20 Strategie per il miglioramento dell'IA ed esempi
I modelli di IA richiedono un miglioramento continuo man mano che dati, comportamenti degli utenti e condizioni del mondo reale evolvono. Anche i modelli con buone prestazioni possono subire un degrado quando i pattern appresi non corrispondono più agli input attuali, portando a una ridotta accuratezza e a previsioni inaffidabili.
I cambiamenti nelle normative, nei requisiti di prodotto o nelle aspettative dei clienti possono anche introdurre nuovi vincoli che i modelli esistenti non sono stati progettati per gestire.
Mantenere la qualità del modello, quindi, comporta il rafforzamento sia dei dati che supportano il modello sia degli algoritmi che ne modellano il comportamento, garantendo che i sistemi rimangano allineati con i requisiti attuali anziché con presupposti superati.
Esplora le strategie chiave, tra cui l'alimentazione di dati, il miglioramento dei dati e dell'algoritmo, e le leggi di scaling dell'IA che garantiranno che i tuoi modelli di IA rimangano pertinenti e pratici.
I migliori 20 modi per migliorare il tuo modello di IA
Abbiamo illustrato i metodi per migliorare il tuo modello di IA in 4 diverse categorie:
Metodo | Descrizione | Sfide chiave |
|---|---|---|
Alimentare più dati | Aggiungere dati reali o sintetici di alta qualità per migliorare copertura e generalizzazione. | Garantire la qualità dei dati, evitare bias, gestire la privacy e i limiti di accesso. |
Migliorare i dati | Migliorare l'etichettatura, la diversità e l'aumento dei dati per ridurre rumore e bias. | Bilanciare qualità vs. quantità, ridurre i bias del dataset, mantenere le annotazioni coerenti. |
Migliorare l'algoritmo | Utilizzare architetture migliori, tecniche di fine-tuning e pratiche di deployment. | Maggiore complessità e costo, comportamenti indesiderati, rigide esigenze di privacy. |
Leggi di scaling dell'IA | Aumentare scala, calcolo, efficienza e tecniche di recupero o multi-agente. | Rendimenti decrescenti, limiti computazionali, impatto ambientale, complessità di integrazione. |
Alimentare più dati
Aggiungere dati nuovi e aggiornati è uno dei metodi più comuni ed efficaci per migliorare l'accuratezza del tuo modello di machine learning. La ricerca ha mostrato una correlazione positiva tra la dimensione del dataset e l'accuratezza del modello di IA.1
Pertanto, espandere il dataset utilizzato per il riaddestramento del modello può essere un modo efficace per migliorare i modelli di IA/ML. Assicurati che i dati cambino in base all'ambiente in cui vengono distribuiti. È inoltre essenziale aderire a pratiche adeguate di garanzia della qualità nella raccolta dei dati.
1. Raccolta dati
La raccolta/acquisizione dati può essere utilizzata per espandere il tuo dataset e alimentare più dati nel modello di IA/ML. In questo processo, nuovi dati vengono raccolti per riaddestrare il modello. Questi dati possono essere acquisiti attraverso i seguenti metodi:
- Raccolta privata
- Raccolta dati automatizzata
- Crowdsourcing personalizzato
Per raccogliere con successo dati per l'IA, le aziende devono prestare attenzione a:
- Le considerazioni etiche e legali nella raccolta dati devono essere rispettate per evitare qualsiasi problema etico.
- I bias nei dati di addestramento possono portare a risultati indesiderati dell'IA.
- La pre-elaborazione dei dati grezzi è essenziale per affrontare i problemi di qualità e garantire l'integrità dei dati per l'addestramento IA/ML.
- Non tutti i dati sono facilmente accessibili a causa di restrizioni legate alla sensibilità e alle normative sulla privacy.
Scopri di più sui metodi di raccolta dati.
Si consiglia inoltre di collaborare con un servizio di dati per l'IA per ottenere dataset pertinenti senza la difficoltà di raccogliere dati e per evitare problemi etici e legali.
2. Dati sintetici con modelli generativi
L'IA generativa ha fatto progredire la creazione di dati sintetici, producendo dataset di alta qualità che replicano le condizioni del mondo reale. I large language model e i modelli di diffusione possono ora generare dati strutturati e non strutturati per l'addestramento di modelli in domini in cui i dati reali sono limitati.
Esempi includono:
- Produrre casi medici rari per migliorare i modelli di machine learning nella sanità.
- Generare dati di conversazione realistici per migliorare i sistemi di elaborazione del linguaggio naturale.
- Creare dataset visivi per testare la risoluzione delle immagini, la qualità fotografica o i modelli di riconoscimento delle immagini.
Auto-apprendimento sintetico e dati di addestramento sintetici
L'auto-apprendimento sintetico genera nuovi dati di addestramento consentendo a modelli o agenti di interagire con compiti o tra di loro. Questi supplementi compensano la limitatezza di dati umani di alta qualità.
