Los 20+ Mejores Frameworks de RAG Agentic
El RAG agentic mejora el RAG tradicional al potenciar el rendimiento de los LLM y permitir una mayor especialización. Realizamos un benchmark para evaluar su rendimiento en el enrutamiento entre múltiples bases de datos y la generación de consultas.
Explore los frameworks y librerías de RAG agentic, las diferencias clave con el RAG estándar, los beneficios y los desafíos para liberar todo su potencial.
Benchmark de RAG agentic: Enrutamiento entre múltiples bases de datos y generación de consultas
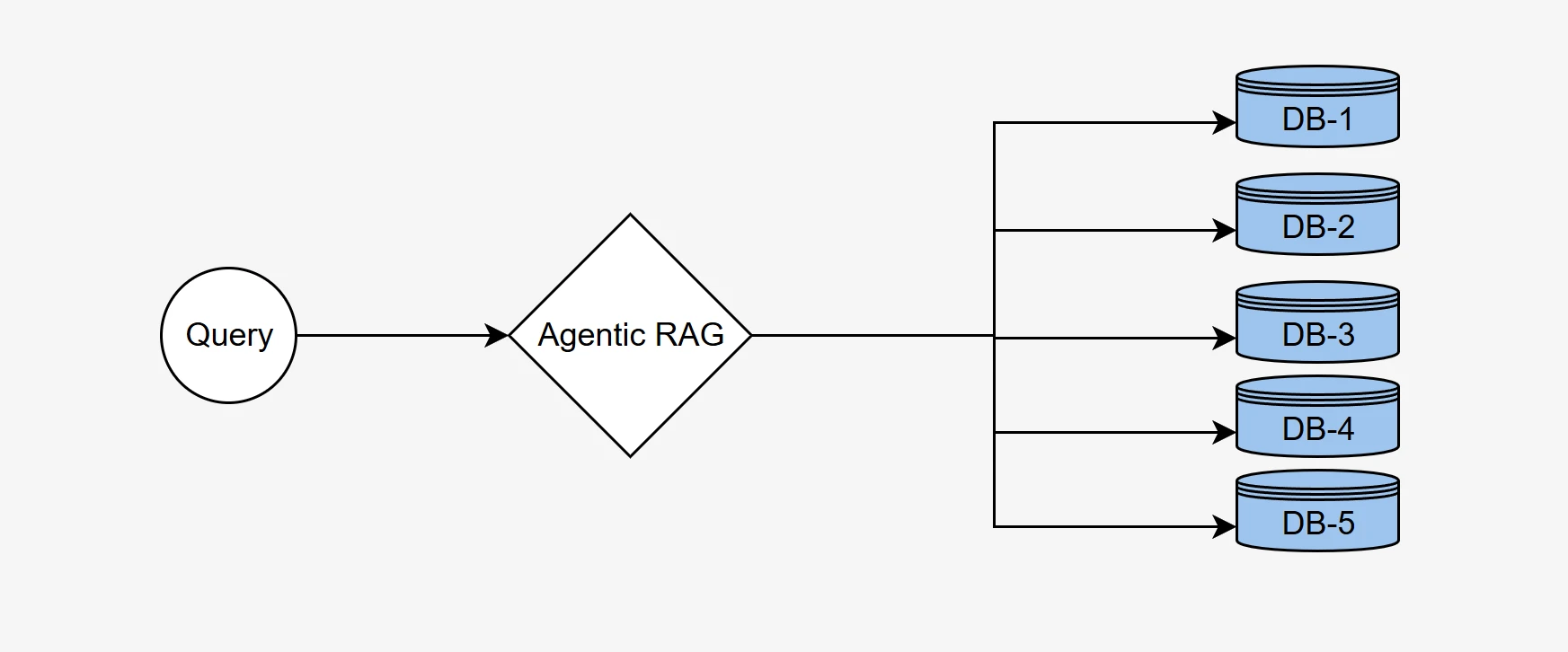
Utilizamos nuestra metodología de benchmark de RAG agentic para demostrar la capacidad del sistema de seleccionar la base de datos correcta de entre cinco bases de datos distintas, cada una con información contextual única, y generar consultas SQL semánticamente precisas para recuperar los datos correctos.
En el benchmark de RAG agentic, utilizamos:
- Framework de agente: Langchain
- Base de datos vectorial: ChromaDB
En muchos escenarios empresariales del mundo real, los datos suelen estar distribuidos en múltiples bases de datos, cada una con información especializada relevante para dominios o tareas específicas. Por ejemplo, una base de datos podría almacenar registros financieros, mientras que otra contiene datos de clientes o detalles de inventario.
Un sistema de RAG agentic eficaz debe enrutar de forma inteligente la consulta de un usuario a la base de datos más relevante para recuperar información precisa. Este proceso implica analizar la consulta, comprender el contexto y seleccionar la fuente de datos adecuada entre un conjunto de bases de datos disponibles.
