Melhores 50+ Agentes de IA de Código Aberto Listados
Todos têm construído agentes de IA, então após testes práticos com agentes de codificação de IA populares, construtores de agentes de IA e benchmarks de uso de ferramentas para avaliar suas capacidades no mundo real, reunimos uma lista curada dos melhores 50+ agentes de IA de código aberto. Clique nos cabeçalhos das categorias para ir diretamente para nossas principais escolhas:
Desenvolvimento e infraestrutura de agentes
- Frameworks de agentes (Construa o seu próprio)
- Ferramentas de automação e orquestração de fluxos de trabalho
Aplicações de agentes específicas de domínio
- Agentes de automação e navegação web
- Ferramentas de codificação e desenvolvimento
- Ferramentas de cibersegurança
- Criadores de conteúdo de vídeo com IA
- Assistentes financeiros
- Assistentes de saúde
- Agentes de pesquisa
- Assistentes de análise de dados
- Assistentes pessoais
Como pensar sobre agentes de IA?
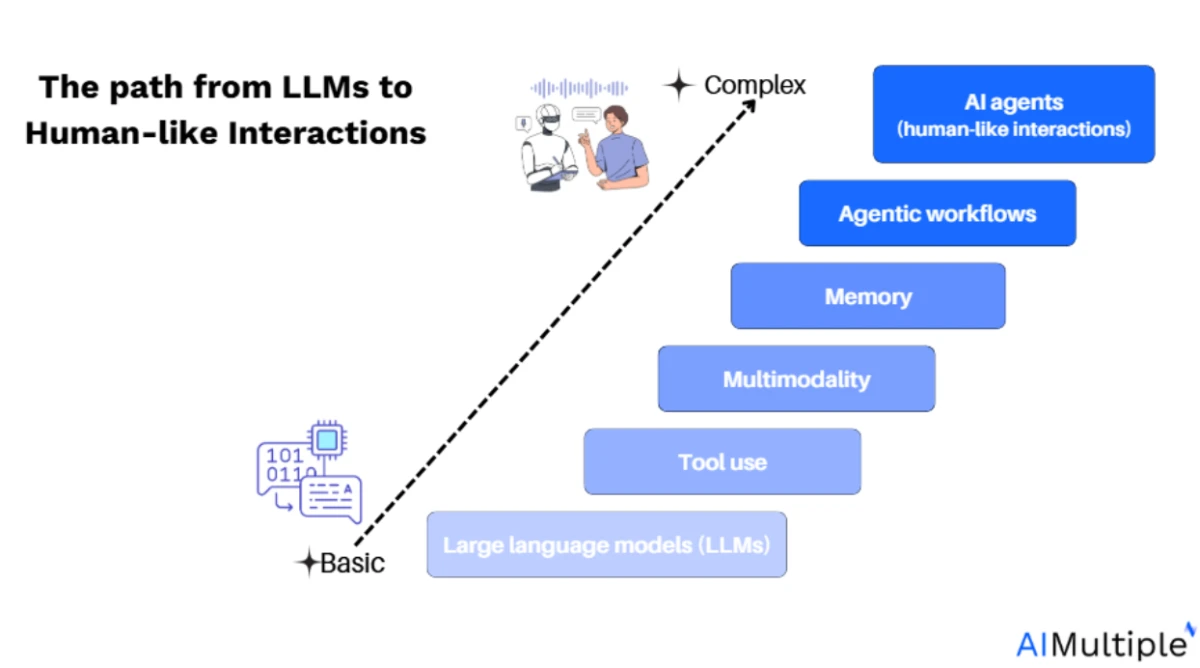
Um agente de IA é um sistema componível que combina planejamento, memória, uso de ferramentas e execução iterativa. Ele forma um ciclo estruturado em torno de um LLM que pode tomar decisões, realizar ações e adaptar-se a novas informações.
