15 Herramientas de Observabilidad de Agentes de IA: AgentOps & Langfuse
Las herramientas de observabilidad de agentes de IA, como Langfuse y Arize, ayudan a recopilar trazas detalladas (un registro de la ejecución de un programa o transacción) y proporcionan paneles para monitorizar métricas en tiempo real.
Muchos frameworks de agentes, como LangChain, utilizan el estándar OpenTelemetry para compartir metadatos con el monitoreo agentivo. Además, muchas herramientas de observabilidad proporcionan instrumentación personalizada para una mayor flexibilidad.
Probamos 15 plataformas de observabilidad para aplicaciones de LLM y agentes de IA. Cada plataforma se implementó de forma práctica mediante la configuración de flujos de trabajo, la integración de conectores y la ejecución de escenarios de prueba. Realizamos benchmarks de 4 herramientas de observabilidad para medir si introducen sobrecarga en los pipelines de producción. También demostramos un tutorial de observabilidad de LangChain usando Langfuse.
Benchmark de sobrecarga de herramientas de monitoreo agentivo
Integramos cada plataforma de observabilidad en nuestro sistema multiagente de planificación de viajes y ejecutamos 100 consultas idénticas para medir su sobrecarga de rendimiento en comparación con una línea base sin instrumentación. Lea nuestra metodología de benchmark.
- LangSmith demostró una eficiencia excepcional con prácticamente ninguna sobrecarga medible, lo que lo hace ideal para entornos de producción donde el rendimiento es crítico.
- Laminar introdujo una sobrecarga mínima del 5%, lo que lo hace altamente adecuado para entornos de producción donde el rendimiento es crítico.
- AgentOps y Langfuse mostraron una sobrecarga moderada del 12% y 15% respectivamente, lo que representa un equilibrio razonable entre las funciones de observabilidad y el impacto en el rendimiento. Estas plataformas aún mantienen una latencia aceptable para la mayoría de los casos de uso en producción.
Posibles razones detrás de las diferencias de rendimiento
Nuestro benchmark indica que las diferencias de latencia están impulsadas por la profundidad de instrumentación y la implicación en la ruta de ejecución, particularmente en flujos de trabajo multiagente. Las herramientas que ofrecen una observabilidad más profunda a nivel de paso exhibieron una mayor sobrecarga, mientras que los enfoques de trazado más ligeros se mantuvieron más cerca de la línea base.
1. Profundidad de instrumentación en la ruta de ejecución
Las herramientas de observabilidad añaden lógica al flujo de ejecución del agente para capturar trazas y metadatos. Cuando esta lógica se ejecuta de forma síncrona durante el manejo de solicitudes, aumenta directamente la latencia de extremo a extremo porque el agente debe completar este trabajo adicional antes de devolver una respuesta.
Por ejemplo:
- LangSmith añadió prácticamente ninguna sobrecarga medible (~0%), lo que indica poco trabajo síncrono,
- La instrumentación más profunda a nivel de paso de Langfuse contribuyó a una sobrecarga mayor (~15%).
2. Amplificación de eventos en pipelines de múltiples pasos
En sistemas multiagente, una sola solicitud de usuario desencadena múltiples acciones del agente. Cuando una herramienta registra datos detallados en cada paso, el número total de eventos crece rápidamente, aumentando la sobrecarga de procesamiento y manejo de trazas a medida que el flujo de trabajo se vuelve más profundo.
En los resultados del benchmark:
- Langfuse y AgentOps generaron una sobrecarga notablemente mayor (15% y 12%) en nuestro flujo de trabajo de planificación de viajes de múltiples pasos
- LangSmith y Laminar emitieron menos eventos por paso del agente.
3. Sobrecarga de evaluación y validación en línea
Algunas plataformas realizan comprobaciones adicionales o monitoreo mientras el agente está en ejecución. Aunque cada comprobación es ligera, aplicarlas repetidamente en todos los pasos del agente añade una latencia medible.
Por ejemplo:
- El monitoreo a nivel de ciclo de vida de AgentOps coincidió con una sobrecarga del 12%
- Laminar no mostró evidencia de que la evaluación en línea afectara la ejecución, manteniéndose en ~5%.
4. Frecuencia de serialización y persistencia
Capturar datos detallados de observabilidad requiere serializar trazas y escribirlas en almacenamiento o backends externos. Un mayor detalle de traza aumenta la frecuencia con la que esto ocurre, añadiendo sobrecarga de E/S a cada solicitud.
En nuestro benchmark:
- El trazado detallado de prompts, salidas y tokens de Langfuse resultó en la mayor sobrecarga (~15%)
- Los artefactos de traza más ligeros de LangSmith se mantuvieron cerca de la línea base.
5. Grado de integración con el framework del agente
El grado de integración de una herramienta con el framework del agente afecta al rendimiento. Las integraciones más estrechas reducen los pasos de traducción y orquestación, mientras que los SDK más genéricos añaden capas adicionales de procesamiento.
Por ejemplo:
- La estrecha alineación de LangSmith con la ejecución del agente se correlacionó con ~0% de sobrecarga
- AgentOps y Langfuse mostraron un mayor impacto en la latencia, consistente con rutas de integración más desacopladas.
Plataformas de observabilidad de agentes de IA
Nivel 1: Observabilidad detallada de LLM y prompt / salida
* Las capacidades enumeradas en estas columnas son ejemplos ilustrativos de lo que cada herramienta puede monitorizar cuando se amplía mediante integraciones o personalización. No son exclusivas de una sola plataforma.