Proceso de pensamiento del agente
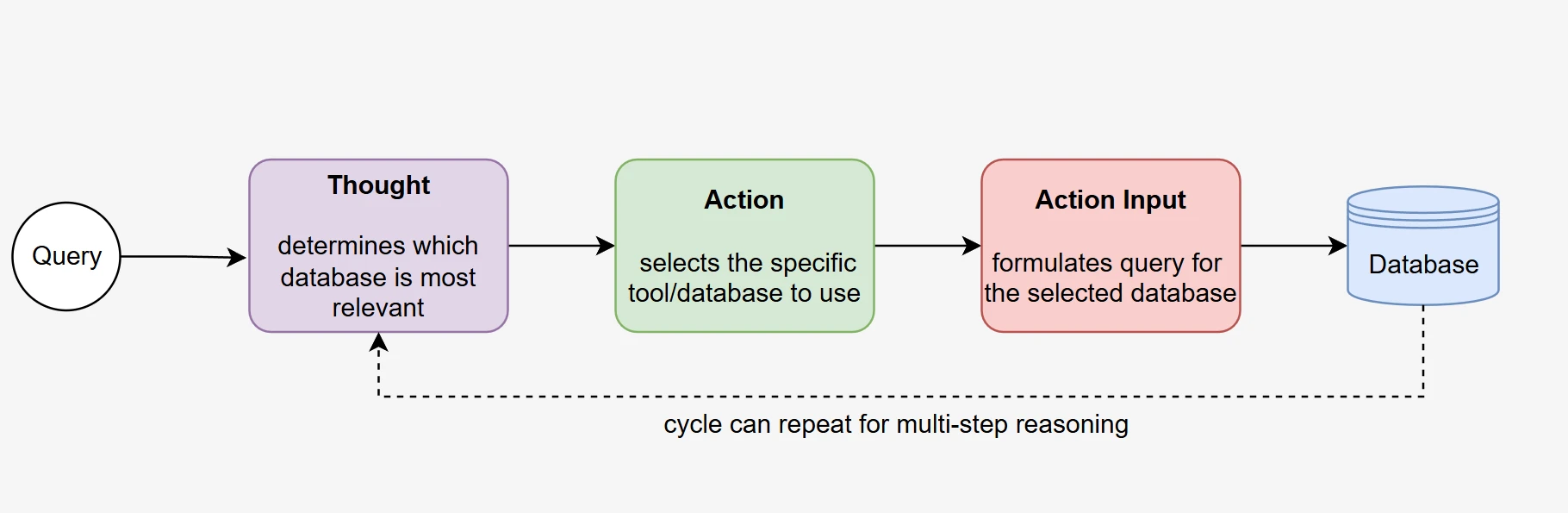
En el corazón de un sistema de RAG agentic se encuentra la capacidad del LLM para razonar y actuar de forma autónoma para alcanzar un objetivo. Nuestro enfoque basado en llamadas a funciones permite a los modelos demostrar un verdadero comportamiento agentivo mediante la selección autodirigida de bases de datos y la recopilación iterativa de información.
Toma de decisiones autónoma: El agente analiza la consulta entrante del usuario y determina de forma autónoma a qué función de base de datos llamar en función del contexto de la consulta y las descripciones de las funciones disponibles. Este proceso de toma de decisiones ocurre sin reglas de enrutamiento predefinidas, lo que demuestra capacidades de razonamiento genuinas.
Ejecución en múltiples pasos: El agente generalmente realiza múltiples llamadas a funciones en secuencia, primero para identificar y acceder a la base de datos relevante, luego para recopilar información detallada del esquema y, finalmente, para refinar su comprensión antes de generar la consulta SQL. Este proceso iterativo refleja los enfoques de resolución de problemas humanos.
Capacidad de autocorrección: Cuando las llamadas iniciales a funciones no proporcionan suficiente información, el agente puede decidir de forma autónoma realizar llamadas adicionales con parámetros refinados, demostrando un comportamiento adaptativo que va más allá de los sistemas de recuperación simples.
Comportamiento orientado a objetivos: A lo largo del proceso, el agente mantiene el enfoque en generar una consulta SQL precisa, utilizando cada resultado de llamada a función para informar decisiones y acciones posteriores.
Este patrón de interacción autónoma y de múltiples turnos diferencia fundamentalmente el RAG agentic de los sistemas de RAG tradicionales que siguen rutas predeterminadas y mecanismos de recuperación de un solo disparo.
Metodología del benchmark de RAG agentic
Este benchmark evalúa la capacidad de los Modelos de Lenguaje de Gran Escala (LLMs) para funcionar como agentes autónomos dentro de un pipeline de Generación Aumentada por Recuperación (RAG). Específicamente, mide dos competencias centrales:
- Enrutamiento de base de datos: La capacidad del agente para identificar y seleccionar correctamente la base de datos más relevante entre múltiples candidatas dada una pregunta en lenguaje natural.
- Generación de SQL: La capacidad del agente para generar una consulta SQL precisa utilizando el esquema de la base de datos seleccionada.
