Avaliação de Grandes Modelos de Linguagem em: Mais de 10 Métricas e Métodos
A avaliação de modelos de linguagem de grande porte (LLM, na sigla em inglês) é a avaliação multidimensional desses modelos . Uma avaliação eficaz é crucial para a seleção e otimização de LLMs.
As empresas têm à sua disposição uma variedade de modelos básicos e suas variações, mas alcançar o sucesso é incerto sem uma medição precisa do desempenho. Para garantir os melhores resultados, é fundamental identificar os métodos de avaliação mais adequados, bem como os dados apropriados para treinamento e avaliação.
Consulte as métricas e métodos de avaliação, como lidar com os desafios dos modelos de avaliação atuais e as soluções para mitigá -los.
Para definições e referências rápidas, consulte o glossário de termos-chave .
Principais modelos e métricas para objetivos específicos
Veja os melhores conjuntos de dados e métricas para seus objetivos específicos:
Avaliação | Melhor conjunto de dados de referência | Métrica indispensável |
|---|---|---|
Avaliação Humana Benchmark de codificação de IA múltipla | Correção funcional | |
Eficiência energética e sustentabilidade | Critério de referência para eficiência energética | Consumo de energia |
Conhecimento de nível especializado | O Último Exame da Humanidade (HLE) GPQA | Lembrar |
Conhecimentos gerais | MMLU-Pro | Precisão |
Perguntas e Respostas Verdadeiras | Precisão | |
Instruções seguindo a precisão | Avaliação IFE | Coherence |
Compreensão da linguagem | BBH/Supercola | Perplexity |
Compreensão de contexto de formato longo | LEval | Coherence |
MATEMÁTICA | Precisão | |
Classificação do Open LLM | Classificações Elo |
5 passos para avaliar mestrados em direito
1. Seleção de referência
A melhor forma de usar o LLM é simular tarefas reais que ele enfrentará em produção. No entanto, devido a desafios como a confidencialidade dos dados, você pode não ter acesso a um grande conjunto de tarefas. Nesse caso, é melhor se basear em benchmarks.
Muitas vezes, é necessário combinar diferentes tipos de testes de desempenho para avaliar de forma abrangente o desempenho de um modelo de linguagem. Um conjunto de tarefas de teste é selecionado para abranger uma ampla gama de desafios relacionados à linguagem.
Essas tarefas podem incluir modelagem de linguagem, preenchimento automático de texto, análise de sentimentos , resposta a perguntas, sumarização, tradução automática e muito mais. Os benchmarks de LLM devem representar cenários do mundo real e abranger diversos domínios e complexidades linguísticas. Temos um ranking de LLM com os resultados mais recentes para LLMs de código aberto e proprietários.
A utilização constante dos mesmos métodos e conjuntos de dados de avaliação comparativa pode levar ao sobreajuste (overfitting). Recomendamos atualizar suas métricas de avaliação e benchmarking para obter resultados generalizáveis. Alguns dos conjuntos de dados de avaliação comparativa mais populares são:
- O MMLU-Pro aprimora o conjunto de dados MMLU oferecendo dez opções por pergunta, exigindo mais raciocínio e reduzindo o ruído por meio da revisão de especialistas. 1
- O GPQA apresenta questões desafiadoras elaboradas por especialistas da área, validadas quanto à dificuldade e veracidade, e acessíveis somente por meio de mecanismos de controle para evitar contaminação. 2
- O MuSR consiste em problemas complexos gerados algoritmicamente, que exigem que os modelos usem raciocínio e análise de contexto de longo alcance, com poucos modelos apresentando desempenho melhor do que o aleatório. 3
- MATH é uma compilação de problemas difíceis de competições de nível médio, formatados para garantir consistência, com foco nas questões mais complexas. 4
- O IFEval testa a capacidade dos modelos de seguir instruções e formatações explícitas, utilizando métricas rigorosas de avaliação. 5
- O BBH inclui 23 tarefas desafiadoras do conjunto de dados BigBench, que medem métricas objetivas e compreensão da linguagem, e apresenta boa correlação com a preferência humana. 6
- O HumanEval avalia o desempenho de um LLM na geração de código, com foco particular em sua correção funcional. 7
- O TruthfulQA aborda os problemas de alucinação medindo a capacidade de um profissional com mestrado em direito (LLM) de gerar respostas verdadeiras. 8
- O General Language Understanding Evaluation (GLUE) e o SuperGLUE testam o desempenho de modelos de processamento de linguagem natural (PLN), particularmente para tarefas de compreensão da linguagem. 9
Entre as principais conclusões da pesquisa, destaca-se também a necessidade de melhor avaliação comparativa, colaboração e inovação para ampliar os limites das competências do LLM.
2. Preparação do conjunto de dados
É aceitável o uso de conjuntos de dados personalizados ou de código aberto. O ponto crucial é que o conjunto de dados deve ser recente o suficiente para que os modelos de lógica latente (LLMs) ainda não tenham sido treinados com ele.
