Principais Ferramentas de Reconhecimento de Imagem Comparadas
Comparamos as configurações padrão da API do Amazon Rekognition, Google Cloud Vision e Microsoft Azure IA Vision em 100 imagens de 5 classes de objetos, e comparamos seus preços e cobertura de recursos.
Resultados do benchmark das ferramentas de reconhecimento de imagem
Visão geral do desempenho em IoU=0.5
As métricas de desempenho de três plataformas de reconhecimento de imagem foram avaliadas em um limiar de Intersection over Union (IoU) de 0.5, comparando valores de mAP, pontuação F1, recall e precisão.
O mAP é a principal métrica de avaliação a ser considerada para tarefas de detecção de objetos, pois fornece uma medida abrangente da qualidade da detecção em diferentes limiares de confiança e classes de objetos.
Você pode ler mais sobre nossa metodologia de benchmark.
Precisão Média por Classe (AP) em IoU=0.5
Todos os três serviços detectam pessoas de forma confiável, mas perdem precisão em equipamentos de proteção, com os capacetes mostrando a queda mais acentuada.
Enquanto o Amazon e o Google mostram baixa precisão na detecção de luvas e chapéus, o Microsoft Azure IA Vision atinge 0% de precisão para ambas as categorias. O Azure IA Vision não detecta objetos pequenos (menos de 5% da imagem) ou dispostos muito próximos, o que pode contribuir para a baixa precisão observada na detecção de luvas e chapéus.1
Nenhum dos serviços consegue detectar máscaras com sucesso (0% de precisão), destacando uma lacuna crítica em suas capacidades de reconhecimento de objetos quando usados em configurações padrão sem rotulagem personalizada.
Você pode ler mais sobre as limitações do reconhecimento de imagem.
mAP em diferentes limiares de IoU [0.5:0.05:0.95]
À medida que os limiares de IoU se tornam mais rigorosos de 0.5 a 0.95, o mAP diminui para todos os três serviços, mas em taxas diferentes. O Amazon Rekognition se mantém melhor em toda a faixa, sugerindo um alinhamento de caixa delimitadora mais preciso do que os outros dois serviços.
Fatores potenciais que afetariam as diferenças de desempenho
Foco do treinamento do modelo e escopo do produto
- Amazon Rekognition inclui capacidades dedicadas relacionadas a EPI, o que provavelmente resulta em melhor cobertura de treinamento e representações de características para objetos como capacetes e luvas.
- Google Cloud Vision e o Azure IA Vision priorizam tarefas gerais de compreensão de imagem (por exemplo, OCR, pontos de referência, marcas, detecção na web), tornando os EPIs e objetos semelhantes secundários em seus objetivos de treinamento.
Configuração padrão da API e compensações entre precisão e recall
- Todos os serviços foram avaliados usando configurações padrão, que normalmente priorizam alta precisão para minimizar falsos positivos.
- Essa escolha de design leva a altas pontuações de precisão entre os provedores, mas a um recall significativamente menor, particularmente para objetos menos proeminentes.
Limitações na detecção de objetos pequenos
- Objetos como luvas, chapéus e capacetes geralmente ocupam uma pequena fração da imagem, tornando-os difíceis de detectar com confiabilidade.
- O Azure IA Vision, que está documentado para ter desempenho inferior em objetos pequenos ou muito próximos, mostra a degradação mais acentuada nessas categorias.
Taxonomia de rótulos e mapeamento de avaliação
- Os rótulos específicos do provedor tiveram que ser mapeados para uma taxonomia unificada de verdade terrestre.
- Detecções válidas usando rótulos não correspondentes ou mais granulares podem ter sido excluídas da avaliação.
Ausência de detecção de máscaras
- Nenhum dos serviços avaliados expõe rótulos de objetos relacionados a máscaras em suas APIs padrão.
- Todos os três, portanto, retornaram 0% de precisão para máscaras.
