Los 5 mejores frameworks de IA agéntica de código abierto
Comparamos 4 frameworks agénticos de código abierto populares en 2,000 ejecuciones (5 tareas, 100 ejecuciones cada una por framework), midiendo la latencia de extremo a extremo, el consumo de tokens y las diferencias arquitectónicas.
Comparativa de frameworks de IA agéntica
Examinamos cómo influyen los propios frameworks en el comportamiento del agente y el impacto resultante en la latencia y el consumo de tokens.
LangGraph es el framework más rápido con los valores de latencia más bajos en todas las tareas, mientras que LangChain tiene la latencia y el uso de tokens más altos.
En 5 tareas y 2,000 ejecuciones, LangChain emerge como el framework más eficiente en tokens, mientras que AutoGen lidera en latencia; LangGraph y LangChain siguen de cerca. CrewAI presenta el perfil más pesado en general.
Tarea 1: Agregación básica
Primero, medimos la sobrecarga de cada framework al llamar a una sola herramienta y devolver el resultado, sin realizar ningún razonamiento complejo.
LangChain & LangGraph: Para tareas simples, se ejecutan casi tan rápido como el código no agéntico, ambos terminan en menos de 5 segundos con menos de 900 tokens de prompt. La arquitectura de máquina de estados de LangGraph no introduce latencia apreciable en comparación con LangChain en este nivel de simplicidad; la sobrecarga de la gestión de estado aparece a medida que crece la complejidad de la tarea.
AutoGen: Se sitúa ligeramente por encima de LangChain y LangGraph tanto en latencia como en uso de tokens, reflejando el coste base de su bucle de conversación multiagente, con dos agentes intercambiando mensajes incluso para una tarea de un solo paso.
CrewAI: Incluso cuando se le pide que realice una única llamada a herramienta, exhibe lo que podría llamarse "sobrecarga gerencial", consumiendo casi 3 veces los tokens de LangChain y tardando casi 3 veces más. El proceso de verificación en varios pasos entre sus personajes Planner y Analyst ofrece un enfoque exhaustivo pero intensivo en recursos que prioriza la completitud sobre la velocidad. Este coste es estructural: aparece independientemente de la complejidad de la tarea.
Tarea 2: Análisis comparativo de ingresos (gestión de estado)
En la Tarea 2, queríamos ver la capacidad de los frameworks para mantener dos grupos de filtros diferentes en memoria (persistencia de estado) y combinarlos.
CrewAI
En nuestro análisis de registros, encontramos que CrewAI proporciona el nivel más alto de transparencia de infraestructura entre los frameworks, pero a costa del mayor consumo de recursos.
En lugar de devolver inmediatamente los datos recuperados, CrewAI valida repetidamente sus propios procesos mediante un mecanismo de auto-revisión. Este comportamiento exploratorio provocó que alcanzara el límite configurado max_iter=10, dejando algunas ejecuciones atascadas en un bucle continuo de pensamiento sin producir una salida JSON.
La causa raíz de este comportamiento es que CrewAI inyecta instrucciones de múltiples capas en el prompt del sistema, asignando a cada agente un rol, objetivo e historia, mientras impone un bucle de estilo ReAct Pensamiento → Acción → Observación en cada paso. Incluso para tareas simples, el LLM no puede omitir esta ceremonia y produce diligentemente monólogos internos verbosos, lo que se agrava aún más en escenarios multiagente.
CrewAI consumió casi el doble de tokens que los otros frameworks y tardó más del triple que LangChain, lo que lo hace más adecuado para transiciones de estado complejas y toma de decisiones multifactorial que para tareas sencillas de recuperación de datos.
LangChain
El framework más rápido y rentable. En nuestros registros, observamos que LangChain completa la tarea en 5-6 pasos sin desvíos: Cargar → Filtrar → Calcular → Filtrar → Calcular → Salida. Dado que su gestión de estado es muy simple, la sobrecarga es casi nula y la latencia es la más baja entre todos los frameworks.
AutoGen
Ofreció un rendimiento muy equilibrado. En la Tarea 2, igualó a LangGraph casi exactamente tanto en uso de tokens como en latencia, mostrando que la sobrecarga del bucle de conversación no se incrementa significativamente cuando la cadena de tareas permanece lineal.
Sin embargo, ocasionalmente añade un paso de verificación adicional para confirmar parámetros durante el proceso de llamada a herramientas, haciéndolo ligeramente más lento que LangChain. Cuando encuentra un error en una llamada a herramienta o los datos no regresan como se esperaba, actualiza inmediatamente su razonamiento en el siguiente paso y llega al JSON correcto. Debido a que gestiona las salidas de las herramientas como un flujo conversacional, es uno de los frameworks más resilientes frente a errores lógicos.
LangGraph
En esta tarea, LangGraph es el framework más estable gracias a su arquitectura basada en grafos. En sus registros, observamos que el estado se transporta de manera muy limpia durante toda la ejecución. El riesgo de contaminación de datos o de que los segmentos interfieran entre sí está en el nivel más bajo en este framework. En las 100 ejecuciones, produjo resultados en casi el mismo número de pasos y dentro del mismo rango de latencia.
Tarea 3: Análisis de umbrales (disciplina numérica)
En esta tarea, queríamos ver con qué precisión los frameworks traducen condiciones numéricas en lenguaje natural, como "menos de 1 año de permanencia" y "más de $70 en cargos mensuales", en parámetros de herramienta precisos como tenure_max=12 y charges_min=70.0.
El LLM sabe cómo hacer esta conversión; lo que realmente queríamos probar era si el framework puede proteger estos parámetros a lo largo de sus propios mecanismos de reintento, re-prompt y ciclos de gestión de estado.
LangChain & LangGraph
Ambos frameworks pasaron los parámetros (tenure_max=12, charges_min=70) directamente a la herramienta exactamente como el LLM los produjo, sin ninguna modificación ni bucle de re-prompt. Esta eficiencia se refleja en las cifras: ambos frameworks completaron la Tarea 3 en menos de 9 segundos con menos de 1,800 tokens de prompt, los más bajos en esta tarea.
Cuando queríamos medir si los umbrales numéricos se preservan sin que el framework interfiera, estos dos cumplieron nuestras expectativas: cualquier parámetro que se generó, eso es lo que se ejecutó.
AutoGen
Autogen tiene pleno éxito en la corrección numérica. En algunas ejecuciones, se observó que el framework añadió un paso de verificación antes de pasar el parámetro generado por el LLM a la herramienta, lo que significa que el framework dedicó un paso extra mientras preservaba el parámetro. Con 2,480 tokens y 8 segundos, igualó la latencia de LangChain a pesar del paso extra, confirmando que la sobrecarga de verificación es real pero pequeña. Cumplió nuestras expectativas en cuanto a la integridad de los parámetros, introduciendo el paso de confirmación un coste marginal en tokens en lugar de una penalización significativa en latencia.
