Comparativa de herramientas de revisión de código de IA
Con el aumento del uso de herramientas de codificación con IA, las bases de código se han vuelto más propensas a vulnerabilidades, lo que aumentó la necesidad de revisiones de código efectivas. Para abordar esto, presentamos RevEval (IA Code Review Eval), que evalúa comparativamente las cuatro principales herramientas de revisión de código de IA en 309 solicitudes de extracción de repositorios de diferentes tamaños y evalúa su rendimiento utilizando la información de 10 desarrolladores y un LLM como juez.
Resultados de la comparativa
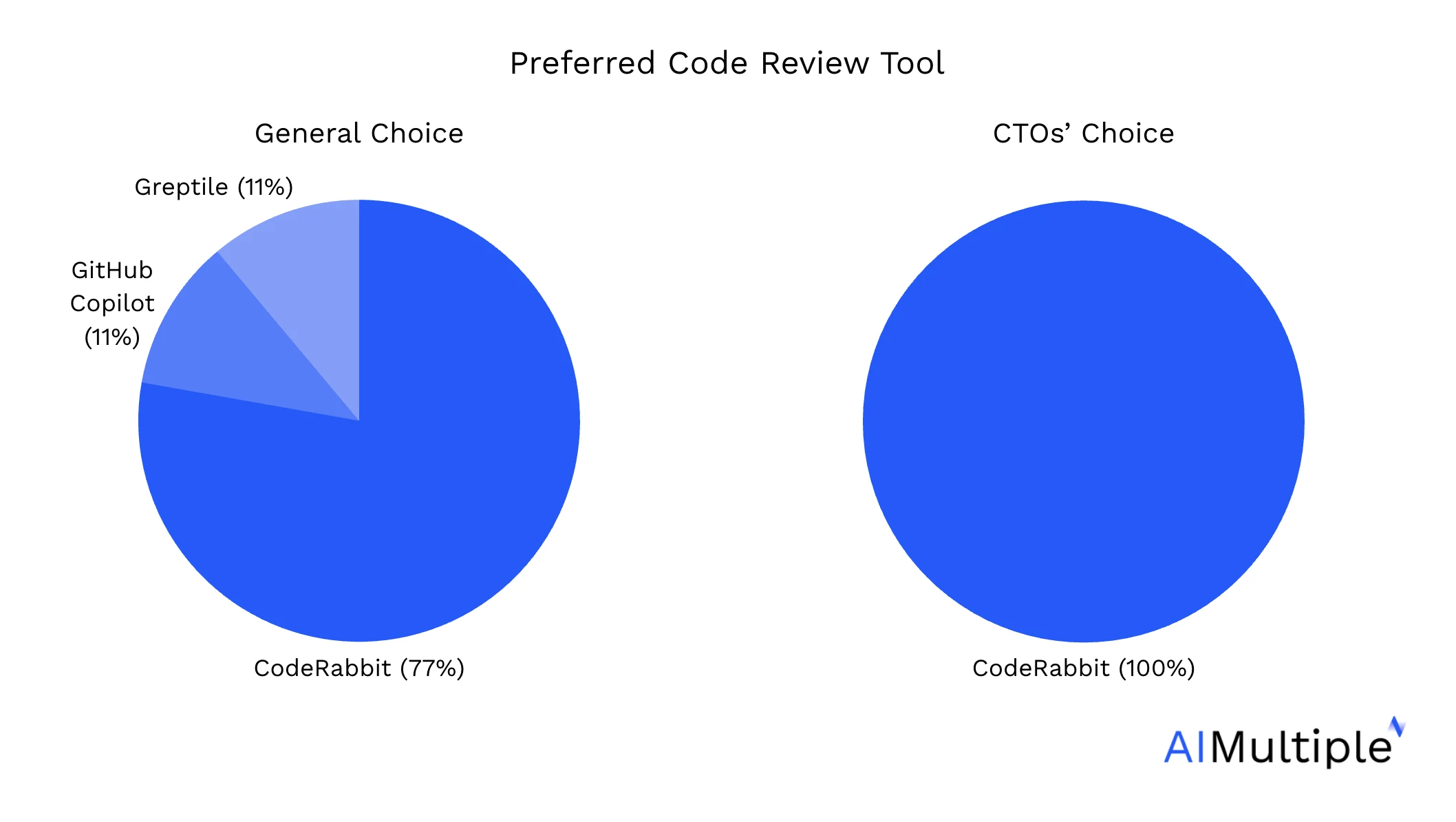
CodeRabbit se clasificó como la herramienta de revisión de código más exitosa en el 51% de las 309 PR:
Para medir la clasificación, utilizamos las puntuaciones del LLM como juez. Examinamos qué herramienta de revisión de código de IA obtuvo la puntuación más alta en cada PR (puntuado mediante nuestro LLM como juez), y luego calculamos el porcentaje de todas las PR en las que cada herramienta se clasificó en primer lugar.