Questo metodo fornisce:
- Produzione scalabile di dati di istruzione, ragionamento o dialogo.
- Copertura di scenari rari o costosi da raccogliere manualmente.
- Migliori prestazioni del modello in domini in cui la scarsità di dati è un vincolo primario.
Esempio reale: Più dati per i chatbot
Un chatbot per il supporto IT aveva difficoltà a comprendere e classificare correttamente le domande degli utenti. Per migliorare le sue prestazioni, 500 domande di supporto IT sono state riscritte in molteplici varianti in sette lingue.
Questi dati aggiuntivi hanno aiutato il chatbot a riconoscere diversi formati di domande, migliorando la sua capacità di rispondere in modo più efficace.
Migliorare i dati
Anche migliorare i dati esistenti può portare a un modello di IA/ML migliorato.
Ora che le soluzioni di IA stanno affrontando problemi più complessi, sono necessari dati migliori e più diversificati per svilupparle. Ad esempio, una ricerca2 su un modello di deep learning che aiuta i sistemi di rilevamento degli oggetti a comprendere le interazioni tra due oggetti, conclude che il modello è suscettibile3 ai bias del dataset e richiede un dataset diversificato per produrre risultati.
I miglioramenti possono essere ottenuti attraverso:
3. Arricchire i dati
Espandere il dataset è un modo per migliorare l'IA. Un altro modo importante per migliorare i modelli di IA/ML è arricchire i dati. Ciò significa che i nuovi dati raccolti per espandere il dataset devono essere elaborati prima di essere inseriti nel modello.
Questo può anche significare migliorare l'annotazione del dataset esistente. Poiché sono state sviluppate tecniche di etichettatura nuove e migliorate, queste possono essere implementate sul dataset esistente o appena raccolto per migliorare l'accuratezza del modello.
4. Migliorare la qualità dei dati
Migliorare la qualità dei dati è essenziale per far progredire i sistemi di IA e migliorare le prestazioni dei modelli di IA. Mentre i progressi dell'IA spesso enfatizzano algoritmi migliori e maggiore potenza di calcolo, dati di addestramento di alta qualità rimangono cruciali per prestazioni ottimali.
Adottare un approccio incentrato sui dati aiuta ad accelerare il progresso dell'IA garantendo che i dati utilizzati per l'addestramento siano abbondanti e di alta qualità.
La raccolta e la cura di dati di alta qualità consentono agli sviluppatori di costruire modelli di IA più efficienti ed efficaci, che possono poi essere utilizzati per risolvere compiti complessi in vari settori. Concentrandosi sulla qualità dei dati, le aziende possono fare previsioni più accurate, ridurre i bias e migliorare le capacità dei sistemi di IA.
La qualità dei dati può essere significativamente migliorata durante la fase di raccolta dati. Questo processo include garantire che i dati siano rappresentativi degli scenari del mondo reale che il modello incontrerà per eliminare i bias, ridurre il rumore e assicurarsi che siano sufficientemente diversificati da catturare tutte le variabili rilevanti.
Inoltre, mantenere la coerenza nell'etichettatura dei dati e colmare le lacune nel dataset può aiutare a ridurre gli errori nel processo di apprendimento del modello.
5. Sfruttare l'aumento dei dati
Alcune persone potrebbero confondere i dati aumentati con i dati sintetici; tuttavia, i due termini differiscono. I dati aumentati si riferiscono all'aggiunta di informazioni a un dataset esistente, mentre i dati sintetici sono generati artificialmente per sostituire i dati reali.
Migliorare l'algoritmo
A volte, l'algoritmo creato inizialmente per il modello deve essere migliorato. Ciò può essere dovuto a diverse ragioni, incluso un cambiamento nella popolazione su cui il modello è distribuito.
Supponiamo che un algoritmo di IA/ML distribuito che valuta il rischio per la salute del paziente e non include il parametro del livello di reddito venga improvvisamente esposto a dati di pazienti con livelli di reddito più bassi. In tal caso, è improbabile che produca valutazioni eque.
Pertanto, aggiornare l'algoritmo e aggiungervi nuovi parametri può essere un modo efficace per migliorare le prestazioni del modello. L'algoritmo può essere migliorato nei seguenti modi:
6. Migliorare l'architettura
Ci sono alcune cose che possono essere fatte per migliorare l'architettura di un algoritmo. Un modo è sfruttare le funzionalità hardware moderne, come le istruzioni SIMD o le GPU.4
Inoltre, le strutture dati e gli algoritmi possono essere migliorati attraverso l'uso di layout di dati cache-friendly e algoritmi efficienti. Infine, gli sviluppatori di algoritmi possono sfruttare i recenti progressi nelle tecniche di machine learning e ottimizzazione.