CrewAI
El comportamiento más notable se observó en CrewAI, que completó la Tarea 3 en 30 segundos con 4,360 tokens, los valores más altos en esta tarea. Dos patrones de fallo distintos surgieron del análisis de registros.
En algunas ejecuciones, un valor que debería haber sido 68.81% se devolvió como 0.6878 (ratio decimal). Esto indica que la serialización de salida del framework puede despojar al resultado del LLM de su contexto original.
Los registros muestran que el LLM produjo inicialmente los parámetros correctos, tenure_max=12 y charges_min=70. Sin embargo, una vez que CrewAI entró en un bucle "Failed to parse", el framework empujó al LLM a reconsiderar. En el contexto de re-prompt, el LLM cambió el umbral a tenure_max=14 y deshabilitó completamente el filtro charges_min, produciendo una tasa de abandono del 46.84%, que es en realidad la tasa de abandono de todos los clientes con permanencia inferior a 14. Este era exactamente el escenario que queríamos observar: el mecanismo de reintento del framework puede corromper un parámetro que el LLM había acertado.
Tarea 4: Resiliencia ante errores y capacidad de pivotar
En esta tarea, queríamos ver cómo maneja cada framework escenarios disruptivos y observar el impacto en la latencia y el consumo de tokens. La herramienta lanza 3 tipos diferentes de errores sucesivamente (Network, Timeout, Rate Limit), acorralando al agente. Los dos primeros errores indican al agente que reintente, y después de reintentar ambos, el error entrante Rate Limit le dice al agente que espere 10 segundos. Una vez que el agente espera y reintenta, la herramienta comienza a funcionar normalmente.
LangGraph & Autogen
Estos dos frameworks encontraron soluciones alternativas de forma autónoma cuando se enfrentaron a fallos de herramientas en esta tarea.
Cuando la herramienta devolvió una advertencia de límite de velocidad, en lugar de pausar y esperar, estos agentes decidieron abandonar la herramienta fallida por completo y encontrar un camino alternativo. Su enfoque fue: "Ya que esta herramienta no funciona, filtraré cada método de pago uno por uno, calcularé la tasa de abandono de cada uno por separado y luego combinaré los resultados yo mismo."
Método: En lugar de realizar la tarea con una única llamada a herramienta, la desglosaron utilizando dos herramientas separadas, una para filtrar y otra para calcular, procesando cada PaymentMethod (Electronic check, Mailed check, etc.) individualmente.
Estos agentes operan con un razonamiento orientado a objetivos en lugar de dependencia del camino. Si el camino más corto no está disponible, pueden construir un plan de ejecución alternativo en cuestión de segundos.
LangGraph alcanzó 15,010 tokens de prompt en la Tarea 4, el mayor conteo de tokens en una sola tarea en toda la comparativa, porque su máquina de estados acumuló el historial creciente de cada llamada manual a herramienta de vuelta al contexto en cada paso. AutoGen siguió con 10,750 tokens, algo más contenido debido a su manejo conversacional de los resultados intermedios. A pesar de esto, ambos terminaron alrededor de 24-27 segundos, confirmando que el coste adicional en tokens no se tradujo en una latencia significativa porque el pivote en sí fue rápido.
CrewAI
A pesar de mostrar el mayor consumo de tokens en tareas anteriores, CrewAI exhibió el menor uso de tokens pero los valores de latencia más altos en esta tarea.
¿Por qué el menor consumo de tokens?
CrewAI no pasó por una solución manual de 10-15 pasos como sus competidores. Cuando encontró errores, en lugar de inyectar repetidamente todo el historial y los datos intermedios complejos de vuelta al LLM en cada paso, construyó un bucle de razonamiento más enfocado y modular. Al evitar la verbosidad innecesaria, se convirtió en el framework más rentable en esta tarea.
¿Por qué la alta latencia?
La estructura gerencial de CrewAI pausa y reevalúa el plan cuando encuentra un error. Cuando recibió la advertencia de esperar 10-segundos, dedicó más tiempo a la fase de "planificación de estrategia". Además, en lugar de pivotar a otra herramienta para filtrar, optó persistentemente por esperar a que la herramienta principal se recuperara o intentarlo con una herramienta estable, lo que extendió la duración total.
LangChain
LangChain experimentó su transformación más significativa en esta tarea, demostrando por qué la resiliencia depende de una configuración adecuada.
En nuestra ejecución inicial, LangChain falló en cada intento con un ConnectionError.
El AgentExecutor predeterminado de LangChain trata las excepciones Python puras lanzadas desde dentro de una herramienta como errores fatales y termina el proceso. A diferencia de sus competidores, no aplica una filosofía de "los errores son observaciones" por defecto. Dado que el agente nunca ve el error, no tiene oportunidad de razonar sobre él.
Envolvimos la llamada a la herramienta dentro de langchain_agent.py con un bloque try-except. Esto convirtió el error en un mensaje legible que el agente pudo procesar.
Comportamiento posterior a la corrección: Después de aplicar la corrección, observamos en los registros de LangChain que exhibió exactamente el mismo razonamiento que LangGraph. Recibió 3 errores de la herramienta, cambió inmediatamente de estrategia y pivotó para usar dos herramientas separadas, una para filtrar y otra para calcular, procesó cada método de pago individualmente y combinó los resultados.
LangChain es en realidad tan capaz y adaptable como LangGraph, pero debido a que el manejo de errores del framework estaba desactivado por defecto, no tuvo oportunidad de demostrar esta capacidad. Una vez configurado correctamente, alcanzó el resultado correcto utilizando el mismo enfoque de camino alternativo.
¿Por qué ocurrieron estas diferencias? (análisis de la arquitectura de los frameworks)
Si el comportamiento del agente dependiera únicamente del LLM (GPT-5.2), todos los frameworks deberían haberse comportado de manera similar. Sin embargo, las claras diferencias en estas proporciones tienen su raíz en los propios mecanismos de bucle interno de los frameworks:
1. LangGraph & AutoGen (90% Pivote):
LangGraph opera sobre una arquitectura de máquina de estados, mientras que AutoGen trabaja sobre un modelo basado en conversaciones. En ambos sistemas, los errores se procesan como un bucle de retroalimentación. En LangGraph, el estado que recibe el error pasa al siguiente nodo; en AutoGen, el agente Proxy reenvía el error al asistente como un mensaje de chat. Este mecanismo constante de incitación obliga al agente a seguir buscando una solución. Debido a que el agente se enfrenta repetidamente a la pregunta "Recibí un error, ¿qué debo hacer?", la probabilidad de que decida tomar un camino manual alternativo aumenta al 90%.
