Top 10+ Frameworks e Ferramentas de Orquestração Agêntica
Comparamos quatro frameworks agênticos principais utilizando um fluxo de trabalho idêntico de planejamento de viagens com cinco agentes e configurações consistentes de LLM. Cada framework foi executado 100 vezes, e medimos a latência do pipeline, o uso de tokens, as transições entre agentes e o intervalo de execução agente-para-ferramenta para isolar a verdadeira sobrecarga de orquestração.
Benchmark de orquestração agêntica
Todos os frameworks concluíram a tarefa com êxito em 100 execuções cada. No entanto, o LangGraph terminou 2,2x mais rápido que o CrewAI, enquanto o LangChain e o AutoGen mostraram diferenças de 8 a 9x na eficiência de tokens. Isso reflete decisões arquiteturais fundamentais na forma como cada framework orquestra fluxos de trabalho multiagente a partir da camada de orquestração, como os frameworks encaminham mensagens, gerenciam estados e coordenam as transferências de agentes.
Para entender o porquê, medimos cada fase do ciclo de vida do agente.
Desempenho por agentes
Agente analisador (Parser): O agente realiza extração simples de texto com complexidade mínima. Todos os frameworks mostram latência semelhante.
Agente buscador de voos (Flight finder): Podemos ver diferenças significativas na latência e no uso de tokens. Este agente utiliza a ferramenta de API de voos, e observamos um notável "intervalo agente-para-ferramenta" — o tempo entre o início do agente e o momento em que ele realmente chama a ferramenta. Examinaremos esse intervalo em detalhes mais adiante na nossa análise, onde veremos que 5 segundos dos 9 segundos de latência do CrewAI vêm desse intervalo.
Agente meteorologista (Weather reporter): Vemos o mesmo padrão de classificação continuar tanto para a latência quanto para o uso de tokens, conforme observado no agente Buscador de Voos.
O LangChain gera significativamente mais tokens e maior latência em comparação com outros frameworks, exceto o CrewAI, cuja sobrecarga decorre principalmente do intervalo agente-para-ferramenta. Isso decorre da abordagem de gerenciamento de memória do LangChain, que mantém etapas intermediárias e o histórico completo da conversa, criando sobrecarga em fluxos de trabalho multiagente.
O LangGraph surge como o framework mais rápido com o menor número de tokens. Sua arquitetura baseada em grafos transmite apenas os deltas de estado necessários entre os nós, em vez de históricos completos de conversa, resultando em uso mínimo de tokens
e latência reduzida.
Agente de atividades (Activity Agent): A maioria dos frameworks demonstra desempenho relativamente próximo. Sem chamadas de ferramentas, todos os frameworks convergem para intervalos semelhantes (6-8 seg de latência, 650-744 tokens), sugerindo que a
variação é principalmente o tempo de geração do LLM com sobrecarga mínima de orquestração. No entanto, a verdadeira lacuna de desempenho surge no agente Planejador de Viagens.
Agente planejador de viagens (Travel planner): O agente recebe e sintetiza as saídas de todos os quatro agentes anteriores (analisador, buscador de voos, meteorologista e recomendador de atividades) em todos os frameworks. No entanto, a forma como cada framework
lida com essa agregação de contexto revela diferenças arquiteturais fundamentais.
O CrewAI transmite a saída completa e não modificada de cada tarefa anterior diretamente para o contexto do planejador através do seu sistema de parâmetros de contexto. O LLM recebe a totalidade dos tokens das saídas anteriores dos agentes mais a
descrição da tarefa em si. Essa abordagem não é uma limitação, mas uma filosofia central de design: o CrewAI prioriza a síntese abrangente e consciente do contexto, onde os agentes têm visibilidade completa do trabalho anterior. O
resultado é um itinerário detalhado de 5.339 tokens que integra completamente todas as informações disponíveis.