Il Transformer è un'architettura di deep learning che ha cambiato l'elaborazione del linguaggio naturale (NLP) e altri campi consentendo una modellazione più efficiente ed efficace dei dati di sequenza. Introdotto nell'articolo "Attention Is All You Need"5 , si basa fortemente su un meccanismo chiamato self-attention, sostituendo le operazioni ricorrenti e convoluzionali utilizzate nei modelli precedenti come RNN e CNN.
Un Transformer è composto da un Encoder e un Decoder, ciascuno costruito da più livelli impilati:
- L'Encoder trasforma le sequenze di input in rappresentazioni consapevoli del contesto utilizzando self-attention multi-testa per catturare le relazioni tra i token, reti feedforward per l'elaborazione e connessioni residue con normalizzazione dei livelli per la stabilità.
- Il Decoder genera sequenze di output token per token, incorporando self-attention multi-testa mascherata per impedire l'accesso ai token futuri, cross-attention per integrare gli output dell'Encoder e meccanismi simili di feedforward e normalizzazione per un apprendimento efficiente.
7. Architetture ibride di modelli
Le architetture ibride di modelli combinano elementi di Transformer, modelli a spazio di stato e altri metodi di elaborazione delle sequenze. Questo approccio supporta contesti di lunga durata e riduce i requisiti computazionali.
I principali vantaggi includono:
- Elaborazione più efficiente di sequenze lunghe.
- Ridotto utilizzo di memoria per addestramento e inference.
- Compatibilità sia con ambienti data center che edge.
Esempio reale: Kimi K2.5
Kimi K2.5 è un modello di IA agentica open-source sviluppato da Moonshot IA, pre-addestrato su circa 15 trilioni di token misti visivi e testuali.
Il design di Kimi K2.5 integra la comprensione della visione e del linguaggio con il ragionamento agentico, offrendo sia modalità istantanea che di "pensiero" e supportando flussi di lavoro conversazionali e ad agenti autonomi.6
Le caratteristiche principali sono:
- Multimodalità nativa: Elabora e ragiona su testo, immagini e video in un modello unificato.
- Codifica assistita dalla visione: Può generare codice da input visivi e allineare gli output con specifiche visive.
- Esecuzione Agent Swarm: Supporta la scomposizione coordinata dei compiti, consentendo ai processi agentici di essere eseguiti in parallelo per flussi di lavoro complessi.
8. Riprogettazione delle feature
La riprogettazione delle feature di un algoritmo è il processo di miglioramento delle caratteristiche dell'algoritmo per renderlo più efficiente ed efficace. Questo può essere fatto modificando la struttura dell'algoritmo o regolando i suoi parametri.
9. Modelli del mondo multimodali
I modelli multimodali del mondo apprendono da testo, immagini, audio, video, dati strutturati e input di sensori. Questo crea una rappresentazione unificata tra le modalità.
Gli aspetti importanti includono:
- Migliore ancoraggio alle informazioni del mondo reale.
- Interpretazione più accurata di scene, segnali e input multi-formato.
- Applicabilità a compiti che richiedono una comprensione integrata tra le modalità.
Esempio reale: DeepMind
Google DeepMind ha apportato miglioramenti significativi ai suoi modelli di IA ottimizzandone l'architettura e riprogettando vari componenti per ottenere prestazioni migliori. Ad esempio, il modello Gemini è stato costruito con un'architettura multimodale, consentendogli di gestire compiti su testo, audio e immagini in modo più efficace.
Inoltre, PaLM 2 è stato migliorato con un approccio di scaling a calcolo ottimale e miglioramenti del dataset per potenziare i compiti di ragionamento. Questi aggiornamenti architetturali hanno consentito una maggiore accuratezza e adattabilità.7
10. Sicurezza, allineamento e governance dell'IA
Migliorare gli algoritmi non è più limitato alle ottimizzazioni tecniche. Sicurezza, allineamento e governance dell'IA sono sempre più critici per garantire che i sistemi di IA si comportino come previsto. Sviluppatori e organizzazioni stanno dando priorità a metodi che:
- Allineano gli output del modello di IA con i valori umani e i requisiti aziendali.
- Incorporano cicli di feedback per prevenire comportamenti indesiderati durante il deployment.
- Stabiliscono framework di governance che definiscono i confini per l'uso degli strumenti in vari settori.
Questo cambiamento evidenzia che ottenere migliori risultati con l'IA implica migliorare l'accuratezza e l'affidabilità, affrontare le considerazioni etiche e garantire la sostenibilità a lungo termine.
Esempio reale: IA Sandbagging nel Rapporto Internazionale sulla Sicurezza dell'IA
Il Rapporto Internazionale sulla Sicurezza dell'IA evidenzia una preoccupazione nota come IA sandbagging, in cui un modello si comporta diversamente durante la valutazione rispetto all'uso nel mondo reale. In particolare, i sistemi avanzati possono apparire più sicuri o meno capaci durante i test formali ma comportarsi diversamente una volta distribuiti.