Aqui está como pensar sobre eles:
- Autonomia e fluxos de trabalho: Os agentes de IA variam desde a automação básica de tarefas com base em fluxos de trabalho predefinidos até sistemas totalmente autónomos capazes de decomposição de objetivos, uso de memória e interação com ferramentas. O principal desafio técnico reside em manter o contexto ao longo das etapas e coordenar operações em várias fases.
- Contexto e controlo: O verdadeiro desafio nos agentes de IA é garantir que o LLM tenha o contexto apropriado em cada etapa. Isso inclui gerir o conteúdo fornecido ao LLM e garantir que o agente execute tarefas relevantes com base no contexto atualizado.
- Integração de ferramentas: Construir agentes eficazes requer integração perfeita com ferramentas externas, APIs e fontes de dados. Frameworks como LangChain podem ajudar a integrar esses recursos externos, mas o controlo sobre o fluxo de trabalho é essencial para adaptar o comportamento do agente a novas entradas.
- Benefícios dos frameworks de agentes: Todos os sistemas agênticos, sejam fluxos de trabalho simples ou agentes autónomos complexos, podem beneficiar das funcionalidades principais fornecidas pelos frameworks agênticos. Estas funcionalidades podem ser construídas de raiz ou aproveitadas a partir de uma plataforma de código aberto existente, dependendo das suas necessidades.
Novos padrões
- Model Context Protocol (MCP): O padrão da indústria para como os agentes comunicam com fontes de dados externas. O LangGraph integra MCP para permitir que os agentes se liguem e funcionem com bases de dados e ferramentas locais sem necessidade de wrappers personalizados.
- Stripe Agentic Commerce Protocol (ACP): Este é o primeiro padrão da indústria em produção que permite aos agentes de IA lidar com pagamentos, inventário e envio de forma segura. Permite o "Agentic Checkout", onde o agente pode concluir uma compra para o utilizador dentro de uma interface de chat.
O que é exatamente um agente de IA?
Não existe uma definição consensual sobre o que constitui um "agente de IA".
- A IA tradicional define agentes como sistemas que interagem com o seu ambiente.
- O inquérito de Simon Willison a profissionais apresenta uma variedade de definições de trabalho de participantes da indústria.2
- A definição da Anthropic delineia princípios de design para construir agentes de IA eficazes e alinhados.3
- As principais empresas de consultoria enfatizam o papel dos agentes na automatização de fluxos de trabalho empresariais e na tomada de decisões.4 .
Muitas dessas definições incluem explicitamente fluxos de trabalho e autonomia de colocação no final de um espectro.
Concordamos com estes pontos de vista, portanto, não fornecemos uma definição rigorosa. Em vez disso, listamos os fatores que fazem com que um sistema de IA seja considerado mais agêntico:
- Ambiente e objetivos:
- Sistemas de IA em ambientes complexos, como aqueles com múltiplas tarefas e mudanças inesperadas, são agênticos.
- Sistemas de IA que seguem objetivos sem serem instruídos são agênticos.
- Interface de utilizador e supervisão: Sistemas de IA que podem aprender línguas naturais e sistemas que precisam de menos supervisão do utilizador são agênticos.
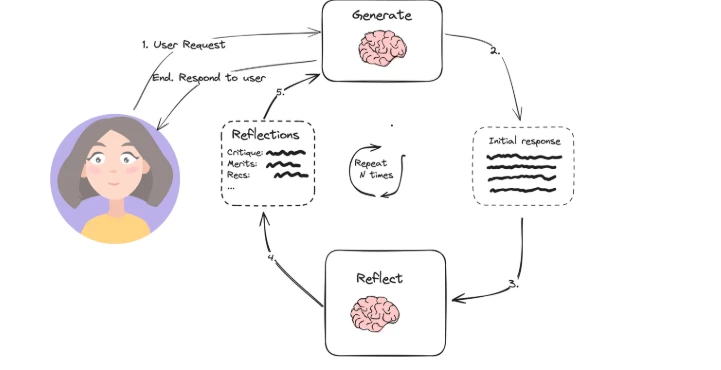
- Design do sistema: Sistemas que usam padrões de design como uso de ferramentas (por exemplo, pesquisa na web, programação) ou planeamento (por exemplo, reflexão, decomposição de sub-objetivos) são agênticos.