O LangChain, o AutoGen e o LangGraph lidam com o contexto de forma diferente. Embora todos os três frameworks transmitam as saídas anteriores dos agentes para o planejador, eles implementam várias estratégias de otimização que reduzem a carga cumulativa de contexto. O gerenciamento de memória do LangChain pode comprimir ou resumir as saídas intermediárias, e o framework pode não preservar a verbosidade completa da resposta de cada agente ao encadeá-los. Isso resulta na saída de 3.187 tokens — mais concisa que a do CrewAI, mas ainda substancial.
O AutoGen mostra comportamento semelhante com 3.316 tokens, sugerindo abordagens comparáveis de tratamento de contexto entre esses dois frameworks. O gerenciamento de estado baseado em grafos do LangGraph transmite apenas os deltas de estado
necessários entre os nós, resultando na saída mais eficiente de 2.589 tokens através de suas transições de estado otimizadas.
Intervalo agente-para-ferramenta
O Intervalo Agente-para-Ferramenta é o tempo entre o momento em que um agente recebe sua tarefa e o momento em que ele realmente invoca a ferramenta.
O intervalo de 5 segundos do CrewAI no Buscador de Voos representa tempo real de deliberação, enquanto outros frameworks mostram chamadas de ferramenta quase instantâneas.
A arquitetura do CrewAI incorpora uma filosofia de agente autônomo. Quando o agente Buscador de Voos recebe sua tarefa, ele não executa imediatamente a ferramenta get_flights. Em vez disso, segue um processo de raciocínio:
- Compreensão da tarefa: O agente analisa quais informações precisa para cumprir o objetivo
- Avaliação de opções: Ele considera as ferramentas disponíveis e determina qual é a mais apropriada
- Planejamento da abordagem: O agente decide os parâmetros e a estratégia de execução
- Tomada de ação: Finalmente, invoca a ferramenta com os parâmetros determinados. Esse intervalo de 5 segundos é o CrewAI literalmente "pensando" antes de agir, uma escolha de design que prioriza a qualidade da decisão e o raciocínio autônomo em detrimento da velocidade bruta. Ninguém diz ao agente "use esta ferramenta específica"; ele determina independentemente o melhor curso de ação.
O CrewAI não oferece uma opção para desativar a deliberação e mudar para chamada direta de ferramenta.
Em contraste, os frameworks LangGraph, LangChain e AutoGen utilizam abordagens de execução direta de ferramenta, alcançando intervalos de execução inferiores a milissegundos.
O LangChain e o LangGraph suportam agentes do estilo ReAct, que exibem raciocínio no padrão "pensamento → ação → observação". No entanto, o componente "Thought" (pensamento) no ReAct é puramente baseado em prompting textual. Por exemplo, o LLM pode gerar "Pensamento: Eu deveria...". Isso introduz alguma geração extra de tokens, mas não cria um ciclo de deliberação separado como o intervalo de 5 segundos do CrewAI. Essas etapas de "pensamento" são geradas dentro da mesma chamada do LLM, como parte de um único processo de geração.
Sobrecarga de orquestração agente-para-agente
Medimos a latência agente-para-agente calculando o tempo médio entre a conclusão de um agente e o início do agente seguinte ao longo de 100 execuções, mas as diferenças foram mínimas, em nível de milissegundos. Isso revela que a arquitetura do framework é mais importante para os padrões de execução de ferramentas e gerenciamento de contexto, não para as transferências entre agentes. As diferenças de desempenho entre os frameworks decorrem da deliberação da ferramenta e da síntese de contexto, não do tempo gasto na troca entre agentes.
O que é orquestração agêntica?
A orquestração agêntica coordena agentes de IA autônomos dentro de um sistema unificado para concluir tarefas complexas e tarefas estruturadas em vários sistemas e domínios.
A multiorquestração permite que vários agentes colaborem como uma equipe virtual, onde cada agente lida com uma função específica: alguns recolhem dados, outros analisam-nos e alguns executam decisões. A camada de orquestração garante que esses agentes se comuniquem, planejem tarefas e trabalhem em conjunto.
Ao contrário dos scripts de automação estáticos, a orquestração agêntica aproveita a IA generativa e modelos de IA para se adaptar ao contexto, minimizar a necessidade de intervenção humana e permitir execução contínua em diversos sistemas.