Nivel 2: Observabilidad de flujo de trabajo, modelo y evaluación
Nivel 3: Observabilidad del ciclo de vida y operaciones del agente
Nivel 4: Monitoreo de sistema e infraestructura (no nativo para agentes)
Datadog (con su módulo de Observabilidad de LLM) y Prometheus (mediante exportadores) se utilizan cada vez más junto con Langfuse/LangSmith.
Plataformas de desarrollo y orquestación de agentes:
- Herramientas como Flowise, Langflow, SuperAGI y CrewAI permiten construir, orquestar y optimizar flujos de trabajo de agentes con interfaces sin código o de bajo código
Ediciones gratuitas de implementación y precios
Las ediciones gratuitas varían según los límites de uso (ej., observaciones, trazas, tokens o unidades de trabajo). Los precios iniciales suelen corresponder a un plan básico, que puede tener restricciones en funciones, usuarios o límites de uso.
Weights & Biases (W&B Weave)
Caso de uso: Depuración de fallos en sistemas multiagente mediante el trazado de cómo se propagan los errores a través de las llamadas entre agentes.
Weights & Biases Weave registra trazas de ejecución estructuradas para sistemas multiagente, preservando las relaciones padre-hijo entre las llamadas de los agentes. Las entradas, salidas, estados intermedios, latencia y uso de tokens se capturan por agente y por traza.
Funciones de monitoreo de Weave
- Trazado jerárquico de agentes en lugar de registros de solicitudes planos
- Atribución de coste y latencia a nivel de agente
- Soporte nativo para calificadores de evaluación aplicados directamente a las trazas.
Capacidades de evaluación
Weave también proporciona calificadores integrados para evaluación, incluyendo:
- HallucinationFreeScorer para detectar alucinaciones,
- SummarizationScorer para evaluar la calidad de los resúmenes,
- EmbeddingSimilarityScorer para similitud semántica,
- ValidJSONScorer y ValidXMLScorer para validación de formato,
- PydanticScorer para cumplimiento de esquemas,
- OpenAIModerationScorer para seguridad del contenido,
- Calificadores RAGAS como ContextEntityRecallScorer,
- ContextRelevancyScorer para evaluación de sistemas RAG.
Más adecuado para: Equipos que ejecutan flujos de trabajo de múltiples pasos o multiagente que necesitan análisis de causa raíz a nivel de traza en lugar de métricas superficiales.
Langfuse
Casos de uso: Rastrear interacciones de LLM, gestionar versiones de prompts y monitorizar el rendimiento del modelo con sesiones de usuario.
Langfuse ofrece una visibilidad profunda de la capa de prompts, capturando prompts, respuestas, costes y trazas de ejecución para ayudar a depurar, monitorizar y optimizar aplicaciones de LLM.
Sin embargo, Langfuse puede no ser adecuado para equipos que prefieren flujos de trabajo basados en Git para la gestión de código y prompts, ya que su sistema externo de gestión de prompts puede no ofrecer el mismo nivel de control de versiones y colaboración.
Funciones de monitoreo de Langfuse
- Visibilidad de la evolución de los prompts y los patrones de uso
- Análisis basado en sesiones adecuado para aplicaciones orientadas al usuario
- Modelo práctico de metadatos y etiquetado para filtrado y revisión
Funciones de nivel empresarial:
Algunas de estas funciones incluyen:
- Niveles de registro: Ajustar la verbosidad de los registros para obtener información más detallada.
- Multimodalidad: Soporta texto, imágenes, audio y otros formatos para aplicaciones multimodales de LLM.
- Lanzamientos y versionado: Rastrear el historial de versiones y ver cómo los nuevos lanzamientos afectan al rendimiento del modelo.
- URLs de trazas: Acceder a trazas detalladas mediante URLs únicas para una inspección y depuración más profundas.
- Grafos de agentes: Visualizar las interacciones y dependencias de los agentes para comprender mejor su comportamiento.
- Muestreo: Recopilar datos representativos de las interacciones para analizarlos sin saturar el sistema.
- Seguimiento de tokens y costes: Rastrear el uso de tokens y los costes de cada llamada al modelo, garantizando una gestión eficiente de los recursos.
- Enmascaramiento: Proteger datos sensibles enmascarándolos en las trazas, garantizando la privacidad y el cumplimiento.
Más adecuado para: Equipos que iteran sobre prompts y monitorizan el uso en producción, especialmente donde las sesiones de usuario son importantes.
Galileo
Casos de uso: Monitorizar coste/latencia, evaluar la calidad de la salida, bloquear respuestas inseguras y proporcionar soluciones prácticas.
Galileo rastrea métricas de coste, latencia y calidad de salida mientras aplica comprobaciones de seguridad y cumplimiento en tiempo real.
La plataforma combina observabilidad tradicional (latencia, coste, rendimiento) con depuración y evaluación impulsadas por IA (detección de alucinaciones, corrección factual, coherencia, adherencia al contexto).
Funciones de monitoreo de Galileo
- Identificación de modos de fallo más allá de los errores superficiales (ej., alucinaciones que conducen a entradas de herramientas no válidas)
- Retroalimentación prescriptiva como cambios de prompt sugeridos o adiciones de few-shot
- Estrecha vinculación entre los resultados de la evaluación y las soluciones recomendadas.
