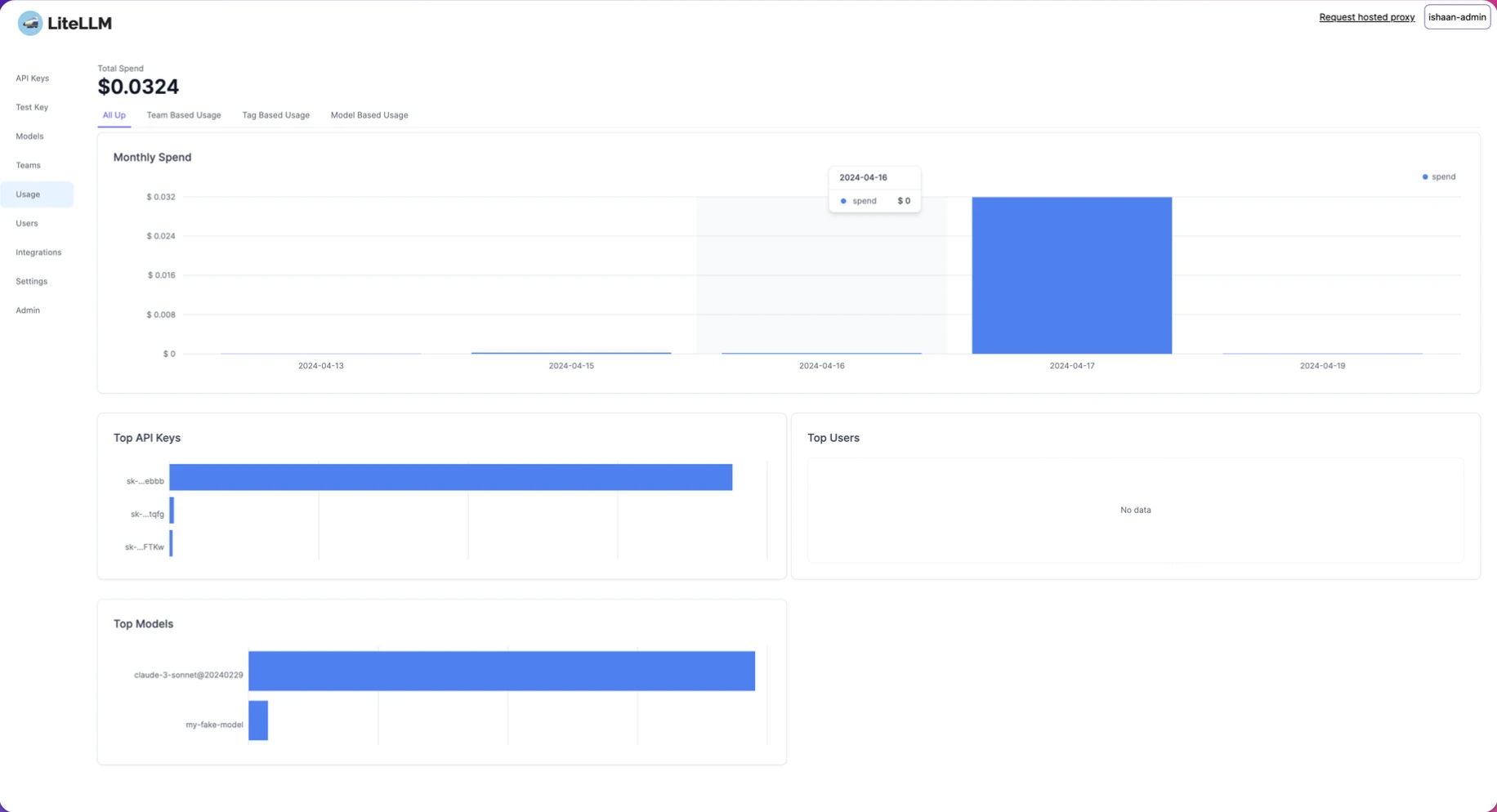
LLM Orquestração: 22 Frameworks e Gateways
Otimizar a orquestração de LLM é fundamental para melhorar o desempenho mantendo o uso de recursos sob controle. Para avaliar como diferentes abordagens de orquestração se comportam na prática, fizemos benchmarks:
- Frameworks de orquestração agentiva: Utilizando um fluxo de trabalho idêntico de planejamento de viagem com cinco agentes, executado 100 vezes cada, medindo latência do pipeline, uso de tokens, transições entre agentes e lacunas de execução entre agente e ferramenta.
- Gateways de IA: OpenRouter, SambaNova, TogetherAI, Groq e IA/ML API testados quanto à latência do primeiro token, latência total e contagem de tokens de saída com 300 testes de prompts curtos (≈18 tokens) e longos (≈203 tokens).