Sensibilidade ao IoU e qualidade da localização
- As diferenças de desempenho aumentam em limiares de IoU mais altos, onde é necessário um alinhamento mais rigoroso da caixa delimitadora.
- O Amazon Rekognition mantém um mAP relativamente mais alto nesses limiares, sugerindo uma precisão de localização mais forte.
Metodologia do benchmark das ferramentas de reconhecimento de imagem
Testamos o desempenho desses provedores fora da caixa (ou seja, sem rotulagem personalizada) em casos da vida real.
Usamos 100 imagens. Redimensionamos as imagens para 512×512 pixels, preservando as regiões essenciais contendo instâncias, já que o conjunto de dados original possuía dimensões variadas.
Queremos executar este teste novamente sem que os fornecedores treinem suas soluções no conjunto de dados. Portanto, não estamos divulgando o conjunto de dados que usamos para este benchmark.
Processamos as respostas das APIs dos provedores de serviço da seguinte maneira:
- mapeamos os rótulos dos provedores de serviço para as categorias de referência definidas na tabela acima. Os rótulos dos provedores de serviço que não corresponderam a esses rótulos de referência foram excluídos da avaliação.
- normalizamos os formatos de caixa delimitadora de diferentes provedores
- calculamos a IoU entre as caixas previstas e de referência
- combinamos as previsões com a referência com base no limiar de IoU
- calculamos as métricas: precisão, recall, F1 e AP por categoria
- calculamos o mAP no estilo COCO usando limiares 0.5-0.95
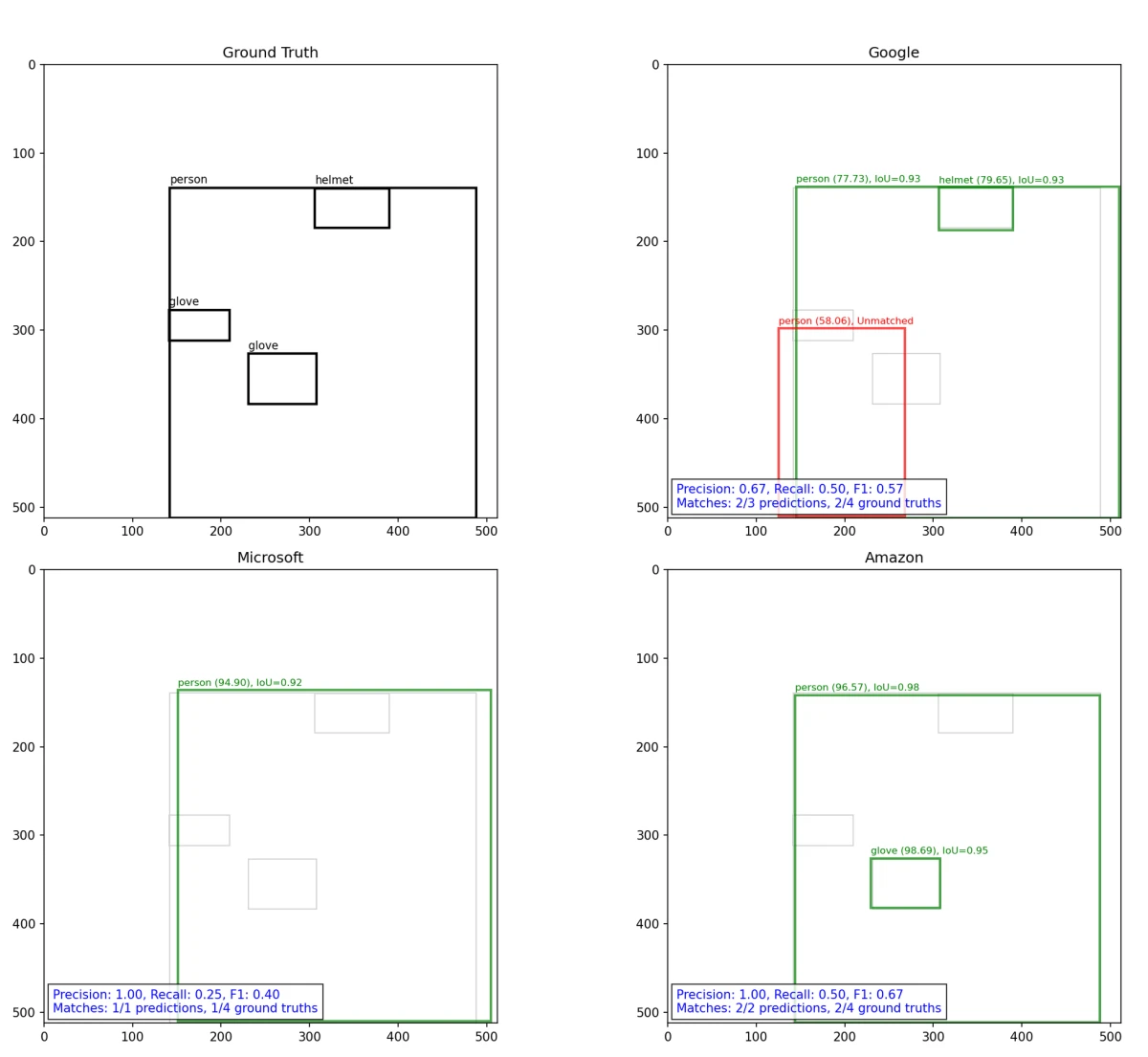
Um exemplo de cálculo de IoU, precisão, recall e F1 é dado na figura abaixo:
Métricas de benchmarking
Precisão
A precisão mede a exatidão das previsões positivas feitas pelo modelo. No reconhecimento de imagem, para uma determinada classe (por exemplo, “pessoa”), ela responde à pergunta: “De todas as imagens que o modelo rotulou como contendo uma pessoa, quantas realmente contêm?”. Isso é crucial em cenários onde falsos positivos (rotular incorretamente uma imagem como positiva) são custosos.