Más adecuado para: Organizaciones que priorizan la calidad de la salida, la seguridad y los ciclos de iteración rápidos con remediación guiada.
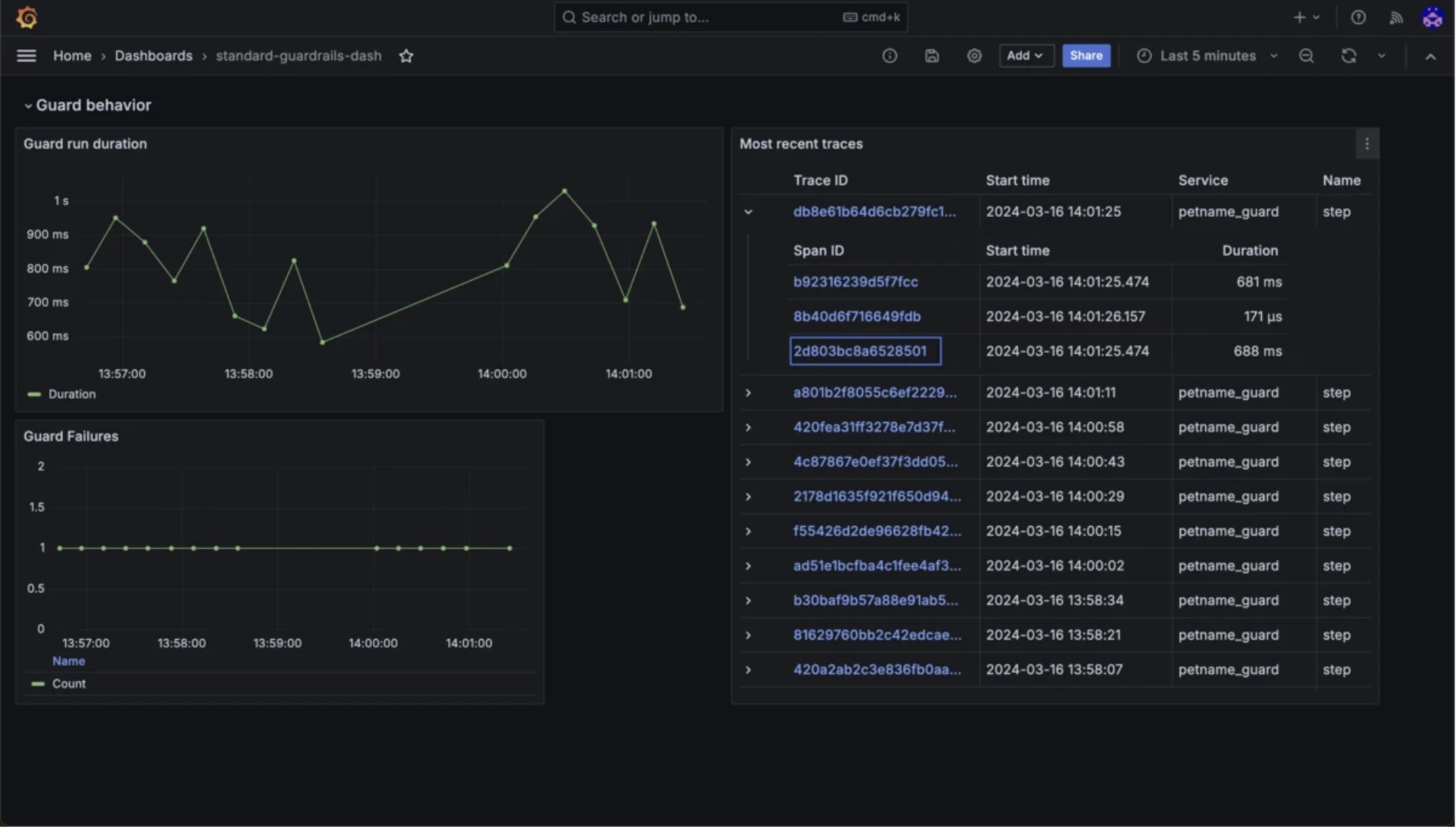
Guardrails IA
Casos de uso: Prevenir salidas dañinas, validar respuestas de LLM y garantizar el cumplimiento de las políticas de seguridad
Guardrails valida las entradas y salidas de LLM contra reglas configurables, incluyendo toxicidad, sesgo, exposición de PII, detección de alucinaciones y cumplimiento de formato.
Funciones de monitoreo de Guardrails IA
- Validación determinista mediante especificaciones RAIL
- Guardas de entrada para detección de inyección de prompts y jailbreak
- Reintentos automáticos cuando la validación falla.
Más adecuado para
Equipos que deben hacer cumplir garantías estrictas de seguridad, cumplimiento o formato antes de que se devuelvan las respuestas.