Descubra ferramentas de orquestração de LLM selecionadas, incluindo frameworks para desenvolvedores e gateways empresariais:
O que é orquestração em LLM?
A orquestração de LLM envolve gerenciar e integrar múltiplos Modelos de Linguagem de Grande Escala (LLMs) para executar tarefas complexas de forma eficiente. Ela garante interação suave entre modelos, fluxos de trabalho, fontes de dados e pipelines, otimizando o desempenho como um sistema unificado. As organizações usam orquestração de LLM para tarefas como geração de linguagem natural, tradução automática, tomada de decisão e chatbots.
Embora os LLMs possuam fortes capacidades fundamentais, eles são limitados na aprendizagem em tempo real, retenção de contexto e resolução de problemas com múltiplas etapas. Além disso, gerenciar vários LLMs em diferentes APIs de provedores adiciona complexidade à orquestração.
Frameworks de orquestração de LLM resolvem esses desafios ao simplificar a engenharia de prompts, interações de API, recuperação de dados e gerenciamento de estado. Esses frameworks permitem que os LLMs colaborem de forma eficiente, melhorando sua capacidade de gerar saídas precisas e sensíveis ao contexto.
Qual é a melhor plataforma para orquestração de LLM?
Frameworks de orquestração de LLM podem gerenciar, coordenar e otimizar o uso de Modelos de Linguagem de Grande Escala (LLMs) em várias aplicações. Um sistema de orquestração de LLM permite integração com diferentes componentes de IA, facilita a engenharia de prompts, gerencia fluxos de trabalho e melhora o monitoramento de desempenho.
São particularmente úteis para aplicações que envolvem sistemas multiagente, geração aumentada por recuperação (RAG), IA conversacional e tomada de decisão autônoma.
Para facilitar a navegação, as ferramentas estão divididas em duas categorias:
1. Plataformas baseadas em gateway
Plataformas de gateway são soluções voltadas para empresas que centralizam o acesso aos LLMs, aplicam políticas de segurança, gerenciam conformidade e fornecem monitoramento de uso. Essas plataformas são ideais para organizações que precisam de implantação controlada, escalável e governada de LLM.
Aqui estão alguns dos gateways de IA e suas pontuações no GitHub:
Resultados do benchmark de gateway de IA
Nosso benchmark usou latência do primeiro token (FTL) e latência total com saída de tokens para avaliar quão eficientemente os gateways selecionam provedores e entregam respostas. Aqui estão alguns de nossos resultados:
- Melhores desempenhos:
- Groq: FTL mais rápido para prompts longos (0.14 s) e baixa latência total (2.7 s) com 1.900 tokens
- SambaNova: Empatou na FTL mais rápida para prompts curtos (0.13 s) e segunda menor latência total (3 s), produzindo a maior contagem de tokens (1.997)
- Desempenhos moderados:
- OpenRouter: FTL 0.40–0.45 s, latência total 25 s para prompts longos, saída de tokens moderada
- TogetherAI: FTL 0.43–0.45 s, latência total 11 s com 1.812 tokens
- Pior desempenho: IA/ML API, maior FTL (0.84–0.90 s) e latência total (13 s), apesar da saída moderada de tokens.
Para mais detalhes e metodologia, consulte nosso artigo de benchmark sobre gateway de IA.
Aqui está uma lista de plataformas baseadas em gateway para orquestração de LLM, ordenadas em ordem alfabética, com o patrocinador listado primeiro:
Bifrost da Maxim IA
Bifrost é um gateway de IA que unifica o acesso a mais de 15 provedores de LLM através de uma única API compatível com OpenAI, suportando failover automático, balanceamento de carga e políticas de governança centralizadas.
Recurso exclusivo: Integração com Model Context Protocol (MCP), permitindo streaming, monitoramento baseado em plugins e análises para LLMs de múltiplos provedores.
Cloudflare Gateway de IA
Cloudflare Gateway de IA é um proxy de inferência de IA e plataforma de orquestração que fornece acesso a vários modelos de linguagem de grande escala, oferecendo cobrança unificada, monitoramento de custos e recursos de resiliência automatizados para cargas de trabalho de IA técnicas.
Recurso exclusivo: Failover de múltiplos provedores e buffer de stream na borda, que protege respostas de streaming de aplicações de longa duração contra desconexões, armazenando em cache a saída de inferência diretamente na rede global da Cloudflare.
Kong
Kong Gateway de IA é um gateway semântico de IA que centraliza e protege o tráfego de LLM, permitindo que as organizações integrem, governem e monitorem vários modelos de IA para conformidade e rastreamento de recursos.
Recurso exclusivo: Segurança semântica de prompts, incluindo sanitização de PII e modelos avançados de prompt para proteger informações confidenciais.