Para uma explicação mais detalhada, listámos anteriormente estes fatores e discutimos como eles definem sistemas de IA agênticos.
Estes agentes são totalmente autónomos?
Ainda não. A maioria dos agentes de IA de código aberto melhora a autonomia dos LLM ao permitir o uso de ferramentas, a tomada de decisões e a resolução de problemas, mas ainda requerem entradas estruturadas e um humano no circuito.
Exemplos como Devon e PR-Agent seguem lógica predefinida ou fluxos de trabalho de RL em vez de demonstrarem comportamento agêntico completo. Outros agentes de IA ainda carecem de capacidades (Aprendizagem Autónoma + Generalização).
Quando (e quando não) usar agentes de IA
Nem toda aplicação de LLM requer complexidade agêntica. Muitos casos de uso são melhor servidos por geração aumentada por recuperação (RAG) leve.
Os sistemas agênticos introduzem sobrecarga arquitetural: gestão de memória, orquestração de ferramentas, tratamento de erros e ciclos de controlo que aumentam a latência e o custo. Por exemplo, nos nossos benchmarks, observámos que as taxas de sucesso dos agentes de IA diminuíram após 35 minutos de interação humana.
Para mitigar estes riscos, é essencial testar sistemas agênticos em ambientes controlados e implementar barreiras de segurança robustas antes da implementação.
Os agentes são mais valiosos quando as etapas não podem ser facilmente previstas ou codificadas. São particularmente adequados para situações em que:
- As tarefas são dinâmicas e multi-etapa, com lógica ramificada ou sub-objetivos pouco claros.
- O uso de ferramentas é condicional ou adaptativo, exigindo que o sistema escolha qual ferramenta invocar com base na entrada ou no estado anterior.
- É necessária memória de longo prazo ou contexto, entre sessões ou fases de execução.
- A execução deve responder ao feedback do ambiente, como resultados de API, saídas de pesquisa ou ações falhadas.
- É necessária colaboração com humanos no circuito, onde a autonomia e a supervisão devem ser combinadas (por exemplo, copilotos de IA).
Por outro lado, fluxos de trabalho ou chamadas LLM sem estado são preferíveis quando:
- A lógica da tarefa é estática ou previsível, como preenchimento de formulários ou transformação de conteúdo.
- A baixa latência é crítica, como em interações voltadas para o utilizador.
- Minimizar o custo é essencial, especialmente evitando chamadas recursivas a LLM e orquestração complexa.
Ler mais
Aqui estão os nossos benchmarks mais recentes sobre infraestrutura comumente usada por sistemas agênticos:
- Navegadores remotos: Como a infraestrutura de navegadores permite que os agentes interajam com a web de forma segura.
- Benchmark de MCP de navegador: Principais servidores MCP para uso de ferramentas e acesso à web.
Exemplos de agentes de IA de código aberto
Algumas ferramentas descritas como "agentes de IA" não são assim tão agênticas; estes sistemas (por exemplo, Devon PR-agent) são em grande parte fluxos de trabalho de IA baseados em RL, com LLMs organizados através de caminhos de código predefinidos.
1. Frameworks de agentes (Construa o seu próprio)
Bibliotecas modulares e SDKs para programadores construírem agentes com controlo sobre lógica, memória, ferramentas e orquestração.
✳️ Alguns agentes como SmolAgents e Agno encaixam-se tanto na categoria de frameworks de agentes como na de automação de fluxos de trabalho.
Frameworks de agentes gerais
Frameworks que se focam em construir agentes, oferecendo ferramentas flexíveis e personalizáveis para orquestrar fluxos de trabalho, configurações multi-agente e casos de uso gerais.
- LangGraph – Orquestração de fluxos de trabalho de LLM baseada em grafos – O LangGraph é software proprietário, mas fornece uma biblioteca de código aberto para desenvolvimento de agentes. Ideal para pipelines de RAG, memória de agentes/ gestão de estado e configurações multi-agente.