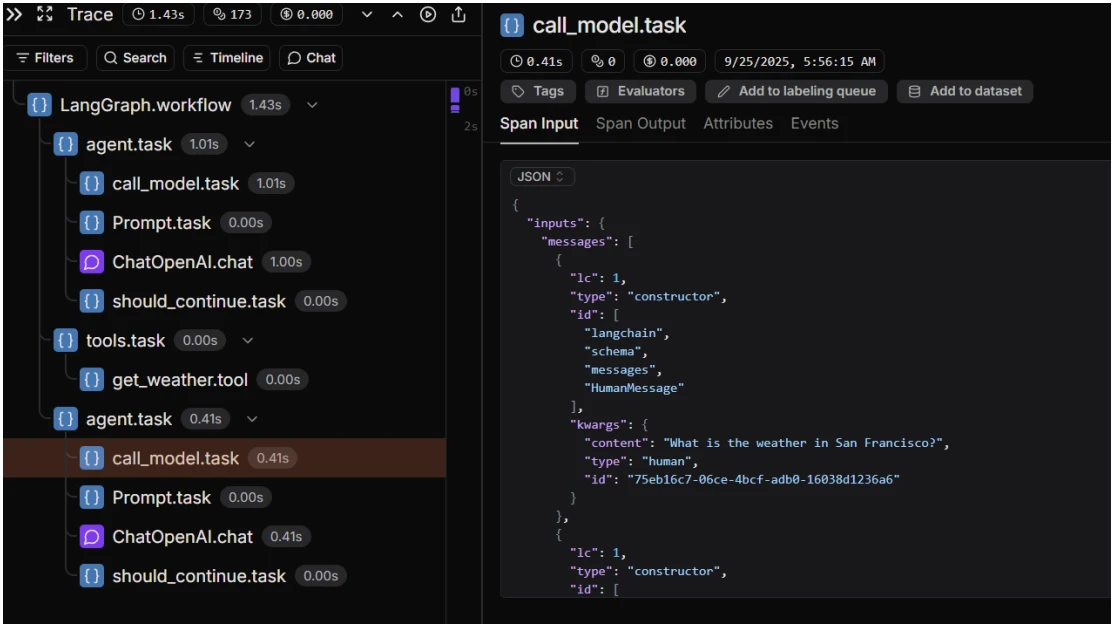
LangSmith
Casos de uso: Depuración del razonamiento del agente y de las llamadas a herramientas (centrado en LangChain)
LangSmith captura trazas completas de razonamiento para agentes basados en LangChain, incluyendo prompts, contexto recuperado, lógica de selección de herramientas, entradas/salidas de herramientas, errores y excepciones.
Funciones de monitoreo de LangSmith
- Inspección paso a paso de las rutas de decisión del agente
- Reproducción de ejecuciones y comparación lado a lado entre prompts, modelos o herramientas
- Integración estrecha con LangChain mediante callbacks.
Más adecuado para
Equipos que construyen con LangChain y necesitan depurar en detalle el razonamiento incorrecto o la invocación de herramientas.
Langtrace IA
Casos de uso: Identificar cuellos de botella de coste y latencia en aplicaciones de LLM
Langtrace rastrea recuentos de tokens, duración de ejecución, costes de API y parámetros de solicitud a través de pipelines de LLM utilizando trazas compatibles con OpenTelemetry.
Funciones de monitoreo de Langtrace IA
- Alineación con OpenTelemetry para integración con backends existentes
- Visibilidad de los factores de coste y latencia por paso
- Versionado ligero de prompts y entorno de pruebas.
Más adecuado para: Equipos que optimizan el rendimiento y el gasto en flujos de trabajo de LLM en lugar de evaluar la calidad de la salida.
Arize (Phoenix)
Casos de uso: Monitorizar la deriva del modelo, detectar sesgos y evaluar las salidas de LLM con sistemas de puntuación integrales
Phoenix se centra en la deriva del comportamiento, la detección de sesgos y la puntuación de LLM como juez para relevancia, toxicidad y precisión.
Sin embargo, tiene una mayor sobrecarga de integración en comparación con proxies ligeros y no gestiona el versionado de prompts tan limpiamente como las herramientas dedicadas.
Funciones de monitoreo de Phoenix
- Núcleo de código abierto con extensiones empresariales opcionales
- Entorno interactivo de pruebas de prompts para desarrollo
- Detección de deriva para rastrear cambios de comportamiento en el tiempo
- Comprobaciones de sesgo para identificar sesgos en las respuestas,
- Puntuación de LLM como juez para precisión, toxicidad y relevancia.
Más adecuado para: Equipos que monitorizan el comportamiento del modelo a largo plazo y el riesgo de regresión en lugar de la iteración de prompts.
Agenta
Casos de uso: Descubrir qué prompt funciona mejor en qué modelo
Agenta compara las respuestas de los modelos en términos de coste, latencia y calidad de salida utilizando entradas compartidas y contexto controlado.
Funciones de monitoreo de Agenta
- Evaluación de modelos lado a lado
- Soporte para decisiones previas a la producción.
Más adecuado para: Evaluación en fase temprana y selección de modelos.
AgentOps.ai
Casos de uso: Monitorizar el razonamiento del agente, rastrear costes y depurar sesiones en producción
AgentOps captura trazas de razonamiento, llamadas a herramientas/API, estado de la sesión, comportamiento de caché y métricas de coste para agentes desplegados.
Funciones de monitoreo de AgentOps
- Reproducción de sesiones para depuración en producción
- Enfoque en el comportamiento del agente en vivo en lugar de la evaluación offline.
Más adecuado para: Equipos que ejecutan agentes en producción y necesitan visibilidad operativa.
Braintrust
Casos de uso: Descubrir qué prompt, dataset o modelo funciona mejor con una evaluación detallada y análisis de errores
Braintrust evalúa prompts, datasets y modelos con respecto a las salidas esperadas, rastreando latencia, coste, errores de herramientas y métricas de ejecución.