Dataset
El benchmark utiliza el dataset BIRD-SQL1 , un benchmark académico ampliamente adoptado para tareas de texto a SQL. BIRD-SQL proporciona preguntas en lenguaje natural emparejadas con identificadores de base de datos de verdad fundamental y consultas SQL de referencia, lo que lo hace ideal para evaluar tanto la precisión del enrutamiento como la calidad de la generación de consultas.
Del dataset completo de BIRD-SQL, seleccionamos un subconjunto de 500 preguntas distribuidas en cinco bases de datos distintas que cubren dominios diversos:
Cada pregunta tiene exactamente una base de datos objetivo correcta. La respuesta a cada pregunta reside en una base de datos específica, lo que requiere que el agente tome una decisión de enrutamiento definitiva.
Desafío de ambigüedad semántica
Para evaluar las capacidades de razonamiento del agente más allá de la coincidencia superficial de palabras clave, introdujimos la similitud semántica entre bases de datos como un factor de confusión deliberado durante la selección de preguntas.
Proceso de selección de preguntas:
- Todas las preguntas candidatas de las cinco bases de datos se incrustaron usando transformadores de oraciones (
all-MiniLM-L6-v2). - Se calcularon y clasificaron los pares de preguntas entre bases de datos por similitud de coseno.
- Se priorizaron intencionalmente las preguntas con puntajes de similitud de coseno entre bases de datos superiores a 0.70 para su inclusión, creando escenarios donde preguntas semánticamente similares pertenecen a bases de datos completamente diferentes.
Ejemplo de confusión semántica:
Pregunta A (BD financiera): “Para el cliente cuyo préstamo se aprobó por primera vez el 1993/7/5, ¿cuál es la tasa de aumento de su saldo de cuenta desde 1993/3/22 hasta 1998/12/27?”
Pregunta B (BD tarjeta_debito): “Para el cliente que pagó 634.8 en 2012/8/25, ¿cuál fue la tasa de disminución del consumo del año 2012 a 2013?”
Ambas preguntas siguen patrones semánticos casi idénticos: identifican a un cliente específico a través de un evento de transacción, luego calculan una tasa de cambio durante un período de tiempo. Sin embargo, las bases de datos correctas difieren por completo; una requiere datos de préstamos y cuentas, mientras que la otra necesita datos de transacciones y consumo. Esto obliga al agente a realizar un razonamiento contextual más profundo sobre el dominio de los datos en lugar de depender de palabras clave financieras superficiales que coincidirían con ambas bases de datos.
Entorno de base de datos
El esquema y una breve descripción en lenguaje natural de cada base de datos se almacenaron en ChromaDB, una base de datos vectorial utilizada para la recuperación semántica eficiente. La colección de cada base de datos contiene:
- Una descripción de alto nivel del dominio y propósito de la base de datos
- Documentos de esquema por tabla, incluyendo nombres de columna, tipos de datos y descripciones de valores
Esta configuración permite al agente recuperar información relevante del esquema mediante búsqueda semántica después de seleccionar una base de datos objetivo.
Arquitectura del agente
Se empleó una arquitectura agentiva basada en llamadas a funciones en todos los modelos para garantizar una comparación justa y estandarizada. Cada una de las cinco bases de datos se representó como una función invocable distinta (herramienta) con parámetros estandarizados. Este diseño aprovecha las capacidades nativas de llamada a funciones de cada modelo, permitiendo a los modelos de forma autónoma:
- Analizar la pregunta entrante
- Seleccionar e invocar la función de base de datos apropiada
- Recibir información del esquema como respuesta de la función
- Opcionalmente invocar funciones adicionales para refinamiento
- Generar la consulta SQL final
Este enfoque mantiene una metodología de evaluación consistente en diferentes familias de modelos, incluidos los modelos tradicionales y los optimizados para razonamiento.
Flujo del proceso agentivo
El sistema implementa un bucle agentivo genuino de múltiples turnos en lugar de un pipeline fijo:
- Análisis de la pregunta: El agente recibe la pregunta en lenguaje natural junto con las descripciones de las cinco funciones de base de datos disponibles.
- Selección de base de datos (Llamada a herramienta): El agente selecciona y llama de forma autónoma a la función de base de datos que considera más relevante. Esta es una llamada a función real; el agente recibe el esquema como una respuesta estructurada de herramienta dentro del mismo contexto de conversación.
- Razonamiento del esquema: El agente observa el esquema devuelto y razona sobre qué tablas y columnas son relevantes para la pregunta.
- Recuperación opcional: Si el agente determina que la base de datos seleccionada no contiene la información requerida, puede llamar a una función de base de datos diferente, lo que permite la autocorrección sin intervención externa.
- Generación de SQL: Basándose en el contexto acumulado (pregunta + observación del esquema), el agente produce la consulta SQL final.
Este flujo conversacional de múltiples turnos diferencia el benchmark de los enfoques tradicionales de RAG de un solo disparo. El agente mantiene el contexto completo a través de los turnos, puede observar los resultados de sus acciones y puede refinar iterativamente su enfoque, características distintivas del verdadero comportamiento agentivo.