Recall
O recall mede a completude das previsões positivas, respondendo: “De todas as imagens que realmente contêm a classe, quantas o modelo identificou corretamente?” Isso é vital quando perder uma instância positiva (falso negativo) é crítico.
Pontuação F1
A pontuação F1 é a média harmônica da precisão e do recall, fornecendo uma medida equilibrada que é especialmente útil quando há uma distribuição desigual de classes (por exemplo, poucas imagens de capacete em comparação com imagens sem capacete). É uma única métrica que captura tanto falsos positivos quanto falsos negativos.
mAP
mAP, ou precisão média, é uma métrica usada principalmente em tarefas de detecção de objetos no reconhecimento de imagem. Ela avalia a precisão do modelo em diferentes classes, calculando a média da Precisão Média (AP) de cada classe. A AP em si é a área sob a curva de precisão-recall, que é gerada variando o limiar de confiança para as detecções.
Esta ferramenta interativa permite comparar os resultados de detecção entre provedores usando imagens de exemplo do conjunto de dados. Use os botões superiores para selecionar Amazon, Google, Microsoft ou todos os provedores. Ative/desative a referência com a caixa de seleção. Navegue entre as imagens de teste usando os botões numerados à esquerda. Caixas codificadas por cores mostram cada detecção com pontuações de confiança.
Melhores APIs de Reconhecimento de Imagem
Amazon Rekognition
Amazon Rekognition inclui APIs dedicadas à detecção de EPI, juntamente com detecção geral de objetos e rostos, o que lhe confere uma cobertura de rótulos mais ampla em classes como capacetes e luvas do que os outros dois serviços. Este escopo de produto é consistente com os resultados de AP por classe no benchmark.
Suas APIs de imagem são divididas em dois grupos:
- Grupo 1 (identificação facial): CompareFaces, IndexFaces, SearchFaces, usados para verificação de identidade e busca facial em coleções de imagens.
