Benchmark dei Web Crawler per fornire siti web all'IA
Abbiamo testato quattro API di crawling su tre domini di difficoltà variabile a tre livelli di profondità massima (5, 10, 20) con un limite di 1.000 pagine, misurando la copertura del crawling, il tempo di esecuzione, la scoperta dei link, la qualità dei link in markdown e l'accuratezza dell'estrazione dei titoli.
Se il tuo obiettivo è:
- Trasformare le pagine web in dati strutturati, consulta la nostra guida sul web scraping.
- Crawlare interi siti web, continua a leggere.
Benchmark dei web crawler
Puoi leggere la nostra metodologia di benchmark.
Pagine medie crawlate vs costo per 1.000 pagine
Pagine crawlate nei domini per profondità massima
Firecrawl ha crawlato costantemente circa 100 pagine su theregister.com indipendentemente dalla profondità massima, circa 90 pagine su entrepreneur.com a tutti i livelli di profondità e solo circa 30 pagine su amazon.com, probabilmente a causa della protezione aggressiva dei bot di Amazon. Va notato che l'aumento della profondità massima non ha avuto praticamente alcun impatto sul numero di pagine che Firecrawl è stato in grado di crawlare in qualsiasi dominio.
Apify ha dimostrato le prestazioni più coerenti, raggiungendo il limite massimo di crawling di 1.000 pagine su ogni dominio a ogni livello di profondità senza apparenti difficoltà, anche su siti fortemente protetti come Amazon.
Cloudflare ha mostrato un comportamento incoerente nei test:
- Su theregister.com a profondità massima 5, ha crawlato solo 100 pagine, ma a profondità massima 20 ha raggiunto quasi 1.000 pagine.
- Come osservato nei test precedenti, Cloudflare occasionalmente crawla solo 1 pagina e poi termina completamente il lavoro. Abbiamo confermato che non si tratta di un problema di caching (la cache era disabilitata) e abbiamo testato con tempi di attesa tra le esecuzioni fino a 1 minuto, ma il comportamento è persistito. A profondità massima 10 su theregister.com, si è verificato esattamente questo problema: Cloudflare ha crawlato solo 1 pagina prima di fermarsi.
- Su entrepreneur.com, Cloudflare ha crawlato 780 pagine a profondità 5, è aumentato a 885 a profondità 10, ma poi è crollato bruscamente a soli 172 pagine a profondità 20. Questo calo potrebbe essere correlato alla pianificazione del crawling di Cloudflare che de-prioritizza o fa scadere le catene di link più profonde, o potrebbe riflettere un limite di concorrenza interno che causa la terminazione anticipata del lavoro quando la frontiera di crawling diventa troppo grande a profondità maggiori.
- Su amazon.com, Cloudflare ha crawlato 905 pagine a profondità 5, ma il numero è diminuito costantemente all'aumentare della profondità massima, scendendo a 809 a profondità 10 e 795 a profondità 20, suggerendo che configurazioni di crawling più profonde potrebbero causare a Cloudflare di spendere più tempo nell'overhead di scoperta dei link piuttosto che nel recupero effettivo delle pagine.
Nimble ha raggiunto o avvicinato il limite di 1.000 pagine su theregister.com a tutti i livelli di profondità (1.000 / 1.000 / 999). Su entrepreneur.com, ha crawlato 1.000 pagine a profondità 5 ma ha mostrato lievi cali a profondità maggiori (896 a profondità 10, 983 a profondità 20), probabilmente a causa del raggiungimento del timeout di 7 ore prima di completare il crawling completo a livelli più profondi; tutte le esecuzioni di Nimble si sono concluse con uno stato di timeout. Amazon si è rivelato più impegnativo:
- A profondità 5 ha gestito solo 319 pagine, ma a profondità 10 è salito a 988 pagine, poi sceso a 906 a profondità 20
- Questa incoerenza riflette probabilmente la combinazione dei meccanismi di protezione dei bot di Amazon e dei vincoli di timeout di Nimble, dove i crawling più profondi richiedono più tempo per elaborare ogni pagina e possono incontrare più sfide anti-bot lungo il percorso
Tempo di esecuzione nei domini per profondità massima
Firecrawl è stato il provider più veloce su tutti i domini, completando i crawling in meno di 5 minuti, tipicamente tra 75-265 secondi. Questa velocità ha un costo in termini di copertura, poiché Firecrawl ha anche crawlato il minor numero di pagine. In sostanza, finisce rapidamente perché si ferma presto.