2. LangChain (65% Pivote / 35% Esperar):
LangChain se ejecuta sobre una arquitectura AgentExecutor secuencial. Incluso con manejo de errores implementado, su bucle de ejecución tiene una estructura más lineal y se centra principalmente en producir una Respuesta Final. Si la herramienta lanza errores durante 3-4 pasos, LangChain a veces prefiere esperar a que la herramienta tenga éxito en el siguiente intento o producir un resultado del contexto existente, en lugar de pivotar a una estrategia alternativa. Debido a que el bloqueo de estado de LangChain es más flexible que el de LangGraph, su ratio de espera/solución directa se sitúa alrededor del 35%.
3. CrewAI (0% Pivote):
CrewAI opera sobre una arquitectura de Proceso Gerencial. Sus agentes están envueltos en definiciones de Rol y Tarea. Cuando ocurren errores, su arquitectura interna típicamente activa lógica de Auto-Corrección o Reintento. Sin embargo, un cambio radical de estrategia como "desechemos todo el plan y hagamos filtrado manual en 5 pasos" entra en conflicto con la estructura del plan gerencial de CrewAI. Opera con la disciplina de "debo arreglar la herramienta que me dieron o usar la alternativa más cercana" en lugar de abandonar su plan por completo. Este es fundamentalmente un enfoque centrado en el plan, en oposición a uno centrado en el objetivo.
Tarea 5: Orquestación de datos no estructurados (enrutamiento de datos no estructurados)
En la tarea 5, observamos cómo se comportan los frameworks cuando encuentran columnas JSON y de texto largo (LongText) dentro de un CSV. Los agentes necesitaban primero descubrir el tipo de datos de estas columnas, luego seleccionar las herramientas de procesamiento correctas, ya sea de forma secuencial o en paralelo.
En el mundo real, la gestión de datos no estructurados requiere que un agente vaya más allá de los datos tabulares estándar y trabaje con blobs JSON, párrafos de gratis text u objetos anidados.
Para que un framework maneje correctamente este tipo de datos, necesita hacer bien dos cosas:
1- una inteligencia de descubrimiento que entienda qué herramienta se ajusta a cada tipo de dato
2- un mecanismo de orquestación que coordine múltiples llamadas a herramientas independientes.
Diseñamos la Tarea 5 específicamente para medir estas dos capacidades por separado.
AutoGen
AutoGen ofreció un fuerte rendimiento en esta tarea, terminando con 8,170 tokens de prompt y una latencia mediana de 47 segundos, el resultado más rápido y eficiente en tokens en la Tarea 5.
El bucle de conversación en el núcleo de su arquitectura, el intercambio de mensajes entre AssistantAgent y UserProxyAgent, se ve típicamente como una estructura que conduce a la verbosidad. Sin embargo, en la Tarea 5, esta estructura se convirtió en una ventaja.
Al mirar el historial de conversación, el LLM reconoció que las columnas Metadata y SupportNotes eran independientes entre sí. Luego envió una única respuesta TOOL CALLS listando 4 herramientas simultáneamente: inspect_column(Metadata), inspect_column(SupportNotes), parse_json_column(…), y summarize_text_column(…) se ejecutaron todas en paralelo. Esto le permitió completar la tarea en 3 turnos del LLM, con la menor cantidad de tokens y el menor número de pasos.
La razón técnica detrás de este comportamiento es clara: el motor de ejecución de herramientas de AutoGen ejecuta la lista tool_calls devuelta por el LLM de forma atómica y recopila los resultados en un único paso de conversación. La filosofía de "gestionar la conversación" del framework permite naturalmente que se abran múltiples canales paralelos al mismo tiempo, y los números de tokens y latencia lo confirman directamente.
LangGraph
LangGraph terminó con 9,150 tokens de prompt y 70 segundos de mediana, cercano a AutoGen en tokens pero más lento en tiempo. Su arquitectura de máquina de estados mostró simultáneamente tanto su mayor fortaleza como su debilidad más notable en la Tarea 5.
En cada ejecución, el bucle nodo llm → nodo tools → nodo llm acumula todas las salidas anteriores de las herramientas en el estado y las pasa al LLM. Esta estructura garantiza que el agente nunca olvide nada, lo que normalmente es una ventaja significativa.
Sin embargo, en la Tarea 5 esta fortaleza jugó en su contra. LangGraph encontraba las herramientas correctas y construía el segmento correcto. Pero incluso después de que el análisis estuviera completo, detectaba ambigüedades en el estado acumulado, interpretando pasos completados como aún pendientes, y desencadenaba repetidamente llamadas adicionales a herramientas. Aunque ya había recuperado los datos necesarios y estaba a punto de producir la respuesta correcta, la señal de "paso faltante" de la máquina de estados se activaba y el agente entraba en bucles innecesarios. Como resultado, el número de llamadas a herramientas por ejecución osciló entre 6 y 16. El poder del estado de "nunca olvidar nada" a veces hacía que los pasos completados parecieran incompletos, arrastrando al agente de vuelta a ciclos redundantes y elevando la latencia 23 segundos por encima de AutoGen a pesar de un conteo de tokens comparable.
CrewAI
El rendimiento de CrewAI en la Tarea 5 produjo la mayor variabilidad en toda la comparativa. En algunas ejecuciones, siguió una secuencia impecable con 5 llamadas a herramientas, sin desvíos, ejecutándose como un script. En estas ejecuciones, la estructura gerencial definida por roles y tareas de CrewAI funcionó exactamente como se pretendía: cuando el agente entendía claramente su rol, se comportaba de manera predecible y disciplinada.
Sin embargo, en otras ejecuciones (p. ej., ejecución 16: 35 llamadas a herramientas), sobrevino el caos total. La causa raíz fue el monólogo interno (Thought) que CrewAI genera en cada paso. Después de construir correctamente el segmento con el filtro adecuado, el monólogo interno del agente comenzó a cuestionar si también debían aplicarse filtros adicionales. Después de ver el resultado, dudaba sobre si el segmento actual era válido o si el anterior debía tener prioridad. Esta duda lo empujaba a recargar los datos desde cero. Luego filtraba de nuevo, entraba en otro bucle de verificación, dudaba otra vez, y repetía esta espiral 8 veces.
En CrewAI, cada Thought produce una evaluación independiente, y estas evaluaciones ocasionalmente invalidan pasos previamente verificados. El reflejo de "verificación continua" del Proceso Gerencial, en algunas ejecuciones, empujó al agente a volver a cuestionar sus propias decisiones correctas.
