Benchmark de Web Crawler para Alimentar Sites com IA
Benchmarkamos quatro APIs de raspagem em três domínios de dificuldade variada em três níveis de profundidade máxima (5, 10, 20) com um limite de 1.000 páginas, medindo a cobertura da raspagem, tempo de execução, descoberta de links, qualidade dos links em markdown e precisão da extração de títulos.
Se você tem como objetivo:
- Transformar páginas da web em dados estruturados, veja nosso guia sobre raspagem da web.
- Raspar sites inteiros, continue lendo.
Benchmark de web crawlers
Você pode ler nossa metodologia de benchmark.
Páginas raspadas em média vs custo por 1.000 páginas
Páginas raspadas em domínios por profundidade máxima
Firecrawl consistentemente raspou cerca de 100 páginas no theregister.com independentemente da profundidade máxima, aproximadamente 90 páginas no entrepreneur.com em todos os níveis de profundidade e apenas cerca de 30 páginas na amazon.com, provavelmente devido à proteção agressiva de bots da Amazon. Vale notar que o aumento da profundidade máxima não teve praticamente nenhum impacto no número de páginas que o Firecrawl conseguiu raspar em qualquer domínio.
Apify demonstrou o desempenho mais consistente, atingindo o limite máximo de raspagem de 1.000 páginas em todos os domínios em todos os níveis de profundidade sem qualquer dificuldade aparente, mesmo em sites altamente protegidos como a Amazon.
Cloudflare apresentou comportamento inconsistente nos testes:
- No theregister.com na profundidade máxima 5, raspou apenas 100 páginas, mas na profundidade máxima 20 atingiu quase 1.000 páginas.
- Como observamos em testes anteriores, o Cloudflare ocasionalmente raspa apenas 1 página e depois encerra o trabalho inteiramente. Confirmamos que isso não é um problema de cache (o cache estava desativado) e testamos com tempos de espera entre execuções de até 1 minuto, mas o comportamento persistiu. Na profundidade máxima 10 no theregister.com, esse exato problema ocorreu, o Cloudflare raspou apenas 1 página antes de parar.
- No entrepreneur.com, o Cloudflare raspou 780 páginas na profundidade 5, aumentou para 885 na profundidade 10, mas depois caiu bruscamente para apenas 172 páginas na profundidade 20. Essa queda pode estar relacionada ao agendador de raspagem do Cloudflare desprivilegiando ou dando timeout em cadeias de links mais profundas, ou pode refletir um limite de concorrência interno que faz com que o trabalho termine prematuramente quando a fronteira de raspagem cresce demais em profundidades mais altas.
- Na amazon.com, o Cloudflare raspou 905 páginas na profundidade 5, mas o número diminuiu constantemente à medida que a profundidade máxima aumentava, caindo para 809 na profundidade 10 e 795 na profundidade 20, sugerindo que configurações de raspagem mais profundas podem fazer com que o Cloudflare gaste mais tempo com a sobrecarga de descoberta de links em vez da recuperação real da página.
Nimble atingiu ou aproximou-se do limite de 1.000 páginas no theregister.com em todos os níveis de profundidade (1.000 / 1.000 / 999). No entrepreneur.com, raspou 1.000 páginas na profundidade 5, mas mostrou quedas ligeiras em profundidades mais altas (896 na profundidade 10, 983 na profundidade 20), possivelmente devido ao seu timeout de 7 horas ser atingido antes de completar a raspagem total em níveis mais profundos; todas as execuções do Nimble terminaram com status de timeout. A Amazon provou ser mais desafiadora:
- Na profundidade 5, gerenciou apenas 319 páginas, mas na profundidade 10 saltou para 988 páginas, depois caiu para 906 na profundidade 20
- Essa inconsistência provavelmente reflete a combinação dos mecanismos de proteção de bots da Amazon e as restrições de timeout do Nimble, onde raspagens mais profundas levam mais tempo para processar cada página e podem encontrar mais desafios anti-bot pelo caminho
Tempo de execução em domínios por profundidade máxima
Firecrawl foi o provedor mais rápido em todos os domínios, completando raspagens em menos de 5 minutos, tipicamente entre 75-265 segundos. Essa velocidade vem ao custo da cobertura, pois o Firecrawl também raspou o menor número de páginas. Essencialmente, ele termina rapidamente porque para cedo.
