Le Sfide Più Comuni del Web Scraping
Il web scraping è diventato più difficile negli ultimi anni. Dal 2025, lo scraping legato all'IA ha sollevato significative preoccupazioni legali. Le piattaforme e i fornitori di infrastrutture hanno adottato nuovi metodi per controllare i crawler IA e gestire la raccolta dati.
Quali sono le principali sfide del web scraping?
Esistono molte sfide tecniche che i web scraper affrontano a causa delle barriere poste dai proprietari dei dati o dei siti web per distinguere tra umani e bot, e limitare l'accesso non umano alle loro informazioni. Le sfide del web scraping possono essere suddivise in queste categorie distinte:
Sfide derivanti dai siti web target:
- Barriera del punteggio di fiducia (rilevamento invisibile dei bot)
- L'inquinamento dei dati da parte di contenuti generati dall'IA
- Contenuti dinamici
- Cambiamenti nella struttura del sito web
- Tecniche anti-scraping (blocchi CAPTCHA, Robots.txt, blocchi IP, Honeypot e fingerprinting del browser)
Sfide inerenti agli strumenti di web scraping:
- Scalabilità
- Questioni legali ed etiche
- Manutenzione dell'infrastruttura
Rischi legali e di conformità
Le piattaforme continuano ad affrontare nuove rivendicazioni basate su contratto, concorrenza sleale, privacy e uso improprio dei dati. Nel 2025, Reddit ha fatto causa a Anthropic, sostenendo che Anthropic abbia raschiato i commenti degli utenti di Reddit per addestrare Claude senza autorizzazione. La causa si è concentrata su questioni relative ai termini di utilizzo e alla concorrenza sleale piuttosto che sul copyright.
Barriera del punteggio di fiducia (rilevamento invisibile dei bot)
Il blocco statico (IP/User-Agent) è stato sostituito da un punteggio comportamentale continuo di fiducia. I moderni fornitori anti-bot (Cloudflare, Akamai) tracciano il jitter del mouse e la velocità di scorrimento prima di un clic.
Gli scraper che saltano direttamente a un pulsante o cliccano con precisione matematica vengono contrassegnati con un punteggio di fiducia basso, portando a blocchi morbidi in cui i dati non vengono caricati senza un messaggio di errore.
Soluzione:
Gli strumenti standard basati su WebDriver/CDP vengono facilmente rilevati dai siti web. Utilizza librerie moderne come Nodriver, che comunica direttamente con Chrome senza lasciare tracce di automazione, o Camoufox, una versione rafforzata di Firefox progettata specificamente per la furtività.1
Inquinamento da contenuti generati dall'IA
Mentre gli scraper acquisiscono dati per l'addestramento, incontrano sempre più spesso il collasso del modello, raschiando accidentalmente allucinazioni generate dall'IA che degradano la qualità del loro stesso output. Questo rende l'autenticità dei dati una sfida tecnica piuttosto che un semplice controllo di qualità.
Soluzione:
Implementa un livello di convalida pre-archiviazione che calcoli la perplessità del testo raschiato. I contenuti generati dall'IA hanno spesso una perplessità innaturalmente bassa. Scarta i dati che scendono al di sotto di una certa soglia di unicità.
Contenuti web dinamici
I contenuti web dinamici rappresentano una sfida significativa per i web scraper, poiché alterano fondamentalmente il modo in cui le informazioni vengono fornite e visualizzate su una pagina web.
A differenza dei siti statici, dove tutto il contenuto si trova nel file HTML iniziale, i siti dinamici costruiscono la pagina al volo, spesso in risposta al comportamento dell'utente. Tecnologie come AJAX (Asynchronous JavaScript and XML) sono al centro dei siti web dinamici.
Il problema principale è che gli strumenti di scraping standard non sono browser web. Vedono il guscio HTML iniziale, che potrebbe contenere segnaposto, animazioni di caricamento e tag <script>, ma spesso manca dei dati effettivi che si desidera estrarre. Questi semplici strumenti non eseguono JavaScript.
Soluzione:
Per superare queste sfide, i web scraper devono evolversi da semplici parser HTML a strumenti in grado di renderizzare completamente una pagina web come il browser di un essere umano.
Un browser headless è un browser web senza interfaccia utente grafica (GUI). Funziona in background ma possiede tutte le capacità di un browser standard, incluso un potente motore JavaScript.
Strumenti come Selenium, Puppeteer e Playwright consentono di controllare programmaticamente i browser (come Chrome, Firefox o WebKit). Utilizzando questi strumenti avanzati, puoi costruire web scraper in grado di interagire con siti web complessi e dinamici e accedere a contenuti che sarebbero completamente invisibili ai metodi di web scraping più semplici.