Conjuntos de dados cuidadosamente selecionados, incluindo conjuntos de treinamento , validação e teste, são preparados para cada tarefa de benchmark. Esses conjuntos de dados devem ser suficientemente grandes para capturar variações no uso da linguagem, nuances específicas do domínio e potenciais vieses. A curadoria cuidadosa dos dados é essencial para garantir uma avaliação imparcial e de alta qualidade.
3. Treinamento e ajuste fino do modelo
Os modelos treinados como modelos de linguagem de grande escala (LLMs, na sigla em inglês) passam por ajustes finos para melhorar o desempenho em tarefas específicas. O processo normalmente começa com o pré-treinamento em grandes fontes de texto, como a Wikipédia ou o Common Crawl, permitindo que o modelo aprenda padrões e estruturas da linguagem, formando a base para a codificação generativa de IA e a geração de texto semelhante ao humano.
Após o pré-treinamento, os LLMs são ajustados em conjuntos de dados de referência específicos para melhorar o desempenho em tarefas como tradução ou sumarização. Esses modelos variam em tamanho, de pequenos a grandes, e utilizam estruturas baseadas em transformadores. Métodos de treinamento alternativos são frequentemente empregados para ampliar suas capacidades.
4. Avaliação do modelo
Os modelos LLM treinados ou ajustados são avaliados em tarefas de referência usando métricas de avaliação predefinidas. O desempenho dos modelos é medido com base em sua capacidade de gerar respostas precisas, coerentes e contextualmente apropriadas para cada tarefa. Os resultados da avaliação fornecem informações sobre os pontos fortes, as limitações e o desempenho relativo dos modelos LLM.
5. Análise comparativa
Os resultados da avaliação são analisados para comparar o desempenho de diferentes modelos LLM em cada tarefa de referência. Os modelos são classificados com base em seu desempenho geral ou em métricas específicas da tarefa. A análise comparativa permite que pesquisadores e profissionais identifiquem os modelos mais avançados, acompanhem o progresso ao longo do tempo e compreendam os pontos fortes relativos de diferentes modelos para tarefas específicas.
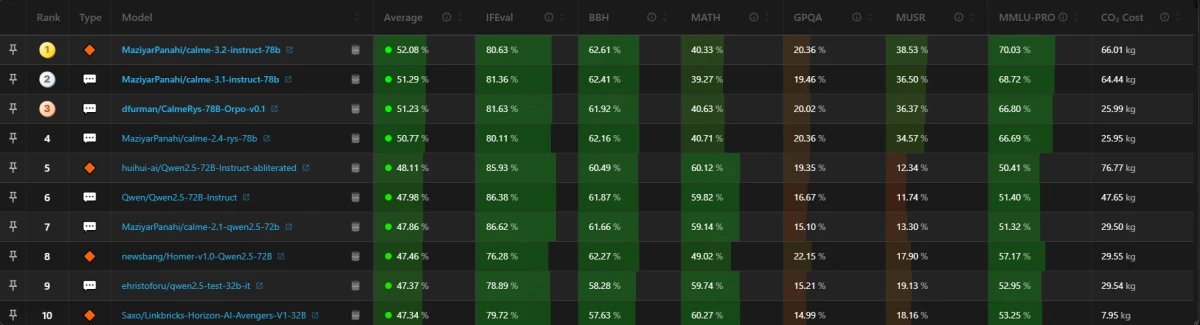
Figura 1: Classificação dos 10 principais modelos de linguagem de grande porte com base em suas métricas de desempenho. 10
Métricas de avaliação
A escolha de um método de avaliação comparativa e de métricas de avaliação para definir os critérios gerais de avaliação com base na finalidade de uso do modelo são tarefas quase simultâneas. Inúmeras métricas são utilizadas para avaliação.
Esses métodos de medição quantitativos ou qualitativos específicos avaliam certas facetas do desempenho do modelo de aprendizagem baseado em aprendizagem (LLM). Com diferentes graus de conexão com avaliações humanas, eles oferecem pontuações numéricas ou categóricas que podem ser monitoradas ao longo do tempo e comparadas entre modelos.
Métricas gerais de desempenho
- A precisão é a porcentagem de respostas corretas em tarefas binárias.
- O recall é o número real de verdadeiros positivos em comparação com os falsos positivos nas respostas do modelo LLM.
- A pontuação F1 combina precisão e recall em uma única métrica. Os valores de F1 variam de 0 a 1, sendo 1 o que representa excelente recall e precisão.
- A latência representa a eficiência e a velocidade do modelo.
- A toxicidade demonstra a imunidade do modelo a conteúdo prejudicial ou ofensivo nas saídas.
- As classificações Elo para modelos de IA classificam os modelos de linguagem com base no desempenho competitivo em tarefas compartilhadas, de forma semelhante à classificação de jogadores de xadrez. Os modelos competem gerando resultados para as mesmas tarefas, e as classificações são ajustadas à medida que novos modelos ou tarefas são introduzidos.