Funciones de monitoreo de Braintrust
- Evaluar datasets de prueba con entradas y salidas esperadas, luego comparar prompts o modelos lado a lado usando variables como
{{input}},{{expected}}y{{metadata}}. - Desgloses de métricas incluyendo la calidad de ejecución de herramientas
Más adecuado para: Equipos que realizan benchmarks de modelos y prompts antes del despliegue.
AgentNeo
Casos de uso: Depuración de interacciones multiagente, trazado del uso de herramientas y evaluación de flujos de trabajo de coordinación
AgentNeo rastrea la comunicación entre agentes, el uso de herramientas, los grafos de ejecución y el coste y la latencia por agente mediante un SDK de Python.
Funciones de monitoreo de AgentNeo
- Código abierto y ejecutable localmente
- Panel local interactivo (
localhost:3000) para monitoreo en tiempo real de flujos de trabajo multiagente. - Integración mediante decoradores (ej.,
@tracer.trace_agent,@tracer.trace_tool)
Más adecuado para: Equipos de ingeniería que experimentan con sistemas multiagente.
Laminar
Caso de uso: Rastrear el rendimiento en diferentes frameworks y modelos de LLM.
Laminar rastrea spans de ejecución, costes, uso de tokens y percentiles de latencia en frameworks y modelos de LLM.
Funciones de monitoreo de Laminar
- Análisis de rendimiento independiente del framework
- Inspección detallada de spans.
Más adecuado para: Análisis comparativo de rendimiento en stacks heterogéneos.
Helicone
Casos de uso: Rastrear flujos de trabajo de agentes de múltiples pasos y analizar patrones de sesiones de usuario.
Helicone captura volúmenes de solicitudes, costes, errores, tendencias de latencia y flujos de trabajo de agentes a nivel de sesión.
Funciones de monitoreo de Helicone
- Visibilidad del recorrido del usuario
- Análisis de tendencias históricas.
Más adecuado para: Equipos de producto que monitorizan patrones de uso y comportamiento a nivel de usuario.
Coval
Casos de uso: Simular miles de conversaciones de agentes, probar interacciones de voz/chat y validar el comportamiento antes del despliegue.
Coval simula miles de conversaciones para medir la finalización de tareas, la corrección y la efectividad de las llamadas a herramientas.
Funciones de monitoreo de Coval
- Pruebas de agentes basadas en simulación
- Detección automática de regresiones
- Soporte para agentes de voz y texto.
Más adecuado para: Validación previa al despliegue y detección de regresiones.
Datadog
Casos de uso: Observabilidad de infraestructura y aplicaciones con correlación de señales de LLM.
Datadog recopila métricas de infraestructura (CPU, memoria, red), datos de rendimiento de aplicaciones (latencia, tasas de error, rendimiento) y registros. Para aplicaciones de LLM, puede ingerir uso de tokens, coste por solicitud, latencia del modelo y señales relacionadas con la seguridad, como intentos de inyección de prompts.
Funciones de monitoreo de Datadog
- Observabilidad amplia de todo el sistema en infraestructura, aplicaciones y cargas de trabajo de IA
- Amplio ecosistema de integración (900+ integraciones) que permite la correlación entre el comportamiento de la IA y el estado de la infraestructura
Más adecuado para: Organizaciones que desean correlacionar el comportamiento de LLM con la infraestructura subyacente y el rendimiento de la aplicación, en lugar de inspeccionar el razonamiento del agente o los prompts
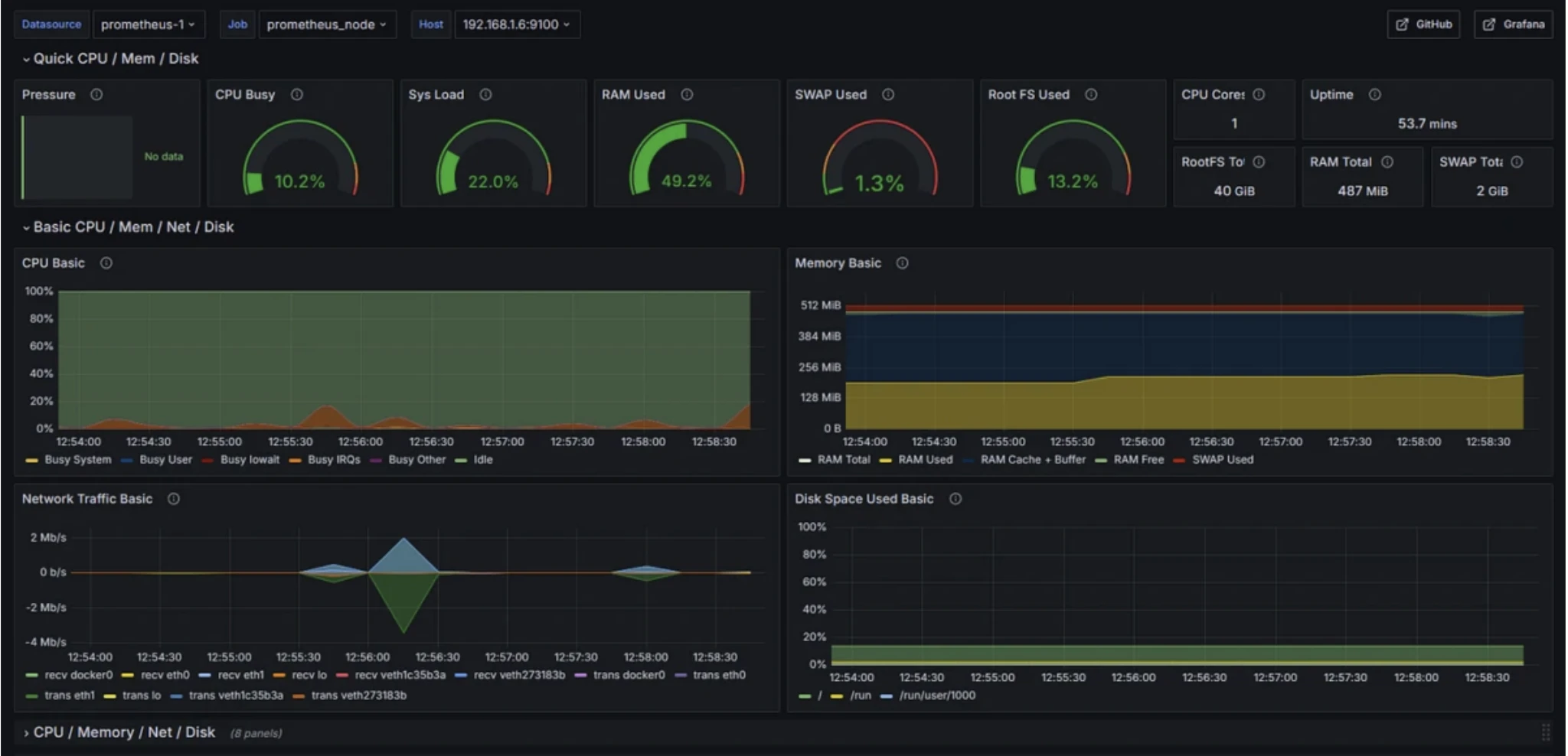