CodeRabbit obtuvo la puntuación más alta tanto en las evaluaciones manuales humanas como en las evaluaciones del LLM como juez, seguido de Greptile y GitHub Copilot:
Al calcular la puntuación media, las tres categorías de evaluación se ponderaron por igual. Las puntuaciones de los repositorios grandes y pequeños fueron evaluadas por el LLM como juez, y las evaluaciones de los desarrolladores se completaron manualmente para verificar dos veces las puntuaciones del LLM como juez.
Evaluaciones humanas
Preguntamos a los desarrolladores que participaron en las evaluaciones qué herramienta de revisión de código de IA preferirían integrar en sus flujos de trabajo. Dado que los CTO desempeñan un papel clave en la toma de decisiones en el desarrollo de software, destacamos sus respuestas en un gráfico separado:
Comparación detallada
Calculamos el número medio de errores por PR contando todos los errores/problemas notificados por cada herramienta de revisión de código y dividiendo por el número total de PR (309). No todas las PR de nuestra base de código contienen errores o problemas. GitHub Copilot no informa explícitamente cuando detecta un error en una PR; por lo tanto, se excluyó de esta comparación.
Puedes consultar nuestra metodología a continuación.
Características
* La proporciona la función “agentic pre-merge checks” de CodeRabbit. Valida automáticamente las solicitudes de extracción con respecto a los estándares de calidad y los requisitos organizativos personalizados antes de la fusión, y devuelve resultados de aprobado/reprobado con explicaciones directamente en el recorrido de la PR. Cada verificación puede configurarse para advertir a los desarrolladores o bloquear las fusiones por completo. Si bien GitHub Copilot, Cursor BugBot y Greptile ofrecen funciones de revisión de PR, funcionan como sistemas de asesoramiento que ofrecen comentarios y sugerencias en lugar de marcos de validación sistemáticos.
** Cursor y GitHub Copilot pueden ofrecer más capacidades más allá de sus componentes de revisión de código; solo se incluyen en nuestra comparativa las características de Cursor Bugbot y GitHub Copilot Code Review.
Las funciones varían según los planes de suscripción, por lo que algunas funciones marcadas como disponibles arriba pueden no estar disponibles en tu suscripción.
En las revisiones de código automatizadas, CodeRabbit, GitHub Copilot y Cursor Bugbot fueron más fáciles de configurar que Greptile porque las revisiones de código automatizadas no se pueden habilitar para un repositorio vacío en Greptile.
Análisis en profundidad de las características
CodeRabbit
- 40+ linters y escáneres de seguridad integrados.
- Instrucciones personalizadas basadas en patrones AST.
- Se adapta a los comentarios de los desarrolladores con el tiempo.
- Los desarrolladores pueden etiquetar a @coderabbitai para hacer preguntas de seguimiento, solicitar correcciones o cuestionar recomendaciones.
- Soporta servidores MCP personalizados para contexto adicional.
GitHub Copilot Code Review
- El botón “Implement suggestion” deriva al agente de codificación Copilot.
- Integración estrecha con el ecosistema de GitHub.
- Instrucciones personalizadas mediante copilot-instructions.md.
Greptile
- Aprende los estándares de codificación del equipo a partir del historial de comentarios de las PR.
- Con los repos de patrones, los desarrolladores pueden hacer referencia a repositorios relacionados en greptile.json para que puedan proporcionar contexto adicional.