Métricas de desempenho agentivo
É provável que os agentes se tornem os casos de uso mais comuns de LLM (Learning Learning Machines). Portanto, avaliar os LLMs enquanto eles controlam os agentes está se tornando cada vez mais importante:
Taxa de sucesso para tarefas de ponta a ponta (por exemplo, identificar todos os profissionais de crescimento nas empresas que se encaixam no nosso Perfil de Cliente Ideal).
Precisão no uso da ferramenta: frequência com que o modelo chama a API correta com os parâmetros corretos.
Segurança do agente : Com que frequência o agente realizou ações prejudiciais, como excluir um arquivo enquanto tentava resolver uma tarefa.
Métricas específicas do texto
- Coherence é a pontuação do fluxo lógico e da consistência do texto gerado.
- As medidas de diversidade avaliam a variedade e a singularidade das respostas geradas. Isso envolve a análise de métricas como a diversidade de n-gramas ou a medição da similaridade semântica entre as respostas geradas. Pontuações de diversidade mais altas indicam resultados mais diversos e únicos.
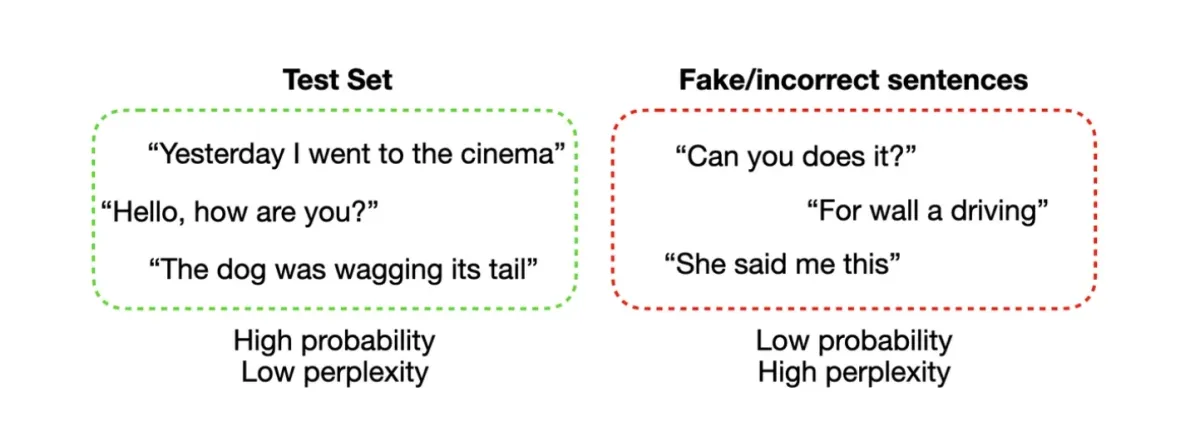
- Perplexity é uma medida usada para avaliar o desempenho de modelos de linguagem. Ela quantifica a precisão com que o modelo prevê uma amostra de texto. Valores de perplexidade mais baixos indicam melhor desempenho.
Figura 2: Exemplos de avaliação de perplexidade.
- BLEU (Bilingual Evaluation Understudy) é uma métrica usada em tarefas de tradução automática. Ela compara a tradução gerada com uma ou mais traduções de referência e mede a similaridade entre elas. As pontuações BLEU variam de 0 a 1, sendo que pontuações mais altas indicam melhor desempenho.
- ROUGE (Recall-Oriented Understudy for Gissing Evaluation) é um conjunto de métricas usado para avaliar a qualidade dos resumos. Ele compara o resumo gerado com um ou mais resumos de referência e calcula a precisão, a revocação e a pontuação F1 (Figura 3). As pontuações ROUGE fornecem informações sobre as capacidades de geração de resumos do modelo de linguagem.
Figura 3: Um exemplo de um processo de avaliação ROUGE. 11
As métricas de avaliação podem ser julgadas por um modelo ou por um humano. Ambas têm suas próprias vantagens e casos de uso:
LLM avaliando LLMs
O LLM avalia a qualidade de seus próprios produtos em um exame conhecido como LLM-como-juiz. Isso pode envolver a comparação de textos gerados por modelos com dados reais ou a mensuração de resultados com métricas estatísticas como acurácia e F1.
O LLM-as-a-judge proporciona às empresas alta eficiência, avaliando rapidamente milhões de resultados a uma fração do custo da revisão humana. É adequado para implantações em larga escala, onde velocidade e otimização de recursos são fatores cruciais para o sucesso, pois é eficaz na avaliação de conteúdo técnico em situações onde revisores qualificados são difíceis de encontrar, permite o monitoramento contínuo da qualidade dos sistemas de IA e produz resultados repetíveis que se mantêm válidos ao longo dos ciclos de avaliação.
Avaliação com participação humana
O processo de avaliação inclui o recrutamento de avaliadores humanos que avaliam a qualidade da saída do modelo de linguagem. Esses avaliadores classificam as respostas geradas com base em diferentes critérios: relevância, fluência, coerência e qualidade geral. Essa abordagem oferece feedback subjetivo sobre o desempenho do modelo.