Prometheus
Casos de uso: Monitorizar el rendimiento del sistema, rastrear métricas de aplicaciones y configurar alertas para problemas de infraestructura.
Prometheus es un sistema de monitoreo de código abierto que recopila métricas de series temporales desde endpoints HTTP a intervalos regulares para rastrear métricas de infraestructura, aplicaciones, bases de datos, contenedores y métricas de negocio personalizadas.
Funciones de monitoreo de Prometheus
- Recopilación de métricas de series temporales mediante scraping basado en pull
- PromQL para consultas, agregación y condiciones de alerta
- Ecosistema de exportadores (ej., Node Exporter) para una amplia cobertura del sistema
Más adecuado para: Monitoreo de infraestructura y aplicaciones con alertas basadas en reglas.
Grafana
Casos de uso: Visualizar métricas, construir paneles y enrutar alertas a través de datos de LLM, agentes e infraestructura.
Grafana es una plataforma de visualización y análisis de código abierto que se integra con fuentes de datos como Prometheus, OpenTelemetry y Datadog para proporcionar paneles de observabilidad unificados.
Funciones de monitoreo de Grafana
- Paneles que abarcan métricas, registros y trazas
- Correlación entre sistemas para señales de LLM, agentes e infraestructura
- Enrutamiento de alertas y gestión de notificaciones.
Más adecuado para: Visualización de observabilidad centralizada y respuesta a incidentes.
Tutorial: Observabilidad de LangChain con Langfuse
Construimos un pipeline de LangChain de múltiples pasos con tres etapas:
- análisis de preguntas
- generación de respuestas
- verificación de respuestas
Después de configurar el pipeline, lo conectamos a Langfuse para monitorizar y rastrear la ejecución en tiempo real. De esta manera, pudimos explorar cómo Langfuse nos ayuda a obtener información detallada sobre el rendimiento, los costes y el comportamiento de las aplicaciones de IA.
Esto es lo que observamos a través de Langfuse:
Vista general del panel
Langfuse nos proporcionó varios paneles que nos dan visibilidad sobre diferentes aspectos del rendimiento del pipeline:
- Panel de Costes: Rastrea el gasto en todas las llamadas a API, con desgloses detallados por modelo y período de tiempo.
- Gestión de Uso: Monitoriza métricas de ejecución, como recuentos de observaciones y asignación de recursos, ayudándonos a rastrear cómo se utilizan los recursos durante la ejecución.
- Panel de Latencia: Este panel nos ayudó a analizar los tiempos de respuesta, detectar cuellos de botella y visualizar tendencias de rendimiento.
Métricas de uso
El panel de métricas de uso nos dio las siguientes perspectivas sobre cómo se desempeñó el sistema:
- Recuento total de trazas: Rastreamos ocho trazas, cada una representando un ciclo completo de pregunta-respuesta en el pipeline.
- Recuento total de observaciones: En promedio, cada traza tuvo 16 observaciones, lo que refleja la naturaleza de múltiples pasos del proceso.
Además, Langfuse nos permite rastrear patrones de uso, asignación de recursos y horas pico durante los últimos 7 días, ayudándonos a entender cuándo el sistema está más activo y cómo se distribuyen los recursos a lo largo del tiempo.
Inspección de trazas
Al profundizar en una traza individual, pudimos ver información detallada de ejecución:
- Filas de trazas: Cada fila representa una ejecución completa del pipeline con un ID de traza único.