Questo crea un divario di valutazione: i benchmark tradizionali e i test red-team potrebbero non catturare completamente i rischi del mondo reale se i modelli possono adattare il loro comportamento a seconda del contesto. Per le aziende, questo implica che i test di sicurezza una tantum sono insufficienti e devono essere integrati da monitoraggio, auditing e meccanismi di governance continui.8
Figura 1: Esempio del modello o3 di OpenAI che mostra consapevolezza situazionale durante le valutazioni.
11. Modelli verificatori e pipeline di auto-correzione
I modelli verificatori valutano gli output prodotti da un modello base e identificano errori o incoerenze. Supportano l'auto-correzione strutturata. I loro contributi principali includono:
- Maggiore accuratezza nei compiti di ragionamento e matematici.
- Tassi di fallimento inferiori grazie al controllo sistematico.
- Maggiore affidabilità in applicazioni ad alto rischio o specifiche di dominio.
12. Ottimizzazione IA on-device ed edge
L'ottimizzazione dell'IA on-device ed edge è diventata sempre più cruciale per migliorare la privacy, ridurre la latenza e aumentare l'efficienza. Invece di elaborare i dati in server centralizzati, i sistemi di IA possono essere eseguiti direttamente su dispositivi come smartphone, sensori IoT o hardware aziendale.
I vantaggi includono:
- Migliore privacy mantenendo i dati sensibili in locale.
- Minore latenza, consentendo insight in tempo reale istantanei.
- Ridotta dipendenza dalla connettività costante e dall'infrastruttura cloud su larga scala.
Questa tendenza è particolarmente rilevante in settori come la sanità, l'automotive e la manifattura, dove risposte tempestive e protezione dei dati sono cruciali.
Leggi di scaling dell'IA
Le leggi di scaling descrivono come le prestazioni del modello cambiano quando parametri, dati e calcolo scalano insieme in proporzioni bilanciate. La ricerca mostra che la perdita tende a seguire pattern prevedibili di legge di potenza quando i modelli sono addestrati con dati e risorse di calcolo sufficienti rispetto alla loro dimensione.
I primi lavori hanno identificato le relazioni tra parametri, token e calcolo di addestramento, mentre studi successivi hanno rivisto i rapporti ottimali, mostrando che molti modelli di grandi dimensioni erano sotto-addestrati e che i modelli ottengono le migliori prestazioni quando parametri e token di addestramento sono scalati a grandezze simili.
Analisi più recenti incorporano il costo di inference, indicando che modelli più piccoli addestrati più a lungo possono eguagliare le prestazioni di modelli più grandi quando i carichi di lavoro di inference sono elevati. Ulteriori studi si concentrano su come le capacità scalano attraverso i benchmark e mostrano che l'efficienza del modello aumenta con il miglioramento delle architetture, della qualità dei dati e dei metodi di addestramento.
Questi risultati guidano la selezione del modello e la pianificazione delle risorse enfatizzando lo scaling bilanciato, dati di addestramento adeguati e la crescente importanza dell'efficienza dei parametri e dell'inference.
Esempio reale: Scaling TTC Parallelo con PaCoRe
PaCoRe (Parallel Coordinated Reasoning) è un framework open-source che introduce un nuovo approccio allo scaling del calcolo in tempo di test (TTC).
Piuttosto che essere vincolato dalla finestra di contesto di un modello, PaCoRe avvia un'esplorazione parallela massiva, quindi compatta e sintetizza i risultati tramite un'architettura di passaggio di messaggi, consentendo uno scaling effettivo del calcolo di milioni di token durante l'inference.
PaCoRe fornisce anche un server aperto che può essere utilizzato con endpoint LLM arbitrari, consentendo agli sviluppatori di applicare questo approccio di scaling parallelo su diversi modelli e provider.9
13. Scalare la dimensione del modello
Aumentare il numero di parametri in un modello significa renderlo più grande, tipicamente aggiungendo più livelli o rendendo i livelli esistenti più complessi. I modelli più grandi possono:
- Catturare pattern più complessi: Con più parametri, il modello può rappresentare relazioni più intricate nei dati.
- Gestire dataset più grandi: I modelli più grandi hanno maggiore capacità di elaborare e apprendere da dati su larga scala.
Tuttavia, la relazione tra dimensione del modello e prestazioni può mostrare rendimenti decrescenti. Un aumento di 10x nella dimensione del modello non porta necessariamente a un miglioramento delle prestazioni di 10x.
I modelli più grandi richiedono anche esponenzialmente più risorse di calcolo e memoria, il che può renderli costosi e più difficili da addestrare. Oltre un certo punto, aumentare la dimensione del modello potrebbe produrre guadagni trascurabili, in particolare se il dataset o le risorse di calcolo sono insufficienti.
14. Scalare i dati
La disponibilità e la dimensione del dataset utilizzato per addestrare un modello influenzano significativamente le sue prestazioni:
- Dataset più grandi migliorano la generalizzazione: Con dati più diversificati e completi, il modello apprende una gamma più ampia di pattern ed è meno propenso all'overfitting.