LangChain
La estructura AgentExecutor de LangChain es inherentemente secuencial, y la Tarea 5 es donde esa restricción fue más visible. Con 10,070 tokens de prompt y 86 segundos de mediana, fue el framework más lento en esta tarea a pesar de no tener el mayor conteo de tokens.
Realiza una única llamada a herramienta en cada paso, recibe el resultado, luego avanza, lo que significa que 4 herramientas independientes requirieron 4 turnos separados del LLM con 4 períodos de espera separados. La mediana de 47 segundos de AutoGen frente a los 86 segundos de LangChain es una medición directa del coste de la ejecución secuencial frente a la paralela.
En la Tarea 5, el conteo de herramientas de LangChain se situó en 9 o 15. Estos dos grupos apuntan a dos estrategias típicas: en algunas ejecuciones, omitió el paso de inspección y fue directamente a analizar y resumir (9 herramientas), mientras que en otras inspeccionó cada columna primero antes de procesar (15 herramientas). La identidad de ejecutor lineal de LangChain quedó clara aquí: no exhibió ni la eficiencia paralela de AutoGen ni el caos de monólogo de CrewAI.
Gestión de datos no estructurados y arquitectura del framework
Los resultados de esta tarea revelan que la eficiencia con la que un framework puede gestionar datos no estructurados (JSON, LongText) está directamente vinculada a su mecanismo de bucle interno:
Los frameworks capaces de llamadas a herramientas paralelas (AutoGen) pueden procesar columnas de datos independientes en un solo paso. En escenarios del mundo real que involucran grandes objetos JSON y numerosas columnas de texto, esta diferencia se traduce en una enorme ventaja de coste y velocidad.
Los frameworks con bucles impulsados por estado (LangGraph) destacan en la consistencia de los datos pero conllevan el riesgo de reevaluar pasos completados acumulados en el historial.
Los frameworks basados en monólogos (CrewAI) son profundamente capaces de entender el tipo y significado de los datos, pero esta profundidad a veces se convierte en un cuestionamiento excesivo y bucles.
Los frameworks de ejecución lineal (LangChain) procesan diferentes ramas de datos no estructurados por separado, produciendo un resultado intermedio de ambos mundos.
Crecimiento de estrellas en GitHub de frameworks agénticos
Comparar frameworks de IA agéntica
Los frameworks de IA agéntica varían en varias dimensiones clave, y comprender estas diferencias es esencial para hacer comparaciones significativas.
Orquestación multiagente
La orquestación multiagente coordina múltiples agentes de IA especializados para abordar flujos de trabajo complejos que superan las capacidades de un solo agente. En lugar de construir un agente monolítico, la orquestación divide el trabajo entre agentes con roles, herramientas y experiencia distintos. Cada framework ofrece diferentes enfoques para la coordinación de agentes.
LangGraph
LangGraph es un framework relativamente conocido y se destaca como una opción clave para los desarrolladores que construyen sistemas de agentes.
Coordinación multiagente explícita: Puede modelar múltiples agentes como nodos individuales o grupos, cada uno con su propia lógica, memoria y rol en el sistema.
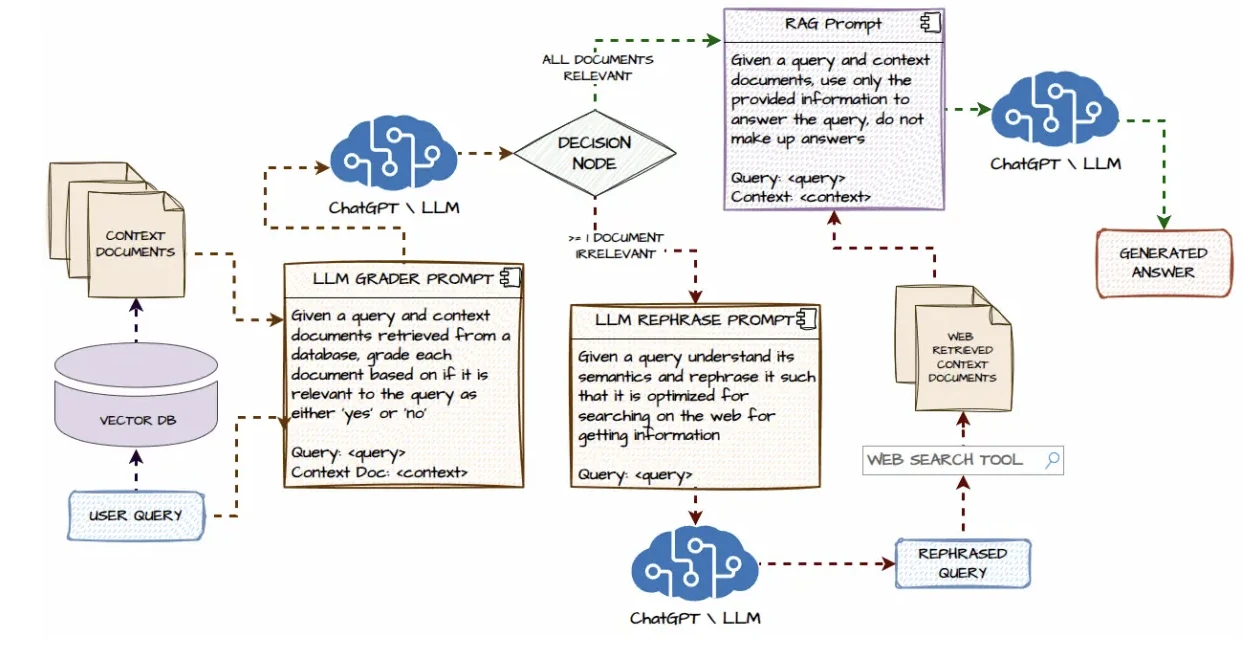
Crea flujos de trabajo de IA a través de APIs y herramientas. Por lo tanto, es adecuado para RAG y pipelines personalizados.
