Compare Modelos de Fundação Relacionais
Fizemos benchmark do SAP-RPT-1-OSS contra boosting de gradiente (LightGBM, CatBoost) em 17 conjuntos de dados tabulares abrangendo o espectro semântico-numeral, tabelas de baixa/alta semântica, conjuntos de dados mistos de negócios e grandes conjuntos de dados numéricos de baixa semântica.
Nosso objetivo é medir onde os priores semânticos pré-treinados de um LLM relacional podem fornecer vantagens sobre modelos de árvore tradicionais e onde enfrentam desafios sob escala ou estrutura de baixa semântica.
SAP-RPT-1-OSS vs. Boosting de Gradiente: Resultados do benchmark
- Taxa de Sucesso: Representa a pontuação normalizada média (0,0 a 1,0). Uma barra mais alta indica que o modelo está consistentemente mais próximo do melhor desempenho possível para conjuntos de dados naquela categoria.
- 100 – 500 linhas (3 Conjuntos de Dados):
- Incluídos: wine (178), sonar (208), vote (435).
- Resultado: O SAP teve o melhor desempenho em 2 de 3 conjuntos de dados. Ele alcançou as pontuações mais altas em wine e sonar, sugerindo que os priores de LLM podem ser benéficos quando os dados de treinamento são escassos. No entanto, o CatBoost garantiu uma vitória estreita no conjunto de dados vote (dentro de 0,1%), indicando que os modelos de árvore permanecem altamente competitivos mesmo em pequenas escalas.
- 501 – 1.000 linhas (3 Conjuntos de Dados):
- Incluídos: cylinder_bands (540), breast_cancer (569), credit_g (1.000).
- Resultado: O SAP teve o melhor desempenho em todos os 3 conjuntos de dados. Em cylinder_bands, o SAP superou o LightGBM por uma margem de 5,5%, possivelmente devido a um melhor manuseio de descrições semânticas de defeitos industriais, embora estudos de ablação adicionais seriam necessários para confirmar esse mecanismo.
- 1.000 – 10.000 linhas (5 Conjuntos de Dados):
- Incluídos: titanic (1,3K), car_evaluation (1,7K), spambase (4,6K), compas (5,2K), employee_salaries (9,2K).
- Resultado: O SAP alcança os melhores resultados em 4 de 5 conjuntos de dados, performando particularmente bem em tarefas ricas em texto como spambase e titanic. No entanto, o CatBoost supera significativamente o SAP em compas em 10,4%, indicando características específicas do conjunto de dados que favorecem modelos de árvore mesmo nesta faixa de tamanho.
- 10.000+ linhas (6 Conjuntos de Dados):
- Incluídos: california_housing (20K), house_sales (21K), default_credit (30K), adult_income (48K), diamonds (53K), higgs_100k (98K).
- Resultado: À medida que o volume de dados cresce, a vantagem potencial de "conhecimento prévio" do LLM diminui. O LightGBM e o CatBoost alcançam os melhores resultados em 5 de 6 conjuntos de dados, oferecendo melhor precisão a uma fração do custo computacional. A única exceção, california_housing, mostra apenas uma vantagem modesta de 1,7% para o SAP.
1. Tabela de conjuntos de dados dos resultados do benchmark
Abaixo está a divisão completa do desempenho do modelo em todos os 17 conjuntos de dados.
2. Análise de custo e eficiência
Calculamos o custo computacional direto para cada modelo com base nos preços da instância H200 do RunPod de $3,59/hora.
O SAP-RPT-1-OSS incorre em custos significativamente mais altos devido ao tempo necessário para o pré-processamento de incorporação de texto e à alta sobrecarga de memória da arquitetura do LLM. Em contraste, o LightGBM e o CatBoost concluem as tarefas quase instantaneamente neste hardware. Os custos abaixo refletem o tempo total de relógio (pré-processamento + treinamento) para uma execução de validação cruzada de 3 dobras.
Custo médio por conjunto de dados (Média de 17 Conjuntos de Dados)
Detalhamento de custos por tamanho do conjunto de dados
- Conjuntos de Dados Pequenos (<1K linhas): O SAP é relativamente barato (≈ $0,03 por execução). A alta taxa de vitória aqui torna o custo insignificante.