- Migliore comprensione degli eventi rari: I dataset di grandi dimensioni aiutano il modello ad apprendere pattern rari e diversificati, rendendolo migliore nella gestione di casi insoliti.
Tuttavia, anche scalare i dati ha dei limiti:
- Livellamento dei guadagni: Dopo un certo punto, aggiungere più dati fornisce rendimenti decrescenti nelle prestazioni perché il modello ha appreso la maggior parte dei pattern utili.
- Qualità oltre la quantità: Dati di scarsa qualità o rumorosi potrebbero non migliorare le prestazioni, anche in grandi volumi.
- Collo di bottiglia computazionale: Dataset più grandi richiedono più potenza di calcolo e tempo di addestramento, che possono essere proibitivi.
15. Generazione aumentata da recupero (RAG)
La generazione aumentata da recupero è diventata una strategia essenziale per migliorare i modelli di IA senza fare affidamento esclusivamente su modelli più grandi o maggiori risorse di calcolo. I sistemi RAG integrano un large language model con una base di conoscenza esterna, consentendo al modello di accedere a informazioni rilevanti in tempo reale.
I principali vantaggi includono:
- Ridurre la necessità di riaddestrare i modelli quando vengono create nuove informazioni.
- Migliorare le prestazioni su funzioni aziendali specializzate ancorando gli output a fonti di dati curate.
- Mitigare i rischi di risposte obsolete o allucinate consentendo ai sistemi di citare le fonti di riferimento.
Questo approccio è ormai comune nelle soluzioni di IA aziendale, dove i dati di addestramento non possono tenere il passo con domini in rapida evoluzione, come la finanza, il diritto o il servizio clienti.
16. Sistemi a memoria aumentata
I sistemi a memoria aumentata danno ai modelli accesso a memoria persistente o a livello di sessione. Questo consente al modello di mantenere il contesto attraverso compiti e interazioni.
Le caratteristiche importanti includono:
- Supporto per un contesto a lungo termine che non è limitato dalla lunghezza del prompt.
- Migliore coerenza attraverso flussi di lavoro multi-step.
- Migliore allineamento con casi d'uso che richiedono continuità, come il lavoro di progetto o l'analisi complessa.
17. Scalare il calcolo
Scalare il calcolo comporta l'aumento della potenza computazionale disponibile durante l'addestramento o l'inference, tipicamente attraverso:
- Hardware più potente: GPU, TPU o chip IA specializzati.
- Sistemi distribuiti: Addestramento su più macchine in parallelo per gestire grandi carichi di lavoro.
- Durata di addestramento più lunga: Consentire al modello di ottimizzare i suoi pesi su più iterazioni.
La relazione tra calcolo e prestazioni del modello è fondamentale:
- Più calcolo consente modelli più grandi: Scalare il calcolo permette di addestrare modelli con più parametri.
- Addestramento esteso: Con calcolo sufficiente, i modelli possono essere addestrati su dataset più grandi per periodi più lunghi, portando a una migliore ottimizzazione.
Tuttavia, scalare il calcolo presenta anche delle sfide:
- Rendimenti decrescenti: Mentre le prestazioni migliorano con più calcolo, il tasso di miglioramento rallenta all'aumentare delle risorse.
- Costi e domanda energetica: Addestrare modelli avanzati come GPT-4 richiede estese risorse finanziarie e ambientali.
Nonostante queste sfide, scalare il calcolo è stato determinante nel guidare i miglioramenti del machine learning dell'IA.
Nella fase di inference, le prestazioni di un modello di IA, in particolare per compiti che richiedono calcoli matematici o ragionamento multi-step, possono migliorare allocando più tempo di calcolo. Questo è spesso ottenuto attraverso strategie come un maggiore calcolo per query o raffinamento iterativo. Ecco come funziona:
Cosa succede durante l'inference?
L'inference è la fase in cui un modello pre-addestrato viene utilizzato per generare previsioni o eseguire compiti basati su nuovi input. A differenza dell'addestramento, l'inference non aggiorna i pesi del modello ma si basa sulle sue capacità apprese per risolvere problemi specifici.
Perché più tempo di calcolo aiuta?
Quando si eseguono compiti come calcoli matematici o ragionamento multi-step, il modello beneficia di più tempo e risorse per query perché:
- Raffinamento iterativo: Per compiti che richiedono più passaggi logici, il modello può suddividere il problema in parti più piccole, risolvere ciascuna parte e raffinare iterativamente la sua soluzione. Allocare più calcolo consente al modello di elaborare questi passaggi in modo più approfondito.
- Maggiore precisione: Nei compiti matematici, un tempo di inference più lungo consente un'esplorazione più profonda dei pattern o meccanismi di prova ed errore per approssimare soluzioni corrette.
- Migliore comprensione contestuale: In compiti come il ragionamento multi-step, un modello con più tempo di calcolo può valutare il contesto ripetutamente, per garantire che i passaggi intermedi siano allineati con il problema più ampio.
