de dados, entender suas dependências e rastrear alterações por meio de pipelines de dados.
- Pesquisar conjuntos de dados: Os usuários podem pesquisar facilmente conjuntos de dados, visualizar seus atributos e entender suas dependências em todo o ecossistema de dados.
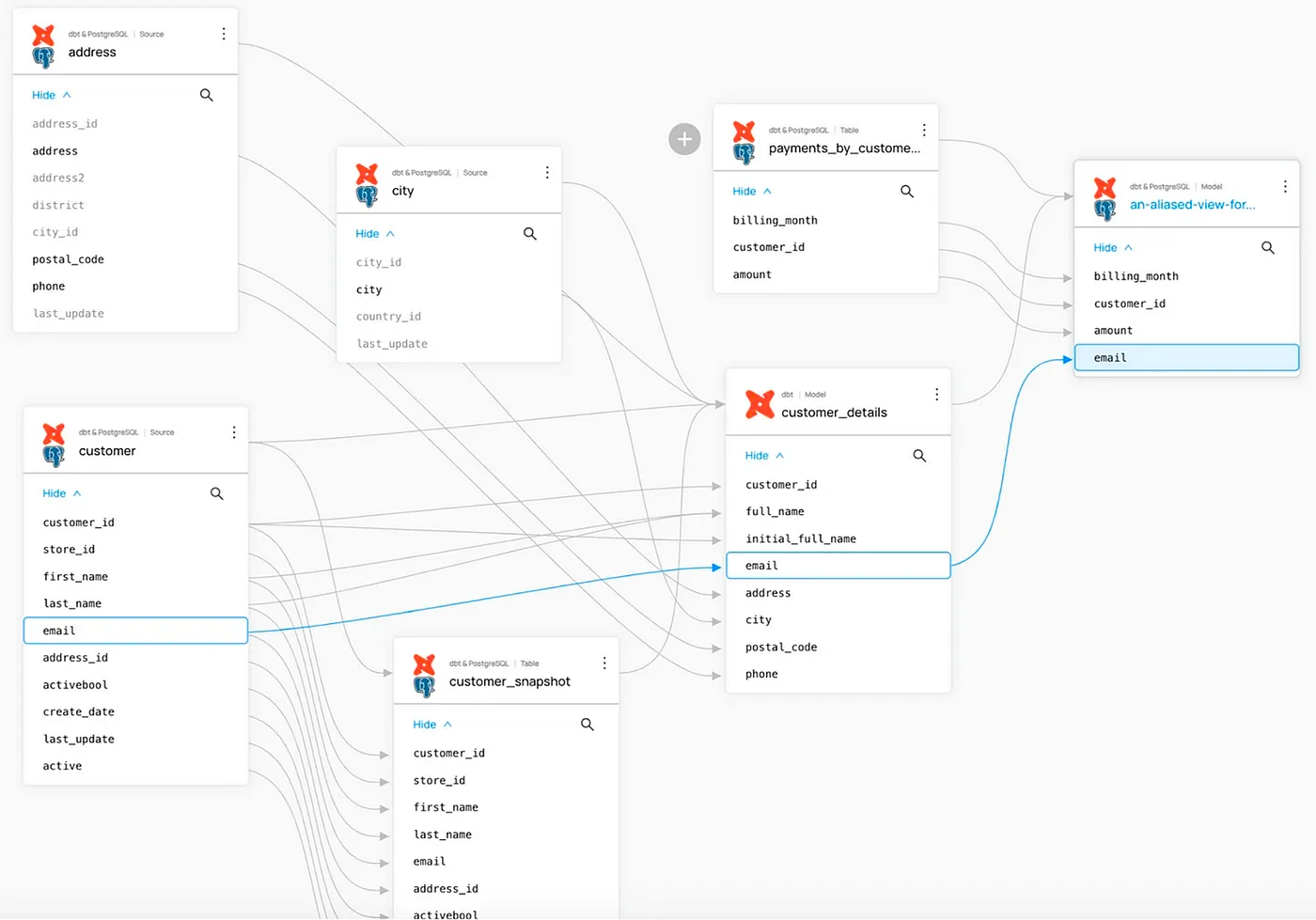
- Visualizar linhagem: O gráfico de linhagem no Marquez fornece uma visão clara e interativa de como os conjuntos de dados estão conectados e transformados por meio de fluxos de trabalho. Isso é crucial para entender pipelines de dados, rastrear erros e garantir a confiabilidade dos dados.