Propiedades arquitectónicas clave:
- La conversación es continua, el agente ve su propio razonamiento previo y las respuestas de las herramientas
- No se imponen límites artificiales de turnos; el agente decide cuándo tiene suficiente información
- Tanto la selección de la base de datos como la generación de SQL ocurren dentro de la misma sesión agentiva
- El número de llamadas a herramientas por pregunta se registra como una métrica adicional para analizar la eficiencia del agente
Proceso de evaluación
Para cada pregunta en el benchmark:
Paso 1: Evaluación del enrutamiento de base de datos
La primera llamada a función de base de datos del agente se registra como su decisión de enrutamiento. Esto se compara con la base de datos de verdad fundamental especificada en el dataset BIRD-SQL.
Métrica: Precisión del enrutamiento de base de datos (% de selecciones correctas del total de preguntas)
Paso 2: Evaluación de calidad de SQL
La consulta SQL generada por el agente se evalúa utilizando un enfoque de LLM como Juez. Un modelo juez separado (Claude 4 Sonnet) recibe tanto el SQL generado por el agente como el SQL de verdad fundamental de BIRD-SQL, y asigna una puntuación de similitud semántica en una escala de 0 a 5:
Decisión de diseño importante: La calidad de SQL se evalúa cuando el agente selecciona la base de datos correcta. Si el agente se enrutó a la base de datos incorrecta, recibe una puntuación automática de 0, ya que una consulta SQL contra el esquema incorrecto es inherentemente sin sentido. Esto asegura que la métrica de calidad de SQL refleje puramente la capacidad de generación de consultas, sin contaminarse por errores de enrutamiento.
Métricas:
- Puntuación media de calidad de SQL (sobre 5.0), calculada sobre las preguntas correctamente enrutadas
- Tasa de coincidencia perfecta: porcentaje de preguntas correctamente enrutadas que obtienen 5/5
Variables controladas
Para garantizar una comparación justa entre modelos:
- Todos los modelos reciben prompts de sistema y definiciones de herramientas idénticos
- La temperatura se establece en 0 para salidas deterministas
- No se proporciona ingeniería de prompts específica del modelo ni ejemplos few-shot (evaluación zero-shot)
- El campo de evidencia de BIRD-SQL (pistas específicas del dominio) se oculta a todos los modelos para medir el razonamiento sin asistencia
- Todos los modelos acceden a la misma instancia de ChromaDB con incrustaciones de esquema idénticas
Frameworks y librerías de RAG agentic
Los frameworks de RAG agentic permiten a los sistemas de IA encontrar información, razonar, tomar decisiones y actuar. Principales herramientas y librerías que impulsan el RAG agentic:
Esta lista incluye herramientas que cumplen los siguientes criterios:
- 50+ estrellas en GitHub.
- Uso común en proyectos de RAG agentic.
Tenga en cuenta que en la tabla:
- Uso de herramientas se refiere a la capacidad nativa de un sistema para enrutar y llamar herramientas dentro de su entorno.
- Tipo de herramienta se refiere al área principal de uso de las herramientas, como:
- Frameworks de RAG agentic están diseñados específicamente para construir, desplegar o configurar sistemas de RAG agentic.
- Librerías de agentes permiten la creación de agentes inteligentes que pueden razonar, tomar decisiones y ejecutar tareas de múltiples pasos.
- Frameworks LLMOps gestionan el ciclo de vida de los LLMs y optimizan el despliegue y uso de LLMs dentro de sistemas basados en agentes.
- LLMs que tienen capacidades integradas para llamada de herramientas y enrutamiento, permitiendo la toma de decisiones dinámica. Otros LLMs pueden requerir APIs externas o integraciones para habilitar la funcionalidad de agente.
- Verificación del uso de herramientas y tipos de agentes se logra a través de fuentes públicas.
¿Qué es el RAG agentic?