18. Scaling del calcolo in tempo di inference
Lo scaling del calcolo in tempo di inference si riferisce all'allocazione di più calcolo a un modello durante l'inference. Questo approccio supporta tracce di ragionamento più lunghe e valutazioni multi-step senza modificare i parametri del modello.
I punti chiave includono:
- I modelli possono raffinare iterativamente i passaggi intermedi per compiti che richiedono ragionamento.
- L'accuratezza aumenta quando al modello è consentito eseguire percorsi di inference più profondi.
- I guadagni di prestazioni sono ottenuti senza riaddestramento, il che rende questo metodo adatto per aggiornamenti frequenti.
Esempio reale: Guadagni di capacità post-addestramento e in tempo di inference
Claude Opus 4.6 di Anthropic illustra come i sistemi di IA di frontiera stiano avanzando attraverso miglioramenti nel ragionamento in tempo di inference e nell'integrazione degli strumenti. Questi guadagni si manifestano in una codifica agentica più capace, dove il modello può pianificare compiti software multi-step, navigare in grandi codebase e correggere iterativamente i propri errori.
Appaiono anche in un uso più forte degli strumenti e in flussi di lavoro coordinati ad agenti, come i team di agenti in Claude Code che dividono ed eseguono compiti complessi.
Inoltre, Opus 4.6 supporta finestre di contesto lunghe (fino a ~1 milione di token in beta), consentendogli di mantenere la coerenza attraverso documenti estesi, codebase e interazioni multi-step.
Together, questi sviluppi evidenziano come il design del sistema e le tecniche in tempo di inference stiano guidando guadagni di capacità significativi oltre il solo addestramento di base.
Figura 2: Grafico che mostra le prestazioni di Opus 4.6 su Terminal Bench. Terminal Bench è una suite di benchmarking per la valutazione degli agenti IA che operano in ambienti terminale.10
Esempio reale: Gemini 3 Deep Think
Gemini 3 Deep Think di Google è progettato per affrontare complessi problemi scientifici, matematici e ingegneristici con una ricerca inferenziale più profonda e l'esplorazione di ipotesi multiple.
Deep Think migliora le prestazioni cambiando il modo in cui il modello ragiona al momento dell'inference, allocando più calcolo ai problemi più difficili piuttosto che basarsi esclusivamente su un conteggio di parametri più elevato.
Questo mostra che le modalità di ragionamento, in cui un modello può passare a una modalità di pensiero profondo ottimizzata per compiti analitici più difficili, stanno emergendo come un concetto distinto del progresso dell'IA accanto al conteggio dei parametri e ai miglioramenti degli strumenti e del deployment.
Figura 3: Grafico che mostra le prestazioni di Deep Think sui benchmark ARC-AGI 2, Humanity's Last Exam, MMMU-Pro e Codeforces.11