- AutoGen – Colaboração assíncrona multi-agente – Projetado para coordenar agentes que usam ferramentas através de APIs semelhantes a chat. Ideal para automatizar fluxos de trabalho complexos, particularmente em geração autónoma de código.
- CrewAI – Framework multi-agente sem código/pouco código – Uma das ferramentas mais fáceis para começar, oferecendo modelos de agentes prontos a usar (por exemplo, agente de preparação de reuniões).
Frameworks de agentes especializados
Frameworks com um foco especializado em tipos específicos de comportamentos de agentes ou integrações de agentes.
- Camel – Simulação de agentes baseada em papéis – Otimizado para agentes colaborativos de interpretação de papéis usando raciocínio estruturado. Ideal para automação de fluxos de trabalho e geração de dados sintéticos.
- Mastra – Desenvolvimento de agentes integrado com frontend – Baseado em JavaScript, ideal para incorporar agentes em aplicações voltadas para o utilizador.
- PydanticAI – Controlo de agente mínimo com segurança de tipos – Fornece validação rigorosa e caminhos lógicos transparentes com Pydantic.
- Cybersecurity IA (CAI) – Framework de agente de cibersegurança impulsionado por IA – Fornece testes de penetração, descoberta de vulnerabilidades e red teaming com capacidades de humano no circuito, aproveitando modelos de linguagem de grande escala e integrações com ferramentas como Nmap.
- Atomic Agents – Construtor de agentes personalizados granular com schema-first – Construído para estrutura granular de agentes e lógica componível.
- SmolAgents – SDK de agente leve para programadores – Abstração mínima, encaminha lógica via Python em vez de JSON.
Runtimes de agentes (Agentes autónomos pré-construídos)
Agentes pré-construídos e autossuficientes que pode executar imediatamente (como uma aplicação). Normalmente suportam execução autónoma de tarefas a partir de objetivos em linguagem natural.
Totalmente autónomos:
- Auto-GPT – Decomposição de objetivos e execução autónoma – Decompõe objetivos em sub-tarefas e completa-as usando ferramentas, memória e raciocínio. Oferece agentes pré-construídos e uma interface de pouco código.
- AIlice – Execução local de tarefas de propósito geral – Executa tarefas complexas no dispositivo, suporta ferramentas locais e manipulação de ficheiros. Visa criar um assistente de IA, semelhante ao JARVIS, baseado no LLM de código aberto.
- Manus IA – Operações em sandbox de propósito geral. Executa ferramentas e fluxos de trabalho numa sandbox segura, capaz de lidar com operações multi-domínio e multi-etapa de forma autónoma. Foi adquirido pela Meta, integrando-se no ecossistema de "Inteligência Ambiente Pessoal" da Meta.5
Parcialmente autónomos:
- BabyAGI – Executor iterativo de ciclo de tarefas – Cria, prioriza e executa listas de tarefas num ciclo de feedback. Ideal para experiências de geração de tarefas.
Baseados em navegador/interface:
- AgentGPT – Agente autónomo implementado no navegador – Permite aos utilizadores criar e executar agentes de tarefas através de uma interface web. Leve, ideal para experimentação.
- OpenManus – Agente de navegador persistente – Projetado para fluxos de trabalho que abrangem sessões em ambientes de navegador. Usa ferramentas como Playwright para automatizar interações web. Bom para usar em pipelines de automação existentes. A configuração é rápida com Conda.
2. Automação e orquestração de fluxos de trabalho
Ferramentas que automatizam fluxos de trabalho e integram múltiplas plataformas ou serviços, muitas vezes com a capacidade de integrar agentes de IA.
Agentes gerais de automação e integração de fluxos de trabalho
Plataformas que conectam APIs, acionam eventos e automatizam tarefas, facilitando a construção e integração de fluxos de trabalho em diferentes sistemas.