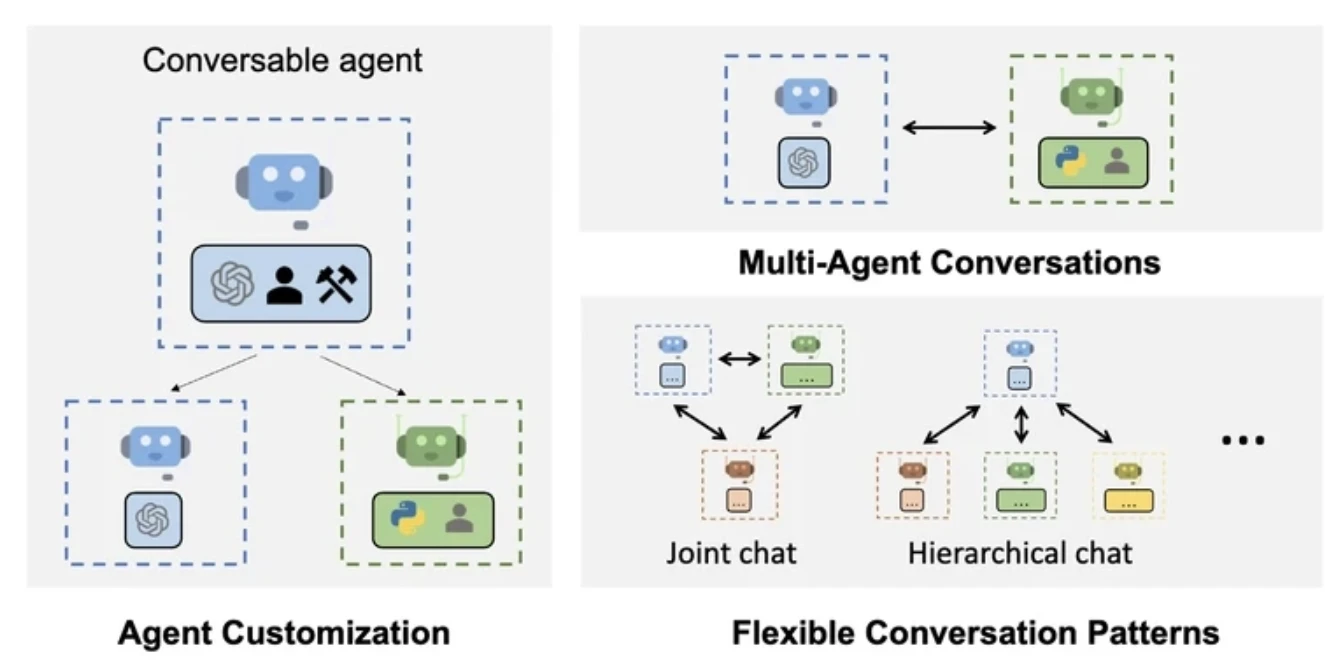
AutoGen
AutoGen permite que múltiples agentes se comuniquen intercambiando mensajes en un bucle. Cada agente puede responder, reflexionar o llamar a herramientas según su lógica interna.
Dispone de colaboración asíncrona de agentes, lo que lo hace particularmente útil para escenarios de investigación y prototipado donde el comportamiento del agente requiere experimentación o refinamiento iterativo.
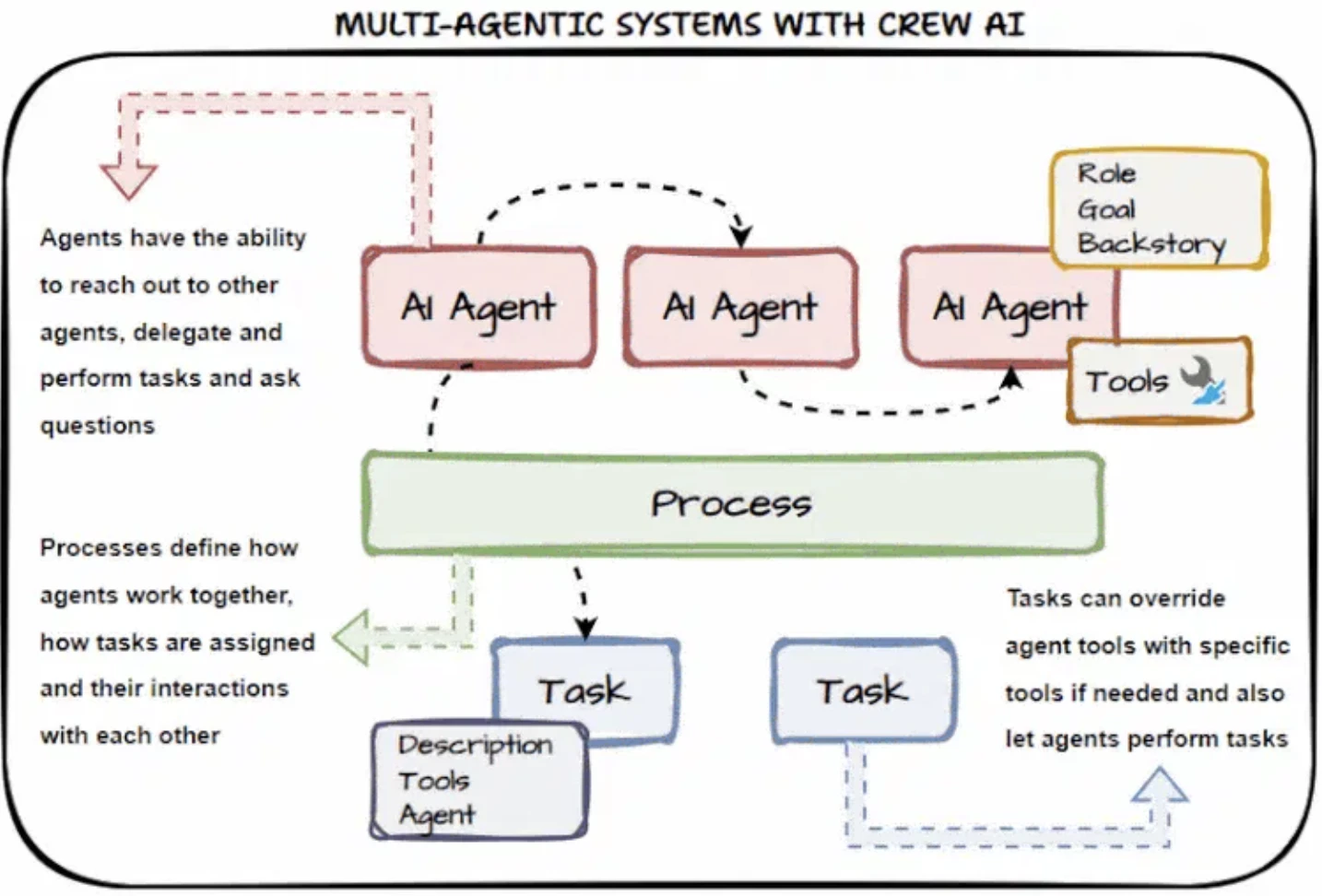
CrewAI
CrewAI maneja la mayor parte de la lógica de bajo nivel por usted y proporciona orquestación multiagente:
- Se integra con herramientas de monitoreo para trazado y depuración
- Control de ejecución incorporado a través de Flows con lógica condicional, bucles y gestión de estado
- Soporta coordinación multiagente jerárquica (gestor-trabajador) y estructurada
OpenAI Swarm
Swarm es un framework multiagente experimental y ligero para prototipado. Los agentes trabajan secuencialmente mediante transferencias, pasando tareas mientras mantienen un contexto compartido. Utiliza rutinas en lenguaje natural y herramientas Python para flujos de trabajo flexibles.