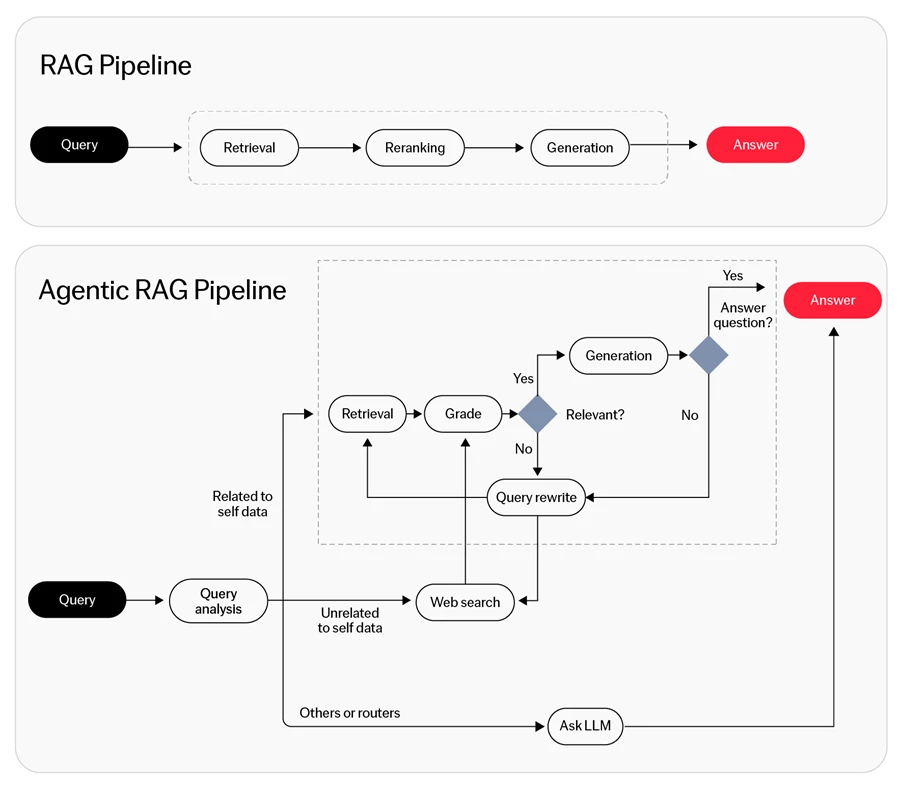
El Retrieval-Augmented Generation (RAG) agentic es un framework de IA que combina técnicas de recuperación con modelos generativos para permitir la toma de decisiones dinámica y la síntesis de conocimiento. Este enfoque integra la precisión del RAG tradicional con las capacidades generativas de la IA avanzada, con el objetivo de mejorar la eficiencia y efectividad de las tareas impulsadas por IA.
Limitaciones de los sistemas de RAG tradicionales
El RAG agentic busca superar las limitaciones del sistema de RAG estándar, tales como:
- Dificultad en la priorización de información: Los sistemas de RAG a menudo luchan por gestionar y priorizar eficientemente los datos dentro de grandes datasets, lo que puede reducir el rendimiento general.
- Integración limitada del conocimiento experto: Estos sistemas pueden subvalorar contenido especializado y de alta calidad, favoreciendo información general en su lugar.
- Comprensión contextual débil: Aunque pueden recuperar datos, con frecuencia no logran comprender completamente su relevancia o cómo se alinea con la consulta específica.
Cómo construir un RAG agentic
1. Uso de herramientas
- Emplear enrutadores: El primer paso implica emplear enrutadores para determinar si se deben recuperar documentos, realizar cálculos o reescribir la consulta. Este enfoque añade capacidades de toma de decisiones para enrutar solicitudes a múltiples herramientas, permitiendo a los modelos de lenguaje de gran escala (LLMs) seleccionar pipelines apropiados.
- Integración de llamada a herramientas: Esto se refiere a crear una interfaz para que los agentes se conecten con las herramientas seleccionadas. Los usuarios pueden aprovechar LLMs con capacidades de llamada a herramientas o construir los suyos propios para:
- Elegir una función para ejecutar.
- Inferir los argumentos necesarios para esa función.
- Mejorar la comprensión de la consulta más allá de los pipelines de RAG tradicionales, permitiendo tareas como consultas a bases de datos o razonamiento complejo.
2. Implementación del agente
- Agentes de una sola llamada: Una consulta desencadena una única llamada a la herramienta apropiada, devolviendo la respuesta. Esto es efectivo para tareas sencillas, pero puede tener dificultades con consultas vagas o complejas.
- Agentes de múltiples llamadas: Este enfoque implica dividir las tareas entre agentes especializados, cada uno enfocado en una subtarea específica. Por ejemplo:
- Agente recuperador: Optimiza la recuperación de consultas en tiempo real.
- Agente gestor: Maneja la delegación de tareas y la orquestación.
3. Razonamiento multi-paso
Para flujos de trabajo complejos, los agentes utilizan bucles de razonamiento para realizar razonamiento iterativo de múltiples pasos mientras retienen la memoria de los pasos intermedios. Estos bucles implican:
- Llamar a múltiples herramientas.
- Recuperar datos y validar su relevancia.
- Reescribir consultas según sea necesario.
Los frameworks a menudo definen múltiples agentes para manejar subtareas específicas, asegurando una ejecución eficiente del proceso general.
4. Enfoques híbridos: combinando recuperación y ejecución
Un enfoque híbrido combina pipelines de recuperación con estrategias de ejecución dinámica:
- Estrategias de incrustación y recuperación basada en vectores para el acceso a documentos.
- Capacidades de llamada a herramientas para la resolución dinámica de consultas.
- Colaboración multi-agente para subtareas especializadas.
¿Cuál es la diferencia entre RAG y RAG agentic?
Aquí están las fortalezas y debilidades de RAG vs. RAG agentic según diferentes aspectos:
- Ingeniería de prompts
- RAG tradicional: Depende en gran medida de la optimización manual de prompts.