- Conjuntos de Dados Grandes (>20K linhas): O SAP torna-se caro.
- Exemplo: Treinar em adult_income (48k linhas) leva ≈$12 minutos no total para 3 dobras.
- Custo: 12 min X $0,06/min = $0,72 por experimento.
- Comparação: O LightGBM conclui a mesma tarefa por $0,01.
Conclusão: Embora $0,22 por conjunto de dados não seja caro em termos absolutos, o SAP é 22 vezes mais caro que a linha de base. Essa diferença de custo pode ser justificada para pequenos conjuntos de dados ricos em semântica onde o SAP mostra melhorias significativas de precisão (por exemplo, cylinder_bands com +5,5% de aumento), mas torna-se mais difícil de justificar para grandes conjuntos de dados onde os modelos de árvore alcançam desempenho igual ou melhor a uma fração do custo.
3. Estrutura de análise: O Espectro Semântico
Para interpretar esses resultados, é crucial entender como selecionamos os dados. Não escolhemos conjuntos de dados aleatoriamente; curamos uma suíte de 17 conjuntos de dados especificamente escolhidos para abranger o Espectro Semântico-Numerical.
Nossa hipótese central era que o SAP (sendo baseado em LLM) se destacaria onde os dados têm significado linguístico, enquanto os modelos de árvore dominariam no cálculo numérico bruto. Categorizamos nossos conjuntos de dados em três clusters distintos:
Cluster A: Conjuntos de dados de alta semântica (6 conjuntos de dados)
Características: Recursos contêm descrições ricas em texto, rótulos categóricos com significado do mundo real (por exemplo, "congelamento de taxas médicas") ou terminologia específica do domínio.
- Conjuntos de Dados:
- cylinder_bands: Defeitos de impressão industrial.
- titanic: Nomes e títulos de passageiros.
- vote: Registros de votação do Congresso (Categorias "Sim/Não" sobre políticas).
- breast_cancer: Descrições de tumores médicos.
- spambase: Frequências de palavras de e-mail.
- wine: Origens químicas.
Cluster B: Dados mistos de negócios (6 conjuntos de dados)
Características: O formato tabular padrão encontrado na maioria dos bancos de dados empresariais, uma mistura de valores numéricos (salário, idade) e strings categóricas (título do cargo, raça, departamento).
- Conjuntos de Dados:
- employee_salaries: Títulos de cargo vs. salário.
- compas: Histórico criminal e demografia (Atributos sensíveis).
- adult_income: Demografia do censo.
- credit_g: Perfis de risco de crédito alemão.
- default_credit: Dados de inadimplência de crédito de Taiwan.
- car_evaluation: Parâmetros de compra de veículos.
Cluster C: Dados de baixa semântica/puros numéricos (5 conjuntos de dados)
Características: Recursos são medições abstratas, leituras de sensores ou coordenadas de física. Os nomes das colunas muitas vezes não importam; apenas as relações matemáticas importam.
- Conjuntos de Dados:
- higgs_100k: Cinemática de partículas de física.
- diamonds: Dimensões físicas e preço.
- sonar: Saltos de energia de frequência.
- california_housing: Coordenadas Lat/Long e estatísticas do censo.
- house_sales: Imóveis do Condado de King (principalmente recursos numéricos).
4. Análise aprofundada: Onde o SAP vence vs. falha
Aplicar a estrutura de análise aos nossos resultados revela quatro padrões de desempenho distintos. A tabela abaixo resume exatamente onde o SAP se destaca e onde falha.
Fundamentos conceituais de modelos de fundação relacionais
O objetivo principal de um modelo de fundação relacional é fazer previsões precisas e realizar tarefas diversas sobre tabelas estruturadas. Esses modelos devem entender como a informação é representada em diferentes tabelas, como as entidades estão vinculadas por meio de relacionamentos e como a informação temporal influencia os resultados.
As capacidades principais de tais modelos incluem:
- Generalização de esquema: A capacidade de se adaptar a novos esquemas relacionais sem retreinamento do zero.