Orquestração agêntica vs. orquestração de LLM
Os termos são por vezes utilizados de forma intercambiável porque ambos envolvem a coordenação de sistemas de IA, mas diferem no foco:
- Orquestração de LLM é centrada no modelo, otimizando interações e fluxos de trabalho entre vários modelos de linguagem.
- Orquestração agêntica coordena agentes autônomos para resolver tarefas de várias etapas em todos os sistemas, com o mínimo de orientação humana.
Princípios fundamentais
- Autonomia: Os agentes podem agir de forma independente dentro das suas funções definidas, apoiados pela chamada de funções para sistemas externos.
- Colaboração: Vários agentes de IA comunicam para resolver problemas complexos, distribuir várias tarefas e alcançar automação de ponta a ponta.
- Alinhamento: Os sistemas mantêm objetivos consistentes e garantem a conformidade com os requisitos organizacionais e regulatórios em setores altamente regulamentados.
- Observabilidade: Registos, ferramentas de monitoramento e avaliações permitem monitoramento contínuo e otimização contínua.
- Supervisão humana: Abordagens com intervenção humana (human-in-the-loop) combinam automação com contribuição humana em contextos de alto risco ou ambíguos.
Padrões de orquestração
A orquestração agêntica pode ser categorizada em vários padrões com base na forma como os agentes são coordenados dentro de um sistema. Esses padrões determinam o fluxo de tarefas, a comunicação entre os agentes e a arquitetura geral do sistema.
Orquestração centralizada
Neste padrão, um único agente gestor ou roteador é responsável por atribuir tarefas, controlar o fluxo de trabalho e garantir que os objetivos sejam cumpridos. O gestor atua como um hub central, direcionando tarefas para agentes especializados com base em regras predefinidas ou num plano dinâmico.
Padrões específicos dentro desta categoria incluem:
- Orquestração sequencial: Um pipeline linear onde um gestor direciona tarefas através de uma sequência fixa e passo a passo de agentes. Isso é ideal para processos com dependências claras, como pipelines de processamento de dados.
- Orquestração hierárquica: Uma estrutura escalável e em camadas onde uma relação gestor-subordinado é utilizada para lidar com tarefas complexas em vários departamentos ou equipas.
Orquestração descentralizada
Este padrão elimina o ponto único de controle, permitindo que vários agentes interajam diretamente e concluam uma tarefa complexa. Esta abordagem aumenta a resiliência e oferece maior flexibilidade para a resolução colaborativa de problemas.
Padrões específicos dentro desta categoria incluem:
- Orquestração por chat em grupo: Os agentes colaboram através de um tópico de conversa partilhado, aproveitando as contribuições uns dos outros para chegar a uma decisão ou resolver um problema. Um gestor de chat pode facilitar a discussão, mas os agentes comunicam diretamente para alcançar um consenso.
- Orquestração por transferência (Handoff): Os agentes delegam tarefas dinamicamente uns aos outros sem a necessidade de um gestor central. Cada agente pode avaliar a tarefa e decidir lidar com ela ou transferi-la para outro agente com experiência mais apropriada, semelhante a um sistema de referência.
Orquestração federada
Este padrão é útil para ambientes altamente regulamentados ou distribuídos. Permite a colaboração entre diferentes silos organizacionais ou sistemas, mantendo a governança e a segurança dos dados. Frequentemente combina elementos de abordagens centralizadas e descentralizadas para gerir uma rede mais ampla de agentes e sistemas.
Ferramentas e frameworks
Vários frameworks de agentes de IA fornecem a infraestrutura para fluxos de trabalho agênticos e orquestração multiagente. Alguns deles incluem:
Aqui está uma lista completa dessas ferramentas em ordem alfabética:
- LangGraph da LangChain: Fornece design modular e fluxos de trabalho baseados em grafos para fluxos de trabalho complexos e tarefas estruturadas.
- MetaGPT da FoundationAgents: Codifica colaboração baseada em funções (por exemplo, engenheiro de software, QA) para coordenar vários agentes no desenvolvimento de software.
- AutoGen da Microsoft: Foca-se na colaboração conversacional entre agentes digitais, frequentemente configurados como ciclos planeador-executor-crítico.