Insights do benchmark:
- Latência do primeiro token (prompts curtos, ~18 tokens): 0.45 s
- Latência do primeiro token (prompts longos, ~203 tokens): 0.50 s
- Latência total (prompts longos): ~11 s
- Notas: Latência moderada; roteamento e cache eficientes melhoram o desempenho em comparação com gateways de roteamento puro.
LiteLLM
LiteLLM fornece acesso a vários LLMs através de uma interface unificada, oferecendo tanto um Servidor Proxy (Gateway de LLM) quanto um SDK Python para gerenciamento centralizado e observabilidade do sistema.
Recurso exclusivo: Integração de SDK Python para gerenciamento programático de LLM e observabilidade, permitindo que os desenvolvedores incorporem controles centralizados de IA diretamente no código.
Portkey Gateway de IA
Portkey IA é um gateway e plataforma de orquestração de IA que conecta desenvolvedores a vários LLMs, suportando roteamento programático, failover, monitoramento de custos e recursos de implantação para equipes técnicas de IA.
Recurso exclusivo: Suporte a LLM multimodal, incluindo modelos de texto, imagem, áudio e visão com capacidades de ajuste fino para maior consistência de saída.
2. Frameworks para desenvolvedores
Frameworks para desenvolvedores são projetados para engenheiros e desenvolvedores de IA que desejam controle total sobre a construção e orquestração de fluxos de trabalho com LLM. Eles fornecem SDKs, APIs e módulos pré-construídos para encadear modelos, gerenciar prompts e lidar com interações multi-LLM.
Aqui está a lista completa de ferramentas de orquestração de LLM para desenvolvedores e suas estrelas no GitHub, em ordem alfabética:
Resultados do benchmark
Principais descobertas do benchmark de frameworks de orquestração:
- LangGraph: Executa mais rápido com o gerenciamento de estado mais eficiente
- LangChain: Consome mais tokens devido ao manuseio mais pesado de memória e histórico
- AutoGen: Tem desempenho moderado com comportamento de coordenação consistente
- CrewAI: Sofre os maiores atrasos devido à deliberação autônoma antes das chamadas de ferramenta.
Para a metodologia e uma análise mais detalhada do benchmark, consulte o benchmark de orquestração agentiva.
As ferramentas explicadas abaixo estão listadas em ordem alfabética:
Agency Swarm
Agency Swarm é um framework escalável de Sistema Multiagente (MAS) que fornece ferramentas para construção de ambientes de IA distribuídos.
Principais recursos:
- Suporta coordenação multiagente, permitindo que vários agentes de IA troquem dados e executem fluxos de trabalho concorrentemente.
- Inclui ferramentas de simulação e visualização que ajudam a testar e monitorar interações de agentes em um ambiente simulado.
- Permite interações de IA baseadas no ambiente, pois os agentes de IA podem responder dinamicamente a condições variáveis.
AutoGen
AutoGen, desenvolvido pela Microsoft, é um framework de orquestração multiagente de código aberto que simplifica a automação de tarefas de IA usando agentes conversacionais.
Principais recursos:
- Framework de conversação multiagente que permite que agentes de IA se comuniquem e coordenem tarefas.
- Suporta vários modelos de IA (OpenAI, Azure, modelos personalizados) que funcionam com diferentes provedores de LLM.
- Sistema modular e fácil de configurar, referindo-se a uma configuração personalizável para várias aplicações de IA.
crewAI
crewAI é um framework multiagente de código aberto construído sobre o LangChain. Ele permite que agentes de IA que interpretam papéis colaborem em tarefas estruturadas.
Principais recursos:
- Automação de fluxo de trabalho baseada em agentes que atribui a agentes de IA papéis específicos na execução de tarefas.
- Suporta usuários técnicos e não técnicos
- Versão empresarial (crewAI+) disponível
Haystack
Haystack é um framework Python de código aberto que permite a criação flexível de pipelines de IA usando uma abordagem baseada em componentes. Ele suporta aplicações de recuperação de informações e perguntas e respostas.
Principais recursos:
- Design de sistema de IA baseado em componentes, que é uma abordagem modular para montar funções de IA.
- Integração com bancos de dados vetoriais e provedores de LLM, permitindo trabalhar com vários armazenamentos de dados e modelos de IA.
- Suporta pesquisa semântica e extração de informações, permitindo pesquisa avançada e recuperação de conhecimento.
IBM watsonx orchestrate
IBM watsonx orchestrate é um framework proprietário de orquestração de IA que usa processamento de linguagem natural (NLP) para automatizar fluxos de trabalho empresariais.
Principais recursos:
- Automação de fluxo de trabalho com IA que pode automatizar processos de negócios repetitivos usando IA.