A avaliação humana continua sendo crucial para aplicações empresariais de alto risco, onde erros podem causar sérios danos às operações ou à reputação da empresa. Os revisores humanos são excelentes em identificar problemas sutis relacionados ao contexto cultural, às implicações éticas e à utilidade prática, que os sistemas automatizados frequentemente ignoram. Eles também atendem aos requisitos regulatórios de supervisão humana em setores sensíveis, como saúde, finanças e serviços jurídicos.
Ferramentas e estruturas de avaliação de LLM
A avaliação do LLM pode ser realizada de duas maneiras: você pode conduzi-la você mesmo usando estruturas de código aberto ou comerciais, ou valores pré-calculados a partir de benchmarks ou resultados de estruturas de código aberto dos modelos base.
Estruturas de código aberto
Estruturas de avaliação abrangentes
Estruturas de avaliação abrangentes são sistemas integrados que fornecem uma variedade de métricas e técnicas de avaliação em um ambiente de teste unificado. Elas geralmente oferecem benchmarks definidos, conjuntos de testes e sistemas de relatórios para avaliar LLMs em uma gama de capacidades e dimensões.
- LEval (Language Model Evaluation) é uma estrutura para avaliar modelos de linguagem de longo prazo (LLMs) quanto à compreensão de contextos extensos. 12 LEval é um conjunto de testes de referência com 411 questões distribuídas em oito tarefas, com contextos que variam de 5.000 a 200.000 tokens. Ele avalia o desempenho de modelos na recuperação de informações e no raciocínio com documentos extensos. O conjunto inclui tarefas como sumarização acadêmica, geração de documentos técnicos e coerência em diálogos com múltiplas interações, permitindo que pesquisadores testem modelos em aplicações práticas, em vez de tarefas linguísticas isoladas.
- Prometheus é uma estrutura de código aberto que utiliza LLMs como juízes com estratégias de estímulo sistemáticas. 13 Ele foi projetado para produzir pontuações de avaliação que estejam alinhadas com as preferências e o julgamento humanos.
abordagens de teste
As abordagens de teste são técnicas metodológicas para organizar e realizar avaliações que não dependem de métricas ou instrumentos específicos. Elas especificam delineamentos experimentais, técnicas de amostragem e filosofias de teste que podem ser aplicadas em diferentes contextos.
- Os fluxos de trabalho de avaliação de DAG (Deep Acyclic Graph) usam grafos acíclicos direcionados para representar os processos de avaliação, embora não seja uma ferramenta de avaliação específica.
- O teste de prompts dinâmicos avalia os modelos expondo-os a cenários reais e em constante evolução que simulam a interação do usuário. Esse método avalia como os modelos respondem a consultas complexas e com múltiplas camadas, bem como a prompts ambíguos.
- A estrutura de avaliação comparativa de eficiência energética e de hardware mede o consumo de energia e a eficiência computacional dos modelos durante o treinamento e a inferência. Ela se concentra em métricas de sustentabilidade, como emissões de carbono e consumo de energia.
Plataformas de avaliação comercial
As plataformas de avaliação comercial são soluções fornecidas pelos fornecedores com recursos de conformidade, integração com pipelines MLOps e interfaces amigáveis, destinadas a casos de uso corporativos. Frequentemente, possuem recursos de monitoramento e representam um equilíbrio entre profundidade técnica e acessibilidade para partes interessadas não técnicas.
- DeepEval (Confident AI) é uma estrutura de testes voltada para desenvolvedores que ajuda a avaliar aplicações LLM usando métricas predefinidas de precisão, viés e desempenho. Ela se integra a pipelines de CI/CD para testes automatizados.
- O Azure AI Studio Evaluation (Microsoft) oferece ferramentas de avaliação integradas para comparar diferentes modelos e prompts, com recursos de rastreamento automático de métricas e coleta de feedback humano.
- O Prompt Flow (Microsoft) é uma ferramenta de desenvolvimento para criar, avaliar e implantar aplicativos LLM. Seus recursos de avaliação integrados permitem testes sistemáticos em diversos modelos e prompts.
- LangSmith (LangChain) é uma plataforma para depuração, teste e monitoramento de aplicações LLM, com recursos para comparação de modelos e rastreamento de caminhos de execução.
- TruLens (TruEra) é um conjunto de ferramentas de código aberto para avaliar e explicar aplicações de LLM (Learning Learning and Modeling), com recursos para rastrear alucinações, relevância e fundamentação.
- O Vertex AI Studio (Google) fornece ferramentas para testar e avaliar as saídas do modelo, com métricas automáticas e recursos de avaliação humana dentro do ecossistema de IA da Google.
- O Amazon Bedrock inclui recursos de avaliação para modelos básicos, permitindo que os desenvolvedores testem e comparem diferentes modelos antes da implantação.
- A Parea AI é uma plataforma para avaliar e monitorar aplicações de Aprendizado de Máquina de Liderança (LLM, na sigla em inglês), com foco específico na qualidade dos dados e no desempenho do modelo.