Apify ha impiegato circa 2.200-2.400 secondi (~40 minuti) su theregister.com indipendentemente dalla profondità. Su entrepreneur.com e amazon.com, i tempi di esecuzione sono stati significativamente più lunghi a 8.300-15.900 secondi (2-4 ore), riflettendo strutture di sito più grandi e complesse. Nonostante i tempi più lunghi, Apify ha costantemente raggiunto il limite di 1.000 pagine, rendendolo il più affidabile in termini di rapporto copertura-tempo.
Cloudflare ha mostrato tempi che rispecchiano i suoi conteggi di crawling incoerenti:
- Su theregister.com a profondità 10, ha completato in soli 1 secondo, perché ha crawlato solo 1 pagina prima di fermarsi.
- Su entrepreneur.com a profondità 20, ha finito in 10 secondi dopo aver crawlato solo 172 pagine.
- Quando Cloudflare completa un crawling completo, i tempi variano da 3.500 a 25.200 secondi.
- All'aumentare della profondità massima, Cloudflare sembra dare priorità al raggiungimento di pagine più profonde rispetto alla larghezza, crawlando meno pagine ma completando più velocemente. Su amazon.com, il tempo di esecuzione è sceso da 25.200 secondi (timeout) a profondità 5 a soli 5.660 secondi a profondità 20, mentre le pagine crawlate sono diminuite da 905 a 795. Questo suggerisce che il crawler di Cloudflare cambia strategia a profondità maggiori, spendendo meno tempo nella scoperta ampia e più nella traversata profonda.
Nimble ha raggiunto il timeout di 7 ore (25.200 secondi) in ogni singola esecuzione su tutti i domini e livelli di profondità. Questo è notevole perché nei nostri precedenti test rapidi con profondità massima 1, Nimble ha completato senza timeout. Nel benchmark completo con profondità di 5-20 e un limite di 1.000 pagine, ha costantemente eseguito fino al raggiungimento del timeout. Nonostante ciò, Nimble è ancora riuscito a crawlare un alto numero di pagine nella maggior parte dei casi (~900-1.000 su theregister.com e entrepreneur.com), il che significa che sta attivamente crawlando durante le 7 ore ma semplicemente non segnala mai il completamento.
Tasso di riempimento del testo dei link tra i provider per profondità massima
Per valutare la qualità dell'output markdown, abbiamo misurato quale percentuale di link nel markdown di ogni provider contiene testo di ancoraggio, la parte cliccabile di un link. Un testo di ancoraggio mancante (ad esempio [](/about) invece di [About Us](/about)) significa che il crawler non è riuscito a estrarre l'etichetta del link.
- Nimble: 100% a tutte le profondità
- Cloudflare: 91-94%
- Firecrawl: 90%
- Apify: 77-78%, circa 1 link su 5 senza testo di ancoraggio
La profondità del crawling ha avuto un impatto minimo sui tassi di riempimento per qualsiasi provider, suggerendo che questa è una caratteristica del motore di parsing di ciascun provider piuttosto che una configurazione di crawling.
Tasso di riempimento del testo dei link tra i provider per dominio
Guardando ai tassi di riempimento tra diversi domini rivela come la complessità del sito influisca sulla qualità dell'estrazione dei link di ciascun provider.
- Nimble ha mantenuto il 100% su tutti i domini.
- Apify ha mostrato la maggiore variazione, 89% su amazon.com ma sceso al 66% su entrepreneur.com, il che significa che un terzo dei suoi link su quel sito mancava di testo di ancoraggio. Questo suggerisce che Apify fatica di più con i siti ricchi di contenuti che hanno strutture di navigazione complesse.
- Firecrawl ha ottenuto i migliori risultati su theregister.com (98%) ma è sceso all'81% su entrepreneur.com, seguendo un modello simile a Apify.
- Cloudflare è stato il più coerente dopo Nimble, rimanendo tra 89-94% indipendentemente dal dominio.
Entrepreneur.com si è rivelato il dominio più impegnativo per l'estrazione del testo dei link; sia Apify (66%) che Firecrawl (81%) hanno avuto i loro punteggi più bassi lì, probabilmente a causa dell'uso intensivo di menu di navigazione nidificati ed elementi di contenuto dinamici che sono più difficili da convertire pulitamente in markdown.
Totale link nell'output markdown tra i domini per profondità massima
La varianza del conteggio dei link tra i provider è stata costantemente alta (74-97%), indicando che i provider estraggono numeri molto diversi di link dalle stesse pagine. Per ottenere una visione più dettagliata di questa disparità, abbiamo misurato il conteggio totale dei link markdown per provider.