- Representação unificada de entrada: Lidar com diferentes tipos de coluna, como recursos numéricos, categóricos e textuais.
- Integração de contexto temporal e estrutural: Capturar dependências ao longo do tempo e entre entidades vinculadas por chaves primárias e estrangeiras.
- Transferibilidade: Realizar tarefas preditivas em novos conjuntos de dados por meio de pré-treinamento e aprendizado zero-shot.
Griffin
O Griffin é uma das primeiras tentativas em grande escala de construir um modelo de fundação relacional unificado. Ele representa dados relacionais como um grafo temporal heterogêneo, onde cada linha se torna um nó e as arestas correspondem a relacionamentos de chave estrangeira. As características principais incluem:
Codificador de recursos unificado
- Recursos categóricos e de texto são codificados com um codificador de texto pré-treinado, enquanto valores numéricos usam um codificador float aprendido.
- Metadados, como nomes de tabelas, nomes de colunas e tipos de arestas, são incorporados para ajudar o modelo a reconhecer o esquema relacional.
- Incorporações de tarefa permitem que um único modelo realize tarefas de regressão e classificação com decodificadores compartilhados.
Passagem de mensagens e atenção
O Griffin integra redes neurais de passagem de mensagens com um módulo de atenção cruzada. O componente de passagem de mensagens agrega informações dentro e entre relações, enquanto a atenção cruzada foca em células relevantes dentro de cada linha. Este design ajuda o modelo a lidar com dados diversos e manter o contexto entre entidades conectadas.
Pré-treinamento e fine-tuning
O modelo é pré-treinado em conjuntos de dados de tabela única por meio de uma tarefa de conclusão de célula mascarada e depois fine-tuned em bancos de dados relacionais para tarefas específicas. Experimentos em grandes benchmarks relacionais mostram que o Griffin supera as bases tradicionais de GNN e modelos de tabela única tanto em precisão quanto em eficiência de aprendizado de transferência.
Figura 1: Gráfico mostrando a Estrutura do Modelo Griffin.1
Relational transformer
Enquanto o Griffin foca na agregação de grafos, o Relational Transformer (RT) aplica arquiteturas de transformer diretamente a bancos de dados relacionais. Ele trata cada célula como um token enriquecido com seu valor, nome da coluna e nome da tabela.
Representação de entrada
Cada token combina:
- Uma incorporação de valor que depende do seu tipo de dado (numérico, texto ou data/hora).
- Uma incorporação de esquema é gerada a partir do texto da tabela e da coluna.
- Um token de máscara é usado quando o valor está oculto durante o pré-treinamento.
Esta estrutura permite que o RT processe bancos de dados relacionais com esquemas diferentes, mantendo um formato de entrada consistente.
Atenção relacional
O RT introduz um mecanismo de atenção relacional que opera no nível da célula. Ele inclui:
- Atenção de coluna para aprender distribuições de valor dentro das colunas.
- Atenção de recurso para combinar atributos dentro da mesma linha ou linhas pai vinculadas.
- Atenção de vizinho para agregar informações de linhas filhas conectadas.
Juntas, essas camadas de atenção formam um transformer de grafo relacional que modela dependências entre linhas, colunas e tabelas.
Resultados de treinamento e transferência
O RT é pré-treinado em bancos de dados relacionais do RelBench. Em experimentos, o modelo pré-treinado alcançou até 94% do desempenho de modelos totalmente supervisionados em configurações zero-shot. Ele também aprendeu mais rápido durante o fine-tuning, exigindo menos etapas de treinamento para alcançar alta precisão.2
Esta abordagem sugere que bancos de dados relacionais compartilham padrões transferíveis entre domínios e que a tokenização no nível da célula fornece uma base prática para tarefas preditivas em dados estruturados.
RelBench
O RelBench foi projetado para avançar o aprendizado profundo relacional, que foca no aprendizado de ponta a ponta a partir de dados distribuídos em várias tabelas relacionadas em bancos de dados relacionais.