- RAG agentic: Ajusta dinámicamente los prompts según el contexto y los objetivos, reduciendo la necesidad de intervención manual.
- Conciencia contextual
- RAG tradicional: Tiene conciencia contextual limitada y se basa en procesos de recuperación estáticos.
- RAG agentic: Considera el historial de la conversación y adapta las estrategias de recuperación dinámicamente según el contexto.
- Autonomía
- RAG tradicional: Carece de acciones autónomas y no puede adaptarse a situaciones cambiantes.
- RAG agentic: Realiza acciones en tiempo real y se ajusta según la retroalimentación y las observaciones en tiempo real.
- Razonamiento
- RAG tradicional: Requiere clasificadores y modelos adicionales para el razonamiento multi-paso y el uso de herramientas.
- RAG agentic: Maneja el razonamiento multi-paso internamente, eliminando la necesidad de modelos externos.
- Calidad de datos
- RAG tradicional: No tiene un mecanismo integrado para evaluar la calidad de los datos o asegurar la precisión.
- RAG agentic: Evalúa la calidad de los datos y realiza verificaciones post-generación para asegurar salidas precisas.
- Flexibilidad
- RAG tradicional: Opera con reglas estáticas, limitando la adaptabilidad.
- RAG agentic: Emplea estrategias de recuperación dinámicas y ajusta su enfoque según sea necesario.
- Eficiencia de recuperación
- RAG tradicional: La recuperación es estática y a menudo costosa debido a ineficiencias.
- RAG agentic: Optimiza las recuperaciones para minimizar operaciones innecesarias, reduciendo costes y mejorando la eficiencia.
- Simplicidad
- RAG tradicional: Presenta una configuración sencilla con menos complejidades de configuración.
- RAG agentic: Implica configuraciones más complejas para soportar operaciones dinámicas y conscientes del contexto.
- Previsibilidad
- RAG tradicional: Consistente y basado en reglas, pero rígido en el comportamiento.
- RAG agentic: El comportamiento puede variar dinámicamente según el contexto y las observaciones en tiempo real.
- Coste en despliegues
- RAG tradicional: Más barato para configuraciones básicas, pero puede incurrir en mayores costes operativos a largo plazo.
- RAG agentic: Requiere una inversión inicial más alta debido a las características avanzadas y las capacidades dinámicas.
Modelos de contexto largo vs RAG agentic: Cuando la recuperación se vuelve innecesaria
La revolución de la ventana de contexto de 2025-2026 desafía un supuesto central en la arquitectura de RAG. Los modelos ahora soportan 1-2 millones de tokens, lo que plantea una pregunta fundamental: ¿cuándo el procesamiento directo del contexto supera a los complejos agentes de recuperación?
El panorama cambiante del contexto
Las ventanas de contexto se expandieron dramáticamente de 128k tokens a principios de 2024 a más de 1M en 2026. Investigaciones recientes utilizando novelas completas como datos de prueba revelan que esta expansión crea nuevos compromisos arquitectónicos que los ingenieros deben considerar.4
El coste computacional de procesar contextos masivos debe sopesarse frente a la complejidad de ingeniería y los posibles puntos de fallo de los sistemas de recuperación. Procesar 1M tokens elimina la compresión con pérdida del chunking y la indexación, pero a un alto coste por consulta.
El problema del cuello de botella de recuperación
La investigación sobre documentos de formato largo identifica una limitación severa en los enfoques de RAG tradicionales. La recuperación top-k estándar crea lo que los investigadores llaman un “cuello de botella de recuperación”: cuando la búsqueda inicial no alcanza el fragmento relevante, el sistema carece de un mecanismo de recuperación.
El RAG agentic aborda esto mediante el refinamiento iterativo de consultas. Los estudios muestran que los sistemas agentivos resuelven con éxito una parte significativa de los problemas que fallan por completo bajo la recuperación de un solo disparo. El bucle autónomo permite a los agentes reformular consultas cuando los intentos iniciales devuelven información insuficiente.5
Sin embargo, cuando los datos caben dentro de las ventanas de contexto ampliadas, el procesamiento directo de contexto largo supera incluso a los sofisticados sistemas de recuperación agentivos. La brecha de rendimiento existe porque el modelo puede razonar sobre todo el documento simultáneamente, evitando la fragmentación inherente a la recuperación basada en fragmentos.
Diferentes tipos de modelos de RAG agentic
Algunos de los agentes que aprovechan los Modelos de Lenguaje de Gran Escala (LLMs) dentro de los frameworks de Generación Aumentada por Recuperación (RAG) incluyen:
- Agente enrutador: Utiliza un Modelo de Lenguaje de Gran Escala (LLM) para el razonamiento agentivo y seleccionar el pipeline de Generación Aumentada por Recuperación (RAG) más apropiado (p. ej., resumen o respuesta a preguntas) para una consulta dada. El agente determina la mejor opción analizando la consulta de entrada.