- Apify ha restituito il maggior numero di link in totale, in particolare su amazon.com con oltre 420K link a profondità 5 (~423 per pagina). Su entrepreneur.com si è stabilizzato intorno a 63K indipendentemente dalla profondità. Il suo output include tracker pubblicitari e pixel di tracciamento insieme ai link del contenuto della pagina.
- Cloudflare ha raggiunto un picco di 303K su entrepreneur.com a profondità 10 ma è sceso a 53K a profondità 20. Sulla stessa homepage di entrepreneur.com, Cloudflare ha estratto 434 link rispetto ai 143 di Apify, catturando menu di navigazione completi e sottomenu.
- Firecrawl ha restituito costantemente 5-9K link in tutte le configurazioni, limitato dal suo basso numero di pagine.
- Nimble ha restituito 3-40K link in totale, con una media di 5-28 link per pagina rispetto a 60-420 per altri provider. Sulla homepage di entrepreneur.com, Nimble ha restituito 13 link contro i 434 di Cloudflare, limitati ai titoli principali degli articoli. Il suo tasso di riempimento del 100% riflette che i link che ha incluso avevano tutti testo di ancoraggio, piuttosto che indicare una copertura completa dei link. Nimble non restituisce link markdown standard. Il suo conteggio include link HTML escapati trovati all'interno dell'output markdown.
Tasso di presenza del titolo tra i provider
La somiglianza dei titoli tra i provider ha mostrato una deviazione inferiore all'1% in tutti i test e domini, confermando che quando i provider estraggono un titolo, restituiscono costantemente lo stesso risultato. Il tasso di presenza del titolo è rimasto anche tra 98-100% a tutti i livelli di profondità massima, mostrando che la profondità del crawling non ha un impatto significativo sull'estrazione del titolo.
Quando scomposto per dominio, sono emerse alcune differenze:
Su entrepreneur.com e theregister.com, la maggior parte dei provider ha raggiunto tassi di presenza del titolo del 99-100%. Amazon.com è stato l'unico dominio in cui sono apparse differenze significative: Firecrawl è sceso al 93% e Nimble al 95,9%, mentre Apify ha mantenuto il 99,6%. Questo si allinea con la protezione dei bot più pesante di Amazon, che può bloccare o distorcere le risposte delle pagine, causando a alcuni provider di restituire pagine senza titoli estraibili.
Cos'è un web crawler?
Un web crawler, a volte chiamato "ragno" o "agente", è un bot che naviga su internet per indicizzare i contenuti.
I crawler si sono spostati oltre i motori di ricerca e ora servono come Livello Dati Agentic. Agiscono come gli occhi per gli agenti IA autonomi come Claude Code e OpenAI Operator, assistendo con compiti in tempo reale come la ricerca competitiva e le transazioni multi-step.
Cosa fa un web crawler?
Il web crawling è stato diviso in tre modalità, ciascuna progettata per un obiettivo di crawler diverso.
- Modalità scoperta (tradizionale): I bot dei motori di ricerca come Googlebot crawlanano URL per l'indicizzazione, aiutando le persone a trovare risultati attraverso i motori di ricerca.
- Modalità recupero (RAG): I bot IA come ChatGPT-User o PerplexityBot recuperano pagine specifiche in tempo reale per rispondere ai prompt degli utenti. Usano markdown invece di HTML per adattarsi ai limiti di token del modello IA.
- Modalità Agentic (orientata all'azione): Questo nuovo tipo di crawler nel 2026 fa più che semplicemente leggere i contenuti. Utilizzando il Protocollo di Contesto del Modello (MCP), questi bot possono interagire con i siti web per prenotare voli o eseguire comandi software.
In passato, i crawler usavano selettori come XPath o CSS per estrarre dati. Estrazione IA-Native è diventata la norma.
Strumenti come Firecrawl e Crawl4AI usano istruzioni in linguaggio naturale per trovare dati. Invece di scrivere regole per ogni elemento, gli sviluppatori possono dire al crawler di "estrarre il prezzo del prodotto" e l'IA troverà il valore corretto anche se il codice del sito web cambia.
Costruire o acquistare web crawler nell'era dell'IA
1. Costruire il proprio crawler
Ideale per proteggere la proprietà intellettuale principale e abilitare una personalizzazione approfondita. Costruire ora richiede lo sviluppo di un livello di agente proprietario, non solo la scrittura di script Scrapy di base.