- Los desarrolladores pueden responder con @greptileai para preguntas de seguimiento o sugerencias de corrección.
- Greptile aprende de los comentarios con pulgar arriba/abajo.
- Diagramas de secuencia generados automáticamente para todas las PR.
Cursor BugBot
- Después de que BugBot identifica un error, los desarrolladores pueden usar el botón “Fix in Cursor” para abrir rápidamente Cursor y corregir el error.
- Los desarrolladores pueden personalizar sus reglas de revisión de código en archivos BUGBOT.md.
También teníamos la intención de evaluar comparativamente Graphite; sin embargo, debido a un error en su panel de control, no pudimos habilitar las revisiones de código automatizadas para nuevos repositorios. Nos pusimos en contacto con su equipo de soporte el 25 de octubre de 2025, pero la respuesta no resolvió el problema. A pesar de los correos electrónicos de seguimiento y un mensaje en su canal de Slack, el problema siguió sin resolverse.
Componentes e integraciones
* Todas estas soluciones son compatibles con GitHub.
Metodología
Creamos repositorios de comparativa separados para cada herramienta dentro de nuestra organización dedicada de GitHub.
Después de habilitar las revisiones de código automáticas para cada herramienta en su repositorio asignado, abrimos solicitudes de extracción en secuencia, esperamos a que la herramienta completara su revisión y luego cerramos las PR para registrar los resultados. No modificamos ni ajustamos la configuración de ninguna herramienta. Cada herramienta se evaluó utilizando su configuración predeterminada, exactamente como se instaló.
Nuestro flujo de trabajo comienza clonando el repositorio de origen tal como existía en una fecha de referencia seleccionada, y luego reproduciendo las solicitudes de extracción enviadas después de esa fecha una por una, preservando la estructura original del repositorio.
Utilizamos las versiones de noviembre de 2025 de todos los productos. Nuestra comparativa constó de 2 rangos diferentes de repositorios de origen:
1. Repositorios de tamaño medio-grande conocidos
Nuestro objetivo era ver qué tan bien las herramientas de revisión de código de IA entienden los repositorios con estructuras grandes y complejas. Tenemos 289 PR revisadas en total en 7 repositorios.
2. Repositorios pequeños y nuevos
Somos conscientes de que no podemos alimentar a nuestro LLM como juez con el
todo el repositorio en los repositorios grandes, ya que sus ventanas de contexto no son suficientes para ello. Por lo tanto, para superar esto, también evaluamos las primeras 3-5 PR de repositorios nuevos y pequeños. Los servidores MCP se adaptaron perfectamente a nuestras necesidades. En consecuencia, elegimos 8 servidores MCP oficiales y revisamos 20 PR en ellos.
Nuestro conjunto de datos contiene código escrito por desarrolladores experimentados. No evaluamos el rendimiento en bases de código generadas completamente por IA.
Evaluaciones de los desarrolladores
Seleccionamos aleatoriamente 35 PR y las asignamos a 10 desarrolladores, de modo que cada PR fue evaluada 5 veces por los desarrolladores. Nuestro objetivo al repetir la evaluación era minimizar el sesgo de los desarrolladores. Los desarrolladores evaluaron los resultados de forma agnóstica al proveedor.
La mayoría de ellos llegó a las mismas conclusiones de alto nivel:
- Las revisiones detalladas de CodeRabbit son útiles, y tiene éxito en la detección de errores.