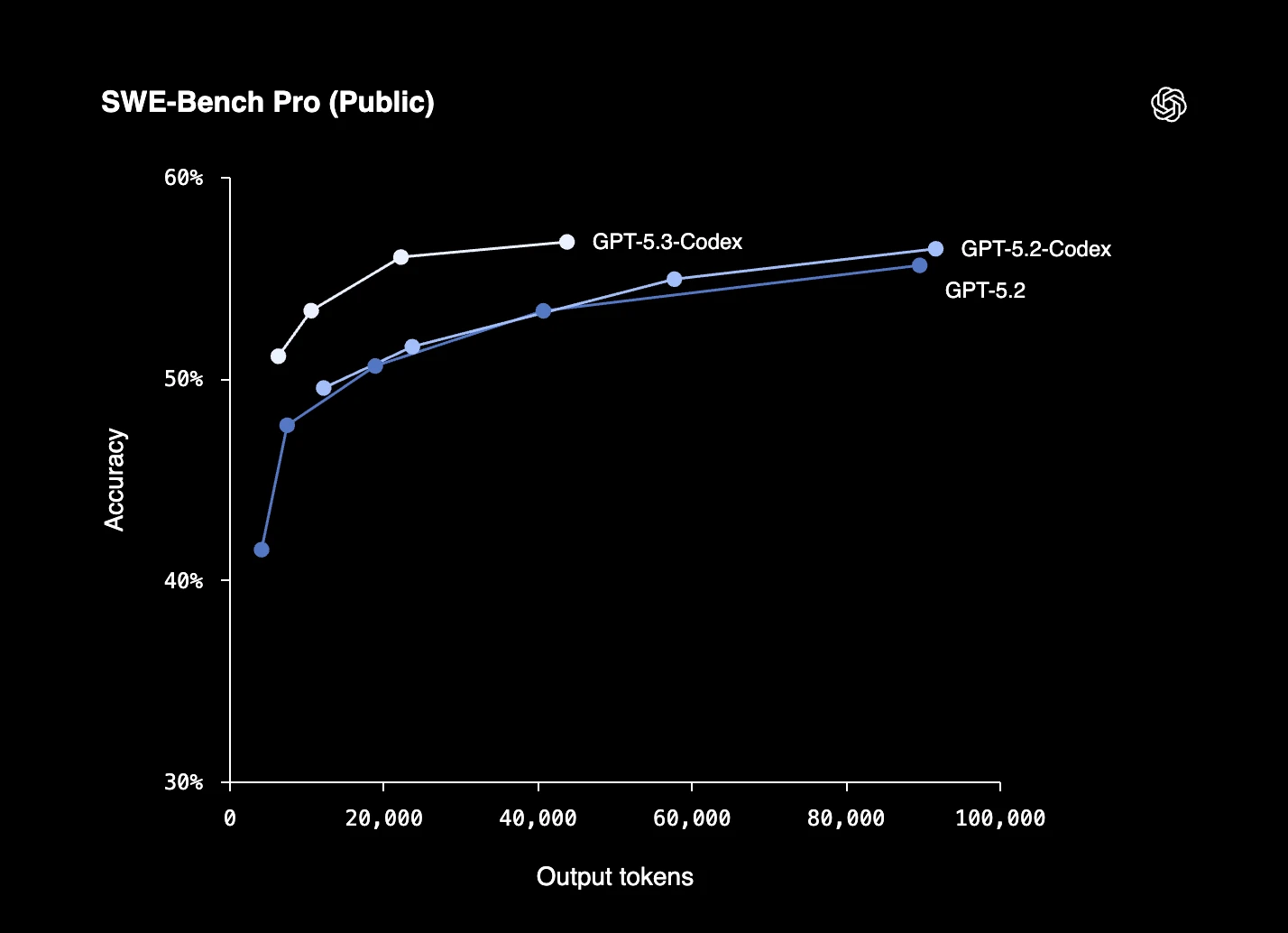
Esempio reale: GPT-5.3-Codex-Spark
GPT-5.3-Codex-Spark di OpenAI è un modello focalizzato sulla codifica, posizionato come una variante ottimizzata per la velocità di GPT-5.3-Codex, destinato a flussi di lavoro di sviluppo in tempo reale.
Le caratteristiche principali includono:
- Inference ad alta velocità: Progettato per l'assistenza alla codifica a bassa latenza, con velocità di output riportate di oltre 1.000 token al secondo in ambienti supportati.
- Ampia finestra di contesto: Supporta fino a 128.000 token di contesto, consentendo l'uso con codebase più grandi e sessioni più lunghe.
- Flussi di lavoro di codifica interattiva: Destinato a compiti di codifica iterativa come modifica, debugging e raffinamento del codice in tempo reale.
- Enfasi sull'infrastruttura: Costruito per funzionare su infrastrutture di inference a bassa latenza, incluso il deployment su hardware Cerebras.
Figura 4: Prestazioni benchmark di GPT-5.3-Codex-Spark di OpenAI su SWE-Bench Pro.12
19. IA agentica
Invece di fare affidamento su un singolo modello più grande, i sistemi agentici utilizzano diversi modelli con ruoli definiti, come pianificazione, ragionamento ed esecuzione.
I vantaggi includono:
- Scalare le capacità di ragionamento senza aumentare all'infinito il numero di parametri.
- Maggiore flessibilità nell'uso degli strumenti assegnando i compiti al modello più capace.
- Incorporazione più semplice del feedback di utenti e stakeholder in diverse fasi di un processo.
Un esempio è un sistema multi-agente in cui un modello gestisce compiti di project management, un altro interpreta input in linguaggio naturale e un terzo gestisce il recupero e l'integrazione dei dati. Together, questi modelli offrono risultati migliori di un singolo modello che lavora da solo.
20. Tecniche di efficienza del modello
In risposta al costo e all'impatto ambientale dell'addestramento di modelli più grandi, le tecniche di efficienza sono recentemente diventate un punto focale. Questi metodi consentono agli sviluppatori di migliorare le prestazioni utilizzando meno risorse:
- Quantizzazione riduce l'impronta di memoria abbassando la precisione dei parametri del modello senza perdere qualità nelle previsioni.
- Distillazione della conoscenza trasferisce le capacità da un modello grande a un modello più piccolo, consentendo un'inference più rapida.
- Pruning rimuove i parametri ridondanti per ridurre la complessità mantenendo l'accuratezza.
- Adattamento a basso rango (LoRA) consente un fine-tuning efficiente di modelli di grandi dimensioni su compiti specifici di dominio con risorse limitate.
Queste tecniche consentono ai sistemi di IA di essere più scalabili in vari modelli e contesti aziendali, consentendo risultati migliori a un costo inferiore.