Como os bancos de dados relacionais permanecem o sistema de gerenciamento de dados dominante em toda a indústria e ciência, o RelBench fornece uma estrutura padronizada e reproduzível para avaliar modelos que operam diretamente em estruturas relacionais, em vez de depender de achatamento manual de recursos.
As versões anteriores do RelBench introduziram 11 bancos de dados relacionais abrangendo domínios como saúde, redes sociais, e-commerce e esportes, com 70 tarefas preditivas projetadas para serem desafiadoras e relevantes para o domínio.3
Em janeiro de 2026, o RelBench v2 foi lançado, adicionando quatro novos bancos de dados (SALT, RateBeer, arXiv e MIMIC-IV) e 40 tarefas preditivas adicionais, incluindo uma nova classe de tarefas de Autocompletar que avaliam a capacidade de um modelo de prever colunas existentes dentro de um banco de dados relacional.
O lançamento também expandiu o acesso a dados por meio da integração CTU, permitindo acesso a mais de 70 conjuntos de dados relacionais via ReDeLEx; adicionou conectividade direta a banco de dados SQL; e incorporou sete conjuntos de dados do repositório 4DBInfer no formato RelBench.
Além de conjuntos de dados e tarefas, o RelBench fornece uma implementação de referência de código aberto para aprendizado profundo relacional baseada em redes neurais de grafos, usando PyTorch Geometric para construção de grafos e PyTorch Frame para modelagem tabular, juntamente com um leaderboard público para acompanhar o progresso.
O lançamento v2 também introduziu várias melhorias de usabilidade e desempenho, incluindo rótulos opcionais censurados por tempo, suporte à métrica NDCG em previsão de links, geração mais rápida de incorporação de sentença e gerenciamento de cache configurável.4
VIEIRA
O VIEIRA adota uma abordagem diferente, focando na programação com modelos de fundação em vez de construir um único motor preditivo. Ele estende o compilador de lógica probabilística SCALLOP com uma linguagem declarativa que integra modelos de linguagem grandes, modelos de visão e outros componentes pré-treinados como predicados estrangeiros.5
Paradigma relacional
No VIEIRA, os modelos de fundação são tratados como funções sem estado com entradas e saídas relacionais. Isso permite compor modelos como GPT, CLIP ou SAM de acordo com regras lógicas. Por exemplo:
- Um programa pode usar o GPT para extrair conhecimento de texto e armazená-lo como relações estruturadas.
- O CLIP pode classificar imagens e vinculá-las a rótulos textuais em uma tabela.
Aplicações
A estrutura suporta:
- Raciocínio de data e matemática usando GPT.
- Raciocínio de parentesco usando extração de texto e inferência lógica.
- Resposta a perguntas que combina recuperação e raciocínio.
- Resposta a perguntas visuais e edição de imagens por meio de composição multimodal.
Unificando lógica simbólica e inferência neural, o VIEIRA permite que analistas de dados e desenvolvedores construam sistemas interpretáveis que usam modelos de fundação pré-treinados para responder a consultas preditivas sobre dados estruturados e imagens.
Estudos de caso
SAP Hana Cloud
O SAP HANA Cloud é um banco de dados como serviço (database-as-a-service) nativo da nuvem e totalmente gerenciado, projetado para atuar como uma fundação de dados unificada para aplicações empresariais que combinam transações, análises e IA. Em vez de servir como um banco de dados relacional de propósito único, o SAP HANA Cloud é posicionado como uma plataforma multi-modelo que permite que as organizações construam "aplicações de dados inteligentes" sobre dados operacionais de negócios.
O SAP HANA Cloud combina processamento em memória com armazenamento baseado em disco e integração de data lake para suportar diferentes requisitos de desempenho e custo. Este design flexível suporta cargas de trabalho em tempo real enquanto escala dinamicamente à medida que os volumes de dados e o uso flutuam.