Indicadores de referência pré-avaliados
Os benchmarks pré-avaliados fornecem informações valiosas usando métricas específicas, tornando-os particularmente úteis para análises orientadas por métricas. Nosso site apresenta benchmarks para os principais modelos, ajudando você a avaliar o desempenho de forma eficaz. Os principais benchmarks incluem:
- Alucinação – Avalia a precisão e a consistência factual do conteúdo gerado.
- Codificação com IA – Avalia a capacidade de codificação, a correção e a execução.
- Raciocínio de IA – Avalia a capacidade de inferência lógica e resolução de problemas.
Além disso, o OpenLLM Leaderboard oferece um sistema de avaliação comparativa em tempo real que avalia modelos em conjuntos de dados disponíveis publicamente. Ele agrega pontuações de tarefas como tradução automática, sumarização e resposta a perguntas, fornecendo uma comparação dinâmica e atualizada do desempenho do modelo.
Casos de uso de avaliação
1. Avaliação de desempenho
Considere uma empresa que precisa escolher entre vários modelos para seu modelo generativo empresarial base. Esses modelos de linguagem natural (LLMs) devem ser avaliados para determinar sua capacidade de gerar texto e responder a entradas. As métricas de avaliação de desempenho podem incluir precisão , fluência , coerência e relevância ao assunto .
Com o advento de grandes modelos multimodais , as empresas também podem avaliar modelos que processam e geram múltiplos tipos de dados, como imagens , texto e áudio , expandindo o escopo e as capacidades da IA generativa .
2. Comparação de modelos
Uma empresa pode ter aperfeiçoado um modelo para obter maior desempenho em tarefas específicas do seu setor. Uma estrutura de avaliação ajuda pesquisadores e profissionais a comparar LLMs e mensurar o progresso, auxiliando-os na seleção do modelo mais adequado para uma determinada aplicação. A capacidade da avaliação de LLMs de identificar áreas de desenvolvimento e oportunidades para sanar deficiências pode resultar em uma melhor experiência do usuário, menos riscos e até mesmo uma possível vantagem competitiva.
3. Detecção e mitigação de viés
Os modelos de aprendizado de máquina (LLMs) podem apresentar vieses em seus dados de treinamento, o que pode levar à disseminação de informações errôneas, representando um dos riscos associados à IA generativa . Uma estrutura de avaliação abrangente ajuda a identificar e mensurar vieses nos resultados dos LLMs, permitindo que pesquisadores desenvolvam estratégias para detecção e mitigação de vieses.
4. Satisfação e confiança do usuário
A avaliação da satisfação e da confiança do usuário é crucial para testar modelos generativos de linguagem. Relevância, coerência e diversidade são avaliadas para garantir que os modelos correspondam às expectativas do usuário e inspirem confiança. Essa estrutura de avaliação auxilia na compreensão do nível de satisfação e confiança do usuário nas respostas geradas pelos modelos.
5. Avaliação dos sistemas RAG
A avaliação LLM pode ser usada para avaliar a qualidade das respostas geradas por sistemas de geração aumentada por recuperação (RAG) . Vários conjuntos de dados podem ser utilizados para verificar a precisão das respostas.
Quais são os desafios comuns dos métodos de avaliação de LLM existentes?
Embora os métodos de avaliação existentes para Modelos de Linguagem de Grande Porte (LLMs) forneçam informações valiosas, eles são imperfeitos. Os problemas comuns associados a eles são:
Sobreajuste
A Scale AI descobriu que alguns modelos de lógica de aprendizagem (LLMs) estão sofrendo de sobreajuste em benchmarks populares de IA. Para isso, criaram o GSM1k, uma versão reduzida do benchmark GSM8k para testes matemáticos. Os LLMs apresentaram desempenho inferior no GSM1k em comparação ao GSM8k, indicando uma falta de compreensão genuína. Essas descobertas sugerem que os métodos atuais de avaliação de IA podem ser enganosos devido ao sobreajuste, ressaltando a necessidade de métodos de teste adicionais, como o GSM1k.
Falta de métricas diversificadas
As técnicas de avaliação utilizadas atualmente para Modelos de Aprendizagem Baseados em Aprendizagem (LLMs) frequentemente não capturam toda a gama de diversidade e inovação dos resultados. A importância crucial de produzir respostas diversas e criativas é, por vezes, negligenciada pelas métricas tradicionais que enfatizam a precisão e a relevância. A pesquisa sobre o problema da avaliação da diversidade nos resultados de LLMs ainda está em andamento. Embora a perplexidade meça a capacidade de um modelo de antecipar o texto, ela ignora elementos cruciais como coerência, consciência contextual e relevância. Portanto, depender apenas da ambiguidade não oferece uma avaliação completa da qualidade real de um LLM.