- Grupo 2 (análise de conteúdo): DetectLabels (detecção geral de objetos), DetectModerationLabels, DetectText, RecognizeCelebrities, DetectPPE.
Ele se integra com o restante da AWS (S3 para armazenamento, Lambda para processamento orientado a eventos, SageMaker para treinamento de modelo personalizado).
Google Cloud Vision
Google Cloud Vision excedeu 89% de precisão em IoU=0.5, o mesmo piso de precisão que os outros dois serviços, mas produziu recall mais baixo em objetos pequenos e equipamentos de proteção. Seu escopo de produto tende mais para a compreensão geral de imagem do que para a detecção industrial: OCR, reconhecimento de pontos de referência, identificação de logotipos e marcas, e Detecção na Web (correspondência de uma imagem com imagens indexadas publicamente).
Principais capacidades:
- Localização de objetos e detecção de rótulos
- OCR para texto impresso e manuscrito em vários idiomas
- Detecção de pontos de referência, logotipos e celebridades
- Detecção na Web para pesquisa reversa de imagem
- Treinamento de modelo personalizado via Vertex IA
Ele se integra ao Cloud Storage, BigQuery e Google Workspace, e aceita uma gama mais ampla de formatos de arquivo do que o Rekognition (JPEG, PNG, GIF, BMP, WEBP, RAW, ICO, PDF, TIFF).
Microsoft Azure IA Vision
Microsoft Azure IA Vision fornece análise de imagem, OCR, legendagem de imagem e um serviço separado de remoção de fundo. Sua documentação observa que o detector de objetos não lida de forma confiável com objetos pequenos ou muito próximos, portanto, ele se posiciona mais para compreensão geral de imagem e leitura de texto do que para detecção refinada de objetos.
As principais capacidades são divididas em dois grupos:
- Grupo 1 (detecção de elementos visuais): marcação, rosto, detecção de objetos, detecção de marcas e pontos de referência, corte inteligente, OCR.
- Grupo 2 (saída sensível ao idioma): descrição de imagem, legendas densas, leitura completa (OCR de documentos).
Recursos diferenciadores dos provedores de serviço
Visão geral de preços da API
Construindo modelos de visão personalizados
As APIs hospedadas, como Amazon Rekognition, Google Cloud Vision e Microsoft Azure IA Vision retornam previsões de um conjunto fixo de rótulos definido pelo provedor. Quando uma classe de objeto necessária está ausente desse conjunto, ou quando a precisão em um domínio específico é muito baixa, a alternativa é treinar um modelo personalizado. O Roboflow é um exemplo que cobre esse fluxo de trabalho.
Roboflow
Roboflow é uma plataforma de visão computacional que abrange anotação de dados, treinamento de modelo e implantação. Ele funciona em um modelo diferente das APIs de detecção hospedadas acima: os usuários treinam modelos em seus próprios conjuntos de dados rotulados e executam inferência em seu próprio hardware, em vez de chamar um endpoint gerenciado. Esse é o caminho que as equipes tomam quando as APIs de nuvem padrão não expõem rótulos para uma classe de objeto específica, como as máscaras que retornaram 0% de precisão em todos os três serviços avaliados.
Roboflow inclui três componentes principais:
- RF-DETR: um modelo baseado em transformer em tempo real para detecção e segmentação de objetos, destinado a entradas de câmera e vídeo ao vivo.2
- AutoDistill: uma ferramenta que usa grandes modelos fundamentais para rotular automaticamente conjuntos de dados de imagem sem anotação manual.3
- Inference: um pacote de implantação que suporta vários backends (ONNX, TensorRT, PyTorch), com execução em GPUs, CPUs ou dispositivos de borda, como NVIDIA Jetson, por meio de um serviço Dockerizado.4
Computação de borda no reconhecimento de imagem
O reconhecimento de imagem baseado em nuvem envia cada quadro para um data center remoto para análise. A computação de borda executa o model no dispositivo que capturou o quadro, de modo que o resultado (um rótulo, um alerta, um sinalizador) sai do dispositivo.