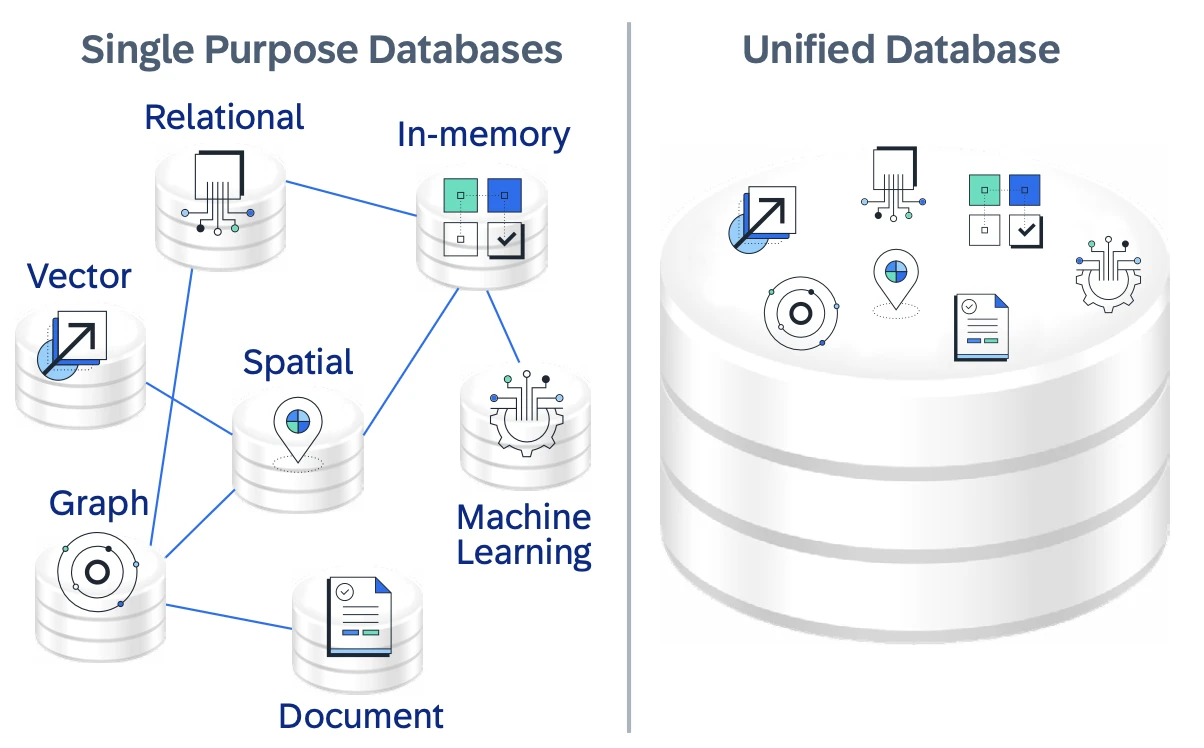
Um diferencial chave é seu motor nativo multi-modelo, que suporta dados relacionais, JSON/documento, grafo, espacial e vetorial dentro de um único banco de dados. Isso permite que aplicações combinem consultas SQL, relacionamentos de grafo e pesquisa de similaridade vetorial sem mover dados entre sistemas separados, simplificando assim a arquitetura e reduzindo a latência.
Como parte da SAP Business Technology Platform, o SAP HANA Cloud integra-se diretamente com fontes de dados SAP e não-SAP, incluindo acesso ao vivo sem replicação, e fornece segurança, disponibilidade e conformidade de nível empresarial por padrão.
No geral, o SAP HANA Cloud é uma plataforma de dados nativa de IA e centrada em relacional, na qual o banco de dados relacional serve como a camada fundamental para análises, dados multi-modelo e aplicações empresariais de IA.
Figura 2: Imagem mostrando o banco de dados unificado do Hana e
processamento de dados multi-modelo.6
sap-rpt-1 da SAP
O sap-rpt-1 introduz um único modelo de fundação relacional que realiza uma ampla gama de tarefas preditivas por meio de aprendizado em contexto. Em vez de retreinar um novo modelo para cada caso de uso, os usuários fornecem alguns exemplos de seu padrão alvo, como "clientes que pagaram em dia" e "clientes que pagaram atrasados". O modelo então reconhece o padrão e imediatamente produz previsões precisas para novos dados.