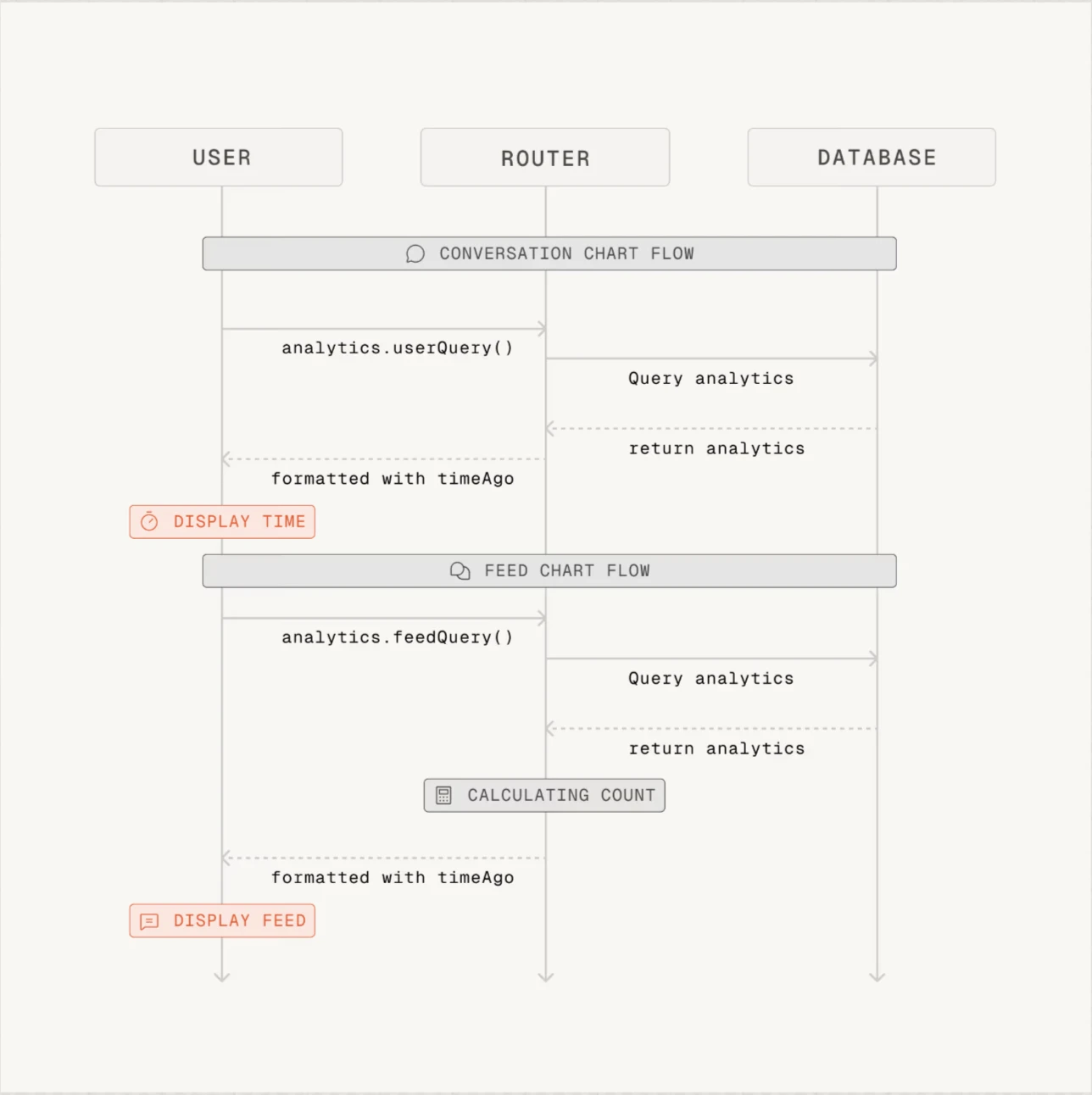
- Greptile proporcionó resúmenes exitosos, pero los diagramas de secuencia que genera no son necesarios para algunas PR.
Figura 1: Ejemplo de diagrama de secuencia proporcionado por Greptile. Greptile genera los diagramas para cada PR.1
- GitHub Copilot tiene mucho éxito en encontrar errores tipográficos en el código y hace sugerencias acertadas; su análisis es más breve que los de CodeRabbit y Greptile.
- Cursor Bugbot proporciona un análisis menos detallado y menos preciso.
Después de las evaluaciones, también declararon que comenzarán a usarlos en sus propios repositorios como herramienta de apoyo para los desarrolladores.
LLM como juez
Utilizamos GPT-5 para evaluar las revisiones. Después de la evaluación, utilizamos GPT-4o para estructurar la salida en formato JSON.