LangChain
LangChain es un framework para construir aplicaciones de LLM de un solo agente con herramientas RAG. Proporciona componentes modulares que incluyen cadenas, herramientas, memoria y recuperación para flujos de trabajo de procesamiento de documentos.
LangChain opera principalmente a través de patrones de ejecución de un solo agente donde un agente gestiona el flujo de trabajo.
Definición de agente y función
LangGraph
LangGraph adopta un enfoque basado en grafos para el diseño de agentes, donde cada agente se representa como un nodo que mantiene su propio estado. Estos nodos se conectan a través de un grafo dirigido, permitiendo lógica condicional, coordinación entre equipos y control jerárquico. Esto le permite construir y visualizar grafos multiagente con nodos supervisores para una orquestación escalable.
LangGraph utiliza funciones anotadas y estructuradas que adjuntan herramientas a los agentes. Puede construir nodos, conectarlos a varios supervisores y visualizar cómo interactúan los diferentes equipos. Piense en ello como dar a cada miembro del equipo una descripción detallada del trabajo. Esto facilita la construcción y prueba de agentes que trabajan juntos.
AutoGen
AutoGen define a los agentes como unidades adaptativas capaces de enrutamiento flexible y comunicación asíncrona. Los agentes interactúan entre sí (y opcionalmente con humanos) intercambiando mensajes, permitiendo la resolución colaborativa de problemas. Al igual que LangGraph, utiliza funciones anotadas y estructuradas.
CrewAI
CrewAI adopta un enfoque de diseño basado en roles. A cada agente se le asigna un rol (p. ej., Investigador, Desarrollador) y un conjunto de habilidades, funciones o herramientas a las que puede acceder. La definición de funciones se realiza mediante anotaciones estructuradas.
OpenAI Swarm
OpenAI Swarm utiliza un modelo basado en rutinas donde los agentes se definen mediante prompts y docstrings de funciones. No tiene modelos formales de orquestación ni de estado, y se basa en flujos de trabajo estructurados manualmente. El comportamiento de las funciones es inferido por el LLM a través de docstrings (Swarm identifica lo que hace una función leyendo su descripción), lo que hace que esta configuración sea flexible pero menos precisa.
LangChain
LangChain utiliza una arquitectura basada en cadenas donde un único agente orquestador gestiona las llamadas a modelos de lenguaje y diversas herramientas. Define funciones a través de interfaces explícitas como toolkits y plantillas de prompts.
Aunque se centra principalmente en flujos de trabajo centralizados, LangChain admite extensiones para configuraciones multiagente pero carece de comunicación agente a agente incorporada.
Memoria
Capacidades de memoria:
- Con estado: Si el framework soporta memoria persistente entre ejecuciones.
- Contextual: Si soporta memoria a corto plazo mediante historial de mensajes o paso de contexto.
Características de memoria son una parte clave de la construcción de sistemas agénticos para recordar contexto y adaptarse con el tiempo:
- Memoria a corto plazo: Realiza un seguimiento de las interacciones recientes, permitiendo a los agentes manejar conversaciones multiturno o flujos de trabajo paso a paso.
- Memoria a largo plazo: Almacena información persistente entre sesiones, como preferencias de usuario o historial de tareas.
- Memoria de entidad: Rastrea y actualiza conocimiento sobre objetos específicos, personas o conceptos mencionados durante las interacciones (p. ej., recordar un nombre de empresa o ID de proyecto mencionado anteriormente).
LangGraph
LangGraph utiliza dos tipos de memoria: memoria en el hilo, que almacena información durante una única tarea o conversación, y memoria entre hilos, que guarda datos a través de sesiones. Los desarrolladores pueden usar MemorySaver para guardar el flujo de una tarea y vincularlo a un thread_id específico. Para almacenamiento a largo plazo, LangGraph soporta herramientas como InMemoryStore u otras bases de datos. Esto proporciona un control flexible sobre cómo se delimita y retiene la memoria a través de las ejecuciones.
AutoGen
AutoGen utiliza un modelo de memoria contextual. Cada agente mantiene un contexto a corto plazo a través de un objeto context_variables, que almacena el historial de interacciones. No tiene memoria persistente incorporada.
CrewAI
CrewAI proporciona memoria en capas lista para usar. Almacena la memoria a corto plazo en un almacén vectorial ChromaDB, los resultados de tareas recientes en SQLite, y la memoria a largo plazo en una tabla SQLite separada (basada en descripciones de tareas). Además, soporta memoria de entidad utilizando embeddings vectoriales. Esta configuración de memoria se configura automáticamente cuando memory=True está habilitado,
OpenAI Swarm
Swarm es sin estado y no gestiona la memoria de forma nativa. Los desarrolladores pueden pasar memoria a corto plazo a través de context_variables manualmente, y opcionalmente integrar herramientas externas o capas de memoria de terceros (p. ej., mem0) para almacenar contexto a más largo plazo.
LangChain
LangChain soporta memoria tanto a corto como a largo plazo a través de componentes flexibles. La memoria a corto plazo se gestiona típicamente mediante búferes en memoria que rastrean el historial de conversación dentro de una sesión. Para la memoria a largo plazo, LangChain se integra con almacenes vectoriales externos o bases de datos para persistir embeddings y datos de recuperación.
Los desarrolladores pueden personalizar los alcances y estrategias de memoria utilizando clases de memoria incorporadas, permitiendo una gestión eficiente de la memoria contextual y específica de entidad a través de las interacciones.
Human-in-the-loop
LangGraph
LangGraph soporta puntos de interrupción personalizados (interrupt_before) para pausar el grafo y esperar la entrada del usuario a mitad de la ejecución.
AutoGen
AutoGen soporta de forma nativa agentes humanos a través de UserProxyAgent, permitiendo a los humanos revisar, aprobar o modificar pasos durante la colaboración de agentes.
CrewAI:
CrewAI permite la retroalimentación después de cada tarea configurando human_input=True; el agente se pausa para recoger la entrada en lenguaje natural del usuario.
OpenAI Swarm
OpenAI Swarm no ofrece HITL incorporado.