O modelo é projetado com um mecanismo de atenção bidimensional que captura relacionamentos entre linhas e colunas, enquanto também incorpora metadados, como nomes de tabelas e colunas, em incorporações vetoriais. Este design permite que ele entenda a semântica de esquemas relacionais e a informação temporal dentro de tabelas de negócios.
A abordagem da SAP traz várias vantagens para analistas de dados e usuários de negócios:
- Um único modelo que funciona em várias tabelas e domínios.
- Nenhuma necessidade de fine-tuning repetido ou desenvolvimento personalizado.
- Acesso a insights preditivos em minutos em vez de semanas.
- Integração com data warehouses existentes e sistemas SAP.
Ao incorporar o sap-rpt-1 dentro do ecossistema SAP, especialistas de negócios podem interagir diretamente com seus próprios dados e receber previsões por meio de interfaces intuitivas. O resultado é um caminho mais rápido de dados estruturados para decisões acionáveis sem engenharia de recursos manual.
Figura 3: Fator de redução de erro do sap-rpt-1-large versus bases de IA estreita em domínios da SAP.
No final de 2025, a SAP confirmou que o SAP-RPT-1 está geralmente disponível através do hub de IA generativa na SAP IA Foundation (SAP IA Core).
O modelo é oferecido em duas variantes de produção:
- SAP-RPT-1-small, otimizado para previsões de baixa latência e alta vazão,
- SAP-RPT-1-large, projetado para priorizar a precisão preditiva.
Este lançamento formaliza o papel do SAP-RPT-1 como um modelo de fundação implantável dentro da pilha de IA empresarial da SAP, em vez de uma capacidade apenas de pesquisa.
Além disso, a SAP oferece o SAP-RPT Playground, um ambiente no-code baseado na web, onde os usuários podem testar o aprendizado em contexto usando seus próprios dados ou dados de amostra fornecidos pela SAP.
SAP-ABAP-1
O SAP-ABAP-1 é um modelo de fundação projetado para suportar casos de uso de produtividade de desenvolvedor baseados em IA para clientes e parceiros da SAP.
Ele está disponível através do hub de IA generativa da SAP e é treinado em mais de 250 milhões de linhas de código ABAP, 30 milhões de linhas de código CDS e documentação técnica extensa. O modelo é otimizado para entender e explicar código ABAP, destacar melhores práticas e fornecer acesso a conhecimento de desenvolvimento SAP atualizado.
A SAP oferece acesso de teste gratuito ao SAP-ABAP-1 via hub de IA generativa, com capacidades adicionais planejadas para lançamento em 2026.7
KumoRFM da Kumo.IA: um transformer de grafo relacional para análises preditivas
A Kumo.IA, fundada pelo professor de Stanford Jure Leskovec, criou o KumoRFM, um modelo de fundação relacional que usa um transformer de grafo relacional para analisar bancos de dados relacionais e data warehouses. Ele representa dados relacionais como um grafo temporal heterogêneo, onde cada entidade é um nó e chaves primárias e estrangeiras formam arestas entre tabelas.
Esta abordagem baseada em grafos permite que o KumoRFM aprenda de várias tabelas simultaneamente e se adapte a novos esquemas relacionais. O modelo é pré-treinado em diversas fontes de dados e pode generalizar para novos conjuntos de dados sem construir modelos separados para cada tarefa preditiva.
O KumoRFM pode ser usado através de diferentes interfaces dependendo da experiência do usuário:
- PQL (Linguagem de Consulta Preditiva): Uma linguagem de consulta especializada para definir consultas preditivas em dados estruturados.
- Interface de linguagem natural: Para usuários não técnicos, entradas em linguagem natural são automaticamente traduzidas em consultas PQL.
- SDK Python: Permite que desenvolvedores integrem o modelo em pipelines e aplicações de IA empresariais.
A arquitetura KumoRFM amostra dinamicamente o banco de dados para criar subgrafos de contexto e subgrafos de previsão. Esses subgrafos são processados pelo transformer de grafo relacional, que captura dependências e informações temporais entre entidades relacionadas. Através do aprendizado em contexto, o modelo fornece previsões precisas e pode explicar seu processo de raciocínio.