Nuestro flujo de trabajo de evaluación incluye:
- Para repositorios grandes: el cuerpo original de la PR, el diff y los comentarios/revisiones de las herramientas.
- Para repositorios pequeños: toda la base de código, el cuerpo original de la PR, el diff y los comentarios/revisiones de las herramientas.
Aquí está el prompt completo que utilizamos:
Evalúa cada herramienta en estas dimensiones (escala 1-5):
1. Corrección
¿Los problemas identificados son realmente problemas/errores/arreglos reales en el código?
– 5 (Excelente): Todos los problemas identificados son reales
– 4 (Bueno): La mayoría de los problemas son reales, identificaciones erróneas menores
– 3 (Aceptable): Mezcla de problemas reales y cuestionables
– 2 (Deficiente): La mayoría de los problemas identificados no son problemas reales
– 1 (Fallido): No puede identificar problemas reales, todos los hallazgos son incorrectos
2. Completitud
¿Detectó problemas importantes? ¿Qué tan completa es la revisión?
– 5 (Excelente): Detecta todos los problemas críticos y la mayoría de los importantes.
– 4 (Bueno): Detecta problemas mayores, omite algunos menores
– 3 (Aceptable): Detecta algunos problemas importantes pero tiene lagunas notables
– 2 (Deficiente): Omite varios problemas críticos
– 1 (Fallido): Omite todos o casi todos los problemas críticos
3. Accionabilidad
¿Son claras y aplicables las sugerencias? ¿Incluye parches/correcciones? Si no hay errores en el código, escribe “null” en accionabilidad para todas las herramientas, no des ninguna puntuación a ninguna herramienta para esa PR.
– 5 (Excelente): Todas las sugerencias incluyen parches/correcciones claros y son directamente aplicables
– 4 (Bueno): La mayoría de las sugerencias tienen una guía clara, algunas incluyen parches
– 3 (Aceptable): Las sugerencias son algo claras pero carecen de parches para algunos problemas
– 2 (Deficiente): Las sugerencias son en su mayoría poco claras o no aplicables
– 1 (Fallido): No se proporcionan sugerencias o guías claras
4. Profundidad
¿Muestra comprensión de la lógica y el propósito del código?
– 5 (Excelente): Demuestra una comprensión profunda de la lógica del código, la arquitectura y el propósito
– 4 (Bueno): Muestra buena comprensión con lagunas menores
– 3 (Aceptable): Comprensión superficial, omite algo de contexto
– 2 (Deficiente): Explicaciones superficiales o incorrectas del comportamiento del código
– 1 (Fallido): No hay comprensión de la lógica y el propósito del código
Formato de salida
Para cada herramienta, proporciona:
1. Razonamiento detallado: ¿Qué encontró? ¿Omitió problemas importantes? ¿Incluyó parches? ¿Comprensión profunda de la base de código? Ejemplos específicos.
2. Puntuaciones individuales (1-5 para cada dimensión, usando la escala anterior)
Ejemplo de salida
Herramienta A:
Razonamiento: La Herramienta A demostró una excelente corrección al identificar una fuga de memoria real en la lógica de agrupación de conexiones en la línea 145, proporcionando un parche específico usando un administrador de contexto. También detectó la falta de manejo de errores en el endpoint de la API con código procesable. La puntuación de completitud refleja que si bien encontró problemas importantes, omitió la condición de carrera en el manejador asíncrono que podría causar problemas en producción. Los 4 comentarios fueron sustanciales y directamente aplicables. La profundidad fue sólida, mostrando comprensión de los patrones de gestión de recursos y la propagación de errores en la base de código.
Corrección: 5
Completitud: 4
Accionabilidad: 5
Profundidad: 4
Herramienta B:
Razonamiento: La Herramienta B identificó correctamente la vulnerabilidad de validación de entrada en la línea 89 y proporcionó una solución clara utilizando la sanitización de parámetros. Sin embargo, la completitud se vio afectada significativamente ya que omitió la vulnerabilidad de seguridad crítica en el flujo de autenticación que permite la reutilización de tokens. La accionabilidad fue mayoritariamente buena: las sugerencias incluían fragmentos de código. La profundidad fue aceptable pero superficial, centrándose en verificaciones a nivel superficial en lugar de comprender el modelo de seguridad o las implicaciones del flujo de datos.