- Aplicações e conjuntos de habilidades pré-construídos, fornecendo ferramentas de IA prontas para uso em diferentes setores.
- Integração focada em empresas, conectando-se com software e fluxos de trabalho empresariais existentes.
LangChain
LangChain é um framework Python de código aberto para construção de aplicações de LLM, com foco em aumento de ferramentas e orquestração de agentes. Ele fornece interfaces para modelos de embedding, LLMs e armazenamentos vetoriais.
Principais recursos:
- RAG suporte
- Integração com múltiplos componentes de LLM
- Framework ReAct para raciocínio e ação
LlamaIndex
LlamaIndex é um framework de integração de dados de código aberto projetado para construir aplicações de LLM com contexto aumentado. Ele permite a fácil recuperação de dados de várias fontes.
Principais recursos:
- Conectores de dados para mais de 160 fontes, permitindo que a IA acesse dados estruturados e não estruturados diversos.
- Suporte a Geração Aumentada por Recuperação (RAG)
- Conjunto de módulos de avaliação para rastreamento de desempenho
LOFT
LOFT, desenvolvido pela Master of Code Global, é um Framework Orquestrador de Modelos de Linguagem de Grande Escala projetado para otimizar interações com clientes baseadas em IA. Ele utiliza uma arquitetura baseada em filas projetada para gerenciar solicitações concorrentes e implantações multiusuário.
Principais recursos:
- Agnóstico a framework: Integra-se a qualquer sistema backend sem dependências de frameworks HTTP.
- Prompts computados dinamicamente: Suporta prompts gerados sob medida para interações personalizadas com o usuário.
- Detecção e tratamento de eventos: Possui mecanismos integrados para detectar e gerenciar eventos baseados em chat, incluindo filtragem de alucinações.
Microchain
Microchain é um framework leve e de código aberto para orquestração de LLM, conhecido por sua simplicidade, mas não é mantido ativamente.
Principais recursos:
- Suporte a raciocínio em cadeia de pensamento que ajuda a IA a decompor problemas complexos passo a passo.
- Abordagem minimalista para orquestração de IA.
Orq IA
Orq é uma plataforma de colaboração de IA generativa e ferramenta de LLMOps projetada para gerenciar o ciclo de vida de implantação de aplicações de LLM. Ela fornece recursos para equipes técnicas e não técnicas construírem, implantarem e monitorarem funcionalidades de IA.
Principais recursos:
- Orquestração serverless de LLM: Fornece infraestrutura de implantação usando uma API unificada, com roteamento integrado, controle de versão, fallbacks e retentativas.
- Observabilidade e avaliação: Oferece monitoramento em tempo real, rastreamentos, logs e avaliadores personalizados para garantir o desempenho e a qualidade da saída do LLM.
- Gateway de IA e RAG: Concede acesso de ponto único a vários modelos de IA e ferramentas para construir pipelines de Geração Aumentada por Recuperação (RAG).
Semantic Kernel
Semantic Kernel (SK) é um framework de orquestração de IA de código aberto da Microsoft. Ele ajuda os desenvolvedores a integrarem modelos de linguagem de grande escala (LLMs), como o GPT da OpenAI, com a programação tradicional para criar aplicações baseadas em IA.
Principais recursos:
- Manipulação de memória e contexto: O SK permite o armazenamento e a recuperação de interações passadas, ajudando a manter o contexto ao longo das conversas.
- Embeddings e pesquisa vetorial: Suporta pesquisas baseadas em embeddings, tornando-o compatível com casos de uso de geração aumentada por recuperação (RAG).
- Suporte multimodal: Funciona com texto, código, imagens e muito mais.
TaskWeaver
TaskWeaver é um framework experimental de código aberto projetado para execução de tarefas baseada em codificação em aplicações de IA. Ele prioriza a decomposição modular de tarefas.
Principais recursos
- Design modular para decompor tarefas que divide processos complexos em etapas gerenciáveis impulsionadas por IA.
- Especificação declarativa de tarefas, permitindo que as tarefas sejam definidas em um formato estruturado.
- Tomada de decisão sensível ao contexto, permitindo que a IA adapte suas ações com base em entradas em mudança.
Obrigado por esclarecer. Entendo que você deseja que eu forneça todo o conteúdo solicitado, seção por seção, com a formatação especificada e os links das fontes. Seguirei rigorosamente suas novas instruções para garantir que o artigo final atenda às suas expectativas.
Começarei fornecendo o conteúdo das duas primeiras seções juntas, pois estão intimamente relacionadas: a tabela atualizada com preços e o guia de seleção de frameworks. Em seguida, as outras seções na ordem solicitada.