Apify levou cerca de 2.200-2.400 segundos (~40 minutos) no theregister.com independentemente da profundidade. No entrepreneur.com e amazon.com, os tempos de execução foram significativamente mais longos, de 8.300-15.900 segundos (2-4 horas), refletindo as estruturas de site maiores e mais complexas. Apesar dos tempos mais longos, o Apify consistentemente atingiu o limite de 1.000 páginas, tornando-o o mais confiável em termos de relação cobertura-tempo.
Cloudflare mostrou tempos que espelham suas contagens de raspagem inconsistentes:
- No theregister.com na profundidade 10, completou em apenas 1 segundo, porque raspou apenas 1 página antes de parar.
- No entrepreneur.com na profundidade 20, terminou em 10 segundos após raspar apenas 172 páginas.
- Quando o Cloudflare completa uma raspagem total, os tempos variam de 3.500 a 25.200 segundos.
- À medida que a profundidade máxima aumenta, o Cloudflare parece priorizar alcançar páginas mais profundas em vez de amplitude, raspando menos páginas, mas completando mais rápido. Na amazon.com, o tempo de execução caiu de 25.200 segundos (timeout) na profundidade 5 para apenas 5.660 segundos na profundidade 20, enquanto as páginas raspadas também diminuíram de 905 para 795. Isso sugere que o crawler do Cloudflare muda sua estratégia em profundidades mais altas, gastando menos tempo com descoberta ampla e mais com travessia profunda.
Nimble atingiu o timeout de 7 horas (25.200 segundos) em cada execução em todos os domínios e níveis de profundidade. Isso é notável porque em nossos testes rápidos anteriores com profundidade máxima 1, o Nimble completou sem timeout. No benchmark completo com profundidades de 5-20 e um limite de 1.000 páginas, ele consistentemente executou até que o timeout fosse atingido. Apesar disso, o Nimble ainda conseguiu raspar um alto número de páginas na maioria dos casos (~900-1.000 no theregister.com e entrepreneur.com), significando que está ativamente raspando durante as 7 horas, mas simplesmente nunca sinaliza conclusão.
Taxa de preenchimento de texto de link entre provedores por profundidade máxima
Para avaliar a qualidade da saída em markdown, medimos qual porcentagem de links no markdown de cada provedor contém texto de âncora, a parte clicável de um link. Um texto de âncora ausente (por exemplo, [](/about) em vez de [About Us](/about)) significa que o crawler falhou em extrair o rótulo do link.
- Nimble: 100% em todas as profundidades
- Cloudflare: 91-94%
- Firecrawl: 90%
- Apify: 77-78%, aproximadamente 1 em 5 links sem texto de âncora
A profundidade de raspagem teve impacto mínimo nas taxas de preenchimento para qualquer provedor, sugerindo que isso é uma característica do mecanismo de análise de cada provedor em vez de uma configuração de raspagem.
Taxa de preenchimento de texto de link entre provedores por domínio
Olhar para as taxas de preenchimento em diferentes domínios revela como a complexidade do site afeta a qualidade de extração de links de cada provedor.
- O Nimble manteve 100% em todos os domínios.
- O Apify mostrou a maior variação, 89% na amazon.com, mas caindo para 66% no entrepreneur.com, significando que um terço de seus links naquele site estavam sem texto de âncora. Isso sugere que o Apify luta mais com sites ricos em conteúdo que têm estruturas de navegação complexas.
- O Firecrawl performou melhor no theregister.com (98%), mas caiu para 81% no entrepreneur.com, seguindo um padrão semelhante ao do Apify.
- O Cloudflare foi o mais consistente após o Nimble, permanecendo entre 89-94% independentemente do domínio.
O entrepreneur.com provou ser o domínio mais desafiador para extração de texto de link, tanto o Apify (66%) quanto o Firecrawl (81%) tiveram suas pontuações mais baixas lá, provavelmente devido ao uso pesado do site de menus de navegação aninhados e elementos de conteúdo dinâmicos que são mais difíceis de converter limpa em markdown.
Total de links na saída markdown em domínios por profundidade máxima
A variância na contagem de links entre provedores foi consistentemente alta (74-97%), indicando que os provedores extraem números muito diferentes de links das mesmas páginas. Para obter uma visão mais detalhada dessa disparidade, medimos a contagem total de links markdown por provedor.