Corrección: 4
Completitud: 1
Accionabilidad: 4
Profundidad: 2
Herramientas a evaluar: CodeRabbit, Cursor Bugbot, Github Copilot, Greptile
Sé objetivo y exhaustivo. Utiliza ejemplos específicos de las revisiones para respaldar tus puntuaciones.
¿Qué es la revisión de código con IA?
La revisión de código con IA es el análisis automatizado del código fuente mediante modelos de aprendizaje automático, principalmente grandes modelos de lenguaje (LLMs), para identificar errores, ineficiencias y posibles vulnerabilidades. Además de detectar problemas, estos sistemas pueden proporcionar explicaciones contextuales, sugerir correcciones concretas y generar parches que ayudan a los desarrolladores a mejorar tanto la calidad como la mantenibilidad del código. Muchas herramientas de revisión de IA también ayudan con la documentación al resumir los cambios y producir comentarios descriptivos o explicaciones para el código recién añadido.
Debido a que los modelos de IA pueden evaluar el código de forma rápida y a gran escala, aceleran significativamente el proceso de revisión y facilitan la detección temprana de problemas, manteniendo estándares de codificación consistentes en proyectos grandes o de rápido movimiento.
En entornos de desarrollo modernos asistidos por IA como Cursor o Claude Code, los desarrolladores pueden perder involuntariamente el control de cómo evoluciona su base de código cuando practican “vibe coding” o dependen en gran medida de las sugerencias generadas automáticamente. Esto puede introducir vulnerabilidades ocultas o incoherencias lógicas. Las herramientas de revisión de código con IA ayudan a mitigar estos riesgos al proporcionar una capa adicional de análisis estructurado y sistemático para validar y mejorar el código generado por IA.
Beneficios de la revisión de código con IA
Eficiencia y velocidad
Las herramientas de revisión de código con IA pueden analizar el código en tiempo real, proporcionando retroalimentación inmediata y señalando posibles problemas mientras los desarrolladores trabajan. Son capaces de detectar errores y vulnerabilidades de seguridad que los revisores humanos pueden pasar por alto, especialmente en bases de código grandes o en rápida evolución. Al automatizar las comprobaciones rutinarias, estas herramientas permiten a los desarrolladores concentrarse en el razonamiento de alto nivel, la resolución de problemas complejos y las decisiones arquitectónicas.
Mejora de la calidad del código
Las herramientas de revisión de código con IA ayudan a mantener estándares de codificación consistentes en los equipos al identificar inconsistencias estilísticas y desviaciones de las mejores prácticas. También ofrecen retroalimentación detallada y recomendaciones sobre una amplia gama de problemas de codificación, desde mejoras menores hasta errores significativos. Con el tiempo, los desarrolladores pueden aprender de esta retroalimentación, perfeccionar sus hábitos de codificación y adoptar nuevas técnicas que refuercen la calidad general de su trabajo.
Limitaciones y desafíos
Dependencia excesiva de las herramientas de IA
Una preocupación común con la revisión de código con IA es la dependencia excesiva de la retroalimentación automatizada. Aunque la IA puede ser una valiosa fuente de información, no debe tratarse como un sustituto completo de la experiencia humana. Las revisiones automatizadas pueden acelerar los flujos de trabajo, pero los revisores humanos siguen siendo esenciales para garantizar la corrección, la conciencia del contexto y la alineación con los objetivos del proyecto. En nuestra comparativa, los desarrolladores afirmaron consistentemente que no confiarían ciegamente en estas herramientas. Las consideraban asistentes que complementan el juicio humano en lugar de reemplazarlo.
Gestión de falsos positivos y falsos negativos
Los falsos positivos ocurren cuando la herramienta identifica incorrectamente código funcional como problemático, mientras que los falsos negativos ocurren cuando se pasan por alto problemas reales. En nuestra evaluación, la mayor preocupación fueron los falsos negativos. Las herramientas eran más propensas a pasar por alto problemas importantes que a generar advertencias incorrectas. Esto resalta la necesidad de una mejora continua en los modelos y algoritmos subyacentes.