- Métricas de latencia: El tiempo de ejecución varió, oscilando entre 0.00s y 34.08s.
- Recuentos de tokens: El panel rastreó el uso de tokens de entrada/salida, lo que ayuda en la gestión de costes y eficiencia.
- Filtrado por entorno: Pudimos filtrar trazas según los entornos de despliegue (ej., desarrollo, producción).
Detalles de trazas individuales
Exploramos más a fondo la traza con más detalle para comprender el desglose de la ejecución:
- Arquitectura de cadena secuencial: La traza mostró un flujo visual que muestra cada paso, comenzando desde SequentialChain → LLMChain → ChatOpenAI, con estructura jerárquica.
- Seguimiento de entrada/salida: La pregunta original, "¿Cuáles son los beneficios de usar Langfuse para la observabilidad de agentes de IA?" fue rastreada en cada etapa, junto con las respectivas salidas producidas por la IA en cada paso.
- Análisis de tokens: Observamos que se utilizaron 1.203 tokens para la entrada y 1.516 tokens para la salida, lo que tiene implicaciones de coste relacionadas con el uso de tokens y ayuda a optimizar la gestión de recursos.
- Datos de temporización: La latencia total para la traza completa fue de 34.08s, desglosada en cada componente:
- SequentialChain → 14.02s
- LLMChain → 10.25s
- ChatOpenAI → 9.81s
- Información del modelo: Langfuse confirmó el uso del modelo Anthropic Claude-Sonnet-4, con detalles sobre la configuración específica, incluyendo la configuración de temperatura.
- Salida formateada: Se proporcionaron vistas tanto en Vista previa como en JSON para la depuración, ofreciendo información sobre la respuesta del modelo en formato legible por humanos y en formato legible por máquina.
Análisis automatizado
Langfuse también proporcionó evaluaciones automatizadas de nuestras respuestas:
- Evaluación de calidad: El sistema evaluó la estructura, coherencia e integridad de las respuestas, destacando secciones bien organizadas pero sugiriendo que las respuestas podrían ser más concisas.
- Sugerencias de mejora: Identificó secciones con redundancia, sugiriendo dónde se podría mejorar la redacción, y combinó puntos relacionados para hacer la respuesta más transparente y más eficiente.
- Perspectivas de rendimiento: El sistema proporcionó retroalimentación sobre el uso de tokens y la relevancia de la respuesta, ayudándonos a optimizar la eficiencia mientras se asegura que la salida siga siendo útil y pertinente.
- Retroalimentación estructurada: La retroalimentación se organizó en categorías, permitiéndonos abordar áreas específicas de mejora de manera dirigida.
Análisis de usuarios
Langfuse rastrea las interacciones detalladas entre los usuarios y el agente de IA:
- Línea de tiempo de actividad del usuario: Muestra la primera y última interacción de cada usuario, ayudando a identificar usuarios activos versus inactivos. Podemos ver cuándo los usuarios interactuaron con el sistema por primera y última vez.
- Seguimiento del volumen de eventos: Rastrea el número de eventos que cada usuario desencadenó. Por ejemplo, algunos usuarios generaron más de 2.000 eventos, mostrando su nivel de engagement con el sistema.
- Análisis de consumo de tokens: Monitoriza el número total de tokens consumidos por cada usuario. El uso de tokens osciló entre 6.59K y 357K tokens, proporcionando información sobre el uso de recursos.
- Atribución de costes: Desglosa los costes asociados con cada usuario, facilitando el seguimiento del gasto y la optimización de la asignación del presupuesto para el uso de recursos.
- Identificación del usuario: Utiliza IDs de usuario anonimizados para mantener la privacidad mientras se rastrean las interacciones individuales de los usuarios, ayudando con el análisis de uso sin comprometer la confidencialidad del usuario.
La vista de sesión nos permite rastrear detalles granulares de las interacciones del usuario:
- Flujo completo de la conversación: Muestra la interacción completa de pregunta-respuesta, facilitando el seguimiento de toda la conversación de principio a fin.
- Visibilidad de la implementación: Muestra el código Python real utilizado durante la sesión, proporcionando información sobre la implementación técnica.
- Correlación entrada/salida: Vincula las preguntas del usuario con las respuestas correspondientes del sistema, ayudándonos a solucionar problemas e identificar dónde pueden haber ocurrido incidencias en la conversación.
- Metadatos de la sesión: Incluye detalles técnicos como temporización, contexto del usuario y datos específicos de implementación, ofreciendo una visión integral de la ejecución de la sesión.
Cuándo no usar herramientas de observabilidad
- Desarrollo en fase temprana: Si todavía está validando el ajuste producto-mercado o construyendo sus primeros flujos de trabajo de agentes, el enfoque debe estar en la funcionalidad principal más que en una observabilidad extensa.
- Cuellos de botella de API: Si sus principales problemas son los costes de API, la latencia o el almacenamiento en caché, la prioridad inmediata debería ser optimizar estas áreas, no rastrear métricas a nivel de sistema.
- Optimización del modelo: Si las mejoras están impulsadas principalmente por la selección de modelos, el fine-tuning o la ingeniería de prompts, las herramientas de observabilidad para deriva y sesgo pueden no ser aún necesarias.
Cuándo usar herramientas de observabilidad
- Producción a escala: Cuando está operando con múltiples modelos, agentes o cadenas, las herramientas de observabilidad son esenciales para monitorizar el rendimiento y garantizar el estado del sistema.