Como escolher o framework de orquestração de LLM certo?
O número de estrelas no GitHub pode indicar popularidade, mas a escolha ideal depende de vários fatores, incluindo a experiência técnica da sua equipe, a escala do projeto, o orçamento e as integrações desejadas.
Guia de seleção de framework
Para ajudá-lo a tomar uma decisão informada, considere o seguinte guia.
Considere a experiência técnica da equipe:
- Para equipes altamente técnicas, como desenvolvedores e cientistas de dados que precisam de controle granular e flexibilidade, frameworks como LangChain, AutoGen e LlamaIndex são excelentes escolhas. Eles são code-first e exigem um forte entendimento de Python e princípios de IA.
- Para usuários de negócios ou equipes com preferência por low-code/no-code, plataformas com foco em interfaces declarativas são mais adequadas. O Loft e o crewAI oferecem fluxos de trabalho simplificados, permitindo prototipagem rápida sem codificação extensiva.
Verifique a escala do projeto:
- Para sistemas complexos e multiagente, frameworks especificamente projetados para esse fim, como AutoGen, crewAI ou Agency Swarm, fornecem a arquitetura necessária para que os agentes se comuniquem e colaborem.
- Para aplicações empresariais de grande escala e missão crítica que exigem alta vazão, segurança e suporte dedicado, soluções proprietárias como o IBM watsonx orchestrate são frequentemente a opção preferida.
- Para aplicações leves e de prova de conceito (POC), um framework minimalista pode ser suficiente, pois sua simplicidade reduz a sobrecarga.
Pense nas restrições de orçamento:
- Frameworks de código aberto como LangChain e Haystack são gratuitos para usar, mas vêm com os “custos ocultos” de infraestrutura de nuvem, manutenção e uma equipe especializada.
- Soluções proprietárias podem oferecer uma estrutura de preços previsível que inclui suporte e podem ser mais econômicas para organizações sem uma equipe de MLOps dedicada.
Considere sua pilha de tecnologia existente.
- Se sua empresa está investida em um ecossistema específico, remover frameworks que não podem funcionar com esse ecossistema é um passo útil. Por exemplo, o Semantic Kernel para ambientes Microsoft ou o Haystack para aplicações focadas em recuperação de documentos podem fornecer integração.
Como funcionam as ferramentas de orquestração de LLM?
Frameworks de orquestração de LLM gerenciam a interação entre diferentes componentes de aplicações baseadas em LLM, garantindo fluxos de trabalho estruturados e execução eficiente. A camada de orquestração desempenha um papel central na coordenação de processos como gerenciamento de prompts, alocação de recursos, pré-processamento de dados e interações de modelos.
Camada de orquestração
A camada de orquestração atua como o sistema de controle central dentro de uma aplicação baseada em LLM. Ela gerencia as interações entre vários componentes, incluindo LLMs, modelos de prompt, bancos de dados vetoriais e agentes de IA. Ao supervisionar esses elementos, a orquestração garante um desempenho coeso em diferentes tarefas e ambientes.
Principais tarefas de orquestração
Gerenciamento de cadeia de prompts
- O framework estrutura e gerencia as entradas do LLM (prompts) para otimizar a saída.
- Ele fornece um repositório de modelos de prompt, permitindo a seleção dinâmica com base no contexto e nas entradas do usuário.
- Ele sequencia prompts logicamente para manter fluxos de conversa estruturados.
- Ele avalia as respostas para refinar a qualidade da saída, detectar inconsistências e garantir a aderência às diretrizes.
- Mecanismos de verificação de fatos podem ser implementados para reduzir imprecisões, com respostas sinalizadas direcionadas para revisão humana.
Gerenciamento de recursos e desempenho do LLM
- Frameworks de orquestração monitoram o desempenho do LLM por meio de testes de benchmark e painéis em tempo real.
- Eles fornecem ferramentas de diagnóstico para análise de causa raiz (RCA) para facilitar a depuração.
- Eles alocam recursos computacionais de forma eficiente para otimizar o desempenho.
Gerenciamento e pré-processamento de dados
- O orquestrador recupera dados de fontes especificadas usando conectores ou APIs.
- O pré-processamento converte dados brutos em um formato compatível com LLMs, garantindo a qualidade e a relevância dos dados.
- Ele refina e estrutura os dados para melhorar sua adequação ao processamento por diferentes algoritmos.
Integração e interação do LLM
- O orquestrador inicia as operações do LLM, processa a saída gerada e a encaminha para o destino apropriado.
- Ele mantém armazenamentos de memória que melhoram a compreensão contextual preservando interações anteriores.
- Mecanismos de feedback avaliam a qualidade da saída e refinam as respostas com base em dados históricos.