- Quando costruire: Scegli questo approccio se il tuo crawler fornisce un vantaggio competitivo unico. Ad esempio, costruisci il tuo se stai sviluppando un motore di ricerca specializzato o richiedi il controllo completo su dati sensibili o regolamentati.
- Il set di strumenti: Non hai più bisogno di iniziare da zero. Gli sviluppatori ora sfruttano il Protocollo di Contesto del Modello (MCP) per abilitare agli agenti IA interni di interagire con il web.
2. Utilizzare strumenti e API di web crawling
Gli strumenti gestiti sono evoluti da scraper di base ad agenti autonomi.
- Estrazione a zero manutenzione: Strumenti moderni come Kadoa e Firecrawl usano IA auto-riparante. Specifici i dati richiesti, come "Prezzo del Prodotto", piuttosto che la sua posizione nel codice. Se il layout del sito web cambia, lo strumento si adatta automaticamente.
- Conformità come servizio: Molti provider offrono conformità integrata con l'IA Act dell'UE. Gestiscono i registri di audit richiesti e i controlli di opt-out sul copyright, che sono difficili da implementare indipendentemente.
- Velocità verso il valore: Acquistare una piattaforma può spostare il tuo progetto dal concetto alla produzione in poche settimane.
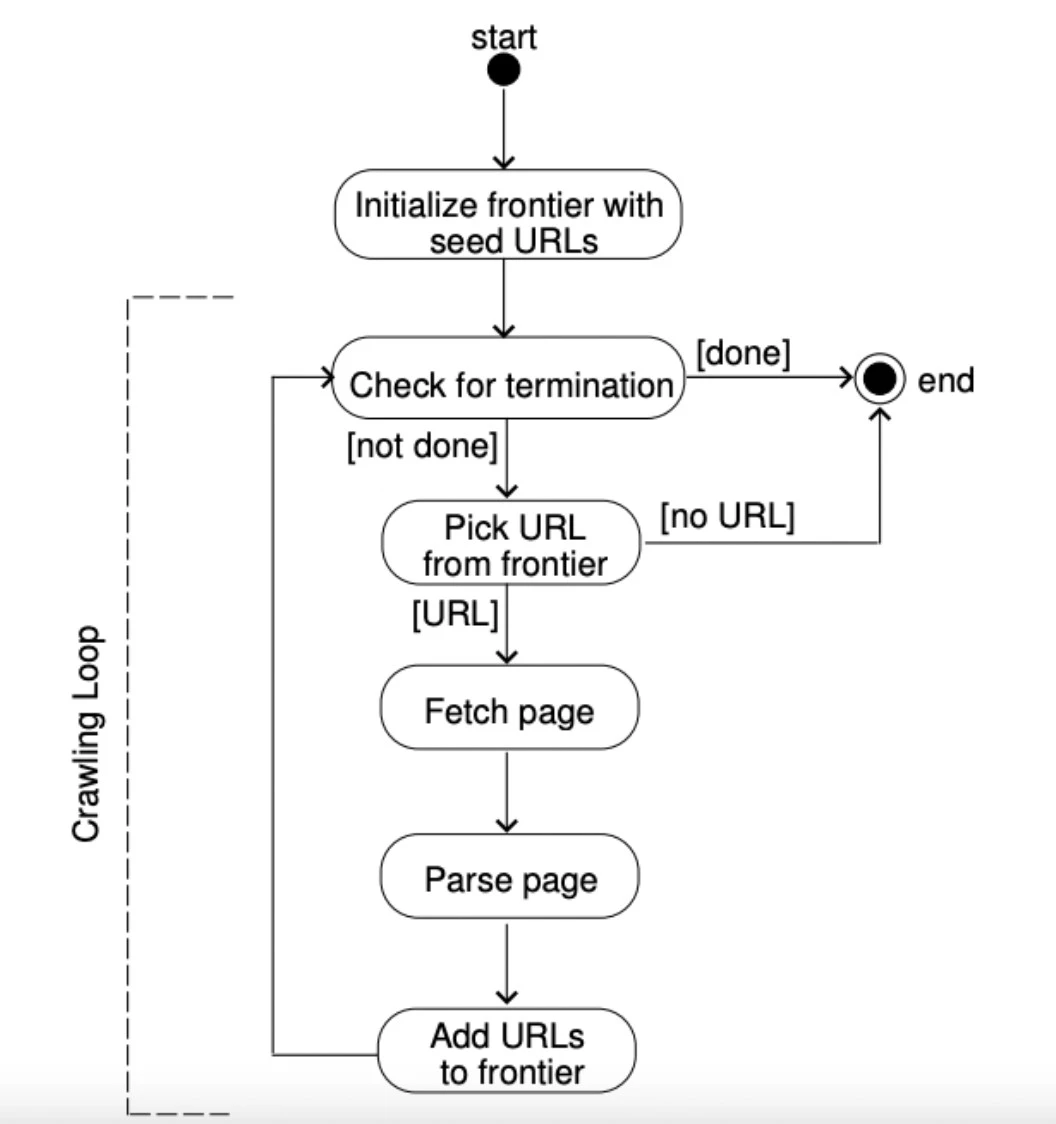
Figura 5: Una spiegazione di come funziona una frontiera URL.
