Melhores 12+ Agentes de Web Scraping com IA (Gratuitos e Pagos)
Seletores CSS manuais e scripts básicos não funcionam mais bem. À medida que as arquiteturas da web se tornam mais dinâmicas e impulsionadas por IA, os métodos de scraping tradicionais tornam-se menos eficazes.
Para manter os dados confiáveis, a indústria está recorrendo a agentes de IA autônomos, scraping baseado em visão (VLM) e scrapers de auto-cura. Visite as principais ferramentas de web scraping com IA:
Melhores ferramentas de web scraping com IA
Como fizemos esta lista
Excluímos intencionalmente ferramentas de scraping de dados de propósito geral e bibliotecas de automação que não possuem capacidades de IA integradas (como Scrapy ou Playwright), mesmo que sejam comumente usadas para web scraping e possam complementar ferramentas de IA em fluxos de trabalho híbridos.
Curamos esta lista usando os seguintes critérios:
- Foco em capacidades impulsionadas por IA: Incluímos ferramentas que usam inteligência artificial, como LLMs e NLP, para entender a estrutura da página sem regras codificadas ou extração de dados orientada por prompt.
- Acessibilidade para usuários: Categorizamos as ferramentas com base no nível técnico, como ferramentas sem código versus ferramentas para desenvolvedores.
O que é web scraping com IA?
O web scraping com IA evoluiu para Liquidação de Dados Autônoma. Não se trata mais de automatizar cliques no navegador ou fazer parsing de HTML; envolve Modelos de Linguagem e Visão (VLMs) que 'veem' uma página da web como um humano e Raciocínio Agente que pode navegar por autenticação complexa e conteúdo dinâmico sem seletores CSS predefinidos ou mapeamento DOM.
Tipos de ferramentas de web scraping com IA
1. Plataformas impulsionadas por IA
Essas soluções usam LLMs, visão computacional ou NLP para fazer parsing, extrair ou interpretar conteúdo de páginas da web. Por exemplo, o scraping adaptativo do Diffbot se adapta dinamicamente a mudanças no DOM ou marcação inconsistente entre páginas. Muitas ferramentas nesta categoria suportam extração baseada em esquema (estruturada) ou baseada em prompt.
Você dá à ferramenta uma instrução em linguagem natural, por exemplo, "Extraia todos os cargos e nomes de empresas desta URL."
2. Ferramentas sem código
Scrapers sem código fornecem interfaces visuais que permitem aos usuários definir os dados a serem capturados usando funcionalidade de clique e apontar ou modelos pré-construídos. Você pode definir regras de extração de dados visualmente.
No entanto, essas ferramentas oferecem uso limitado de IA em comparação com plataformas impulsionadas por IA, que utilizam IA para detecção de padrões ou sugestões inteligentes de campos.
3. Ferramentas de IA open-source
Esta categoria inclui bibliotecas ou frameworks que usam LLMs ou agentes de IA para extrair dados de páginas da web. Eles fornecem controle programático; você precisa definir esquemas de extração ou prompts de IA.
Técnicas e tecnologias envolvidas no web scraping impulsionado por IA
A abordagem de web scraping impulsionada por IA se adapta automaticamente a redesenhos de sites e extrai dados carregados dinamicamente via JavaScript. É importante empregar esses métodos considerando os termos do site e considerações éticas.
1. Scraping adaptativo
Métodos tradicionais de web scraping dependem da estrutura ou layout específico de uma página da web. Quando os sites atualizam seus designs e estruturas, os scrapers tradicionais podem quebrar facilmente. Métodos de coleta de dados baseados em IA, como o scraping adaptativo, permitem que as ferramentas de web scraping se adaptem a mudanças nos sites, incluindo design e estrutura.
Scrapers adaptativos usam aprendizado de máquina e IA para ajustar dinamicamente seu comportamento com base na estrutura de uma página da web. Eles identificam autonomamente a estrutura da página da web alvo analisando o Document Object Model (DOM) ou seguindo padrões específicos. Para identificar padrões ou antecipar mudanças, a ferramenta pode ser treinada usando dados históricos raspados.
Por exemplo, modelos de IA como redes neurais convolucionais (CNNs) podem ser usados para reconhecer e analisar elementos visuais de uma página da web, como botões. Tipicamente, as técnicas de scraping de dados tradicionais dependem do código subjacente de uma página da web, como elementos HTML, para extrair dados.
Extração de visão zero-shot:
O scraping adaptativo tradicional ainda depende da árvore DOM. No entanto, em 2026, ferramentas como Firecrawl e Crawl4AI migraram para extração 'Zero-Shot'. Ao tirar uma captura visual (VLM), a IA identifica elementos com base na intenção visual em vez do código. Isso torna os scrapers mais resilientes à randomização de classes CSS e armadilhas de código 'Honey-pot'.