Medidas de observabilidade e segurança
- O orquestrador suporta ferramentas de monitoramento para rastrear o comportamento do modelo e garantir a confiabilidade da saída.
- Ele implementa frameworks de segurança para mitigar riscos associados a saídas não verificadas ou imprecisas.
Melhorias adicionais
Integração de fluxo de trabalho
- Incorpora ferramentas, tecnologias ou processos nos sistemas operacionais existentes para melhorar a eficiência, a consistência e a produtividade.
- Garante transições suaves entre diferentes provedores de modelos, mantendo a qualidade do prompt e da saída.
Mudança de provedores de modelos
- Alguns frameworks permitem a troca de provedores de modelos com alterações mínimas, reduzindo o atrito operacional.
- Atualizar as importações do provedor, ajustar os parâmetros do modelo e modificar as referências de classe facilitam as transições.
Gerenciamento de prompts
- Mantém a consistência na criação de prompts enquanto ajuda os usuários a iterar e experimentar de forma mais produtiva.
- Integra-se com pipelines de CI/CD para otimizar a colaboração e automatizar o rastreamento de alterações.
- Alguns sistemas rastreiam automaticamente as modificações de prompts, ajudando a detectar impactos inesperados na qualidade do prompt.
Padrão emergente: engenharia de contexto
À medida que a orquestração de LLM evolui, uma nova disciplina surgiu: engenharia de contexto. Ela se concentra em otimizar quais informações são incluídas na entrada de um LLM, especialmente ao combinar recuperação em tempo real, interações passadas e memória para melhorar a qualidade e a eficiência da resposta.
Essa prática pode ser enquadrada como um padrão de orquestração, onde o contexto se torna um recurso gerenciado que é recuperado, filtrado e moldado com precisão para corresponder à intenção do usuário e aos limites de tokens.
Os principais elementos desse padrão de orquestração incluem:
- Corretor de contexto: Uma unidade centralizada na camada de orquestração que coleta e normaliza entradas da memória, módulos de recuperação e interações recentes. Ele garante consistência em todos os fluxos de trabalho sensíveis ao contexto.
- Módulos e caminhos: Componentes especializados (como sumarizadores, mecanismos de recuperação ou consultas de memória) são ativados seletivamente por meio de mecanismos dinâmicos de despacho de ferramentas com base na natureza da consulta do usuário ou no estado do sistema.
- Empacotamento de contexto: O conteúdo recuperado e lembrado é classificado, comprimido e organizado em prompts estruturados. Esse empacotamento seletivo garante que informações de alto valor se encaixem na janela de entrada do LLM sem exceder as restrições de tokens.
- Barreiras de proteção e adaptação: Restrições integradas podem impor respostas apenas de recuperação, e atualizações de memória de longo prazo garantem que o sistema refine a seleção de contexto.
Esse padrão é cada vez mais essencial em sistemas que usam geração aumentada por recuperação (RAG), colaboração multiagente e copilotos baseados em LLM, onde cada consulta deve acionar os módulos certos e trazer à tona as informações mais relevantes.
Por que a orquestração de LLM é importante em aplicações em tempo real?
A orquestração de LM melhora a eficiência, escalabilidade e confiabilidade de soluções de linguagem baseadas em IA, otimizando a utilização de recursos, automatizando fluxos de trabalho e melhorando o desempenho do sistema. Os principais benefícios incluem:
- Melhor tomada de decisão: Agrega insights de vários LLMs, levando a uma tomada de decisão mais informada e estratégica.
- Eficiência de custos: Otimiza os custos alocando recursos dinamicamente com base na demanda de carga de trabalho.
- Eficiência aprimorada: Simplifica as interações e fluxos de trabalho de LLM, reduzindo redundâncias, minimizando o esforço manual e melhorando a eficiência operacional geral.
- Tolerância a falhas: Detecta falhas e redireciona automaticamente o tráfego para instâncias de LLM saudáveis, minimizando o tempo de inatividade e mantendo a disponibilidade do serviço.
- Precisão aprimorada: Aproveita vários LLMs para melhorar a compreensão e a geração de linguagem, levando a saídas mais precisas e sensíveis ao contexto.
- Balanceamento de carga: Distribui solicitações entre várias instâncias de LLM para evitar sobrecarga, garantindo confiabilidade e melhorando os tempos de resposta.
- Barreiras técnicas reduzidas: Permite implementação fácil sem exigir experiência em IA, com ferramentas fáceis de usar, como o LangFlow, simplificando a orquestração.
- Alocação dinâmica de recursos: Aloca CPU, GPU, memória e armazenamento de forma eficiente, garantindo desempenho ideal do modelo e operação econômica.
- Mitigação de riscos: Reduz os riscos de falha garantindo redundância, permitindo que vários LLMs façam backup uns dos outros.