LangChain
LangChain permite insertar puntos de interrupción personalizados dentro de cadenas o agentes para pausar la ejecución y solicitar entrada humana. Esto admite revisión, retroalimentación o intervención manual en puntos definidos del flujo de trabajo.
Integración del Protocolo de Contexto del Modelo (MCP) en frameworks de IA agéntica
Los agentes de IA necesitan interactuar con herramientas externas como bases de datos, APIs, sistemas de archivos y aplicaciones empresariales. Sin un estándar, cada framework tenía que construir integraciones personalizadas para cada herramienta, creando un ecosistema fragmentado. MCP resuelve esto proporcionando un protocolo universal que permite a cualquier agente conectarse a cualquier herramienta a través de una única interfaz.
Cómo se integra cada framework con MCP
LangGraph
LangGraph se conecta a servidores MCP a través de un adaptador que descubre automáticamente las herramientas disponibles y las convierte al formato compatible con LangChain. Los agentes pueden entonces usar estas herramientas sin problemas junto con sus capacidades nativas.
AutoGen
AutoGen proporciona integración MCP incorporada a través de su módulo de extensión. Los desarrolladores pueden conectarse a servidores MCP y poner todas sus herramientas a disposición de los agentes de AutoGen con solo unas pocas líneas de código.
CrewAI
Los agentes de CrewAI pueden referenciar directamente servidores MCP en su configuración usando URLs simples o ajustes estructurados. El framework maneja el ciclo de vida de la conexión y la gestión de errores automáticamente.
OpenAI Swarm
Swarm se beneficia del soporte nativo de MCP de OpenAI en todo su ecosistema. Dado que OpenAI integró MCP en ChatGPT y su Agents SDK, Swarm puede aprovechar esta infraestructura directamente.
LangChain
LangChain ofrece capacidades de llamada a herramientas MCP donde las funciones Python actúan como puentes hacia servidores MCP. Esto permite extraer herramientas de diversas fuentes e integrarlas en cadenas, agentes y otros componentes de LangChain sin contenedores personalizados.
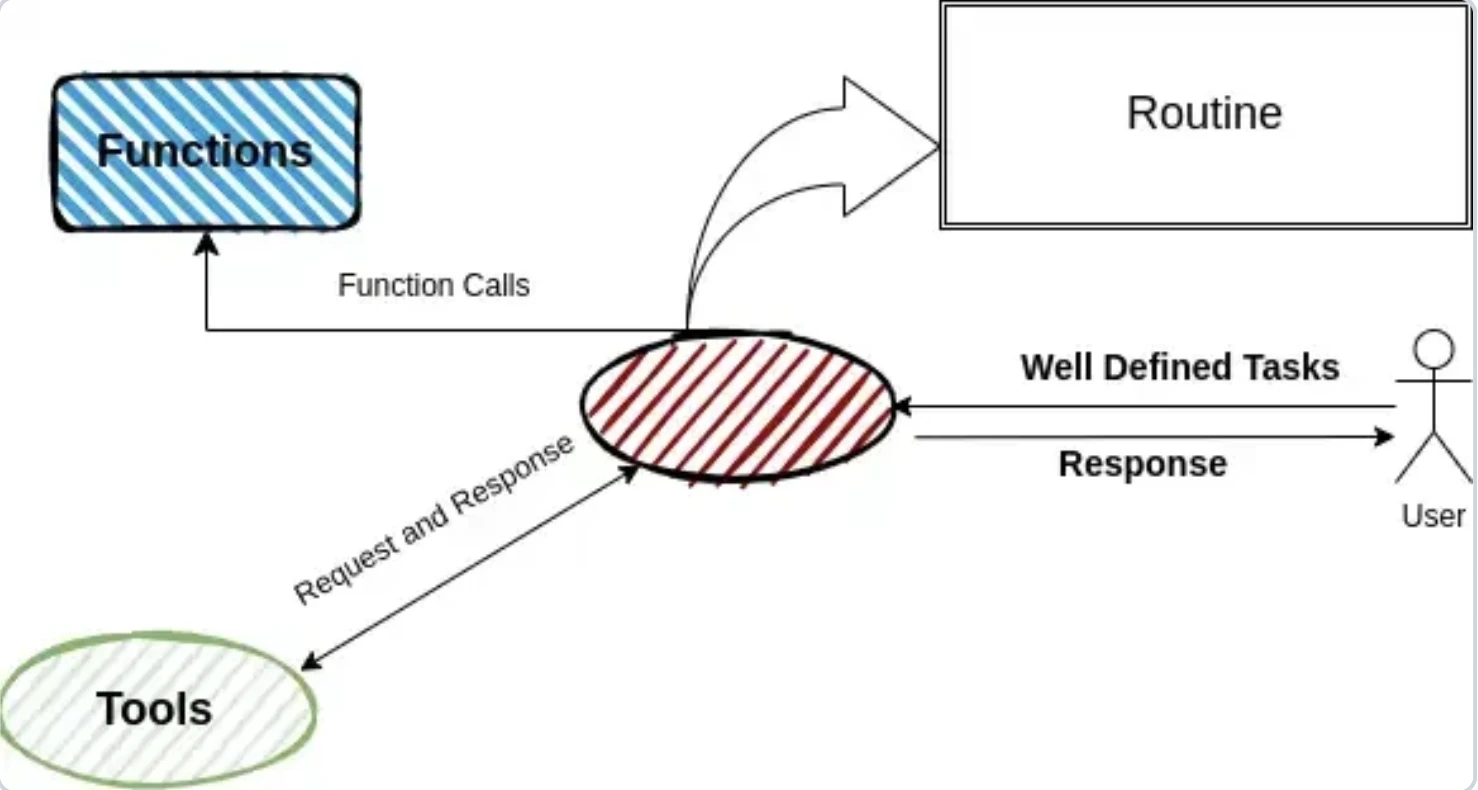
¿Qué hacen realmente los frameworks de IA agéntica?
Los frameworks de IA agéntica asisten con la ingeniería de prompts y la gestión de cómo fluyen los datos hacia y desde los LLMs. A un nivel básico, ayudan a estructurar prompts para que el LLM responda en un formato predecible y enruten las respuestas a la herramienta, API o documento correctos.
Si se construyera desde cero, usted definiría manualmente el prompt, extraería la herramienta que el LLM quiere usar y desencadenaría la llamada a la API correspondiente. Los frameworks agilizan esto mediante:
- Orquestación de prompts: Construcción, gestión y enrutamiento de prompts complejos hacia los LLMs
- Integración de herramientas: Permitir que los agentes llamen a APIs externas, bases de datos, funciones de código, etc.