- Agente de planificación de consultas de un solo disparo: Descompone consultas complejas en subconsultas más pequeñas, las ejecuta a través de varios pipelines de RAG con diferentes fuentes de datos y combina los resultados en una respuesta completa.
- Agente de uso de herramientas: Mejora los frameworks de RAG estándar incorporando fuentes de datos externas (p. ej., APIs, bases de datos) para proporcionar contexto adicional. Esto permite un procesamiento más enriquecido de las consultas utilizando LLMs.
- Agente ReAct: Integra razonamiento y acción para manejar consultas secuenciales de varias partes. Mantiene un estado en memoria e invoca herramientas de forma iterativa, procesa sus salidas y determina los siguientes pasos hasta que la consulta se resuelve por completo.
- Agente de planificación y ejecución dinámica: Dirigido a gestionar consultas más complejas, este agente separa la planificación de alto nivel de la ejecución. Utiliza un LLM como planificador para diseñar un grafo computacional de los pasos necesarios para responder la consulta y emplea un ejecutor para llevar a cabo estos pasos de manera eficiente. El enfoque está en la fiabilidad, observabilidad, paralelización y optimización para entornos de producción.
Beneficios del RAG agentic
El RAG agentic mejora los LLMs a través de:
- Enfoque autónomo y orientado a objetivos: A diferencia del RAG tradicional, el RAG agentic actúa como un agente autónomo, tomando decisiones para alcanzar objetivos definidos y buscando interacciones más profundas y significativas.
- Mejora de la conciencia y sensibilidad contextual: El RAG agentic considera dinámicamente el historial de la conversación, las preferencias del usuario, las interacciones previas y el contexto actual para proporcionar respuestas relevantes e informadas y toma de decisiones.
- Recuperación dinámica y razonamiento avanzado: Utiliza métodos de recuperación inteligentes adaptados a las consultas, mientras evalúa y verifica la precisión y fiabilidad de los datos recuperados.
- Orquestación multi-agente: Coordina múltiples agentes especializados, descomponiendo consultas en tareas manejables y asegurando una coordinación perfecta para entregar resultados precisos.
- Mayor precisión con verificación post-generación: Los modelos de RAG agentic realizan controles de calidad en el contenido generado, asegurando la mejor respuesta posible y combinando LLMs con sistemas basados en agentes para un rendimiento superior.
- Adaptabilidad y aprendizaje: Estos sistemas aprenden y mejoran continuamente con el tiempo, mejorando las habilidades de resolución de problemas, precisión y eficiencia, y adaptándose a varios dominios para tareas específicas.
- Utilización flexible de herramientas: Los agentes pueden aprovechar herramientas externas como motores de búsqueda, bases de datos o APIs para mejorar la recopilación de datos, el procesamiento y la personalización para aplicaciones diversas.
Desafíos del RAG agentic
- Calidad de datos: Las salidas fiables requieren datos seleccionados y de alta calidad. Surgen desafíos al integrar y procesar datasets diversos, incluidos datos textuales y visuales, para cumplir con los requisitos de las consultas de los usuarios. Además, los procesos de recuperación de datos deben garantizar precisión y consistencia.
- Consejo: Implemente herramientas automatizadas de limpieza de datos y técnicas de validación de datos impulsadas por IA para asegurar una integración de datos consistente y de alta calidad en datasets textuales y visuales.
- Escalabilidad: La gestión eficiente de los recursos del sistema y los procesos de recuperación es crítica a medida que el sistema crece. A medida que aumentan las consultas de los usuarios y los volúmenes de datos, manejar tanto el procesamiento en tiempo real como por lotes para una mayor recuperación de datos se convierte en un desafío significativo.
- Consejo: Utilice infraestructura escalable basada en la nube y frameworks de computación distribuida para manejar cargas de datos crecientes de manera eficiente. Incorpore balanceo de carga dinámico para el manejo de consultas en tiempo real.
- Explicabilidad: Asegurar la transparencia en la toma de decisiones genera confianza. Proporcionar información clara sobre cómo se generan las respuestas a las consultas de los usuarios, particularmente cuando se aprovechan datos textuales y visuales, sigue siendo un desafío persistente.
- Consejo: Aproveche herramientas de explicabilidad de IA como SHAP o LIME para hacer que las predicciones del modelo sean interpretables e integre paneles de visualización para aclarar el razonamiento detrás de las respuestas.
- Privacidad y seguridad: Es esencial una fuerte protección de datos y protocolos de comunicación seguros. La gestión de datos sensibles o confidenciales requiere cifrado robusto y mecanismos de cumplimiento durante el almacenamiento, la recuperación adicional de datos y el procesamiento.
- Consejo: Emplee cifrado de extremo a extremo y soluciones de gestión de acceso, y asegure el cumplimiento de regulaciones de protección de datos como GDPR o CCPA. Utilice pasarelas de API seguras para la recuperación adicional de datos.
- Preocupaciones éticas: Abordar el sesgo, la equidad y el mal uso es crucial para un despliegue responsable de la IA. Asegurar respuestas imparciales a consultas diversas de los usuarios sigue siendo una consideración clave en el diseño ético de IA.