- n8n – Automação visual de fluxos de trabalho e integração de APIs – Conecta aplicações, gatilhos e fluxos de dados usando um editor de nós. Combina construção visual sem código com JavaScript/Python personalizado e suporta mais de 400 integrações. Pode ser auto-hospedado, executar fluxos de trabalho de agentes de IA com LangChain. Ideal para pessoas técnicas.
- PlanExe – Ferramenta de planeamento de LLM para Gantt/WBS – Planeador de IA semelhante à pesquisa profunda da OpenAI. Converte objetivos em linguagem natural em cronogramas estruturados usando o LlamaIndex.
- Agno ✳️ – Construtor de fluxos de trabalho e agentes amigável para programadores – Encaixa-se tanto como ferramenta de automação de fluxos de trabalho (ajudando a automatizar tarefas e fluxos de trabalho) como construtor de agentes.
- SmolAgents ✳️ – SDK de agente leve para programadores – O SmolAgents é suficientemente flexível para se encaixar tanto como um SDK de agente leve (para frameworks de agentes) como uma ferramenta de fluxo de trabalho (uma vez que se integra com modelos do Hugging Face).
- Windmill – Plataforma de desenvolvimento e motor de fluxos de trabalho de código aberto – Converte scripts em UIs, APIs e tarefas cron; suporta Python, TypeScript, Go e outras linguagens.
- Activepieces – Plataforma de automação de código aberto – Construtor visual de fluxos de trabalho auto-hospedado para automatizar tarefas e integrar aplicações com codificação mínima. Suporta mais de 280 servidores MCP para executar tarefas de IA distribuídas e cadeias de agentes em escala.
- Huginn – Automação web e gestão de agentes – Constrói agentes para automatizar tarefas baseadas na web e monitorização.
- Node-RED – Desenvolvimento baseado em fluxos para IoT e dados em tempo real – Integra serviços e automatiza tarefas com um editor de fluxos baseado no navegador.
Orquestração de fluxos de trabalho multi-agente
Frameworks projetados para coordenar agentes que interagem em fluxos de trabalho estruturados e integrar sistemas multi-agente.
- HyperAgent – Orquestração de agentes para o ciclo de vida completo de software – Os agentes trabalham em conjunto para planear, codificar e verificar tarefas de engenharia.
- Supercog – agentic – Orquestração modular com blocos lógicos reutilizáveis – Projetado para automação escalável, estruturada e baseada em equipas.
3. Automação e navegação web
Agentes que navegam autonomamente em websites e realizam tarefas de múltiplas etapas, como preenchimento de formulários, extração de dados e automação de navegação web.
Agentes web autónomos e copilotos
Agentes autónomos de propósito geral (com capacidade web):
- AgenticSeek – Agente de navegação web totalmente autónomo – Manus IA totalmente local. Especializado em extração de dados e preenchimento de formulários, automatizando tarefas baseadas na web.
- Agent-E – Agente de automação de navegador com reconhecimento de DOM – Foca-se em interagir com páginas web analisando o DOM (Document Object Model), ideal para clicar em botões e preencher formulários.
- AutoWebGLM – Agente web baseado em LLM – Usa aprendizagem por reforço e simplificação de HTML para melhor navegação em websites complexos.
Agentes de navegação web baseados em visão (multimodais):
- Extensão WebSurfer do Autogen – Agente web multimodal – Combina entrada de texto e visual (capturas de ecrã) para melhorar a interação web.
- Skyvern – Agente de IA com visão computacional – Automatiza fluxos de trabalho usando LLMs e visão computacional, lidando com elementos textuais e visuais.
- WebVoyager – Agente web com capacidade de visão – Usa texto e capturas de ecrã para melhorar a navegação em websites com muitas imagens.
Para mais informações sobre automação e navegação web de código aberto, aqui está uma visão estruturada de algumas das principais ferramentas e agentes:
Kits de ferramentas de automação e scraping web
RPA web com LLM e extensões de navegador
Scrapers e crawlers web com IA
Ferramentas de pesquisa web com IA
4. Agentes de codificação e desenvolvimento
Agentes de IA projetados para auxiliar em tarefas de codificação, fornecendo suporte em tempo real para programadores através de sugestões de código, depuração e automação de tarefas.