- Escalabilidade: Gerencia e integra dinamicamente LLMs, permitindo que os sistemas de IA aumentem ou diminuam de escala com base na demanda sem degradação do desempenho.
- Integração: Suporta interoperabilidade com serviços externos, incluindo armazenamento de dados, registro, monitoramento e análises.
- Segurança e conformidade: Controle e monitoramento centralizados garantem a aderência aos padrões regulatórios, melhorando a segurança e a privacidade de dados confidenciais.
- Controle de versão e atualizações: Facilita as atualizações do modelo e o gerenciamento de versões sem interromper as operações.
- Automação de fluxo de trabalho: Automatiza processos complexos, como pré-processamento de dados, treinamento de modelo, inferência e pós-processamento, reduzindo a carga de trabalho do desenvolvedor.
Explore os KPIs de processo para entender como simplificá-los com orquestração de LLM.
A orquestração de LLM bem-sucedida em um ambiente de produção requer mais do que conectar modelos; exige práticas de engenharia disciplinadas para garantir confiabilidade, eficiência de custos e qualidade.
4 práticas recomendadas de orquestração de LLM
1-Comece com uma arquitetura sólida e modular
- Decomposição de tarefas: Defina claramente seu fluxo de trabalho e divida o problema em etapas pequenas, distintas e testáveis. Projete seu pipeline para que funções-chave (por exemplo, criação de prompts, acesso à memória, lógica avançada) sejam isoladas em seus próprios módulos.
- Design iterativo: Comece com o protótipo funcional mais simples (um “produto mínimo viável”) e adicione complexidade incrementalmente. Valide que cada etapa, desde a recuperação de dados até a saída final, funcione isoladamente antes de integrá-la a uma cadeia complexa.
2-Roteamento e seleção dinâmica de modelos
- Otimize para custo e velocidade: Evite usar o LLM mais caro e maior para cada tarefa. Implemente lógica no orquestrador para rotear consultas simples (como classificação ou sumarização) para modelos mais baratos e menores e reserve modelos de primeira linha para raciocínios complexos ou análises de múltiplas etapas.
- Agnosticismo de fornecedor: Estruture sua camada de orquestração para permitir a troca fácil entre provedores de modelos (por exemplo, OpenAI, Anthropic, Google) para mitigar o aprisionamento do fornecedor, gerenciar limites de taxa da API e capitalizar com os modelos de melhor desempenho conforme o mercado evolui.
3-Implemente observabilidade e monitoramento robustos
- Registre tudo: Registre as entradas e saídas de cada etapa na cadeia, não apenas o resultado final. Isso é crucial para depurar fluxos conversacionais de múltiplas etapas e realizar análise de causa raiz (RCA) em erros.
- Acompanhe métricas-chave: Monitore latência, vazão, consumo de tokens (para controle de custos) e taxas de erro do modelo em tempo real. Alertas automáticos devem ser configurados para sinalizar picos de alucinações ou falhas imediatamente.
4-Verifique as barreiras de governança e segurança
- Verificações de pré e pós-processamento: Envolva todas as chamadas de LLM com barreiras de proteção. Use verificações de pré-processamento (por exemplo, filtragem de conteúdo, lista negra de tópicos não permitidos) na entrada do usuário e verificações de pós-processamento (por exemplo, verificação do formato de saída estruturada, verificações de segurança) na resposta do modelo antes da entrega.
- Conformidade: Para dados confidenciais, implemente camadas de permissão, anonimização e criptografia no início do processo de design para manter a conformidade (por exemplo, HIPAA, GDPR).
4 desafios de orquestração de LLM e estratégias de mitigação
Aqui estão alguns problemas associados à orquestração de LLM e métodos para enfrentá-los:Desafios Centrais na Orquestração Multi-LLM
1.Coordenação e bloqueios de fluxo de trabalho
Devido à natureza não determinística do LLM, definir transferências claras entre funções especializadas de LLM é difícil. Isso resulta em sobreposição de tarefas (uso redundante de tokens) ou bloqueios de fluxo de trabalho (uma instância de LLM aguarda indefinidamente por uma saída ambígua de outra).
Mitigar com fluxo de trabalho estruturado e comunicação
- Use um controlador de fluxo de trabalho para decompor o objetivo em um Grafo Acíclico Dirigido (DAG) de subtarefas.
- Imponha um Protocolo de Comunicação Pydantic/JSON para todas as transferências de tarefas. Isso força o LLM a produzir dados legíveis por máquina e validados por esquema, tornando os sinais de progresso inequívocos e prevenindo ciclos.