Patrocinado
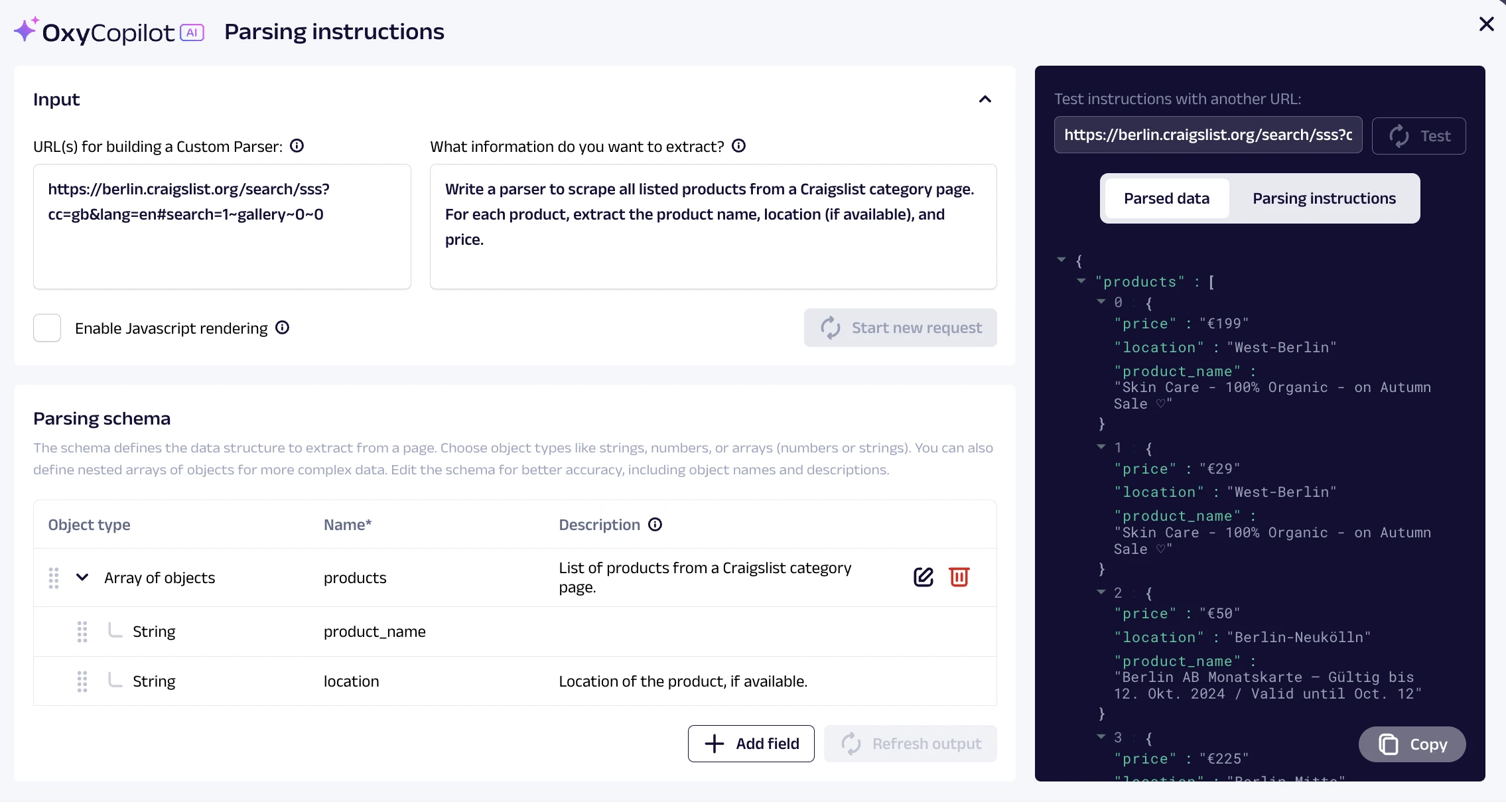
O Oxylabs fornece um construtor de parser personalizado baseado em ML, chamado OxyCopilot, que aprimora a API do Web Scraper da Oxylab, permitindo que os usuários refinem e organizem os dados coletados usando prompts. Isso simplifica o processo, eliminando a necessidade de classificar campos de dados irrelevantes ou realizar limpeza de dados manual.
2. Gerando padrões de navegação semelhantes aos humanos
A maioria dos sites emprega medidas anti-scraping, como CAPTCHAs, para impedir que scrapers da web acessem e raspem seu conteúdo. Ferramentas de web scraping impulsionadas por IA podem simular comportamento semelhante ao humano, como velocidade, movimentos do mouse e padrões de clique.
3. Modelos de IA generativa
Em 2025/2026, paramos de pedir à IA para escrever código BeautifulSoup. Em vez disso, usamos Agentes de Scraping (como Skyvern ou Browser-use).
- Como funciona: Você fornece um objetivo em inglês simples (por exemplo, 'Encontre o laptop mais barato neste site e exporte para JSON').
- Padrão Reason-act (ReAct): O agente explora o site, resolve CAPTCHA, lida com paginação e valida a qualidade dos dados em tempo real sem uma única linha de código manual.
4. Processamento de linguagem natural (NLP)
O NLP, um subconjunto de ML, permite que você execute tarefas como análise de sentimento, resumo de conteúdo e reconhecimento de entidades. É necessário derivar insights dos dados raspados.
Por exemplo, se você extraiu uma quantidade significativa de dados de avaliação de produtos, precisa determinar o tom emocional por trás de cada palavra, como positivo, negativo ou neutro. A análise de sentimento permite que você categorize os dados extraídos como positivos ou negativos. Isso ajuda as empresas a abordar as preocupações dos clientes e melhorar suas ofertas.
Cite esta pesquisa
Escolha o formato adequado ao local onde você vai publicar. Colar a versão com link no seu CMS preserva o backlink.
@misc{karatas2026,
author = {Karatas, Gulbahar},
title = {{Melhores 12+ Agentes de Web Scraping com IA (Gratuitos e Pagos)}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/ai-web-scraping}},
note = {AIMultiple. Acessado em 5 Junho 2026}
}
Seja o primeiro a comentar
Seu endereço de e-mail não será publicado. Todos os campos são obrigatórios. Os comentários são deixados em seu idioma original.