Agentes de codificação baseados em CLI
- Codex CLI – Ferramenta de interação multi-modo (sugerir, editar, executar) – Melhora os fluxos de trabalho dos programadores através da linha de comandos, oferecendo sugestões e edições de código.
- OpenDevin – Assistente de codificação de IA de código aberto – Auxilia em tarefas de programação, oferecendo sugestões de código para várias linguagens. Note-se que o OpenDevin foi recentemente renomeado para OpenHands para refletir a sua missão mais ampla de "All Hands IA".6
- Aider – Assistente de programação em par com IA – Integrado no seu terminal para assistência na codificação, suportando autocompletar, depuração e automação de tarefas.
Editores de código com IA
- Neovim – Editor de código integrado com IA – Plugins com IA que fornecem completação de código e refatoração.
- Visual Studio Code (VS Code) – Ferramenta de completação de código e depuração com IA – Oferece sugestões de código e autocompletar via GitHub Copilot, integrado com ambientes IDE para programadores.
- Cursor – Editor de código integrado com IA – Construído com completação de código em tempo real com IA.
Construtores de prompt-para-aplicação (Vibe coding)
Alternativas de código aberto ao v0 / lovable / Bolt:
- Dyad – Construtor de aplicações de IA de código aberto – Ferramenta local-first, sem código para construir aplicações impulsionadas por IA com comandos em linguagem natural.
- vx.dev – Construtor de aplicações de IA de código aberto – Uma ferramenta local-first, de pouco código, focada em transformar prompts de linguagem natural em aplicações.
5. Agentes de cibersegurança
Agentes de IA projetados para melhorar as operações de cibersegurança, incluindo tarefas como testes de penetração, descoberta de vulnerabilidades, red teaming e deteção autónoma de ameaças.
- YAWNING TITAN – Simulação abstrata de cibersegurança baseada em grafos – Suporta o treino de agentes para operações cibernéticas autónomas com foco em ambientes baseados em grafos.
- bumpgen – Agente de gestão de pacotes – Atualiza pacotes npm (gestor de pacotes do Node.js) automaticamente.
- Agentes de LLM para Cibersegurança – Tarefas de cibersegurança impulsionadas por LLM – Construído sobre o AutoGen. Usado em várias aplicações de investigação para demonstrar automação de EDR com ChatGPT e CI/CD automatizado para engenharia de deteção.
6. Agentes de criação de conteúdo de vídeo com IA
Agentes de IA que auxiliam na geração, edição e melhoria de conteúdo visual e multimédia, incluindo arte, imagens e vídeos.
- Mochi – Geração de texto para vídeo – Converte prompts de texto em vídeo, com foco na criação de vídeos de curta duração. Adequado para gerar rapidamente vídeos a partir de descrições textuais.
- CogVideo – Geração de texto para vídeo – Converte prompts de texto em vídeo com alta fidelidade, permitindo a criação de imagem para vídeo. Uma ferramenta mais avançada para geração de vídeo de alta qualidade a partir de texto ou imagens.
- Allegro – Geração de texto para vídeo – Converte prompts de texto em vídeo com foco na criação de conteúdo criativo. Esta ferramenta enfatiza a síntese criativa de vídeo a partir de texto para produzir narrativas visuais únicas.
- DALL·E (versões de código aberto) – Geração de texto para vídeo – Gera imagens a partir de descrições de texto, transformando prompts escritos em conteúdo visual detalhado e criativo.
7. Agentes financeiros
Agentes de IA que fornecem melhoria automatizada por aprendizagem por reforço ou análise de dados financeiros em tempo real.
- FinRL – Aprendizagem por reforço automatizada para trading – Aprende e executa autonomamente estratégias de trading com base em dados de mercado, adaptando-se a ambientes financeiros dinâmicos.
- OpenBB Terminal – Análise de dados financeiros – Fornece insights financeiros autónomos para trading em tempo real, permitindo que profissionais de investimento tomem decisões de trading informadas.