Browser remoti
Un'altra soluzione sono i browser di scraping, chiamati anche browser remoti. Sono browser gestiti da aziende di dati web. Consentono inoltre ai web scraper di interagire con JavaScript.
Cambiamenti nella struttura del sito web
I siti web vengono continuamente migliorati. Queste modifiche possono influenzare il layout, il design o il codice sottostante del sito. L'impatto di un cambiamento minore:
- Ad esempio, se uno sviluppatore decide di cambiare la classe dell'elemento prezzo da price a current-price per maggiore chiarezza, le istruzioni dello scraper falliranno:
- Lo scraper non sarà più in grado di trovare il prezzo. Potrebbe restituire un errore, un valore vuoto o, peggio, potrebbe accidentalmente prelevare il dato sbagliato che si trova in una posizione simile.
- Poiché questi cambiamenti possono verificarsi in qualsiasi momento e senza preavviso, il codice dello scraper necessita costantemente di potenziali modifiche.
Soluzione
Invece di affidarsi a selettori altamente specifici e fragili, gli sviluppatori possono scriverne di più intelligenti. Ad esempio, invece di cercare un <span> con l'esatta classe price, un parser adattabile potrebbe cercare un <span> che si trova accanto al testo "Prezzo:" o uno che contiene il simbolo del dollaro ($).
È possibile eseguire controlli automatizzati periodicamente per convalidare i dati raschiati. Supponiamo che il campo del prezzo inizi improvvisamente a restituire valori vuoti per tutti i prodotti. In tal caso, il sistema può avvisare automaticamente lo sviluppatore che la struttura del sito web è probabilmente cambiata e che il parser deve essere aggiornato.
LLM
I modelli di IA possono essere utilizzati per identificare gli elementi da raschiare oppure per raccogliere dati dalle pagine web. Sebbene aggiungano latenza e costi allo scraping, aumentano l'adattabilità dei web scraper.
Tecniche anti-scraping
Molti siti web impiegano tecnologie anti-scraping per prevenire o ostacolare le attività di web scraping. I seguenti punti forniscono una panoramica di alcune delle misure anti-bot più comuni incontrate nel processo di web scraping:
Blocchi CAPTCHA
I siti web utilizzano i CAPTCHA quando sospettano che un visitatore possa essere un bot. Questo è comune sulle pagine web per la registrazione degli utenti, i moduli di accesso, le sezioni dei commenti e durante i processi di checkout per articoli ad alta domanda.
Implementazioni eccessivamente aggressive di CAPTCHA possono bloccare i "bot buoni", come il bot di Google che esegue la scansione del web per indicizzare le pagine per i risultati di ricerca. Se il crawler di Google viene bloccato, le pagine di un sito web potrebbero non essere indicizzate correttamente, il che può influire negativamente sulle sue pratiche SEO e sul posizionamento nei motori di ricerca.
Soluzione:
Per superare questo ostacolo, gli scraper devono essere dotati di un meccanismo per risolvere queste sfide. Sebbene efficace, l'utilizzo di un servizio di risoluzione CAPTCHA aggiunge un ulteriore livello di complessità e costi finanziari al progetto di web scraping, poiché questi servizi in genere applicano una tariffa per ogni CAPTCHA risolto.
Robots.txt
Dal 2025, la governance dei crawler si è ampliata oltre il classico robots.txt. Cloudflare ha introdotto controlli per i crawler IA, funzionalità gestite di robots.txt, Content Signals Policy e strumenti Pay Per Crawl che consentono agli editori di bloccare, consentire o far pagare l'accesso ai crawler.2
Soluzione:
L'approccio corretto è trovare un modo ufficialmente autorizzato per ottenere i dati web. La migliore alternativa è verificare se il sito web offre un'API per l'accesso ai dati. Se non è disponibile alcuna API pubblica, il passo successivo è la comunicazione diretta. Puoi contattare il proprietario del sito web o dei dati, spiegando chi sei e cosa intendi fare con i dati.
Blocco IP
Il blocco IP (noto anche come ban IP) è una delle misure anti-scraping più comuni e fondamentali adottate dai siti web. Quando il server di un sito web rileva un traffico insolitamente elevato da un singolo indirizzo IP, lo contrassegna come sospetto. Una volta che il tuo IP viene bloccato, qualsiasi ulteriore richiesta dal tuo scraper verrà rifiutata.