- CrewAI: Organiza agentes especializados em "equipas" com objetivos específicos de função, útil para processos de negócio e operações de rotina.
- Agents SDK da OpenAI: Permite orquestração leve e transferências de agentes com chamada de funções para ferramentas externas.
- CAMEL-IA: Fornece sociedades modulares de agentes de IA autônomos com coordenadores para simulações em larga escala e processos complexos.
- Agent Development Kit da Google: Suporta orquestração multiagente com capacidades integradas de avaliação, depuração e implantação.
- Langroid: Implementa um estilo de modelo de ator para orquestração multiagente, enfatizando a modularidade e a delegação.
- BeeAI: Enfatiza a interoperabilidade através do protocolo de contexto de modelo e integração de agentes de terceiros para integração perfeita.
- Azure IA Foundation Agent Service: Permite a operação de agentes ao longo do desenvolvimento, implantação e produção, abstraindo a complexidade da infraestrutura.
Protocolos de comunicação de agentes
Frameworks de orquestração agêntica de código aberto como LangGraph, CrewAI e AutoGen implementam cada um as suas próprias convenções para comunicação de agentes. Isso cria desafios de interoperabilidade ao combinar agentes de diferentes frameworks dentro da mesma camada de orquestração. Dois protocolos emergentes visam colmatar esta lacuna.
Model Context Protocol (MCP) da Anthropic padroniza a forma como os agentes se conectam a ferramentas externas e fontes de dados. Em vez de cada framework implementar a sua própria camada de integração de ferramentas, o MCP fornece uma interface comum que as plataformas de orquestração podem aproveitar para uma comunicação consistente agente-para-ferramenta.
Protocolo Agent-to-Agent (A2A) da Google permite que agentes construídos em diferentes frameworks descubram as capacidades uns dos outros e troquem mensagens. O A2A foi concebido para complementar o MCP: enquanto o MCP lida com interações agente-para-ferramenta, o A2A foca-se na colaboração agente-para-agente. Os agentes anunciam as suas capacidades através de "Agent Cards", que são documentos de metadados JSON que descrevem identidade, endpoints e modalidades suportadas.
Por que os protocolos são importantes para a orquestração:
- Interoperabilidade: O A2A conquistou suporte de mais de 150 organizações, incluindo LangChain, Salesforce e SAP, permitindo que agentes de diferentes fornecedores trabalhem em conjunto
- Descoberta: Os agentes podem encontrar e compreender dinamicamente as capacidades uns dos outros em tempo de execução através de mecanismos padronizados
- Design complementar: Um sistema orquestrado pode utilizar A2A para comunicação entre agentes, enquanto cada agente utiliza internamente MCP para aceder às suas ferramentas
- Complexidade reduzida: Protocolos padronizados reduzem a necessidade de adaptadores personalizados ao misturar agentes de diferentes ecossistemas
Os frameworks que adotam A2A ou MCP podem integrar-se mais facilmente com agentes e ferramentas externos, reduzindo a dependência de fornecedor (vendor lock-in) e simplificando implantações multiframework.
Aplicações de orquestração agêntica
A orquestração agêntica é a capacidade crítica que transforma agentes individuais num sistema coeso e orientado a objetivos. A seguir estão aplicações do mundo real onde os sistemas multiagente se coordenam para entregar valor de negócio.
Processos de negócio
A orquestração agêntica permite automação de ponta a ponta em vários departamentos e sistemas. Coordena agentes especializados para lidar com fluxos de trabalho complexos e de várias etapas sem transferências manuais.
- Recursos humanos: Orquestra uma equipa de agentes para gerir todo o ciclo de vida do funcionário, desde a integração (onboarding) e perguntas e respostas sobre políticas até à gestão da força de trabalho e desligamento (offboarding).
- Integração de clientes (Customer onboarding):
- Operações de clientes: Sistemas orquestrados melhoram a qualidade do serviço gerindo as interações com clientes em vários canais, com um grupo de agentes a lidar com consultas iniciais, fornecendo informações de diferentes bases de dados e transferindo questões complexas para um humano no circuito (human-in-the-loop) para verificação.