Como funciona a computação de borda
Em uma configuração de nuvem, as câmeras atuam como coletoras de dados e transmitem quadros brutos para o upstream; o modelo reside no data center. Em uma configuração de borda, o dispositivo executa a rede neural localmente e transmite a saída relevante: “pessoa detectada”, “estoque baixo”, “defeito encontrado”.
Por que isso é importante para o reconhecimento de imagem
- Latência: a inferência local elimina a ida e volta na nuvem, o que é importante para veículos autônomos, robôs de manufatura e qualquer sistema que precise agir sobre a previsão em milissegundos.
- Privacidade: as imagens não saem do dispositivo, o que é útil onde residência de dados ou restrições do GDPR se aplicam (imagens médicas, CFTV em lojas).
- Largura de banda e custo: os metadados são enviados, não o vídeo completo, o que reduz os custos de rede e de uso de API na nuvem para implantações de alto volume.
- Operação offline: os dispositivos de borda continuam funcionando quando a rede falha, o que é necessário para sistemas de segurança e instalações industriais remotas.
Exemplos do mundo real de IA de borda no reconhecimento de imagem
Captur on-device SDK
O processamento no dispositivo é a forma mais comum de IA de borda em contextos móveis. A Captur fornece um SDK de verificação de imagem no dispositivo que executa modelos de visão computacional localmente em dispositivos móveis em ~30ms, mesmo offline.5 A provedora de logística GoBolt integrou o SDK da Captur em seu aplicativo de motorista para verificação de comprovante de entrega e relatou uma queda de 30% nas reclamações de não recebimento de entrega na primeira semana.6
Ultralytics YOLO26
O YOLO26 da Ultralytics é um modelo de visão computacional de código aberto projetado para dispositivos de borda e de baixo consumo. Sua arquitetura totalmente ponta a ponta, NMS-gratuito, remove etapas de pós-processamento, como a supressão não máxima, reduzindo a latência e melhorando a exportabilidade para hardware de borda, ao mesmo tempo que suporta detecção de objetos, segmentação, classificação e estimativa de pose em uma única família de modelos.7
Transformers de visão no reconhecimento de imagem
As APIs de reconhecimento de imagem avaliadas aqui usam detectores baseados em CNN. Os Vision Transformers (ViTs) são uma arquitetura alternativa que divide a imagem em patches de tamanho fixo (tipicamente 16×16 pixels) e processa todos os patches em paralelo, o que permite que o modelo relacione regiões distantes da imagem desde a primeira camada, em vez de construir esse contexto gradualmente por meio de convoluções empilhadas.
Para detecção de objetos, isso é importante quando a identidade de um objeto depende da cena ao redor (um chapéu em uma pessoa versus um chapéu em uma prateleira). As CNNs capturam isso por meio de convoluções empilhadas; os ViTs capturam por meio da atenção em todos os patches de uma vez.
Os três serviços de nuvem neste benchmark executam modelos baseados em CNN em produção. Arquiteturas híbridas CNN-Transformer estão aparecendo em modelos de código aberto mais recentes (por exemplo, o RF-DETR do Roboflow usa um backbone transformer DINOv2), mas as APIs de nuvem em produção ainda não migraram.
Modelos de transformer de visão para reconhecimento de imagem
- Google ViT: o Vision Transformer original, treinado no ImageNet para classificação de imagens. Disponível no Hugging Face com pesos pré-treinados.
- Swin Transformer: usa um mecanismo de janela deslocada para capturar detalhes globais e locais, usado para detecção e segmentação.
- DINOv2 (Meta): modelo auto-supervisionado treinado sem rótulos manuais, produzindo embeddings de imagem de propósito geral.
- Segment Anything Model (SAM): segmentador baseado em ViT que pode isolar objetos nos quais não foi treinado.