Soluzione:
Un proxy è un server intermedio che si frappone tra il tuo scraper e il sito web target. Quando invii una richiesta tramite un proxy, il sito web vede la richiesta provenire dall'indirizzo IP del proxy, non dal tuo indirizzo IP. Due potenti tipi di proxy per questo scopo:
- Proxy rotanti: Il tuo strumento di web scraping è configurato per utilizzare questo pool e, con ogni nuova richiesta (o dopo un determinato numero di richieste), ruota automaticamente su un indirizzo IP diverso. Questo distribuisce le tue richieste su più indirizzi IP, in modo che nessuno superi i limiti di velocità del sito web.
- Proxy residenziali: Gli indirizzi IP in un pool di proxy residenziali appartengono a connessioni internet reali di tipo consumer fornite dai fornitori di servizi internet (ISP) ai proprietari di abitazioni. Poiché il traffico proviene da un indirizzo IP residenziale legittimo, è quasi impossibile per un sito web distinguere la richiesta di uno scraper da quella di un autentico utente umano.
Trappole honeypot
Gli honeypot sono sistemi informatici progettati per attirare gli hacker e impedire loro di accedere ai siti web. Una trappola honeypot appare tipicamente come una parte legittima del sito web e contiene dati che un utente malintenzionato potrebbe prendere di mira.
Se un bot di crawling tenta di estrarre il contenuto di una trappola honeypot, entrerà in un ciclo infinito di richieste e non riuscirà a estrarre ulteriori dati.
Perché i bot ci cascano
Un utente umano interagisce con la versione renderizzata e visiva di un sito web e non vedrebbe né cliccherebbe mai su questo collegamento nascosto. Tuttavia, molti scraper semplici non renderizzano visivamente la pagina.
Funzionano analizzando il codice sorgente HTML grezzo ed estraendo programmaticamente tutti i collegamenti (tag <a href="…">) che trovano. Poiché il collegamento honeypot esiste nell'HTML, il bot ingenuo lo vedrà e lo seguirà, come qualsiasi altro collegamento legittimo.
Soluzione
Invece di analizzare l'HTML grezzo, utilizza un browser headless, come Selenium, Puppeteer o Playwright. Inoltre, definendo posizioni specifiche e prevedibili per i collegamenti che desideri seguire, puoi ridurre la probabilità che il tuo scraper si imbatta in un collegamento honeypot che è stato intenzionalmente posizionato in una parte oscura dell'HTML.
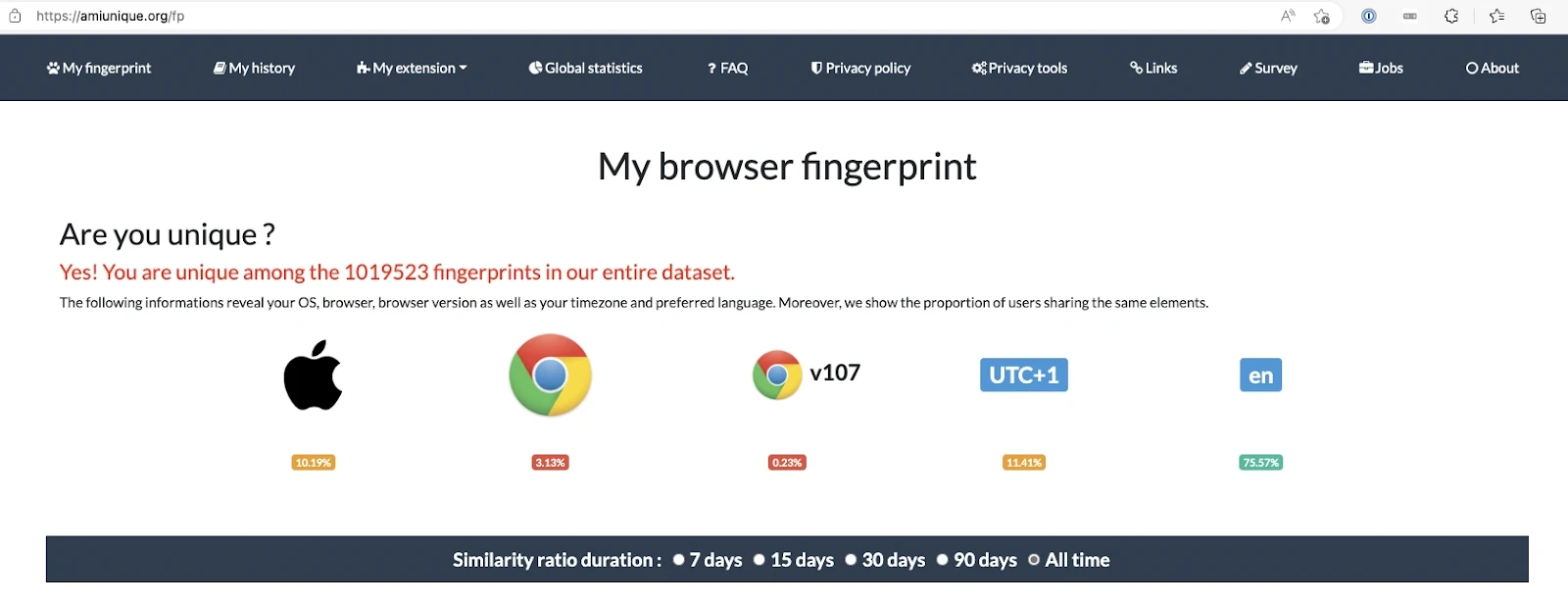
Browser fingerprinting
Il browser fingerprinting è un metodo utilizzato dai siti web per raccogliere informazioni sui propri visitatori attraverso i loro indirizzi IP. Ogni volta che accedi a un sito web, il tuo dispositivo invia una richiesta di connessione al sito per caricare il suo contenuto. Questo consente al sito web di recuperare e archiviare i dati trasmessi dal tuo browser riguardanti il tuo dispositivo.