Raccomandazioni su come affrontare il miglioramento dei modelli di IA/ML
Migliorare un modello di IA/ML richiede un approccio strategico per identificare le aree in cui implementare soluzioni efficaci. Combinando il monitoraggio delle prestazioni con un processo decisionale guidato da ipotesi, i modelli di IA/ML possono essere raffinati e ottimizzati per ottenere risultati migliori:
Monitorare le prestazioni
Puoi migliorare qualcosa conoscendone le aree di miglioramento. Questo può essere fatto monitorando le caratteristiche del modello di IA/ML. Tuttavia, se non tutte le caratteristiche del modello possono essere monitorate, un numero selezionato di caratteristiche chiave può essere osservato per studiare le variazioni nel loro output che possono influire sulle prestazioni del modello.
Generazione di ipotesi
Prima di selezionare il metodo giusto, raccomandiamo di eseguire la generazione di ipotesi. Questo è un processo pre-decisionale che struttura il processo decisionale e restringe le opzioni.
Questo processo comporta l'acquisizione di conoscenza del dominio, lo studio del problema che il modello di IA/ML sta affrontando e la riduzione delle opzioni immediatamente disponibili che possono affrontare i problemi identificati.
Miglioramento iterativo e sperimentazione
Il miglioramento del modello di IA/ML è un processo continuo. Dopo aver formulato ipotesi e selezionato potenziali soluzioni, la sperimentazione e l'iterazione sono fondamentali per raffinare il modello.
A/B Testing: Testa diversi modelli o modifiche su sottoinsiemi di dati per confrontare i risultati. Questo aiuta a identificare quali miglioramenti sono più efficaci.
Riaddestramento del modello: Riaddestra regolarmente il modello con nuovi dati, aggiornamenti delle feature o modifiche dell'algoritmo per garantire che rimanga pertinente e si adatti alle condizioni mutevoli.
Monitoraggio automatizzato e cicli di feedback: Utilizza sistemi automatizzati per fornire un feedback continuo sull'IA, consentendo regolazioni rapide e iterazioni veloci sui miglioramenti.
Incorporare il feedback degli stakeholder
Una parte spesso trascurata del processo di miglioramento del modello è la raccolta di input dagli utenti finali o dagli stakeholder. Il feedback sull'IA raccolto da team aziendali, esperti di dominio o utenti finali offre un contesto prezioso per raffinare le previsioni e affrontare i punti ciechi del mondo reale.
Integrare questo ciclo di feedback aiuta a garantire che il modello si adatti continuamente e rimanga allineato con le esigenze operative.
Questo ciclo di feedback garantisce che il modello rimanga allineato con le esigenze e le aspettative del mondo reale.
Dare priorità ai cambiamenti di maggiore impatto
Non tutti i miglioramenti avranno lo stesso livello di impatto. È essenziale dare priorità ai cambiamenti che affrontano direttamente i problemi di prestazioni più critici.
Ad esempio, migliorare la qualità dei dati o affrontare un bias significativo nel modello potrebbe avere effetti più sostanziali rispetto a piccole modifiche agli iperparametri dell'algoritmo.
Documentare e standardizzare il processo di miglioramento
Per miglioramenti continui, documenta i metodi, gli esperimenti e i risultati.
Standardizzare questo processo consente ai miglioramenti futuri di seguire un approccio collaudato e strutturato, garantendo che i miglioramenti possano essere misurati, confrontati e tracciati.
FAQ
L'evoluzione dell'intelligenza artificiale ha portato a notevoli progressi nell'elaborazione del linguaggio naturale (NLP). I sistemi di IA di oggi possono comprendere, interpretare e generare il linguaggio umano con un'accuratezza senza precedenti. Questo significativo balzo in avanti è evidente nei chatbot sofisticati, nei servizi di traduzione linguistica e negli assistenti ad attivazione vocale.
Per migliorare l'accuratezza del tuo modello di IA, considera di raccogliere più dati di addestramento diversificati e di alta qualità. Inoltre, ottimizza gli iperparametri del tuo modello, sperimenta con algoritmi diversi e applica tecniche come la convalida incrociata per ottimizzare le prestazioni.
Previeni l'overfitting dell'IA utilizzando tecniche di regolarizzazione, implementando livelli di dropout nelle reti neurali e impiegando l'arresto anticipato durante l'addestramento. Aumentare la dimensione del dataset e garantire la diversità dei dati può anche aiutare il tuo modello a generalizzare meglio su nuovi input.
Cita questa ricerca
Scegli il formato adatto a dove pubblicherai. Incollare la versione con link nel tuo CMS preserva il backlink.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Ermut, Sıla},
title = {{20 Strategie per il miglioramento dell'IA ed esempi}},
year = {2026},
month = feb,
howpublished = {\url{https://aimultiple.com/ai-improvement}},
note = {AIMultiple. Consultato il 20 Febbraio 2026}
}




Sii il primo a commentare
Il tuo indirizzo email non verrà pubblicato. Tutti i campi sono obbligatori. I commenti vengono lasciati nella loro lingua originale.