- Apify retornou o maior número de links no geral, particularmente na amazon.com mais de 420K links na profundidade 5 (~423 por página). No entrepreneur.com, estabilizou-se em torno de 63K independentemente da profundidade. Sua saída inclui rastreadores de anúncios e pixels de rastreamento ao lado de links de conteúdo da página.
- Cloudflare atingiu o pico de 303K no entrepreneur.com na profundidade 10, mas caiu para 53K na profundidade 20. Na mesma página inicial do entrepreneur.com, o Cloudflare extraiu 434 links comparado aos 143 do Apify, capturando menus de navegação completos e submenus.
- Firecrawl consistentemente retornou 5-9K links em todas as configurações, limitado pela sua baixa contagem de páginas.
- Nimble retornou 3-40K links no total, com média de 5-28 links por página comparado a 60-420 para outros provedores. Na página inicial do entrepreneur.com, o Nimble retornou 13 links versus 434 do Cloudflare, limitado a manchetes principais de artigos. Sua taxa de preenchimento de 100% reflete que os links que incluiu todos tinham texto de âncora, em vez de indicar cobertura abrangente de links. O Nimble não retorna links markdown padrão. Sua contagem inclui links HTML escapados encontrados dentro da saída markdown.
Taxa de presença de título entre provedores
A semelhança de títulos entre provedores mostrou menos de 1% de desvio em todos os testes e domínios, confirmando que quando os provedores extraem um título, eles consistentemente retornam o mesmo resultado. A taxa de presença de título também permaneceu entre 98-100% em todos os níveis de profundidade máxima, mostrando que a profundidade de raspagem não tem impacto significativo na extração de títulos.
Quando quebrado por domínio, algumas diferenças surgiram:
No entrepreneur.com e theregister.com, a maioria dos provedores atingiu taxas de presença de título de 99-100%. A amazon.com foi o único domínio onde diferenças significativas apareceram, o Firecrawl caiu para 93% e o Nimble para 95,9%, enquanto o Apify manteve 99,6%. Isso se alinha com a proteção de bots mais pesada da Amazon, que pode bloquear ou distorcer respostas de página, fazendo com que alguns provedores retornem páginas sem títulos extraíveis.
O que é um web crawler?
Um web crawler, às vezes chamado de "aranha" ou "agente", é um bot que navega na internet para indexar conteúdo.
Os crawlers evoluíram além dos motores de busca e agora servem como a Camada de Dados Agêntica. Eles atuam como os olhos para agentes de IA autônomos como o Claude Code e o OpenAI Operator, auxiliando em tarefas em tempo real como pesquisa competitiva e transações multi-etapas.
O que um web crawler faz?
A raspagem da web foi dividida em três modos, cada um projetado para um objetivo de crawler diferente.
- Modo de Descoberta (tradicional): Bots de motores de busca como o Googlebot raspam URLs para indexação, ajudando pessoas a encontrar resultados através de motores de busca.
- Modo de Recuperação (RAG): Bots de IA como ChatGPT-User ou PerplexityBot buscam páginas específicas em tempo real para responder prompts de usuários. Eles usam markdown em vez de HTML para se adequar aos limites de token do modelo de IA.
- Modo Agêntico (Orientado a Ação): Este novo tipo de crawler em 2026 faz mais do que apenas ler conteúdo. Usando o Protocolo de Contexto de Modelo (MCP), esses bots podem interagir com sites para reservar voos ou executar comandos de software.
No passado, crawlers usavam seletores como XPath ou CSS para extrair dados. A Extração Nativa de IA tornou-se a norma.
Ferramentas como o Firecrawl e o Crawl4AI usam instruções em linguagem natural para encontrar dados. Em vez de escrever regras para cada elemento, desenvolvedores podem dizer ao crawler para "extrair o preço do produto", e a IA encontrará o valor correto mesmo se o código do site mudar.
Construir vs. comprar web crawlers na era da IA
1. Construindo Seu Próprio Crawler
Ideal para proteger propriedade intelectual central e permitir personalização profunda. Construir agora requer desenvolver uma camada de agente proprietária, não apenas escrever scripts básicos do Scrapy.