Subjetividade e alto custo das avaliações humanas
A avaliação humana é um método valioso para avaliar os resultados de grandes modelos de linguagem (LLMs). No entanto, pode ser subjetiva, tendenciosa e significativamente mais cara do que as avaliações automatizadas. Diferentes avaliadores humanos podem ter opiniões divergentes e os critérios de avaliação podem ser inconsistentes. Além disso, a avaliação humana pode ser demorada e dispendiosa, especialmente em avaliações de grande escala. Os avaliadores frequentemente discordam ao avaliar aspectos subjetivos, como utilidade ou criatividade, o que dificulta o estabelecimento de uma verdade fundamental confiável para a avaliação.
Viéses em avaliações automatizadas
As avaliações de modelos de aprendizagem linear (LLM) sofrem de vieses previsíveis. Apresentamos um exemplo para cada viés, mas os casos opostos também são possíveis (por exemplo, alguns modelos podem favorecer os últimos itens).
- Viés de ordem : os primeiros itens são preferidos.
- Desvanecimento da compaixão : nomes são preferidos em vez de palavras-código anônimas.
- Viés de ego : respostas semelhantes são favorecidas.
- Viés de saliência : respostas mais longas são preferidas.
- Efeito de adesão : a crença da maioria é preferida.
- Viés de atenção : Prefere-se compartilhar informações irrelevantes.
Dados de referência limitados
Alguns métodos de avaliação, como BLEU ou ROUGE, requerem dados de referência para comparação. No entanto, obter dados de referência de alta qualidade pode ser um desafio, especialmente quando existem múltiplas respostas aceitáveis ou em tarefas abertas. Dados de referência limitados ou tendenciosos podem não capturar toda a gama de resultados aceitáveis do modelo.
Generalização para cenários do mundo real
Os métodos de avaliação normalmente se concentram em conjuntos de dados ou tarefas de referência específicos que não refletem totalmente os desafios das aplicações no mundo real. A avaliação de conjuntos de dados controlados pode não ser generalizável para contextos diversos e dinâmicos onde os LLMs são implementados.
Ataques adversários
Os modelos de aprendizado de máquina (LLMs) podem ser suscetíveis a ataques adversários, como manipulação de previsões e envenenamento de dados, nos quais entradas cuidadosamente elaboradas podem induzir o modelo ao erro ou iludi-lo. Os métodos de avaliação existentes geralmente não levam em conta esses ataques, e a avaliação de robustez continua sendo uma área ativa de pesquisa.
Além desses problemas, os modelos generativos de IA para empresas podem enfrentar dificuldades com questões legais e éticas , o que pode afetar os LLMs (Licensed Liability Management - Gestão de Liderança Jurídica) em sua empresa.
Complexidade e custo da avaliação multidimensional
Os Grandes Modelos de Linguagem (LLMs) devem ser avaliados em várias dimensões, como precisão factual, toxicidade e viés. Isso geralmente envolve concessões, o que dificulta o desenvolvimento de sistemas de pontuação unificados. Uma avaliação completa desses modelos em múltiplas dimensões e conjuntos de dados exige recursos computacionais substanciais, o que pode limitar o acesso para organizações menores.
Melhores práticas para superar problemas nos métodos de avaliação do LLM
Pesquisadores e profissionais estão explorando diversas abordagens e estratégias para lidar com os problemas relacionados aos métodos de avaliação de desempenho de grandes modelos de linguagem. Embora o uso de todas essas abordagens em cada projeto possa ser proibitivamente caro, o conhecimento dessas boas práticas pode aumentar o sucesso dos projetos de modelos de linguagem de grande porte.
Dados de treinamento conhecidos
Utilize modelos básicos que compartilham seus dados de treinamento para evitar contaminação.
Múltiplas métricas de avaliação
Em vez de se basear apenas na perplexidade, incorpore múltiplas métricas de avaliação para uma análise mais abrangente do desempenho do LLM. Métricas como essas podem capturar melhor os diferentes aspectos da qualidade do modelo:
- Fluência
- Coherence
- Relevância
- Diversidade
- Compreensão do contexto
Avaliação humana aprimorada
Diretrizes claras e critérios padronizados podem melhorar a consistência e a objetividade da avaliação humana. O uso de múltiplos avaliadores humanos e a realização de verificações de confiabilidade interavaliadores podem ajudar a reduzir a subjetividade. Além disso, a avaliação por crowdsourcing pode fornecer perspectivas diversas e avaliações em maior escala.
Dados de referência diversos
Criar dados de referência diversificados e representativos para melhor avaliar os resultados dos mestrados em direito. A curadoria de conjuntos de dados que abranjam uma ampla gama de respostas aceitáveis, o incentivo a contribuições de diversas fontes e a consideração de vários contextos podem aprimorar a qualidade e a abrangência dos dados de referência.
Incorporando múltiplas métricas
Incentive a geração de respostas diversas e avalie a singularidade do texto gerado por meio de métodos como diversidade de n-gramas ou medidas de similaridade semântica.
Avaliação no mundo real
Aprimorar os métodos de avaliação com cenários e tarefas do mundo real pode melhorar a generalização do desempenho do LLM. Utilizar conjuntos de dados de avaliação específicos do domínio ou da indústria pode fornecer uma avaliação mais realista das capacidades do modelo.