Para abordar estos desafíos, las herramientas de revisión de código con IA deben evolucionar mediante un mejor entrenamiento, un manejo mejorado del contexto y capacidades de razonamiento más precisas.
Mejores prácticas para usar revisiones de código con IA
Consejos de expertos
Combina las revisiones de IA con la perspectiva humana: utiliza las revisiones de código con IA junto con las revisiones humanas para garantizar que el código sea técnicamente sólido y se alinee con los objetivos del proyecto.
Personaliza las reglas para adaptarlas a tu proyecto: ajusta las reglas de la herramienta de IA para que coincidan con los estándares de codificación de tu proyecto y reducir las alertas innecesarias.
Utiliza la retroalimentación de la IA como herramienta de aprendizaje: trata las sugerencias de la IA como una forma de aprender y mejorar, discutiéndolas con tu equipo para entender por qué y cómo evitar problemas similares en el futuro.
Agradecimientos
Extendemos nuestro más sincero agradecimiento a los desarrolladores que contribuyeron con su tiempo y experiencia para realizar las evaluaciones manuales:
Aziz Durmaz (CTO de una empresa de transporte y logística)
Berk Kalelioğlu (cofundador de un estudio de desarrollo de videojuegos)
Elif Ece Örnek (ingeniera de software en un sitio web de viajes)
Haydar Külekçi (consultor en una empresa de tecnologías de búsqueda e IA)
Mehmet Şirin Can (jefe de desarrollo en AIMultiple)
Mehmet Korkmaz (CTO de una empresa de medios en la industria de los deportes electrónicos y los videojuegos)
Murat Orno (ex CTO de una plataforma de pagos regional con más de 500 empleados)
Orçun Candan (desarrollador full-stack en AIMultiple)
Yalçın Börlü (ingeniero de software sénior en una empresa de salud y bienestar)
Yiğit Dinç (cofundador de una empresa de tecnología legal)
También agradecemos a los desarrolladores y mantenedores de los repositorios de código abierto incluidos en nuestra comparativa por su trabajo y valiosas contribuciones a la comunidad.
Anonimización de las identidades de los desarrolladores originales
Para llevar a cabo la comparativa de manera responsable, anonimizamos todos los nombres y direcciones de correo electrónico de los desarrolladores originales al reproducir las solicitudes de extracción de los repositorios ascendentes. Debido a que los repositorios de la comparativa son públicos, preservar la información original del autor podría exponer involuntariamente datos personales y crear el riesgo de notificar a los desarrolladores cada vez que se abre o actualiza una solicitud de extracción recreada. Aunque GitHub normalmente no notifica a los autores cuando sus commits se reproducen en un repositorio separado, consideramos una buena práctica evitar cualquier posibilidad de notificaciones no deseadas, problemas de atribución o preocupaciones de privacidad.
La anonimización garantiza que:
- Los desarrolladores no se vean perturbados por miles de eventos de PR automatizados.
- La información personal no se vuelva a publicar en un repositorio público diferente.
- Las comparativas permanezcan imparciales, evitando que las herramientas o los jueces LLM sean influenciados por nombres de autores reconocibles.
- Se mantengan los estándares éticos y de privacidad al trabajar con contribuciones de código abierto.
Solo se modificaron los metadatos de identidad; todo el código, los diffs, el orden de los commits y las estructuras de archivos se conservaron exactamente para mantener la autenticidad y la reproducibilidad de la comparativa.
Cita este benchmark
Elige el formato que se ajuste al lugar donde vas a publicar. Pegar la versión con enlace en tu CMS conserva el enlace de retroceso.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Alper, Şevval},
title = {{Comparativa de herramientas de revisión de código de IA}},
year = {2026},
month = mar,
howpublished = {\url{https://aimultiple.com/ai-code-review-tools}},
note = {AIMultiple. Recuperado el 13 de Marzo de 2026}
}
Sé el primero en comentar
Tu dirección de correo electrónico no será publicada. Todos los campos son obligatorios. Los comentarios se dejan en su idioma original.