I web crawler sono legali?
In generale, il web crawling è legale, ma a seconda di come e cosa crawli, potresti trovarti rapidamente in un problema legale. Quattro pilastri principali determinano se il crawling (e lo scraping che tipicamente segue) è legale:
1. Pubblico vs privato: Crawla solo dati che sono apertamente disponibili al pubblico senza un account.
2. Informazioni personali: Evita le PII (nomi, email e indirizzi) a meno che tu non abbia una base legale.
3. Salute del server: Usa limiti di velocità per evitare di rallentare il server; evita di "DDOSare" un sito web.
4. Copyright: Articoli e immagini sono protetti da copyright, ma i fatti (prezzi, date) non lo sono.
Qual è la differenza tra web crawling e web scraping?
Il web scraping è l'uso di web crawler per scansionare e memorizzare tutto il contenuto da una pagina web mirata. In altre parole, il web scraping è un caso d'uso specifico del web crawling per creare un dataset mirato, come estrarre tutte le notizie finanziarie per l'analisi degli investimenti e la ricerca di nomi di aziende specifici.
Tradizionalmente, una volta che un web crawler ha crawlato e indicizzato tutti gli elementi della pagina web, uno web scraper estraeva dati dalla pagina web indicizzata. Tuttavia, al giorno d'oggi i termini scraping e crawling sono usati in modo intercambiabile con la differenza che crawler tende a riferirsi più ai crawler dei motori di ricerca. Poiché le aziende diverse dai motori di ricerca hanno iniziato a usare i dati web, il termine web scraper ha iniziato a prendere il sopravvento sul termine web crawler.
Quali sono le sfide del web crawling?
1. Aggiornamento del database
I contenuti dei siti web vengono aggiornati regolarmente. Le pagine web dinamiche, ad esempio, cambiano i loro contenuti in base alle attività e ai comportamenti dei visitatori. Ciò significa che il codice sorgente del sito web non rimane lo stesso dopo aver crawlato il sito web. Per fornire le informazioni più aggiornate all'utente, il web crawler deve ricrawlare quelle pagine web più frequentemente.
2. Trappole per crawler
I siti web impiegano diverse tecniche, come le trappole per crawler, per impedire ai web crawler di accedere e crawlare determinate pagine web. Una trappola per crawler, o trappola per ragno, fa sì che un web crawler faccia un numero infinito di richieste e rimanga intrappolato in un circolo vizioso di crawling. I siti web possono anche creare involontariamente trappole per crawler. In ogni caso, quando un crawler incontra una trappola per crawler, entra in qualcosa come un ciclo infinito che spreca le risorse del crawler.
3. Larghezza di banda di rete
Scaricare un gran numero di pagine web irrilevanti, utilizzare un web crawler distribuito o ricrawlare molte pagine web comportano tutti un alto tasso di consumo della capacità di rete.
4. Pagine duplicate
I bot web crawler crawlanano principalmente tutto il contenuto duplicato sul web; tuttavia, viene indicizzata solo una versione di una pagina. Il contenuto duplicato rende difficile per i bot dei motori di ricerca determinare quale versione del contenuto duplicato indicizzare e classificare. Quando Googlebot scopre un gruppo di pagine web identiche nei risultati di ricerca, indicizza e seleziona solo una di queste pagine da visualizzare in risposta alla query di ricerca di un utente.
Top 3 le migliori pratiche di web crawling
1. Cortesia/velocità di crawling
I siti web impostano una velocità di crawling per limitare il numero di richieste effettuate dai bot web crawler. La velocità di crawling indica quante richieste un web crawler può fare al tuo sito web in un dato intervallo di tempo (ad esempio, 100 richieste all'ora). Permette ai proprietari di siti web di proteggere la larghezza di banda dei loro server web e ridurre il sovraccarico del server. Un web crawler deve rispettare il limite di crawling del sito web target.