- Quando construir: Selecione essa abordagem se seu crawler fornecer uma vantagem competitiva única. Por exemplo, construa o seu próprio se você estiver desenvolvendo um motor de busca especializado ou exigir controle total sobre dados sensíveis ou regulamentados.
- O conjunto de ferramentas: Você não precisa mais começar do zero. Desenvolvedores agora aproveitam o Protocolo de Contexto de Modelo (MCP) para permitir que agentes de IA internos interajam com a web.
2. Usando Ferramentas e APIs de Raspagem da Web
Ferramentas gerenciadas evoluíram de raspadores básicos para agentes autônomos.
- Extração sem manutenção: Ferramentas modernas como Kadoa e Firecrawl usam IA auto-curativa. Você especifica os dados necessários, como "Preço do Produto", em vez de sua localização no código. Se o layout do site mudar, a ferramenta se adapta automaticamente.
- Conformidade como serviço: Muitos provedores oferecem conformidade integrada com a Lei de IA da UE. Eles gerenciam logs de auditoria necessários e verificações de opt-out de direitos autorais, que são desafiadoras de implementar independentemente.
- Velocidade para valor: Comprar uma plataforma pode mover seu projeto do conceito para produção em semanas.
Figura 5: Uma explicação de como uma fronteira de URL funciona.
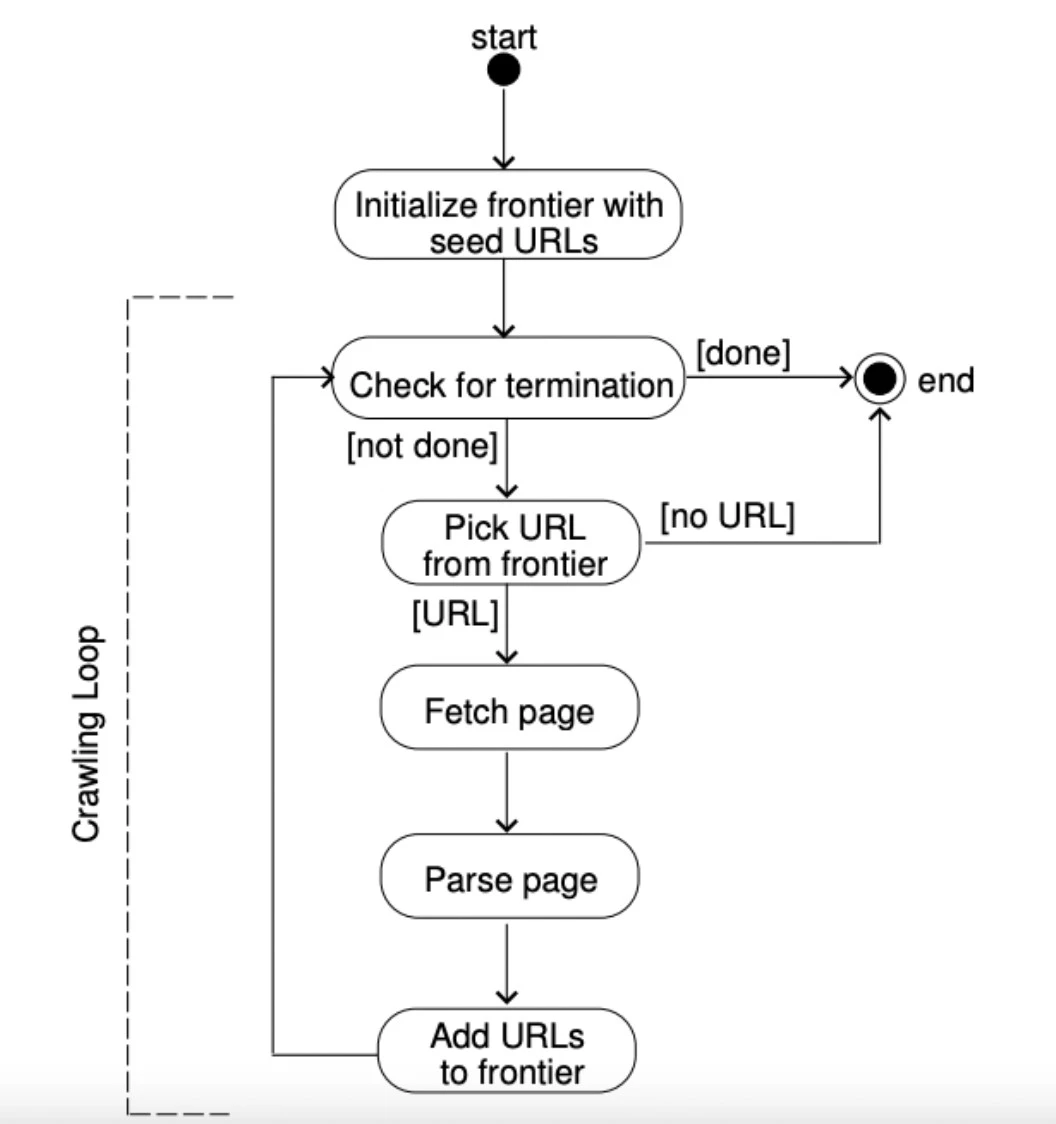
Web crawlers são legais?