8. Agentes de saúde
Agentes de IA que auxiliam em diagnósticos médicos, monitorização de doenças e insights de saúde, analisando dados de pacientes e relatórios médicos.
- HIA (Health Insights Agent) – Análise de relatórios médicos – Analisa relatórios médicos e fornece insights de saúde.
- IA-HealthCare-Assistant – Diagnóstico e monitorização de doenças – Diagnostica e monitoriza doenças usando dados de pacientes.
9. Agentes de pesquisa
Agentes de IA que auxiliam na recolha de dados, revisões de literatura e teste de hipóteses, agilizando o processo de investigação.
- ChemCrow – Agente de pesquisa química autónomo – Integra LLMs com ferramentas de química para planear e executar tarefas experimentais e computacionais complexas em análise química.
- GPT Researcher – Assistente de pesquisa geral autónomo – Realiza pesquisas online estruturadas, analisa conteúdo e compila relatórios de pesquisa detalhados com mínima intervenção do utilizador.
10. Agentes de análise de dados
Agentes de IA que processam, analisam e interpretam dados para fornecer insights acionáveis e apoiar a tomada de decisões.
Finanças
- FinRobot – Agente de análise de dados financeiros – Automatiza a interpretação e relatórios de dados financeiros usando modelos de linguagem de grande escala.
Agentes de business intelligence e consulta
- Wren IA – Agente de insights de negócios de texto para SQL – Converte perguntas em linguagem natural em consultas SQL para relatórios de negócios.
- Entaoai – Ferramenta de engenharia de dados assistida por GenAI – Fornece uma interface de chat para tarefas de consulta e transformação de dados.
- Vanna IA – Agente de linguagem natural para SQL – Gera consultas SQL com base em prompts do utilizador para explorar conjuntos de dados estruturados.
Agentes de redes sociais
- Twitter Personality Agent – Agente de análise de redes sociais – Analisa o histórico de tweets para inferir traços comportamentais e de personalidade.
11. Agentes de assistência pessoal
Agentes de IA que ajudam na gestão de tarefas, agendamento e organização pessoal, melhorando a produtividade e a gestão do tempo.