- Repositório centralizado de metadados: Marquez agrega metadados de diversas fontes, consolidando-os em um único sistema para fácil acesso e gerenciamento.
Exemplo de fluxo de trabalho: Para inspecionar metadados de linhagem, navegue até a interface do usuário do Marquez e pesquise por um trabalho (por exemplo, etl_delivery_7_days) usando a caixa de pesquisa. A partir do conjunto de dados de saída do trabalho (public.delivery_7_daysYou can view the dataset name, schema, description, and upstream inputs.
Piiano Vault – ReDiscovery
Piiano Vault é um cofre de privacidade para armazenar e proteger dados pessoais sensíveis dentro do seu próprio ambiente de nuvem. Em vez de pesquisar bancos de dados existentes em busca de dados sensíveis, o Vault é projetado como o repositório autorizado para os campos mais sensíveis: números de cartão de crédito, números de conta bancária, IDs nacionais (SSNs), nomes, e-mails e números de telefone instalados junto aos seus bancos de dados de aplicativos existentes.
O Vault é implantado em sua arquitetura via Docker ou Kubernetes (cartões Helm disponíveis). SDKs estão disponíveis para Python (Django ORM), TypeScript, Java e Go. O repositório vault-releases foi atualizado pela última vez em agosto de 2025.
Distinção de caso de uso: O Vault não é um scanner de descoberta de dados. É um sistema de armazenamento estruturado para dados sensíveis que as organizações desejam centralizar e proteger, não uma ferramenta para encontrar dados sensíveis já espalhados por sistemas existentes.
Nightfall
Nightfall é uma plataforma DLP nativa de IA comercial, não uma ferramenta totalmente de código aberto. Seus repositórios do GitHub incluem scripts de scanner de código aberto (Apache 2.0) que usam a API da Nightfall para pesquisar diretórios, exportações e backups. A execução de varreduras requer uma chave API da Nightfall e chama o mecanismo de detecção comercial da Nightfall. O nível gratuito permite até 100 varreduras por mês em repositórios públicos e privados.
Capacidades do scanner de código aberto (nível gratuito):
- Pesquisa o histórico completo de commits de repositórios públicos e privados.
- Detecta credenciais, segredos, PII e números de cartão de crédito.
- Executa até 100 varreduras por mês.
Recurso distinto: Nightfall pode enviar alertas para o Slack quando violações são detectadas e enviar resultados para um SIEM, ferramenta de relatórios ou endpoint de webhook.
Exemplo de caso de uso: Pesquise um backup do Salesforce para detectar dados sensíveis em repouso. O scanner (1) envia arquivos de backup para a API da Nightfall para varredura, (2) executa um servidor de webhook local para receber resultados e (3) exporta descobertas para um arquivo CSV.
A URL acima é fornecida pela Nightfall. É a URL S3 assinada temporariamente para recuperar as descobertas sensíveis que a Nightfall identificou.
Leitura adicional
Cite esta pesquisa
Escolha o formato adequado ao local onde você vai publicar. Colar a versão com link no seu CMS preserva o backlink.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Sezer, Sena},
title = {{Top 6 Ferramentas de Descoberta de Dados Sensíveis de Código Aberto}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/open-source-sensitive-data-discovery}},
note = {AIMultiple. Acessado em 24 Junho 2026}
}


Seja o primeiro a comentar
Seu endereço de e-mail não será publicado. Todos os campos são obrigatórios. Os comentários são deixados em seu idioma original.