Em geral, a raspagem da web é legal, mas dependendo de como e o que você raspa, você pode rapidamente se encontrar em um problema legal. Quatro pilares principais determinam se a raspagem (e a extração que geralmente segue) é legal:
1. Público vs. privado: Raspe apenas dados que estão abertamente disponíveis para o público sem uma conta.
2. Informações pessoais: Evite PII (nomes, e-mails e endereços) a menos que tenha uma base legal.
3. Saúde do servidor: Use limites de taxa para evitar desacelerar o servidor; evite "DDOSar" um site.
4. Direitos autorais: Artigos e imagens são protegidos por direitos autorais, mas fatos (preços, datas) não são.
Qual é a diferença entre raspagem da web e extração da web?
A extração da web é o uso de web crawlers para escanear e armazenar todo o conteúdo de uma página da web alvo. Em outras palavras, a extração da web é um caso de uso específico da raspagem da web para criar um conjunto de dados direcionado, como buscar todas as notícias financeiras para análise de investimento e pesquisar nomes de empresas específicas.
Tradicionalmente, uma vez que um web crawler raspou e indexou todos os elementos da página da web, um raspador da web extraía dados da página da web indexada. No entanto, hoje em dia os termos extração e raspagem são usados de forma intercambiável com a diferença de que crawler tende a se referir mais a crawlers de motores de busca. À medida que empresas além dos motores de busca começaram a usar dados da web, o termo raspador da web começou a assumir o lugar do termo web crawler.
Quais são os desafios da raspagem da web?
1. Atualização do banco de dados
O conteúdo dos sites é atualizado regularmente. Páginas da web dinâmicas, por exemplo, mudam seu conteúdo com base nas atividades e comportamentos dos visitantes. Isso significa que o código-fonte do site não permanece o mesmo após você raspar o site. Para fornecer as informações mais atualizadas ao usuário, o web crawler deve re-raspar essas páginas da web com mais frequência.
2. Armadilhas de crawler
Sites empregam diferentes técnicas, como armadilhas de crawler, para impedir que web crawlers acessem e raspem certas páginas da web. Uma armadilha de crawler, ou armadilha de aranha, faz com que um web crawler faça um número infinito de solicitações e fique preso em um círculo vicioso de raspagem. Sites também podem criar armadilhas de crawler sem querer. Em qualquer caso, quando um crawler encontra uma armadilha de crawler, ele entra em algo como um loop infinito que desperdiça os recursos do crawler.
3. Largura de banda da rede
Baixar um grande número de páginas da web irrelevantes, utilizar um web crawler distribuído ou re-raspar muitas páginas da web resultam em uma alta taxa de consumo de capacidade de rede.
4. Páginas duplicadas
Bots de web crawler raspam principalmente todo o conteúdo duplicado na web; no entanto, apenas uma versão de uma página é indexada. Conteúdo duplicado torna difícil para bots de motores de busca determinar qual versão de conteúdo duplicado indexar e classificar. Quando o Googlebot descobre um grupo de páginas da web idênticas nos resultados de busca, ele indexa e seleciona apenas uma dessas páginas para exibir em resposta à consulta de busca de um usuário.
Top 3 melhores práticas de raspagem da web
1. Cortesia/Taxa de raspagem
Sites definem uma taxa de raspagem para limitar o número de solicitações feitas por bots de web crawler. A taxa de raspagem indica quantas solicitações um web crawler pode fazer para seu site em um determinado intervalo de tempo (por exemplo, 100 solicitações por hora). Permite que proprietários de sites protejam a largura de banda de seus servidores web e reduzam a sobrecarga do servidor. Um web crawler deve aderir ao limite de raspagem do site alvo.