Avaliação de robustez
A avaliação da robustez dos Modelos de Aprendizagem Baseada em Lógica (LLMs) contra ataques adversários é uma área de pesquisa em andamento. O desenvolvimento de métodos de avaliação que testem a resiliência do modelo a diversas entradas e cenários adversários pode aprimorar a segurança e a confiabilidade dos LLMs.
Aproveite o LLMOps
A LLMOps , uma divisão especializada da MLOps , dedica-se ao desenvolvimento e aprimoramento de LLMs. Utilizar a LLMOps para testar e personalizar LLMs em sua empresa não só economiza tempo, como também minimiza erros.
Exemplos práticos de avaliação de LLM
Diversas organizações compartilharam suas experiências práticas com a avaliação de mestrados em Direito (LLM):
Considerações éticas na avaliação do LLM
Embora as métricas de desempenho e a comparação com benchmarks sejam cruciais, as empresas também devem considerar as implicações éticas da avaliação do LLM. Estas incluem:
- Equidade: Os modelos podem produzir resultados tendenciosos que refletem problemas sistêmicos em seus dados de treinamento. As estruturas de avaliação devem mensurar o viés em diferentes dados demográficos, contextos e aplicações.
- Transparência: Documentar claramente os conjuntos de dados, os critérios de avaliação e as limitações do modelo aumenta a confiança e a responsabilidade.
- Responsabilidade: As empresas que implementam LLMs devem garantir que seus processos de avaliação estejam alinhados com as estruturas legais e regulatórias relevantes, particularmente nos setores de saúde , finanças e governo .
- Implantação responsável : as avaliações devem medir não apenas a precisão, mas também o impacto social, a segurança e o potencial de uso indevido. Isso pode incluir testes de intrusão e testes adversários para expor os riscos.
Ao incorporar considerações éticas em seus modelos de avaliação, as organizações podem mitigar riscos à reputação, garantir a conformidade e fomentar a confiança dos usuários.
Tendências recentes na avaliação de LLM
A pesquisa em avaliação de LLM está evoluindo rapidamente. Algumas tendências notáveis incluem:
- Benchmaxxing : Modelos como o Llama 4 foram ajustados em excesso às preferências do público em comunidades como o LMArena. Isso foi conseguido enviando vários modelos para a comunidade e escolhendo o mais popular. O modelo falhou em apresentar bons resultados em tarefas do mundo real. 14
- Avaliação multimodal: À medida que os modelos se expandem para além do texto, incluindo imagens, áudio e vídeo, as estruturas de avaliação estão sendo ampliadas para testar a compreensão e a geração multimodal.
- Criação dinâmica de benchmarks: em vez de conjuntos de dados estáticos que podem levar ao sobreajuste dos modelos, os pesquisadores estão desenvolvendo benchmarks adaptativos que evoluem (por exemplo, conjuntos de testes específicos do domínio gerados automaticamente).
- LLM-como-juiz 2.0: Estratégias aprimoradas de estímulo e avaliações de raciocínio estão possibilitando avaliações automatizadas mais confiáveis e que se alinham melhor com os julgamentos humanos.
- Avaliação comparativa com foco em energia: Indicadores de referência voltados para a sustentabilidade , que avaliam o custo do carbono e a eficiência energética, estão ganhando força.
- Estruturas de Red Teaming: Os testes adversários sistemáticos estão se tornando parte integrante dos processos de avaliação, permitindo a mensuração da robustez contra manipulação e comportamentos inseguros.
O que pensam os principais pesquisadores sobre as avaliações?
A confiança está se deteriorando em avaliações que já não são capazes de avaliar com precisão o desempenho do modelo:
Glossário de termos-chave
Para leitores que são novos na área, aqui está uma referência rápida às principais métricas de avaliação:
- Perplexity: Uma medida de quão bem o modelo prevê o texto; quanto menor, melhor.
- BLEU (Bilingual Evaluation Understudy): mede a sobreposição entre traduções automáticas e traduções humanas.
- ROUGE (Recall-Oriented Understudy for Gisting Evaluation): Compara resumos gerados por máquina com referências escritas por humanos.
- Precisão: Proporção de resultados corretos em relação ao total de resultados.
- Recordação: Capacidade de recuperar resultados relevantes dentre todos os resultados corretos possíveis.
- Pontuação F1: Média harmônica da precisão e da recordação.
- Coherence: Fluxo lógico e consistência do texto gerado.
- Diversidade: Singularidade e variabilidade das saídas do modelo, frequentemente medidas com n-gramas ou similaridade semântica.
- Classificação Elo: Um sistema de classificação competitivo adaptado do xadrez para comparar modelos diretamente.