Cadeia de suprimentos
A orquestração agêntica melhora a gestão da cadeia de suprimentos coordenando vários agentes especializados para gerir e otimizar uma rede complexa de planejamento, abastecimento, logística e gestão de inventário.
- Manutenção preditiva: Uma plataforma de orquestração coordena agentes para analisar dados de equipamentos em tempo real, prever falhas potenciais e acionar automaticamente um agente de manutenção para agendar uma reparação ou encomendar novas peças.
- Gestão de inventário: Os agentes são orquestrados para monitorizar os níveis de stock, reordenar automaticamente os suprimentos quando um limite é atingido e comunicar com agentes de logística para lidar com interrupções em tempo real, como atrasos no envio.
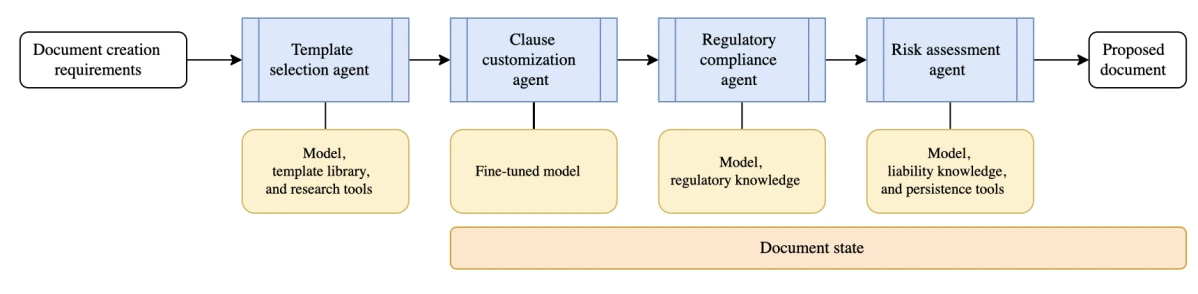
- Integração de fornecedores: Um sistema coordenado de agentes digitais lida com todo o processo, desde a execução de verificações de conformidade e geração de contratos até à integração de novos fornecedores nos fluxos de trabalho existentes da empresa.
Sistemas empresariais
A orquestração agêntica fornece a lógica central para processos orientados por IA que exigem colaboração contínua entre diferentes plataformas empresariais, como ERP, CRM e RPA.
- Compra-para-pagamento (Purchase-to-pay): Uma série de agentes orquestrados gere o ciclo completo de procurement, desde um agente de compras a fazer um pedido até um agente de contas a pagar a processar a fatura para pagamento, reduzindo os tempos de ciclo e aumentando a transparência.
- Pedido-para-recebimento (Order-to-cash): Um sistema multiagente acelera toda a jornada desde a receção do pedido até ao pagamento, coordenando agentes que lidam com o processamento de pedidos, a expedição e as contas a receber, melhorando o fluxo de caixa e a satisfação do cliente.
- Resolução de disputas: Um fluxo de trabalho orquestrado automatiza o acompanhamento de reclamações e contestações (chargebacks), fazendo com que um agente recolha informações, outro analise a disputa e um terceiro comunique a resolução, simplificando o processo e tornando-o mais rápido.
Explore como os agentes de IA são utilizados em sistemas empresariais, tais como:
Serviços Bancários e Financeiros
Neste setor, a orquestração é utilizada para fluxos de trabalho complexos e sensíveis ao risco que exigem a colaboração de vários agentes para garantir precisão e conformidade.
- Conformidade regulatória: Um sistema coordenado de agentes impõe a conformidade validando as informações dos clientes em relação a listas de vigilância, sinalizando discrepâncias e mantendo uma trilha de auditoria transparente de cada ação para revisão regulatória.
- Processamento de empréstimos e hipotecas: Um fluxo de trabalho orquestrado permite que um grupo de agentes lide com todo o processo de aprovação de empréstimos — desde a recolha e verificação de documentos até à aplicação de modelos financeiros e ao fornecimento de autorização final para revisão por um analista humano.