Casos de uso do software de reconhecimento de imagem
No cenário digital atual, a visão computacional e as tecnologias de processamento de imagem transformaram a forma como as empresas aproveitam os dados visuais. Algoritmos avançados de classificação de imagem permitem ferramentas sofisticadas de reconhecimento de imagem que estão remodelando as operações em todos os setores.
Essas tecnologias de reconhecimento de imagem combinam abordagens poderosas de treinamento de modelo com interfaces intuitivas que permitem aos usuários automatizar tarefas visuais complexas. De soluções de visão personalizadas para necessidades comerciais específicas a sistemas de reconhecimento facial para segurança, essas ferramentas podem identificar padrões, objetos e características nas imagens.
Inspeção visual
O reconhecimento de imagem permite a inspeção visual automatizada em vários setores. Esses sistemas identificam objetos, detectam características e verificam a compatibilidade analisando dados visuais.
Por exemplo, o Chamberlain Group implementou o Amazon Rekognition em seu aplicativo myQ, permitindo que os usuários capturem automaticamente imagens do abridor de porta de garagem para verificar a compatibilidade. Essa solução simplificada substituiu um processo manual complexo e aumentou significativamente as taxas de conexão dos usuários.8
Processamento de documentos
A tecnologia de OCR extrai texto de imagens e documentos, automatizando a entrada de dados em vários idiomas. Sistemas modernos podem processar texto manuscrito e layouts complexos, transformando fluxos de trabalho baseados em papel e tornando os documentos pesquisáveis.
Por exemplo, o grupo segurador francês LSA Courtage usa a Google Cloud Vision API para reconhecer texto de carteiras de motorista e documentos de registro. Essa implementação de OCR reduziu o tempo de processamento de documentos em 45% por página e aumentou a produtividade dos subscritores em 20%, permitindo-lhes processar 1,500 documentos diariamente.9
Você pode conferir nosso OCR benchmark para ver a precisão das várias ferramentas de OCR para diferentes tipos de documentos.
Monitoramento agrícola
Os agricultores utilizam imagens de drones com reconhecimento de imagem para monitorar a saúde das culturas, detectar doenças e otimizar a irrigação. Ao identificar áreas de estresse nas culturas antes que os sintomas visíveis apareçam, os agricultores podem intervir precocemente e reduzir o uso de recursos.
Por exemplo, o Project FarmBeats da Microsoft (agora Azure Data Manager for Agriculture) usa sensores, drones e aprendizado de máquina para permitir a agricultura orientada por dados em ambientes com energia e conectividade de internet limitadas. O sistema ajuda a aumentar a produtividade agrícola e reduzir custos combinando dados visuais com o conhecimento dos agricultores sobre suas terras.10
Segurança e vigilância
Os sistemas de segurança usam reconhecimento facial e detecção de objetos para identificar atividades, controlar o acesso e localizar pessoas. Esses sistemas monitoram feeds de vídeo e alertam o pessoal sobre ameaças. Por exemplo, a Sun Finance usa o Amazon Rekognition para verificar a identidade do cliente comparando selfies com documentos de identidade, agilizando a verificação e prevenindo fraudes, ao mesmo tempo que expande a inclusão financeira.11
Moderação de conteúdo
As plataformas de mídia social usam reconhecimento de imagem para filtrar conteúdo inadequado, como nudez, violência ou imagens gráficas, de uploads de usuários. A geração de legendas pode adicionar uma segunda camada descrevendo o contexto da imagem que os classificadores em nível de pixel não detectam, por exemplo, detectando símbolos de ódio no fundo de uma foto aparentemente inofensiva. De acordo com a AWS, a filtragem por máquina normalmente reduz o volume que os moderadores humanos precisam revisar para 1–5% do total.12
Por exemplo, o CoStar Group usa o Amazon Rekognition para moderação de conteúdo e análise de vídeo de aproximadamente 150,000 uploads diários de imagens e vídeos em sua plataforma de imóveis comerciais. Essa solução de moderação de conteúdo escaneia imagens, classifica o conteúdo, detecta material indesejado e aproveita a tecnologia de legendagem de imagem para entender o contexto, economizando tempo e garantindo conformidade e dados de alta qualidade.13
Você pode ler mais sobre as aplicações do reconhecimento de imagem.