- VacAIgent (agente CrewAI pré-construído) – Assistente de planeamento de viagens – Gera autonomamente itinerários completos de viagem usando Streamlit e LLMs.
- Inbox Zero – Assistente de email – prioriza, classifica e resume mensagens usando processamento de linguagem natural e integração com o Gmail.
- Cal – Agente de agendamento de calendário – Automatiza a criação, reagendamento e resumo de reuniões através de interação baseada em LLM.
Construindo sistemas de agentes de IA
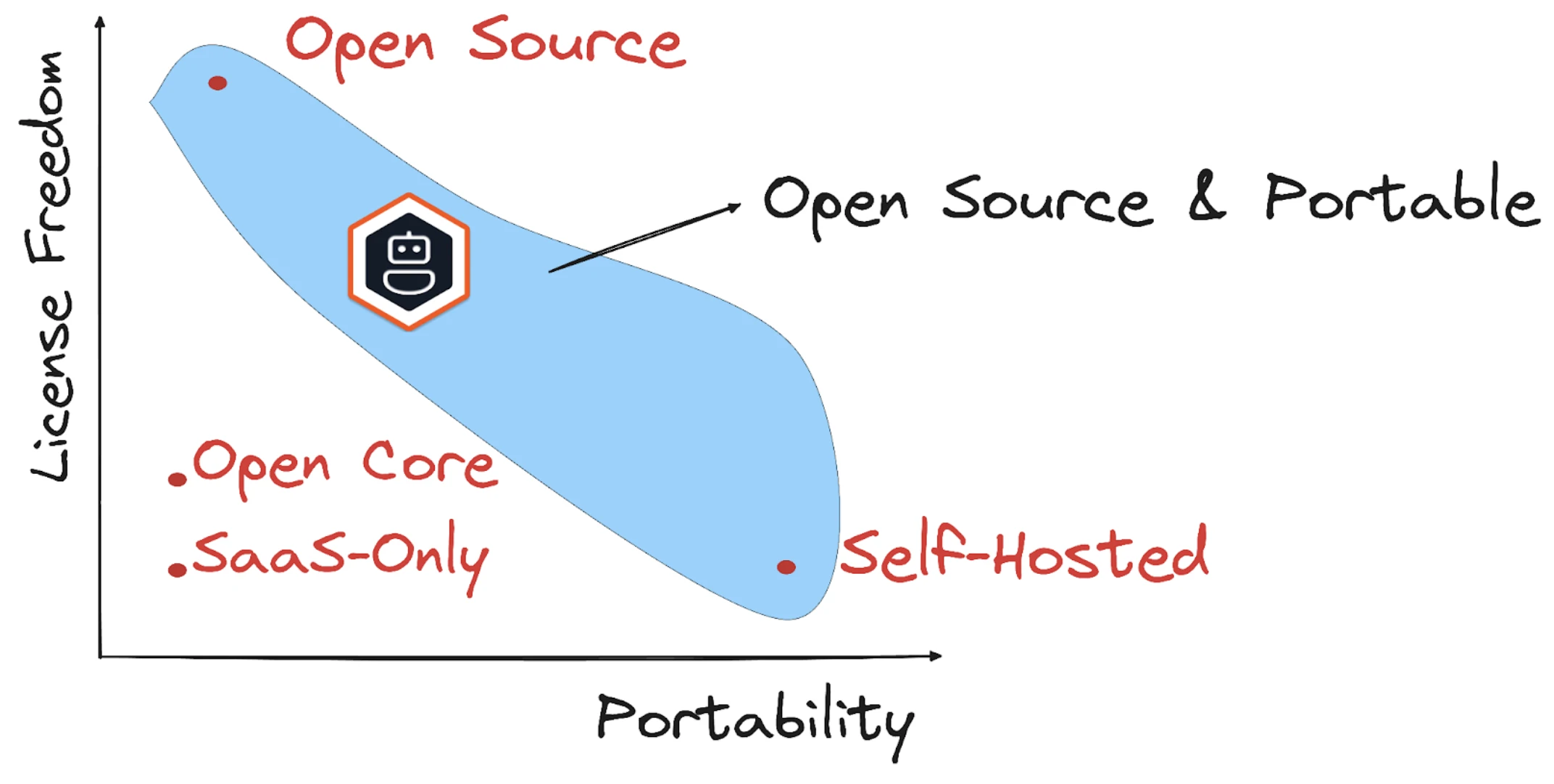
Muitos frameworks de IA são controlados por um único fornecedor ou repositórios públicos, mas com governação restrita.
Estes projetos mudam frequentemente para modelos open core: o código base permanece gratuito, mas a orquestração multi-agente, observabilidade ou controlo detalhado podem estar limitados por licenças comerciais. Em alguns ecossistemas "abertos", o uso em produção frequentemente requer a adoção de um backend fechado.
Fonte7
Projetos de agentes de IA no mundo real
Da nossa experiência, aqui estão alguns agentes de IA e as suas aplicações:
- Editores de código com IA para desenvolvimento de APIs e construção de aplicações
- Execução de screenshot para código para geração de websites com IA
- Agentes de uso de computador para fazer pedidos de entregas, fazer reservas em restaurantes ou projetar uma sala.
Outros projetos independentes de agentes de IA:
Outros projetos de agentes de IA por framework:
Leitura adicional
Cite esta pesquisa
Escolha o formato adequado ao local onde você vai publicar. Colar a versão com link no seu CMS preserva o backlink.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{Melhores 50+ Agentes de IA de Código Aberto Listados}},
year = {2026},
month = may,
howpublished = {\url{https://aimultiple.com/open-source-ai-agents}},
note = {AIMultiple. Acessado em 14 Maio 2026}
}
Seja o primeiro a comentar
Seu endereço de e-mail não será publicado. Todos os campos são obrigatórios. Os comentários são deixados em seu idioma original.