I siti web possono accumulare dettagli estesi sul dispositivo di un utente, consentendo loro di personalizzare i suggerimenti per i propri visitatori utilizzando il browser fingerprinting. Ad esempio, il sito web target può estrarre dati sui tuoi user agent, intestazioni HTTP, impostazioni della lingua e plugin installati.
Fonte: AmIUnique
La sfida per gli scraper
Il browser fingerprinting rappresenta una sfida significativa perché gli scraper, per impostazione predefinita, hanno impronte digitali strane e incoerenti.
- Impronte generiche: Uno scraper di base che utilizza una semplice libreria invierà un set minimo di intestazioni e non avrà plugin, risoluzione dello schermo o altri attributi "umani".
- Impronte incoerenti: Uno scraper potrebbe utilizzare proxy rotanti, facendo sì che il suo indirizzo IP appaia dalla Germania in una richiesta e dal Giappone in quella successiva.
Soluzione
Utilizza browser headless come Selenium, Puppeteer o Playwright. Si tratta di veri motori browser che generano un'impronta digitale più completa e credibile fin da subito rispetto alle semplici librerie HTTP.
Puoi anche mantenere un elenco di stringhe User-Agent standard e reali e ruotarle per diverse sessioni. Assicurati che le intestazioni HTTP inviate siano coerenti con quelle di un browser reale.
Scalabilità
Potresti aver bisogno di raschiare una grande quantità di dati web da più siti web per ottenere approfondimenti sull'intelligence dei prezzi, sulle ricerche di mercato e sulle preferenze dei clienti. Man mano che la quantità di dati da raschiare aumenta, hai bisogno di un web scraper altamente scalabile per effettuare molteplici richieste parallele.
Soluzione:
Devi utilizzare un web scraper progettato per gestire richieste asincrone per migliorare la velocità e raccogliere grandi quantità di dati più rapidamente.
Lo scraping asincrono dei dati è una tecnica che consente a uno scraper di inviare più richieste a diversi siti web senza attendere che ciascuna risponda prima di inviare la successiva.
Ad esempio, se un sito web è lento a rispondere, uno scraper asincrono può continuare a inviare ed elaborare richieste ad altri siti web più veloci nel frattempo.
Manutenzione dell'infrastruttura
Per mantenere prestazioni ottimali del server, è essenziale aggiornare o espandere regolarmente risorse come lo storage per accogliere volumi di dati crescenti e le complessità del web scraping. Devi aggiornare continuamente la tua infrastruttura di web scraping per stare al passo con le esigenze in evoluzione.
Costruire e gestire un'infrastruttura di scraping richiede un'ampia gamma di competenze tecniche. Ciò include l'amministrazione dei server, la gestione delle reti, l'ottimizzazione dei database e le conoscenze specializzate necessarie per aggirare i meccanismi anti-bot.
Soluzione:
Quando esternalizzi le tue esigenze di web scraping, assicurati che il fornitore di servizi offra funzionalità integrate come un rotatore di proxy e un parser di dati. Inoltre, il fornitore dovrebbe offrire opzioni scalabili e aggiornare regolarmente la propria infrastruttura per soddisfare le esigenze in evoluzione.
Cita questa ricerca
Scegli il formato adatto a dove pubblicherai. Incollare la versione con link nel tuo CMS preserva il backlink.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{Le Sfide Più Comuni del Web Scraping}},
year = {2026},
month = may,
howpublished = {\url{https://aimultiple.com/web-scraping-challenges}},
note = {AIMultiple. Consultato il 13 Maggio 2026}
}
Sii il primo a commentare
Il tuo indirizzo email non verrà pubblicato. Tutti i campi sono obbligatori. I commenti vengono lasciati nella loro lingua originale.