2. Conformità a robots.txt
Un file robots.txt è un file di testo posizionato nella root di un sito web che dice ai crawler quali pagine sono consentite o non consentite di accedere. È uno standard volontario, il che significa che i bot conformi lo rispettano ma tecnicamente non impedisce l'accesso. Seguire il robots.txt di un sito web è considerato una migliore pratica e in molte giurisdizioni, ignorarlo potrebbe esporre a rischi legali o reputazionali.
3. Rotazione IP
I siti web impiegano diverse tecniche anti-scraping come i CAPTCHA per gestire il traffico dei crawler e ridurre le attività di web scraping. Ad esempio, browser fingerprinting è una tecnica di tracciamento utilizzata dai siti web per raccogliere informazioni sui visitatori, come la durata della sessione o le visualizzazioni delle pagine.
Questo metodo permette ai proprietari di siti web di rilevare il "traffico non umano" e bloccare l'indirizzo IP del bot. Per evitare il rilevamento, puoi integrare proxy rotanti, come i residenziali proxy, nel tuo web crawler.
Metodologia di benchmark dei web crawler
Abbiamo testato quattro API di crawling (Apify, Nimble, Cloudflare, Firecrawl) su tre domini di difficoltà variabile: amazon.com (protezione pesante dei bot), entrepreneur.com (sito web complesso) e theregister.com (sito di notizie).
Configurazione condivisa
Tutti i provider hanno ricevuto impostazioni di base identiche per garantire un confronto equo:
- Sitemap: Disabilitata, i provider devono scoprire le pagine solo attraverso link HTML
- Link esterni: Disabilitati, i crawler rimangono all'interno del dominio target
- Sottodomini: Abilitati, le pagine dei sottodomini sono seguite (ad esempio, india.entrepreneur.com)
- Rendering JavaScript: Abilitato, tutti i provider usano un browser headless
- Cache: Disabilitata
- Limite pagine: 1.000 pagine per esecuzione
- Timeout: 7 ore (25.200 secondi)
- Gestione limite di velocità: attesa di 20 secondi con fino a 3 tentativi su HTTP 429
Ogni provider è stato testato a tre livelli di profondità massima (5, 10, 20) su tutti e tre i domini, per un totale di 36 esecuzioni di crawling. I provider sono stati testati in sequenza (non in parallelo), ogni combinazione è stata eseguita una volta e lo stato del crawling è stato interrogato ogni 1 secondo.
Apify è stato configurato con l'actor website-content-crawler usando Playwright/Firefox come browser headless. L'accesso ai sottodomini è stato controllato tramite pattern glob e il proxy integrato di Apify è stato usato per tutte le richieste.
Nimble, Cloudflare e Firecrawl sono stati configurati usando le rispettive API REST con le impostazioni condivise descritte sopra. Non sono state applicate configurazioni specifiche del provider aggiuntive oltre ai parametri standardizzati.
Per Cloudflare, abbiamo usato il piano Workers Paid. Il costo riportato riflette quanto abbiamo speso per crawlare 1.000 pagine con questo piano. Cloudflare addebita in base al tempo di rendering del browser piuttosto che al numero di pagine.
Per Firecrawl, abbiamo usato il piano Hobby. Il costo riportato è l'importo proporzionato per 1.000 crediti sui crediti forniti in questo piano. Il costo effettivo per pagina varia a seconda del livello del piano e se vengono acquistati pacchetti di crediti aggiuntivi.
Cita questa ricerca
Scegli il formato adatto a dove pubblicherai. Incollare la versione con link nel tuo CMS preserva il backlink.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Şipi, Nazlı},
title = {{Benchmark dei Web Crawler per fornire siti web all'IA}},
year = {2026},
month = jul,
howpublished = {\url{https://aimultiple.com/web-crawler}},
note = {AIMultiple. Consultato il 2 Luglio 2026}
}
Commenti 1
Condividi i tuoi pensieri
Il tuo indirizzo email non verrà pubblicato. Tutti i campi sono obbligatori. I commenti vengono lasciati nella loro lingua originale.
Hi Cem, I think there is a misunderstanding regarding the robots.txt role in the crawling context. The web bots can crawl any website when indexing is allowed without having the robots.txt somewhere on their top domain, subdomains and ports and so on. The role of a robots.txt is to keep control of the traffic from web bots so the website is not overloaded by requests.