- Consejo: Despliegue plataformas de IA responsable y herramientas de gobernanza de IA para hacer frente al sesgo de IA y cumplir con los cuatro principios rectores de la IA.
Perspectivas futuras
La investigación más reciente sobre el RAG agentic incluye áreas de mejora como:
- Integración de grafos de conocimiento: Mejora el razonamiento al aprovechar relaciones de datos complejas.
- Tecnologías emergentes: Incorporación de herramientas como ontologías y la web semántica para avanzar en las capacidades del sistema.
- Colaboración de agentes especializados: Agentes con experiencia en diferentes dominios (p. ej., ventas, marketing, finanzas) trabajan juntos en un flujo de trabajo coordinado para abordar tareas complejas.
- Optimización de la calidad: Abordar la salida inconsistente para mejorar la fiabilidad y precisión de los sistemas multi-agente.
Lecturas adicionales
Explore otros benchmarks de RAG, tales como:
- Top 10 Modelos de Incrustación Multilingüe para RAG
- Modelos de Incrustación: OpenAI vs Gemini vs Cohere
- Top 16 Modelos de Incrustación de Código Abierto para RAG
- Top Base de Datos Vectorial para RAG: Qdrant vs Weaviate vs Pinecone
- Benchmark de Re-rankers: Top 8 Modelos Comparados
- Modelos de Incrustación Multimodal: Apple vs Meta vs OpenAI
Preguntas frecuentes
La Generación Aumentada por Recuperación (RAG) es una técnica que combina métodos basados en recuperación con modelos generativos para mejorar la recuperación de información y la generación de respuestas.
Explore más sobre la técnica de generación aumentada por recuperación y modelos comunes.
Un agente es un programa informático diseñado para observar su entorno, tomar decisiones y ejecutar acciones de forma autónoma para alcanzar objetivos específicos sin intervención humana directa.
Uso en Sistemas de IA
Los agentes se utilizan para automatizar tareas, optimizar procesos y tomar decisiones inteligentes en entornos dinámicos. Dependiendo de su complejidad, los agentes pueden variar desde sistemas simples basados en reglas hasta modelos avanzados que utilizan técnicas de aprendizaje.
Tipos de Agentes
Agentes Reactivos: Operan basándose en el estado actual del entorno y siguen reglas predefinidas, sin utilizar experiencias pasadas.
Agentes Cognitivos: Almacenan experiencias pasadas y las utilizan para analizar patrones y tomar decisiones, lo que permite el aprendizaje de interacciones previas.
Agentes Colaborativos: Interactúan con otros agentes o sistemas para alcanzar objetivos compartidos, a menudo dentro de sistemas multi-agente donde la coordinación y el intercambio de información son clave.
El RAG agentic puede ser mejor para tareas que requieren una toma de decisiones más dinámica y consciente del contexto e interacciones iterativas, pero su efectividad depende del caso de uso específico y las necesidades de implementación.
El RAG vainilla recupera y genera respuestas pasivamente basándose en un modelo estático de consulta-respuesta, mientras que el RAG agentic incorpora procesos iterativos, toma de decisiones e interacciones dinámicas para refinar respuestas o manejar tareas complejas.
Cita este benchmark
Elige el formato que se ajuste al lugar donde vas a publicar. Pegar la versión con enlace en tu CMS conserva el enlace de retroceso.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Sarı, Ekrem},
title = {{Los 20+ Mejores Frameworks de RAG Agentic}},
year = {2026},
month = jul,
howpublished = {\url{https://aimultiple.com/agentic-rag}},
note = {AIMultiple. Recuperado el 17 de Julio de 2026}
}Enlaces de referencia
El trabajo de Cem ha sido citado por publicaciones globales líderes como Business Insider, Forbes, Washington Post, firmas globales como Deloitte, HPE y ONG como el Foro Económico Mundial y organizaciones supranacionales como la Comisión Europea.
A lo largo de su carrera, Cem se ha desempeñado como consultor tecnológico, comprador de tecnología y emprendedor tecnológico. Asesoró a empresas en sus decisiones tecnológicas en McKinsey & Company y Altman Solon durante más de una década. También publicó un informe de McKinsey sobre digitalización.
Lideró la estrategia tecnológica y las adquisiciones de una empresa de telecomunicaciones reportando directamente al CEO. También lideró el crecimiento comercial de la empresa de tecnología profunda Hypatos, que alcanzó ingresos recurrentes anuales de 7 dígitos y una valoración de 9 dígitos desde 0 en 2 años. El trabajo de Cem en Hypatos fue cubierto por publicaciones tecnológicas líderes como TechCrunch y Business Insider.
Cem habla regularmente en conferencias internacionales de tecnología. Se graduó de la Universidad de Bogazici como ingeniero informático y tiene un MBA de Columbia Business School.





Sé el primero en comentar
Tu dirección de correo electrónico no será publicada. Todos los campos son obligatorios. Los comentarios se dejan en su idioma original.