A Kumo oferece duas opções de implantação adequadas para ambientes empresariais:
- Plataforma SaaS: Um serviço baseado em nuvem construído sobre Apache Spark para fácil acesso e escalabilidade
- Nativo de data warehouse: Permite que as organizações usem seus próprios dados no Snowflake ou Databricks sem movê-los para fora de seu ambiente seguro
Diferente de grafos de conhecimento tradicionais que exigem definição manual de esquema, o KumoRFM constrói automaticamente seu grafo relacional a partir de fontes estruturadas. Isso o torna bem adequado para comércio eletrônico, finanças e saúde, onde relacionamentos, padrões temporais e contexto em evolução são essenciais para previsões confiáveis.
As capacidades principais do KumoRFM incluem:
- Flexibilidade entre diferentes tabelas e estruturas de esquema.
- Compatibilidade com uma variedade de tipos de coluna e identificadores personalizados.
- Adaptação a tarefas específicas durante o tempo de inferência.
- Alta precisão e interpretabilidade em tarefas preditivas.
Figura 4: A imagem mostra como os Modelos de Fundação Relacionais (RFMs) funcionam em vários domínios, como comércio eletrônico, finanças e saúde, para fazer previsões, fornecer explicações e avaliar resultados.8
Metodologia do benchmark
Configuração e ambiente do benchmark
Para garantir comparações justas entre árvores limitadas por CPU e modelos acelerados por GPU, utilizamos um ambiente de alto desempenho capaz de lidar com ambos eficientemente.
- Hardware: Instância RunPod com uma NVIDIA H200 140GB GPU.
- Software: Python 3.12 com bibliotecas fixadas para reprodutibilidade:
- scikit-learn 1.5.2, lightgbm 4.5.0, catboost 1.2.7
- torch 2.5.1, pandas 2.2.3, numpy 2.1.3
- sap-rpt-oss (Fonte: GitHub Oficial)
- Reprodutibilidade: random_state=42 foi usado consistentemente em todas as divisões, inicializações e modelos.
Conjuntos de dados: O espectro semântico
Avaliamos os modelos em 17 conjuntos de dados de aprendizado supervisionado provenientes do OpenML e Scikit-Learn. Em vez de seleção aleatória, curamos esta suíte para abranger o "Espectro Semântico-Numerical", testando a hipótese de que LLMs se destacam onde os recursos contêm significado linguístico em vez de apenas estatísticas brutas.
O inventário:
- Pequenos e semânticos (<1K linhas):
- wine (178), sonar (208), vote (435), cylinder_bands (540), breast_cancer (569).
- Médios/mistos (1K – 10K linhas):
- credit_g (1K), titanic (1,3K), car_evaluation (1,7K), spambase (4,6K), compas (5,2K), employee_salaries (9,2K).
- Grandes/numéricos (10K+ linhas):
- california_housing (20K), house_sales (21K), default_credit (30K), adult_income (48K), diamonds (53K), higgs (amostrado para 100K).
Tarefas cobertas:
- 11 tarefas de Classificação Binária
- 2 tarefas de Classificação Multiclasse
- 4 tarefas de Regressão
Configurações do modelo e pré-processamento
Visamos uma "comparação de praticante" realista, usando padrões fortes em vez de ajuste exaustivo de hiperparâmetros.
LightGBM & CatBoost
Para garantir uma comparação justa contra o modelo SAP computacionalmente pesado, aumentamos os estimadores padrão robustos.
- LightGBM: n_estimators=500, learning_rate=0.05, num_leaves=31. Roda em CPU (n_jobs=-1).
- CatBoost: iterations=500, learning_rate=0.05, depth=6. Roda em GPU (task_type="GPU").
- Pré-processamento: Codificação de Rótulo simples para categóricos; nenhuma escala para numéricos; imputação mediana/moda para valores ausentes.
SAP-RPT-1-OSS
Configuramos o SAP para equilibrar desempenho e custo com base em nossos experimentos de configuração preliminares.
- Configuração: max_context_size=4096, bagging=4.