Conclusão
A avaliação de grandes modelos de linguagem é crucial ao longo de todo o seu ciclo de vida, abrangendo a seleção, o ajuste fino e a implantação segura e confiável. À medida que as capacidades dos modelos de linguagem aumentam, torna-se inadequado depender exclusivamente de uma única métrica (como a perplexidade) ou de um benchmark. Portanto, uma estratégia multidimensional que integre pontuações automatizadas (por exemplo, BLEU/ROUGE, verificações de consistência factual), avaliações humanas estruturadas (com diretrizes específicas e concordância entre avaliadores) e testes personalizados para viés, imparcialidade e toxicidade é vital para avaliar tanto o desempenho quantitativo quanto os riscos qualitativos.
No entanto, desafios significativos persistem. Benchmarks públicos podem levar ao sobreajuste em conjuntos de dados já bastante explorados, enquanto avaliações com intervenção humana são demoradas e complexas de escalar. Entradas adversárias expõem lacunas de robustez, e modelos com alto consumo de energia levantam preocupações quanto à sustentabilidade. Para solucionar esses problemas, é necessário criar conjuntos de testes diversos e específicos para cada domínio; integrar testes de estresse com equipes vermelhas e adversários; implementar pipelines com modelos de aprendizado de máquina (LLM) como avaliadores para uma avaliação rápida e econômica; e monitorar os custos de energia e inferência juntamente com as métricas de precisão.
Ao incorporar essas melhores práticas em uma estrutura LLMOps, as organizações podem manter uma visão robusta e contínua do comportamento do modelo em produção. Essa estratégia de avaliação holística mitiga riscos como viés, alucinação e vulnerabilidades de segurança, garantindo que os LLMs forneçam resultados confiáveis e de alto impacto à medida que evoluem.
Perguntas frequentes
Geralmente, as organizações empregam uma combinação de métricas de avaliação predeterminadas que abrangem uma ampla gama de competências ao avaliar modelos de aprendizagem de linguagem (LLMs). A avaliação quantitativa do desempenho do modelo é fornecida por meio de medições automatizadas, como a precisão em benchmarks padronizados (por exemplo, Massive Multitask Language Understanding, Stanford Question Answering Dataset). Estruturas de avaliação completas também incluem avaliação humana para avaliar fatores qualitativos, como utilidade e considerações éticas. A abordagem mais confiável integra o julgamento humano com métricas automatizadas, avaliando situações de avaliação específicas do contexto, geração aumentada por recuperação e a capacidade do modelo de aderir a modelos de instruções, mantendo-se alinhado com a verdade fundamental.
No processo de avaliação de LLMs (Modelos de Aprendizado de Liderança), os conjuntos de dados de avaliação têm uma função fundamentalmente diferente dos dados de treinamento. Os conjuntos de dados de avaliação avaliam a compreensão geral e a capacidade de generalização do modelo, enquanto os dados de treinamento instruem o modelo. Uma ampla variedade de casos de uso, incluindo situações típicas e circunstâncias extremas que podem testar a arquitetura do modelo, deve ser representada em conjuntos de dados de avaliação eficazes. Os conjuntos de dados de avaliação, ao contrário dos dados de treinamento, precisam ser cuidadosamente selecionados para evitar contaminação (sobreposição com os dados de treinamento) e devem conter uma variedade de instâncias que avaliem o modelo em diversos aspectos, como lógica, factualidade e comportamento ético. A principal distinção é que os conjuntos de dados de avaliação oferecem critérios imparciais pelos quais diferentes LLMs podem ser comparados sistematicamente.
A avaliação mais completa do desempenho de um modelo de linguagem é obtida por meio de uma combinação de testes offline (experimentos controlados) e avaliação online (avaliação em tempo real com usuários reais). Os testes online expõem problemas que podem não aparecer em ambientes controlados, mostrando como o modelo se comporta em cenários reais e imprevisíveis. Enquanto isso, os testes offline com benchmarks estabelecidos possibilitam comparações confiáveis entre modelos e versões. Juntos, eles produzem uma avaliação resumida que abrange tanto a utilidade prática do modelo quanto suas capacidades técnicas. Essa abordagem dupla é especialmente crucial ao avaliar grandes modelos de linguagem para uso em sistemas de inteligência artificial, onde o desempenho deve ser confiável em uma ampla gama de circunstâncias e questões éticas exigem testes rigorosos antes do lançamento público.
Leitura complementar
Saiba mais sobre o ChatGPT para entender melhor os LLMs lendo o seguinte:
- Transformação da IA: 6 estratégias práticas para alcançar o sucesso
- Casos de uso, benefícios e desafios do ChatGPT na área da educação
- Como usar o ChatGPT para negócios: 40 principais aplicações
- GPT-5: Guia detalhado
Cite esta pesquisa
Escolha o formato adequado ao local onde você vai publicar. Colar a versão com link no seu CMS preserva o backlink.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{Avaliação de Grandes Modelos de Linguagem em: Mais de 10 Métricas e Métodos}},
year = {2026},
month = may,
howpublished = {\url{https://aimultiple.com/large-language-model-evaluation}},
note = {AIMultiple. Retrieved Maio 22, 2026}
}

Seja o primeiro a comentar
Seu endereço de e-mail não será publicado. Todos os campos são obrigatórios. Os comentários são deixados em seu idioma original.