- Deteção e prevenção de fraudes: Este é um exemplo clássico de orquestração, onde um agente monitoriza transações, outro identifica e sinaliza atividades suspeitas, e um terceiro congela a conta e gera um relatório de incidente para uma equipa de segurança humana.
Veja como os agentes de IA e os LLMs agênticos são utilizados nas finanças:
Energia e serviços públicos
A orquestração agêntica permite a gestão de sistemas altamente distribuídos e complexos, como redes elétricas e gestão da força de trabalho, permitindo que agentes especializados comuniquem e atuem em tempo real.
- Gestão da rede elétrica: Um sistema multiagente com agentes distintos para estações de geração, centros de distribuição, medidores inteligentes individuais e soluções de redes inteligentes trabalha em conjunto para equilibrar a oferta e a procura de energia, otimizar a distribuição e prevenir interrupções.
- Medição-para-recebimento (Meter-to-cash): Um processo de medição-para-recebimento orquestrado pode automatizar todo o ciclo de faturação, coordenando agentes que lidam com a leitura automática de medidores, geração de faturas e cobrança de pagamentos para melhorar a precisão e a eficiência.
- Gestão da força de trabalho: Um sistema de orquestração otimiza a forma como os técnicos de campo são agendados e mobilizados, fazendo com que os agentes se coordenem para monitorizar a disponibilidade dos técnicos, atribuir tarefas com base na localização e competência e fornecer atualizações em tempo real sobre o progresso do trabalho.
Telecomunicações
Nas telecomunicações, a orquestração é utilizada para gerir e automatizar redes complexas de grande escala e operações voltadas para o cliente.
- Operações de rede: Um sistema coordenado de agentes monitoriza diferentes partes da rede para detetar automaticamente falhas, diagnosticar o problema e acionar uma série de ações para resolvê-lo, garantindo a fiabilidade da rede e minimizando o tempo de inatividade.
- Integração de clientes: A orquestração acelera o processo fazendo com que os agentes se coordenem para lidar com a ativação do SIM, configuração do dispositivo e ativação do serviço, proporcionando uma experiência de cliente perfeita do início ao fim.
- Faturação e gestão de receitas: Um fluxo de trabalho orquestrado automatiza ajustes de faturação complexos, pagamentos e reembolsos, fazendo com que agentes especializados gerenciem cada etapa, o que aumenta a precisão e a satisfação do cliente.
Benefícios
79% dos executivos têm adotado agentes de IA. No entanto, 19% das empresas enfrentam dificuldades com a coordenação.7 A orquestração agêntica ajuda a gerir agentes em diferentes aplicações. Aqui estão alguns benefícios da orquestração agêntica:
- Eficiência operacional: Simplifica as operações de rotina, reduz custos e melhora a escalabilidade.
- Agilidade operacional: Permite responder dinamicamente a dados e interrupções em tempo real.
- Colaboração perfeita: Garante a cooperação entre agentes, humanos e vários sistemas.
- Vantagens competitivas: Apoia a inovação, permitindo que os sistemas de IA operem ao lado da equipa humana.
- Satisfação melhorada: Impulsiona experiências superiores para o cliente e melhorias mensuráveis na qualidade do serviço.
Desafios
- Governança: Requer uma governança de dados robusta para prevenir riscos decorrentes da interação de vários agentes com diversos sistemas.
- Conformidade: Os sistemas devem garantir a conformidade em setores altamente regulamentados, especialmente nas finanças e na saúde.
- Supervisão humana: A implantação eficaz requer limites claros para a intervenção humana e escalonamento.
- A integração perfeita com fluxos de trabalho existentes e sistemas legados continua a ser uma barreira significativa. Esses sistemas mais antigos podem ser construídos em arquiteturas obsoletas que não são compatíveis com as tecnologias de IA modernas.
Metodologia do benchmark
Arquitetura do fluxo de trabalho
O nosso fluxo de trabalho sequencial de agentes processa pedidos de viagem através de cinco etapas:
- Agente analisador (Parser): Extrai dados estruturados de entrada em linguagem natural ("Quero viajar de Berlim para Roma em 25 de outubro de 2025. Ficarei 3 dias") para identificar origem, destino, datas e duração.