- Aplicaciones empresariales u orientadas al cliente: Para aplicaciones donde la fiabilidad, la seguridad y el cumplimiento son innegociables, las herramientas de observabilidad proporcionan la visibilidad y el control necesarios.
- Monitoreo continuo: Cuando necesita monitorizar la deriva, el sesgo, el rendimiento y los problemas de seguridad a lo largo del tiempo, lo cual no puede capturarse fácilmente con scripts básicos o comprobaciones manuales, las herramientas de observabilidad son cruciales.
- Escenarios de alto riesgo: En entornos donde el coste del fallo (ej., alucinaciones, salidas inseguras) es significativo, la observabilidad garantiza que los riesgos se minimicen y los problemas se detecten tempranamente.
Metodología del benchmark
Para evaluar la sobrecarga de rendimiento de las plataformas de observabilidad en aplicaciones de LLM en producción, desarrollamos un enfoque sistemático de benchmarking utilizando un flujo de trabajo agentivo del mundo real.
Aplicación de prueba
Construimos un sistema de planificación de viajes multiagente secuencial utilizando LangChain que procesa solicitudes de viaje en lenguaje natural a través de cinco etapas:
- Agente analizador: Extrae datos estructurados (origen, destino, fechas, duración) de la entrada del usuario
- Agente buscador de vuelos: Recupera vuelos disponibles mediante la API de Amadeus
- Agente de informes meteorológicos: Obtiene previsiones meteorológicas del destino utilizando WeatherAPI
- Agente recomendador de actividades: Sugiere actividades basadas en las condiciones meteorológicas
- Agente planificador de viajes: Sintetiza todas las salidas en un itinerario completo
El sistema utiliza Claude 4 Haiku a través de OpenRouter para todas las llamadas de LLM e integra APIs externas para datos en tiempo real.
Diseño del benchmark
Establecimiento de la línea base: Primero medimos el rendimiento de la aplicación sin ninguna instrumentación de observabilidad, ejecutando 100 consultas idénticas para establecer una línea base de comparación.
Integración de plataformas: Luego integramos cinco plataformas de observabilidad líderes (LangSmith, Laminar, AgentOps, Langfuse) una a la vez, instrumentando los mismos puntos de trazado en todas las plataformas para mantener la consistencia.
Ejecución secuencial: Cada plataforma se probó de forma independiente ejecutando todas las 100 consultas consecutivamente antes de pasar a la siguiente plataforma. Este enfoque minimiza la variabilidad de factores externos como las condiciones de red o los límites de tasa de API.
Entorno Controlado: Todas las pruebas se ejecutaron en la misma infraestructura de servidor con conjuntos de consultas idénticos para garantizar una comparación justa. Para aislar la sobrecarga de las variaciones de latencia inducidas por LLM, configuramos el modelo con temperature=0 y prompts estructurados para minimizar la variabilidad de las respuestas entre ejecuciones.
Métricas recopiladas
Para cada plataforma, medimos la latencia promedio y calculamos la sobrecarga como la latencia adicional introducida en comparación con la línea base: ((Platform Latency - Base Latency) / Base Latency) × 100
Preguntas frecuentes
La observabilidad es la capacidad de comprender el funcionamiento interno de un agente de IA examinando señales externas como registros, métricas y trazas.
Para los agentes de IA, esto implica monitorizar acciones, uso de herramientas, interacciones con modelos y respuestas para solucionar problemas y mejorar el rendimiento.
La observabilidad de agentes es crucial para rastrear y mejorar el rendimiento de la IA al permitir:
Comprender los compromisos: Ayuda a medir métricas clave como la precisión y el coste, facilitando el equilibrio entre el rendimiento y el uso de recursos.
Medir la latencia: El seguimiento de la latencia en tiempo real ofrece información sobre los tiempos de respuesta, ayudando a optimizar el rendimiento del agente.
Detectar entradas maliciosas: La observabilidad ayuda a identificar lenguaje dañino e inyecciones de prompts, permitiendo una intervención rápida para prevenir problemas.
Monitoreo de la retroalimentación del usuario: Al observar las interacciones y la retroalimentación de los usuarios, la observabilidad proporciona datos valiosos para la mejora continua y el fine-tuning de los agentes.
Los componentes clave incluyen:
– Seguimiento de acciones: Monitorizar cada paso dado por el agente.
– Uso de herramientas: Observar las herramientas y recursos que el agente utiliza.
– Medición de latencia: Monitorizar los tiempos de respuesta para optimizar el rendimiento.
– Evaluaciones: Valorar el comportamiento del agente y el rendimiento del modelo.
– Detección de entradas maliciosas: Identificar prompts dañinos o ataques.
Cita esta investigación
Elige el formato que se ajuste al lugar donde vas a publicar. Pegar la versión con enlace en tu CMS conserva el enlace de retroceso.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{15 Herramientas de Observabilidad de Agentes de IA: AgentOps & Langfuse}},
year = {2026},
month = jul,
howpublished = {\url{https://aimultiple.com/agentic-monitoring}},
note = {AIMultiple. Recuperado el 2 de Julio de 2026}
}














.")





Sé el primero en comentar
Tu dirección de correo electrónico no será publicada. Todos los campos son obligatorios. Los comentarios se dejan en su idioma original.