- Memoria: Mantener el estado a lo largo de turnos o sesiones (corto y largo plazo)
- Integración RAG: Habilitar la recuperación de conocimiento desde fuentes externas
- Coordinación multiagente: Estructurar cómo colaboran o delegan tareas los agentes
Frameworks de IA agéntica: Casos de uso en la vida real
LangGraph – Planificador de viajes multiagente
Un proyecto de producción construido con LangGraph demuestra un asistente de viajes multiagente con estado que extrae datos de vuelos y hoteles (usando las APIs de Google Flights y Hotels) y genera recomendaciones de viaje.4
CrewAI – Creador de contenido agéntico
El repositorio de ejemplos oficiales de CrewAI incluye flujos como planificación de viajes, estrategia de marketing, análisis de acciones y asistentes de reclutamiento, donde agentes con roles específicos (p. ej., "Investigador", "Redactor") colaboran en tareas.5
CrewAI convierte un briefing de contenido de alto nivel en un artículo completo utilizando Groq.
Características principales de los frameworks de IA agéntica
Soporte de modelos:
- La mayoría son agnósticos al modelo, soportando múltiples proveedores de LLM (p. ej., OpenAI, Anthropic, modelos de código abierto).
- Sin embargo, las estructuras de los prompts del sistema varían según el framework y pueden funcionar mejor con unos modelos que con otros.
- El acceso y la personalización de los prompts del sistema es a menudo esencial para obtener resultados óptimos.
Herramientas:
- Todos los frameworks soportan uso de herramientas, una parte central para habilitar las acciones del agente.
- Ofrecen abstracciones simples para definir herramientas personalizadas.
- La mayoría soporta Model-Context-Protocol (MCP), ya sea de forma nativa o a través de extensiones de la comunidad.
Memoria / Estado:
- Usan seguimiento de estado para mantener la memoria a corto plazo a través de pasos o llamadas al LLM.
- Algunos ayudan a los agentes a retener interacciones o contexto previos dentro de una sesión.
RAG (Generación Aumentada por Recuperación):
- La mayoría incluye opciones de configuración sencilla para RAG, integrando bases de datos vectoriales o almacenes de documentos.
- Esto permite a los agentes hacer referencia a conocimiento externo durante la ejecución.
Otras características comunes
- Soporte para ejecución asíncrona, permitiendo llamadas concurrentes a agentes o herramientas.
- Manejo incorporado para salidas estructuradas (p. ej., JSON).
- Soporte para salidas en streaming donde el modelo genera resultados de forma incremental.
- Características básicas de observabilidad para monitorizar y depurar las ejecuciones de los agentes.
Metodología de la comparativa
1. Estructura de las tareas
Tarea 1: Mide si se puede realizar una única llamada a herramienta con el parámetro correcto. La sobrecarga de infraestructura base del framework se revela más claramente en este escenario simple.
Tarea 2: Requiere mantener los resultados de dos grupos de filtros separados en memoria y combinarlos en una única salida. Se prueban la gestión de estado y la coordinación de múltiples segmentos.
Tarea 3: Mide si las condiciones numéricas en lenguaje natural se traducen en parámetros de herramienta sin distorsión. La verdadera prueba es si los mecanismos de reintento y re-prompt del framework pueden preservar estos parámetros.
Tarea 4: Una herramienta lanza errores de Network, Timeout y RateLimit sucesivamente. Se mide si el framework cambia de estrategia frente a estos errores.
Tarea 5: El agente debe primero descubrir las columnas JSON y LongText, luego llamar a las herramientas correctas con los parámetros de alcance adecuados. Se observa si el framework ejecuta las herramientas independientes en paralelo o secuencialmente.
Cómo es realmente una tarea
Para concretar la configuración, aquí está la Tarea 5, la tarea más compleja en la comparativa de frameworks de IA agéntica. Cada framework recibió el prompt idéntico y el conjunto idéntico de herramientas; solo cambió el framework que envolvía al LLM.
Prompt dado al agente:
Analiza los clientes que se han dado de baja (Churn=’Yes’) que pagan más de 100 en MonthlyCharges.
- Filtra el conjunto de datos a Churn=’Yes’.
- Inspecciona las columnas ‘Metadata’ y ‘SupportNotes’ para descubrir sus tipos de datos.
- Extrae la distribución de ‘device_type’ de la columna JSON ‘Metadata’.
- Cuenta las palabras clave de quejas de la columna de gratis text ‘SupportNotes’.
Devuelve el resultado solo como JSON.
Salida JSON requerida:
Por qué esta tarea discrimina entre frameworks: el agente tiene que planificar una cadena de cuatro llamadas a herramientas, mantener el segmento filtrado en estado a lo largo de cada llamada, y reconocer que una columna es JSON mientras que la otra es gratis text. Un framework que ejecuta las columnas independientes en paralelo (AutoGen) termina mucho más rápido que uno que las ejecuta secuencialmente (LangChain), y un framework que reevalúa los pasos completados (LangGraph, CrewAI) entra en bucles innecesarios. El esquema JSON estricto nos permite puntuar la corrección automáticamente.
2. Configuración
Todos los frameworks utilizaron el mismo modelo de LLM (openai/gpt-5.2) y el mismo valor de temperatura (0.1). Para todas las tareas, a cada agente se le dieron las mismas herramientas y los mismos prompts. Cada framework se configuró en su estructura nativa: LangChain con AgentExecutor, LangGraph con StateGraph, AutoGen con AssistantAgent + UserProxyAgent, y CrewAI con Agent + Task + Crew.
Se utilizó el conjunto de datos de abandono de clientes de telecomunicaciones de IBM (7,032 clientes). El estado de las herramientas se reinició antes de cada ejecución. Se ejecutaron 100 ejecuciones independientes para cada combinación de framework y tarea.
Los límites máximos de iteración se establecieron según la complejidad de la tarea: 10 para las Tareas 1, 2 y 3; 20 para la Tarea 4 debido al bucle de herramienta inestable; y 20 para la Tarea 5 debido a la cadena de descubrimiento de 4 pasos.
Cita este benchmark
Elige el formato que se ajuste al lugar donde vas a publicar. Pegar la versión con enlace en tu CMS conserva el enlace de retroceso.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Şipi, Nazlı},
title = {{Los 5 mejores frameworks de IA agéntica de código abierto}},
year = {2026},
month = jul,
howpublished = {\url{https://aimultiple.com/agentic-frameworks}},
note = {AIMultiple. Recuperado el 6 de Julio de 2026}
}

Comentarios 1
Comparte tus ideas
Tu dirección de correo electrónico no será publicada. Todos los campos son obligatorios. Los comentarios se dejan en su idioma original.
Thank you for this informative and detailed article! It helped me get a reading on these frameworks.