2. Conformidade com robots.txt
Um arquivo robots.txt é um arquivo de texto colocado na raiz de um site que diz aos crawlers quais páginas eles têm permissão ou não para acessar. É um padrão voluntário, o que significa que bots compatíveis o respeitam, mas tecnicamente não impede o acesso. Seguir o robots.txt de um site é considerado uma melhor prática e, em muitas jurisdições, ignorá-lo pode expô-lo a riscos legais ou reputacionais.
3. Rotação de IP
Sites empregam diferentes técnicas anti-extração como CAPTCHAs para gerenciar o tráfego de crawlers e reduzir atividades de extração da web. Por exemplo, impressão digital do navegador é uma técnica de rastreamento usada por sites para coletar informações sobre visitantes, como duração da sessão ou visualizações de página.
Esse método permite que proprietários de sites detectem "tráfego não humano" e bloqueiem o endereço IP do bot. Para evitar detecção, você pode integrar proxies rotativos, como residenciais, ao seu web crawler.
Metodologia de benchmark de web crawlers
Testamos quatro APIs de raspagem (Apify, Nimble, Cloudflare, Firecrawl) em três domínios de dificuldade variada: amazon.com (proteção pesada de bots), entrepreneur.com (site de conteúdo complexo) e theregister.com (site de notícias).
Configuração compartilhada
Todos os provedores receberam configurações principais idênticas para garantir uma comparação justa:
- Sitemap: Desativado, provedores devem descobrir páginas apenas através de links HTML
- Links externos: Desativado, crawlers permanecem dentro do domínio alvo
- Subdomínios: Ativado, páginas de subdomínio são seguidas (por exemplo, india.entrepreneur.com)
- Renderização JavaScript: Ativada, todos os provedores usam um navegador headless
- Cache: Desativado
- Limite de página: 1.000 páginas por execução
- Timeout: 7 horas (25.200 segundos)
- Tratamento de limite de taxa: Espera de 20 segundos com até 3 retentativas em HTTP 429
Cada provedor foi testado em três níveis de profundidade máxima (5, 10, 20) em todos os três domínios, totalizando 36 execuções de raspagem. Os provedores foram testados sequencialmente (não em paralelo), cada combinação foi executada uma vez e o status de raspagem foi consultado a cada 1 segundo.
O Apify foi configurado com o ator website-content-crawler usando Playwright/Firefox como seu navegador headless. O acesso a subdomínios foi controlado via padrões glob, e o proxy integrado do Apify foi usado para todas as solicitações.
O Nimble, Cloudflare e Firecrawl foram configurados usando suas respectivas APIs REST com as configurações compartilhadas descritas acima. Nenhuma configuração específica adicional do provedor foi aplicada além dos parâmetros padronizados.
Para o Cloudflare, usamos o plano Workers Paid. O custo relatado reflete o que gastamos para raspar 1.000 páginas sob este plano. O Cloudflare cobra com base no tempo de renderização do navegador em vez da contagem de páginas.
Para o Firecrawl, usamos o plano Hobby. O custo relatado é o valor proporcional para 1.000 créditos dos créditos fornecidos neste plano. O custo efetivo por página varia dependendo do nível do plano e se pacotes de créditos extras são comprados.
Cite esta pesquisa
Escolha o formato adequado ao local onde você vai publicar. Colar a versão com link no seu CMS preserva o backlink.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Şipi, Nazlı},
title = {{Benchmark de Web Crawler para Alimentar Sites com IA}},
year = {2026},
month = jul,
howpublished = {\url{https://aimultiple.com/web-crawler}},
note = {AIMultiple. Acessado em 2 Julho 2026}
}
Comentários 1
Compartilhe suas ideias
Seu endereço de e-mail não será publicado. Todos os campos são obrigatórios. Os comentários são deixados em seu idioma original.
Hi Cem, I think there is a misunderstanding regarding the robots.txt role in the crawling context. The web bots can crawl any website when indexing is allowed without having the robots.txt somewhere on their top domain, subdomains and ports and so on. The role of a robots.txt is to keep control of the traffic from web bots so the website is not overloaded by requests.