- Nota:
- Contexto: Testar em adult_income mostrou que aumentar o contexto de 4096 para 8192 triplicou o tempo de execução (4 min para 12 min) para ganho de precisão insignificante (0,917 vs 0,917 ROC-AUC).
- Bagging: Aumentar o bagging de 4 para 8 (configuração padrão do SAP usada no artigo9 ) ofereceu retornos decrescentes.
- Pré-processamento: Nenhum. O DataFrame bruto do pandas é passado diretamente. O modelo codifica usando incorporações de texto (sentence-transformers/all-MiniLM-L6-v2).
Protocolo de avaliação
Estratégia de validação cruzada
Utilizamos Validação Cruzada de 3 Dobras com embaralhamento.
- Reduzimos o padrão de 5 dobras para 3 dobras para acomodar os tempos de inferência lentos do SAP (economia de 40% de tempo) mantendo a validade estatística.
- Divisão: StratifiedKFold para classificação; K-Fold Padrão para regressão.
Métricas e diagnósticos
Vamos além da simples precisão para capturar uma visão holística do desempenho do modelo:
- Métricas de classificação primárias: ROC-AUC (Binária), Precisão Balanceada (Multiclasse), R² (Regressão).
- Diagnósticos secundários: Acompanhamos o coeficiente de correlação de Matthews (MCC) e a perda logarítmica para garantir que as vitórias não fossem artefatos de desequilíbrio de classe, e o MAPE para calibração de erro de regressão.
- Cálculo de custo: Baseado no tempo total de relógio (pré-processamento + treinamento + inferência) na instância RunPod H200 ($3,59/h).
Significância estatística
Aplicamos um teste de postos sinalizados de Wilcoxon (p<0,05) a comparações de modelos em pares para determinar se as diferenças de desempenho eram estatisticamente significativas ou ruído aleatório.
Limitações e validade interna
Aceitamos explicitamente as seguintes restrições em nossa metodologia:
- Configurações padronizadas vs ajuste: Utilizamos configurações padrão fixas e fortes para todos os modelos em vez de realizar otimização exaustiva de hiperparâmetros (por exemplo, CV aninhado ou varreduras Optuna). Embora isso garanta uma linha de base consistente, vale notar que os modelos de árvore muitas vezes veem ganhos de desempenho com ajuste específico do conjunto de dados, o que poderia estreitar as margens no cluster "Competitivo".
- Limites de escala de dados: Nossa análise focou em conjuntos de dados abaixo de 100k linhas para simular cenários típicos de empresas de médio porte. Observamos a vantagem do LLM diminuindo à medida que o volume de dados crescia, mas não estendemos os testes para escalas de milhões de linhas onde a latência de inferência e o custo provavelmente se tornariam as restrições principais.
- Uniformidade de infraestrutura: Para manter um ambiente de teste consistente, executamos todos os modelos no mesmo hardware NVIDIA H200. O LightGBM e o CatBoost são altamente otimizados para CPUs de commodity; portanto, em um ambiente de produção dedicado apenas a modelos de árvore, a diferença de custo provavelmente seria maior.
- Generalização além da semântica: Nossa hipótese de "Espectro Semântico" previu com sucesso muitos resultados, mas o forte desempenho do LLM em conjuntos de dados abstratos como sonar e california_housing sugere capacidades além da compreensão linguística. Isso indica que o modelo também pode estar aproveitando padrões de regularização de alta dimensão, um fenômeno que merece mais investigação além do escopo deste estudo inicial.
Cite esta pesquisa
Escolha o formato adequado ao local onde você vai publicar. Colar a versão com link no seu CMS preserva o backlink.
@misc{ermut2026,
author = {Ermut, Sıla and Sarı, Ekrem},
title = {{Compare Modelos de Fundação Relacionais}},
year = {2026},
month = jul,
howpublished = {\url{https://aimultiple.com/relational-foundation-model}},
note = {AIMultiple. Acessado em 2 Julho 2026}
}


 funcionam em vários domínios.")
Seja o primeiro a comentar
Seu endereço de e-mail não será publicado. Todos os campos são obrigatórios. Os comentários são deixados em seu idioma original.