2. Deriva contextual e inconsistência de memória
A janela de contexto fixa do LLM e sua falta de estado inerente o tornam propenso à deriva contextual, onde uma função de LLM esquece o objetivo geral ou fatos anteriores cruciais. Em uma configuração multi-LLM, isso cria decisões conflitantes e saídas gerais inconsistentes.
Mitigar usando base de conhecimento externalizada com RAG
- Implemente um sistema de memória externa (banco de dados vetorial ou grafo de conhecimento). Funções especializadas de LLM registram fatos, decisões e saídas principais como dados estruturados. Quando uma instância de LLM precisa de contexto, ela usa Geração Aumentada por Recuperação (RAG) para consultar essa fonte externa, garantindo que recupere as informações mais relevantes e não redundantes.
3. Saída não determinística e alucinação em cascata
A saída probabilística do LLM significa que as respostas não são confiáveis. Quando uma instância de LLM (o produtor) fabrica informações (alucina), uma instância de LLM downstream (o consumidor) as trata como fato, levando a uma falha completa em cascata do fluxo de trabalho multi-LLM.
Mitigar com mecanismos de consenso e validação
- Empregue um padrão de consenso para saídas críticas. O Controlador de Fluxo de Trabalho encaminha a saída inicial para uma função secundária de Validador LLM ou um Banco de Dados/API externo para verificação de fatos. O fluxo de trabalho prossegue se a saída for verificada com sucesso, mitigando efetivamente o risco de erros não determinísticos do modelo.
4. Contenção de recursos e estouro de custos
Dimensionar fluxos de trabalho multi-LLM cria alta demanda pela API de LLM (um recurso caro e limitado por taxa). Isso resulta em falhas de limite de taxa (limitação de API) e consumo massivo de tokens (estouro de custos) devido a trabalho redundante ou loops.
Mitigar com filas assíncronas e barreiras de orçamento
- Utilize uma fila de tarefas assíncrona (por exemplo, Celery) com um limitador de taxa para controlar a concorrência de execução de chamadas de API.
- Implemente ferramentas de observabilidade para rastrear o uso de tokens por tarefa e definir orçamentos automáticos de tokens (disjuntores) que terminam ou pausam qualquer instância de LLM descontrolada, gerenciando o custo operacional em tempo real.
A orquestração é um componente-chave do LLM?
Sim. A orquestração é um componente-chave em sistemas baseados em LLM, mas não é um componente central do modelo como os pesos do modelo ou o tokenizador. Em vez disso, é uma capacidade em nível de sistema que torna os LLMs utilizáveis em aplicações do mundo real.
Entre os componentes essenciais, a orquestração normalmente está ao lado de:
- Modelo de LLM: Um Modelo de Linguagem de Grande Escala (LLM) processa grandes quantidades de dados para entender e gerar texto semelhante ao humano. Modelos de código aberto oferecem flexibilidade, enquanto os de código fechado proporcionam facilidade de uso e suporte. LLMs de propósito geral lidam com várias tarefas, enquanto modelos específicos de domínio atendem a setores especializados.
- Prompts: Prompts eficazes orientam as respostas do LLM.
- Prompts zero-shot: Geram respostas sem exemplos anteriores.
- Prompts few-shot: Usam algumas amostras para refinar a precisão. Saiba mais sobre prompting de aprendizado few-shot e outros métodos de ajuste fino de LLM.
- Prompts de cadeia de pensamento: Incentivam o raciocínio lógico para melhores respostas.
- Banco de dados vetorial: Armazena dados estruturados como vetores numéricos. Os LLMs usam pesquisas de similaridade para recuperar contexto relevante, melhorando a precisão e prevenindo respostas desatualizadas.
- Agentes e ferramentas: Estendem as capacidades do LLM executando pesquisas na web, executando código ou consultando bancos de dados. Eles melhoram a automação impulsionada por IA e as soluções de negócios.
- Orquestrador (Camada de controle): Integra LLMs, prompts, bancos de dados vetoriais e agentes em um sistema coeso. Garante coordenação suave para aplicações eficientes baseadas em IA.
- Monitoramento: Acompanha o desempenho, detecta anomalias e registra interações. Garante respostas de alta qualidade e ajuda a mitigar erros nas saídas do LLM.
Leitura adicional
Fontes externas
Cite esta pesquisa
Escolha o formato adequado ao local onde você vai publicar. Colar a versão com link no seu CMS preserva o backlink.
@misc{simsek2026,
author = {Şimşek, Hazal},
title = {{LLM Orquestração: 22 Frameworks e Gateways}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/llm-orchestration}},
note = {AIMultiple. Acessado em 3 Junho 2026}
}



Seja o primeiro a comentar
Seu endereço de e-mail não será publicado. Todos os campos são obrigatórios. Os comentários são deixados em seu idioma original.