Limitações da tecnologia de reconhecimento de imagem
Redução de detalhes em objetos pequenos
Quando os objetos aparecem pequenos nas imagens, eles contêm menos pixels, resultando em dados visuais limitados. Além disso, as CNNs tendem a perder detalhes finos importantes durante o processamento através de camadas de redução de resolução, o que dificulta significativamente as capacidades de detecção.
Detecções perdidas
Os sistemas de reconhecimento de imagem normalmente favorecem objetos maiores durante as fases de treinamento e análise, resultando em frequências mais altas de objetos pequenos perdidos ou falsos negativos.
Interferência de fundo
Objetos menores são mais vulneráveis a serem obscurecidos por ruído visual, desordem de fundo ou elementos sobrepostos, tornando-os mais difíceis de identificar com precisão. Mesmo a oclusão parcial pode afetar desproporcionalmente objetos pequenos, pois eles têm menos área distinguível para começar.
Variabilidade de escala
Objetos que aparecem em diferentes distâncias ou escalas representam dificuldades para modelos não projetados especificamente para detectar detalhes finos em tamanhos variados de objetos.
Demandas computacionais
Técnicas para melhorar a detecção de objetos pequenos, como extração de características em múltiplas escalas ou entradas de resolução mais alta, exigem mais poder de processamento, limitando a aplicabilidade em tempo real.
Treinamento viés
Os conjuntos de dados muitas vezes sub-representam objetos pequenos ou carecem de anotações suficientes para eles, reduzindo a generalização do modelo para esses casos em cenários do mundo real.
Perguntas frequentes
O software de reconhecimento de imagem é um tipo de tecnologia de visão computacional que usa algoritmos de aprendizado de máquina para analisar dados não estruturados, como imagens digitais e dados de vídeo. Ele vai além da identificação de objetos específicos; sistemas avançados visam a compreensão da cena, interpretando o contexto e as relações dentro de uma imagem para fornecer uma análise mais completa. Isso permite que os computadores vejam e classifiquem informações visuais de forma eficaz.
Nenhum software único de reconhecimento de imagem ou software de visão computacional é universalmente o melhor. A escolha ideal entre as tecnologias de reconhecimento de imagem depende de suas necessidades específicas. Considere fatores como precisão necessária, o tipo de tarefas que você precisa realizar (como detecção de objetos ou OCR, e até mesmo considerar se você precisa integrar com processamento de linguagem natural para tarefas que combinam compreensão de imagem com análise de texto), facilidade de uso, escalabilidade, orçamento, opções de personalização e a experiência técnica de sua equipe. Experimentar diferentes opções é a melhor maneira de encontrar as tecnologias de reconhecimento de imagem que melhor fornecem os recursos de visão computacional de que você precisa para sua aplicação.
Embora o reconhecimento de imagem tenha melhorado significativamente, a precisão não é garantida. Os fatores que impactam o desempenho incluem a qualidade da imagem (iluminação, resolução), a complexidade da cena, variações na aparência dos objetos e a qualidade dos dados de treinamento usados para os algoritmos de aprendizado profundo. Alcançar uma compreensão robusta da cena e detectar com precisão objetos específicos pode ser desafiador em dados visuais complexos ou ruidosos.
Cite este benchmark
Escolha o formato adequado ao local onde você vai publicar. Colar a versão com link no seu CMS preserva o backlink.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{Principais Ferramentas de Reconhecimento de Imagem Comparadas}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/image-recognition-software}},
note = {AIMultiple. Acessado em 17 Junho 2026}
}
Seja o primeiro a comentar
Seu endereço de e-mail não será publicado. Todos os campos são obrigatórios. Os comentários são deixados em seu idioma original.