- Agente buscador de voos (Flight finder): Chama a API da Amadeus para recuperar voos disponíveis usando códigos IATA extraídos e datas de partida.
- Agente meteorologista (Weather reporter): Obtém previsões meteorológicas para o destino durante toda a estadia usando a WeatherAPI.
- Agente recomendador de atividades (Activity recommender): Combina atividades com as condições meteorológicas (museus para chuva, passeios ao ar livre para sol).
- Agente planejador de viagens (Travel planner): Sintetiza todas as saídas anteriores num itinerário abrangente dia a dia com
voos, previsões meteorológicas e atividades recomendadas.
Variáveis controladas
Para garantir uma comparação justa, mantivemos componentes idênticos em todos os frameworks:
Configuração do LLM:
- Modelo: Claude Haiku 4.5 via OpenRouter
- Temperatura: 0,1
- Sem limites máximos de tokens impostos a qualquer agente
Funções de ferramenta:
- Implementações Python idênticas de get_flights() e get_weather() em todos os frameworks
- Chamadas de API externas para Amadeus (voos) e WeatherAPI (meteorologia)
Parâmetros de teste
- Tamanho da amostra: 100 execuções por framework
- Modo de execução: Execução sequencial de agentes (sem processamento paralelo)
- Agregação de métricas: Valores médios em todas as execuções
Métricas medidas
- Latência do pipeline: Tempo total de execução de ponta a ponta, desde a entrada até ao itinerário final
- Transições agente-para-agente: Sobrecarga do framework entre transferências sequenciais de agentes
- Latência por agente: Tempo de execução individual para cada um dos cinco agentes
- Intervalo agente-para-ferramenta: Tempo decorrido desde a inicialização do agente até à primeira invocação da ferramenta
- Uso de tokens: Tokens de saída gerados.
Implementação da cronometragem: Toda a cronometragem foi capturada usando time.time() do Python com precisão de milissegundos. Para cada agente, registámos o tempo de início antes da execução e o tempo de fim após a conclusão, calculando a latência como a
diferença. Para a execução da ferramenta, medimos o tempo imediatamente antes de chamar a API e imediatamente após receber a resposta. As transições agente-para-agente capturaram o intervalo entre o momento em que um agente conclui e
o momento em que o framework inicia o agente seguinte; essa sobrecarga pura do framework exclui o tempo de execução do LLM e da ferramenta.
Contagem de tokens: Utilizámos uma abordagem de dupla fonte para precisão:
- Rastreamento integrado do framework (quando disponível):
- LangChain: cb.total_tokens dos callbacks
- LangGraph: Uso de tokens dos checkpoints de estado
- AutoGen: agent.get_total_usage() dos resultados do chat
- Estimação Tiktoken (alternativa para Claude via OpenRouter)
Dado que o Claude não expõe contagens de tokens via OpenRouter em todos os frameworks, usámos o tiktoken como uma aproximação consistente entre as implementações.
Infraestrutura de observabilidade: Todas as métricas validadas através de ferramentas de observabilidade:
- Laminar: Recolha de traces em tempo real, medições de latência e rastreamento de tokens.
- AgentOps: Rastreamento de execução de agentes, monitoramento de desempenho.
Essas plataformas forneceram validação de verdade fundamental (ground-truth) para a nossa instrumentação manual, garantindo a precisão
da medição em diferentes frameworks.
Resultados agregados como médias em 100 execuções.
Leitura adicional sobre orquestração agêntica
Descubra mais sobre IA Agêntica consultando:
Cite esta pesquisa
Escolha o formato adequado ao local onde você vai publicar. Colar a versão com link no seu CMS preserva o backlink.
@misc{simsek2026,
author = {Şimşek, Hazal},
title = {{Top 10+ Frameworks e Ferramentas de Orquestração Agêntica}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/agentic-orchestration}},
note = {AIMultiple. Acessado em 30 Junho 2026}
}


Seja o primeiro a comentar
Seu endereço de e-mail não será publicado. Todos os campos são obrigatórios. Os comentários são deixados em seu idioma original.